自然界和社会上发生的事件是多种多样的,有的是一定条件下必然发生的,还有的是在自然界和社会生活中大量存在着的随机现象,例如人的寿命,天气现象,金融市场等等。随机现象虽然存在不确定性,但还是有某些规律的。概率论与数理统计是研究和揭示随机现象统计规律性的一门数学学科。
概率论是数学的一个分支,研究如何定量描述随机现象及其规律
第1到第5章节为概率论的内容
数理统计则是以数据为唯一研究对象,包括数据的收集,整理,分析和建模,从而对随机现象的某些规律进行预测或决策。大数据时代的来临,更为统计的发展带来了极大的机遇和挑战
从第6章节开始为数理统计内容
在概率论中,满足以下三个特点的实验称为随机实验 :
可以在相同的条件下重复地进行
每次实验地可能结果不止一个,并且能事先明确实验地所有可能结果
进行一次实验之前不能确定哪一个结果会出现
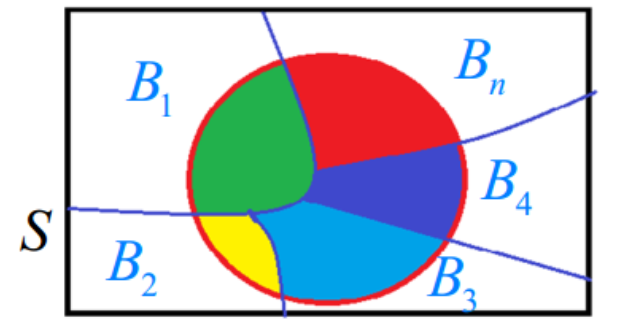
样本空间
定义:随机实验地所有可能结果构成地集和称为样本空间,记为S = { e } S = \lbrace e \rbrace S = { e } S S S e e e
随机事件
定义:样本空间S S S A A A A A A A A A A A A A A A
如果把S看作事件,则每次实验S总是发生,所以S称为必然事件
如果事件只含有一个样本点,称其为基本事件
如果事件是空集,里面不包括任何样本点,记为∅ \varnothing ∅ ∅ \varnothing ∅ ∅ \varnothing ∅ 不可能事件
事件的相互关系有:
相等 A ⊂ B A \subset B A ⊂ B
和事件 A ∪ B A \cup B A ∪ B
积事件 A ∩ B A \cap B A ∩ B
差事件 A − B A - B A − B
互不相容,互斥的 A ∩ B = ∅ A \cap B = \varnothing A ∩ B = ∅
逆事件,对立事件 B ∪ B ‾ = S , B ∩ B ‾ = ∅ B \cup \overline{B} = S, \quad B \cap \overline{B} = \varnothing B ∪ B = S , B ∩ B = ∅
在进行事件运算时,常用以下定律,设A,B,C为事件,则有:
交换律 :A ∪ B = B ∪ A ; A ∩ B = B ∩ A A \cup B = B \cup A ; \quad A \cap B = B \cap A A ∪ B = B ∪ A ; A ∩ B = B ∩ A 结合律 :A ∪ ( B ∪ C ) = ( A ∪ B ) ∪ C ; A ∩ ( B ∩ C ) = ( A ∩ B ) ∩ C A \cup (B \cup C) = (A \cup B) \cup C ; \quad A \cap (B \cap C) = (A \cap B) \cap C A ∪ ( B ∪ C ) = ( A ∪ B ) ∪ C ; A ∩ ( B ∩ C ) = ( A ∩ B ) ∩ C 分配律 :A ∪ ( B ∩ C ) = ( A ∪ B ) ∩ ( A ∪ C ) ; A ∩ ( B ∪ C ) = ( A ∩ B ) ∪ ( A ∩ C ) A \cup (B \cap C) = (A \cup B) \cap (A \cup C) ; \quad A \cap (B \cup C) = (A \cap B) \cup (A \cap C) A ∪ ( B ∩ C ) = ( A ∪ B ) ∩ ( A ∪ C ) ; A ∩ ( B ∪ C ) = ( A ∩ B ) ∪ ( A ∩ C ) 德摩根律 :A ∪ B ‾ = A ‾ ∩ B ‾ ; A ∩ B ‾ = A ‾ ∪ B ‾ \overline{A \cup B} = \overline{A} \cap \overline{B} ; \quad \overline{A \cap B} = \overline{A} \cup \overline{B} A ∪ B = A ∩ B ; A ∩ B = A ∪ B
频率定义:f n ( A ) = n A n \color{blue}{f_n(A) = \frac{n_A}{n}} f n ( A ) = n n A
其中n A n_A n A f n ( A ) f_n(A) f n ( A )
频率的基本性质:
0 ≤ f n ( A ) ≤ 1 0 \leq f_n(A) \leq 1 0 ≤ f n ( A ) ≤ 1 f n ( S ) = 1 f_n(S) = 1 f n ( S ) = 1 若A 1 ⋯ A k A_1 \cdots A_k A 1 ⋯ A k f n ( A 1 ∪ ⋯ ∪ A k ) = f n ( A 1 ) + ⋯ + f n ( A k ) f_n(A_1 \cup \cdots \cup A_k) = f_n(A_1) + \cdots + f_n(A_k) f n ( A 1 ∪ ⋯ ∪ A k ) = f n ( A 1 ) + ⋯ + f n ( A k )
概率的统计性定义:当试验的次数增加时,随机事件A发生的频率的稳定值p称为概率,记为P ( A ) = p P(A) = p P ( A ) = p
概率的公理化定义:
设随机试验对应的样本空间为S,对每个事件A,定义P(A),满足:
非负性:P ( A ) ≥ 0 \color{blue}{P(A) \geq 0} P ( A ) ≥ 0
规范性:P ( S ) = 1 \color{blue}{P(S) = 1} P ( S ) = 1
可列可加性:A 1 , ⋯ A_1, \cdots A 1 , ⋯ A i A j = ∅ , i ≠ j A_iA_j = \varnothing, i \neq j A i A j = ∅ , i = j P ( ⋃ i = 1 ∞ ) = ∑ i = 1 ∞ P ( A i ) \color{blue}{P(\bigcup_{i=1}^{\infty}) = \sum_{i=1}^{\infty} P(A_i)} P ( ⋃ i = 1 ∞ ) = ∑ i = 1 ∞ P ( A i )
称P(A)为事件A的概率
概率的性质:
P ( ∅ ) = 0 \color{blue}{P(\varnothing) = 0} P ( ∅ ) = 0 P ( A ) = 1 − P ( A ‾ ) \color{blue}{P(A) = 1 - P(\overline{A})} P ( A ) = 1 − P ( A ) A 1 , ⋯ , A n , A i A j = ∅ , i ≠ j ⇒ P ( ⋃ i = 1 n A i ) = ∑ i = 1 ∞ P ( A i ) \color{blue}{A_1, \cdots, A_n, A_iA_j = \varnothing, i \neq j \Rightarrow P(\bigcup_{i=1}^n A_i) = \sum_{i=1}^{\infty} P(A_i)} A 1 , ⋯ , A n , A i A j = ∅ , i = j ⇒ P ( ⋃ i = 1 n A i ) = ∑ i = 1 ∞ P ( A i ) 若A ⊂ B \color{blue}{A \subset B} A ⊂ B P ( B − A ) = P ( B ) − P ( A ) \color{blue}{P(B - A) = P(B) - P(A)} P ( B − A ) = P ( B ) − P ( A )
概率的加法公式:P ( A ∪ B ) = P ( A ) + P ( B ) − P ( A B ) \color{blue}{P(A \cup B) = P(A) + P(B) - P(AB)} P ( A ∪ B ) = P ( A ) + P ( B ) − P ( A B )
定义:若试验满足:
样本空间S中样本点有限(有限性)
出现每一个样本点的概率相等(等可能性)
称这种试验为等可能概型(或古典概型)
事件A A A B B B 条件概率
P ( B ∣ A ) = P ( A B ) P ( A ) \begin{aligned}
P(B \ |\ A) = \frac{P(AB)}{P(A)}
\end{aligned}
P ( B ∣ A ) = P ( A ) P ( A B )
P ( B ∣ A ) P(B \ |\ A) P ( B ∣ A ) A A A B B B P ( A B ) P(AB) P ( A B ) A A A B B B
条件概率本质上是把原来的样本空间S缩小到了现在的A的范围,所以它依然是概率,同样满足概率的性质:
非负性 :对于每一个事件有P ( B ∣ A ) ≥ 0 P(B \ |\ A) \geq 0 P ( B ∣ A ) ≥ 0 规范性 :对于必然事件S S S P ( S ∣ A ) = 1 P(S \ |\ A) = 1 P ( S ∣ A ) = 1 可列可加性 :设B 1 , B 2 , ⋯ B_1,B_2,\cdots B 1 , B 2 , ⋯ P ( ⋃ i = 1 ∞ B i ∣ A ) = ∑ i = 1 ∞ P ( B i ∣ A ) P(\bigcup^\infty_{i=1} B_i \ |\ A) = \sum^\infty_{i=1}P(B_i \ |\ A) P ( ⋃ i = 1 ∞ B i ∣ A ) = ∑ i = 1 ∞ P ( B i ∣ A )
当下面的条件概率都有意义时:
P ( A B ) = P ( A ) ⋅ P ( B ∣ A ) = P ( B ) ⋅ P ( A ∣ B ) \color{blue}{P(AB) = P(A) \cdot P(B \ |\ A) = P(B) \cdot P(A \ |\ B)} P ( A B ) = P ( A ) ⋅ P ( B ∣ A ) = P ( B ) ⋅ P ( A ∣ B ) P ( A B C ) = P ( A ) P ( B ∣ A ) P ( C ∣ A B ) \color{blue}{P(ABC) = P(A) P(B \ |\ A) P(C \ |\ AB)} P ( A B C ) = P ( A ) P ( B ∣ A ) P ( C ∣ A B ) P ( A 1 A 2 ⋯ A n ) = P ( A 1 ) P ( A 2 ∣ A 1 ) P ( A 3 ∣ A 1 A 2 ) ⋯ P ( A n ∣ A 1 ⋯ A n − 1 ) \color{blue}{P(A_1 A_2 \cdots A_n) = P(A_1) P(A_2 \ |\ A_1) P(A_3 \ |\ A_1A_2) \cdots P(A_n \ |\ A_1 \cdots A_{n-1})} P ( A 1 A 2 ⋯ A n ) = P ( A 1 ) P ( A 2 ∣ A 1 ) P ( A 3 ∣ A 1 A 2 ) ⋯ P ( A n ∣ A 1 ⋯ A n − 1 )
定义:称B 1 , ⋯ , B n B_1, \cdots, B_n B 1 , ⋯ , B n 划分 ,若
不漏 B 1 ∪ ⋯ ∪ B n = S B_1 \cup \cdots \cup B_n = S B 1 ∪ ⋯ ∪ B n = S
不重 B i B j = ∅ , i ≠ j B_iB_j = \varnothing, i \neq j B i B j = ∅ , i = j
定理:设B 1 , ⋯ , B n B_1, \cdots, B_n B 1 , ⋯ , B n P ( B i ) > 0 P(B_i) > 0 P ( B i ) > 0 全概率公式 :
P ( A ) = ∑ J = 1 n P ( B j ) ⋅ P ( A ∣ B j ) \begin{aligned}
\color{blue}{P(A) = \sum_{J = 1}^n P(B_j) \cdot P(A \ |\ B_j)}
\end{aligned}
P ( A ) = J = 1 ∑ n P ( B j ) ⋅ P ( A ∣ B j )
定理:设B 1 , ⋯ , B n B_1, \cdots, B_n B 1 , ⋯ , B n P ( B i ) > 0 P(B_i) > 0 P ( B i ) > 0 P ( A ) > 0 P(A) > 0 P ( A ) > 0 Bayes公式 :
P ( B i ∣ A ) = P ( B i ) P ( A ∣ B i ) ∑ j = 1 n P ( B j ) P ( A ∣ B j ) \begin{aligned}
\color{blue}{P(B_i \ |\ A) = \frac{P(B_i) P(A \ |\ B_i)}{\sum_{j=1}^n P(B_j) P(A \ |\ B_j)}}
\end{aligned}
P ( B i ∣ A ) = ∑ j = 1 n P ( B j ) P ( A ∣ B j ) P ( B i ) P ( A ∣ B i )
定义:设A , B A,B A , B
P ( A B ) = P ( A ) P ( B ) \begin{aligned}
\color{blue}{P(AB) = P(A)P(B)}
\end{aligned}
P ( A B ) = P ( A ) P ( B )
则称A , B A,B A , B 相互独立
若P ( A ) > 0 , P ( B ) > 0 P(A) > 0, P(B) > 0 P ( A ) > 0 , P ( B ) > 0 A , B A,B A , B A , B A,B A , B
若A , B A,B A , B P ( B ∣ A ) = P ( B ) P(B \ |\ A) = P(B) P ( B ∣ A ) = P ( B )
若A , B A,B A , B A A A B ‾ \overline{B} B A ‾ \overline{A} A B B B A ‾ \overline{A} A B ‾ \overline{B} B
定义:设随机试验的样本空间为S,若
X = X ( e ) \begin{aligned}
\color{blue}{X = X(e)}
\end{aligned}
X = X ( e )
为定义在S上的实值单值函数,则称X ( e ) X(e) X ( e ) 随机变量 ,简写为X 。
常见的两类随机变量:
离散型随机变量及其分布率
定义:若随机变量X的取值为有限个或可数个,则称X为离散型随机变量
离散型随机变量的概率分布律(简称分布律):
X X X x 1 x_1 x 1 x 2 x_2 x 2 ⋯ \cdots ⋯ x k x_k x k ⋯ \cdots ⋯
P P P p 1 p_1 p 1 p 2 p_2 p 2 ⋯ \cdots ⋯ p k p_k p k ⋯ \cdots ⋯
分布律的内容:
分布律的性质:p k ≥ 0 , ∑ k = 1 + ∞ p k = 1 \color{blue}{p_k \geq 0, \quad \sum_{k=1}^{+\infty} p_k = 1} p k ≥ 0 , ∑ k = 1 + ∞ p k = 1
分布律的另一表现形式:P ( X = x k ) = p k , k = 1 , 2 , ⋯ P(X = x_k) = p_k, \quad k = 1, 2, \cdots P ( X = x k ) = p k , k = 1 , 2 , ⋯
下面介绍三种重要的离散型随机变量
定义:若X的概率分布律为
X X X 0 0 0 1 1 1
P P P 1 − p 1-p 1 − p p p p
其中0 < p < 1 0 < p < 1 0 < p < 1 0-1分布(或两点分布) ,记为X ∼ 0 − 1 ( p ) \color{blue}{X \sim 0-1(p)} X ∼ 0 − 1 ( p ) X ∼ B ( 1 , p ) \color{blue}{X \sim B(1, p)} X ∼ B ( 1 , p )
其分布律还可以写成:P ( X = k ) = p k ( 1 − p ) 1 − k , k = 0 , 1 P(X = k) = p^k(1 - p)^{1-k}, \quad k = 0,1 P ( X = k ) = p k ( 1 − p ) 1 − k , k = 0 , 1
设试验E只有两个可能的结果:A A A A ‾ \overline{A} A P ( A ) = p , 0 < p < 1 P(A) = p, \quad 0 < p < 1 P ( A ) = p , 0 < p < 1 独立地重复 进行n次,则称这一串重复地独立试验为n重伯努利试验
二项分布定义:若X X X
P ( X = k ) = C n k p k ( 1 − p ) n − k , k = 0 , 1 , ⋯ , n \begin{aligned}
\color{blue}{P(X = k) = C_n^k p^k (1 - p)^{n-k}, \quad k = 0, 1, \cdots, n}
\end{aligned}
P ( X = k ) = C n k p k ( 1 − p ) n − k , k = 0 , 1 , ⋯ , n
其中n ≥ 1 , 0 < p < 1 n \geq 1,\quad 0 < p < 1 n ≥ 1 , 0 < p < 1 X X X n , p n,p n , p 二项分布(Binomial) ,记为X ∼ B ( n , p ) \color{blue}{X \sim B(n, p)} X ∼ B ( n , p )
E ( X ) = n p E(X) = np E ( X ) = n p V ( X ) = n p ( 1 − p ) V(X) = np(1 - p) V ( X ) = n p ( 1 − p )
〇×で解答する試験において、気まぐれに解答する。10問ある時、正答の個数を X X X X X X X ≥ 8 X \geq 8 X ≥ 8
E ( X ) = n p = 10 ∗ 0.5 = 5 E(X) = np = 10 * 0.5 = 5 E ( X ) = n p = 1 0 ∗ 0 . 5 = 5 V ( X ) = n p ( 1 − q ) = 10 ∗ 0.5 ∗ 0.5 = 2.5 V(X) = np(1 - q) = 10 * 0.5 * 0.5 = 2.5 V ( X ) = n p ( 1 − q ) = 1 0 ∗ 0 . 5 ∗ 0 . 5 = 2 . 5 P ( X ≥ 8 ) = P ( X = 8 ) + P ( X = 9 ) + P ( X = 10 ) = C 10 8 ( 1 2 ) 8 ( 1 2 ) 2 + C 10 9 ( 1 2 ) 9 ( 1 2 ) + C 10 10 ( 1 2 ) 10 ( 1 2 ) 0 ≃ 0.0547 P(X \geq 8) = P(X = 8) + P(X = 9) + P(X = 10) = C_{10}^8 (\frac{1}{2})^8 (\frac{1}{2})^2 + C_{10}^9 (\frac{1}{2})^9 (\frac{1}{2}) + C_{10}^{10} (\frac{1}{2})^{10} (\frac{1}{2})^0 \simeq 0.0547 P ( X ≥ 8 ) = P ( X = 8 ) + P ( X = 9 ) + P ( X = 1 0 ) = C 1 0 8 ( 2 1 ) 8 ( 2 1 ) 2 + C 1 0 9 ( 2 1 ) 9 ( 2 1 ) + C 1 0 1 0 ( 2 1 ) 1 0 ( 2 1 ) 0 ≃ 0 . 0 5 4 7
定义:若X X X
P ( X = k ) = λ k e − λ k ! , k = 0 , 1 , 2 , ⋯ \begin{aligned}
\color{blue}{P(X = k) = \frac{\lambda^k e^{-\lambda}}{k!}, \quad k = 0, 1, 2, \cdots}
\end{aligned}
P ( X = k ) = k ! λ k e − λ , k = 0 , 1 , 2 , ⋯
E ( X ) = λ E(X) = \lambda E ( X ) = λ V ( X ) = λ V(X) = \lambda V ( X ) = λ
其中λ > 0 \lambda > 0 λ > 0 X X X λ \lambda λ 泊松分布(Poisson) ,记为X ∼ π ( λ ) \color{blue}{X \sim \pi(\lambda)} X ∼ π ( λ ) X ∼ P ( λ ) \color{blue}{X \sim P(\lambda)} X ∼ P ( λ )
泊松分布的用途:
某人一天内收到的微信的数量
来到某公交汽车站的乘客
某放射性物质发射出的粒子
显微镜下某区域中的白血球
如果某事件以固定强度 λ \lambda λ 泊松分布
二项分布与泊松分布有以下近似关系:
C n k p k ( 1 − p ) n − k ≃ e − λ λ k k ! , λ = n p , n > 10 , p < 0.1 \begin{aligned}
C_n^k p^k (1 - p)^{n - k} \simeq \frac{e^{-\lambda}\lambda^k}{k!}, \quad \lambda = np, n > 10, p < 0.1
\end{aligned}
C n k p k ( 1 − p ) n − k ≃ k ! e − λ λ k , λ = n p , n > 1 0 , p < 0 . 1
ある製品の製造工程では、微小領域に1万個の点にレーザーを当てていく。位置をずれるのは2万個に一つ であるという。この工程ではずれが一つもないという確率を求めよ
λ = n p = 10000 ∗ 1 20000 = 0.5 \lambda = np = 10000 * \frac{1}{20000} = 0.5 λ = n p = 1 0 0 0 0 ∗ 2 0 0 0 0 1 = 0 . 5 E ( X ) = λ = 0.5 E(X) = \lambda = 0.5 E ( X ) = λ = 0 . 5 V ( X ) = λ = 0.5 V(X) = \lambda = 0.5 V ( X ) = λ = 0 . 5 P ( X = 0 ) = P ( 0 , λ ) = e − 0.5 ⋅ 0. 5 0 0 ! ≃ 0.606531 P(X = 0) = P(0, \lambda) = e^{-0.5} \cdot \frac{0.5^0}{0!} \simeq 0.606531 P ( X = 0 ) = P ( 0 , λ ) = e − 0 . 5 ⋅ 0 ! 0 . 5 0 ≃ 0 . 6 0 6 5 3 1 B ( n , p ) = C 10000 0 ( 1 20000 ) 0 ( 19999 20000 ) 10000 ≃ 0.606523 B(n, p) = C_{10000}^0 (\frac{1}{20000})^0 (\frac{19999}{20000})^{10000} \simeq 0.606523 B ( n , p ) = C 1 0 0 0 0 0 ( 2 0 0 0 0 1 ) 0 ( 2 0 0 0 0 1 9 9 9 9 ) 1 0 0 0 0 ≃ 0 . 6 0 6 5 2 3
定义:若X X X
P ( X = k ) = p ( 1 − p ) k − 1 , k = 1 , 2 , 3 , ⋯ , \begin{aligned}
P(X = k) = p(1 - p)^{k - 1}, \quad k = 1, 2, 3, \cdots,
\end{aligned}
P ( X = k ) = p ( 1 − p ) k − 1 , k = 1 , 2 , 3 , ⋯ ,
其中0 < p < 1 0 < p < 1 0 < p < 1 X X X p p p 几何分布(Geometric) ,记为X ∼ G e o m ( p ) \color{blue}{X \sim Geom(p)} X ∼ G e o m ( p )
几何分布的用途:在重复多次的伯努利实验中,实验进行到某种结果出现第一次为止,此时的试验总次数服从几何分布 。如:射击,首次击中目标时射击的次数
E ( X ) = 1 p E(X) = \frac{1}{p} E ( X ) = p 1 V ( X ) = 1 − p p 2 V(X) = \frac{1 - p}{p^2} V ( X ) = p 2 1 − p
合格率10%の試験を挑み、X X X X X X X = 3 X = 3 X = 3
E ( X ) = 1 p = 1 0.1 = 10 E(X) = \frac{1}{p} = \frac{1}{0.1} = 10 E ( X ) = p 1 = 0 . 1 1 = 1 0 V ( X ) = 1 − p p 2 = 1 − 0.1 0. 1 2 = 90 V(X) = \frac{1 - p}{p^2} = \frac{1 - 0.1}{0.1^2} = 90 V ( X ) = p 2 1 − p = 0 . 1 2 1 − 0 . 1 = 9 0 P ( X = 3 ) = 0. 9 2 ∗ 0.1 = 0.081 P(X = 3) = 0.9^2 * 0.1 = 0.081 P ( X = 3 ) = 0 . 9 2 ∗ 0 . 1 = 0 . 0 8 1
定义:随机变量X X X x x x
F ( x ) = P ( X ≤ x ) \begin{aligned}
F(x) = P(X \leq x)
\end{aligned}
F ( x ) = P ( X ≤ x )
为X X X 分布函数
分布函数用途:可以给出随机变量落入任意一个范围的可能性
F ( x ) F(x) F ( x )
0 ≤ F ( x ) ≤ 1 0 \leq F(x) \leq 1 0 ≤ F ( x ) ≤ 1 F ( x ) F(x) F ( x ) F ( − ∞ ) = 0 , F ( + ∞ ) = 1 F(-\infty) = 0, F(+\infty) = 1 F ( − ∞ ) = 0 , F ( + ∞ ) = 1 F ( x ) F(x) F ( x ) F ( x + 0 ) = F ( x ) F(x + 0) = F(x) F ( x + 0 ) = F ( x )
对于随机变量X X X F ( x ) F(x) F ( x ) f ( x ) f(x) f ( x ) x x x
F ( x ) = ∫ − ∞ x f ( t ) d t \begin{aligned}
\color{blue}{F(x) = \int_{-\infty}^x f(t) dt}
\end{aligned}
F ( x ) = ∫ − ∞ x f ( t ) d t
则称X X X 连续型随机变量 ,其中f ( x ) f(x) f ( x ) X X X 概率密度函数 ,简称概率密度,有时也写为f X ( x ) f_X(x) f X ( x )
f ( x ) f(x) f ( x )
f ( x ) ≥ 0 f(x) \geq 0 f ( x ) ≥ 0 ∫ − ∞ + ∞ f ( x ) d x = 1 \int_{-\infty}^{+\infty} f(x) dx = 1 ∫ − ∞ + ∞ f ( x ) d x = 1 对于任意的实数x 1 , x 2 ( x 1 < x 2 ) x_1,x_2(x_1 < x_2) x 1 , x 2 ( x 1 < x 2 ) P ( x 1 < X ≤ x 2 ) = ∫ X 1 X 2 f ( t ) d t P(x_1 < X \leq x_2) = \int_{X_1}^{X_2} f(t)dt P ( x 1 < X ≤ x 2 ) = ∫ X 1 X 2 f ( t ) d t
若f ( x ) f(x) f ( x ) x x x F ′ ( x ) = f ( x ) F'(x) = f(x) F ′ ( x ) = f ( x )
下面介绍3种重要的连续性随机变量
若 X X X
f ( x ) = { 1 b − a , x ∈ ( a , b ) 0 , 其他 \begin{aligned}
\color{blue}{f(x) =
\begin{cases}
\frac{1}{b-a}, \quad &x \in (a, b)
\\
0, \quad &\text{其他}
\end{cases}}
\end{aligned}
f ( x ) = { b − a 1 , 0 , x ∈ ( a , b ) 其他
其中 a < b a < b a < b X X X ( a , b ) (a, b) ( a , b ) 均匀分布(Uniform) ,记为 X ∼ U ( a , b ) \color{blue}{X \sim U(a, b)} X ∼ U ( a , b ) X ∼ Unif ( a , b ) \color{blue}{X \sim \text{Unif}(a, b)} X ∼ Unif ( a , b )
均匀分布的性质:均匀分布具有等可能性 ,即,服从 U ( a , b ) U(a, b) U ( a , b ) X X X ( a , b ) (a, b) ( a , b ) X X X ( a , b ) (a, b) ( a , b ) 等长度 的任意子区间上是等可能 的。
E ( X ) = b + a 2 E(X) = \frac{b + a}{2} E ( X ) = 2 b + a V ( X ) = ( b − a ) 2 12 V(X) = \frac{(b - a)^2}{12} V ( X ) = 1 2 ( b − a ) 2
ある自動車のブレーキテストで時速50kmでブレーキをかけた時、とまるまでに要する距離 X X X ( a , b ) (a, b) ( a , b ) 一様分布 に従うという。b b b a a a
P ( a < X < a + b 2 ) = ∫ a a + b 2 1 b − a d x = 1 2 P(a < X < \frac{a+b}{2}) = \int_a^{\frac{a+b}{2}} \frac{1}{b - a} dx = \frac{1}{2}
P ( a < X < 2 a + b ) = ∫ a 2 a + b b − a 1 d x = 2 1
若 X X X
f ( x ) = { λ e − λ x , x > 0 0 , x ≤ 0 \begin{aligned}
\color{blue}{f(x) =
\begin{cases}
\lambda e^{-\lambda x}, \quad &x > 0
\\
0, \quad &x \leq 0
\end{cases}}
\end{aligned}
f ( x ) = { λ e − λ x , 0 , x > 0 x ≤ 0
其中 λ > 0 \lambda > 0 λ > 0 X X X λ \lambda λ 指数分布(Exponential) ,记为 X ∼ E ( λ ) \color{blue}{X \sim E(\lambda)} X ∼ E ( λ ) X ∼ Exp ( λ ) \color{blue}{X \sim \text{Exp}(\lambda)} X ∼ Exp ( λ )
E ( X ) = 1 λ E(X) = \frac{1}{\lambda} E ( X ) = λ 1 V ( X ) = 1 λ 2 V(X) = \frac{1}{\lambda^2} V ( X ) = λ 2 1
随机变量 X X X 分布函数 为:
F ( x ) = { 1 − e − λ x , x > 0 0 , x ≤ 0 \begin{aligned}
\color{blue}{F(x) =
\begin{cases}
1 - e^{-\lambda x}, \quad &x > 0
\\
0, \quad &x \leq 0
\end{cases}}
\end{aligned}
F ( x ) = { 1 − e − λ x , 0 , x > 0 x ≤ 0
指数分布的性质:指数分布具有无记忆性
指数分布的用途:
指数分布可以用来表示独立随机事件发生的时间间隔,比如旅客进机场的时间间隔,中文维基百科新条目出现的时间间隔等等
在排队论中,一个旅客接受服务的时间长短也可以用指数分布来近似
无记忆性的现象(连续时)
若 X X X
f ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 , − ∞ < x < + ∞ \begin{aligned}
\color{blue}{f(x) = \frac{1}{\sqrt{2\pi}\sigma} e^{-\frac{(x - \mu)^2}{2\sigma^2}}, \quad -\infty < x < +\infty}
\end{aligned}
f ( x ) = 2 π σ 1 e − 2 σ 2 ( x − μ ) 2 , − ∞ < x < + ∞
其中 − ∞ < μ < + ∞ , σ > 0 -\infty < \mu < +\infty, \sigma > 0 − ∞ < μ < + ∞ , σ > 0 X X X μ , σ \mu, \sigma μ , σ 正态分布(或高斯分布) ,记为 X ∼ N ( μ , σ 2 ) \color{blue}{X \sim N(\mu, \sigma^2)} X ∼ N ( μ , σ 2 )
E ( X ) = μ E(X) = \mu E ( X ) = μ V ( X ) = σ 2 V(X) = \sigma^2 V ( X ) = σ 2
正态分布的特征:
f ( x ) f(x) f ( x ) x = μ x = \mu x = μ 当 x ≤ μ x \leq \mu x ≤ μ f ( x ) f(x) f ( x )
f m a x = f ( μ ) = 1 2 π σ f_{max} = f(\mu) = \frac{1}{\sqrt{2\pi}\sigma} f m a x = f ( μ ) = 2 π σ 1 lim ∣ x − μ ∣ → ∞ f ( x ) = 0 \lim_{|x - \mu| \rightarrow \infty} f(x) = 0 lim ∣ x − μ ∣ → ∞ f ( x ) = 0
正态分布的参数:
μ \mu μ 位置参数 ,决定对称轴位置σ \sigma σ 尺度参数 ,决定曲线分散程度
正态分布的用途:
自然界和人类社会中很多现象可以看做正态分布
例如:人的生理尺寸(身高,体重),医学检验指标(红细胞数,血小板),测量误差等等
多个随机变量的和可以用正态分布来近似
例如:注册MOOC的某位同学完成所有作业的时间,二项分布等等
若 Z ∼ N ( 0 , 1 ) Z \sim N(0, 1) Z ∼ N ( 0 , 1 ) Z Z Z
Z Z Z ϕ ( z ) = 1 2 π e − z 2 2 \phi(z) = \frac{1}{\sqrt{2\pi}}e^{-\frac{z^2}{2}} ϕ ( z ) = 2 π 1 e − 2 z 2 Z Z Z Φ ( z ) = ∫ − ∞ Z 1 2 π e − t 2 2 d t \Phi(z) = \int_{-\infty}^Z \frac{1}{\sqrt{2\pi}} e^{-\frac{t^2}{2}} \, dt Φ ( z ) = ∫ − ∞ Z 2 π 1 e − 2 t 2 d t
标准正态分布的分布函数有一个重要的性质:
Φ ( − z 0 ) = 1 − Φ ( z 0 ) \Phi(-z_0) = 1 - \Phi(z_0)
Φ ( − z 0 ) = 1 − Φ ( z 0 )
对于任意的实数 z 0 z_0 z 0
此外,当 X ∼ N ( μ , σ 2 ) X \sim N(\mu, \sigma^2) X ∼ N ( μ , σ 2 ) X − μ σ ∼ N ( 0 , 1 ) \frac{X - \mu}{\sigma} \sim N(0, 1) σ X − μ ∼ N ( 0 , 1 ) X ∼ N ( μ , σ 2 ) X \sim N(\mu, \sigma^2) X ∼ N ( μ , σ 2 ) a a a
F X ( a ) = P ( X ≤ a ) = P ( X − μ σ ≤ a − μ σ ) = Φ ( a − μ σ ) \color{blue}{F_X(a) = P(X \leq a) = P(\frac{X - \mu}{\sigma} \leq \frac{a - \mu}{\sigma}) = \Phi(\frac{a - \mu}{\sigma})}
F X ( a ) = P ( X ≤ a ) = P ( σ X − μ ≤ σ a − μ ) = Φ ( σ a − μ )
在实际中,我们常对某些随机变量的函数更感兴趣,例如,我们能测量圆轴截面的直径 d d d A A A A A A d d d
一般,若已知 X X X Y = g ( X ) Y = g(X) Y = g ( X ) Y Y Y Y Y Y 等价事件 来给出概率分布
若 X X X 离散型随机变量 ,则先写出 Y Y Y y 1 , ⋯ , y j , ⋯ y_1, \cdots, y_j, \cdots y 1 , ⋯ , y j , ⋯ { Y = y j } \lbrace Y = y_j \rbrace { Y = y j } { X ∈ D } \lbrace X \in D \rbrace { X ∈ D } P ( Y = y j ) = P ( X ∈ D ) P(Y = y_j) = P(X \in D) P ( Y = y j ) = P ( X ∈ D )
若 X X X 连续型随机变量 ,先根据 X X X Y Y Y Y Y Y F Y ( y ) = P ( Y ≤ y ) F_Y(y) = P(Y \leq y) F Y ( y ) = P ( Y ≤ y ) { Y ≤ y } \lbrace Y \leq y \rbrace { Y ≤ y } { X ∈ D } \lbrace X \in D \rbrace { X ∈ D } F Y ( y ) = P ( X ∈ D ) F_Y(y) = P(X \in D) F Y ( y ) = P ( X ∈ D ) Y Y Y f Y ( y ) f_Y(y) f Y ( y )
定理:设随机变量 X ∼ f X ( x ) , − ∞ < x < + ∞ , Y = g ( X ) , g ′ ( x ) > 0 X \sim f_X(x), -\infty < x < +\infty, Y = g(X), g'(x) > 0 X ∼ f X ( x ) , − ∞ < x < + ∞ , Y = g ( X ) , g ′ ( x ) > 0 g ′ ( x ) < 0 g'(x) < 0 g ′ ( x ) < 0 Y Y Y
f Y ( y ) = { f X ( h ( y ) ) ⋅ ∣ h ′ ( y ) ∣ , α < y < β 0 , 其他 \begin{aligned}
f_Y(y) = \begin{cases}
f_X(h(y)) \cdot |h'(y)|, \quad &\alpha < y < \beta
\\
0, \quad &\text{其他}
\end{cases}
\end{aligned}
f Y ( y ) = { f X ( h ( y ) ) ⋅ ∣ h ′ ( y ) ∣ , 0 , α < y < β 其他
注意:
这里 ( α , β ) (\alpha, \beta) ( α , β ) Y Y Y α = g ( − ∞ ) , β = g ( + ∞ ) \alpha = g(-\infty), \beta = g(+\infty) α = g ( − ∞ ) , β = g ( + ∞ ) g ′ ( x ) < 0 g'(x) < 0 g ′ ( x ) < 0 α = g ( + ∞ ) , β = g ( − ∞ ) \alpha = g(+\infty), \beta = g(-\infty) α = g ( + ∞ ) , β = g ( − ∞ )
h h h g g g h ( y ) = x ⇔ y = g ( x ) h(y) = x \Leftrightarrow y = g(x) h ( y ) = x ⇔ y = g ( x )
一般的,若随机变量 X ∼ N ( μ , σ 2 ) X \sim N(\mu, \sigma^2) X ∼ N ( μ , σ 2 ) Y = a X + b ⇒ Y ∼ N ( a μ + b , a 2 σ 2 ) Y = aX + b \Rightarrow Y \sim N(a\mu + b, a^2\sigma^2) Y = a X + b ⇒ Y ∼ N ( a μ + b , a 2 σ 2 )
以上只限于讨论一个随机变量的情况,但在实际问题中,对于某些随机实验的结果需要同时用两个或两个以上的随机变量来描述。
设 E E E S = { e } S = \lbrace e \rbrace S = { e } X = X ( e ) X = X(e) X = X ( e ) Y = Y ( e ) Y = Y(e) Y = Y ( e ) S S S ( X , Y ) (X, Y) ( X , Y ) 二维随机向量 或二元随机变量
设 ( X , Y ) (X,Y) ( X , Y ) x , y x,y x , y
F ( x , y ) = P ( ( X ≤ x ) ∩ ( Y ≤ y ) ) = P ( X ≤ x , Y ≤ y ) F(x,y) = P((X \leq x) \cap (Y \leq y)) =P(X \leq x, Y \leq y)
F ( x , y ) = P ( ( X ≤ x ) ∩ ( Y ≤ y ) ) = P ( X ≤ x , Y ≤ y )
称为二维随机变量 ( X , Y ) (X,Y) ( X , Y ) X X X Y Y Y 联合分布函数
分布函数 F ( x , y ) F(x, y) F ( x , y )
F ( x , y ) F(x,y) F ( x , y ) x x x y y y 0 ≤ F ( x , y ) ≤ 1 , F ( + ∞ , + ∞ ) = 1 0 \leq F(x,y) \leq 1, F(+\infty, +\infty) = 1 0 ≤ F ( x , y ) ≤ 1 , F ( + ∞ , + ∞ ) = 1 x , y x, y x , y F ( − ∞ , y ) = F ( x , − ∞ ) = F ( − ∞ , − ∞ ) = 0 F(-\infty, y) = F(x, -\infty) = F(-\infty, -\infty) = 0 F ( − ∞ , y ) = F ( x , − ∞ ) = F ( − ∞ , − ∞ ) = 0 F ( x + 0 , y ) = F ( x , y ) , F ( x , y + 0 ) = F ( x , y ) F(x+0, y) = F(x,y), F(x, y+0)=F(x,y) F ( x + 0 , y ) = F ( x , y ) , F ( x , y + 0 ) = F ( x , y ) F ( x , y ) F(x,y) F ( x , y ) x x x y y y 对于任意 ( x 1 , y 1 ) , ( x 2 , y 2 ) , x 1 < x 2 , y 1 < y 2 (x_1, y_1), (x_2, y_2), x_1 < x_2, y_1 < y_2 ( x 1 , y 1 ) , ( x 2 , y 2 ) , x 1 < x 2 , y 1 < y 2 F ( x 2 , y 2 ) − F ( x 2 , y 1 ) + F ( x 1 , y 1 ) − F ( x 1 , y 2 ) ≥ 0 F(x_2, y_2) - F(x_2, y_1) + F(x_1, y_1) - F(x_1, y_2) \geq 0 F ( x 2 , y 2 ) − F ( x 2 , y 1 ) + F ( x 1 , y 1 ) − F ( x 1 , y 2 ) ≥ 0
若二元随机变量 ( X , Y ) (X, Y) ( X , Y ) ( X , Y ) (X, Y) ( X , Y ) 二元离散型随机变量
设二维随机变量 ( X , Y ) (X,Y) ( X , Y ) ( x i , y j ) , i , j = 1 , 2 , ⋯ (x_i, y_j),i,j=1,2,\cdots ( x i , y j ) , i , j = 1 , 2 , ⋯ P ( X = x i , Y = y i ) = p i j P(X=x_i,Y=y_i)=p_{ij} P ( X = x i , Y = y i ) = p i j
p i j ≥ 0 ∑ i = 1 ∞ ∑ j = 1 ∞ p i j = 1 p_{ij} \geq 0 \qquad\sum^\infty_{i=1}\sum^\infty_{j=1}p_{ij} = 1
p i j ≥ 0 i = 1 ∑ ∞ j = 1 ∑ ∞ p i j = 1
我们称 P ( X = x i , Y = y i ) = p i j , i , j = 1 , 2 , ⋯ P(X=x_i, Y=y_i) = p_{ij},i,j=1,2,\cdots P ( X = x i , Y = y i ) = p i j , i , j = 1 , 2 , ⋯ ( X , Y ) (X,Y) ( X , Y ) 分布律 ,或随机变量 X X X Y Y Y 联合分布律
联合分布律的性质:
p i j ≥ 0 p_{ij} \geq 0 p i j ≥ 0 ∑ i = 1 ∞ ∑ j = 1 ∞ p i j = 1 \sum_{i=1}^{\infty} \sum_{j=1}^{\infty} p_{ij} = 1 ∑ i = 1 ∞ ∑ j = 1 ∞ p i j = 1 P ( ( X , Y ) ∈ D ) = ∑ ( x i , y j ) ∈ D p i j P((X, Y) \in D) = \sum_{(x_i, y_j) \in D} p_{ij} P ( ( X , Y ) ∈ D ) = ∑ ( x i , y j ) ∈ D p i j
对于二维随机变量 ( X , Y ) (X,Y) ( X , Y ) F ( x , y ) F(x,y) F ( x , y ) f ( x , y ) f(x,y) f ( x , y ) x , y x,y x , y
F ( x , y ) = ∫ − ∞ y ∫ − ∞ x f ( u , v ) d u , d v \color{blue}{F(x,y) = \int^y_{-\infty}\int^x_{-\infty}f(u,v)du,dv}
F ( x , y ) = ∫ − ∞ y ∫ − ∞ x f ( u , v ) d u , d v
则称 ( X , Y ) (X,Y) ( X , Y ) 二元连续型随机变量 ,函数 f ( x , y ) f(x,y) f ( x , y ) ( X , Y ) (X,Y) ( X , Y ) 概率密度 或联合概率密度
概率密度的性质:
f ( x , y ) ≥ 0 f(x, y) \geq 0 f ( x , y ) ≥ 0 ∫ − ∞ ∞ ∫ − ∞ ∞ f ( x , y ) d x d y = F ( ∞ , ∞ ) = 1 \int^\infty_{-\infty}\int^\infty_{-\infty}f(x,y)dxdy = F(\infty,\infty)= 1 ∫ − ∞ ∞ ∫ − ∞ ∞ f ( x , y ) d x d y = F ( ∞ , ∞ ) = 1 设 D D D x o y xoy x o y ( X , Y ) (X,Y) ( X , Y ) D D D P ( ( X , Y ) ∈ D ) = ∬ D f ( x , y ) d x d y P((X,Y) \in D) = \iint_D f(x,y)dxdy P ( ( X , Y ) ∈ D ) = ∬ D f ( x , y ) d x d y
若 f ( x ) f(x) f ( x ) x x x ∂ 2 F ( x , y ) ∂ x ∂ y = f ( x , y ) \frac{\partial^2F(x,y)}{\partial x \partial y} = f(x,y) ∂ x ∂ y ∂ 2 F ( x , y ) = f ( x , y )
二维随机变量 ( X , Y ) (X, Y) ( X , Y ) F ( x , y ) F(x, y) F ( x , y ) X X X Y Y Y F X ( x ) , F Y ( y ) F_X(x), F_Y(y) F X ( x ) , F Y ( y ) ( X , Y ) (X, Y) ( X , Y ) X X X Y Y Y 边缘分布函数
X\Y
y 1 y_1 y 1 y 2 y_2 y 2 ⋯ \cdots ⋯ y j y_j y j ⋯ \cdots ⋯ P ( X = x i ) P(X = x_i) P ( X = x i )
x 1 x_1 x 1 p 11 p_{11} p 1 1 p 12 p_{12} p 1 2 ⋯ \cdots ⋯ p 1 j p_{1j} p 1 j ⋯ \cdots ⋯ p 1 ⋅ p_{1 \cdot} p 1 ⋅
x 2 x_2 x 2 p 21 p_{21} p 2 1 p 22 p_{22} p 2 2 ⋯ \cdots ⋯ p 2 j p_{2j} p 2 j ⋯ \cdots ⋯ p 2 ⋅ p_{2 \cdot} p 2 ⋅
⋮ \vdots ⋮ ⋯ \cdots ⋯ ⋯ \cdots ⋯ ⋯ \cdots ⋯ ⋯ \cdots ⋯ ⋯ \cdots ⋯ ⋮ \vdots ⋮
x i x_i x i p i 1 p_{i1} p i 1 p i 2 p_{i2} p i 2 ⋯ \cdots ⋯ p i j p_{ij} p i j ⋯ \cdots ⋯ p i ⋅ p_{i \cdot} p i ⋅
⋮ \vdots ⋮ ⋯ \cdots ⋯ ⋯ \cdots ⋯ ⋯ \cdots ⋯ ⋯ \cdots ⋯ ⋯ \cdots ⋯ ⋮ \vdots ⋮
P ( Y = y j ) P(Y = y_j) P ( Y = y j ) p ⋅ 1 p_{\cdot 1} p ⋅ 1 p ⋅ 2 p_{\cdot 2} p ⋅ 2 ⋯ \cdots ⋯ p ⋅ j p_{\cdot j} p ⋅ j ⋯ \cdots ⋯ 1
注:分别称 p i ⋅ p_{i \cdot} p i ⋅ p ⋅ j p_{\cdot j} p ⋅ j ( X , Y ) (X,Y) ( X , Y ) X X X Y Y Y
p i ⋅ = ∑ j = 1 ∞ p i j = P ( X = x i ) , i = 1 , 2 , ⋯ p ⋅ j = ∑ i = 1 ∞ p i j = P ( Y = y j ) , j = 1 , 2 , ⋯ \begin{aligned}
p_{i \cdot} &= \sum^\infty_{j=1}p_{ij} = P(X = x_i), \quad i=1,2,\cdots
\\
p_{\cdot j} &= \sum^\infty_{i=1}p_{ij} = P(Y = y_j), \quad j=1,2,\cdots
\end{aligned}
p i ⋅ p ⋅ j = j = 1 ∑ ∞ p i j = P ( X = x i ) , i = 1 , 2 , ⋯ = i = 1 ∑ ∞ p i j = P ( Y = y j ) , j = 1 , 2 , ⋯
对于连续型随机变量 ( X , Y ) (X, Y) ( X , Y ) f ( x , y ) f(x, y) f ( x , y )
F X ( x ) = F ( x , ∞ ) = ∫ − ∞ x [ ∫ ∞ ∞ f ( x , y ) d y ] d x F_X(x) = F(x, \infty) = \int^x_{-\infty}\left [\int^\infty_\infty f(x,y)dy\right ]dx
F X ( x ) = F ( x , ∞ ) = ∫ − ∞ x [ ∫ ∞ ∞ f ( x , y ) d y ] d x
可得
f X ( x ) = ∫ − ∞ ∞ f ( x , y ) d y f Y ( y ) = ∫ − ∞ ∞ f ( x , y ) d x \begin{aligned}
f_X(x) &= \int^\infty_{-\infty}f(x,y)dy
\\
f_Y(y) &= \int^\infty_{-\infty}f(x,y)dx
\end{aligned}
f X ( x ) f Y ( y ) = ∫ − ∞ ∞ f ( x , y ) d y = ∫ − ∞ ∞ f ( x , y ) d x
分别称 f X ( x ) f_X(x) f X ( x ) f Y ( y ) f_Y(y) f Y ( y ) ( X , Y ) (X,Y) ( X , Y ) X X X Y Y Y 边缘概率密度
由条件概率很自然地引出条件概率分布的概念
( X , Y ) (X,Y) ( X , Y )
P ( X = x i , Y = y j ) = p i j , i , j = 1 , 2 , ⋯ P(X = x_i, Y = y_j) = p_{ij}, \quad i,j = 1,2,\cdots
P ( X = x i , Y = y j ) = p i j , i , j = 1 , 2 , ⋯
( X , Y ) (X,Y) ( X , Y ) X X X Y Y Y
P ( X = x i ) = P i ⋅ = ∑ j = 1 ∞ p i j , i = 1 , 2 , ⋯ P ( Y = y j ) = P ⋅ j = ∑ j = 1 ∞ p i j , j = 1 , 2 , ⋯ \begin{aligned}
P(X = x_i) &= P_{i\cdot} = \sum^\infty_{j=1}p_{ij}, \quad i=1,2,\cdots
\\
P(Y = y_j) &= P_{\cdot j} = \sum^\infty_{j=1}p_{ij}, \quad j=1,2,\cdots
\end{aligned}
P ( X = x i ) P ( Y = y j ) = P i ⋅ = j = 1 ∑ ∞ p i j , i = 1 , 2 , ⋯ = P ⋅ j = j = 1 ∑ ∞ p i j , j = 1 , 2 , ⋯
现在考虑在事件 Y = y j Y=y_j Y = y j 已发生的条件下 X = x i X=x_i X = x i
P ( X = x i ∣ Y = y j ) = P ( X = x i , Y = y j ) P ( Y = y i ) = p i j p ⋅ j , i = 1 , 2 , ⋯ P(X=x_i|Y=y_j) = \frac{P(X=x_i,Y=y_j)}{P(Y=y_i)} = \frac{p_{ij}}{p_{\cdot j}}, \quad i = 1,2,\cdots
P ( X = x i ∣ Y = y j ) = P ( Y = y i ) P ( X = x i , Y = y j ) = p ⋅ j p i j , i = 1 , 2 , ⋯
由此引出以下定义:
设 ( X , Y ) (X,Y) ( X , Y ) y j y_j y j P ( Y = y j ) > 0 P(Y = y_j) > 0 P ( Y = y j ) > 0
P ( X = x i ∣ Y = y j ) = P ( X = x i , Y = y j ) P ( Y = y j ) = p i j p ⋅ j , i = 1 , 2 , ⋯ \color{blue}{P(X = x_i|Y = y_j) = \frac{P(X = x_i, Y = y_j)}{P(Y = y_j)} = \frac{p_{ij}}{p_{\cdot j}}, \quad i=1,2,\cdots}
P ( X = x i ∣ Y = y j ) = P ( Y = y j ) P ( X = x i , Y = y j ) = p ⋅ j p i j , i = 1 , 2 , ⋯
为在 Y = y j Y = y_j Y = y j X X X 条件分布律 ;同样,对于固定的 x i x_i x i P ( X = x i ) > 0 P(X = x_i) > 0 P ( X = x i ) > 0
P ( Y = y j ∣ X = x i ) = P ( X = x i , Y = y j ) P ( X = x i ) = p i j p i ⋅ , j = 1 , 2 , ⋯ \color{blue}{P(Y = y_j|X = x_i) = \frac{P(X = x_i, Y = y_j)}{P(X = x_i)} = \frac{p_{ij}}{p_{i\cdot}}, \quad j=1,2,\cdots}
P ( Y = y j ∣ X = x i ) = P ( X = x i ) P ( X = x i , Y = y j ) = p i ⋅ p i j , j = 1 , 2 , ⋯
为在 X = x i X = x_i X = x i Y Y Y 条件分布律
设二元随机变量 ( X , Y ) (X,Y) ( X , Y ) f ( x , y ) f(x,y) f ( x , y ) ( X , Y ) (X,Y) ( X , Y ) Y Y Y f Y ( y ) f_Y(y) f Y ( y ) y y y f Y ( y ) > 0 f_Y(y) > 0 f Y ( y ) > 0 f ( x , y ) f Y ( y ) \frac{f(x,y)}{f_Y(y)} f Y ( y ) f ( x , y ) Y = y Y=y Y = y X X X
f X ∣ Y ( x ∣ y ) = f ( x , y ) f Y ( y ) f_{X|Y}(x|y) = \frac{f(x,y)}{f_Y(y)}
f X ∣ Y ( x ∣ y ) = f Y ( y ) f ( x , y )
称
∫ − ∞ x f X ∣ Y ( x ∣ y ) d x = ∫ − ∞ x f ( x , y ) f Y ( y ) d x \int^x_{-\infty} f_{X|Y}(x|y)dx = \int^x_{-\infty}\frac{f(x,y)}{f_Y(y)}dx
∫ − ∞ x f X ∣ Y ( x ∣ y ) d x = ∫ − ∞ x f Y ( y ) f ( x , y ) d x
为在 Y = y Y=y Y = y X X X P ( X ≤ x ∣ Y = y ) P(X \leq x | Y = y) P ( X ≤ x ∣ Y = y ) F X ∣ Y ( x ∣ y ) F_{X|Y}(x|y) F X ∣ Y ( x ∣ y )
∫ − ∞ y f Y ∣ X ( y ∣ x ) d y = ∫ − ∞ y f ( y , x ) f X ( x ) d y \int^y_{-\infty} f_{Y|X}(y|x)dy = \int^y_{-\infty}\frac{f(y,x)}{f_X(x)}dy
∫ − ∞ y f Y ∣ X ( y ∣ x ) d y = ∫ − ∞ y f X ( x ) f ( y , x ) d y
为在 X = x X=x X = x Y Y Y P ( Y ≤ y ∣ X = x ) P(Y \leq y | X = x) P ( Y ≤ y ∣ X = x ) F Y ∣ X ( y ∣ x ) F_{Y|X}(y|x) F Y ∣ X ( y ∣ x )
若二元随机变量 ( X , Y ) (X, Y) ( X , Y ) D D D ( X , Y ) (X, Y) ( X , Y ) D D D 均匀分布 ,设
f ( x , y ) = { 1 A , ( x , y ) ∈ D 0 , ( x , y ) ∉ D \begin{aligned}
f(x, y) = \begin{cases}
\frac{1}{A}, \quad &(x, y) \in D
\\
0, \quad & (x, y) \notin D
\end{cases}
\end{aligned}
f ( x , y ) = { A 1 , 0 , ( x , y ) ∈ D ( x , y ) ∈ / D
其中 A A A D D D
设二元随机变量 ( X , Y ) (X, Y) ( X , Y )
f ( x , y ) = 1 2 π σ 1 σ 2 1 − ρ 2 × exp { − 1 2 ( 1 − ρ 2 ) [ ( x − μ 1 ) 2 σ 1 2 − 2 ρ ( x − μ 1 ) ( y − u 2 ) σ 1 σ 2 + ( y − u 2 ) 2 σ 2 2 ] } \begin{aligned}
f(x, y) = \frac{1}{2\pi \sigma_1 \sigma_2 \sqrt{1 - \rho^2}} \times \exp \lbrace \frac{-1}{2(1-\rho^2)} [\frac{(x - \mu_1)^2}{\sigma_1^2} - 2\rho \frac{(x - \mu_1)(y - u_2)}{\sigma_1 \sigma_2} + \frac{(y - u_2)^2}{\sigma_2^2}] \rbrace
\end{aligned}
f ( x , y ) = 2 π σ 1 σ 2 1 − ρ 2 1 × exp { 2 ( 1 − ρ 2 ) − 1 [ σ 1 2 ( x − μ 1 ) 2 − 2 ρ σ 1 σ 2 ( x − μ 1 ) ( y − u 2 ) + σ 2 2 ( y − u 2 ) 2 ] }
其中,μ 1 , μ 2 , σ 1 > 0 , σ 2 > 0 , − 1 < ρ < 1 \mu_1, \mu_2, \sigma_1 > 0, \sigma_2 > 0, -1 < \rho < 1 μ 1 , μ 2 , σ 1 > 0 , σ 2 > 0 , − 1 < ρ < 1 ( X , Y ) (X, Y) ( X , Y ) μ 1 , μ 2 , σ 1 , σ 2 , ρ \mu_1, \mu_2, \sigma_1, \sigma_2, \rho μ 1 , μ 2 , σ 1 , σ 2 , ρ 二元正态分布 ,记为:( X , Y ) ∼ N ( μ 1 , μ 2 , σ 1 2 , σ 2 2 , ρ ) \color{blue}{(X, Y) \sim N(\mu_1, \mu_2, \sigma_1^2, \sigma_2^2, \rho)} ( X , Y ) ∼ N ( μ 1 , μ 2 , σ 1 2 , σ 2 2 , ρ )
二元正态分布的两个边际分布都是一元正态分布,并且都不依赖于参数ρ \rho ρ
本节讲利用两个事件相互独立的概念引出两个随机变量相互独立 的概念
设 F ( x , y ) F(x,y) F ( x , y ) ( X , Y ) (X, Y) ( X , Y ) F X ( x ) , F Y ( y ) F_X(x),F_Y(y) F X ( x ) , F Y ( y ) X , Y X, Y X , Y x , y x,y x , y
P ( X ≤ x , Y ≤ y ) = P ( X ≤ x ) P ( Y ≤ y ) P(X \leq x, Y \leq y) = P(X \leq x)P(Y \leq y)
P ( X ≤ x , Y ≤ y ) = P ( X ≤ x ) P ( Y ≤ y )
即
F ( x , y ) = F X ( x ) F Y ( y ) \color{blue}{F(x,y) = F_X(x)F_Y(y)}
F ( x , y ) = F X ( x ) F Y ( y )
称随机变量 X , Y X, Y X , Y
设 ( X , Y ) (X, Y) ( X , Y ) P ( X = x i , Y = y j ) P(X = x_i, Y = y_j) P ( X = x i , Y = y j ) P ( X = x i ) P(X = x_i) P ( X = x i ) P ( Y = y j ) P(Y = y_j) P ( Y = y j ) ( X , Y ) (X, Y) ( X , Y ) X X X Y Y Y
P ( X = x i , Y = y j ) = P ( X = x i ) P ( Y = y j ) \color{blue}{P(X = x_i, Y = y_j) = P(X = x_i) P(Y = y_j)}
P ( X = x i , Y = y j ) = P ( X = x i ) P ( Y = y j )
需要检验所有等式成立才能得独立结论
设 ( X , Y ) (X, Y) ( X , Y ) f ( x , y ) f(x, y) f ( x , y ) f X ( x ) f_X(x) f X ( x ) f Y ( y ) f_Y(y) f Y ( y ) ( X , Y ) (X, Y) ( X , Y ) X X X Y Y Y
f ( x , y ) = f X ( x ) f Y ( y ) \color{blue}{f(x, y) = f_X(x) f_Y(y)}
f ( x , y ) = f X ( x ) f Y ( y )
连续型变量独立,其联合密度函数一定能分解成 x x x y y y f ( x , y ) = g ( x ) h ( y ) f(x, y) = g(x)h(y) f ( x , y ) = g ( x ) h ( y )
上一章介绍了随机变量的分布函数,概率密度,分布律 ,它们都能完整地描述随机变量,但在某些实际或理论问题中,人们感兴趣于某些能描述随机变量某一种特征地常数
本章介绍随机变量几个重要地数字特征:
数学期望
方差
协方差与相关系数
其他数字特征
多元正态分布的性质
定义:设离散型随机变量 X X X P ( X = x k ) = p k , k = 1 , 2 , ⋯ P(X = x_k) = p_k, k = 1, 2, \cdots P ( X = x k ) = p k , k = 1 , 2 , ⋯ ∑ k = 1 + ∞ x k p k \color{blue}{\sum_{k=1}^{+\infty}} x_k p_k ∑ k = 1 + ∞ x k p k ∑ k = 1 + ∞ x k p k \sum_{k=1}^{+\infty} x_k p_k ∑ k = 1 + ∞ x k p k X X X 数学期望 ,记为 E ( X ) E(X) E ( X )
E ( X ) = ∑ k = 1 + ∞ x k p k \color{blue}{E(X) = \sum_{k=1}^{+\infty}} x_k p_k
E ( X ) = k = 1 ∑ + ∞ x k p k
p k p_k p k 加权平均 中 x k x_k x k 期望 ,又称均值(mean)
定理:设 Y Y Y X X X Y = g ( X ) Y = g(X) Y = g ( X ) X X X P ( X = x k ) = p k , k = 1 , 2 , ⋯ P(X = x_k) = p_k, k = 1, 2, \cdots P ( X = x k ) = p k , k = 1 , 2 , ⋯ ∑ k = 1 ∞ g ( x k ) p k \sum_{k=1}^{\infty}g(x_k)p_k ∑ k = 1 ∞ g ( x k ) p k
E ( Y ) = E [ g ( X ) ] = ∑ k = 1 ∞ g ( x k ) p k \color{blue}{E(Y) = E[g(X)] = \sum_{k=1}^{\infty}} g(x_k) p_k
E ( Y ) = E [ g ( X ) ] = k = 1 ∑ ∞ g ( x k ) p k
定义:设连续型随机变量 X X X f ( x ) f(x) f ( x ) ∫ − ∞ + ∞ x f ( x ) d x \int_{-\infty}^{+\infty} xf(x) dx ∫ − ∞ + ∞ x f ( x ) d x ∫ − ∞ + ∞ ∣ x ∣ f ( x ) d x < + ∞ \int_{-\infty}^{+\infty} |x|f(x) dx < +\infty ∫ − ∞ + ∞ ∣ x ∣ f ( x ) d x < + ∞ ∫ − ∞ + ∞ x f ( x ) d x \int_{-\infty}^{+\infty} xf(x) dx ∫ − ∞ + ∞ x f ( x ) d x X X X
E ( X ) = ∫ − ∞ + ∞ x f ( x ) d x \color{blue}{E(X) = \int_{-\infty}^{+\infty} xf(x) dx}
E ( X ) = ∫ − ∞ + ∞ x f ( x ) d x
定理:设 Y Y Y X X X Y = g ( X ) Y = g(X) Y = g ( X ) X X X f ( x ) f(x) f ( x ) ∫ − ∞ + ∞ g ( x ) f ( x ) d x \int_{-\infty}^{+\infty} g(x) f(x) dx ∫ − ∞ + ∞ g ( x ) f ( x ) d x
E ( Y ) = E ( g ( X ) ) = ∫ − ∞ + ∞ g ( x ) f ( x ) d x \color{blue}{E(Y) = E(g(X)) = \int_{-\infty}^{+\infty} g(x) f(x) dx}
E ( Y ) = E ( g ( X ) ) = ∫ − ∞ + ∞ g ( x ) f ( x ) d x
E ( c ) = c E(c) = c E ( c ) = c E ( c X ) = c E ( X ) E(cX) = cE(X) E ( c X ) = c E ( X ) E ( X + Y ) = E ( X ) + E ( Y ) E(X + Y) = E(X) + E(Y) E ( X + Y ) = E ( X ) + E ( Y ) E ( X Y ) = E ( X ) E ( Y ) X , Y 相互独立 E(XY) = E(X) E(Y) \quad X, Y\text{相互独立} E ( X Y ) = E ( X ) E ( Y ) X , Y 相互独立
E [ a ∣ Y ] = a E[a∣Y] = a E [ a ∣ Y ] = a E [ a X + b Z ∣ Y ] = a E [ X ∣ Y ] + b E [ Z ∣ Y ] E[aX + bZ|Y] = aE[X|Y] + bE[Z|Y] E [ a X + b Z ∣ Y ] = a E [ X ∣ Y ] + b E [ Z ∣ Y ] E [ X ∣ Y ] = E [ X ] ( 独立 ) E[X|Y] = E[X](\text{独立}) E [ X ∣ Y ] = E [ X ] ( 独立 ) E [ E [ X ∣ Y ] ] = E [ X ] E[E[X|Y]] = E[X] E [ E [ X ∣ Y ] ] = E [ X ] E [ X g ( Y ) ∣ Y ] = g ( Y ) E [ X ∣ Y ] E[Xg(Y)|Y] = g(Y)E[X|Y] E [ X g ( Y ) ∣ Y ] = g ( Y ) E [ X ∣ Y ] E [ X ∣ Y , g ( Y ) ] = E [ X ∣ Y ] E[X|Y,g(Y)] = E[X|Y] E [ X ∣ Y , g ( Y ) ] = E [ X ∣ Y ] E [ E [ X ∣ Y , Z ] ] = E [ X ∣ Y ] E[E[X|Y,Z]] = E[X|Y] E [ E [ X ∣ Y , Z ] ] = E [ X ∣ Y ]
设 X X X E { [ X − E ( X ) ) ] 2 } E \lbrace [X - E(X))]^2 \rbrace E { [ X − E ( X ) ) ] 2 } X X X 方差 ,记为 D ( X ) \color{blue}{D(X)} D ( X ) Var ( X ) \color{blue}{\text{Var}(X)} Var ( X )
D ( X ) = E { [ X − E ( X ) ] 2 } \color{blue}{D(X) = E \lbrace[X - E(X)]^2 \rbrace}
D ( X ) = E { [ X − E ( X ) ] 2 }
D ( X ) \sqrt{D(X)} D ( X ) σ ( X ) \color{blue}{\sigma(X)} σ ( X ) X X X 标准差 或均方差
对于离散型随机变量 X X X P ( X = x k ) = p k , k = 1 , 2 , ⋯ P(X = x_k) = p_k, k = 1, 2, \cdots P ( X = x k ) = p k , k = 1 , 2 , ⋯
D ( X ) = ∑ k = 1 ∞ [ x k − E ( X ) ] 2 p k \color{blue}{D(X) = \sum_{k=1}^\infty[x_k - E(X)]^2 p_k}
D ( X ) = k = 1 ∑ ∞ [ x k − E ( X ) ] 2 p k
对于连续型随机变量 X X X f ( x ) f(x) f ( x )
D ( X ) = ∫ − ∞ ∞ [ x − E ( X ) ] 2 f ( x ) d x \color{blue}{D(X) = \int_{-\infty}^\infty[x - E(X)]^2 f(x)dx}
D ( X ) = ∫ − ∞ ∞ [ x − E ( X ) ] 2 f ( x ) d x
D ( c ) = 0 D(c) = 0 D ( c ) = 0 D ( c X ) = c 2 D ( x ) D(cX) = c^2D(x) D ( c X ) = c 2 D ( x ) D ( X ) = E ( X 2 ) − E ( X ) 2 D(X) = E(X^2) - E(X)^2 D ( X ) = E ( X 2 ) − E ( X ) 2 D ( X ± Y ) = D ( X ) + D ( Y ) ± 2 C o v ( X , Y ) D(X \pm Y) = D(X) + D(Y) \pm 2Cov(X,Y) D ( X ± Y ) = D ( X ) + D ( Y ) ± 2 C o v ( X , Y )
C o v ( X , Y ) = E { [ X − E ( X ) ] [ Y − E ( Y ) ] } Cov(X,Y) = E \lbrace [X - E(X)][Y - E(Y)] \rbrace C o v ( X , Y ) = E { [ X − E ( X ) ] [ Y − E ( Y ) ] } 特别的,若 X , Y X, Y X , Y D ( X + Y ) = D ( X ) + D ( Y ) D(X + Y) = D(X) + D(Y) D ( X + Y ) = D ( X ) + D ( Y )
D ( X ) = 0 ⇔ P ( X = c ) = 1 D(X) = 0 \Leftrightarrow P(X = c) = 1 D ( X ) = 0 ⇔ P ( X = c ) = 1 c = E ( X ) c = E(X) c = E ( X )
Var [ Y ∣ X ] = E [ Y − E [ Y ∣ X ] 2 ∣ X ] \text{Var}[Y∣X] = E[Y - E[Y∣X]2∣X] Var [ Y ∣ X ] = E [ Y − E [ Y ∣ X ] 2 ∣ X ] E [ Var [ Y ∣ X ] ] = E [ E [ Y 2 ∣ X ] ] − E [ E [ Y ∣ X ] 2 ] = E [ Y 2 ] − E [ E [ Y ∣ X ] 2 ] E[\text{Var}[Y|X]] = E[E[Y^2|X]] - E[E[Y|X]^2] = E[Y^2] - E[E[Y|X]^2] E [ Var [ Y ∣ X ] ] = E [ E [ Y 2 ∣ X ] ] − E [ E [ Y ∣ X ] 2 ] = E [ Y 2 ] − E [ E [ Y ∣ X ] 2 ] Var [ E [ Y ∣ X ] ] = E [ E [ Y ∣ X ] 2 ] − E [ E [ Y ∣ X ] ] 2 = E [ E [ Y ∣ X ] 2 ] − E [ Y ] 2 \text{Var}[E[Y|X]] = E[E[Y|X]^2] - E[E[Y|X]]^2 = E[E[Y|X]^2] - E[Y]^2 Var [ E [ Y ∣ X ] ] = E [ E [ Y ∣ X ] 2 ] − E [ E [ Y ∣ X ] ] 2 = E [ E [ Y ∣ X ] 2 ] − E [ Y ] 2 E [ Var [ Y ∣ X ] ] + Var [ E [ Y ∣ X ] ] = E [ Y 2 ] − E [ Y ] 2 = Var [ Y ] E[\text{Var}[Y|X]] + \text{Var}[E[Y|X]] = E[Y^2] - E[Y]^2 = \text{Var}[Y] E [ Var [ Y ∣ X ] ] + Var [ E [ Y ∣ X ] ] = E [ Y 2 ] − E [ Y ] 2 = Var [ Y ]
上一节中方差性质3:
设 X , Y X,Y X , Y
D ( X + Y ) = D ( X ) + D ( Y ) + 2 E { [ X − E ( X ) ] [ Y − E ( Y ) ] } D(X + Y) = D(X) + D(Y) + \color{blue}{2E \lbrace [X - E(X)] [Y - E(Y)] \rbrace }
D ( X + Y ) = D ( X ) + D ( Y ) + 2 E { [ X − E ( X ) ] [ Y − E ( Y ) ] }
特别地,若 X X X Y Y Y D ( X + Y ) = D ( X ) + D ( Y ) D(X + Y) = D(X) + D(Y) D ( X + Y ) = D ( X ) + D ( Y ) X X X Y Y Y E { [ X − E ( X ) ] [ Y − E ( Y ) ] } = 0 \color{blue}{E \lbrace [X - E(X)] [Y - E(Y)] \rbrace } = 0 E { [ X − E ( X ) ] [ Y − E ( Y ) ] } = 0
这意味着当 E { [ X − E ( X ) ] [ Y − E ( Y ) ] } ≠ 0 E \lbrace [X - E(X)] [Y - E(Y)] \rbrace \neq 0 E { [ X − E ( X ) ] [ Y − E ( Y ) ] } = 0 X X X Y Y Y
定义:数值 E { [ X − E ( X ) ] [ Y − E ( Y ) ] } E \lbrace [X - E(X)] [Y - E(Y)] \rbrace E { [ X − E ( X ) ] [ Y − E ( Y ) ] } X X X Y Y Y C o v ( X , Y ) Cov(X, Y) C o v ( X , Y )
C o v ( X , Y ) = E { [ X − E ( X ) ] [ Y − E ( Y ) ] } Cov(X, Y) = E \lbrace [X - E(X)] [Y - E(Y)] \rbrace
C o v ( X , Y ) = E { [ X − E ( X ) ] [ Y − E ( Y ) ] }
协方差 C o v ( X , Y ) Cov(X, Y) C o v ( X , Y ) X X X Y Y Y
当 C o v ( X , Y ) > 0 Cov(X, Y) > 0 C o v ( X , Y ) > 0 X X X Y Y Y
当 C o v ( X , Y ) < 0 Cov(X, Y) < 0 C o v ( X , Y ) < 0 X X X Y Y Y
当 C o v ( X , Y ) = 0 Cov(X, Y) = 0 C o v ( X , Y ) = 0 X X X Y Y Y
由于
E { [ X − E ( X ) ] [ Y − E ( Y ) ] } = E { X Y − X E ( Y ) − Y E ( X ) + E ( X ) E ( Y ) } = E ( X Y ) − E ( X ) E ( Y ) − E ( Y ) E ( X ) + E ( X ) E ( Y ) = E ( X Y ) − E ( X ) E ( Y ) \begin{aligned}
&E \lbrace [X - E(X)] [Y - E(Y)] \rbrace
\\
= &E \lbrace XY - XE(Y) - YE(X) + E(X)E(Y) \rbrace
\\
= &E(XY) - E(X)E(Y) - E(Y)E(X) + E(X)E(Y)
\\
= &E(XY) - E(X)E(Y)
\end{aligned}
= = = E { [ X − E ( X ) ] [ Y − E ( Y ) ] } E { X Y − X E ( Y ) − Y E ( X ) + E ( X ) E ( Y ) } E ( X Y ) − E ( X ) E ( Y ) − E ( Y ) E ( X ) + E ( X ) E ( Y ) E ( X Y ) − E ( X ) E ( Y )
C o v ( X , Y ) = E ( X Y ) − E ( X ) E ( Y ) \color{blue}{Cov(X, Y) = E(XY) - E(X)E(Y)}
C o v ( X , Y ) = E ( X Y ) − E ( X ) E ( Y )
C o v ( X , Y ) = C o v ( Y , X ) Cov(X, Y) = Cov(Y, X) C o v ( X , Y ) = C o v ( Y , X ) C o v ( X , X ) = D ( X ) Cov(X, X) = D(X) C o v ( X , X ) = D ( X ) C o v ( a X , b Y ) = a b ⋅ C o v ( X , Y ) Cov(aX, bY) = ab \cdot Cov(X, Y) C o v ( a X , b Y ) = a b ⋅ C o v ( X , Y ) a , b a, b a , b C o v ( X 1 + X 2 , Y ) = C o v ( X 1 , Y ) + C o v ( X 2 , Y ) Cov(X_1 + X_2, Y) = Cov(X_1, Y) + Cov(X_2, Y) C o v ( X 1 + X 2 , Y ) = C o v ( X 1 , Y ) + C o v ( X 2 , Y )
例题:
(1)
C o v ( 3 X + 2 Y , X ) = C o v ( 3 X , X ) + C o v ( 2 Y , X ) = 3 C o v ( X , X ) + 2 C o v ( Y , X ) = 3 D ( X ) + 2 C o v ( X , Y ) \begin{aligned}
&Cov(3X + 2Y, X)
\\
= &Cov(3X, X) + Cov(2Y, X)
\\
= &3Cov(X, X) + 2Cov(Y, X)
\\
= &3D(X) + 2Cov(X, Y)
\end{aligned}
= = = C o v ( 3 X + 2 Y , X ) C o v ( 3 X , X ) + C o v ( 2 Y , X ) 3 C o v ( X , X ) + 2 C o v ( Y , X ) 3 D ( X ) + 2 C o v ( X , Y )
(2)
D ( 3 X − 2 Y ) = D ( 3 X + ( − 2 Y ) ) = D ( 3 X ) + D ( − 2 Y ) + 2 C o v ( 3 X , − 2 Y ) = 9 D ( X ) + 4 D ( X ) − 12 C o v ( X , Y ) \begin{aligned}
&D(3X - 2Y)
\\
= &D(3X + (-2Y))
\\
= &D(3X) + D(-2Y) + 2Cov(3X, -2Y)
\\
= &9D(X) + 4D(X) - 12Cov(X, Y)
\end{aligned}
= = = D ( 3 X − 2 Y ) D ( 3 X + ( − 2 Y ) ) D ( 3 X ) + D ( − 2 Y ) + 2 C o v ( 3 X , − 2 Y ) 9 D ( X ) + 4 D ( X ) − 1 2 C o v ( X , Y )
协方差是有量纲的数字特征,为了消除其量纲的影响,引入一个新概念:
定义:数值 ρ X Y = C o v ( X , Y ) D ( X ) D ( Y ) \rho_{XY} = \frac{Cov(X, Y)}{\sqrt{D(X)D(Y)}} ρ X Y = D ( X ) D ( Y ) C o v ( X , Y ) X X X Y Y Y 相关系数 ,是没有量纲的
若记作标准化变量
X ∗ = X − E ( X ) D ( X ) , Y ∗ = Y − E ( Y ) D ( Y ) \begin{aligned}
X^* = \frac{X - E(X)}{\sqrt{D(X)}}, \qquad Y^* = \frac{Y - E(Y)}{\sqrt{D(Y)}}
\end{aligned}
X ∗ = D ( X ) X − E ( X ) , Y ∗ = D ( Y ) Y − E ( Y )
则,ρ X Y = C o v ( X ∗ , Y ∗ ) \rho_{XY} = Cov(X^*, Y^*) ρ X Y = C o v ( X ∗ , Y ∗ )
∣ ρ X Y ∣ ≤ 1 |\rho_{XY}| \leq 1 ∣ ρ X Y ∣ ≤ 1 ∣ ρ X Y ∣ = 1 ⇔ |\rho_{XY}| = 1 \Leftrightarrow ∣ ρ X Y ∣ = 1 ⇔ a , b a, b a , b P ( Y = a + b X ) = 1 P(Y = a + bX) = 1 P ( Y = a + b X ) = 1 ρ X Y = 1 \rho_{XY} = 1 ρ X Y = 1 b > 0 b > 0 b > 0 ρ X Y = − 1 \rho_{XY} = -1 ρ X Y = − 1 b < 0 b < 0 b < 0
上面性质也可以写为:
当 D ( X ) D ( Y ) ≠ 0 D(X)D(Y) \neq 0 D ( X ) D ( Y ) = 0 ( C o v ( X , Y ) ) 2 ≤ D ( X ) D ( Y ) (Cov(X, Y))^2 \leq D(X)D(Y) ( C o v ( X , Y ) ) 2 ≤ D ( X ) D ( Y ) X X X Y Y Y a , b a, b a , b P ( Y = a + b X ) = 1 P(Y = a + bX) = 1 P ( Y = a + b X ) = 1
相关系数是一个用来表征两个随机变量之间线性关系密切程度的特征数,有时也称为”线性相关系数“。
当 ∣ ρ X Y ∣ |\rho_{XY}| ∣ ρ X Y ∣ X X X Y Y Y
当 ∣ ρ X Y ∣ |\rho_{XY}| ∣ ρ X Y ∣ X X X Y Y Y
当 ∣ ρ X Y ∣ = 1 |\rho_{XY}| = 1 ∣ ρ X Y ∣ = 1 X X X Y Y Y
当 ∣ ρ X Y ∣ = 0 |\rho_{XY}| = 0 ∣ ρ X Y ∣ = 0 X X X Y Y Y
本节先介绍随机变量的另外几个数字特征,设 ( X , Y ) (X, Y) ( X , Y )
定义1.1:若 E ( X k ) , k = 1 , 2 , ⋯ E(X^k), k = 1, 2, \cdots E ( X k ) , k = 1 , 2 , ⋯ X X X k 阶(原点)矩 \color{blue}{k\text{阶(原点)矩}} k 阶 ( 原点 ) 矩
定义1.2:若 E { [ X − E ( X ) ] k } , k = 1 , 2 , ⋯ E \lbrace [X - E(X)]^k \rbrace, k = 1, 2, \cdots E { [ X − E ( X ) ] k } , k = 1 , 2 , ⋯ X X X k 阶中心矩 \color{blue}{k\text{阶中心矩}} k 阶中心矩
之前提到的随机变量的期望和方差就是其1阶原点矩和2阶中心矩
定义2.1:若 E ( X k Y l ) , k , l = 1 , 2 , ⋯ E(X^k Y^l), k,l = 1, 2, \cdots E ( X k Y l ) , k , l = 1 , 2 , ⋯ X X X Y Y Y k + l 阶混合(原点)矩 \color{blue}{k+l\text{阶混合(原点)矩}} k + l 阶混合 ( 原点 ) 矩
定义2.2:若 E { [ X − E ( X ) ] k [ Y − E ( Y ) ] l } , k , l = 1 , 2 , ⋯ E \lbrace [X - E(X)]^k [Y - E(Y)]^l \rbrace, k,l = 1, 2, \cdots E { [ X − E ( X ) ] k [ Y − E ( Y ) ] l } , k , l = 1 , 2 , ⋯ X X X Y Y Y k + l 阶混合中心矩 \color{blue}{k+l\text{阶混合中心矩}} k + l 阶混合中心矩
之前提到的随机变量的协方差就是其1 + 1阶混合中心矩
定义3:设 n n n X ~ = ( X 1 , X 2 , ⋯ , X n ) T , n ≥ 1 \tilde{X} = (X_1, X_2, \cdots, X_n)^T, n \geq 1 X ~ = ( X 1 , X 2 , ⋯ , X n ) T , n ≥ 1
E ( X ~ ) = ( E ( X 1 ) , E ( X 2 ) , ⋯ , E ( X n ) ) T , n ≥ 1 E(\tilde{X}) = (E(X_1), E(X_2), \cdots, E(X_n))^T, n \geq 1
E ( X ~ ) = ( E ( X 1 ) , E ( X 2 ) , ⋯ , E ( X n ) ) T , n ≥ 1
为 n n n X ~ \tilde{X} X ~
定义4:设 n n n X ~ = ( X 1 , X 2 , ⋯ , X n ) T , n ≥ 1 \tilde{X} = (X_1, X_2, \cdots, X_n)^T, n \geq 1 X ~ = ( X 1 , X 2 , ⋯ , X n ) T , n ≥ 1 C o v ( X i , X j ) , i , j = 1 , 2 , ⋯ , n Cov(X_i, X_j), i,j = 1, 2, \cdots, n C o v ( X i , X j ) , i , j = 1 , 2 , ⋯ , n
C = C o v ( X ~ ) = ( D ( X 1 ) C o v ( X 1 , X 2 ) ⋯ C o v ( X 1 , X n ) C o v ( X 2 , X 1 ) D ( X 2 ) ⋯ C o v ( X 2 , X n ) ⋮ ⋮ ⋱ ⋮ C o v ( X n , X 1 ) C o v ( X n , X 2 ) ⋯ D ( X n ) ) \begin{aligned}
C = Cov(\tilde{X}) = \begin{pmatrix}
D(X_1) & Cov(X_1, X_2) & \cdots & Cov(X_1, X_n)
\\
Cov(X_2, X_1) & D(X_2) & \cdots & Cov(X_2, X_n)
\\
\vdots & \vdots & \ddots & \vdots
\\
Cov(X_n, X_1) & Cov(X_n, X_2) & \cdots & D(X_n)
\end{pmatrix}
\end{aligned}
C = C o v ( X ~ ) = ⎝ ⎜ ⎜ ⎜ ⎜ ⎛ D ( X 1 ) C o v ( X 2 , X 1 ) ⋮ C o v ( X n , X 1 ) C o v ( X 1 , X 2 ) D ( X 2 ) ⋮ C o v ( X n , X 2 ) ⋯ ⋯ ⋱ ⋯ C o v ( X 1 , X n ) C o v ( X 2 , X n ) ⋮ D ( X n ) ⎠ ⎟ ⎟ ⎟ ⎟ ⎞
为 n n n X ~ \tilde{X} X ~
即:C = ( c i j ) n × n , c i j = C o v ( X i , X j ) , i , j = 1 , 2 , ⋯ , n \mathbf{C} = (c_{ij})_{n \times n}, c_{ij} = Cov(X_i, X_j), i,j = 1, 2, \cdots, n C = ( c i j ) n × n , c i j = C o v ( X i , X j ) , i , j = 1 , 2 , ⋯ , n
引入列向量 x ~ = ( x 1 , ⋯ , x n ) T , μ = ( E ( X 1 ) , ⋯ , E ( X n ) ) T ~ \tilde{\mathbf{x}} = (x_1, \cdots, x_n)^T, \tilde{\mathbf{\mu} = (E(X_1), \cdots, E(X_n))^T} x ~ = ( x 1 , ⋯ , x n ) T , μ = ( E ( X 1 ) , ⋯ , E ( X n ) ) T ~ C = ( c i j ) n × n , c i j = C o v ( X i , X j ) , i , j = 1 , ⋯ , n \mathbf{C} = (c_{ij})_{n \times n}, c_{ij} = Cov(X_i, X_j), i,j = 1, \cdots, n C = ( c i j ) n × n , c i j = C o v ( X i , X j ) , i , j = 1 , ⋯ , n n n n X ~ = ( X 1 , ⋯ , X n ) T , n ≥ 1 \tilde{X} = (X_1, \cdots, X_n)^T, n \geq 1 X ~ = ( X 1 , ⋯ , X n ) T , n ≥ 1
f ( x 1 , ⋯ , x n ) = 1 ( 2 π ) n 2 ∣ C ∣ 1 2 exp { − 1 2 ( x ~ − μ ~ ) T C − 1 ( x ~ − μ ~ ) } \begin{aligned}
f(x_1, \cdots, x_n) = \frac{1}{(2\pi)^{\frac{n}{2}} |\mathbf{C}|^{\frac{1}{2}}} \exp \lbrace -\frac{1}{2}(\tilde{\mathbf{x}} - \tilde{\mathbf{\mu}})^T \mathbf{C}^{-1} (\tilde{\mathbf{x}} - \tilde{\mathbf{\mu}}) \rbrace
\end{aligned}
f ( x 1 , ⋯ , x n ) = ( 2 π ) 2 n ∣ C ∣ 2 1 1 exp { − 2 1 ( x ~ − μ ~ ) T C − 1 ( x ~ − μ ~ ) }
n n n X ~ = ( X 1 , X 2 , ⋯ , X n ) T , n ≥ 1 \tilde{X} = (X_1, X_2, \cdots, X_n)^T, n \geq 1 X ~ = ( X 1 , X 2 , ⋯ , X n ) T , n ≥ 1 ( X i 1 , ⋯ , X i k ) T ( 1 ≤ k ≤ n ) (X_{i1}, \cdots, X_{ik})^T (1 \leq k \leq n) ( X i 1 , ⋯ , X i k ) T ( 1 ≤ k ≤ n ) k k k X i , i = 1 , ⋯ , n X_i, i = 1, \cdots, n X i , i = 1 , ⋯ , n X i , i = 1 , ⋯ , n X_i, i = 1, \cdots, n X i , i = 1 , ⋯ , n X ~ = ( X 1 , ⋯ , X n ) T , n ≥ 1 \tilde{X} = (X_1, \cdots, X_ n)^T, n \geq 1 X ~ = ( X 1 , ⋯ , X n ) T , n ≥ 1 n n n
例如:X ~ = ( X 1 , X 2 , X 3 ) T \tilde{X} = (X_1, X_2, X_3)^T X ~ = ( X 1 , X 2 , X 3 ) T ( X 1 , X 2 ) T , ( X 1 , X 3 ) T , ( X 2 , X 3 ) T (X_1,X_2)^T, (X_1, X_3)^T, (X_2, X_3)^T ( X 1 , X 2 ) T , ( X 1 , X 3 ) T , ( X 2 , X 3 ) T
n n n X ~ = ( X 1 , X 2 , ⋯ , X n ) T , n ≥ 1 \tilde{X} = (X_1, X_2, \cdots, X_n)^T, n \geq 1 X ~ = ( X 1 , X 2 , ⋯ , X n ) T , n ≥ 1 n n n ⇔ X 1 , ⋯ , X n \Leftrightarrow X_1, \cdots, X_n ⇔ X 1 , ⋯ , X n l 0 + l 1 X 1 + ⋯ + l n X n l_0 + l_1X_1 + \cdots + l_nX_n l 0 + l 1 X 1 + ⋯ + l n X n l 1 , ⋯ , l n l_1, \cdots, l_n l 1 , ⋯ , l n
例如:X ~ = ( X 1 , X 2 , X 3 ) T \tilde{X} = (X_1, X_2, X_3)^T X ~ = ( X 1 , X 2 , X 3 ) T 3 X 1 − X 2 , 2 X 1 + 4 X 3 + 1 , X 2 − 3 X 1 − X 3 − 2 3X_1 - X_2, 2X_1 + 4X_3 + 1, X_2 - 3X_1 - X_3 - 2 3 X 1 − X 2 , 2 X 1 + 4 X 3 + 1 , X 2 − 3 X 1 − X 3 − 2
n n n X ~ = ( X 1 , X 2 , ⋯ , X n ) T , n ≥ 1 \tilde{X} = (X_1, X_2, \cdots, X_n)^T, n \geq 1 X ~ = ( X 1 , X 2 , ⋯ , X n ) T , n ≥ 1 Y 1 , ⋯ , Y k , k ≥ 1 Y_1, \cdots, Y_k, k \geq 1 Y 1 , ⋯ , Y k , k ≥ 1 X i , i = 1 , 2 , ⋯ , n X_i, i = 1, 2, \cdots, n X i , i = 1 , 2 , ⋯ , n ( Y 1 , ⋯ , Y k ) T (Y_1, \cdots, Y_k)^T ( Y 1 , ⋯ , Y k ) T k k k
这一性质称为正态变量的线性变换不变性 \color{blue}{\text{正态变量的线性变换不变性}} 正态变量的线性变换不变性
例如:X ~ = ( X 1 , X 2 , X 3 ) T \tilde{X} = (X_1, X_2, X_3)^T X ~ = ( X 1 , X 2 , X 3 ) T ( 3 X 1 − X 2 , 2 X 1 + 4 X 3 + 1 , X 2 − 3 X 1 − X 3 − 2 , X 2 ) T (3X_1 - X_2, 2X_1 + 4X_3 + 1, X_2 - 3X_1 - X_3 - 2, X_2)^T ( 3 X 1 − X 2 , 2 X 1 + 4 X 3 + 1 , X 2 − 3 X 1 − X 3 − 2 , X 2 ) T
设 X ~ = ( X 1 , X 2 , ⋯ , X n ) T , n ≥ 1 \tilde{X} = (X_1, X_2, \cdots, X_n)^T, n \geq 1 X ~ = ( X 1 , X 2 , ⋯ , X n ) T , n ≥ 1 n n n X 1 , ⋯ , X n X_1, \cdots, X_n X 1 , ⋯ , X n ⇔ X 1 , ⋯ , X n \Leftrightarrow X_1, \cdots, X_n ⇔ X 1 , ⋯ , X n ⇔ X ~ \Leftrightarrow \tilde{X} ⇔ X ~
C = ( D ( X 1 ) 0 ⋯ 0 0 D ( X 2 ) ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ D ( X n ) ) \begin{aligned}
\mathbf{C} = \begin{pmatrix}
D(X_1) & 0 & \cdots & 0
\\
0 & D(X_2) & \cdots & 0
\\
\vdots & \vdots & \ddots & \vdots
\\
0 & 0 & \cdots & D(X_n)
\end{pmatrix}
\end{aligned}
C = ⎝ ⎜ ⎜ ⎜ ⎜ ⎛ D ( X 1 ) 0 ⋮ 0 0 D ( X 2 ) ⋮ 0 ⋯ ⋯ ⋱ ⋯ 0 0 ⋮ D ( X n ) ⎠ ⎟ ⎟ ⎟ ⎟ ⎞
常用公式:
C o v ( X , Y ) = E ( X Y T ) − E ( X ) E ( Y ) T Cov(\mathbf{X}, \mathbf{Y}) = E(\mathbf{X}\mathbf{Y}^T) - E(\mathbf{X})E(\mathbf{Y})^T C o v ( X , Y ) = E ( X Y T ) − E ( X ) E ( Y ) T C o v ( X , X ) = E ( X X T ) − E ( X ) E ( X ) T Cov(\mathbf{X}, \mathbf{X}) = E(\mathbf{X}\mathbf{X}^T) - E(\mathbf{X})E(\mathbf{X})^T C o v ( X , X ) = E ( X X T ) − E ( X ) E ( X ) T C o v ( A X , B Y ) = A C o v ( X , Y ) B T Cov(\mathbf{AX}, \mathbf{BY}) = \mathbf{A}Cov(\mathbf{X}, \mathbf{Y})\mathbf{B}^T C o v ( A X , B Y ) = A C o v ( X , Y ) B T C o v ( A X , A X ) = A C o v ( X , X ) A T Cov(\mathbf{AX}, \mathbf{AX}) = \mathbf{A}Cov(\mathbf{X}, \mathbf{X})\mathbf{A}^T C o v ( A X , A X ) = A C o v ( X , X ) A T E ( X T A X ) = t r A C o v ( X , X ) + E ( X ) T A E ( X ) E(\mathbf{X}^T\mathbf{AX}) = tr \mathbf{A} Cov(\mathbf{X}, \mathbf{X}) + E(\mathbf{X})^T\mathbf{A}E(\mathbf{X}) E ( X T A X ) = t r A C o v ( X , X ) + E ( X ) T A E ( X )
补充矩阵的迹的性质:
A , B \mathbf{A},\mathbf{B} A , B n × n n \times n n × n
t r ( A + B ) = t r ( A ) + t r ( B ) tr(\mathbf{A} + \mathbf{B}) = tr(\mathbf{A}) + tr(\mathbf{B}) t r ( A + B ) = t r ( A ) + t r ( B ) t r A B = t r B A tr \mathbf{AB} = tr \mathbf{BA} t r A B = t r B A t r A ( A T A ) − 1 A T = t r A T A ( A T A ) − 1 = t r I n = n tr \mathbf{A}(\mathbf{A}^T\mathbf{A})^{-1}\mathbf{A}^T = tr \mathbf{A}^T \mathbf{A} (\mathbf{A}^T \mathbf{A})^{-1} = tr \mathbf{I}_n = n t r A ( A T A ) − 1 A T = t r A T A ( A T A ) − 1 = t r I n = n A \mathbf{A} A m × n m \times n m × n r a n k ( A ) = n rank(\mathbf{A}) = n r a n k ( A ) = n x T A x = t r A x x T \mathbf{x}^T \mathbf{Ax} = tr \mathbf{Axx}^T x T A x = t r A x x T x \mathbf{x} x n n n
贝努里大数定律 :记 n A n_A n A n n n A A A A A A p ( 0 < p < 1 ) p(0 < p < 1) p ( 0 < p < 1 ) ∀ ϵ > 0 \forall \epsilon > 0 ∀ ϵ > 0
lim n → + ∞ P { ∣ n A n − p ∣ ≥ ϵ } = 0 \lim_{n \rightarrow +\infty} P \lbrace |\frac{n_A}{n} - p| \geq \epsilon \rbrace = 0
n → + ∞ lim P { ∣ n n A − p ∣ ≥ ϵ } = 0
即,n A n → p \frac{n_A}{n} \rightarrow p n n A → p n → + ∞ n \rightarrow +\infty n → + ∞
贝努里大数定律的重要意义:
提供了用大量重复独立试验中事件出现的频率的极限值来确定概率的理论依据,使得概率才有严格的意义
提供了通过试验来确定事件的概率的方法:可以通过做试验确定某事件发生的概率并把它作为相应的概率估计。例如:想估计某产品的不合格频率 p p p n n n n n n n n n p p p
大数定律(Laws of Large Numbers) :设 X 1 , X 2 , ⋯ , X n , ⋯ X_1, X_2, \cdots, X_n, \cdots X 1 , X 2 , ⋯ , X n , ⋯ Y n = X 1 + X 2 + ⋯ + X n n Y_n = \frac{X_1 + X_2 + \cdots + X_n}{n} Y n = n X 1 + X 2 + ⋯ + X n μ \mu μ n → ∞ n \rightarrow \infty n → ∞
随机变量序列 Y n Y_n Y n μ \mu μ 依概率收敛
μ \mu μ X i X_i X i μ = E ( X i ) \mu = E(X_i) μ = E ( X i ) 在不一样的条件下得到不同的大数定律
切比雪夫大数定律的推论 :设 X 1 , X 2 , ⋯ , X n , ⋯ X_1, X_2, \cdots, X_n, \cdots X 1 , X 2 , ⋯ , X n , ⋯ μ \mu μ σ 2 \sigma^2 σ 2 1 n ∑ i = 1 n X i → μ \frac{1}{n} \sum_{i=1}^n X_i \rightarrow \mu n 1 ∑ i = 1 n X i → μ n → ∞ n \rightarrow \infty n → ∞
前面的定理要求随机变量的方差存在,但当随机变量服从相同分布时,就不需要这一要求
辛钦大数定律 :X 1 , X 2 , ⋯ , X n , ⋯ X_1, X_2, \cdots, X_n, \cdots X 1 , X 2 , ⋯ , X n , ⋯ μ \mu μ 1 n ∑ i = 1 n X i → μ \frac{1}{n} \sum_{i=1}^n X_i \rightarrow \mu n 1 ∑ i = 1 n X i → μ n → ∞ n \rightarrow \infty n → ∞
辛钦大数定律的意义:
提供了求随机变量 X X X E ( X ) E(X) E ( X ) X X X n n n k k k X k X_k X k X 1 , X 2 , ⋯ , X n X_1, X_2, \cdots, X_n X 1 , X 2 , ⋯ , X n X X X E ( X ) E(X) E ( X ) n n n n n n 1 n ∑ i = 1 n X i \frac{1}{n} \sum_{i=1}^n X_i n 1 ∑ i = 1 n X i E ( X ) E(X) E ( X )
其目的是寻求 X X X X X X
问题的提出:有许多随机变量,它们是由大量的相互独立的随机变量的综合影响所形成的,而其中每个个别的因素作用都很小,这种随机变量往往服从或近似服从正态分布,或者说它的极限分布是正态分布,中心极限定理正是从数学上论证了这一现象,它在长达两个世纪的时期内曾是概率论研究的中心课题
独立同分布的中心极限定理(CLT) :设随机变量 X 1 , ⋯ , X n , ⋯ X_1, \cdots, X_n, \cdots X 1 , ⋯ , X n , ⋯ E ( x i ) = μ , D ( X i ) = σ 2 , i = 1 , 2 , ⋯ E(x_i) = \mu, D(X_i) = \sigma^2, i = 1, 2, \cdots E ( x i ) = μ , D ( X i ) = σ 2 , i = 1 , 2 , ⋯ n n n ∑ i = 1 n X i ∼ N ( n μ , n σ 2 ) \sum_{i=1}^n X_i \sim N(n \mu, n \sigma^2) ∑ i = 1 n X i ∼ N ( n μ , n σ 2 ) P ( a < ∑ i = 1 n X i ≤ ) ≃ Φ ( b − n μ n σ ) − Φ ( a − n μ n σ ) P(a < \sum_{i=1}^n X_i \leq) \simeq \Phi(\frac{b - n\mu}{\sqrt{n} \sigma}) - \Phi(\frac{a - n\mu}{\sqrt{n} \sigma}) P ( a < ∑ i = 1 n X i ≤ ) ≃ Φ ( n σ b − n μ ) − Φ ( n σ a − n μ )
德莫弗-拉普拉斯中心极限定理 :记 n A n_A n A n n n A A A A A A p ( 0 < p < 1 ) p(0 < p < 1) p ( 0 < p < 1 ) n n n n A ∼ N ( n p , n p ( 1 − p ) ) n_A \sim N(np, np(1 - p)) n A ∼ N ( n p , n p ( 1 − p ) ) B ( n , p ) B(n, p) B ( n , p ) n n n 可用正态分布来近似
从本章节开始为数理统计内容,在前述的概率论中,我们所研究的随机变量,它的分布都是假设已知的 ,在这一前提下去研究它的性质,特点和规律性,例如求出它的数字特征,讨论随机变量函数的分布,介绍常用的各种分布等
在数理统计中,我们研究的随机变量,它的分布是未知的 ,或者是完全不知道的,人们是通过对所研究的随机变量进行重复独立的观察,得到许多观察值,对这些数据进行分析,从而对所研究的随机变量分布做出种种推断的
本章介绍总体,随机样本及统计量 等基本概念,并着重介绍几个常用统计量及抽样分布
在统计学中,高斯-马尔可夫定理(Gauss-Markov Theorem)陈述的是:在线性回归模型中,如果误差满足零均值、同方差且互不相关,则回归系数的最佳线性无偏估计(BLUE, Best Linear unbiased estimator)就是普通最小二乘法估计。
这里最佳的意思是指相较于其他估计量有更小方差的估计量,同时把对估计量的寻找限制在所有可能的线性无偏估计量中
值得注意的是这里不需要假定误差满足独立同分布(iid)或正态分布,而仅需要满足零均值、不相关及同方差这三个稍弱的条件
分布
参数
符号
分布律/概率密度函数
期望
方差
0 − 1 0-1 0 − 1 0 < p < 1 0<p<1 0 < p < 1 X ∼ 0 − 1 ( p ) \color{red}{X \sim{} 0 - 1(p)} X ∼ 0 − 1 ( p ) P ( X = k ) = p k ( 1 − p ) 1 − k P(X=k) = p^k(1-p)^{1-k} P ( X = k ) = p k ( 1 − p ) 1 − k p p p p ( 1 − p ) p(1-p) p ( 1 − p )
二项分布
n ≥ 1 0 < p < 1 \begin{aligned}n \geq 1\quad\\0<p<1\end{aligned} n ≥ 1 0 < p < 1 X ∼ b ( n , p ) \color{red}{X \sim{} b(n, p)} X ∼ b ( n , p ) P ( X = k ) = ( n k ) p k ( 1 − p ) n − k P(X=k) = \binom{n}{k}p^k(1-p)^{n-k} P ( X = k ) = ( k n ) p k ( 1 − p ) n − k n p np n p n p ( 1 − p ) np(1 - p) n p ( 1 − p )
几何分布
0 < p < 1 0<p<1 0 < p < 1 X ∼ G ( p ) \color{red}{X \sim{} G(p)} X ∼ G ( p ) P ( X = k ) = ( 1 − p ) k − 1 p k = 1 , 2 , ⋯ P(X=k) = (1-p)^{k-1}p \quad k=1,2,\cdots P ( X = k ) = ( 1 − p ) k − 1 p k = 1 , 2 , ⋯ 1 p \frac{1}{p} p 1 1 − p p 2 \frac{1-p}{p^2} p 2 1 − p
超几何分布
N , M , n ( M ≤ N ) ( n ≤ N ) \begin{aligned}N,M,n\\(M \leq N)\\(n \leq N)\end{aligned} N , M , n ( M ≤ N ) ( n ≤ N ) X ∼ H ( n , K , N ) \color{red}{X \sim{} H(n, K, N)} X ∼ H ( n , K , N ) P ( X = k , n , K , N ) = ( M k ) ( N − M n − k ) N k P(X=k, n, K, N) = \frac{\binom{M}{k}\binom{N-M}{n-k}}{\frac{N}{k}} P ( X = k , n , K , N ) = k N ( k M ) ( n − k N − M ) n M N \frac{nM}{N} N n M n M N ( 1 − M N ) ( 1 − n − 1 N − 1 ) n\frac{M}{N}(1 - \frac{M}{N})(1 - \frac{n-1}{N-1}) n N M ( 1 − N M ) ( 1 − N − 1 n − 1 )
泊松分布
λ > 0 \lambda > 0 λ > 0 X ∼ π ( λ ) \color{red}{X \sim{} \pi(\lambda)} X ∼ π ( λ ) P ( X = k ) = λ k e − λ k ! P(X=k) = \frac{\lambda^k e^{-\lambda}}{k!} P ( X = k ) = k ! λ k e − λ λ \lambda λ λ \lambda λ
均匀分布
a < b a<b a < b X ∼ U ( a , b ) \color{red}{X \sim{} U(a, b)} X ∼ U ( a , b ) f ( x ) = { 1 b − a a < x < b 0 其他 f(x) =\begin{cases}\frac{1}{b-a} \quad & a < x < b\\0 \quad & \text{其他}\end{cases} f ( x ) = { b − a 1 0 a < x < b 其他 a + b 2 \frac{a+b}{2} 2 a + b ( b − a ) 2 12 \frac{(b-a)^2}{12} 1 2 ( b − a ) 2
指数分布
0 < λ < 1 0<\lambda<1 0 < λ < 1 X ∼ E x p ( λ ) \color{red}{X \sim{} Exp(\lambda)} X ∼ E x p ( λ ) f ( x ) = { λ e − λ x x ≥ 0 0 x < 0 f(x) =\begin{cases}\lambda{}e^{-\lambda{}x} \quad & x \geq 0\\0 \quad & x < 0\end{cases} f ( x ) = { λ e − λ x 0 x ≥ 0 x < 0 1 λ \frac{1}{\lambda} λ 1 1 λ 2 \frac{1}{\lambda^2} λ 2 1
正态分布
u . σ > 0 u.\sigma>0 u . σ > 0 X ∼ N ( μ , σ 2 ) \color{red}{X \sim{} N(\mu, \sigma^2)} X ∼ N ( μ , σ 2 ) f ( x ) = 1 2 π σ e − ( x − u ) 2 2 σ 2 − ∞ < x < ∞ f(x) = \frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-u)^2}{2\sigma^2}} \quad -\infty < x < \infty f ( x ) = 2 π σ 1 e − 2 σ 2 ( x − u ) 2 − ∞ < x < ∞ μ \mu μ λ \lambda λ
Gamma分布
x ≥ 0 , α > 0 , λ > 0 x \geq 0, \alpha > 0, \lambda > 0 x ≥ 0 , α > 0 , λ > 0 X ∼ Γ ( α , 1 λ ) \color{red}{X \sim{} \Gamma(\alpha, \frac{1}{\lambda})} X ∼ Γ ( α , λ 1 ) f X ( x ) = λ α Γ ( α ) x α − 1 e − λ x ( Γ ( α ) = ∫ 0 ∞ e − t t α − 1 d t ) f_X(x) = \frac{\lambda^{\alpha}}{\Gamma(\alpha)} x^{\alpha - 1}e^{-\lambda x} (\Gamma(\alpha) = \int_0^{\infty} e^{-t} t^{\alpha - 1} dt) f X ( x ) = Γ ( α ) λ α x α − 1 e − λ x ( Γ ( α ) = ∫ 0 ∞ e − t t α − 1 d t ) α λ \frac{\alpha}{\lambda} λ α α λ 2 \frac{\alpha}{\lambda^2} λ 2 α
离散型随机变量
连续型随机变量
概率
P ( X = x k ) = p k , k = 1 , 2 , ⋯ P(X = x_k) = p_k, \quad k =1,2,\cdots P ( X = x k ) = p k , k = 1 , 2 , ⋯ f ( x ) f(x) f ( x )
(分布/概率密度)函数
F ( x ) = P ( X ≤ x ) , ∞ < x < ∞ F(x) = P(X \leq x), \quad \infty < x < \infty F ( x ) = P ( X ≤ x ) , ∞ < x < ∞ F ( x ) = ∫ − ∞ x f ( t ) d t F(x) = \int^x_{-\infty}f(t)dt F ( x ) = ∫ − ∞ x f ( t ) d t
离散型二维随机变量
连续型二维随机变量
联合(分布/概率)函数
F ( x , y ) = P ( ( X ≤ x ) ∪ ( Y ≤ y ) ) = P ( X ≤ x , Y ≤ y ) F(x,y) = P((X \leq x) \cup (Y \leq y)) =P(X \leq x, Y \leq y) F ( x , y ) = P ( ( X ≤ x ) ∪ ( Y ≤ y ) ) = P ( X ≤ x , Y ≤ y ) F ( x , y ) = ∫ − ∞ y ∫ − ∞ x f ( u , v ) d u , d v F(x,y) = \int^y_{-\infty}\int^x_{-\infty}f(u,v)du,dv F ( x , y ) = ∫ − ∞ y ∫ − ∞ x f ( u , v ) d u , d v
边缘分布函数
p i ⋅ = ∑ j = 1 ∞ p i j = P ( X = x i ) , i = 1 , 2 , ⋯ p ⋅ j = ∑ i = 1 ∞ p i j = P ( Y = y j ) , j = 1 , 2 , ⋯ \begin{aligned}p_{i \cdot} = \sum^\infty_{j=1}p_{ij} = P(X = x_i), \quad i=1,2,\cdots\\p_{\cdot j} = \sum^\infty_{i=1}p_{ij} = P(Y = y_j), \quad j=1,2,\cdots\end{aligned} p i ⋅ = j = 1 ∑ ∞ p i j = P ( X = x i ) , i = 1 , 2 , ⋯ p ⋅ j = i = 1 ∑ ∞ p i j = P ( Y = y j ) , j = 1 , 2 , ⋯ f X ( x ) = ∫ − ∞ ∞ f ( x , y ) d y f Y ( y ) = ∫ − ∞ ∞ f ( x , y ) d x \begin{aligned}f_X(x) = \int^\infty_{-\infty}f(x,y)dy\\f_Y(y) = \int^\infty_{-\infty}f(x,y)dx\end{aligned} f X ( x ) = ∫ − ∞ ∞ f ( x , y ) d y f Y ( y ) = ∫ − ∞ ∞ f ( x , y ) d x
条件分布
P ( X = x i ∣ Y = y j ) = P ( X = x i , Y = y j ) P ( Y = y j ) = p i j p ⋅ j , i = 1 , 2 , ⋯ P ( Y = y i ∣ X = x i ) = P ( X = x i , Y = y j ) P ( X = x i ) = p i j p i ⋅ , j = 1 , 2 , ⋯ \begin{aligned}P(X = x_i\vert Y = y_j) = \frac{P(X = x_i, Y = y_j)}{P(Y = y_j)} = \frac{p_{ij}}{p_{\cdot j}}, \quad i=1,2,\cdots\\P(Y = y_i\vert X = x_i) = \frac{P(X = x_i, Y = y_j)}{P(X = x_i)} = \frac{p_{ij}}{p_{i\cdot}}, \quad j=1,2,\cdots\end{aligned} P ( X = x i ∣ Y = y j ) = P ( Y = y j ) P ( X = x i , Y = y j ) = p ⋅ j p i j , i = 1 , 2 , ⋯ P ( Y = y i ∣ X = x i ) = P ( X = x i ) P ( X = x i , Y = y j ) = p i ⋅ p i j , j = 1 , 2 , ⋯ ∫ − ∞ x f X ∣ Y ( x ∣ y ) d x = ∫ − ∞ x f ( x , y ) f Y ( y ) d x ∫ − ∞ y f Y ∣ X ( y ∣ x ) d y = ∫ − ∞ y f ( y , x ) f X ( x ) d y \begin{aligned}\int^x_{-\infty} f_{X\vert Y}(x\vert y)dx = \int^x_{-\infty}\frac{f(x,y)}{f_Y(y)}dx\\\int^y_{-\infty} f_{Y\vert X}(y\vert x)dy = \int^y_{-\infty}\frac{f(y,x)}{f_X(x)}dy\end{aligned} ∫ − ∞ x f X ∣ Y ( x ∣ y ) d x = ∫ − ∞ x f Y ( y ) f ( x , y ) d x ∫ − ∞ y f Y ∣ X ( y ∣ x ) d y = ∫ − ∞ y f X ( x ) f ( y , x ) d y
相互独立
P ( X = x i , Y = y j ) = P ( X = x i ) P ( Y = y i ) \begin{aligned}P(X=x_i, Y=y_j) = P(X=x_i)P(Y=y_i)\end{aligned} P ( X = x i , Y = y j ) = P ( X = x i ) P ( Y = y i ) f ( x , y ) = f X ( x ) f Y ( y ) f(x,y) = f_X(x)f_Y(y) f ( x , y ) = f X ( x ) f Y ( y )