- 1. Database紹介
- 2. database基礎理論
- 3. Relational data model
- 4. Relational algebra
- 5. SQL
- 6. SQLによる高度な問合せ
- 7. 正規化
- 8. データモデリング(data modeling)
- 9. データベース管理システムと外部記憶装置
- 10. transaction
- 11. NOSQL
CS专业课学习笔记
Database紹介
データベース(database)とは複数のデータを多様な用途に利用できるよう組織化したうえで一元的に管理されたデータの集合
DBMS
データベース管理システム(DataBase Management System)とはデータを組織化し管理するための仕組みを提供するソフトウェア
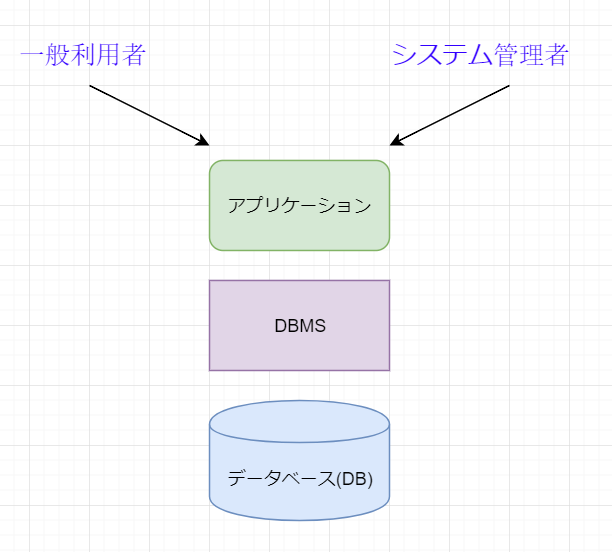
- データベースシステム = DBMS + データベース
Webアプリケーションのシステム構成
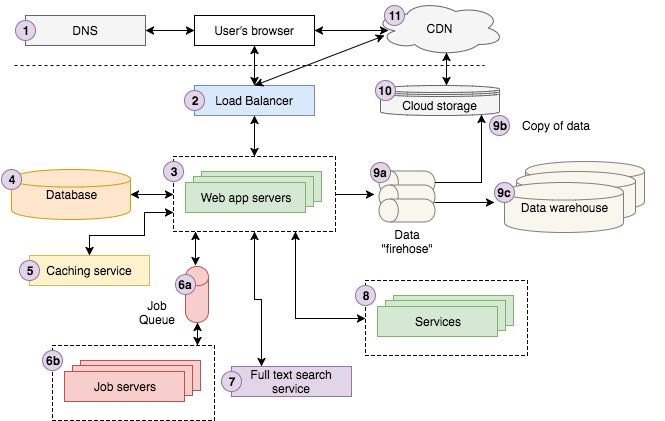
DBMSの必要性
- 検索の高速性・容易性
- 異なるアプリケーション間でのデータ共有
- アクセス権限の管理(機密保護)
- 同時アクセス制御
- 障害時データ保護
DBMSの特徴
- 検索や更新を高速に行うためにデータを組織化して格納する
- 複数のアプリケーションからデータにアクセスしても整合性が担保される
- データにウィルスが含まれるかチェックする機能は一般的にはない
- ユーザの権限によるデータのアクセス可否をチェックする
- 障害に備えてデータをバックアップしたり,バックアップからデータを復元したりする
- データスキーマは設計時に確定してデータベース管理システムに設定する.自動的に選択するわけではない
Data modelとDatabaseの種類
データモデルとはデータの種別や組織化方法,操作方法の体系を定めたもの
例:
- ネットワーク型DB(networked)
- 階層型DB(hierarchical)
- リレーショナルDB(relational)
- オブジェクト指向DB(object oriented)
- 半構造DB(semistructured)
- NoSQL DB(Not Only SQL)
ネットワーク型DB(networked)
- 米国の情報技術標準か団体のCODASYLにより標準化(1971)
- データ構造:1組のデータをレコードにより表現し,複数のレコード間をポインタにより紐付ける
- Webのようにネットワークをたどることで目的のデータにアクセスできる(ただし,集中管理)
階層型DB(hierarchical)
- セグメント(レコードと同義)をノードとし,ノード間の親子関係に基づいて,木構造を構成
- eg.Windowsのレジストリ(データベース)
- 1対Nの親子関係により整理が可能なものは扱い易い(N対Mの関係は定義できない場合も多い)
リレーショナルDB(relational)
- IBMサンノゼ研究所のE. F. Coddにより提唱された
- リレーショナルモデル(relational model) = 関係モデル
- すべてのデータは数学の集合論に基づいた表(テーブル)で表現できるという考え方
まとめ
| データベース | 特徴 |
|---|---|
| ネットワーク型DB | 親レコード: 複数の子レコードを持つ 子レコード: 複数の親レコードしか持てない |
| 階層型DB | 親レコード: 複数の子レコードを持つ 子レコード: 1つの親レコードしか持てない |
| リレーショナルDB | データを表で表し、複数の表を関連させて使用する |

- NoSQLとは、関係データベース管理システム (RDBMS) 以外のデータベース管理システムを指す大まかな分類語である
- 半構造データベースとは,データベースに保存するデータのデータ構造を予め規定せず,保存しようとしているデータに応じてデータ構造を定義するデータベースである.扱うデータ形式の例としてXMLやJSONがある
- キーバリュー型データベースは識別子(キー)とデータの組み合わせによるシンプルなデータの問い合わせを可能にするもので,インターネット上の大量データを効率的な扱う仕組みとして注目されている
database基礎理論
集合
- 集合(set):「もの」の集まり.数,文字,記号など
- 要素(element):集合に属する「もの」のこと.元とも呼ぶ.
- 空集合(empty set):何も要素を含まない集合
集合演算
- 和集合
- 共通集合(積集合)
- 差集合
- べき集合
- 部分集合全体からなる集合
- 直積集合
Relational data model
実世界のモノ・概念を表(=リレーション)として表現
- 属性(attribute):データの種類
- タプル(tuple):データの組
- リレーション(relation):タプルの集合,インスタンス
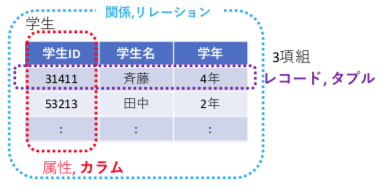
注意:
- 同じタプル(行)が重複して,リレーション(表)の中に現れることはない(リレーションはタプルの「集合」だから)
- タプル(行)の順序に意味がない
- 属性(列)の順序には意味がない
リレーションと第1正規形
- 単純な値でできている表
- 表の中に表やリストがない(入れ子型リレーションではない)
- 各行の構造が共通している
- リレーショナルデータモデルで扱うリレーション
例:
- 名前が直積であるので非第1正規形
| 学籍番号 | 名前 |
|---|---|
| 100 | (鈴木, 一郎) |
| 200 | (松井, 秀喜) |
- 第1正規形
| 学籍番号 | 姓 | 名 |
|---|---|---|
| 100 | 鈴木 | 一郎 |
| 200 | 松井 | 秀喜 |
- 趣味が集合値なので非第1正規形
| 学籍番号 | 名前 | 趣味 |
|---|---|---|
| 100 | (鈴木, 一郎) | (野球, サッカー, テニス) |
| 200 | (松井, 秀喜) | (野球, ショッピング) |
- 第1正規形
| 学籍番号 | 名前 | 趣味 |
|---|---|---|
| 100 | 鈴木一郎 | 野球 |
| 100 | 鈴木一郎 | サッカー |
| 100 | 鈴木一郎 | テニス |
| 200 | 松井秀喜 | 野球 |
| 200 | 松井秀喜 | ショッピング |
数学的な定義
- リレーション名:
- 属性名: (n:次数degree)
- リレーションスキーマ:
- ドメイン(定義域):
- 直積集合:
- タプル:
- リレーション(インスタンス):
リレーションスキーマ
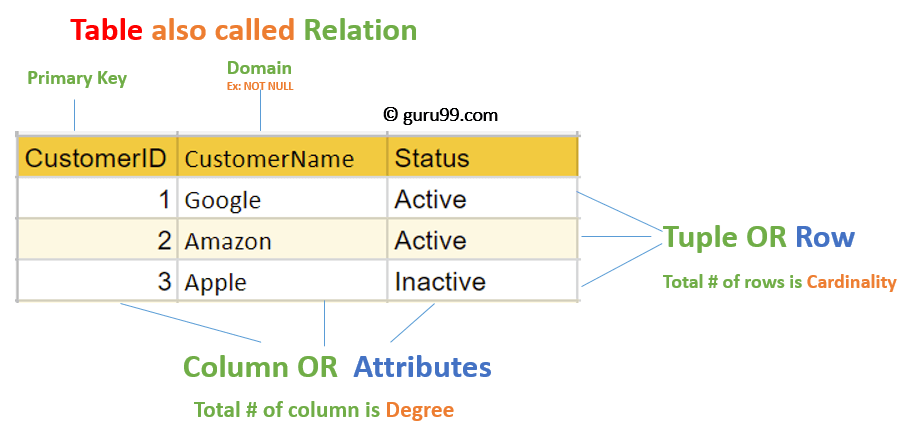
- 次数(degree)=列数
- 濃度(cardinality)=行数
例題:
リレーションスキーマの属性のドメインをそれぞれとする
(1) 直積集合を求めなさい.
(2)リレーションスキーマの次数はいくつか?リレーションスキーマに従うリレーションの濃度の最大数はいくつか
- 次数:2
- 濃度の最大数: 6
リレーションと整合性制約
データベースとして矛盾なく健全である状態を保つための条件や制約
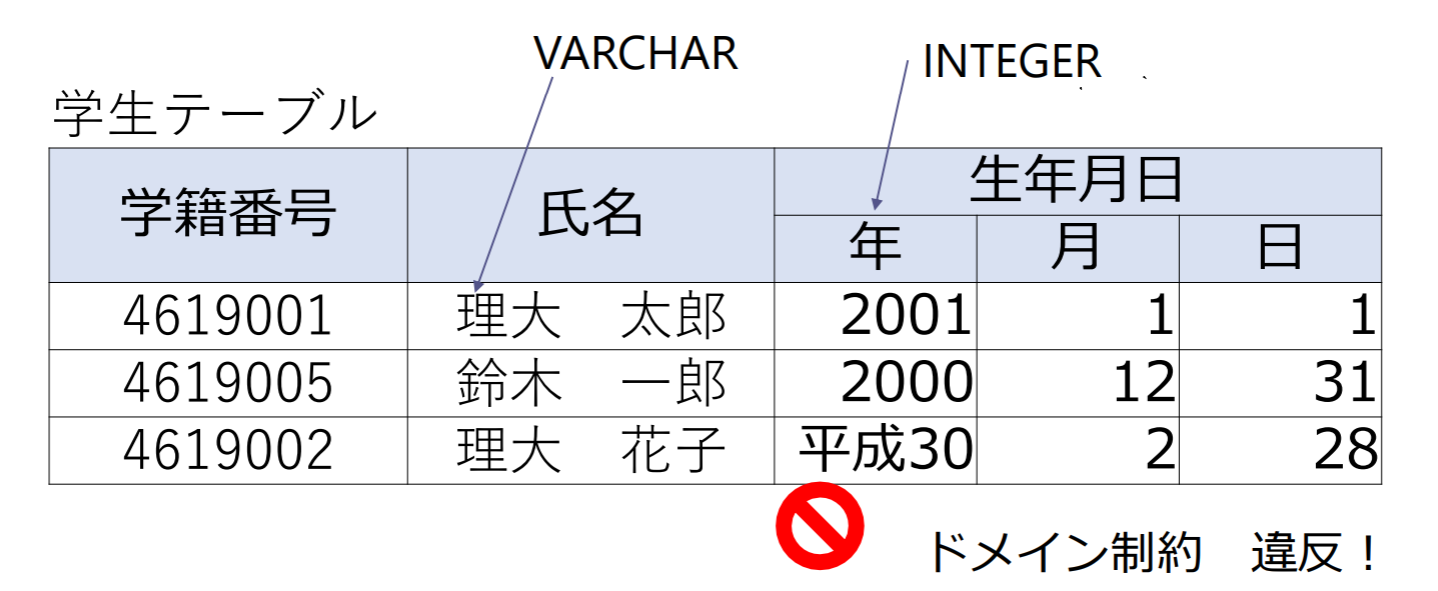
ドメイン制約
属性値が,その属性のドメインに含まれる(データ型が一致)
- 年:正の整数,月:1~12,日:1~31
- 氏名:文字列
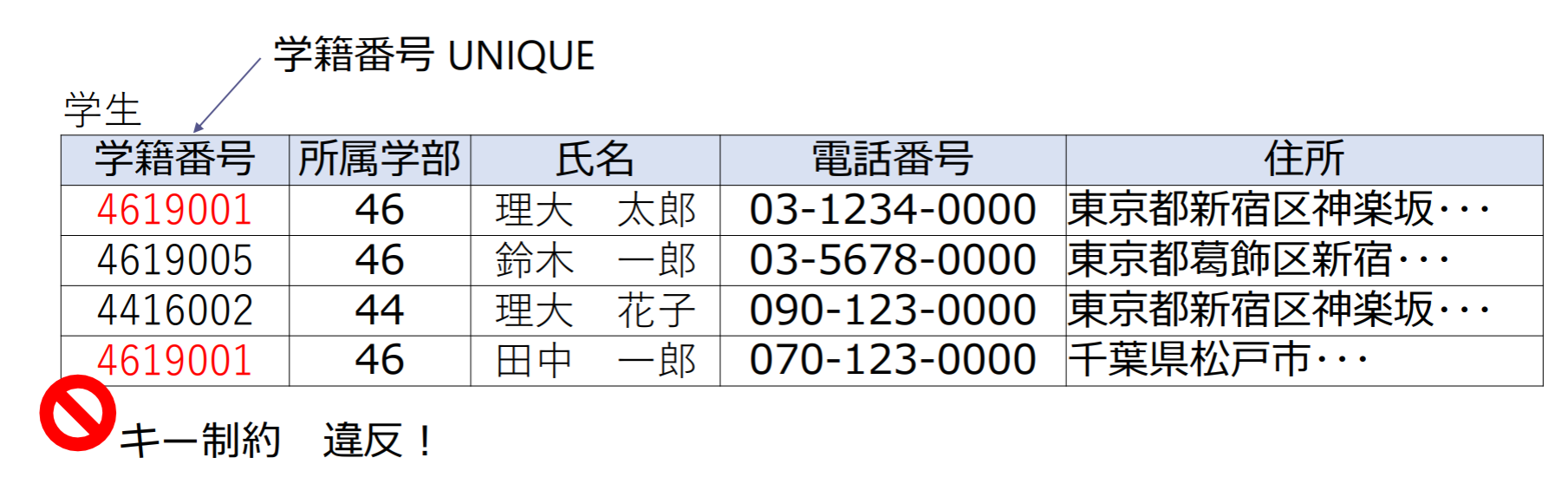
キー制約 | 一意性制約
属性または属性の集合において,同じ属性値がリレーションの中で重複して現れることがない
- eg. 学籍番号は重複しない(キー制約)
キー (key)
- スーパーキー(super key):タプルを一意的に特定できる属性や属性の集合
- 学籍号可以特定这个表中的一行,所以学籍号是super key。当然跟学籍号组合的集合也能特定(学籍号+名字),这也是super key
- はスーパーキーであるが、候補キーではない
- 候補キー(candidate key):他のスーパーキーを含まない極小の属性集合
- 由于学籍号本身就是super key了,所以学籍号+名字不是candidate key
- は候補キー
- 主キー(primary key) :候補キーから任意に選択した一つ(NULLを含まない)
- 複合主キー:主キーを構成する属性集合(主キーが2個以上の属性から構成される場合)

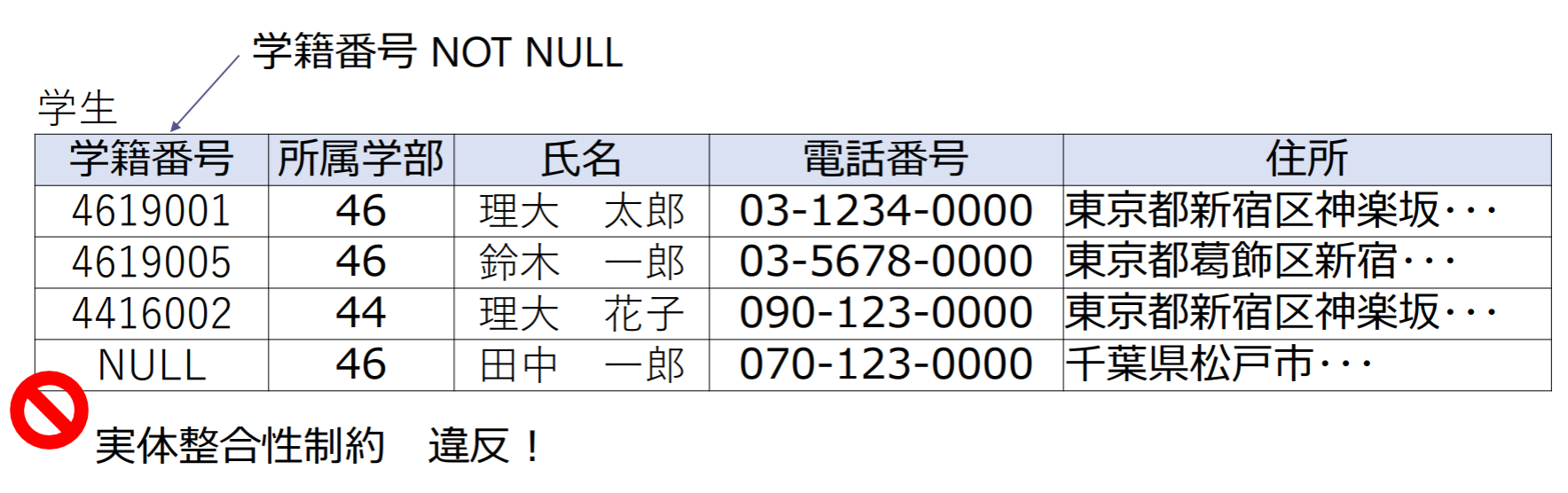
実体整合性制約
実体整合性制約: 属性(または属性の集合)がNULL(空値)をとらない
- 主キーはNULLをとらない,候補キーはNULLをとってもよい
参照整合性制約
参照整合性制約: 外部キー(foreign key):NULLを除いて他リレーションの主キーにある属性値をとる属性
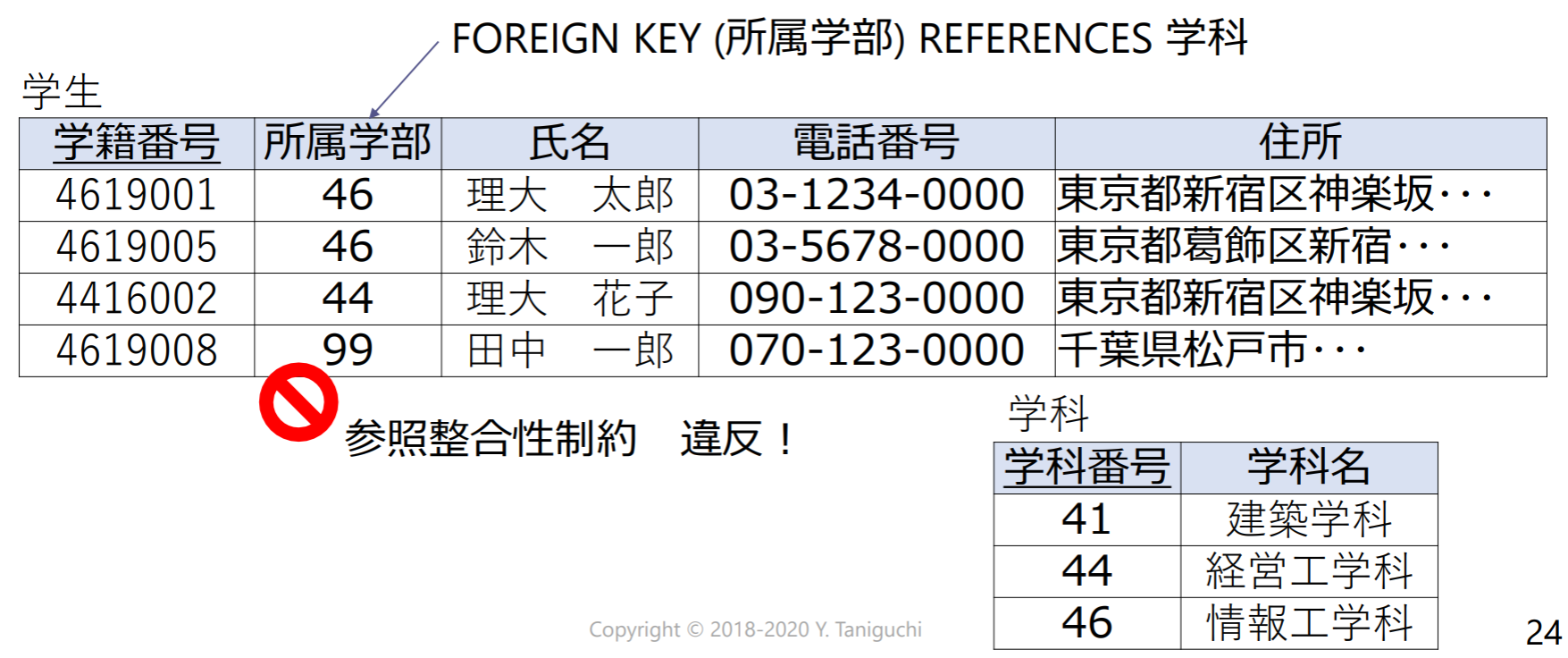
まとめ
| キーの種類 | 説明 |
|---|---|
| スーパーキー | 行を一意に識別するための属性(あるいは属性の組合せ) |
| 候補キー | スーパーキーのうち、行を一意に識別するために必要最低限の組合せ |
| 主キー | あるテーブルのレコードを特定するための識別子 |
| 外部キー | リレーションにおいて、他のエンティティの主キーを参照する属性 |
商品
| 商品番号 | 商品名 | 値段 |
|---|---|---|
| R001 | プリンタ1 | 49,800 |
| C001 | パソコン1 | 148,000 |
| H002 | HDD2 | 9,800 |
| M001 | Camera1 | 38,800 |
| M005 | Camera5 | 49,800 |
- リレーション名: 商品
- 属性名(すべて): {商品番号,商品名,値段}
- 次数 (arity, degree): 3
- 濃度 (cardinality): 5
- リレーションスキーマ: 商品(商品番号,商品名,値段)
- タプル(複数あるうちの一つ): (R001, プリンタ1, 49800)
リレーショナルモデルについて:
- リレーションはタプルの集合である
- リレーションのことをインスタンスとよぶ場合がある
- 同じタプルが重複して一つのリレーションに表れることはない
リレーションスキーマについて:
商品(商品ID, 商品名,型番)
ここで、商品リレーションは、商品のデータを格納するためのもので、商品毎に商品ID、商品名、型番を属性値としてもつ。ここで、商品IDはデータ登録時に払い出される商品固有の番号である。同じ商品名でも、仕様が異なれば異なる商品として管理する必要がある。例えば、商品名が同じ"USBキー"でも、容量が異なれば、別商品として扱い、異なる型番が付与される。
- 候補キー: 商品ID, 型番
- キー制約: ある属性(または属性の集合)において,同じ属性値がリレーションの中で重複して表れることはない
- ドメイン制約: 属性値が,予め指定したデータ型(属性値の定義域)に含まれる値である必要がある
- 実体整合性制約: 属性(または属性の集合)が空値をとってはならない
- 参照整合性制約: 外部キーの属性値は,空値の場合を除いて参照先の主キーの値である必要がある
Relational algebra
リレーショナル代数とは単一または複数のリレーションに対して定義された演算の体系
- 集合演算
- 関係演算(リレーショナル演算)
集合演算
- 和集合
- 共通集合(積集合)
和両立(union compatible)
リレーションスキーマとが次の二つの条件を満たすとき,リレーションとは和両立である
- との次元が等しい(つまり)
- 各に対して,属性とのドメインが等しい(つまりdom() = dom())
必ずしも属性名は同じでなくてもよい
例
次のリレーションのは,和両立か否か?(ドメインは常識的に考えて答えなさい.)
- R(学籍番号, 氏名),S(学籍番号,名前)
- 「氏名」と「名前」のドメインは「文字列」と考えれば和両立
- R(学籍番号,氏名), S(教員番号,氏名,役職)
- RとSの次数(列の数)が一致しないので和両立ではない
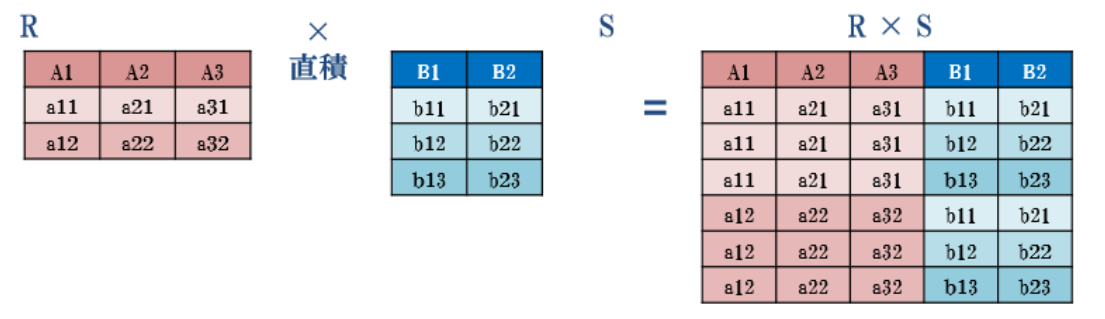
直積演算
- 直積,デカルト積 (Cartesian product):
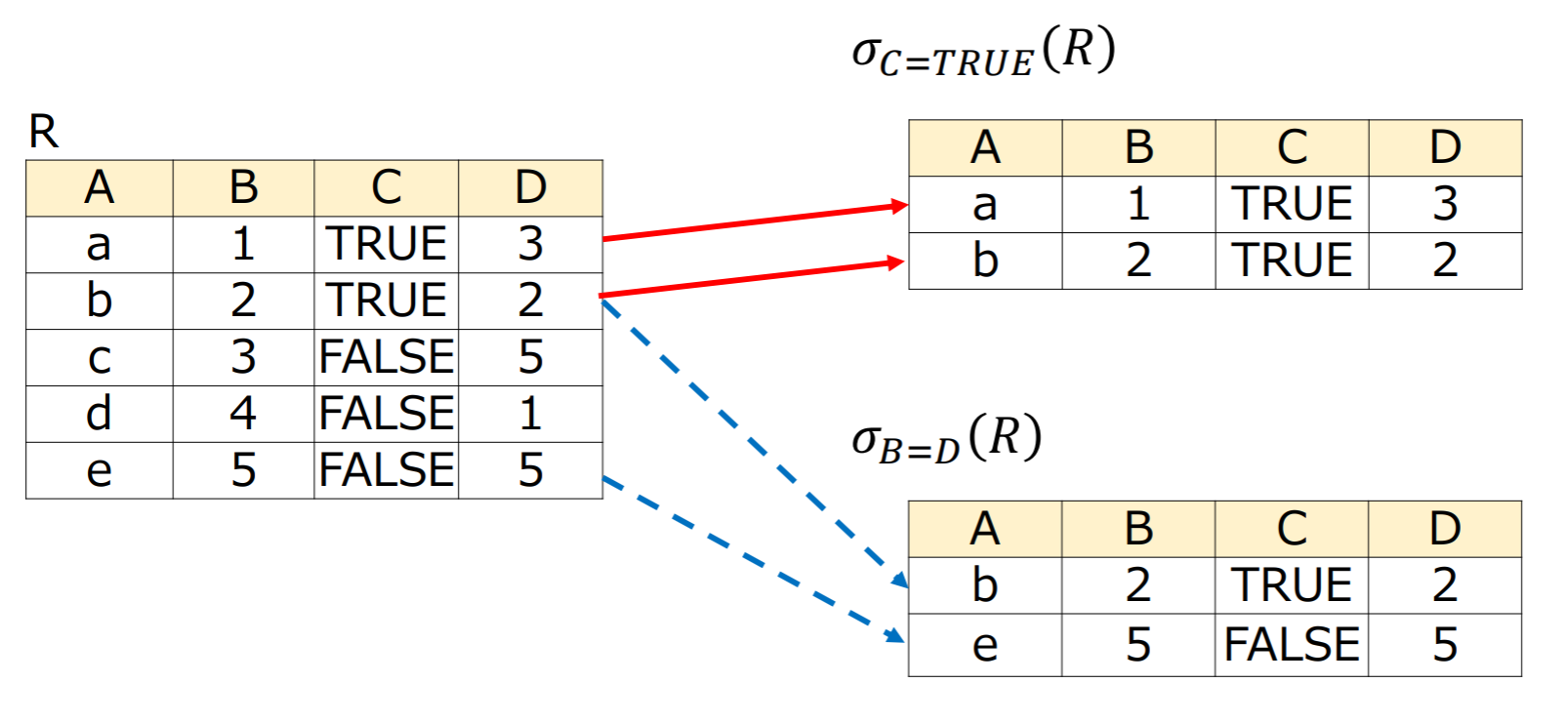
関係演算
選択演算(selection)
リレーションの中から条件式を満たすタプルを抽出する演算
タプルが条件式を満たせばtrue,満たさなければfalseを返す関数
射影演算(projection)
リレーションから,指定した属性集合のみを持つリレーションを抽出する演算
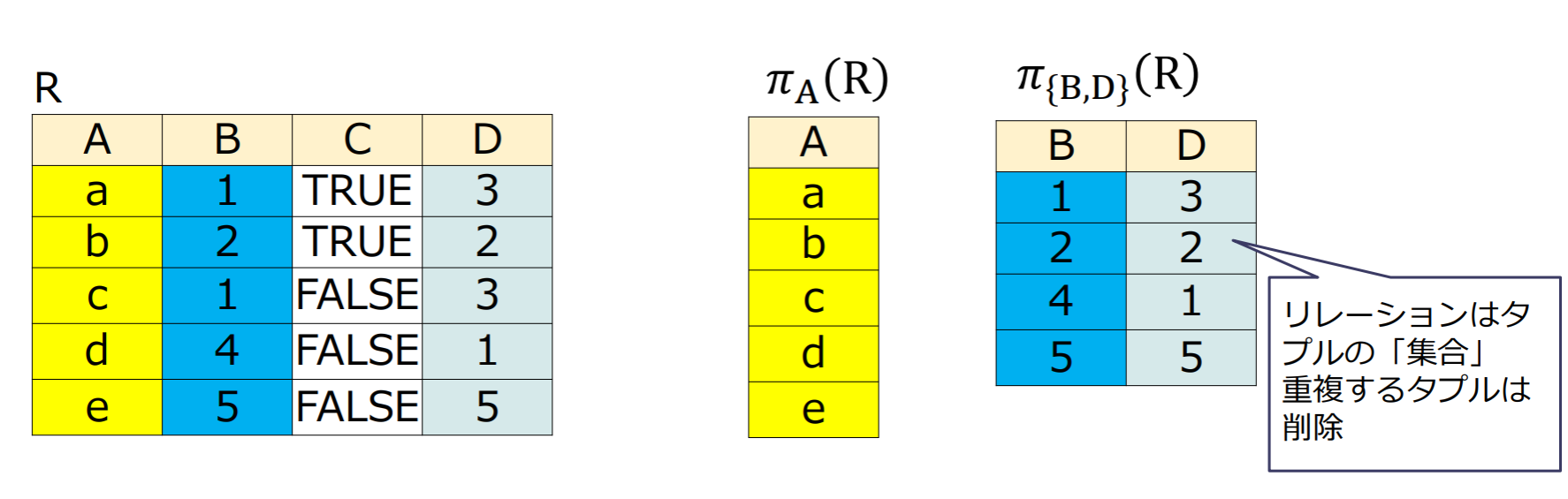
リレーションはタプルの「集合」重複するタプルは削除
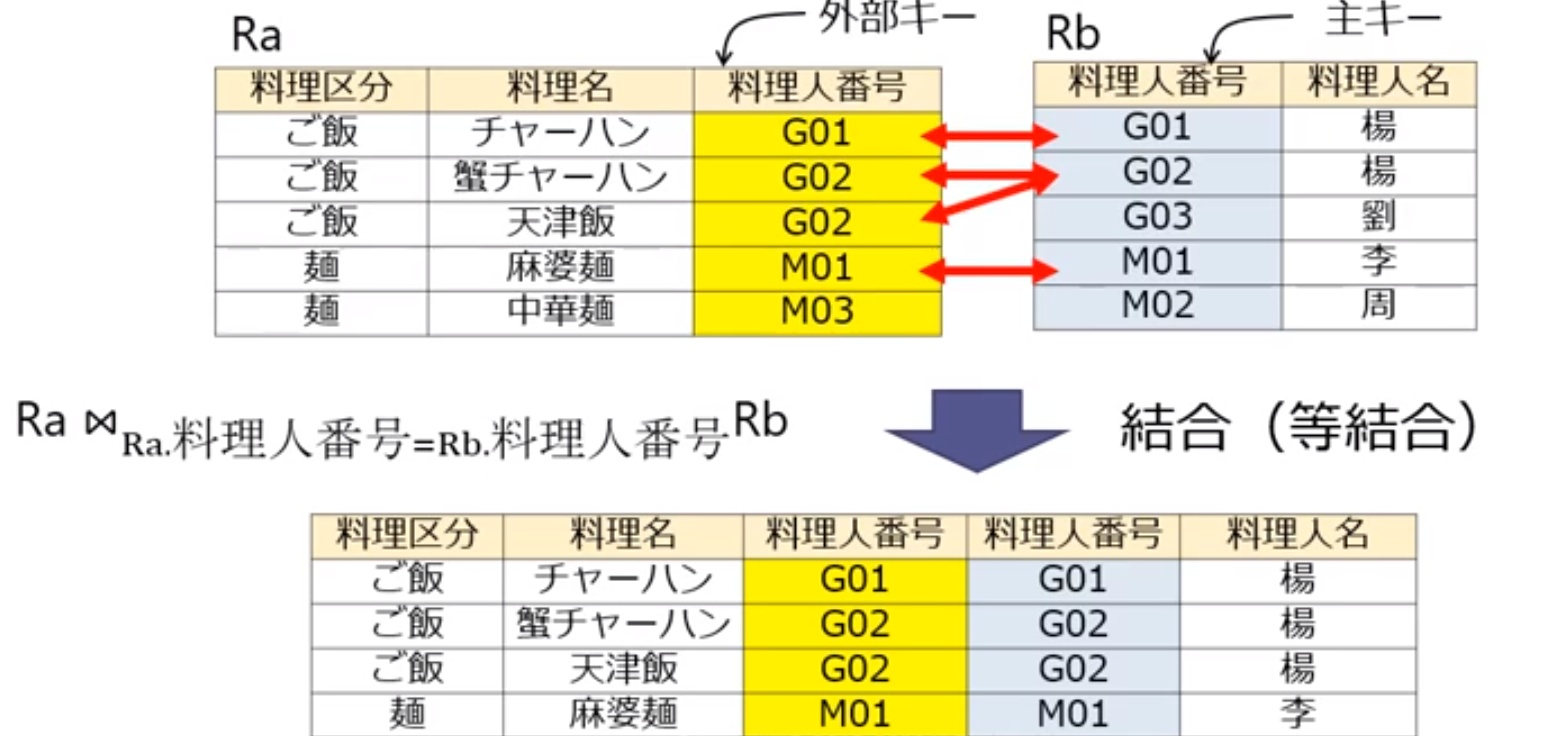
結合演算(join)
二つのリレーションとを条件に従って一つのリレーションに統合する.内部結合(inner join)ともよぶ
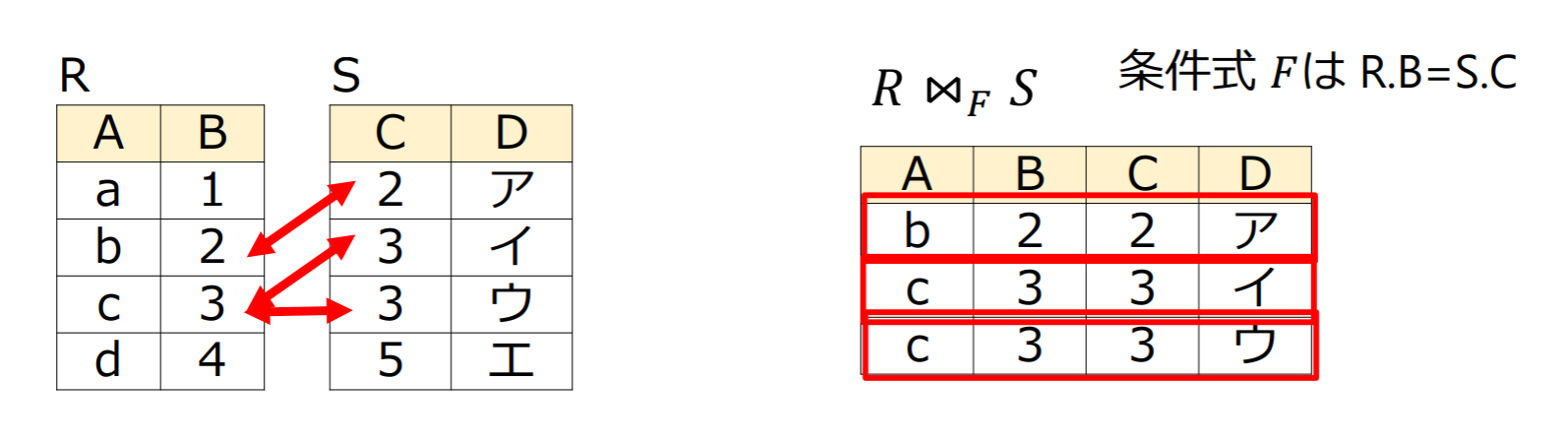
等結合(equi-join)
結合演算の条件として,2つのリレーションの対応する属性が等しいことを用いるもの
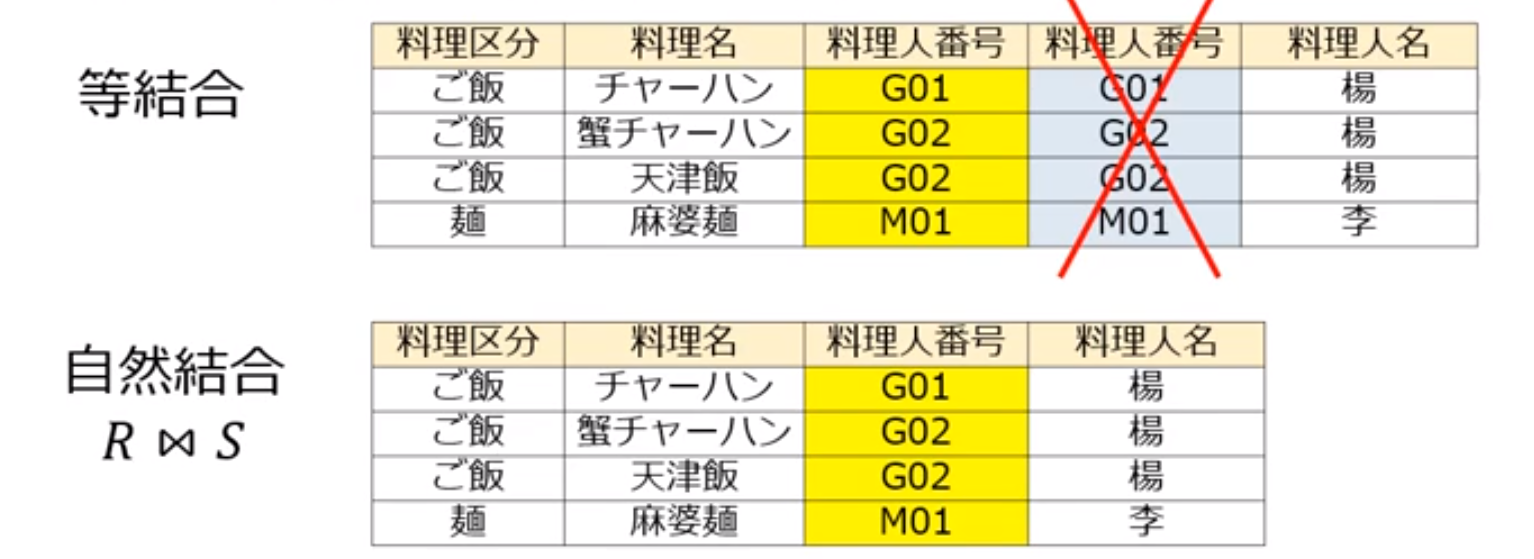
自然結合演算(natural join)
等結合で得られるリレーションから重複する属性を射影により取り除いたもの
- 交換法則と結合法則が成り立つ
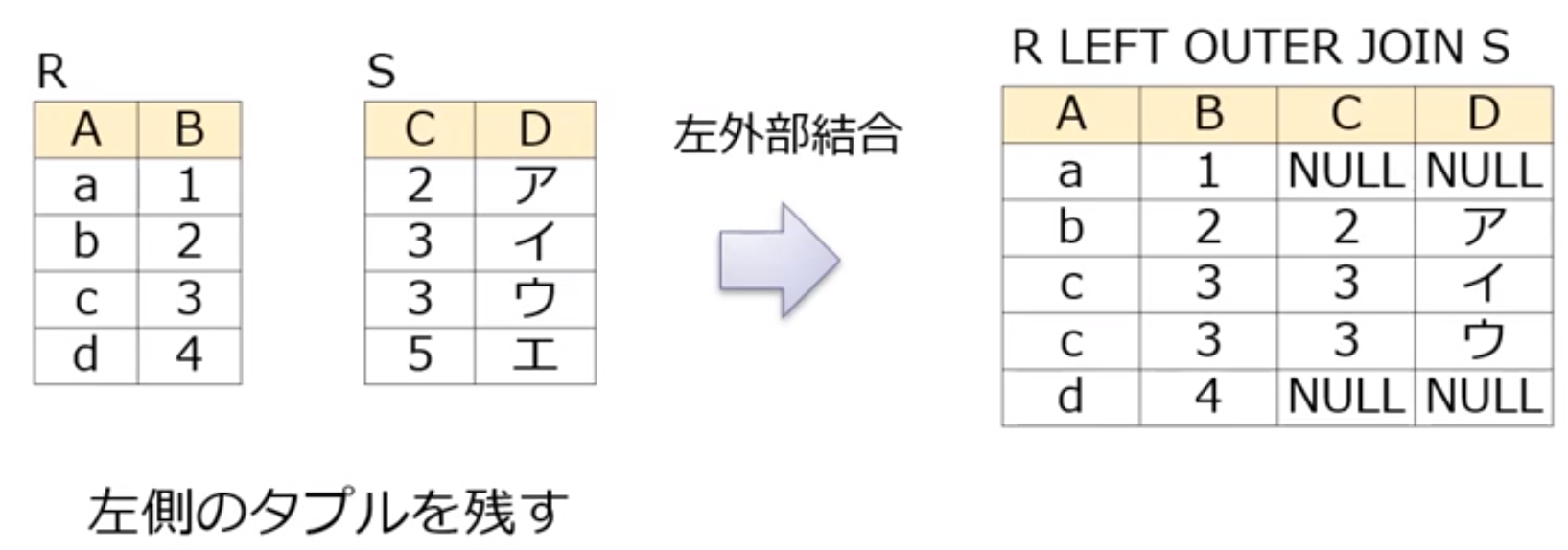
外部結合演算(outer join)
一方のリレーションのタプルのうち,もう一方のリレーションに対応するタプルがないものは,対応するの属性値をNULLにする
- 左外部結合(left outer join)
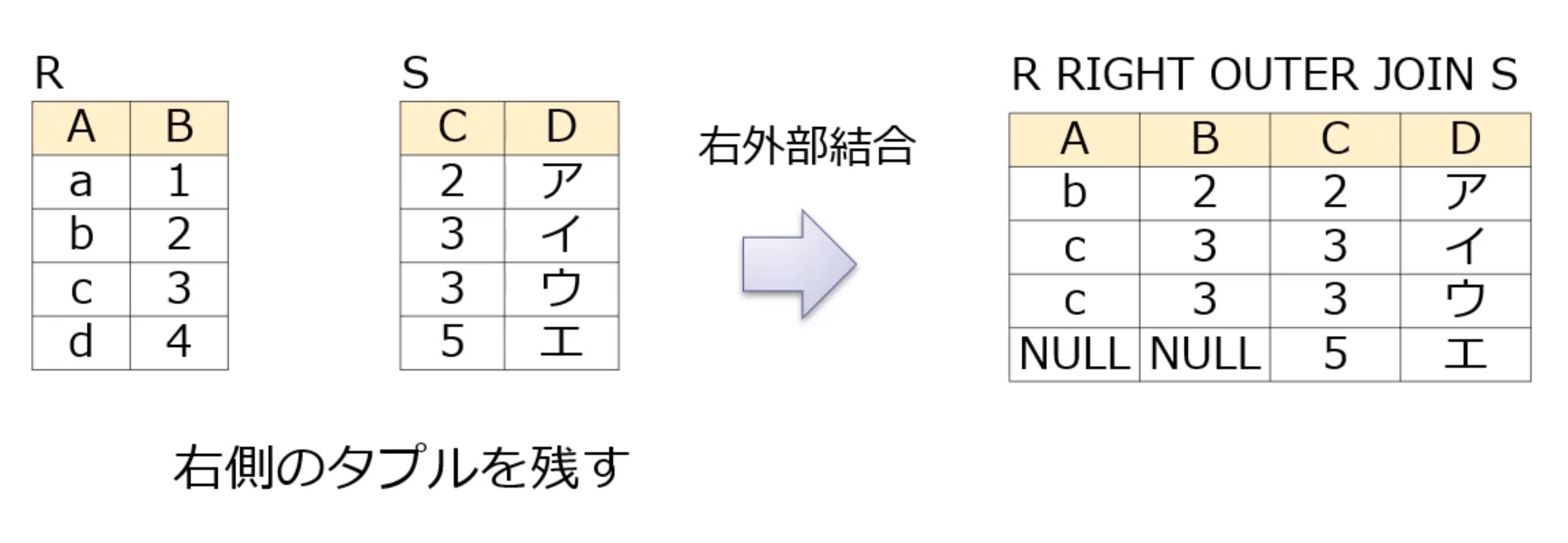
- 右外部結合(right outer join)
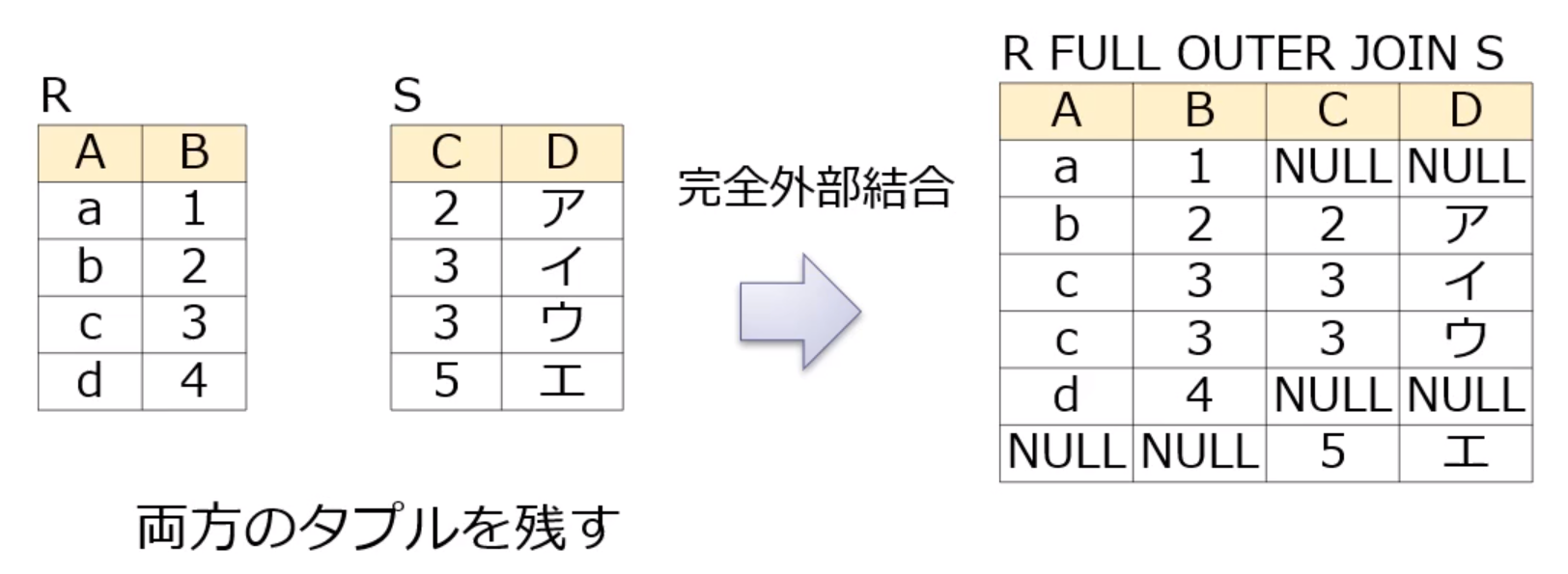
- 完全外部結合(complete outer join)
左外部結合
右外部結合
完全外部結合
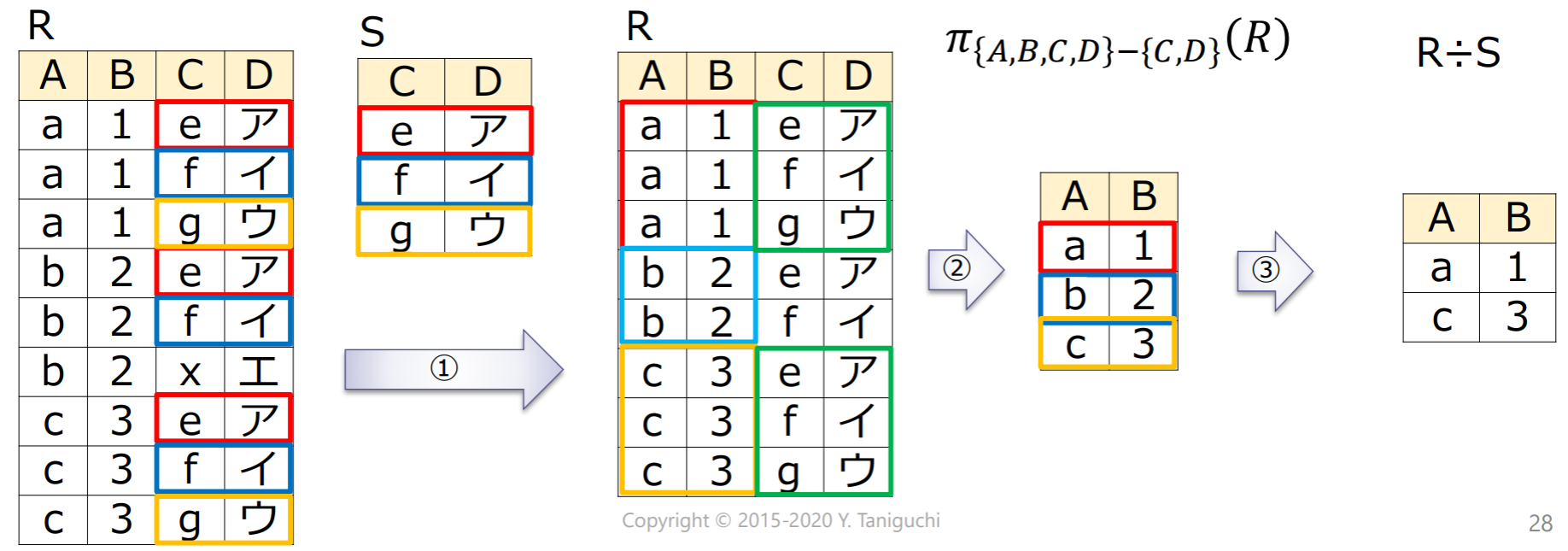
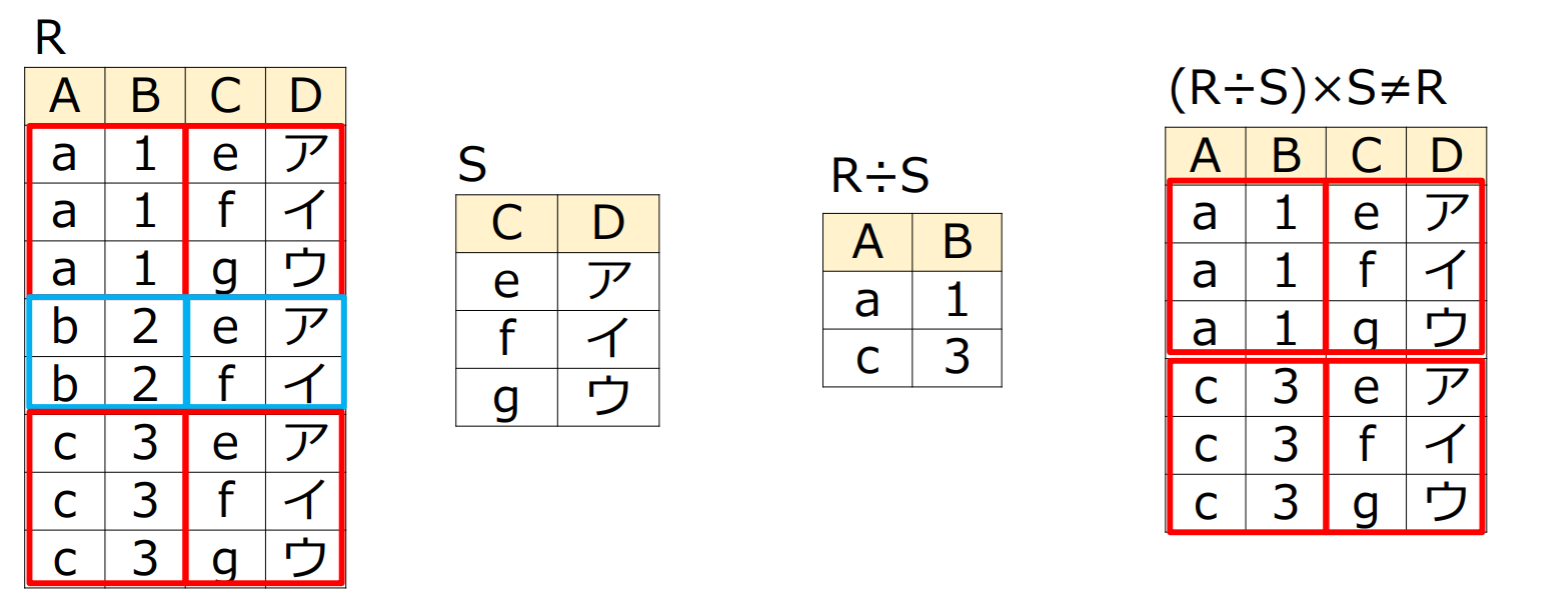
商演算(division)
- の各タプルに対して同じ値を持つのタプルを選択
- の属性集合からの属性集合を除いた上で同じ値を持つタプルを集約
- のすべてのタプルを含んでいる場合に対応するタプルを選択
商演算は直積演算の逆演算
整数などの商演算と同じようにが成立
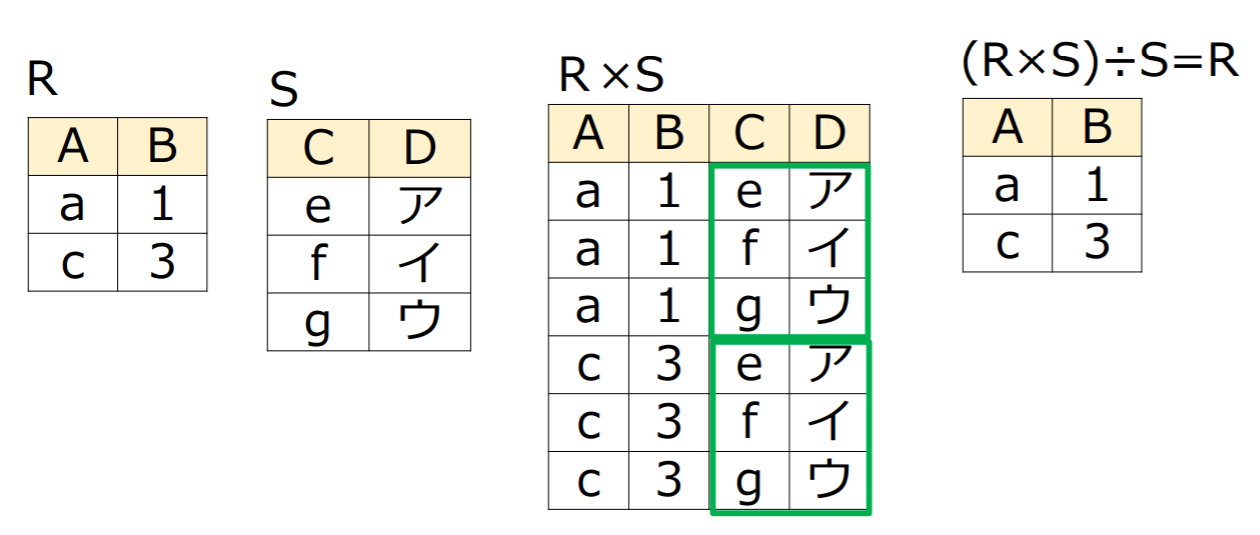
は成立しない(整数演算と同じ)
課題4.1(集合演算)
(1) 下記に示すリレーションとに対して,和集合,共通集合,差集合の各演算結果を求めよ
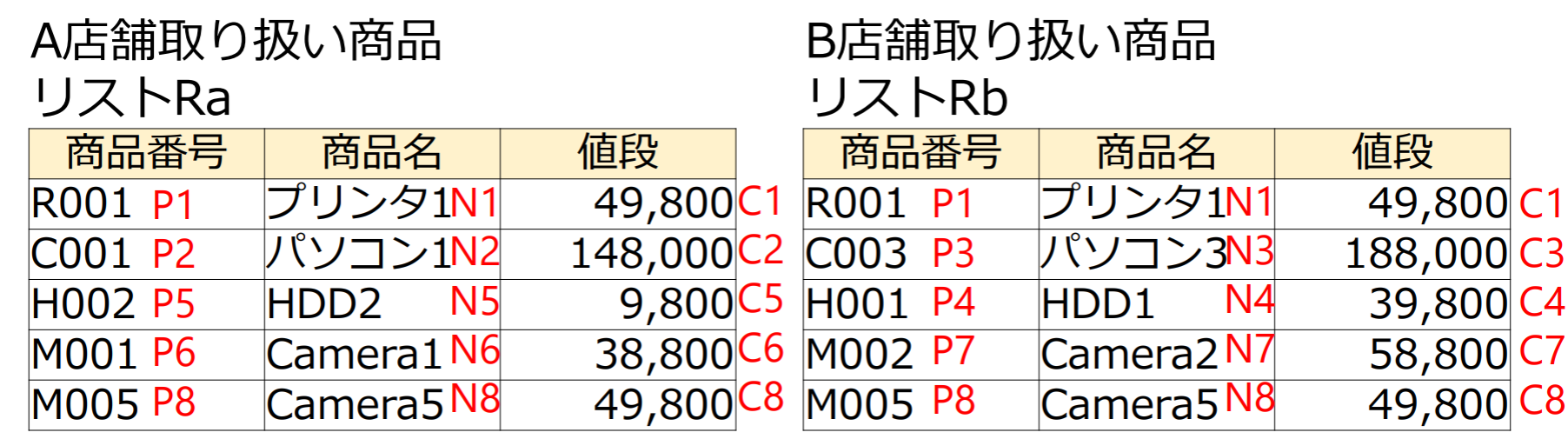
- 和集合
| 商品番号 | 商品名 | 値段 |
|---|---|---|
| P1 | N1 | C1 |
| P2 | N2 | C2 |
| P3 | N3 | C3 |
| P4 | N4 | C4 |
| P5 | N5 | C5 |
| P6 | N6 | C6 |
| P7 | N7 | C7 |
| P8 | N8 | C8 |
- 共通集合
| 商品番号 | 商品名 | 値段 |
|---|---|---|
| P1 | N1 | C1 |
| P8 | N8 | C8 |
- 差集合
| 商品番号 | 商品名 | 値段 |
|---|---|---|
| P2 | N2 | C2 |
| P5 | N5 | C5 |
| P6 | N6 | C6 |
(2) 下記に示すリレーションに対して直積集合を求めなさい
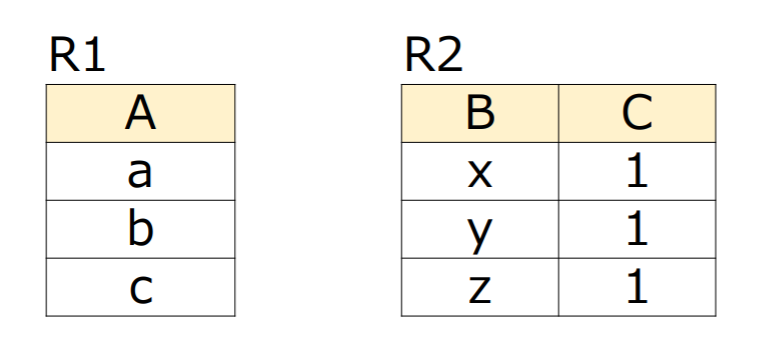
- 直積集合
| A | B | C |
|---|---|---|
| a | x | 1 |
| a | y | 1 |
| a | z | 1 |
| b | x | 1 |
| b | y | 1 |
| b | z | 1 |
| c | x | 1 |
| c | y | 1 |
| c | z | 1 |
課題4.2(関係演算)
(1) 下記に示すリレーションとに対して,結合条件を両リレーションにおける属性が等しいとした場合の内部結合,自然結合,左外部結合,右外部結合,完全外部結合の各演算結果を求めよ
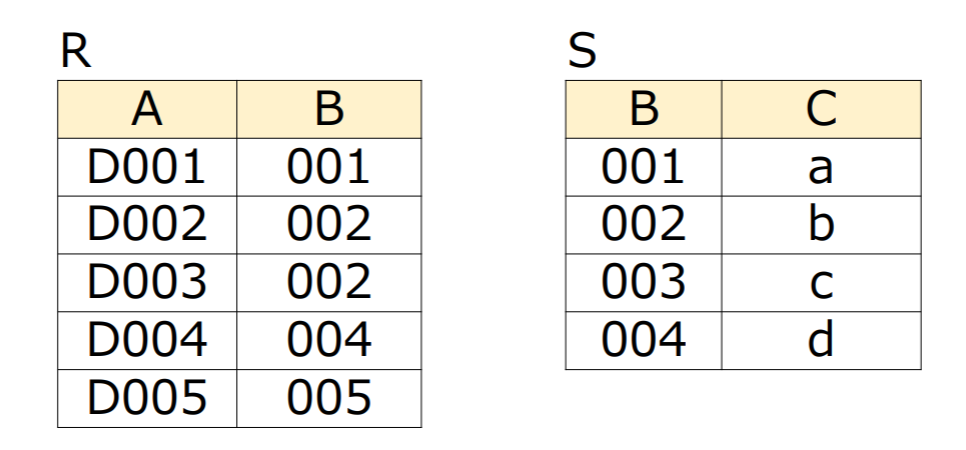
- 内部結合(結合演算)
| A | B | B | C |
|---|---|---|---|
| D001 | 001 | 001 | a |
| D002 | 002 | 002 | b |
| D003 | 002 | 002 | b |
| D004 | 004 | 004 | d |
- 自然結合
| A | B | C |
|---|---|---|
| D001 | 001 | a |
| D002 | 002 | b |
| D003 | 002 | b |
| D004 | 004 | d |
- 左外部結合
| A | B | B | C |
|---|---|---|---|
| D001 | 001 | 001 | a |
| D002 | 002 | 002 | b |
| D003 | 002 | 002 | b |
| D004 | 004 | 004 | d |
| D005 | 005 | NULL | NULL |
- 右外部結合
| A | B | B | C |
|---|---|---|---|
| D001 | 001 | 001 | a |
| D002 | 002 | 002 | b |
| D003 | 002 | 002 | b |
| NULL | NULL | 003 | C |
| D004 | 004 | 004 | d |
- 完全外部結合
| A | B | B | C |
|---|---|---|---|
| D001 | 001 | 001 | a |
| D002 | 002 | 002 | b |
| D003 | 002 | 002 | b |
| NULL | NULL | 003 | C |
| D004 | 004 | 004 | d |
| D005 | 005 | NULL | NULL |
(2) 以下のリレーションRについて,日付,商品名(日付=2013/10/3())を求めよ.
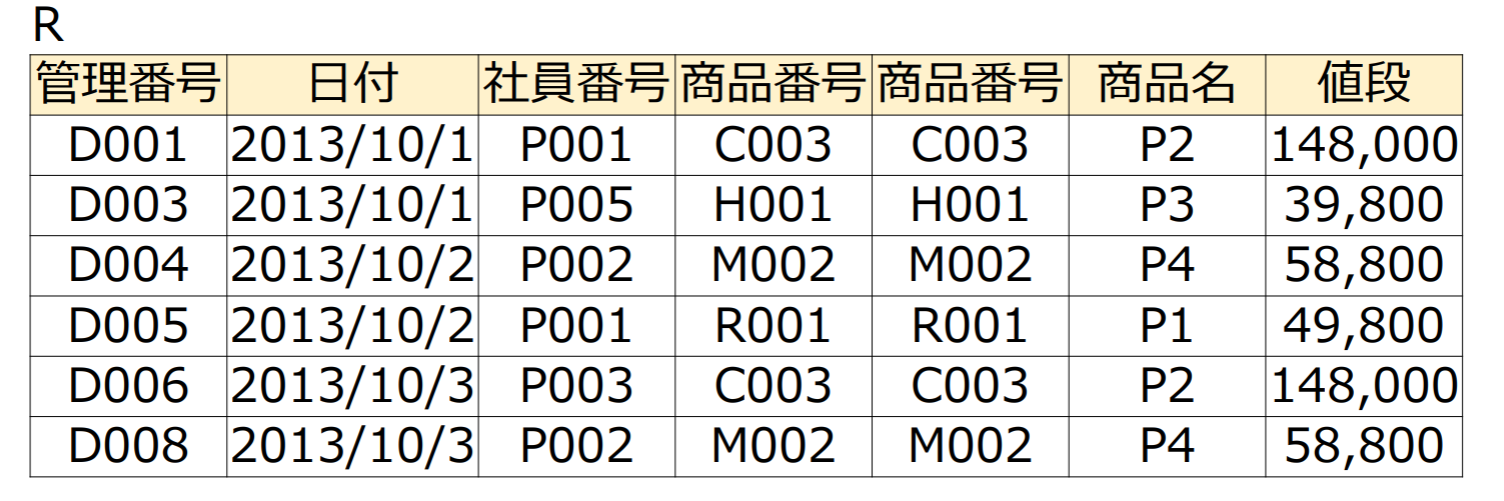
| 日付 | 商品名 |
|---|---|
| 2013/10/3 | P2 |
| 2013/10/3 | P4 |
課題4.3(商演算)
次のリレーション、サークル活動,サークルに対してサークル活動サークルを求めなさい.
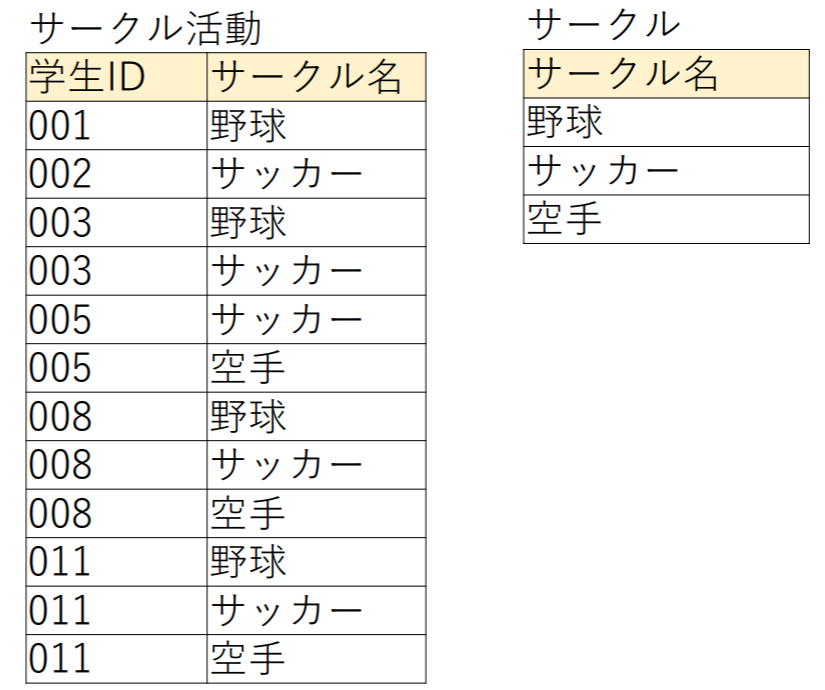
| 学生ID |
|---|
| 008 |
| 011 |
SQL
SQLの概要
リレーショナルデータベースを操作するための標準言語
IBMのE.F.Coddが提案したDBMSであるSystem Dで使われていたSEQUEL(Structured English Query Language)が元祖
- データ定義言語(DDL)
- eg. CREATE TABLE
- データ操作言語(DML)
- eg. SELECT … FROM … WHERE, INSERT, UPDATE, DELETE
- データ制御言語(DCL)
- eg. 権限の制御 CREATE USER…, GRANT
databseへの接続
- 専用コマンドラインインターフェース(mysql)による接続
1 | # passwordを送信 |
- アプリケーション(ホスト言語)からの接続
1 | $dsn = 'mysql:dbname = データベース名; host = ホスト名;' |
SQLite
- 軽量・コンパクトなリレーショナルデータベース
- 単独アプリケーション、ライブラリとして動作
- 組み込み用途や小規模システムのデータストアとして利用される
- マルチプラットフォーム
テーブル
SQLとリレーショナルモデル
- 共通点
- テーブル、行、列 リレーション、ダブル、属性
- リレーショナルモデルとの違い
- 行と列の順序に意味がある(ソートした場合)
- 同じ内容を持つ重複した行を持つことができる
- データベースに実際に作成したテーブル
- 実テーブルから演算関係などにより作成されたテーブル
- 仮想的なテーブル(保存されているわけではなく, 問い合わせの度にテーブルを作成)
データ型
- NULL
- NULL値
- INTEGER
- 符号付き整数
- REAL
- 浮動小数点数. 8バイトで格納
- TEXT
- 文字列
- char(文字数), varchar(文字数)型はSQLiteには存在しないのでTEXT型に変換される
- BLOB
- 入力値をそのまま格納(Binary Large Object)
create文
create: テーブルの定義
1 | create table テーブル名( |
例:
1 | create table 商品) |
drop,alter文
drop: テーブルの削除
alter: テーブルの変更
1 | drop table テーブル名 |
1 | alter table テーブル名 |
INSERT文
insert: 行(ダブル)の挿入
1 | insert into デーブル名[(列名1, ..., 列名m)] values (値1, ..., 値m) |
例:
1 | insert into 商品 values('A01', 'オフィス用紙A4', 2000); |
データ操作
SELECT文
1 | select [distinct] 列名1, ..., 列名m -- *(アスタリスク)もケ可 |
例:
1 | select * from 商品; |
検索条件
| 述語・演算子 | 説明(例) |
|---|---|
| 比較演算子 =, <>, >, <, >=, <= | 商品番号 <> ‘A01’(不等号) |
| [not] between 値式 and 値式 | 社員ID between ‘1002’ and ‘1004’ |
| [not] in (定数[,定数]) | 社員ID in (‘1002’, ‘1003’) |
| [not] like | %は0個以上の任意長の任意文字列を, _は1個の任意文字列を表す. |
| 列名 is [not] like | 商品番号 is not null |
1 | select * from 商品 where 商品番号 <> 'A01'; |
UPDATE文
update: 行(タプル)の更新
1 | UPDATE テーブル名 SET 列名1=値1 [, 列名2 = 値2, ...] [WHERE条件] |
例:
1 | update 商品 set 価格=1000 where 商品番号='A01'; |
DELETE文
delete: 行(タプル)の削除
1 | delete from テーブル名 [where 条件] |
例:
1 | select * from 商品; |
ビュー
create view文
ビュー(view): 仮想的なテーブル(保存されているわけではなく、問い合わせ度にテーブルを作成)
1 | create view ビュー名 [(列名1, ..., 列名m)] as select 文; |
例:
1 | create view 商品一覧(商品番号, 商品名) |
データベースのユーザとアクセス権限
- ユーザ登録
1 | create user u1301 identified by 'password'; |
- 権限の付与と取消
1 | grant 権限p [列名p1 [, 列名p2 ...]] |
SQLによる高度な問合せ
distinct句とorder by句
distinct: 行の重複削除
1 | select distinct 列名1, ..., 列名n from テール名; |
order by: 行の並べ替え
1 | select * from テーブル名 order by 列名 [desc]; |
- desc: 降順(descending)
- asc: 昇順(ascending)
例:
1 | -- 科目名のデータから重複を取り除いて,科目名の一覧を表示 |
複数テーブルからのデータ抽出
テーブルの和(union), 積(intersect), 差(except)
- テーブルの和(union)
1 | -- 学生IDが'701'か'702'の学生が履修している科目名を抽出 |
- テーブルの積(intersect)
1 | select * from R intersect select * from S |
- テーブルの差(except)
1 | select * from R except select * from S |
テーブルの結合
- 内部結合・等結合
1 | -- 直積集合を求めてG.学生ID = S.学生IDの条件で行を選択 |
- 外部結合
1 | -- 左外部結合を求める |
SQLとリレーショナル代数

副問合せ(sub query)
select文中にselect文を入れ子に記述することができる. 入れ子の内側の問合せを副問合せと呼ぶ.
1 | select [列の指定に使用] from [from句に使用] where [where句で使用] |
- where句で使用
- 比較演算子
- in と not in 演算子
- exist と not exist 演算子
- any(some) 演算子
- all 演算子
- from句に使用
- 仮想的なテーブルとして扱うことができる
- 列の指定に使用
where句で使用
- 比較演算子を使って主問合せと連携
1 | select 学生ID, 修得単位数 from 修得単位 |
- in と not in 演算子
1 | select 学生ID, 氏名 from 学生 |
- exist と not exist 演算子
1 | select 学生ID, 氏名 from 学生 as G |
- any(some) 演算子(sqlite未実装)
1 | select 学生ID, 氏名 from 学生 where 学生ID = any(select 学生ID from 履修); |
- all 演算子(sqlite未実装)
1 | select 学生ID, 氏名 from 学生 |
from句に使用
- select文の結果を仮想的なテーブルとして扱うことができる
1 | -- 修得単位数が44以上の学生を検索 |
列の指定に使用
- select文の(1個の)列を指定
1 | select 学生ID, 学年, 修得単位数, (select 氏名 from 学生 as G where G.学生ID=S.学生ID) |
集約関数(aggregate functions)
- count関数
1 | -- 履修テーブルの行数をカウント |
- max, min関数
1 | -- 取得単位数の最大値 |
- avg, stddev, variance関数(stddev, varianceはSQLite未実装)
1 | -- 平均 |
group by句とhaving句
- group by句:テーブルの特定の列で行をグループ化して,個々のグループに対して集約関数を適用
1 | -- 科目名ごとにグループ化して集約関数を適用 |
- having句:集約化された値に対する選択条件を指定
1 | -- having句で集約化された値に対する選択条件を指定 |
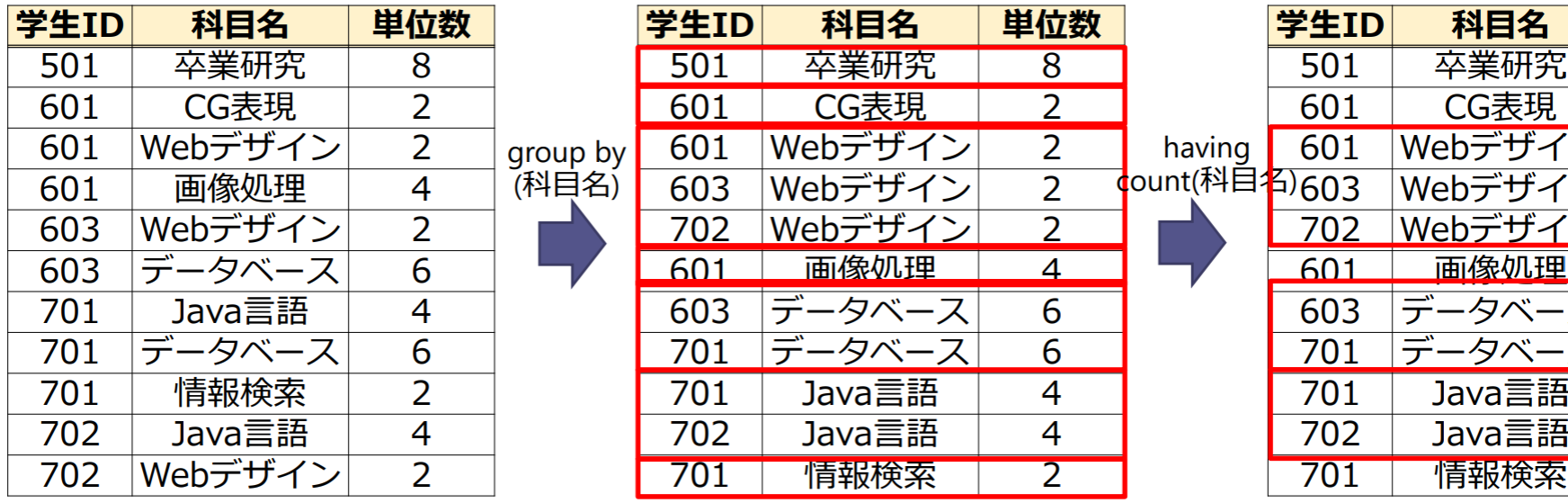
例:
1 | -- 80単位以上を修得した学生と修得単位数の合計を検索 |
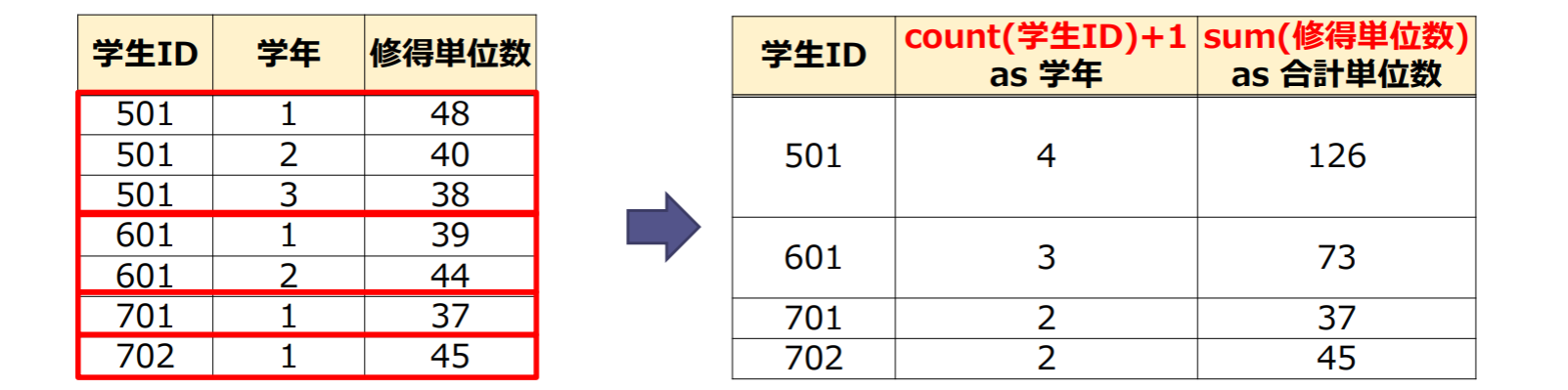
集約関数を含むビュー
ビューの定義に集約関数を含めることができる
1 | create view 合計修得単位 |
トランザクション
-
トランザクション(transaction):データベースの状態を整合性のある状態から,別の整合性のある状態に変化させるデータ操作の並び(データ操作の順番の入れ替えはない)
-
まとめて行わなくてはいけないワンセットの処理のこと
例: 口座aから口座bに10万円を送金する
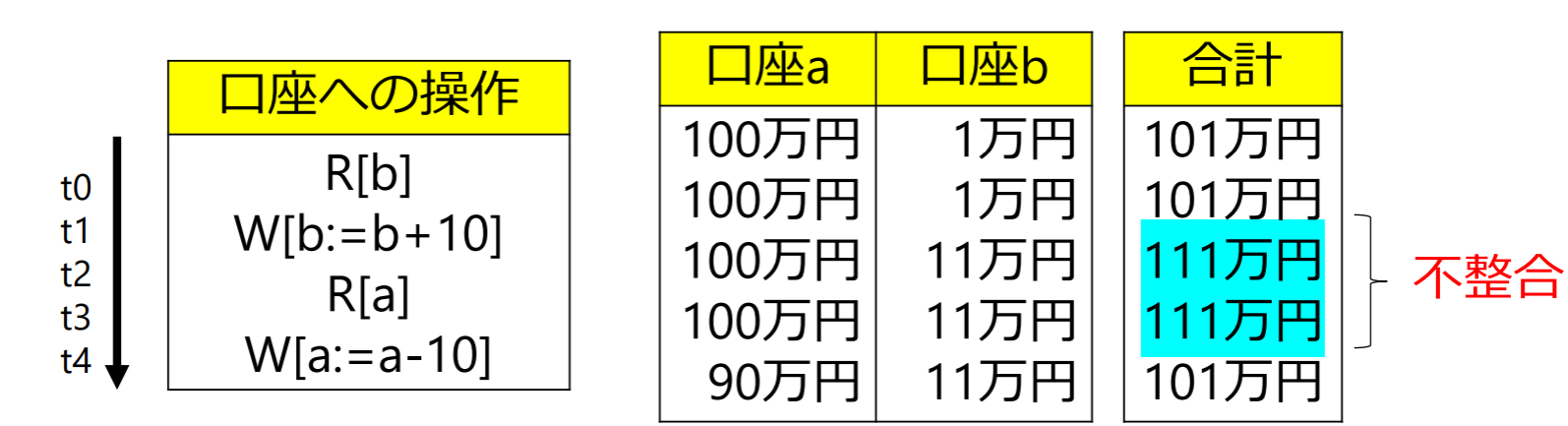
- : 口座bの貯金額を読み出す操作
- : 口座bの預金額に10万円を足す操作
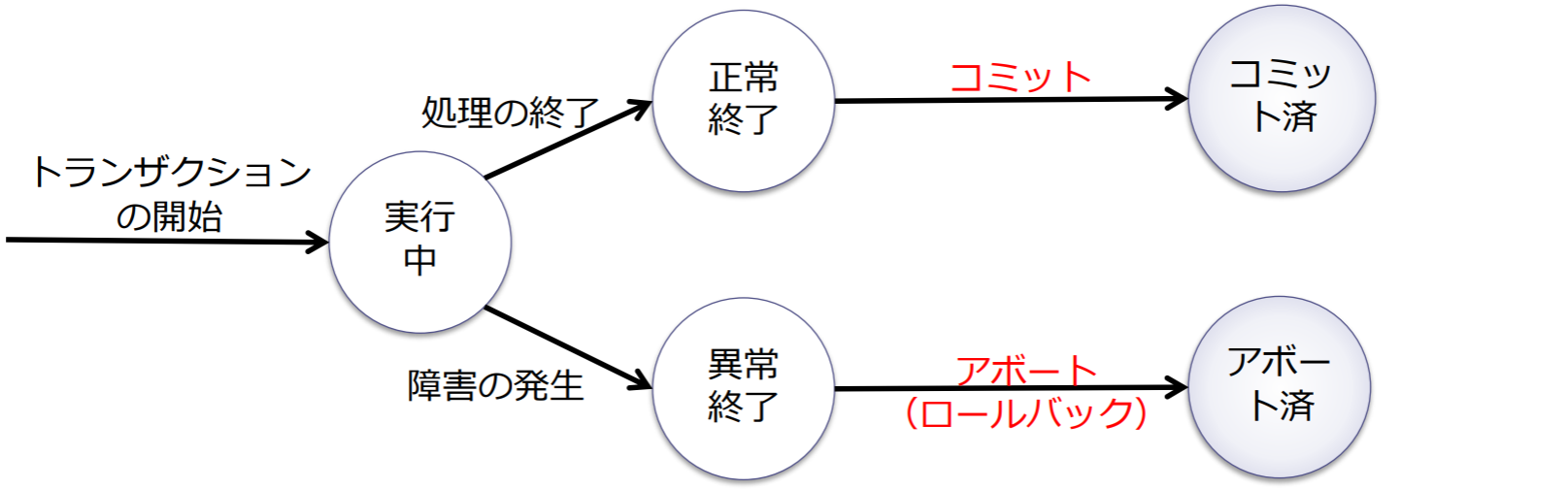
トランザクションの状態遷移
- コミット(commit):正常終了した場合に,すべての更新を確定したものとしてデータベースに反映する処理
- アボート(abort):異常終了した場合に,すべてのデータ操作を取り消して元の状態に戻す処理(ロールバック)
- トランザクションの開始と正常終了(commit)
1 | begin transaction; |
- トランザクションの中止(abort, rollback)
1 | begin transaction; |
正規化
更新時異常
属性間の依存関係を考慮しないでリレーションを適当に設計すると,更新時にどのような問題が発生するか?
更新操作:
- 挿入 (insert)
- 削除 (delete)
- 修正 or 更新 (update)
次の制約を持つ履修登録リレーションを考える
- 各科目は1人あるいは複数の教員が担当
- 1人の学生が同じ科目を複数履修することはない
- 教員は複数の科目を担当できる
- 学生は一つの学科に属し,各学科に学科長は2人
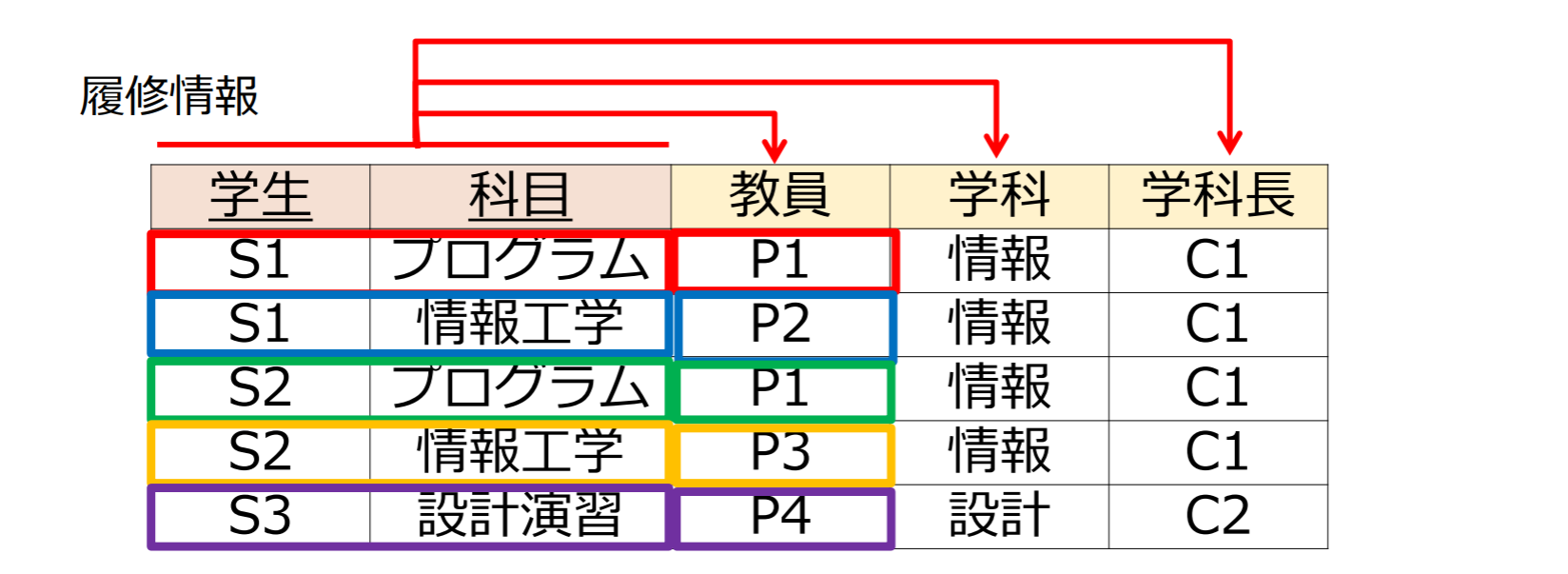
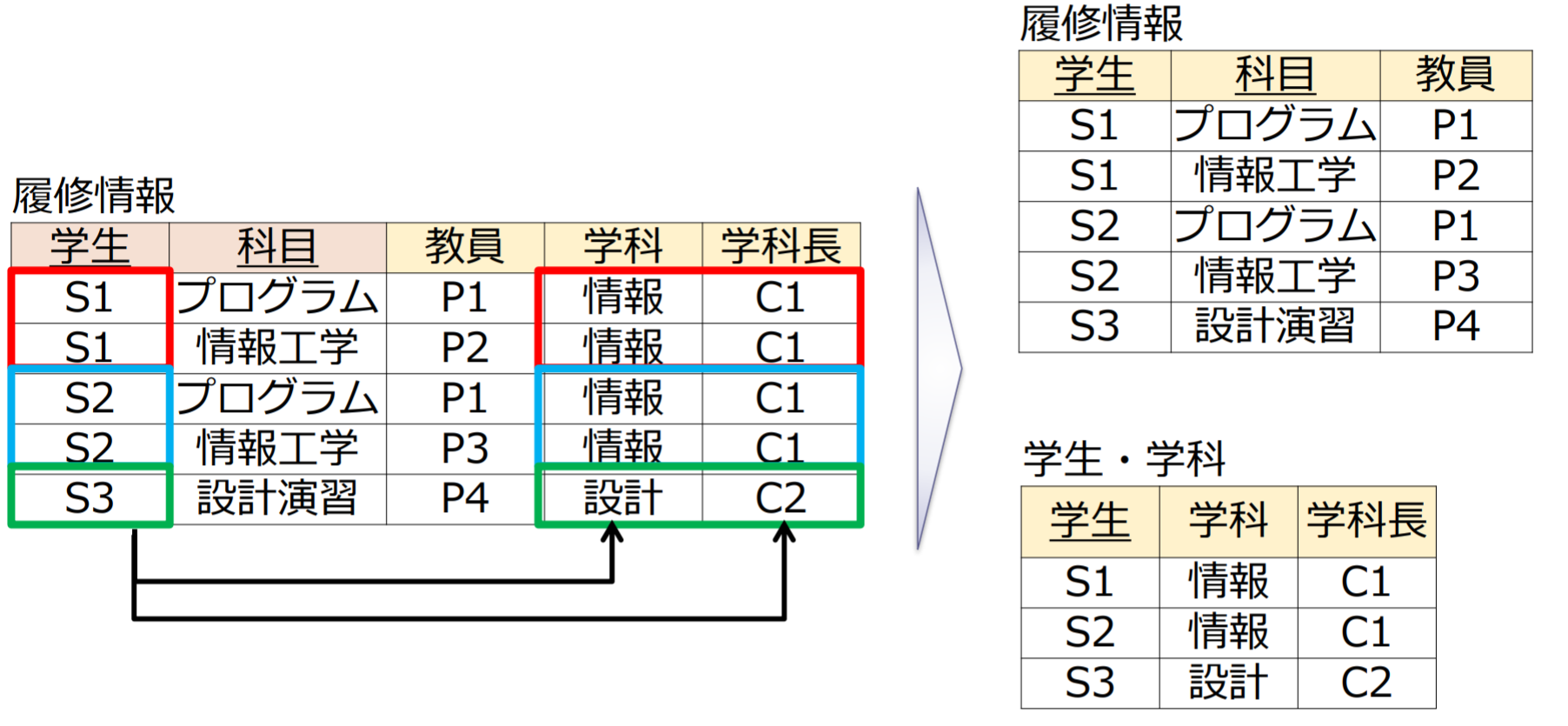
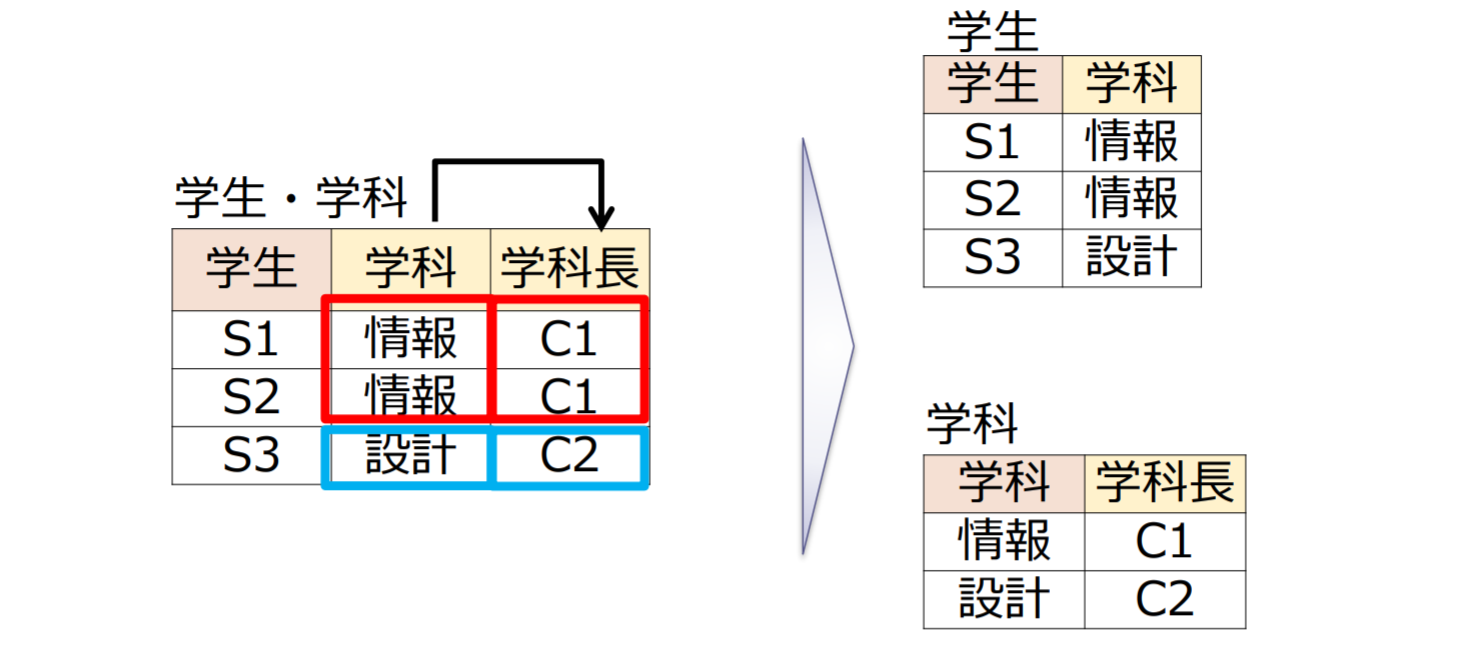
履修情報
| 学生 | 科目 | 教員 | 学科 | 学科長 |
|---|---|---|---|---|
| S1 | プログラム | P1 | 情報 | C1 |
| S1 | 情報工学 | P2 | 情報 | C1 |
| S2 | プログラム | P1 | 情報 | C1 |
| S2 | 情報工学 | P3 | 情報 | C1 |
| S3 | 設計演習 | P4 | 設計 | C2 |
- 複合主キー: 学生, 科目
挿入時異常(insertion anomaly)
- 新たな学生S4が学科設計に加わった場合
履修情報
| 学生 | 科目 | 教員 | 学科 | 学科長 |
|---|---|---|---|---|
| S1 | プログラム | P1 | 情報 | C1 |
| S1 | 情報工学 | P2 | 情報 | C1 |
| S2 | プログラム | P1 | 情報 | C1 |
| S2 | 情報工学 | P3 | 情報 | C1 |
| S3 | 設計演習 | P4 | 設計 | C2 |
| S4 | NULL | NULL | 設計 | C2 |
キー制約違反: 履修する科目が決まるまで新規学生を追加できない
削除時異常(deletion anomaly)
- 学生S3が科目設計演習を取り消した場合
履修情報
| 学生 | 科目 | 教員 | 学科 | 学科長 |
|---|---|---|---|---|
| S1 | プログラム | P1 | 情報 | C1 |
| S1 | 情報工学 | P2 | 情報 | C1 |
| S2 | プログラム | P1 | 情報 | C1 |
| S2 | 情報工学 | P3 | 情報 | C1 |
タプルを削除すると学生 S3 がいないことになる
修正時異常(update anomaly)
- 学生S1の学科が情報から設計に変更になった場合
履修情報
| 学生 | 科目 | 教員 | 学科 | 学科長 |
|---|---|---|---|---|
| S1 | プログラム | P1 | 設計 | C1 |
| S1 | 情報工学 | P2 | 情報 | C1 |
| S2 | プログラム | P1 | 情報 | C1 |
| S2 | 情報工学 | P3 | 情報 | C1 |
| S3 | 設計演習 | P4 | 設計 | C2 |
学生S1所属している学科は矛盾!
更新時異常を回避
- リレーションを分解することで冗長性を取り除く
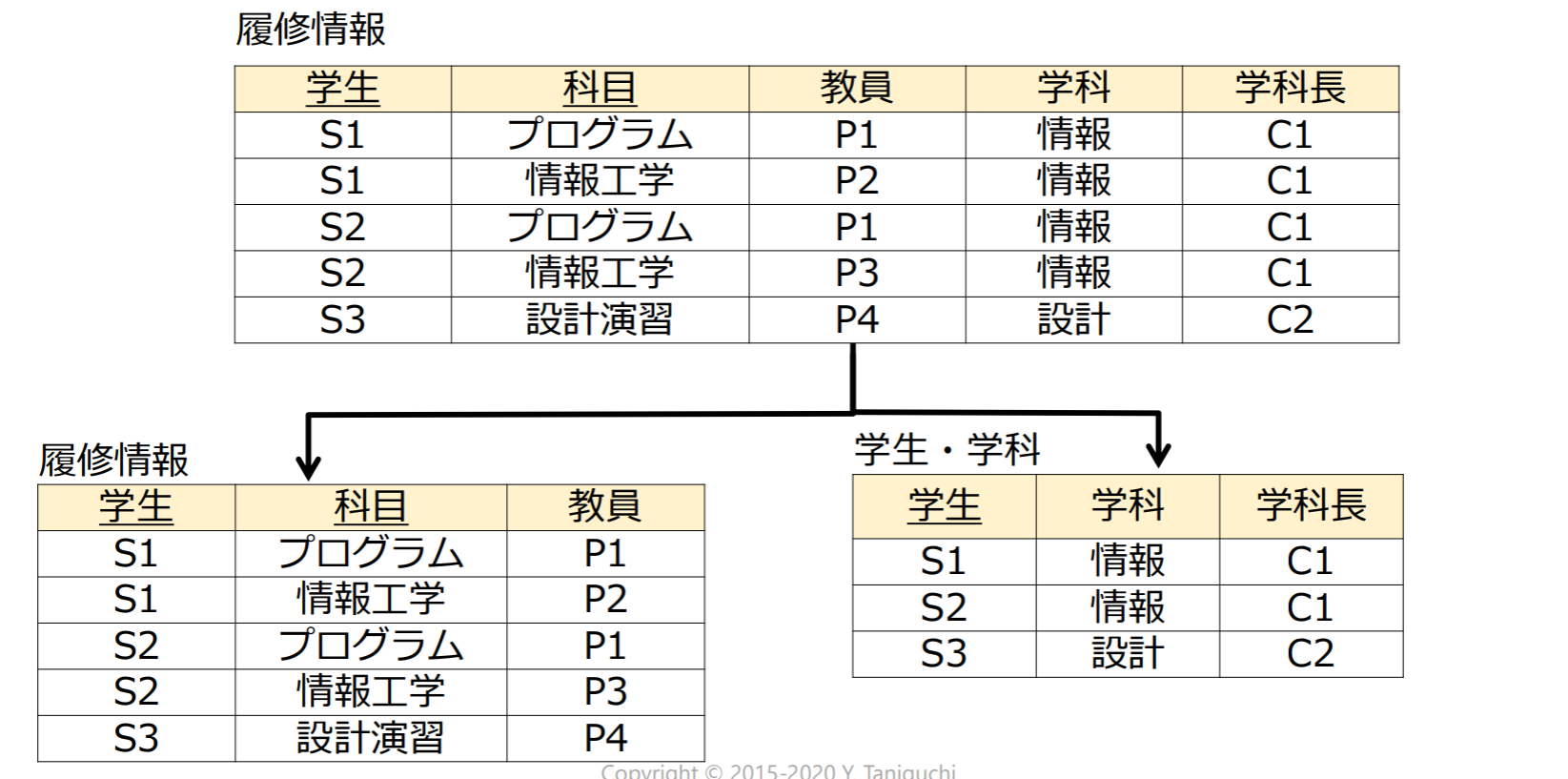
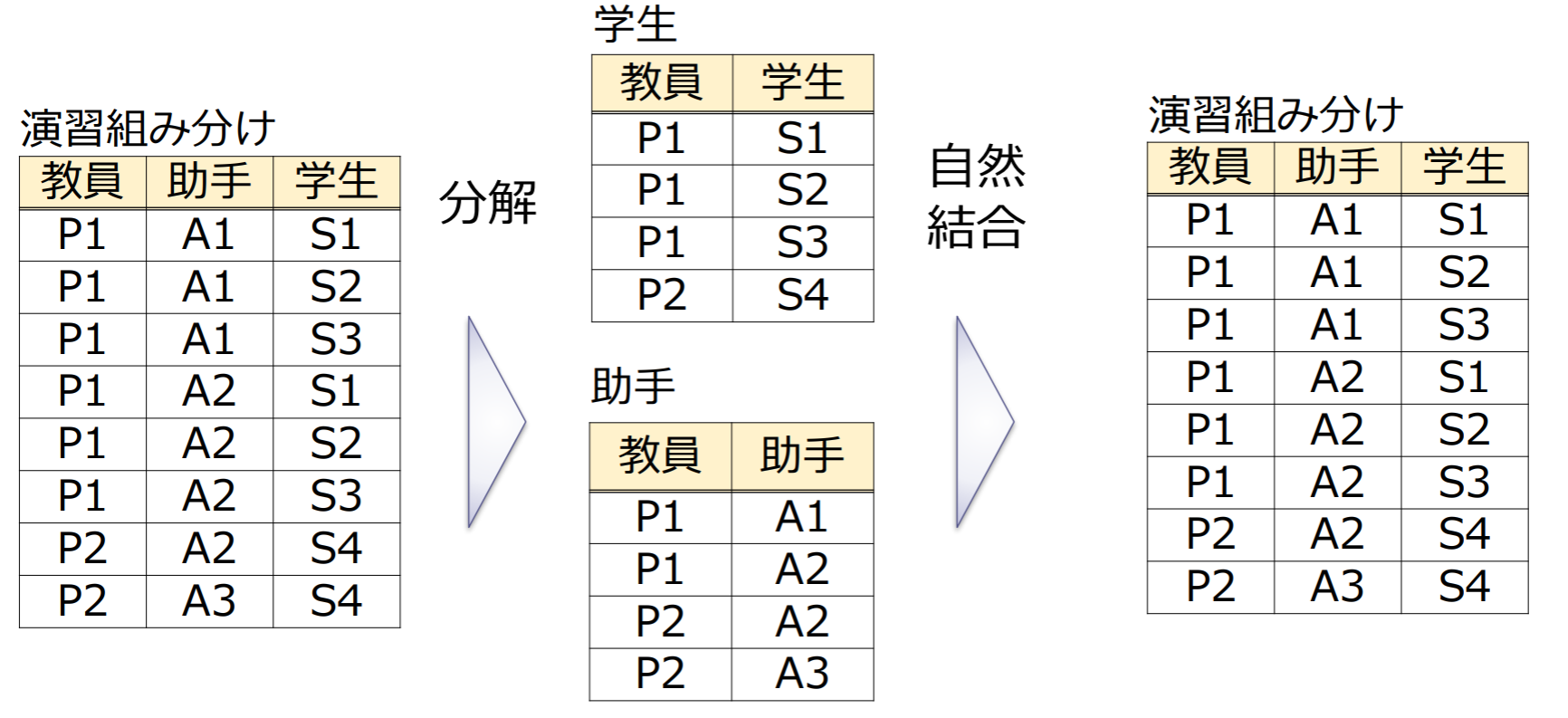
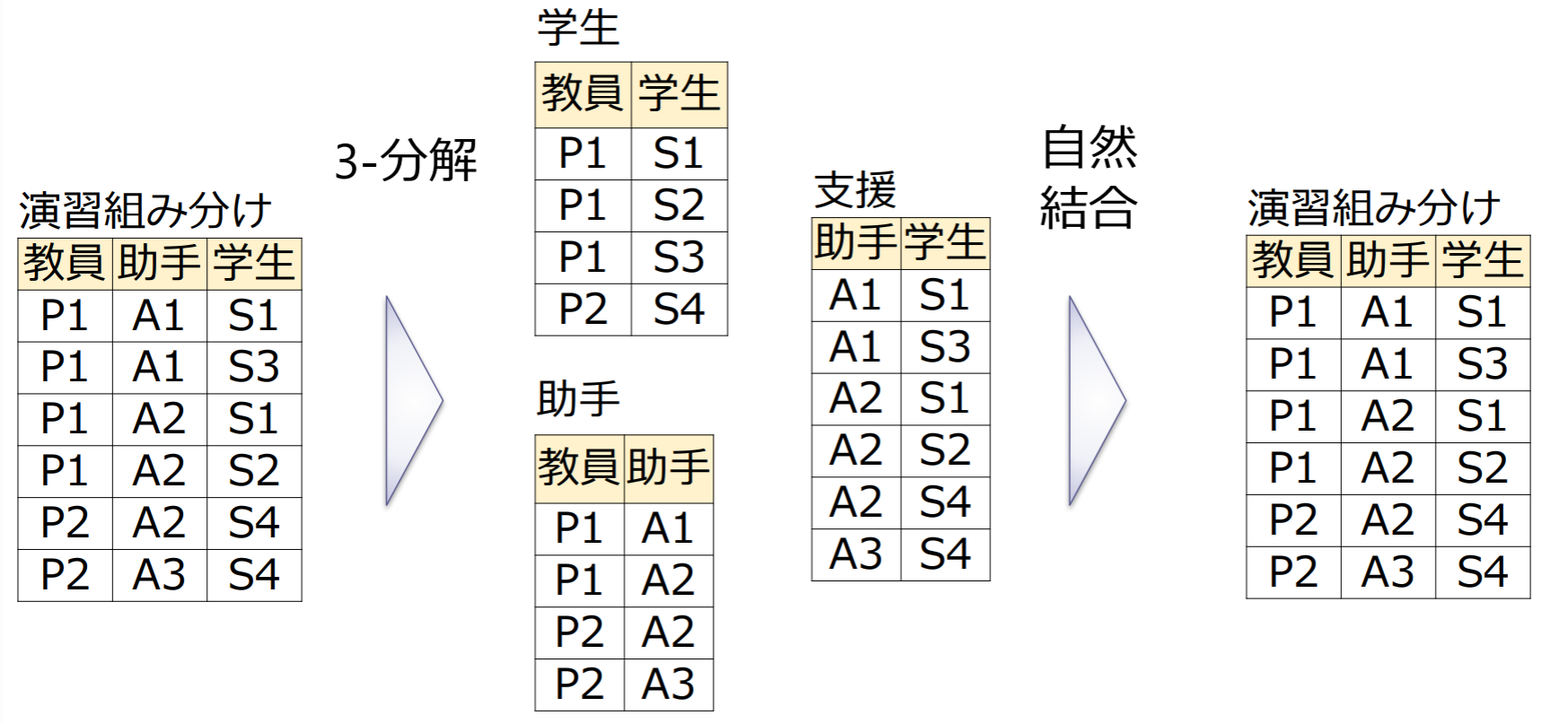
情報無損失分解
情報無損失分解:自然結合で復元可能な分解
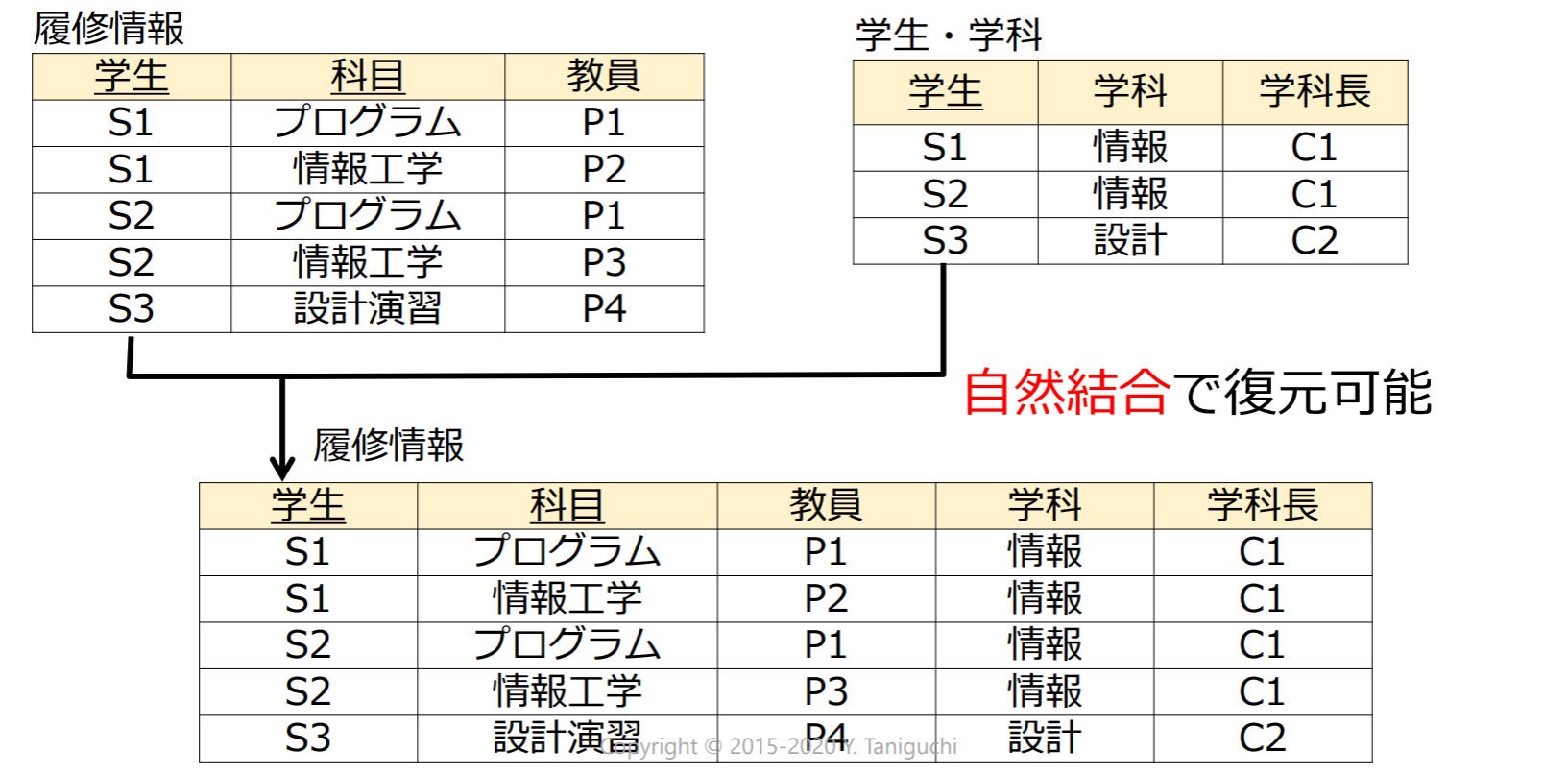
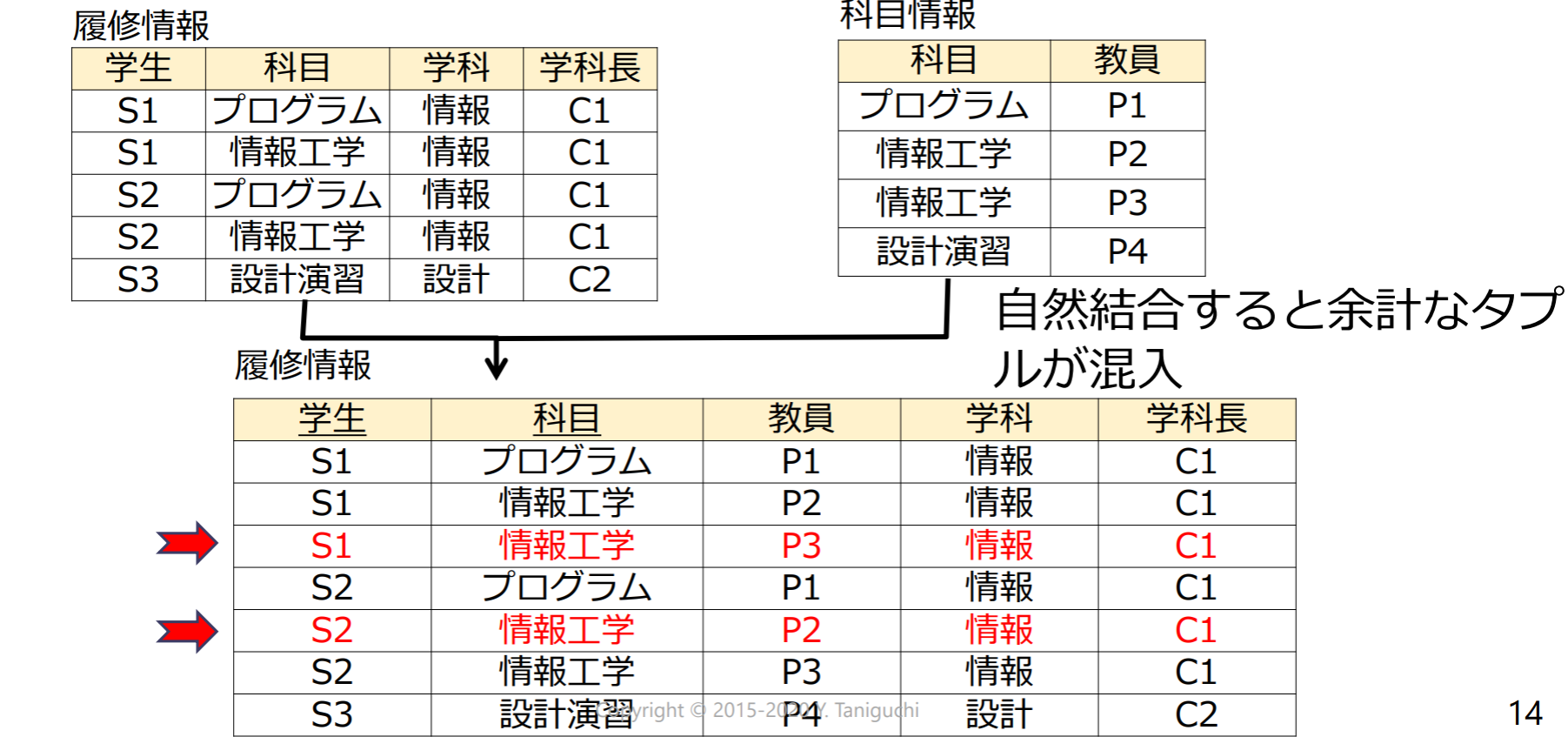
結合の罠(connection trap)
どんな分解でも情報無損失分解になるわけではない
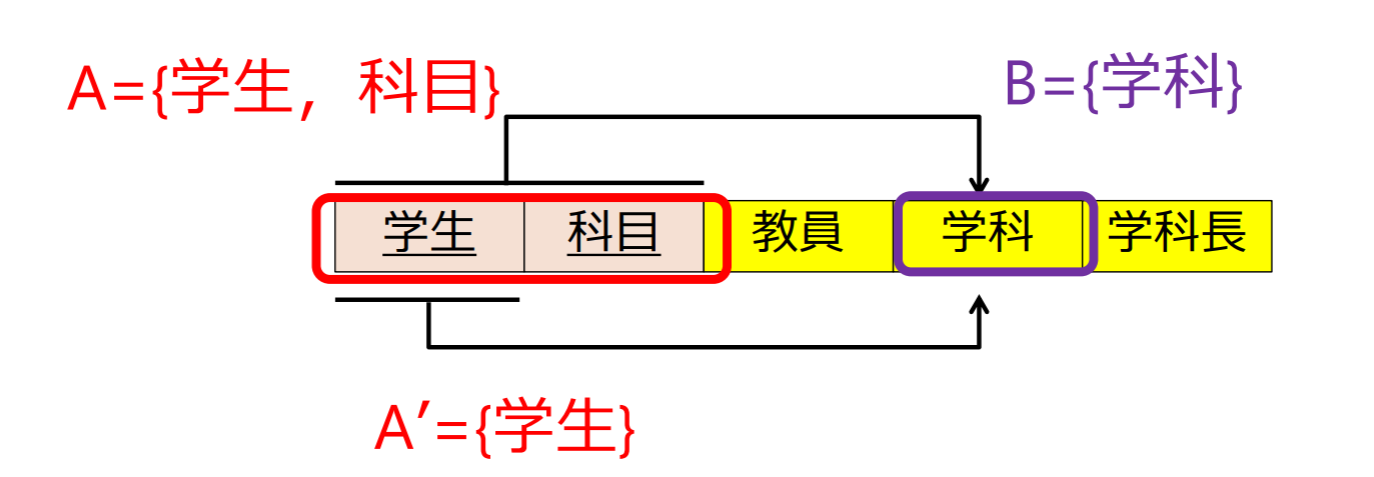
関数従属性(FD)
関数従属性(functional dependency, FD)の定義: 関数従属性が成立
- リレーションスキーマの任意のタプルにおいて,属性集合の値が等しければ属性集合の値が等しいという制約が成り立つこと
- A: 決定項(determinant), B: 被決定項(resultant)とよぶ.
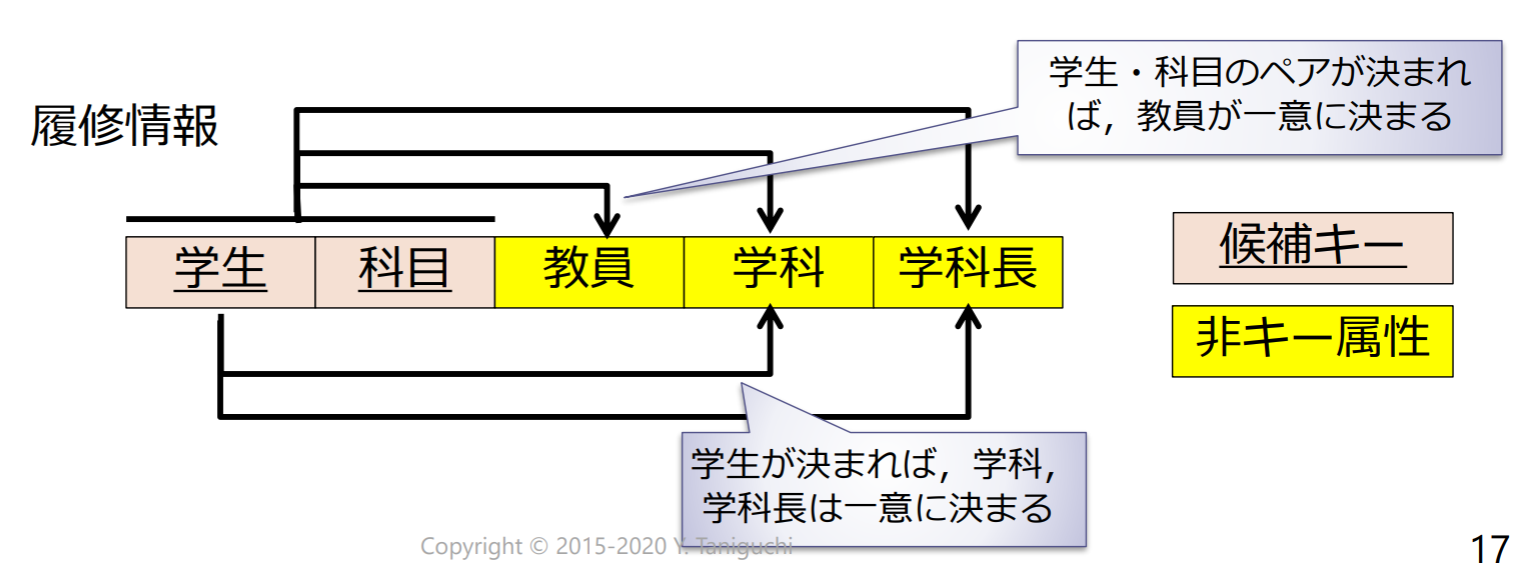
関数従属性の例:
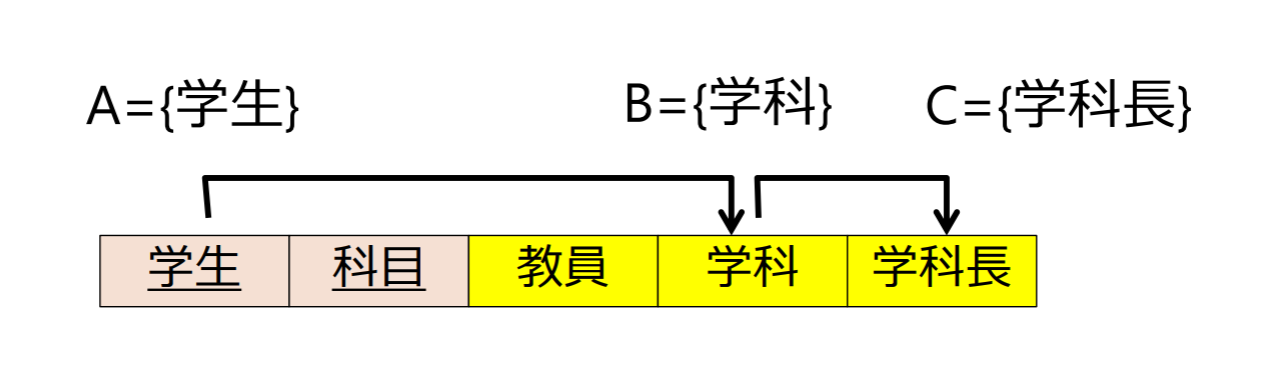
関数従属性 {学生}{学科}, {学生}{学科長} が成り立つ
- 学生は一つの学科に所属するという制約があるから
{学生}{教員}の関数従属性は成立しない
- 学生が決まっても,履修する科目によって教員が変わるから
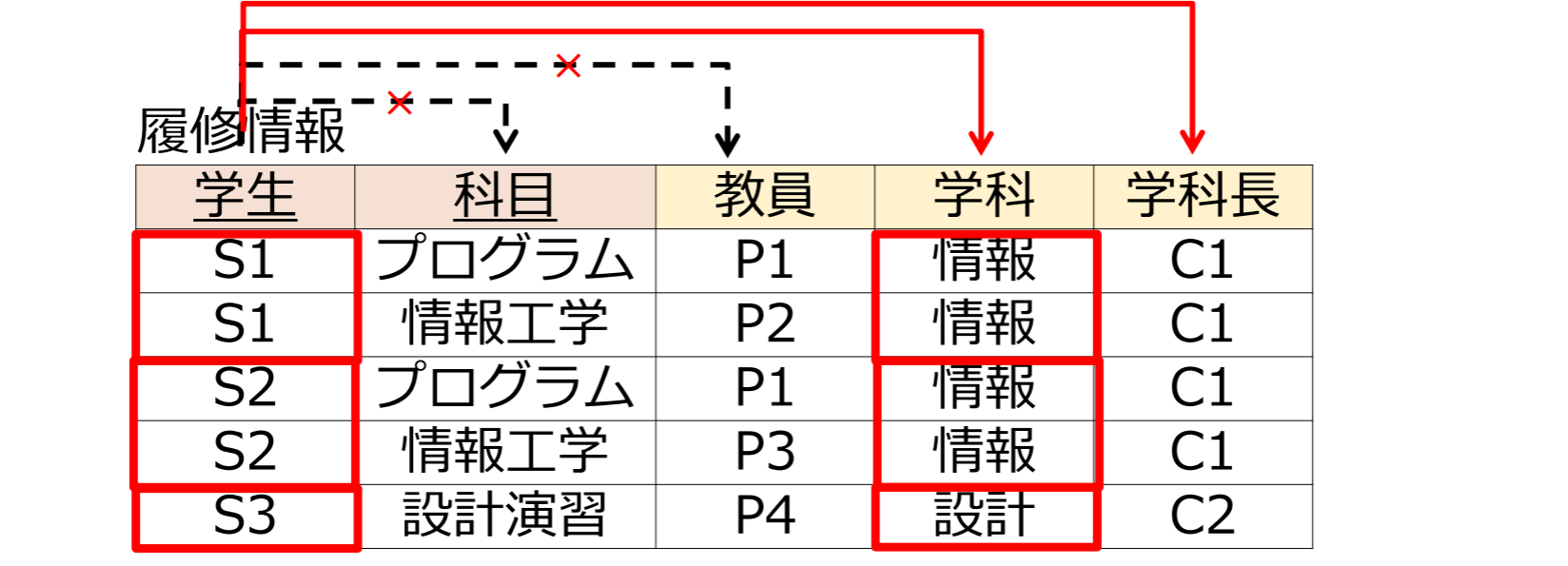
関数従属性 {学生,科目}{教員} が成り立つ
- {学生,科目}は主キー.同じ値を持つタプルは唯一.
- {学生,科目}{学科}, {学生,科目}{学科長}, {学生,科目}{教員,学科}等も従属
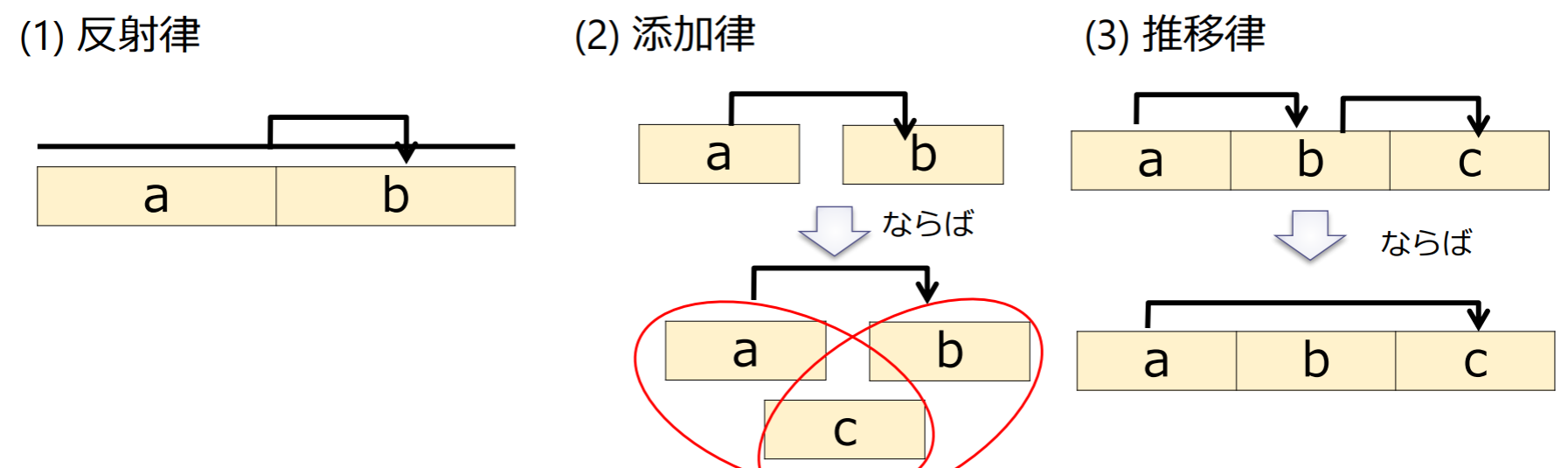
アームストロングの公理系 (Armstrong’s axioms)
関数従属性では以下の公理系が成立
- 反射律:BがAの部分集合であるならば,
- 添加律: ならば
- 推移律:かつならば,
自明な関数従属性(trivial functional dependency)
被決定項が決定項の部分集合である場合(必ず関数従属する)
推移的関数従属性 (transitive functional dependency)
かつならば,が成立すると,CはAに推移的に関数従属するという.
完全関数従属性(full functional dependency)
関数従属性で,Aの任意の真部分集合について,関数従属性が成立しないとき,完全関数従属性が成り立つという
の真部分集合について が成立するので,は完全関数従属ではない
例
- は関数従属性が成立するが,完全関数従属ではない
- だから
- は関数従属性が成立し,かつ,完全関数従属性が成立
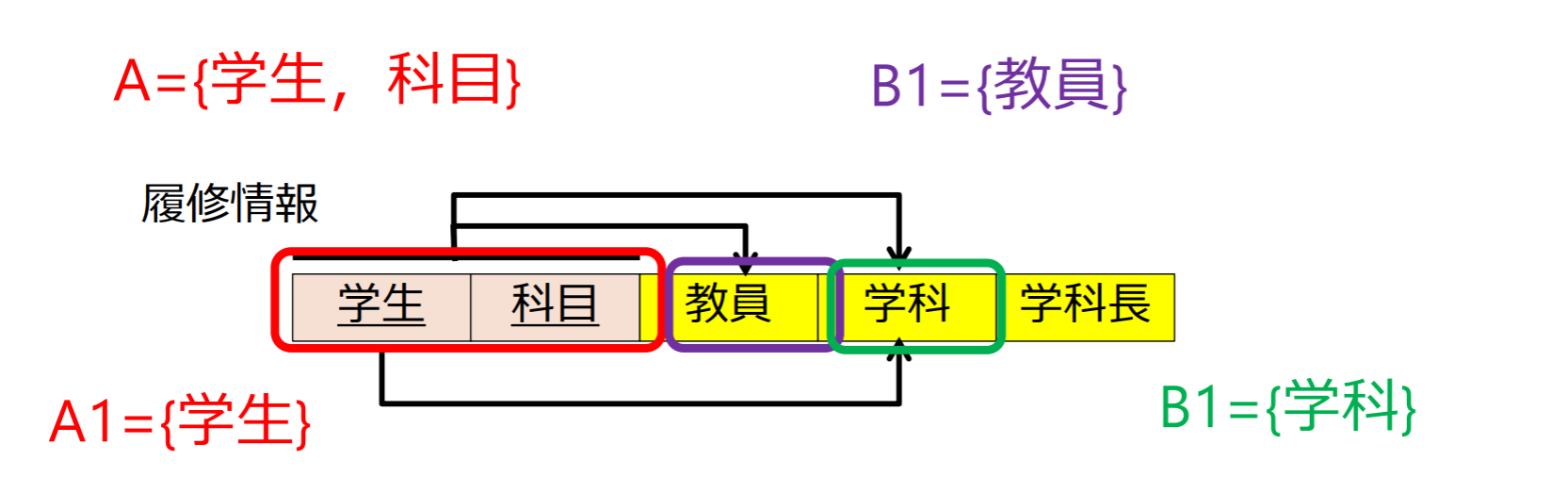
注意: B2 = {教員}
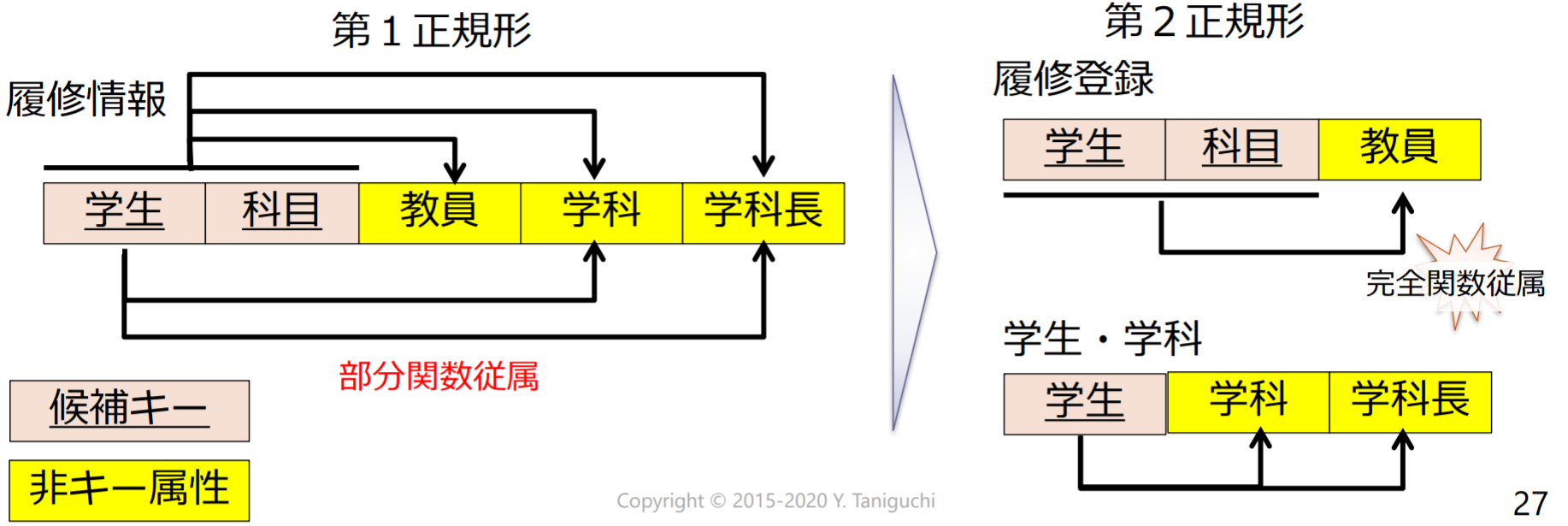
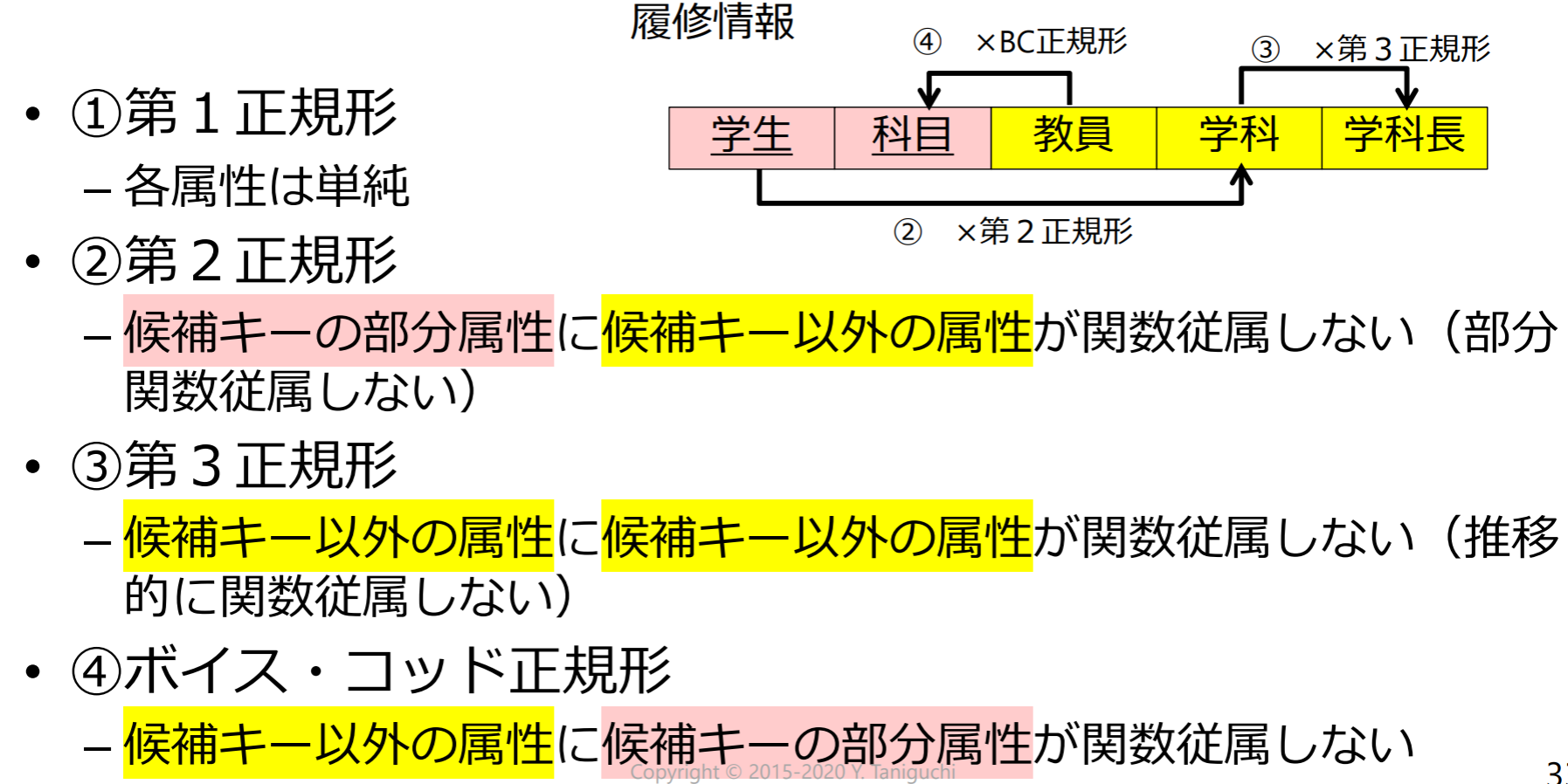
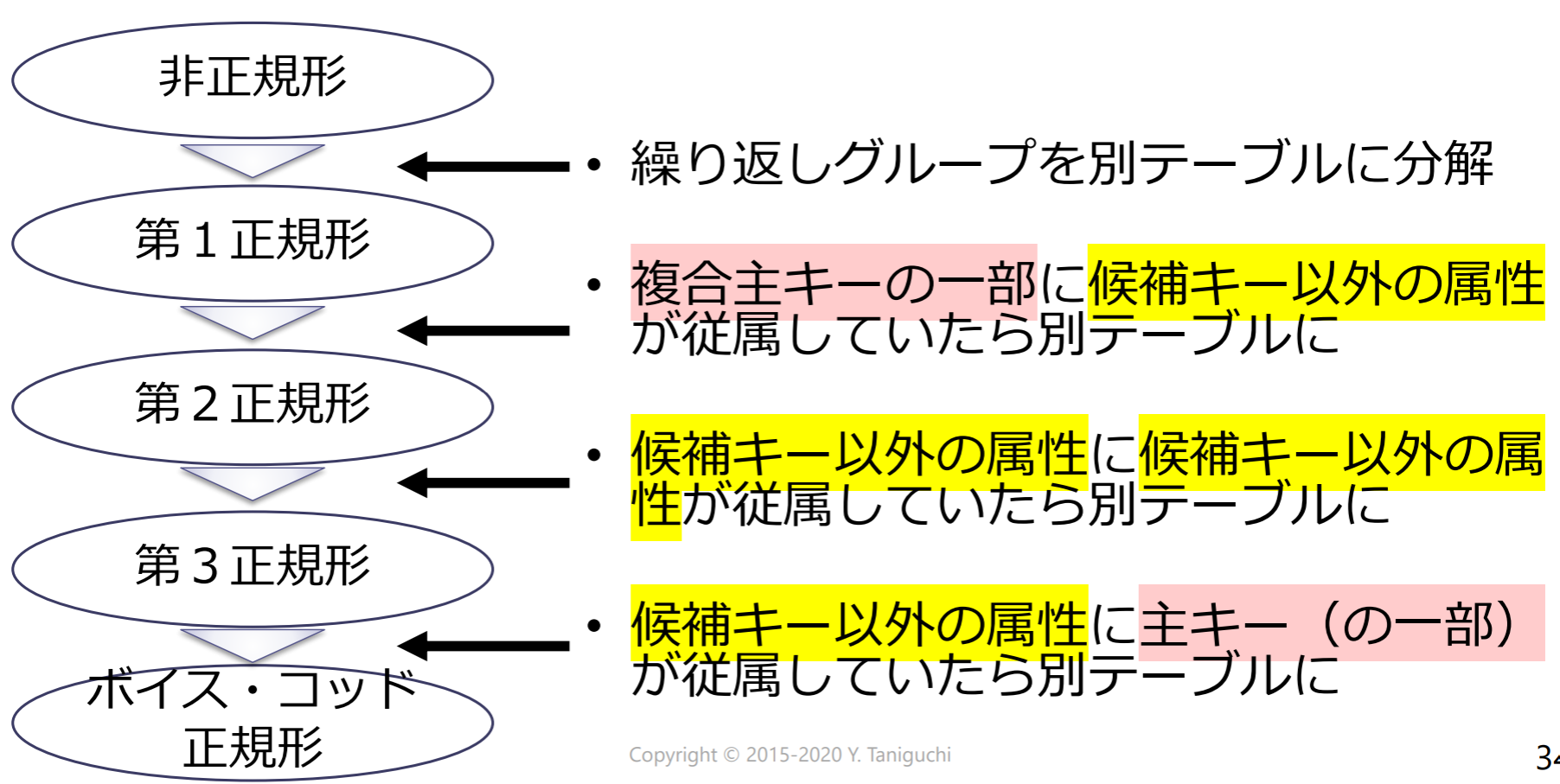
第2正規形(second normal form, 2NF)
リレーションスキーマRにおいて以下の2つの条件が成り立つ場合にRは第2正規形である.
- Rは第1正規形である
- すべての非キー属性は各候補キーに完全関数従属している.(部分関数従属しない)
- 部分関数従属: 候補キーの真部分集合に関数従属する非キー属性が存在
第二范式(2NF):候选键完全决定每一个非主属性
第3正規形(third normal form, 3NF)
リレーションスキーマRにおいて,以下の2つの条件が成り立つ場合にRは第3正規形である.
- Rは第2正規形である
- すべての非キー属性はどの候補キーにも推移的に関数従属しない
- 言い換えれば,非キー属性に従属する非キー属性が存在しない
第三范式(3NF):没有传递函数依赖
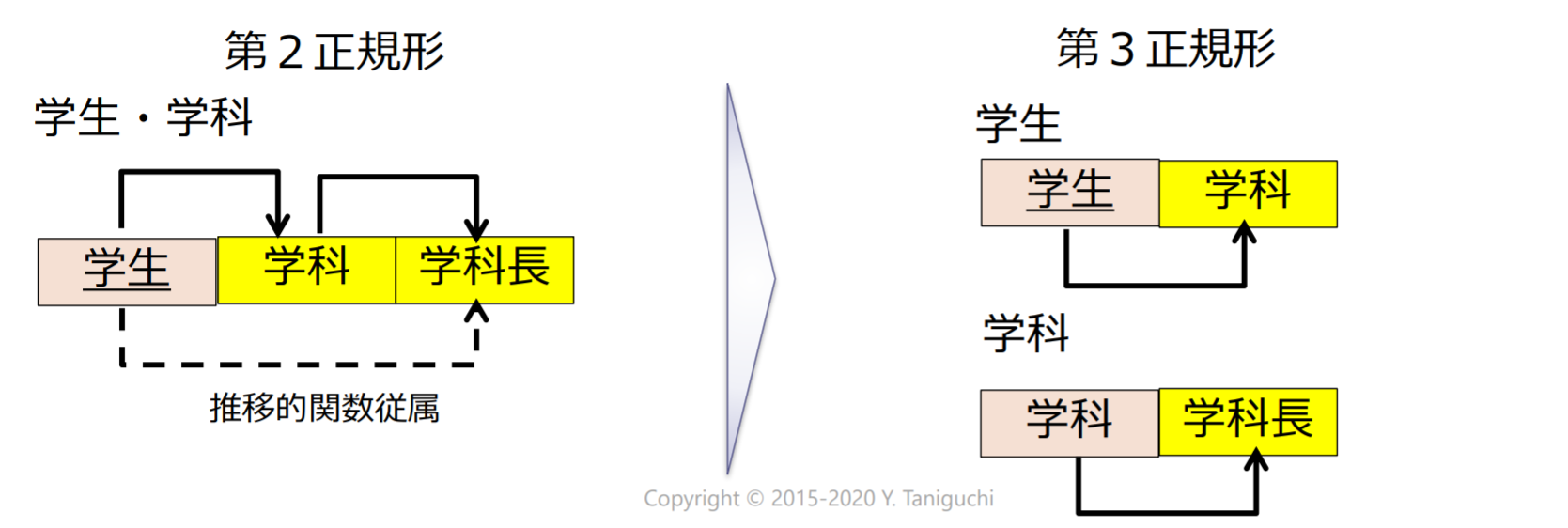
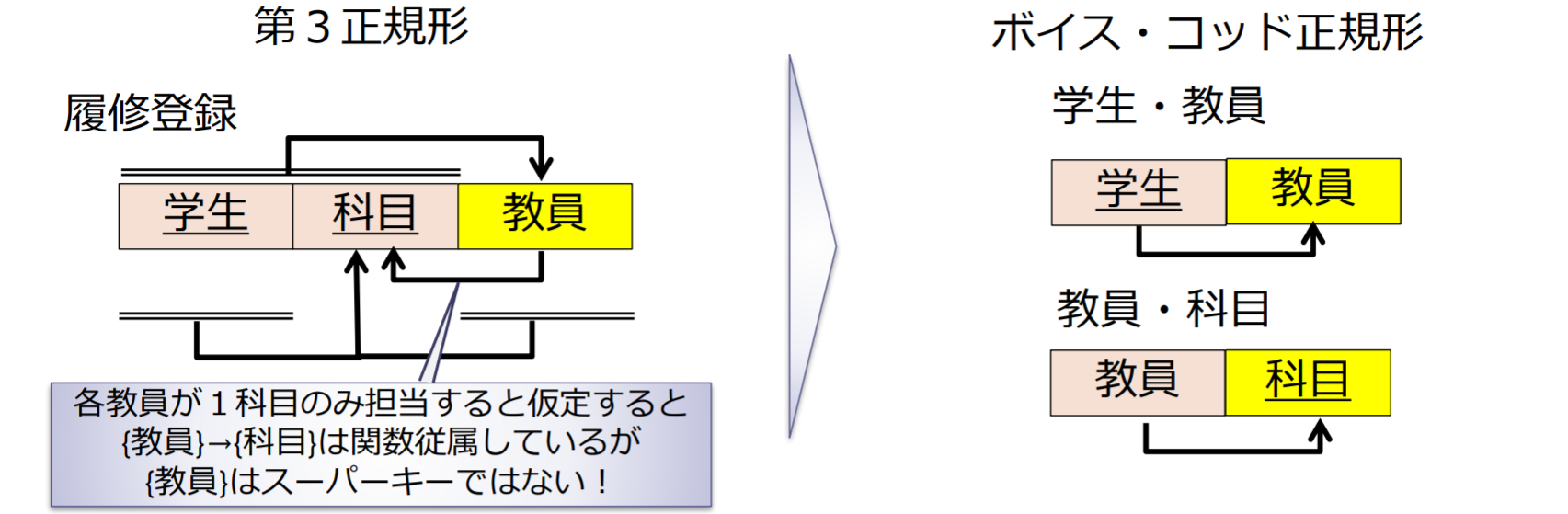
ボイス・コッド正規形(Boyce-Codd normal form, BCNF)
リレーションスキーマRのすべての関数従属性において,以下のいずれかが成り立つ場合にRはボイス・コッド正規形である
- は自明な関数従属性である
- AがRのスーパーキーである
BCNF:没有不依赖于候选键的函数依赖存在
- (城市,街道,邮政编码)
- (城市,街道)-> 邮政编码
- 邮政编码 -> 城市
課題7.1
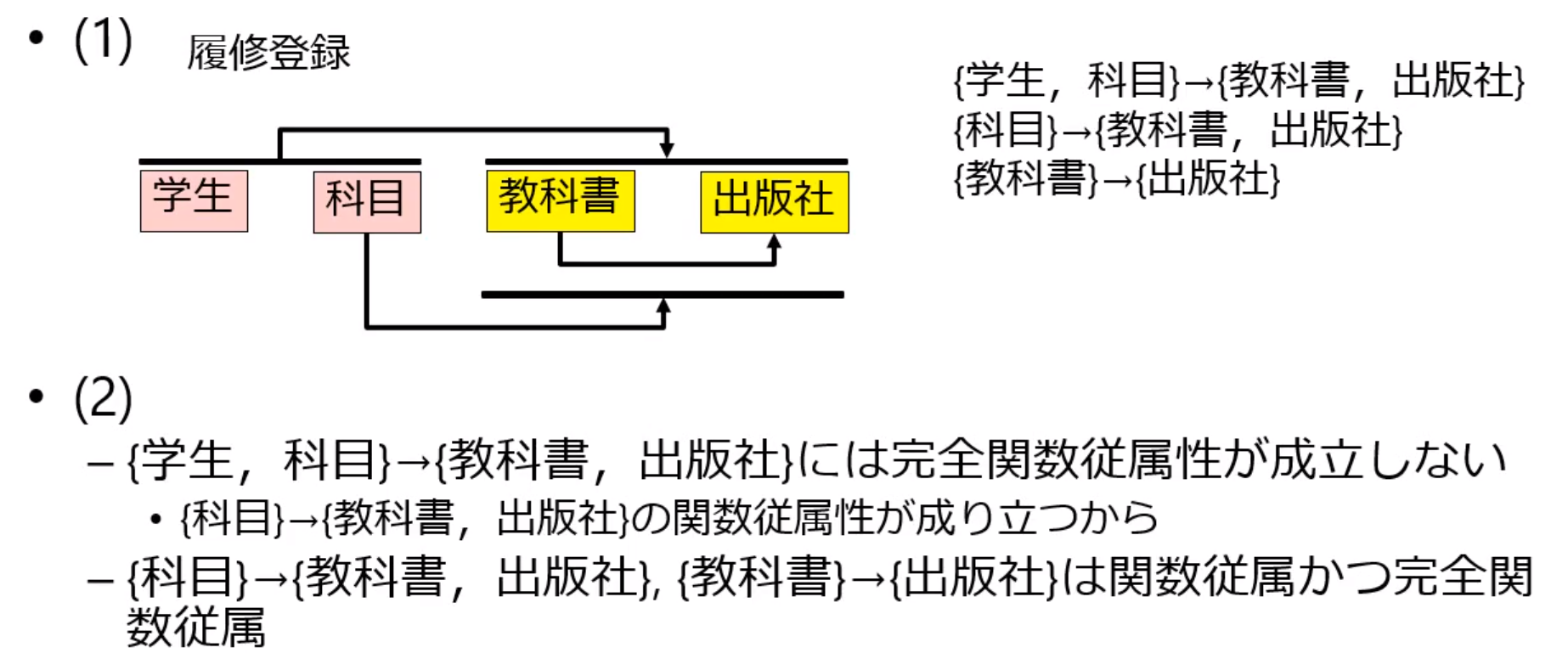
学生の履修登録に関するリレーションスキーマ 履修登録(学生,科目,教科書,出版社)があり,以下の制約があるものとする.このときに以下の問いに答えよ.
- 学生は任意の科目を履修できる
- 科目毎に1冊の教科書が指定されている.ただし,科目が異なっても教科書が異なるとは限らない
- 教科書は出版社をもつ.ただし,教科書が異なっても出版社が異なるとは限らない
関数従属性
(1) リレーションスキーマ履修登録(学生,科目,教科書,出版社)の持つ関数従属性を示せ.ただし,自明な関数従属性は除くものとする.また,1つの決定項に対して被決定項が複数存在する場合には,1つの関数従属性としてよい.
(2) 上記で列挙した関数従属性のうち,完全関数従属性が成立しないものを挙げなさい
正規化
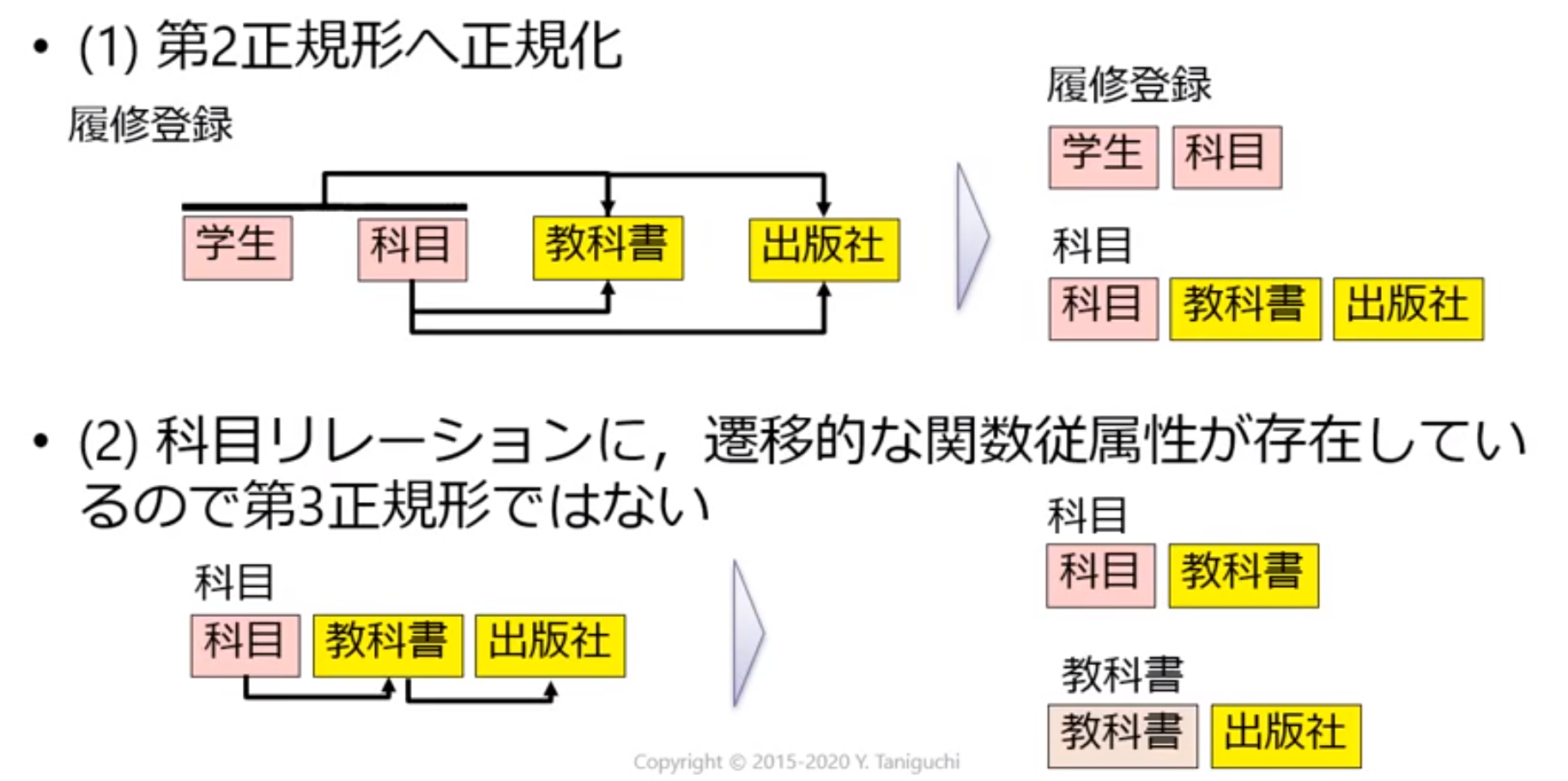
(1) このリレーションを第2正規形に正規化したリレーションを示せ
(2) (1)で作成したリレーションが第3正規形になっているか確認し,なっていない場合には第3正規形に正規化せよ
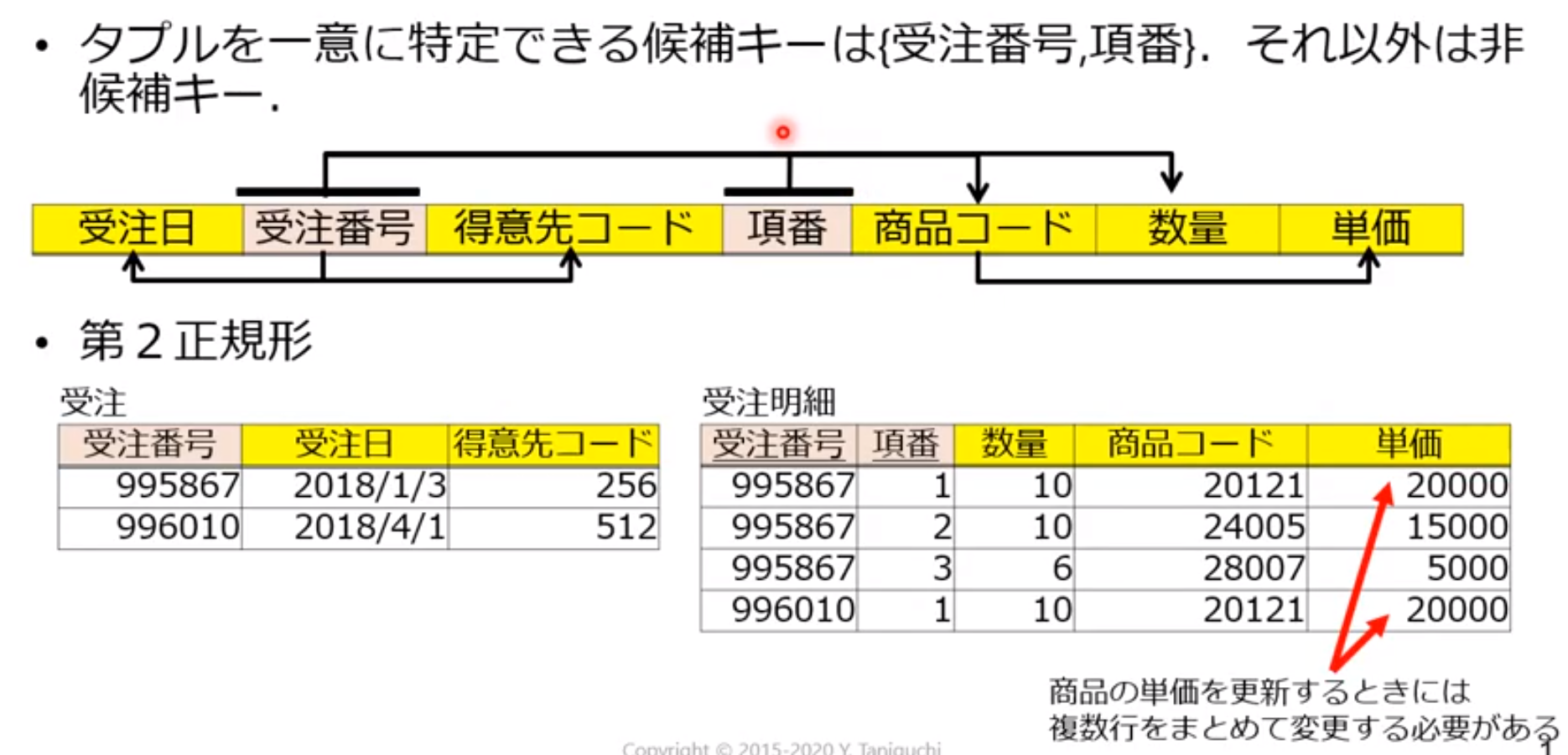
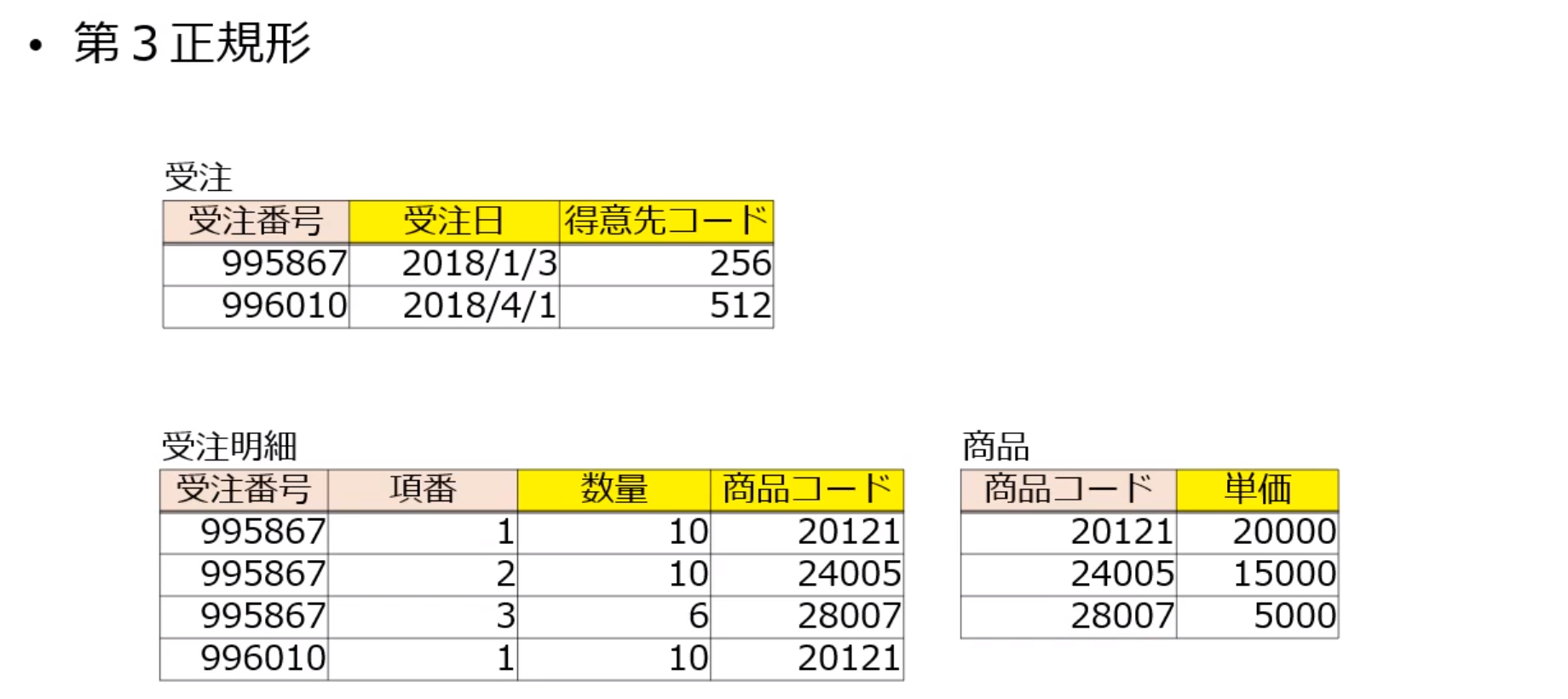
以下の受注票リレーションを第3正規形まで正規化しなさい.
- 受注番号は受注毎に新たに発行される番号であり,
- 項番は1回の受注で商品コード別に連番で発行される番号である.
- なお,単価は商品コードによって一意に定まる
| 受注日 | 受注番号 | 得意先コード | 項番 | 商品コード | 数量 | 単価 |
|---|---|---|---|---|---|---|
| 2018/1/3 | 995867 | 256 | 1 | 20121 | 10 | 20000 |
| 2018/1/3 | 995867 | 256 | 2 | 24005 | 10 | 15000 |
| 2018/1/3 | 995867 | 256 | 3 | 28007 | 6 | 5000 |
| 2018/4/1 | 996010 | 512 | 1 | 20121 | 10 | 20000 |
多値従属性(MVD)
リレーションスキーマ R(A, B, C)においてA, B, CをRの属性集合の部分集合とする.
- Bの値がAの値のみに依存し
- Cの値から独立しているとき
多値従属性 が成り立つという.
- 「候補キーのみ」からなるリレーションRが対象
- 関数従属性の一般化

多値従属性の性質
- 多値従属性が成り立つための必要十分条件は, が成り立つことである.
- と表記する.
- が射影 に情報無損失分解されるための必要十分条件は, 多値従属性が存在することである.
- 関数従属性 が成り立つならば, 多値従属性 が成り立つ.
を自明な多値従属性という
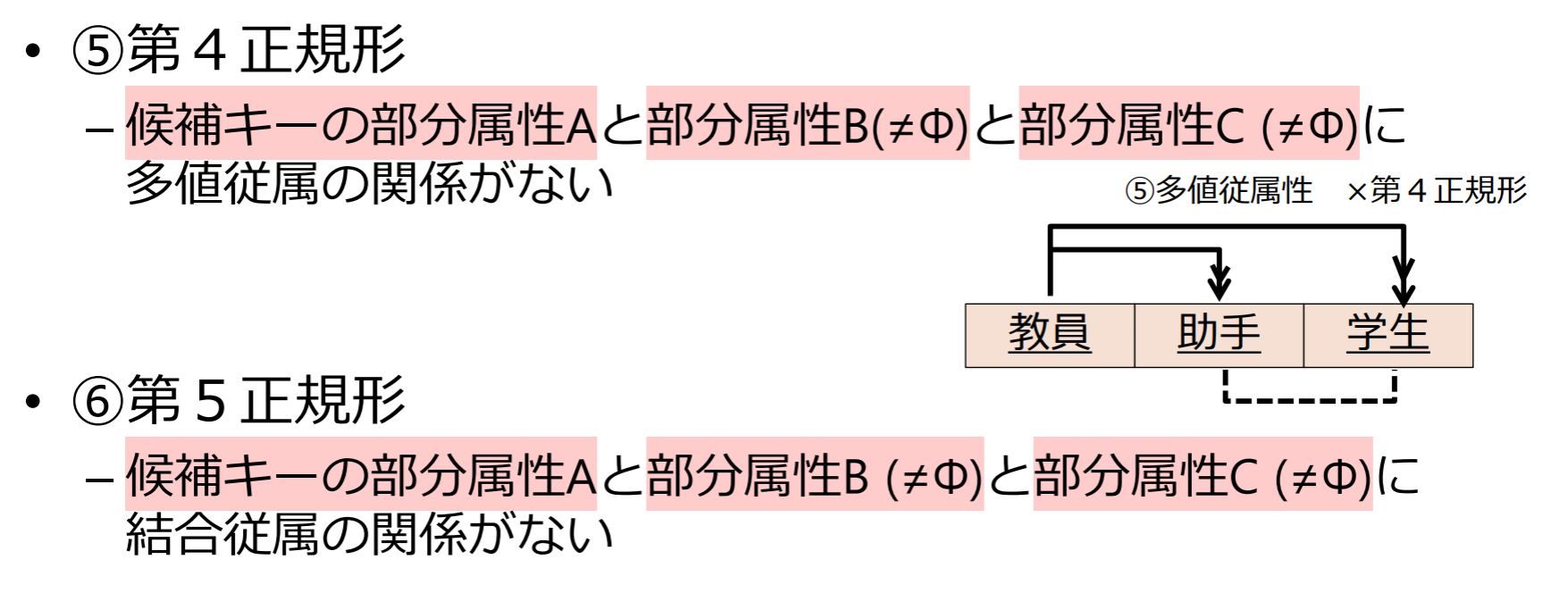
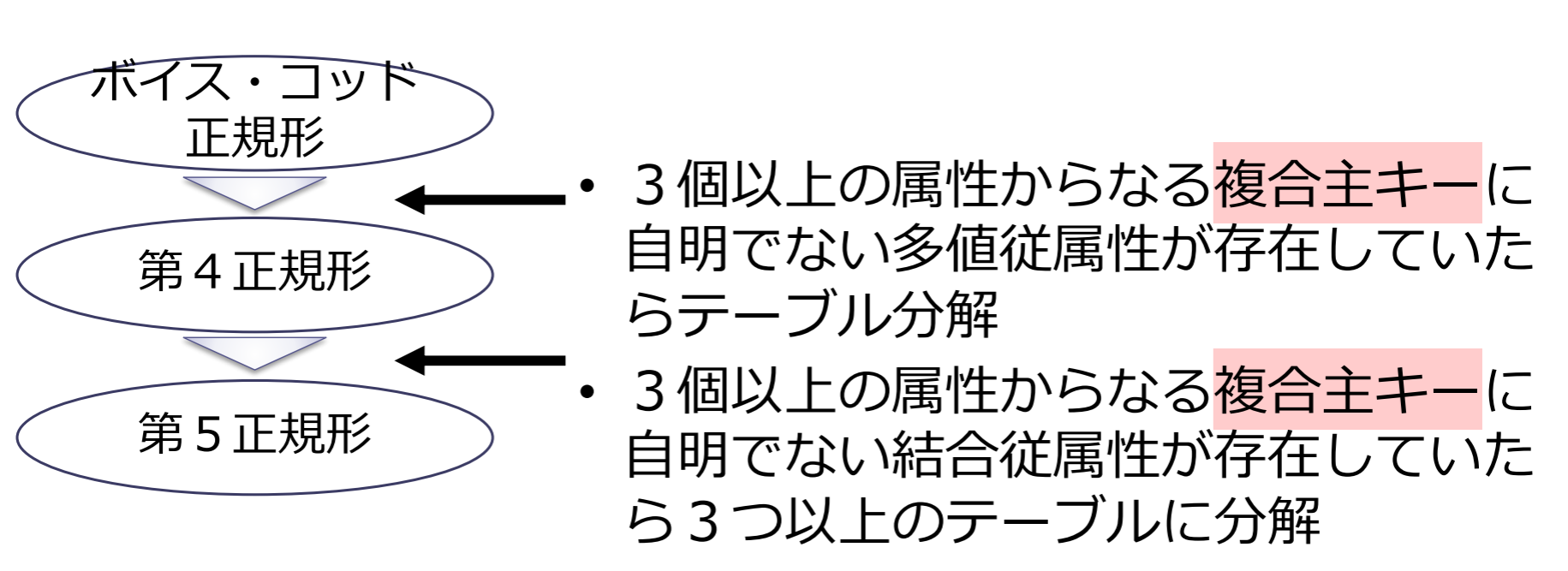
第4正規形
リレーションスキーマ のすべての多値従属性 において, 以下のいずれかが成り立つ場合に は第4正規形であるという.
- は自明な多値従属性である
- が のスーパーキーである
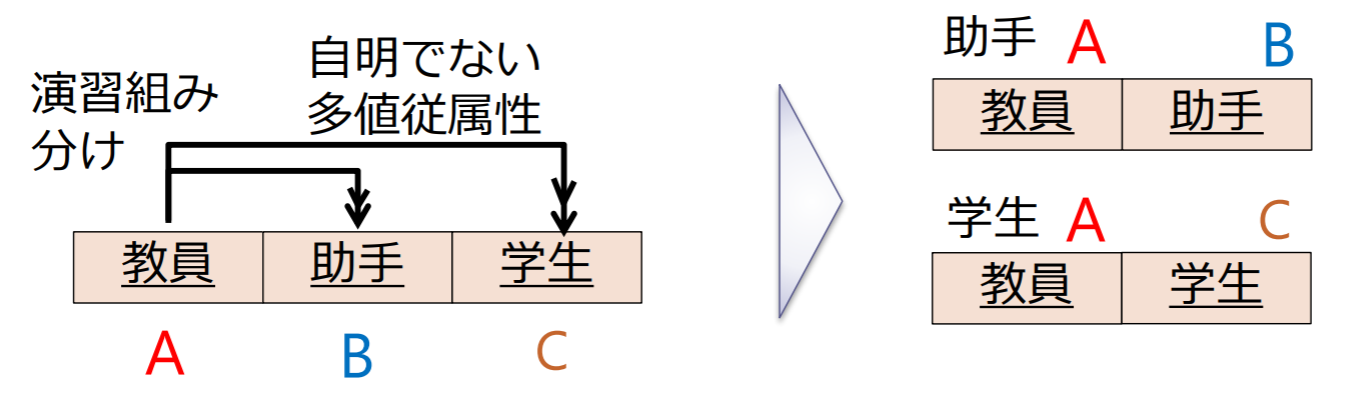
2つのリレーションに情報無損失分解が可能:
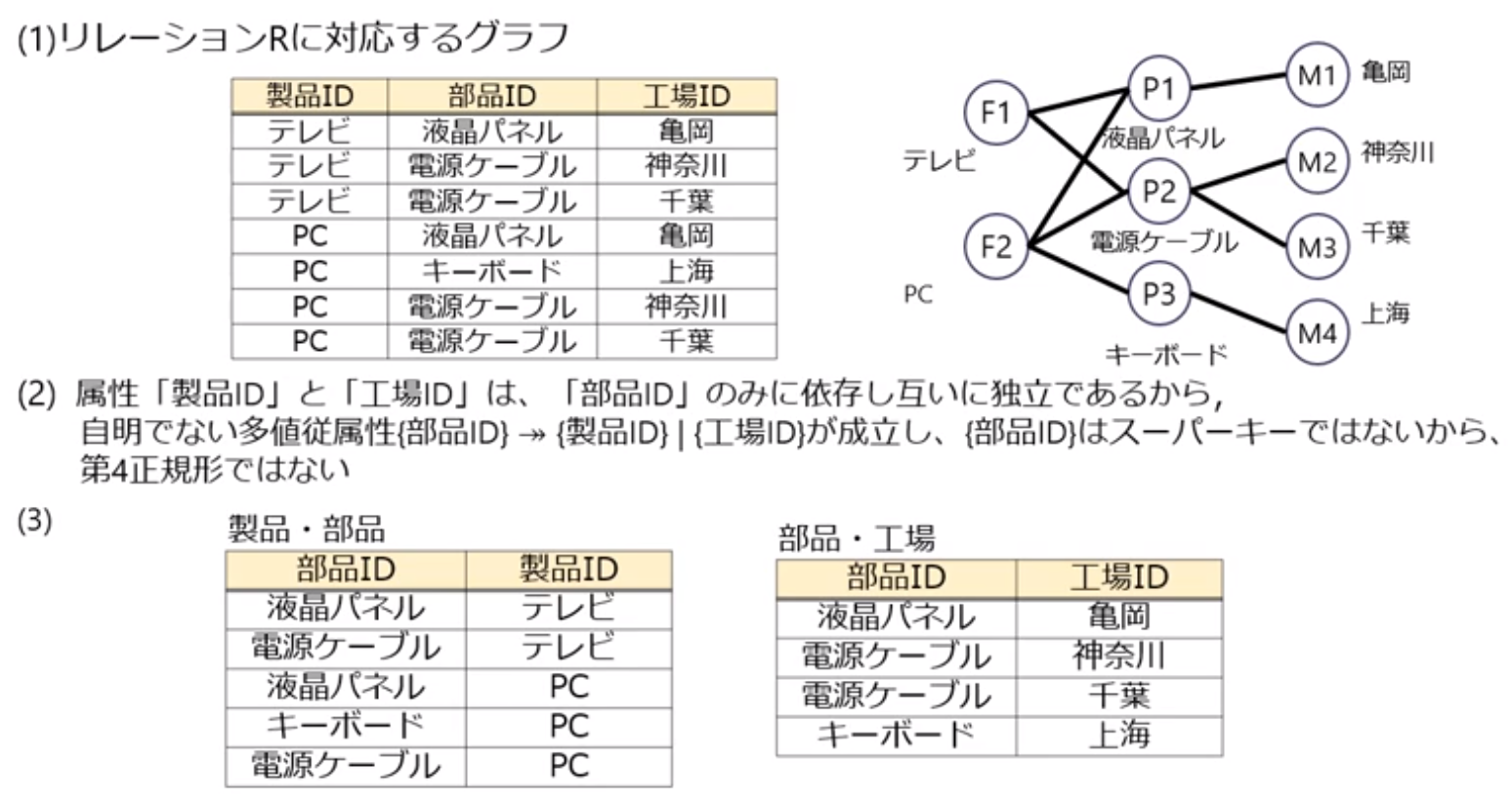
課題7.2
多値従属性について以下の問いに答えよ
R
| 製品ID | 部品ID | 工場ID |
|---|---|---|
| テレビ | 液晶パネル | 亀岡 |
| テレビ | 電源ケーブル | 神奈川 |
| テレビ | 電源ケーブル | 千葉 |
| PC | 液晶パネル | 亀岡 |
| PC | キーボード | 上海 |
| PC | 電源ケーブル | 神奈川 |
| PC | 電源ケーブル | 千葉 |
- 以下の制約を持つリレーションRに対応する3部グラフを作成しなさい
- 製品は複数の部品から構成されている
- 部品は複数の工場で製造されている
- 製品と部品の工場は独立している
- リレーションRが第4正規形でないことを示しなさい
- リレーションRを第4正規形に正規化せよ
結合従属性(JD)
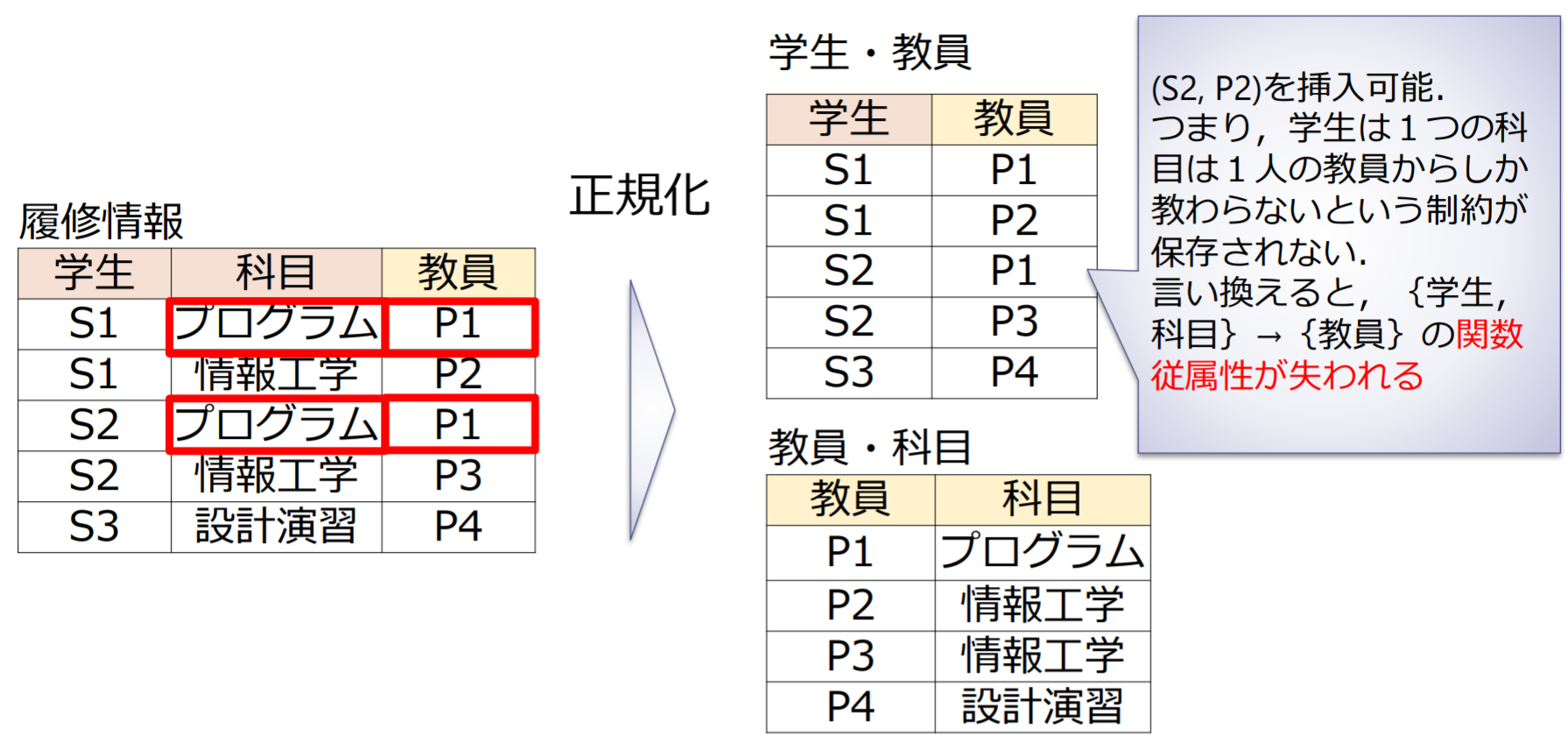
2つのリレーションに情報無損失分解できない例
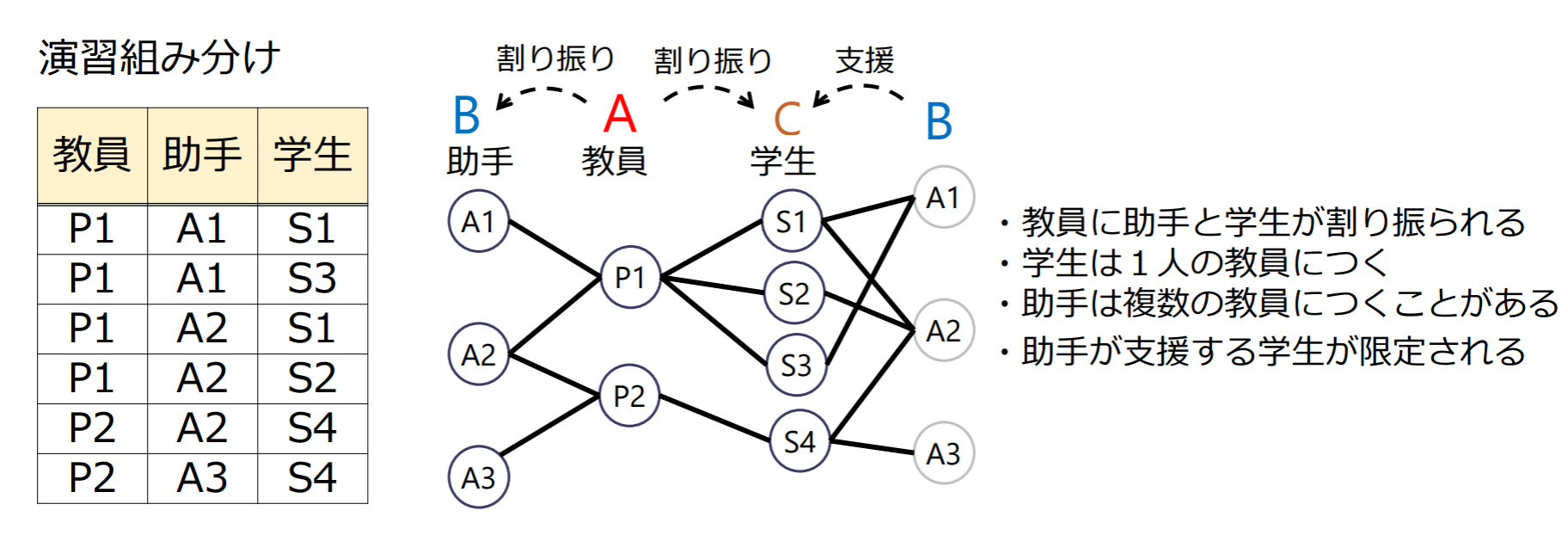
2-分解による情報無損失分解が不可能な事例
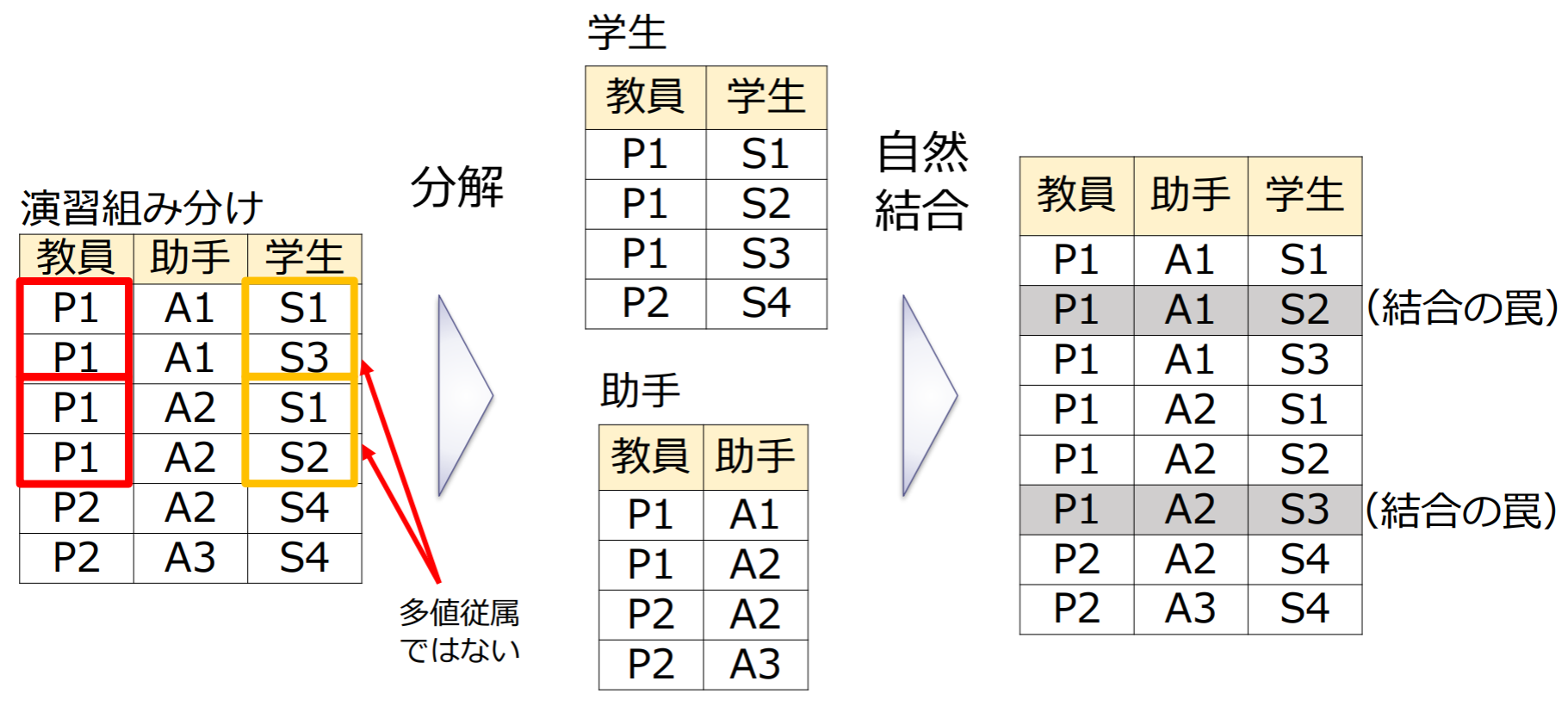
多値従属性ではない理由:教員P1が決まっても、助手が違えば対応する学生が変わる!
リレーションスキーマ において, を の属性集合の部分集合とする. のすべてのリレーションが での射影の自然結合と等しい場合に限り, に結合従属性 * が存在するという.
個の射影に情報無損失分解できるリレーションスキーマをn-分解可能(n-decomposable)という.
結合従属性の性質
結合従属性は多値従属性の一般化である
- が情報無損失分解可能
- 2つのリレーション(への射影)に2-分解可能
自明な結合従属性(trivial join dependency): の1つが の全属性集合と等しい場合
第5正規形
リレーションスキーマ のすべての結合従属性 * において, 以下のいずれかが成り立つ場合に は第5正規形であるという.
- * は自明な結合従属性である
- すべての は のスーパーキーである
課題7.3
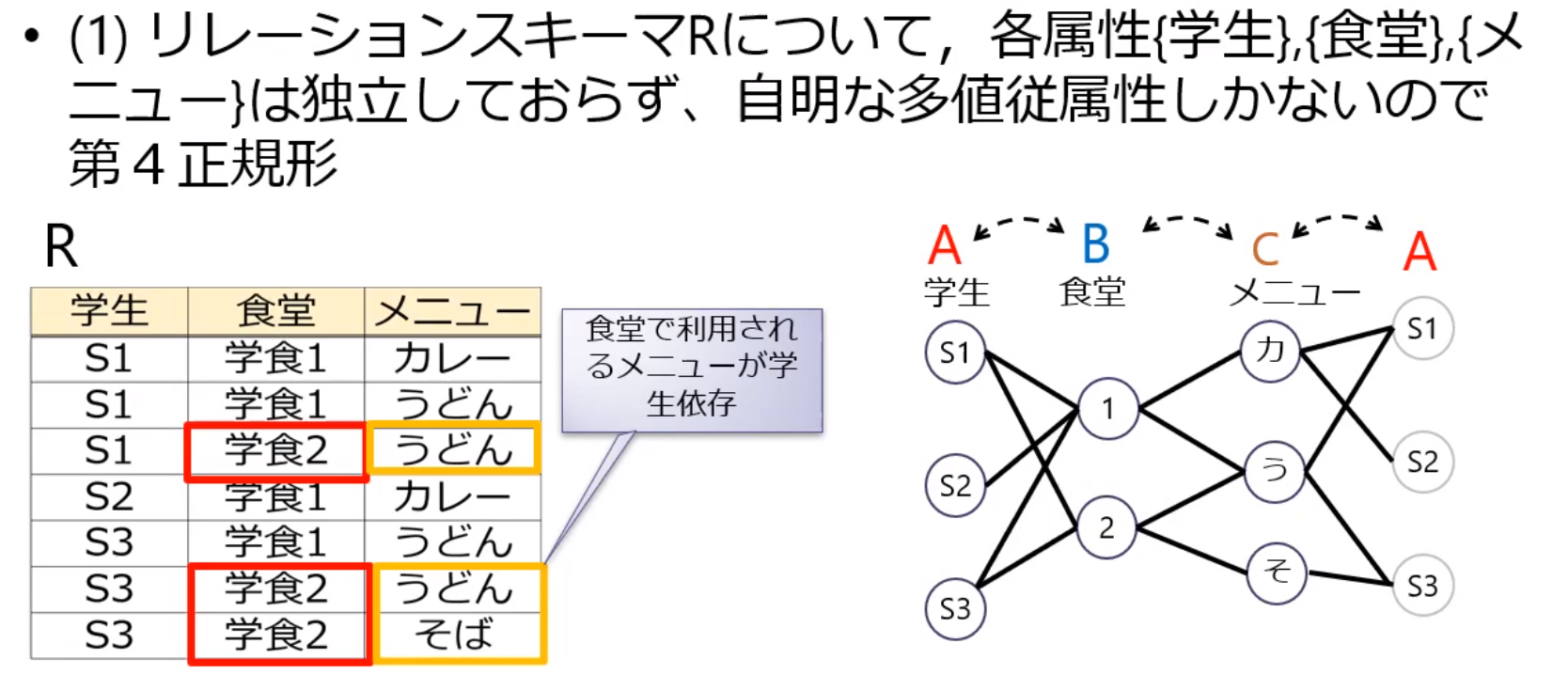
下記のリレーション は,学生が昼食に利用するメニューと食堂の関係を表す.学生とメニュー,メニューと食堂,食堂と学生の関係は多対多であるとする.ここで,多対多とは,例えば,学生とメニューの関係では,各学生は1つ以上のメニューを利用し,各メニューは1人以上の学生から利用されるものとする.また,学生が利用するメニューは,そのメニューを扱うすべての食堂で提供される.このリレーションについて以下の問いに答えなさい.
R
| 学生 | 食堂 | メニュー |
|---|---|---|
| S1 | 学食1 | カレー |
| S1 | 学食1 | うどん |
| S1 | 学食2 | うどん |
| S2 | 学食1 | カレー |
| S3 | 学食1 | うどん |
| S3 | 学食2 | うどん |
| S3 | 学食2 | そば |
- このリレーションが第4正規形であるか否かを,理由を挙げて示せ
- このリレーションを第5正規形に正規化せよ
- 正規化したリレーションを自然結合し,情報無損失分解であることを示せ
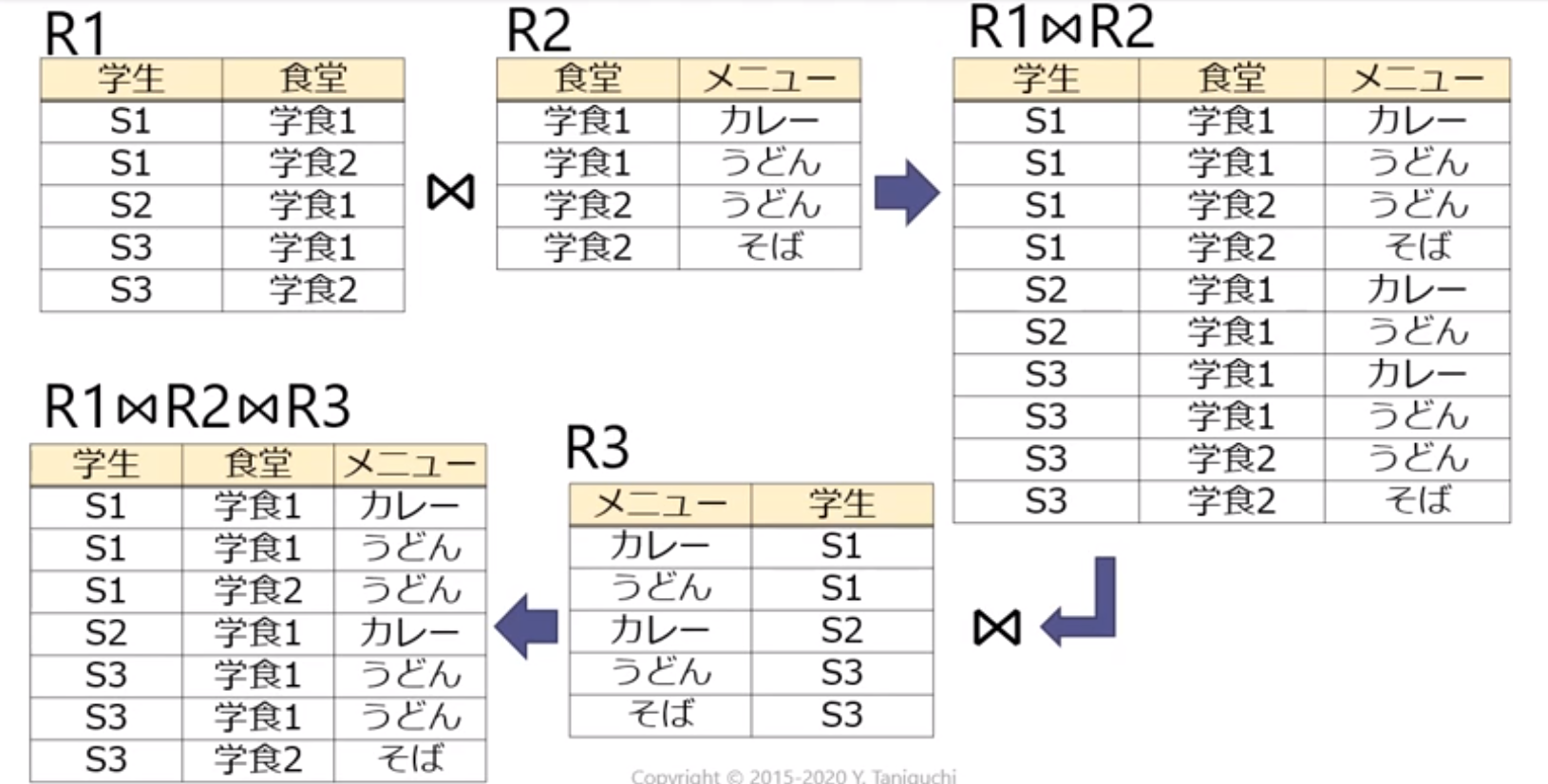
正規化とリレーションスキーマの設計
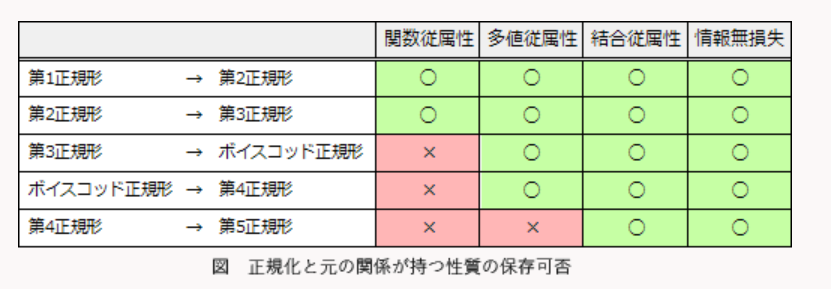
関数従属性,多値従属性,結合従属性の順に一般化された従属性
正規化が常に良いわけではない. 従って. 更新時異常の回避,検索性能,制約の保存のトレードオフを考えて,正規化の有無を決定する必要がある.
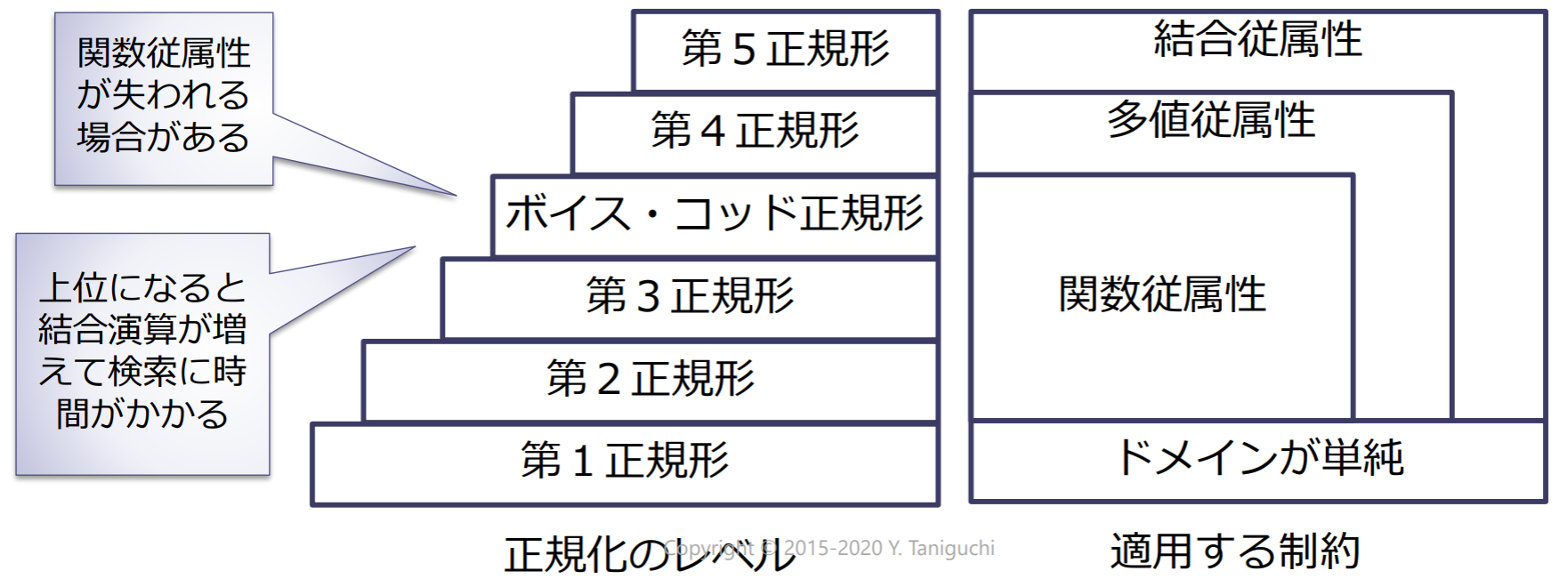
まとめ
リレーションの更新時異常を解消するために正規化を行う
- 関数従属性の概念を理解
- 第2正規形:部分関数従属性を解消
- 第3正規形:推移的な関数従属性を解消
- ボイス・コッド正規形:自明でない関数従属性を解消
- 上位の正規形にすれば,必ずしも良いわけではない.検索性能を高めるために,正規形を崩すこともある.
总结
第一范式要求数据库中的每个字段都是原子性的,即不可再分解的。具体来说:
- 每一列都是原子的,不可再分解
- 每个单元格中的值都是单一的,不会有多个值
例:考虑一个存储学生信息的表,如果我们将学生的姓名和姓氏分别存储在两个不同的列中,这就不符合第一范式。正确的做法是将姓名和姓氏合并成一个字段
第二范式要求表中的每个非主键列完全依赖于整个主键,而不是依赖于主键的一部分。换句话说,表中的每个字段都应该与整个主键直接相关,而不是只与主键的一部分相关
例:考虑一个订单表,其中包含订单号、产品编号和产品名称。在这种情况下,产品名称不依赖于订单号,而是依赖于产品编号。为了符合第二范式,我们应该将产品名称移动到与产品编号相关的表中
第三范式(3NF):第三范式要求表中的每个非主键列既不传递依赖于主键,也不传递依赖于其他非主键列。换句话说,任何非主键列都不应该依赖于其他非主键列
例:考虑一个包含员工信息的表,其中包括员工编号、部门编号和部门名称。在这种情况下,部门名称依赖于部门编号,而不应该依赖于员工编号。如果我们将部门名称移动到一个独立的表中,并将部门编号作为主键,则可以符合第三范式
BCNF 是第三范式(3NF)的一种推广,它更严格地规定了数据库中的表结构,确保表中的每个非主键属性都完全依赖于主键,而不是依赖于主键的任何候选键
例:考虑一个订单表,其中包含订单号、产品编号和产品名称。在这种情况下,产品名称依赖于产品编号,但不依赖于订单号。如果我们将产品名称存储在订单表中,可能会违反 BCNF。为了符合 BCNF,我们应该将产品名称移动到一个与产品编号相关的表中
第四范式主要解决多值依赖问题。如果关系模式中存在一个以上的多值依赖,就可以使用第四范式来分解表
例:考虑一个图书和作者的关系,其中一个作者可能写了多本书,而一本书可能由多个作者合作编写。如果我们直接在图书表中存储作者信息,可能会导致多值依赖。在这种情况下,可以将作者和书籍拆分成两个独立的表,每个表都包含一个作者或书籍,并使用一个连接表来管理多对多关系
第五范式是一种较高级别的范式,用于消除关系中可能存在的连接依赖
例:考虑一个包含学生、课程和教师的关系模式。如果一个学生可以参加多门课程,一门课程可以有多个教师,那么存在连接依赖。在这种情况下,可以将学生、课程和教师分别拆分成独立的表,并使用连接表来管理它们之间的关系
多值依赖指的是关系模式中一个或多个属性对另一组属性形成的依赖关系。具体来说,如果一个属性组的值对于关系中的另一个属性组的每个值都是多值的,那么就存在多值依赖。
例:考虑一个学生选修课程的数据库表,其中包含学生姓名、学生所在班级和学生选修的多门课程。如果一个学生可以选修多门课程,而每门课程又可以由多个学生选修,这就构成了多值依赖
连接依赖指的是关系模式中多个属性的组合对另一组属性形成的依赖关系。具体来说,如果一个属性组的值对于关系中的另一个属性组的每个值都是连接的,那么就存在连接依赖
例:考虑一个包含学生、课程和教师的关系模式。如果一个学生可以参加多门课程,一门课程可以有多个教师,而每个学生选修的课程和每个课程的教师都是连接的,那么就存在连接依赖
データモデリング(data modeling)
データモデリングとは
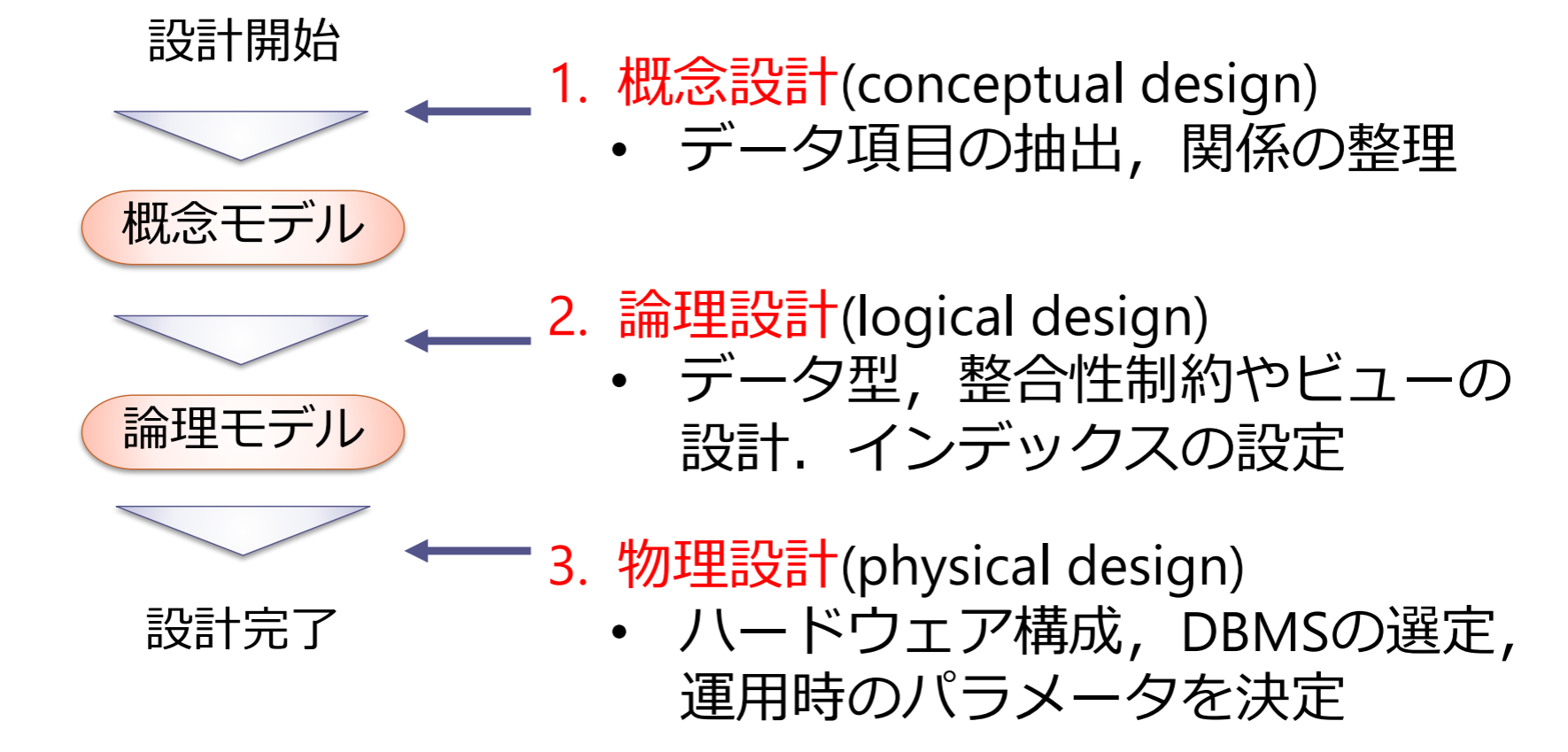
実社会の中でデータベース化したい対象からデータ項目を抽出・整理し,適切なデータ構造を決定すること
リレーショナルデータベースの場合であれば,以下を決めること
- データ項目:テーブル名,属性名
- データ構造:ドメイン,整合性制約,主キー・外部キー
情報システムの要求分析・定義工程,設計工程の一部
- 業務フローや顧客の要求を把握する必要がある
データベース設計と実体関連図
3層スキーマ
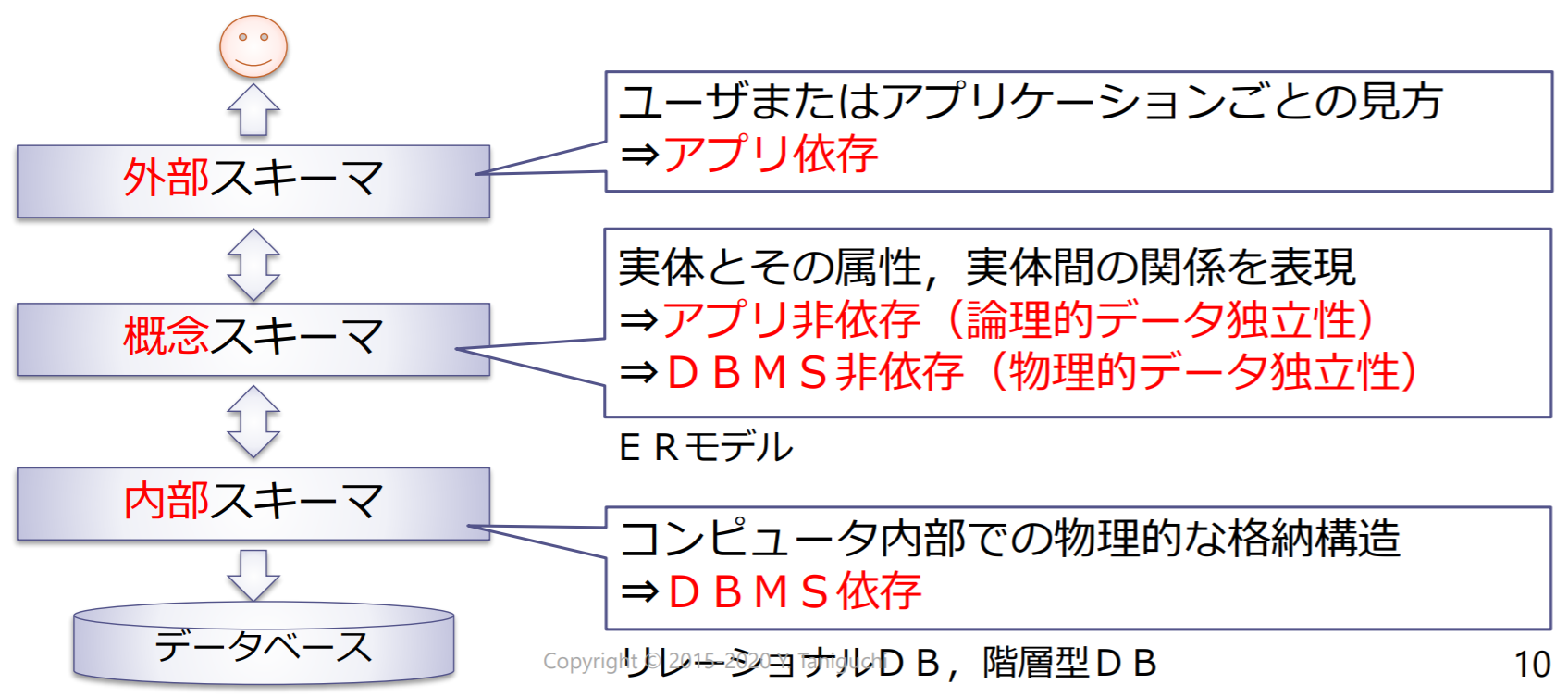
三層スキーマ:ANSI/X3(米国規格委員会情報処理部会)のSPARC(標準計画要件委員会)によって提案されたデータモデリングの基本的な概念
3層スキーマとデータベース設計手順の対応
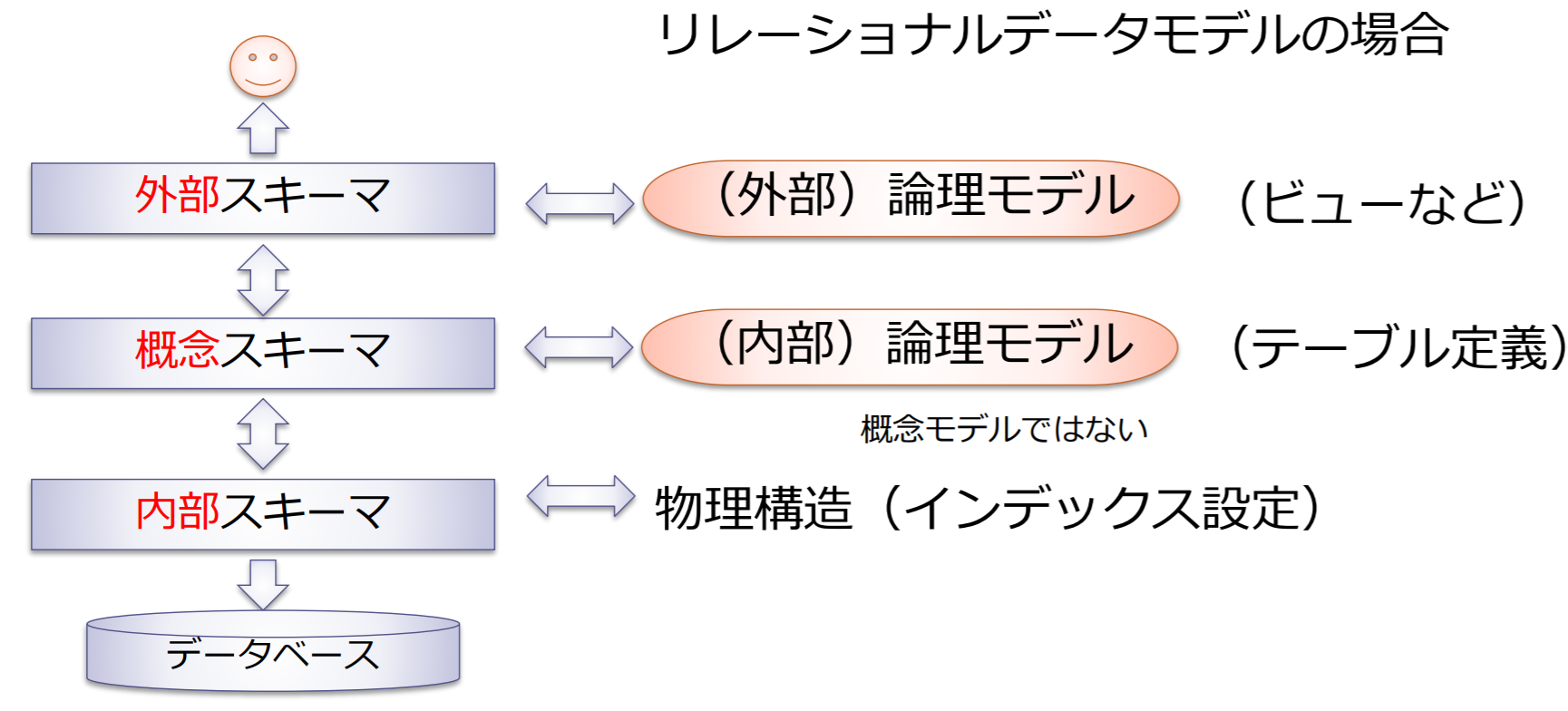
実体関連図(ER図)
1976年にChenが提唱したエンティティとリレーションシップという二つの概念でデータ構造の分析を行い図に表現する手法.
- エンティティ(実体):システムで関心対象となり得る「人・もの」や「概念」
- eg. 社員,顧客,商品,部署
- リレーションシップ(関係):実体間の関係
- eg. 1対1関係,1対多関係,多対多関係
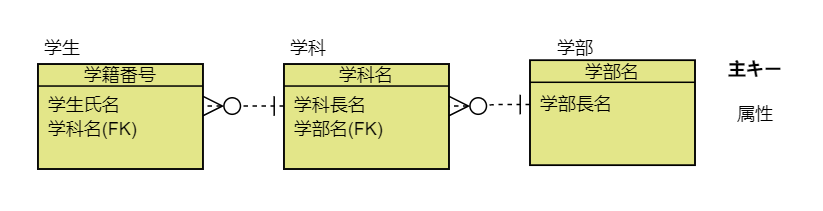
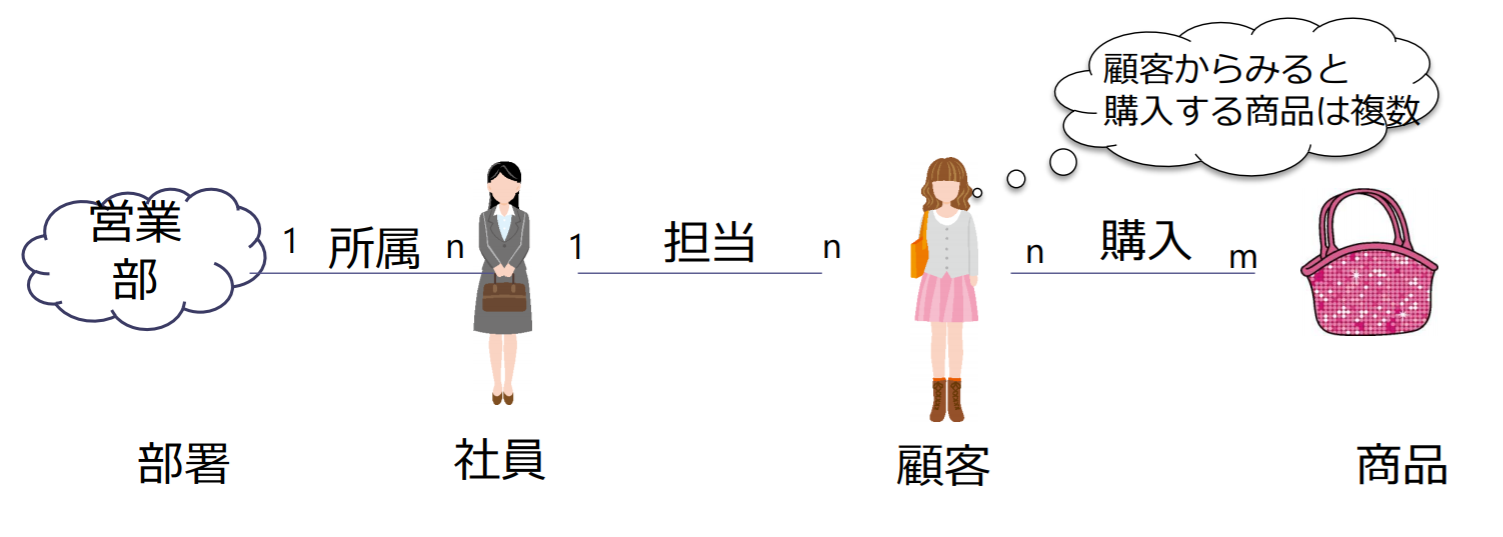
実体間のリレーションシップ:多重度(cardinality)
- 1対1関係,1対多関係,多対多関係
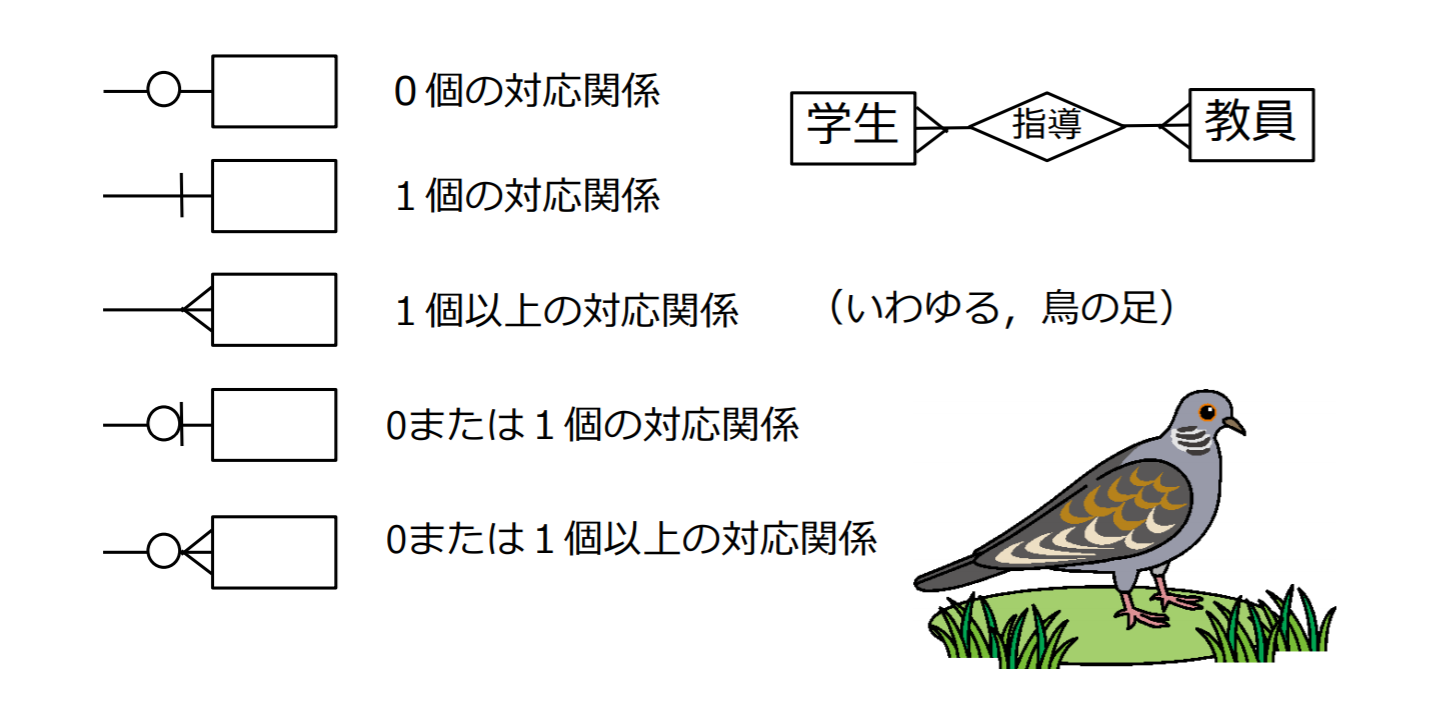
IE記法における多重度の表現
課題8.1
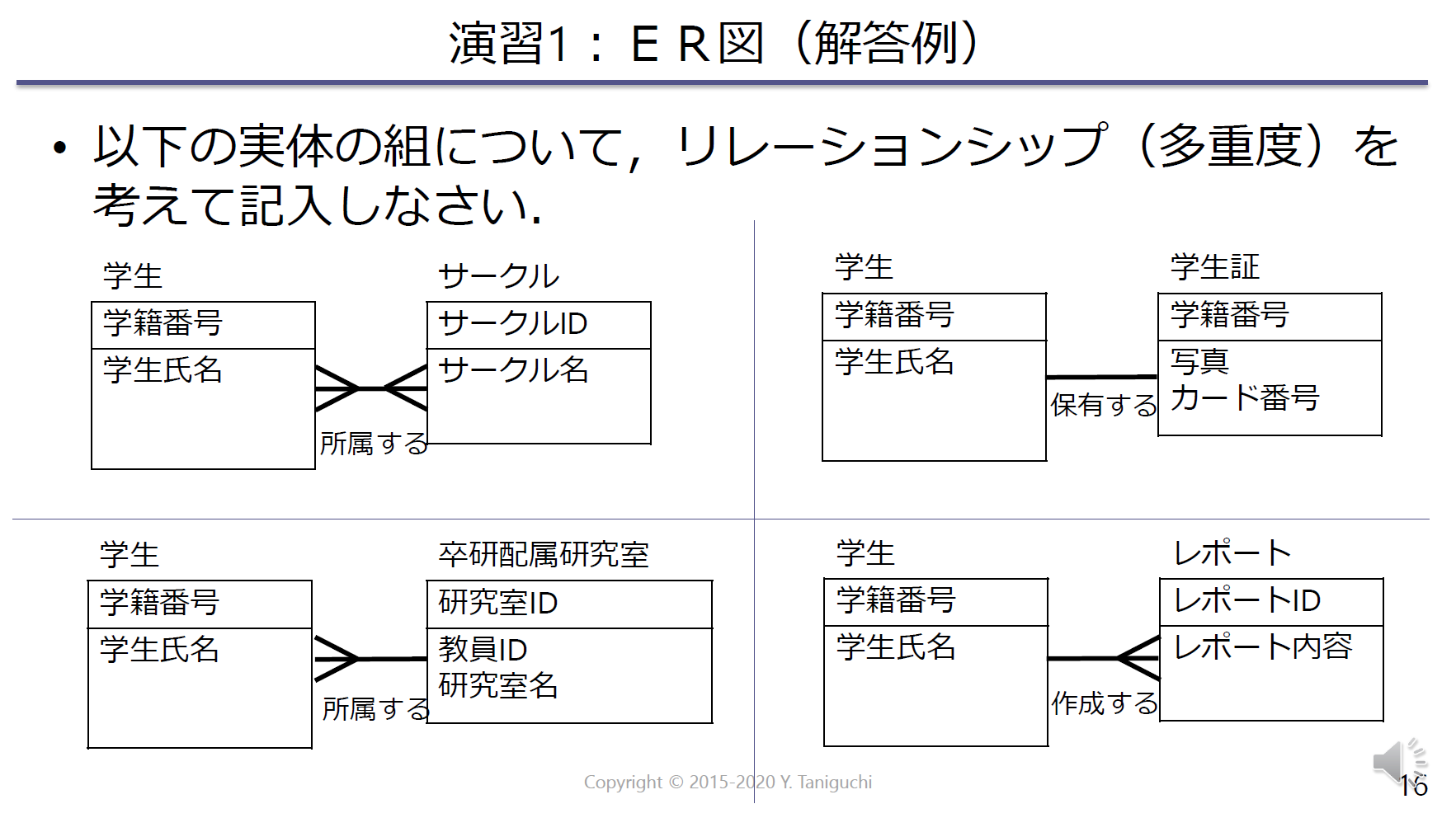
データモデリングの方法
データモデリングの手順
- 実体の抽出
- 実体間の関係の設定
- 多対多の関係の分解
- キーと属性の設定
- 正規化
- 実世界の要求の反映
- リレーショナルデータモデルへの変換
手順1:実体を抽出
業務フロー,帳票,画面,ユースケースシナリオから名詞部分を抽出
ガイドライン:
- 管理対象である
- eg. 「大学」は履修登録システムの管理対象外なので実体として扱わない
- 一つの実体には複数のインスタンスが発生しうる
- 固有名詞ではなく,その総称を実体にする
- 実体の持つ特徴や状態はエンティティの属性とする(例,生年月日)
- 一意識別子(キー)を持ちうる
- 一意識別子の例:社員番号,商品コード,マイナンバー(個人番号),端末ID,など
- eg. 「年齢」はキーを持たないので実体として扱わない.「年齢層」なら実体として扱うこともある
例:手順1:実体の抽出(履修管理システム)
- 要求(1):履修管理システムは大学のすべての学生と開講科目を管理し,どの学生がどの科目をどのセメスタ(学期)で履修したかを検索表示できる
- 要求(2):履修管理システムは学生の履修履歴を管理し,学生ごと,科目ごと,学科ごとに検索表示できる
手順2:実体間の関係の設定
実体間にどのような関係があるか検討する
- 1対1関係,1対多関係,多対多関係
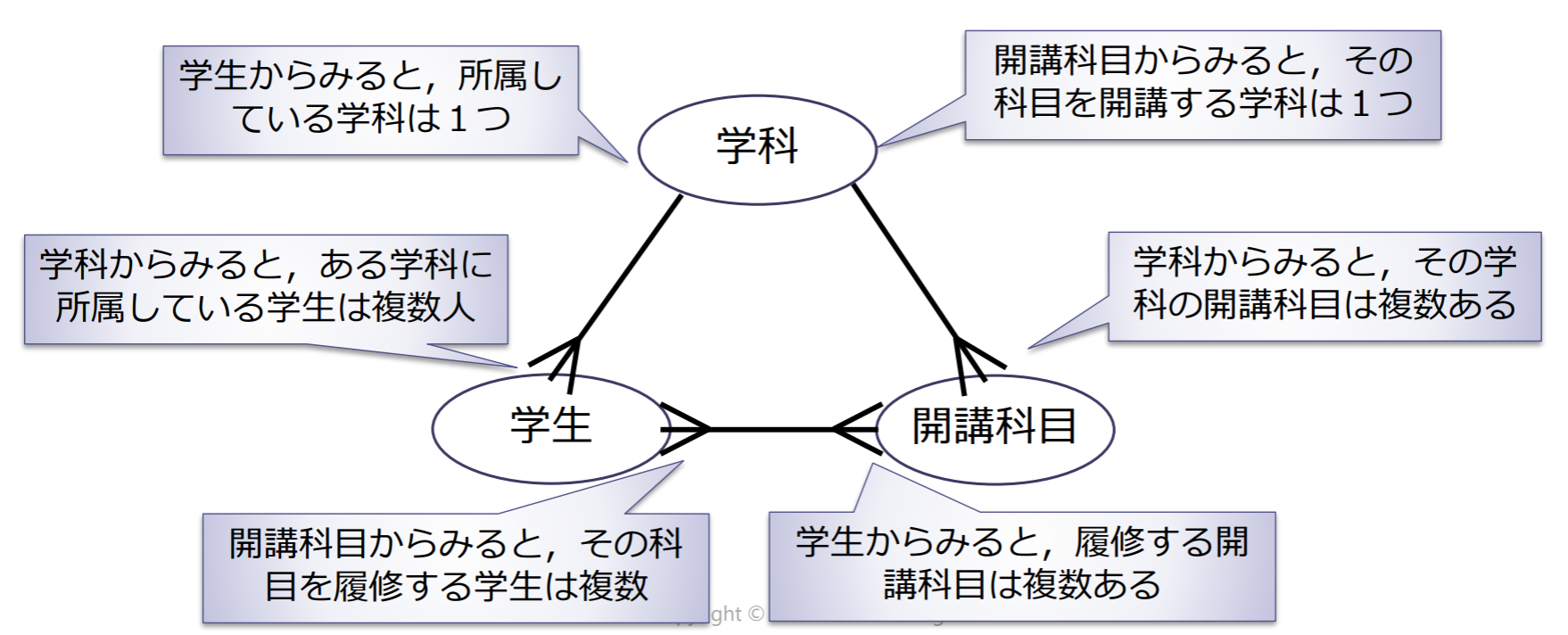
手順3:多対多の関係の分解
実体間の関連に「多対多」がある場合には,複数の「1対多」の関連に分解する(リレーショナルデータモデルの場合)
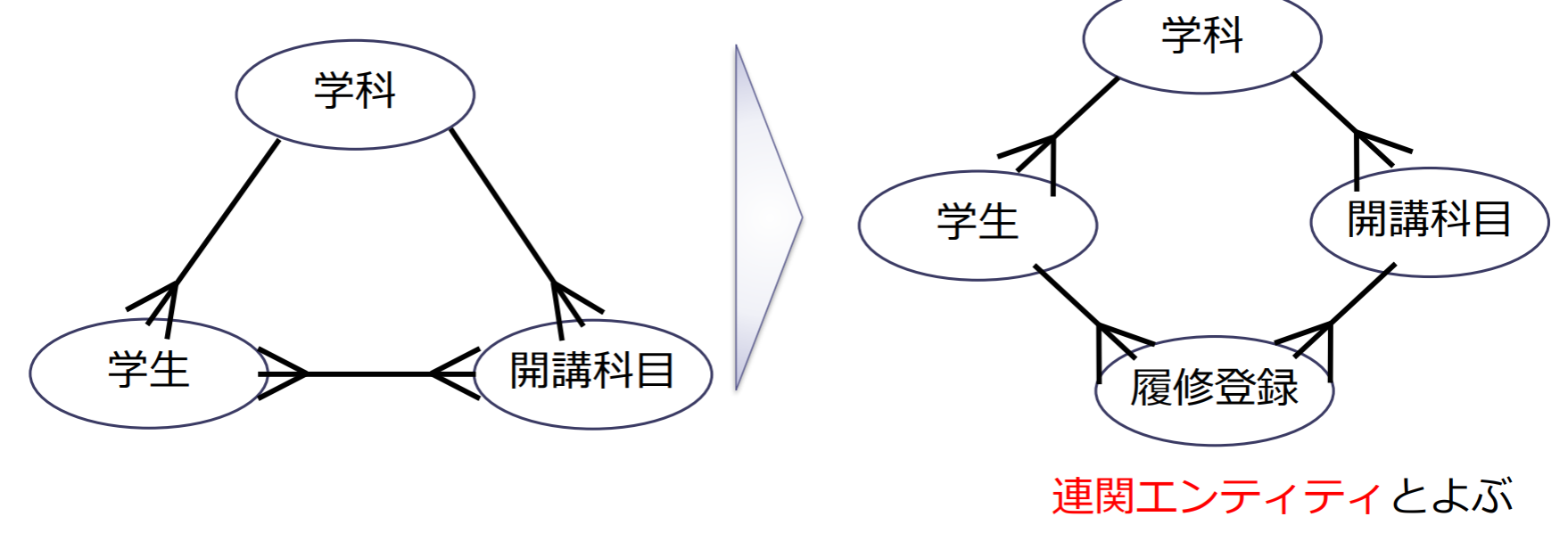
手順4:キーと属性の設定
- 主キーを設定
- 実体のインスタンス(リレーションにおけるタプル)を一意に特定できる属性
- 属性を設定
- 実体を管理するために必要なデータ項目
- 外部キーを設定
- 1対多の「多」の方の実体に1つ設定する
例:手順4:キーと属性の設定(履修管理システム)
実体として「学生」と「学科」しか抽出しなかった場合
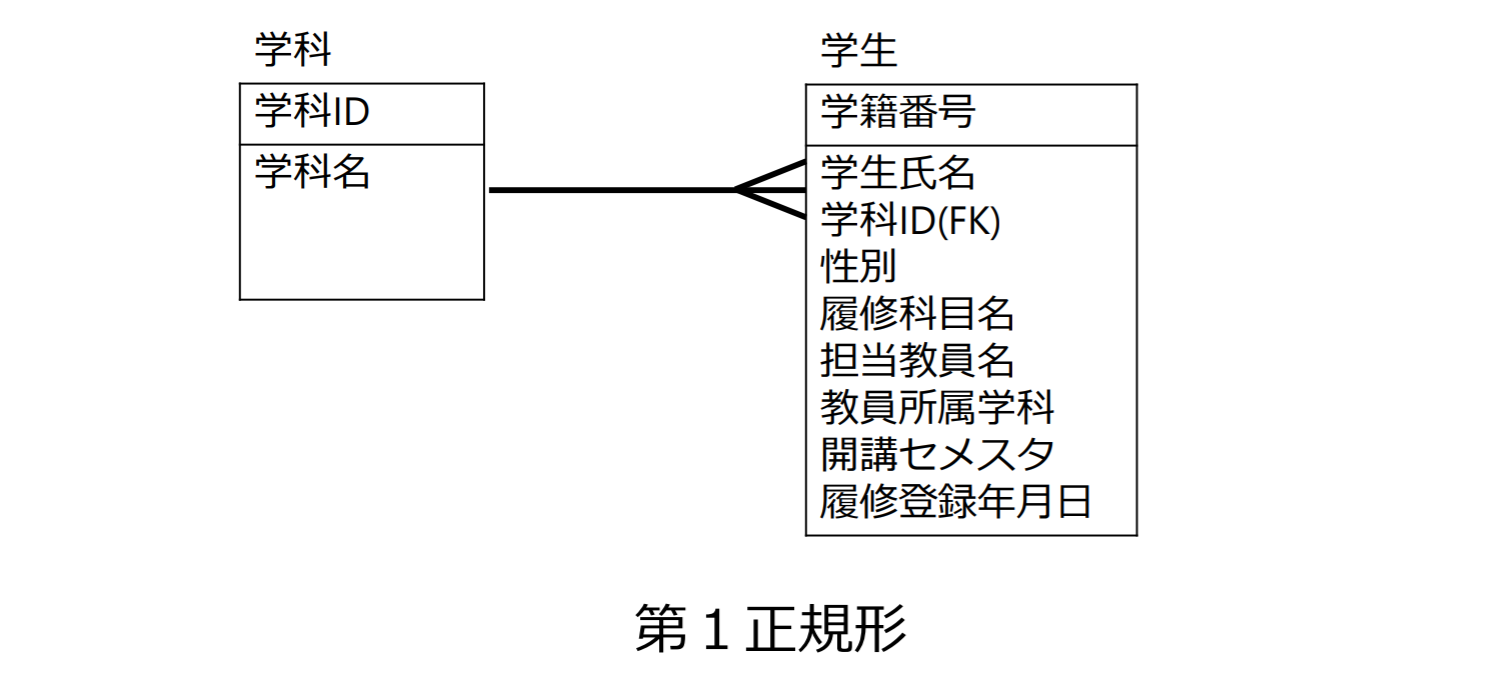
手順5:正規化
リレーションを正規化する(第3正規形までで十分な場合が多い)
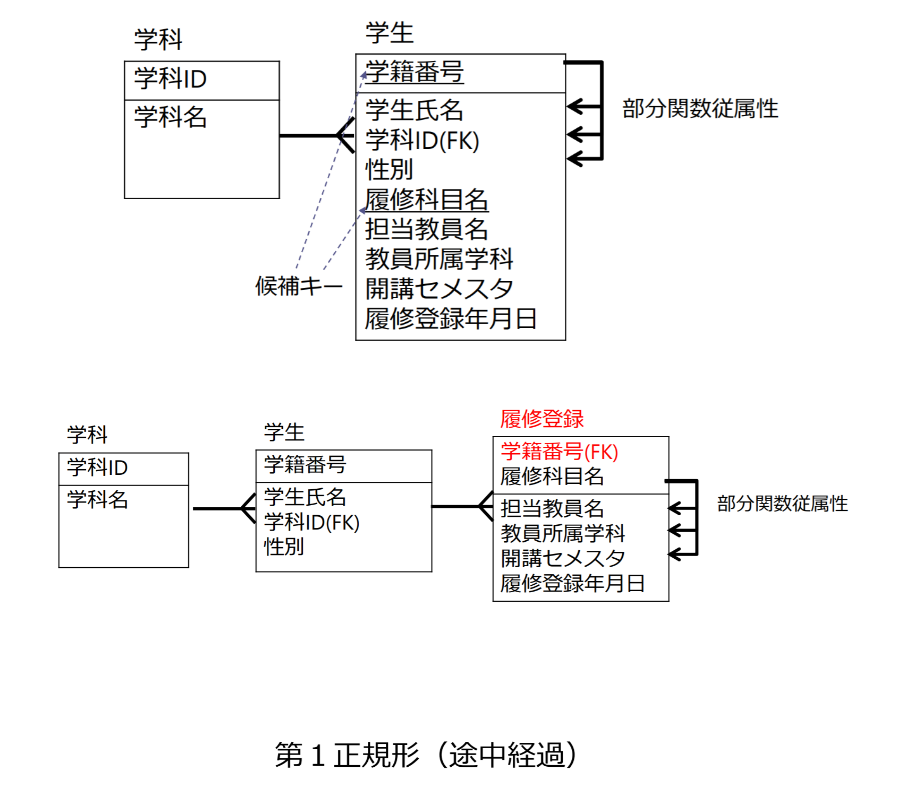
- 学生リレーションタプルを特定するために、学籍番号と履修科目名が必要(学生が複数科目履修可能)
- 担当教員名、教員所属学科、開講セメスタ、履修登録年月日は学籍番号と独立しているため、学生氏名、学科ID、性別を別のリレーションに分解する
- 部分関数従属性が残っているため(科目に関する属性)、別のテーブルに分解する
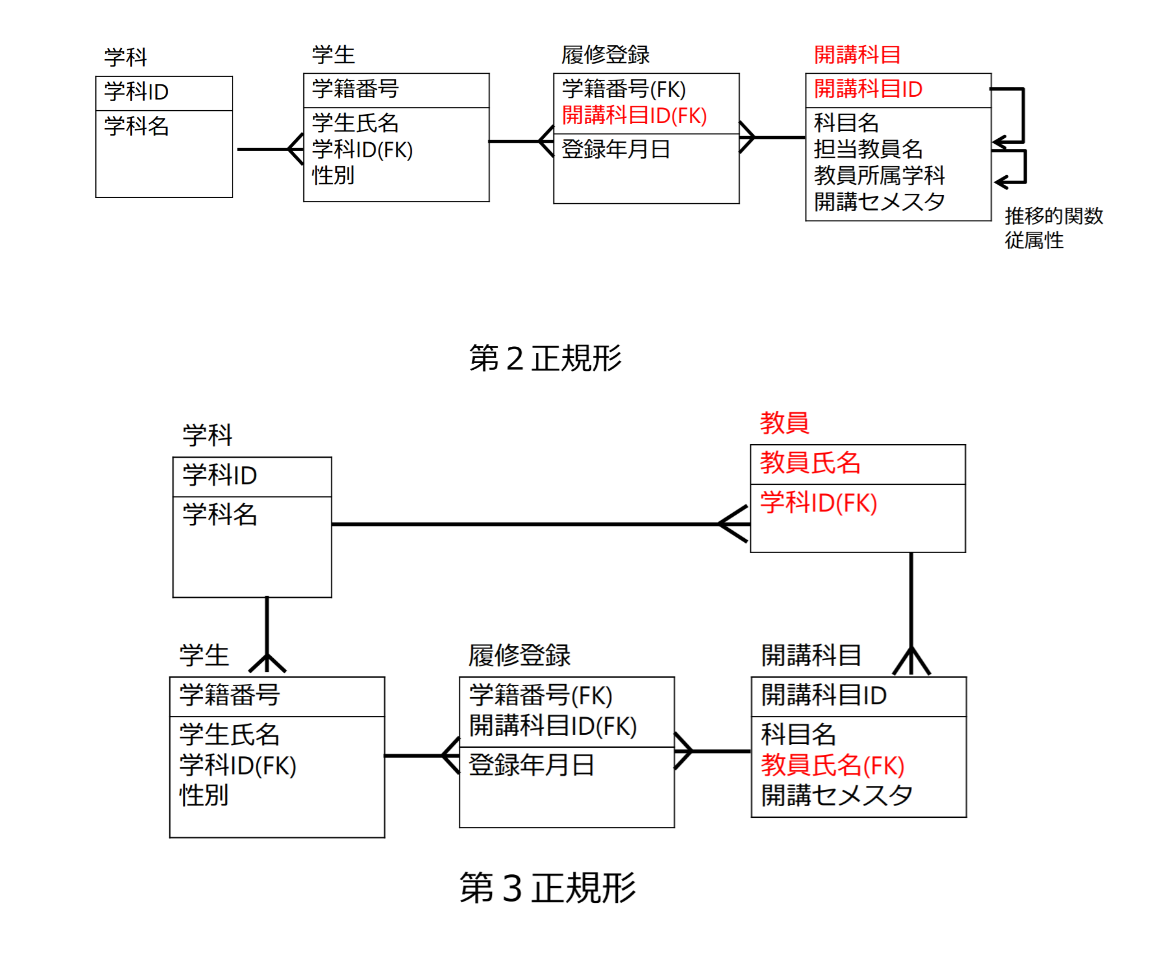
- 推移的関数従属性が残っているため、それを分解して第3正規形にする
- 関数従属性が残っていないため、第3正規形になる
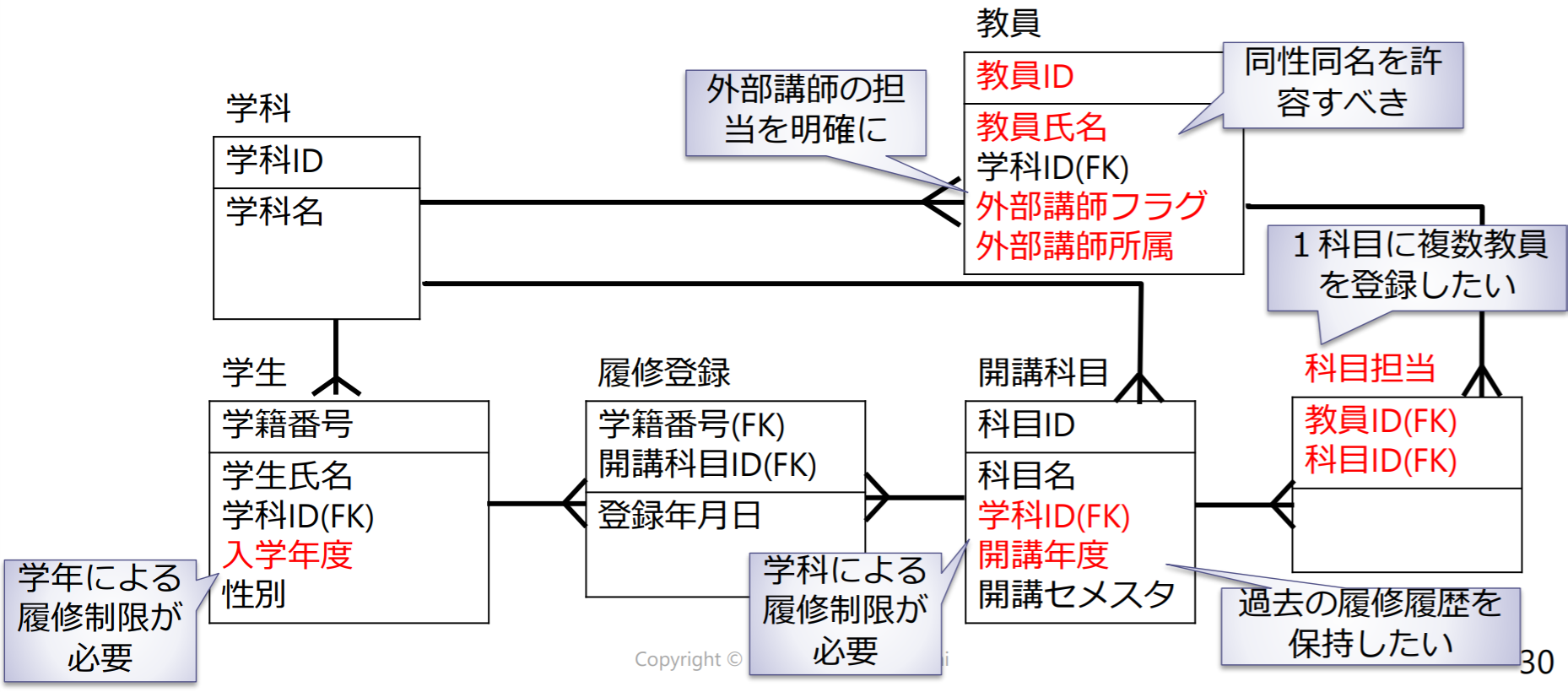
手順6:実世界の要求の反映
構築するシステムへの要求を満たしているか検証
手順7:リレーショナルデータモデルへの変換
各属性のデータ型を決め整合性制約を設定
課題8.2
課題8.3
- 設問1:ER図を作成しなさい
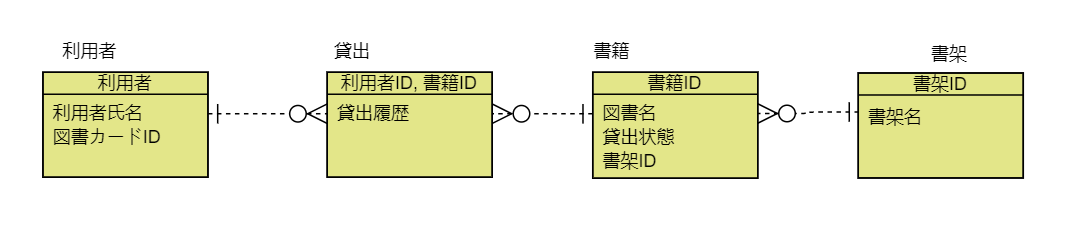
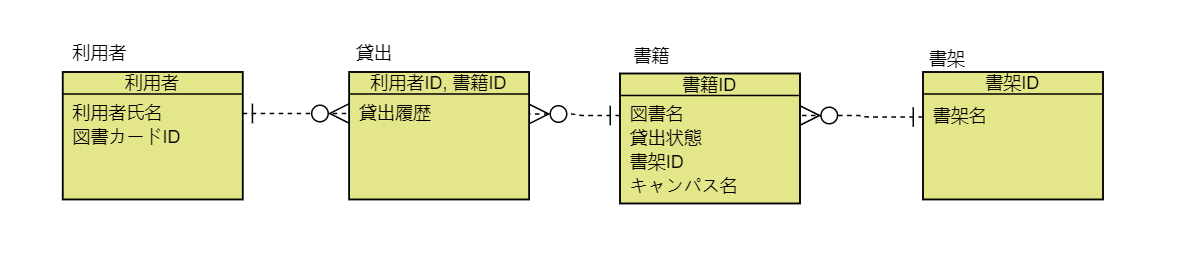
- 設問2:新たな要求を考えて,要求を追加した場合に,どのようにER図を変更する必要があるか検討しなさい.
他のキャンパスの図書も扱えるように要求を追加する
データベース管理システムと外部記憶装置
データベース管理システムの基本構成と機能
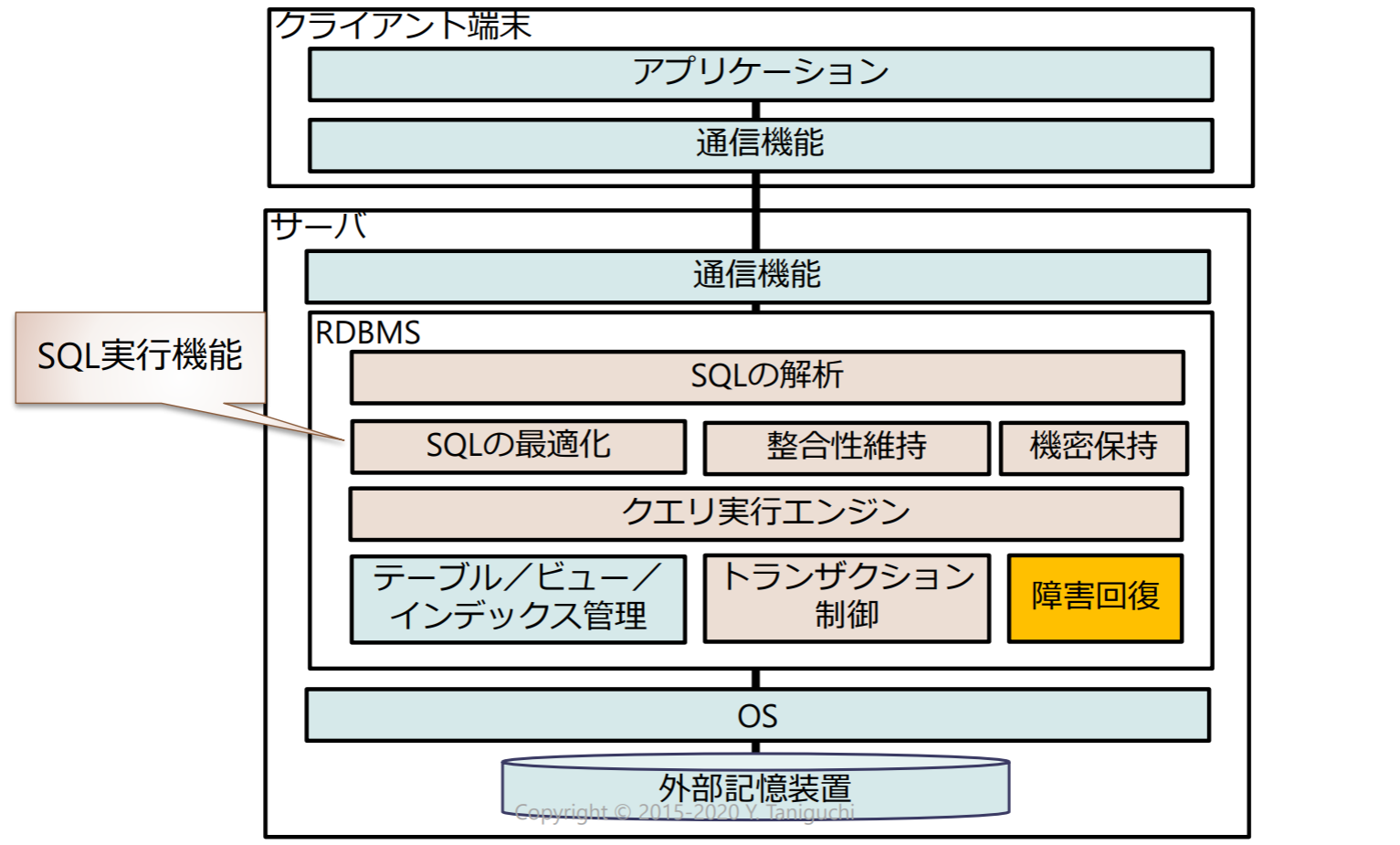
SQL実行機能
- SQL文の解析(パーサ):SQL文の構文解析
- 機密保持:ユーザの権限を確認しアクセス可能か判断
- SQL文の最適化(オプティマイザ):効率化のためにSQL文の実行順序等を変更インデックスの利用可否の判断
- クエリ実行エンジン:クエリの実行
- 整合性維持:整合性制約を遵守しているか監視違反していたらロールバック(実行を取消)
- トランザクション制御:同時実行制御
テーブル/ビュー/インデックスの管理機能
- テーブルの管理
- リレーション名,属性名,ドメイン,制約,インデックス名などを管理
- テーブルのデータを外部記憶装置のどこに書き込むかを管理
- ビューの管理
- ビューの属性と実テーブルの対応関係を管理
- インデックスの管理
- データベースの検索性能を向上させるためのデータを管理(B-tree, B+tree, ハッシュなど)
データベースが管理するファイル群
- データファイル
- テーブル内のデータを保持するファイル
- インデックスファイル
- インデックスデータを保存しているファイル
- システムファイル(システムカタログ)
- RDBMSの運用や内部処理のためのシステム情報を保持するファイル
- テーブル名,列名,データ型,整合性制約なども格納される
- 一時ファイル
- クエリを実行する際に一時的に生成されるファイル(group by句,distinctを実行した時のソートデータなど)
- ログファイル
- データベースの変更情報が記録されたファイル
データベースの外部記憶装置への書き込み
外部記憶装置への書き込み
- ページ:固定サイズ(例えば,4, 8, 16, 32KB)の記憶領域
- エクステント:連続する複数ページのまとまり
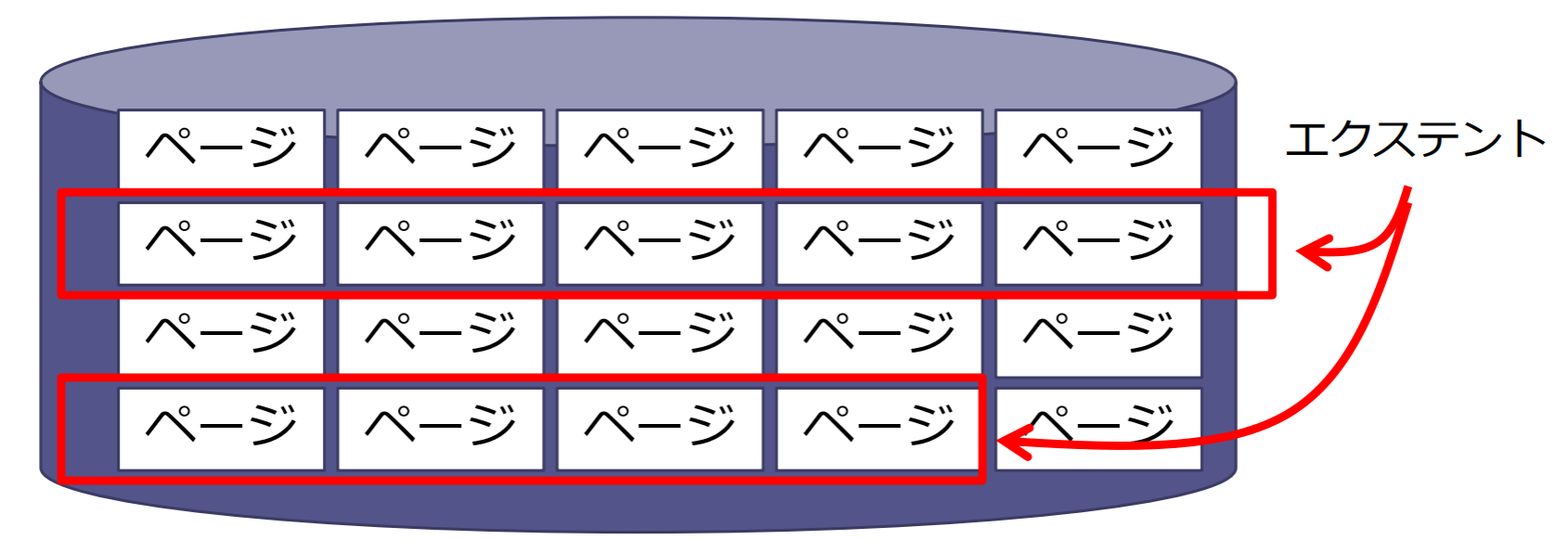
ヒープファイル:ページへのレコードの格納
- リレーションのタプル(テーブルの1行)を内部レベルではレコード(record)として表現してHDDに格納
- ヘッダ,スロット(ディレクトリ),レコードから構成される.レコードサイズはページサイズより小さく設定する
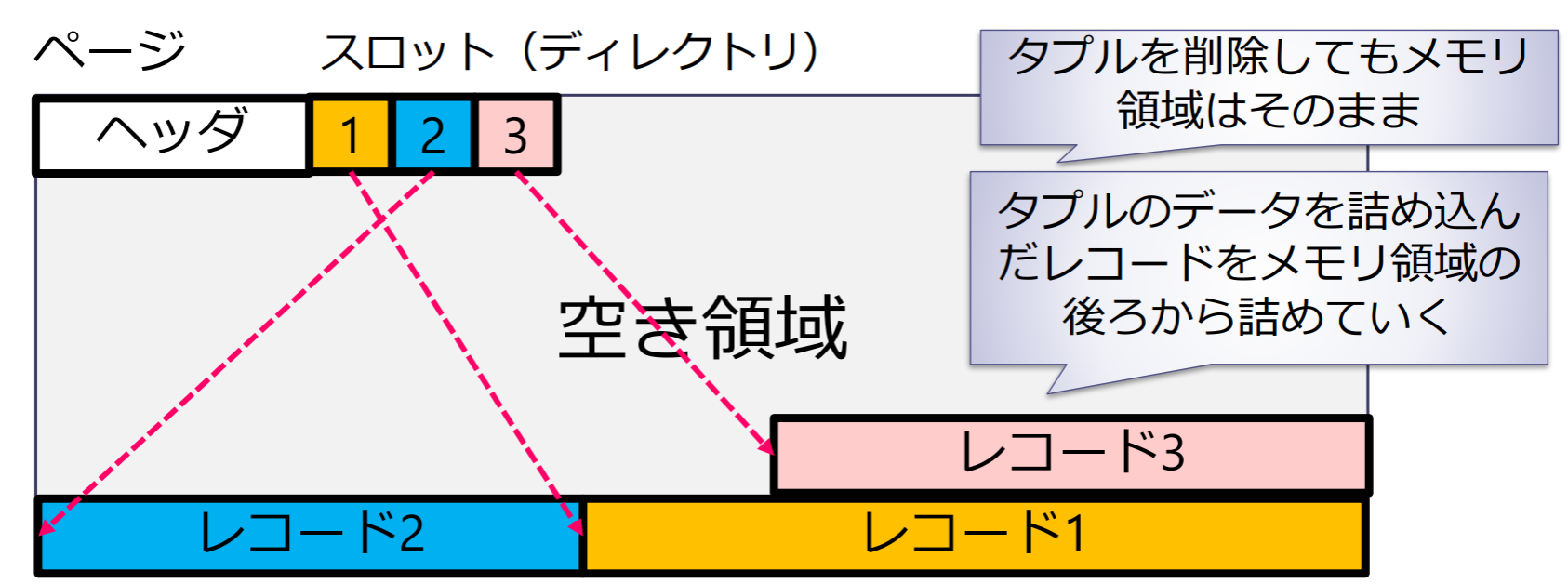
レコードの構造
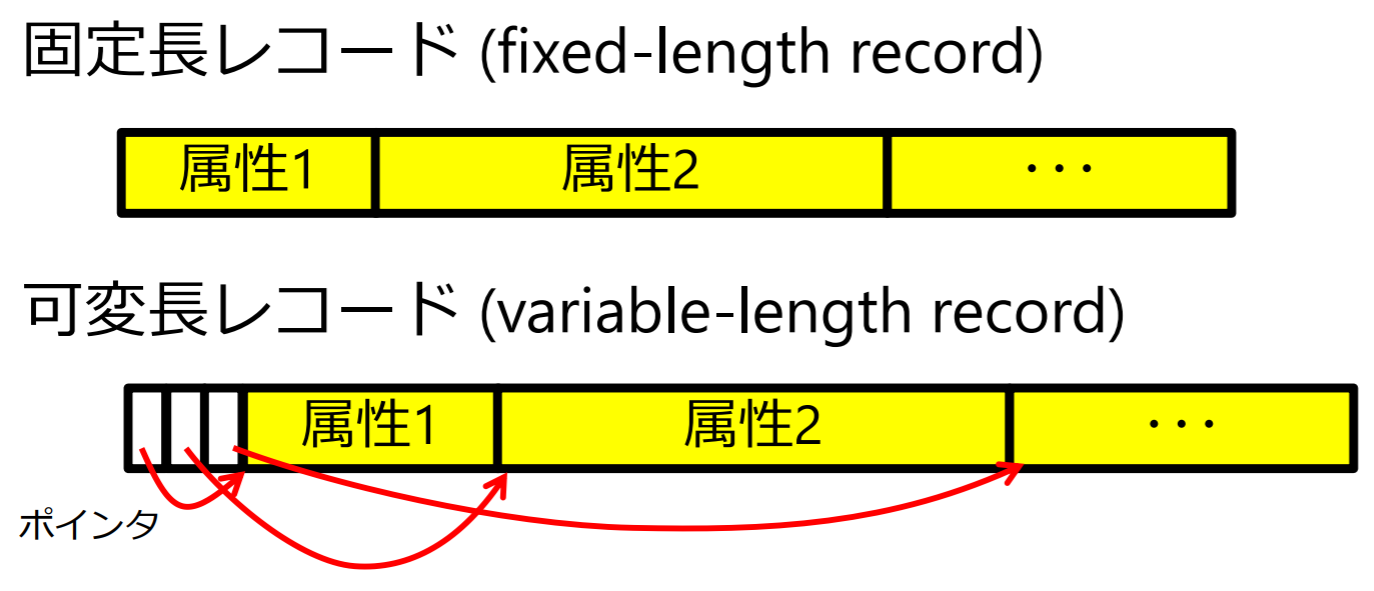
- 更新で可変長属性が大きくなった場合は,別ページに移動する必要がある
インデックス方式
インデックス(index):書籍の巻末にある索引(インデックス)と同じように本体のデータに効率的にアクセスするための仕組み
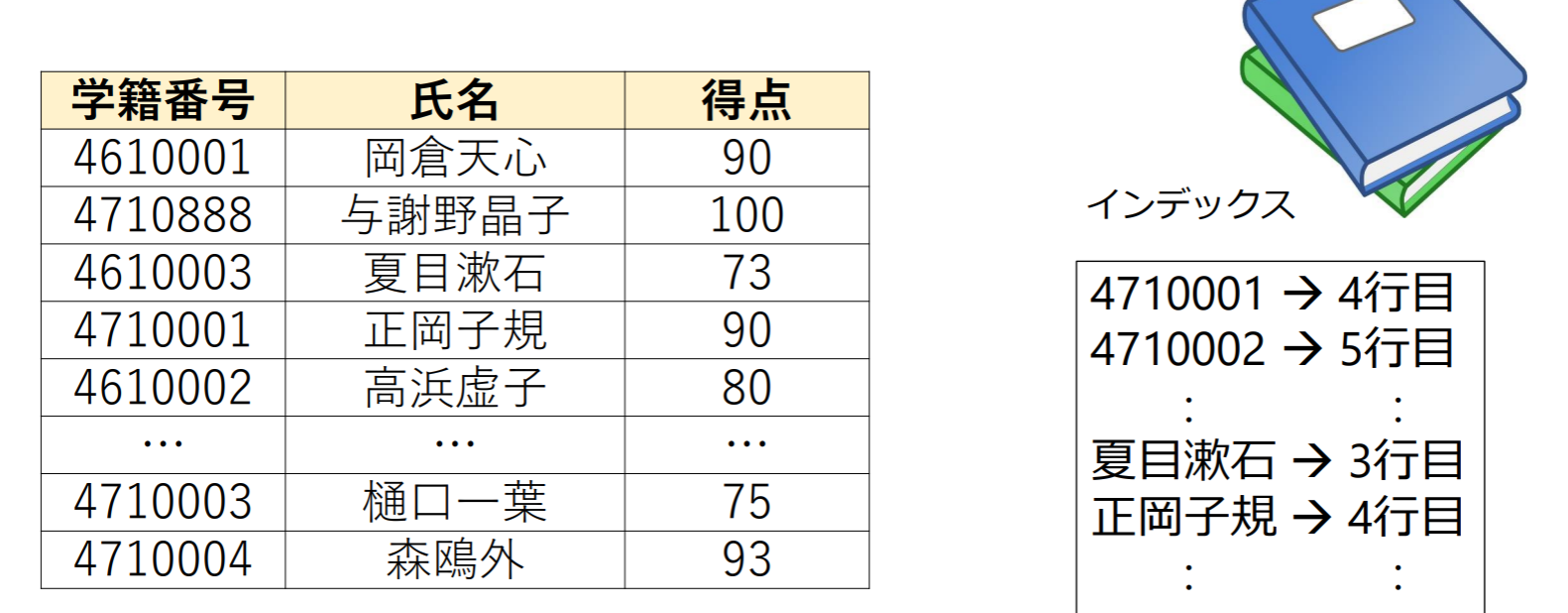
インデックス方式:
- B-tree, B+treeインデックス
- バランス木構造
- B+treeが,RDBMSでは標準的に使われている (SQLiteにも実装されている)
- ハッシュインデックス
- ハッシュ関数を利用
- B树的每个结点都存储了key和data,B+树的data存储在叶子节点上。节点不存储data,这样一个节点就可以存储更多的key。可以使得树更矮,所以IO操作次数更少。
- 树的所有叶结点构成一个有序链表,可以按照关键码排序的次序遍历全部记录由于数据顺序排列并且相连,所以便于区间查找和搜索。而B树则需要进行每一层的递归遍历。相邻的元素可能在内存中不相邻,所以缓存命中性没有B+树好。
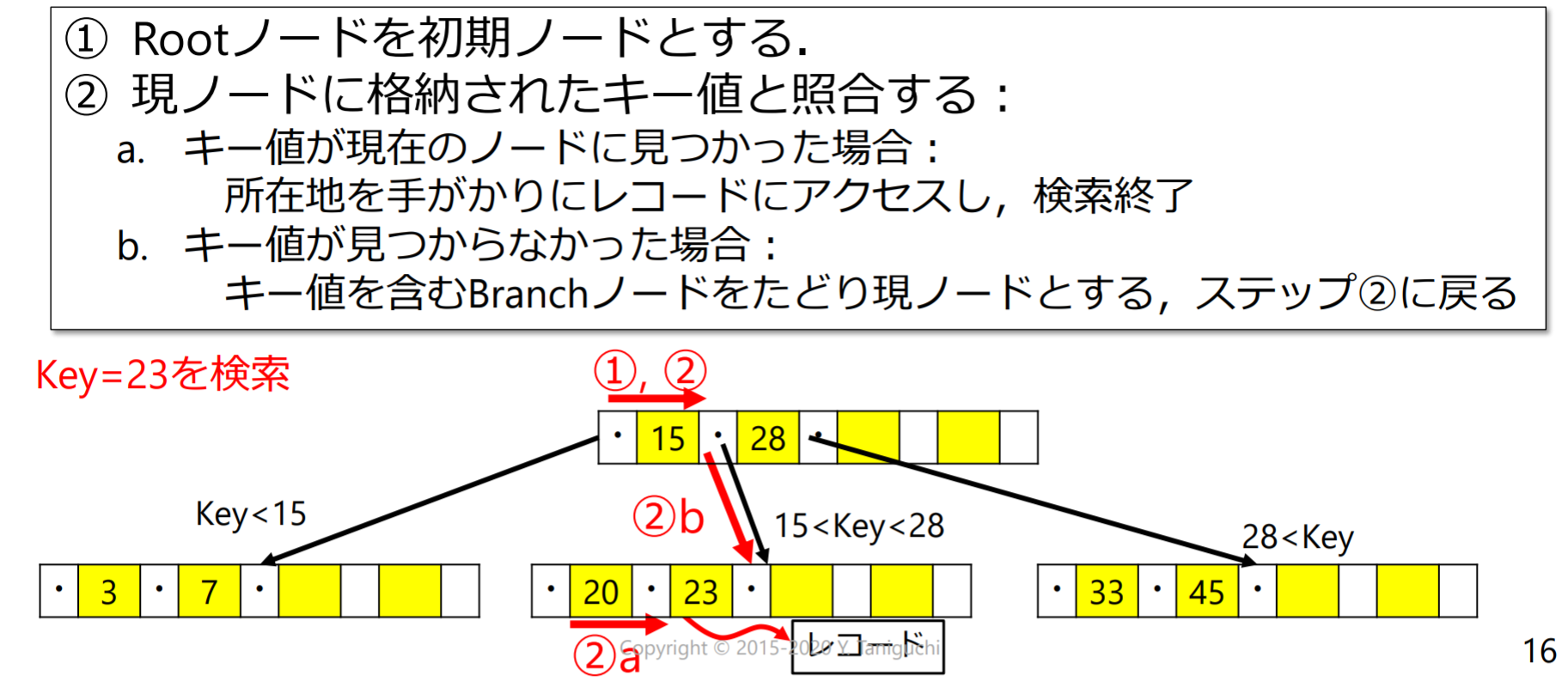
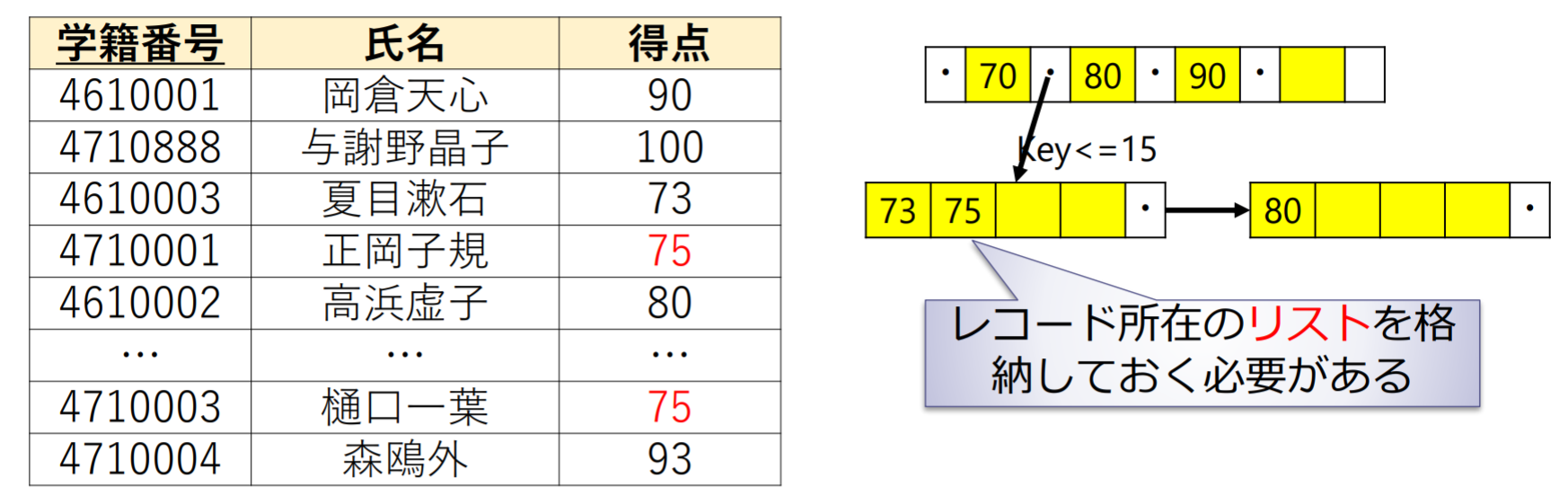
B-treeを用いたレコードの検索
- 各ノードにはキー値とコード所在を固定数まで格納可能
- レコード:ページ番号とスロット番号
- キー値は整列している
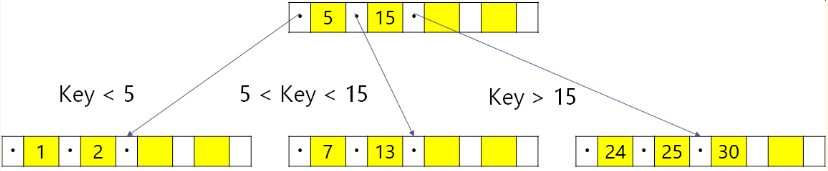
B-treeへのレコード挿入

B-treeインデックス
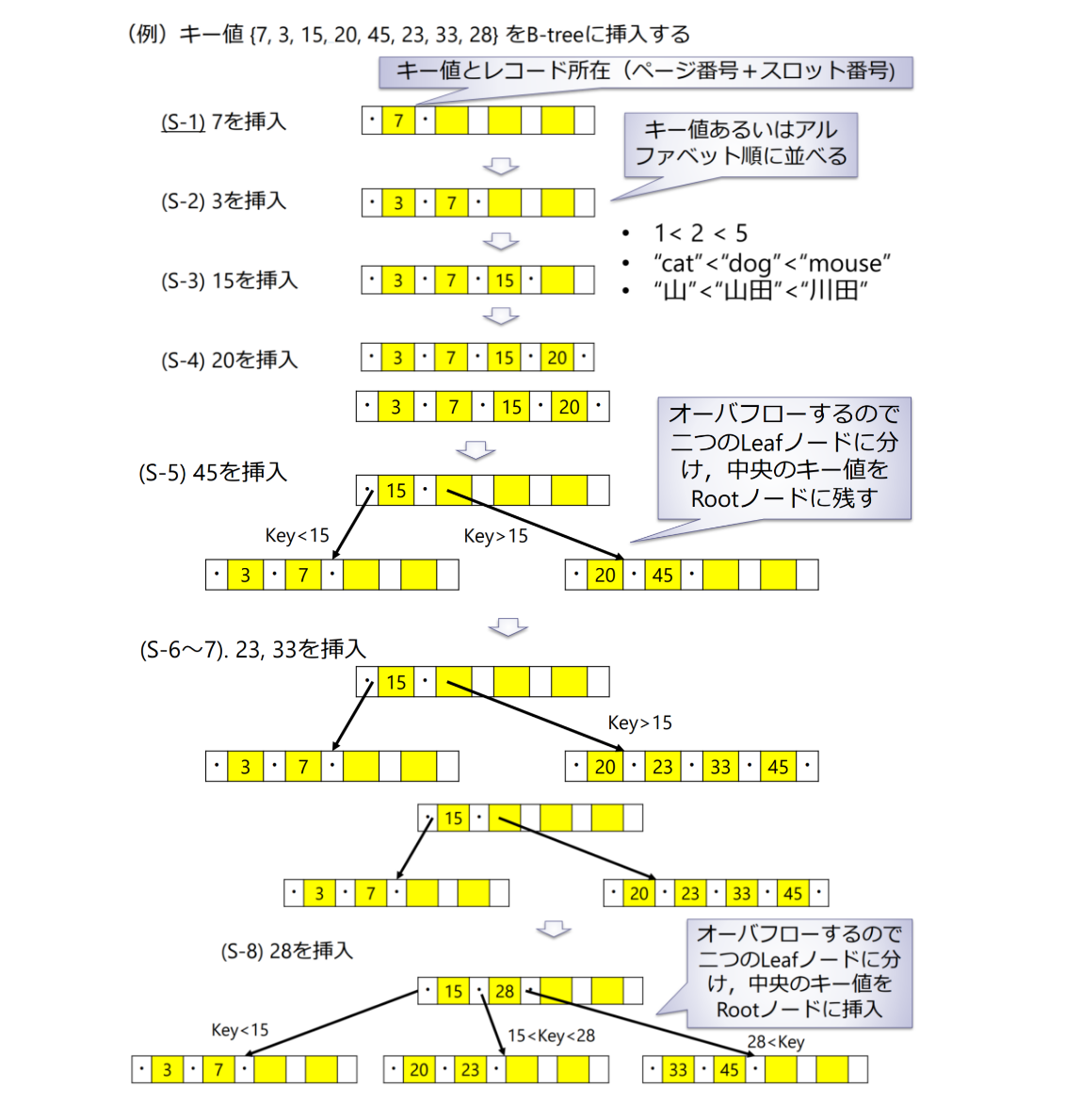
B+ treeインデックス
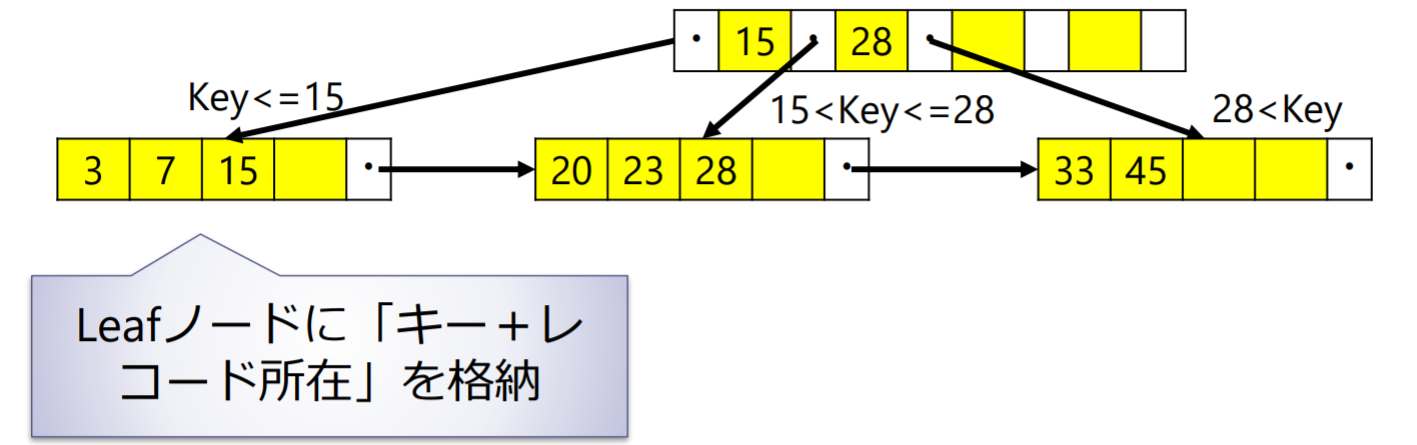
B+treeインデックス:Leafノードにキーに対応したデータ所在を持たせる方式(B-treeインデックスでは,Root, Branchノードにも「キー値+レコード所在」を保持する)
B-tree/B+treeの特徴
- 高速な一致検索が可能
- eg. 学籍番号が469999の学生を検索
- 高速な範囲検索が可能
- eg. 年齢が20未満の学生を検索
- eg. 生年月日が2000/4/1~2001/3/31までの学生 (Between句)
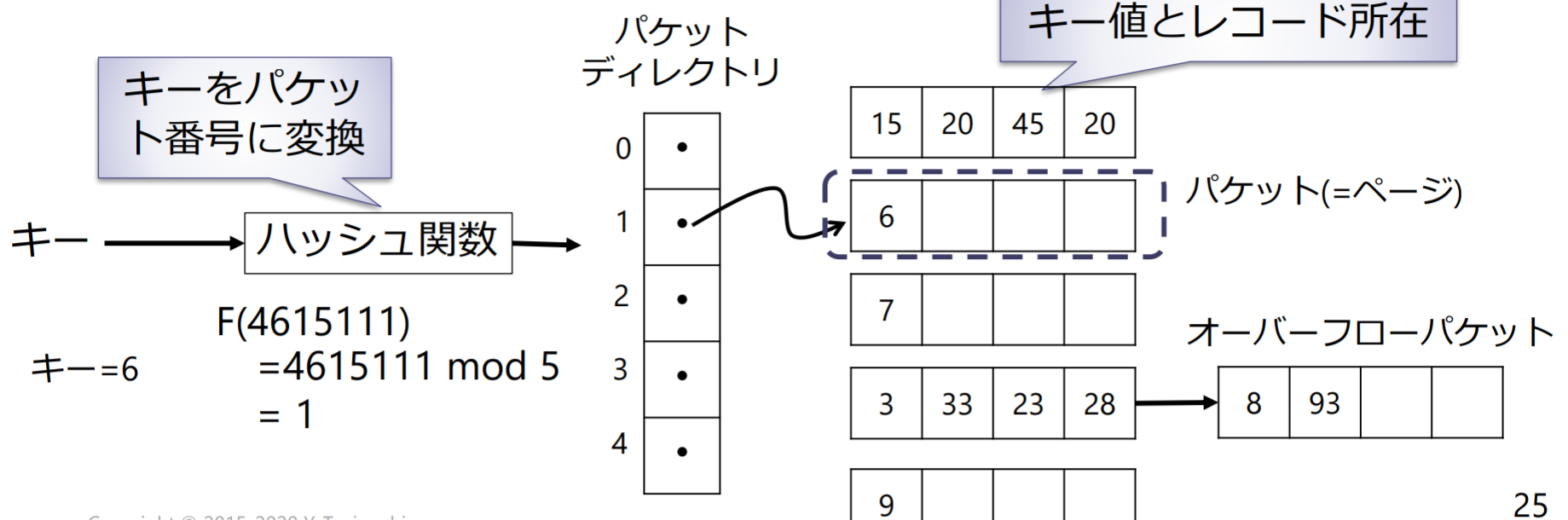
ハッシュインデックス
ハッシュ関数:任意の長さのデータを固定長のデータに変換する関数
ハッシュ関数を用いて,パケット番号からパケットキーをレコード所在に変換
パケットに空きがなくなったらオーバーフロー処理が必要 検索効率の悪化
- 動的ハッシング:キーのパケットへの割り当てを動的に決定
- 静的ハッシング:ハッシュ関数は固定
「B-tree,B+tree」と「ハッシュ」インデックスの比較:
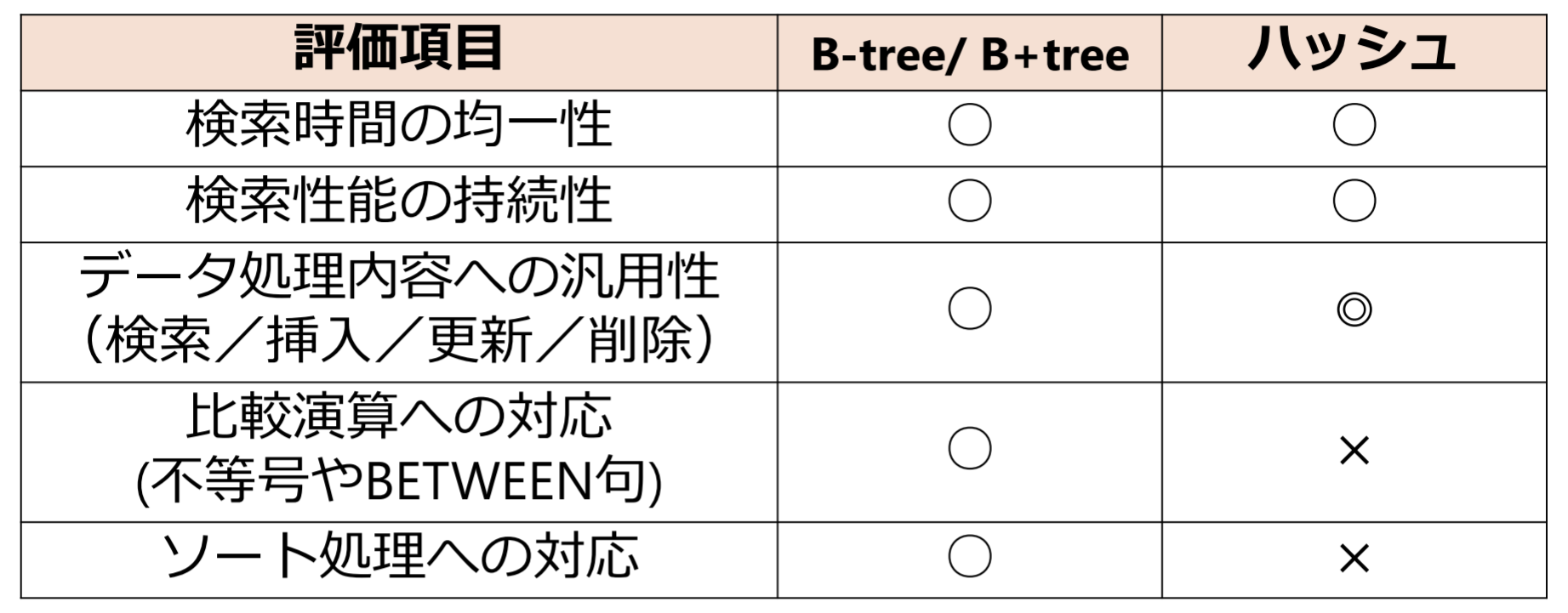
2次インデックス
- 主キー以外の属性に対してインデックスを付与すること
- 検索キーに対して複数の行が抽出されるので,一つのキーに対して複数のレコード所在を格納する必要がある
SQLでのインデックスの作成
1 | create [unique] index インデックス名 [using method] on テーブル名(属性1, …); |
- MySQL,PostgreSQLではインデクスの種類を選べる(btree, index, …)
課題9.1
キー値 [25, 1, 15, 7, 24, 30, 2, 13, 5, …]をこの順にB-treeに挿入するとどのようになるか.ノードには4つまでのキー値を格納するものとする.
外部記憶装置の種類
記録メディアによる分類
- 磁気ディスク:HDD (Hard Disc Drive)
- 光学式ディスク:CD (Compact Disc), DVD (Digital Versatile Disc), BD(Blue-ray Disc)
- 半導体メモリ: SSD (Solid State Drive)

接続インタフェースによる分類
- DAS: Direct Attached Storage
- NAS: Network Attached Storage
- SAN: Storage Area Network

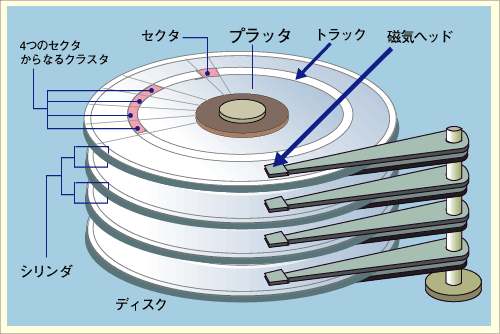
ハードディスク
- トラック:ディスク上のデータを書き込む円周部分
- セクタ:読み書きの単位 (512~4096バイト)
- ブロック:固定数の連続したセクタから構成される単位(初期化の際にサイズが決まり,通常は0.5, 1, 2, 4Kバイト)
- シリンダ:トラックを縦に並べたもの
HDDの平均アクセス時間
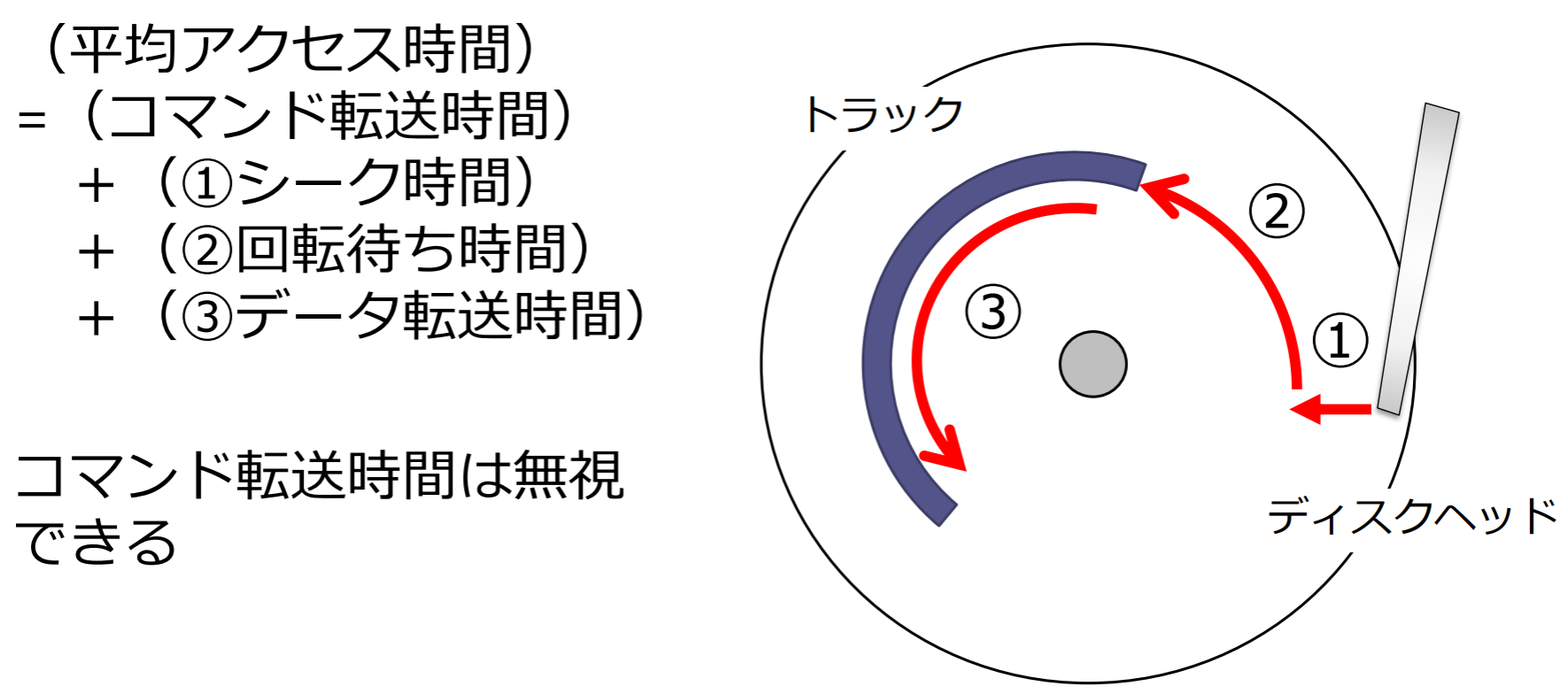
平均アクセス時間の計算
回転速度:5000rpm(=rotations per minute; 回転/分),平均シーク時間=20ミリ秒, 1トラックあたりの記憶容量=16000バイト,1ブロック4000バイトのデータを転送するために必要な平均アクセス時間は?
平均回転待ち時間は、ディスクが半回転する時間である
1トラックあたりの記憶容量は16000バイト,ブロックの容量は4000バイトだから,1トラックは4(=16000 / 4000)ブロックから構成される
- ディスクが1回転する時間は12ミリ秒(60 / 5000)
- 平均回転待ち時間は6ミリ秒(60 / 5000 / 2)
- 1トラックあたりの(データ転送時間)は12ミリ秒
- 1ブロックあたりの(データ転送時間)は3ミリ秒
平均アクセス時間 = 平均シーク時間 + 平均回転待ち時間 + データ転送時間 = 20 + 6 + 3 = 29ms
課題9.2
回転速度:5000回転/分,平均シーク時間=20ミリ秒, 1トラックあたりの記憶容量=16000バイト, 1ブロック4000バイトとする
- 連続する3ブロックのデータを転送するために必要な平均アクセス時間は?
- 20+6+3*3=35ms
- 断片化した3ブロックのデータを転送するために必要な平均アクセス時間は?
- (20+6+3)*3=87ms
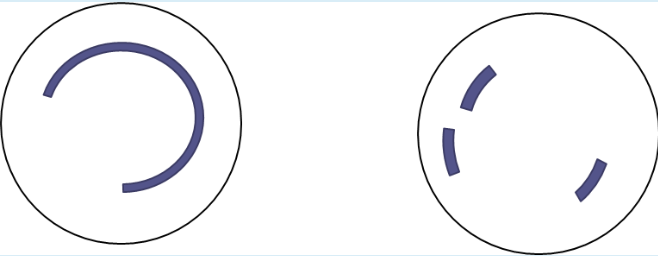
断片化していると倍時間がかかる
transaction
トランザクション(transaction):データベースの状態を整合性のある状態から,別の整合性のある状態に変化させるデータ操作の並び(データ操作の順番の入れ替えはない)
ACID特性
- 原子性(atomicity):トランザクションがDBを更新後の状態に遷移させるか,あるいは全く処理を行わないかのいずれか
- 一貫性(consistency):整合性のあるDBに対してトランザクションが実行された場合,完了後にも整合性が維持される
- 分離性(isolation):あるトランザクションは他のトランザクションに影響を与えないように,分離された状態で実行される
- 持続性(durability):一旦コミットされたトランザクションの更新は,その後の障害などで失われることがない
スケジュールと直列化可能性
同時実行制御(concurrency control)
同時実行(concurrent execution):複数のユーザが同時にデータベースにアクセスすること
- 利点
- CPUとI/Oは並列に実行できるので,ディスクとCPUが暇な(idle)時間の量を減らせる
- 短いトランザクションと長いトランザクションを交互に実行すると,通常は短いトランザクションが早く終わり,長いトランザクションの後回しになることが少ない
- 欠点
- 実行するタイミングによっては不整合が発生し,分離性が維持できなくなる
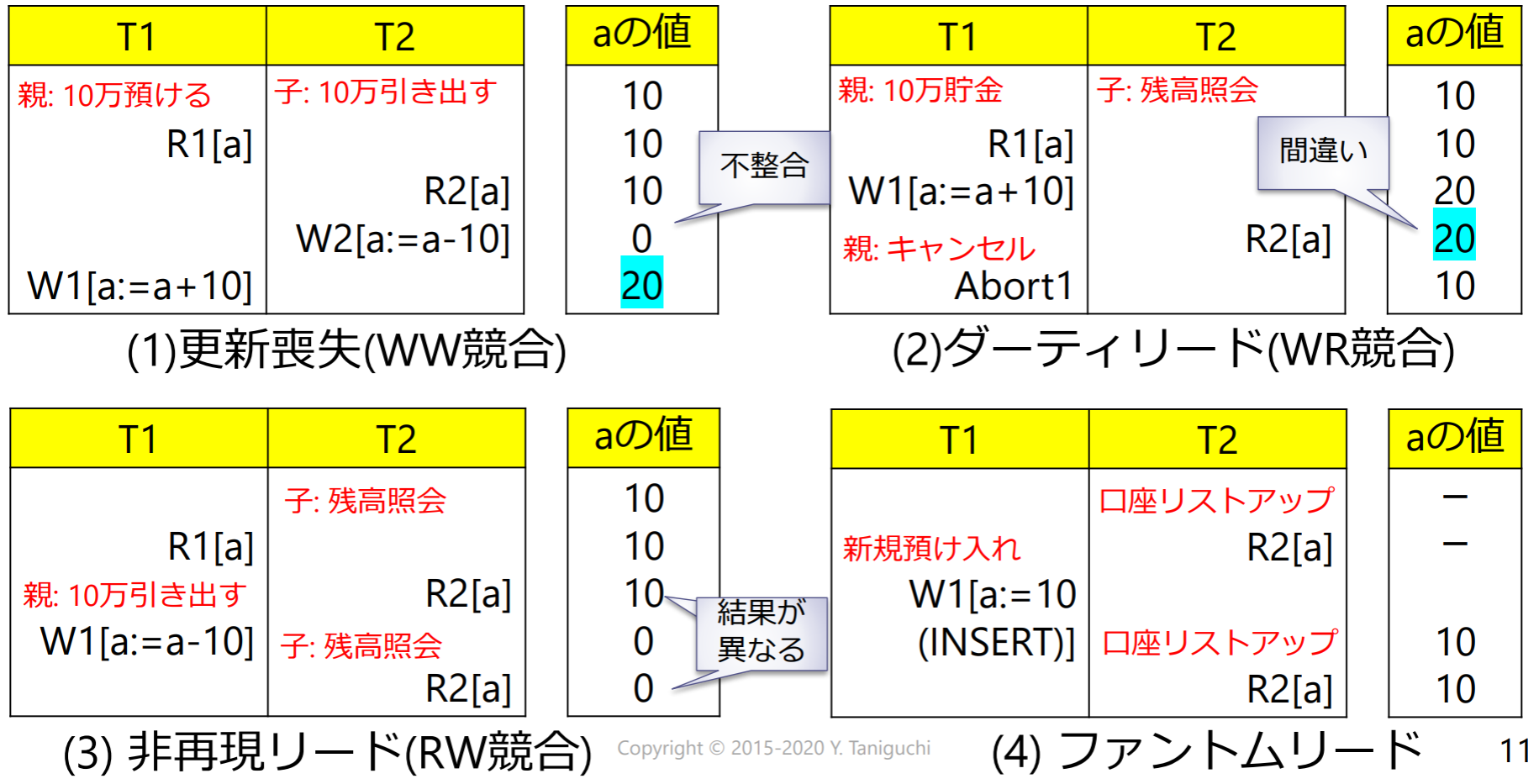
- 脏读(Dirty reads): 有俩事务T1,T2。如果T1读了一条数据,这条数据是T2更新的但是还没提交,突然T2觉得不合适进行事务回滚了,也就是不提交了。此时T1读的数据就是无效的数据
- 不可重复读(Non-repeatable reads): 有俩事务T1,T2。如果T1读了一条数据,之后T2更新了这条数据,T1再次读取就发现值变了
- 幻读(Phantom reads): 有俩事务T1,T2。如果T1读了一条数据,之后T2插入了一些新的数据,T1再次读取就会多出现一些数据
スケジュール
スケジュール:トランザクションのデータベースに対するデータ操作の順序
- データ操作(Read, Write, Commit, Abort)の順序
- トランザクション内で操作順序は入れ替えない
直列スケジュールと非直列スケジュール
直列スケジュール(serial schedule):複数のトランザクションを直列に実行
如下图,按照顺序(T1 -> T2)执行的schedule是直列スケジュール

競合操作(conflict)
スケジュールの中の二つの操作について,次の場合に競合(conflict)があるという
- 二つの操作は別のトランザクションに属する
- 二つの操作は同じデータにアクセスする
- 二つの操作のうち少なくとも一方はデータを更新する
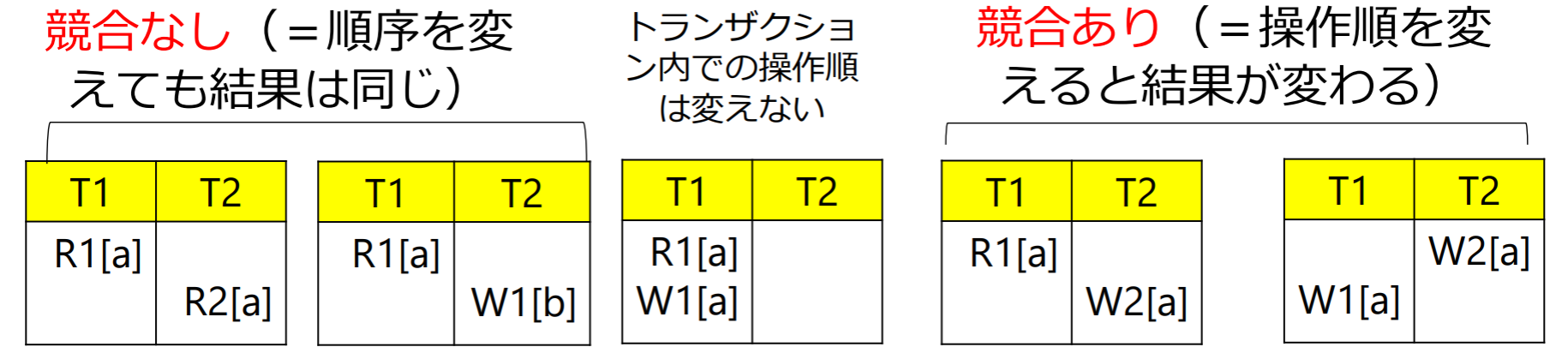
冲突操作:不同的事务对同一数据的读写操作和写写操作
- 同一事务的两个动作冲突:
- 不同事务对同一数据库元素的写冲突:
- 不同事务对同一数据库元素的读和写冲突:
- 这些都是冲突操作:
課題10.1
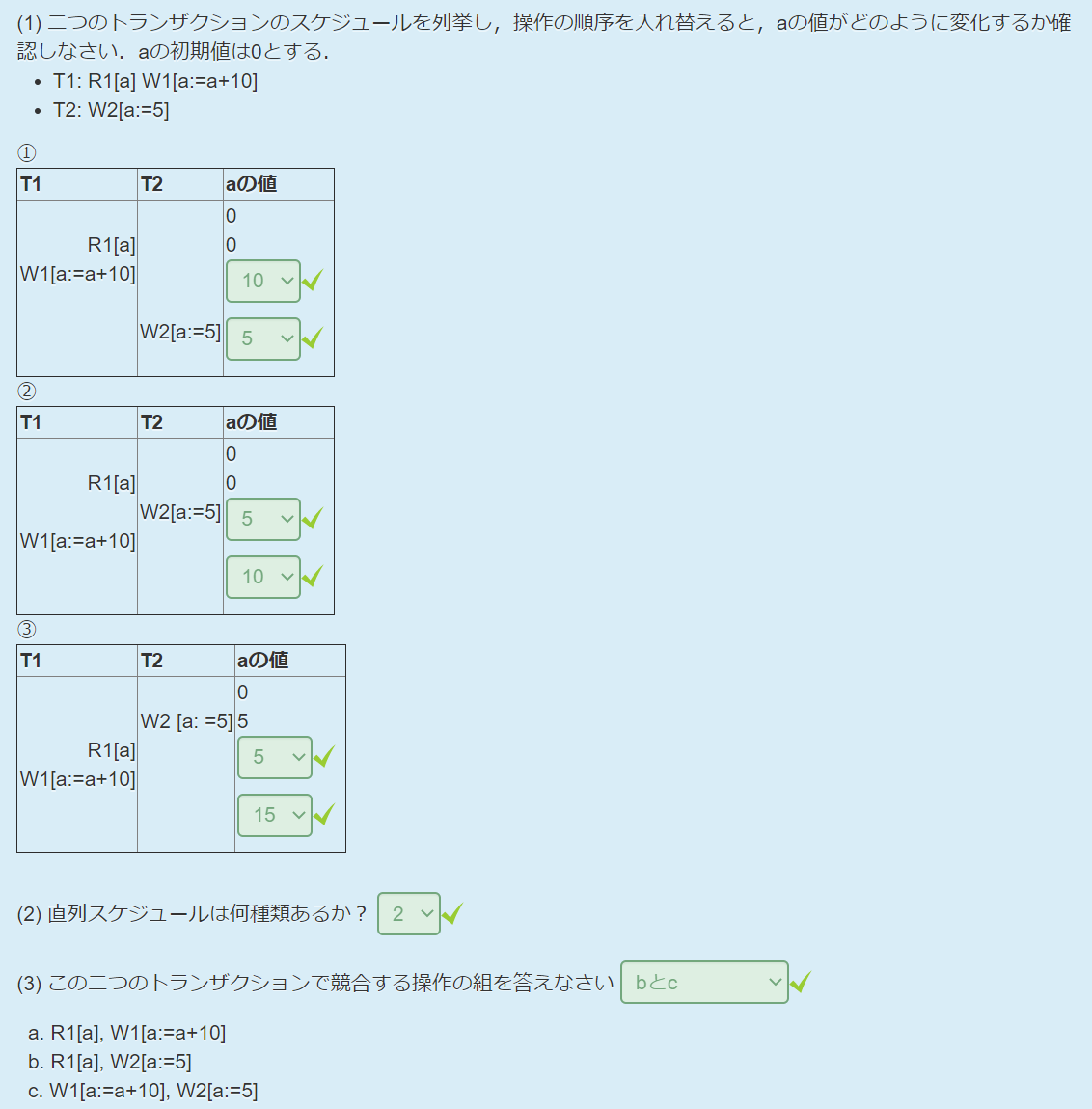
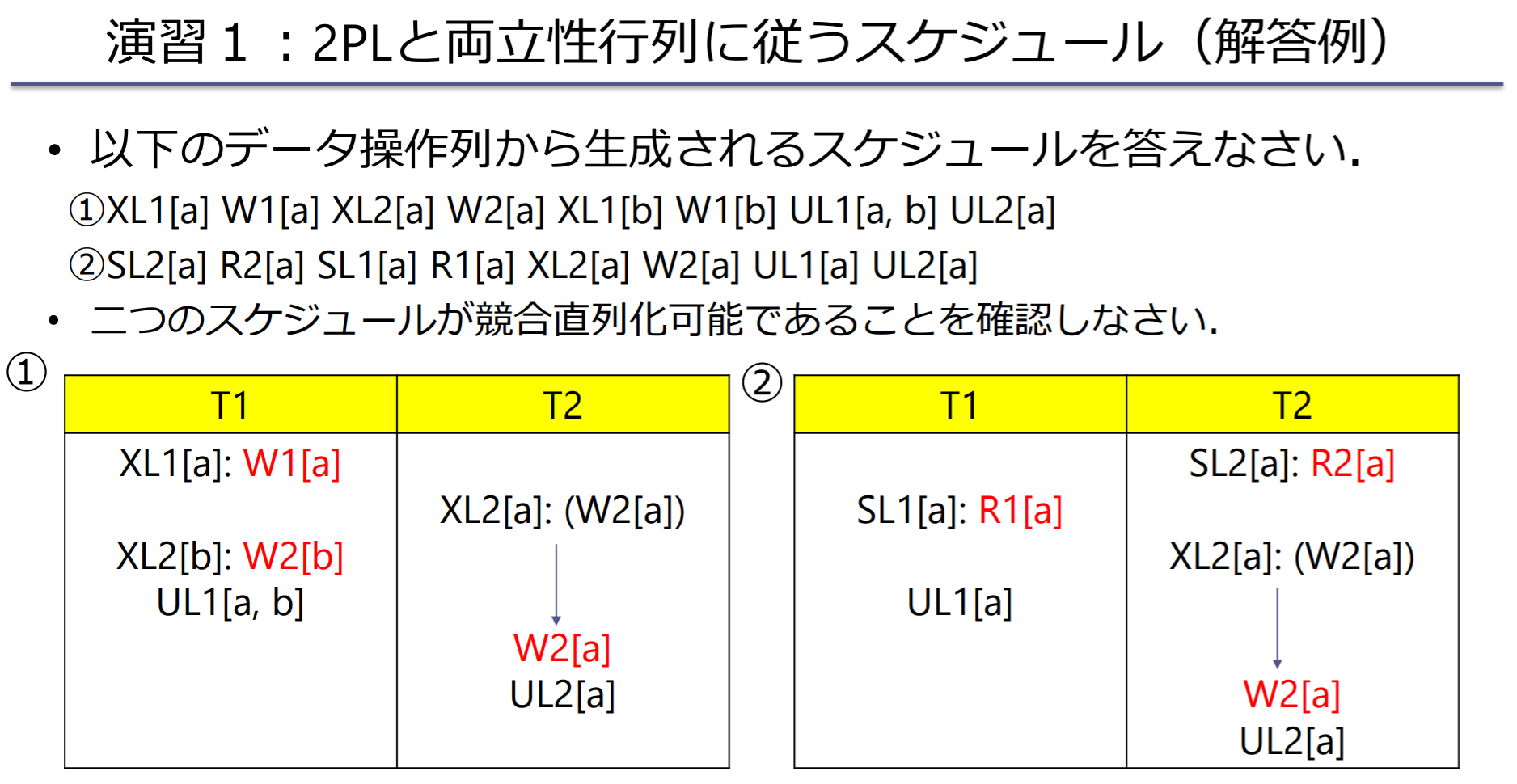
直列化可能スケジュール
直列化可能スケジュール(serializable schedule):非直列スケジュールとしてトランザクションを同時実行しながら,直列スケジュールと実行結果が等価なもの
- ビュー等価(view equivalence)
- 競合等価(conflict equivalence)
可串行化调度:多个事务的并发执行是正确的,当且仅当其结果与按某一次序串行执行这些事务时的结果相同,称这种调度策略为可串行化调度。可串行性是并发事务正确调度的准则。
ビュー等価
スケジュール (直列)と (非直列)は次の条件が成り立つ場合,ビュー等価である
- において が先行する の結果(あるいは の初期値)を読み出すならば, においても同様
- 各データ について, において最後の更新が ならば においても同様
どんな初期状態から始めても直列スケジュールと最終状態が等しくなるが, 与えられたスケジュールがビュー直列化可能か否かの判定はNP完全
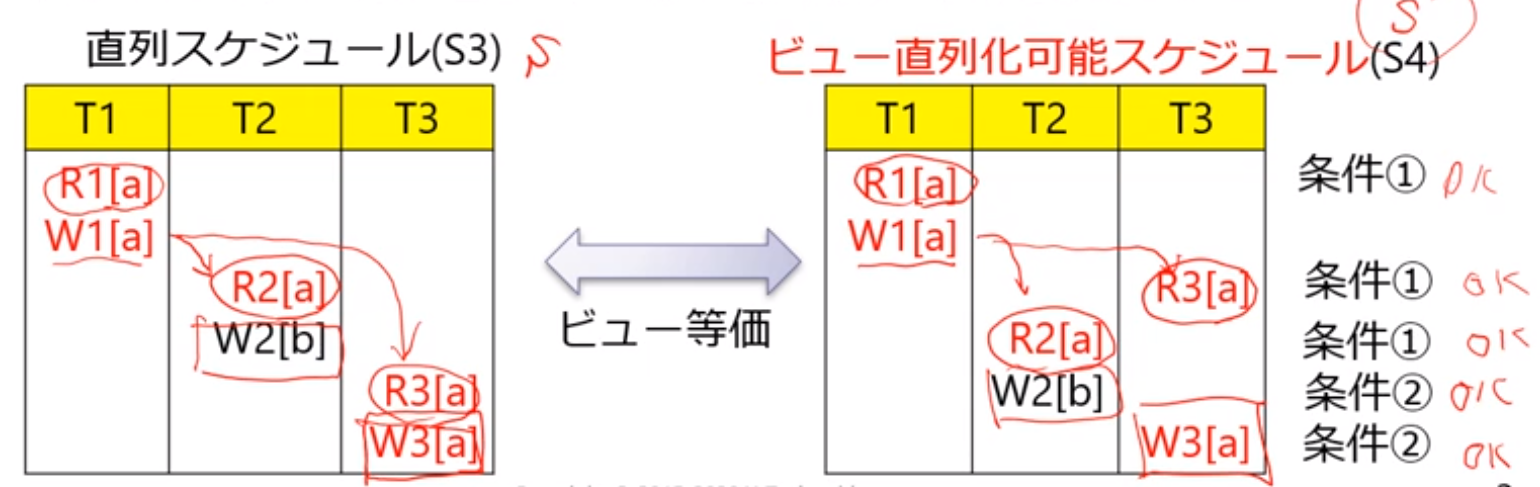
競合等価(conflict equivalence)
競合等価:スケジュール (直列)と (非直列)は競合するデータ操作の順番が同じ, 競合等価であればビュー等価
競合直列化可能スケジュール:直列スケジュールと競合等価なスケジュール
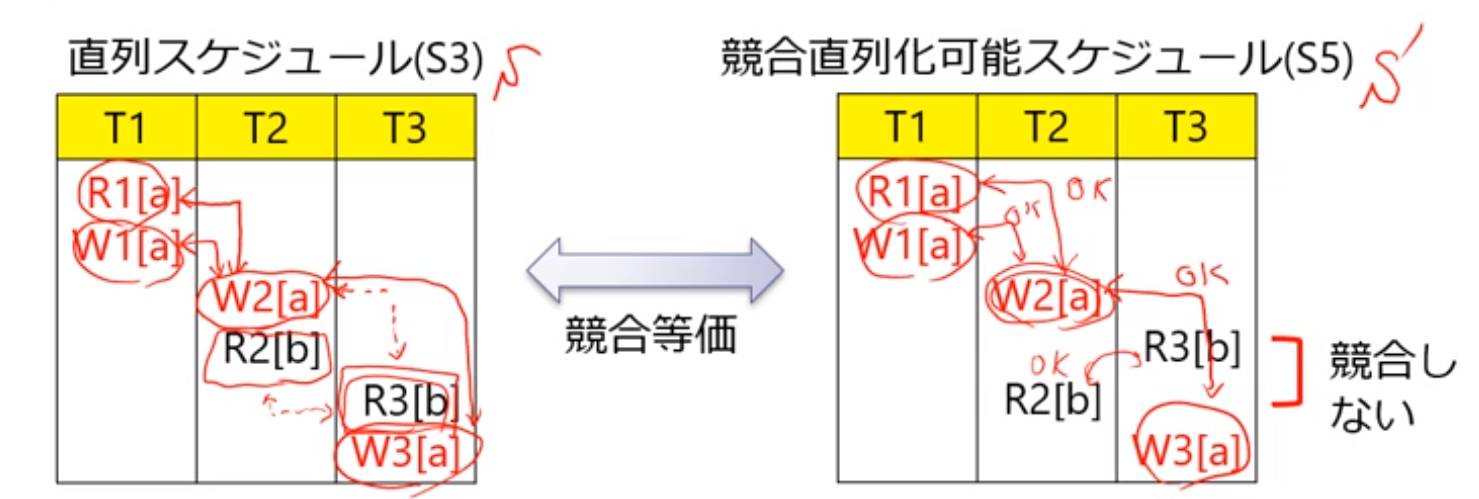
- 分别看冲突的次序是否一致即可
冲突可串行化调度:一个调度S在保证冲突操作的次序不变的情况下,通过交换两个事物不冲突操作的次序得到另一个调度S’,如果S’是串行的,称调度S为冲突可串行化的调度
競合直列化可能性の判定
先行グラフ(precedence graph):
- すべてのトランザクションをグラフの頂点として記載する
- トランザクションTjが,Tiによって更新Wされたデータを読み出すRならばTiからTjに有向辺を引く
- トランザクションTjが,Tiによって読み出されたRデータに対して更新Wを行うならば, TiからTjに有向辺を引く
- トランザクションTjが,Tiによって更新Wされたデータに対して更新Wを行うならば, TiからTjに有向辺を引く
- スケジュールのすべての操作に対して,2から4を行った結果,グラフに閉路(cycle)がなければ競合直列化可能であり,閉路があれば競合直列化可能ではない

前趋图画法:节点: S中的事务,弧: whenever
- 涉及同一数据库元素
- 至少一个是写动作
判断是否冲突可串行化:如果存在环, S 不是冲突可串行的, 否则, S 是冲突可串行的
課題10.2
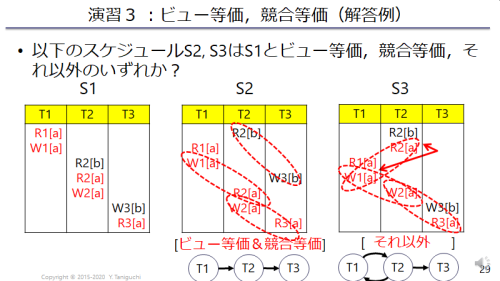
スケジュール と は競合するデータ操作の順番が同じかどうか確認する
課題10.3
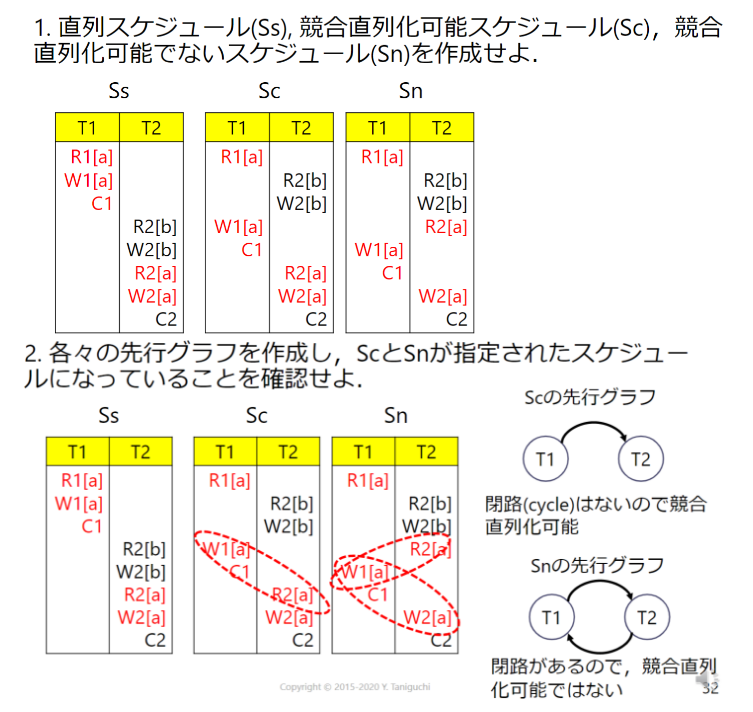
ロックによる同時実行制御
多くの場合はトランザクションを予測できないので,一般的には事前に実行スケジュールを作成できない.
- 動的に同時実行制御を行う必要がある
- ロック(lock),アンロック(unlock)による同時実行制御
共有ロックと排他ロック
共有ロック(shared lock; SL):データの読み出しを行うためのロック
排他ロック(exclusive lock; XL):データの更新を行うためのロック
既にロックされたデータに対して,他のトランザクションがロックを要求した場合,両立性行列に従ってロックが許可される

- 両方が共有ロックかけているだけロックが許可される
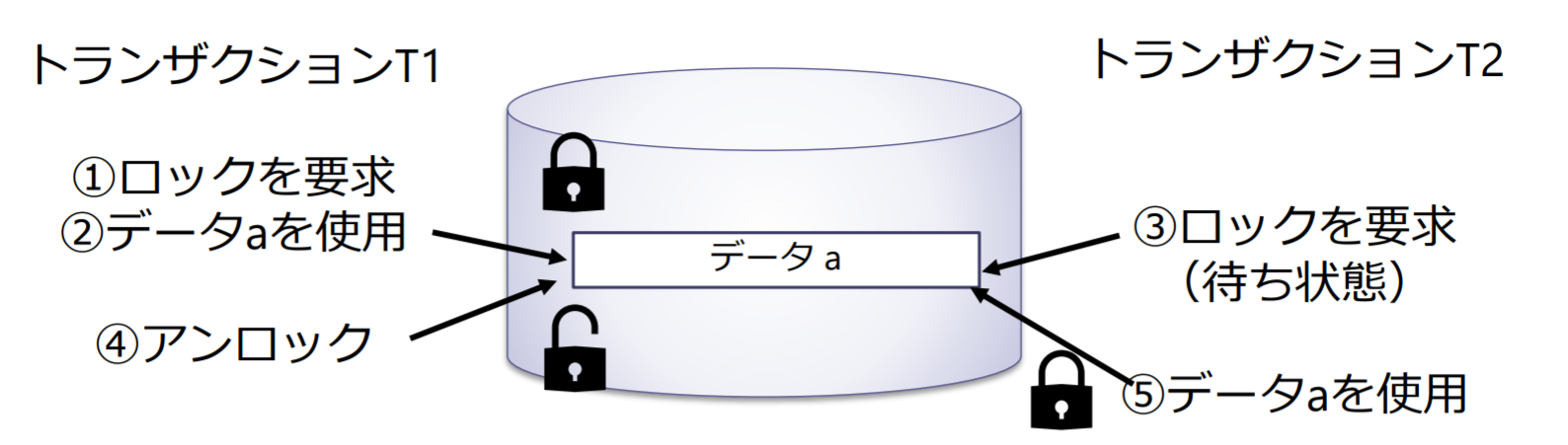
ロックの変換
アップグレード:あるトランザクションが既にかけている共有ロック(SL)を排他ロック(XL)に変換.他のトランザクションが共有ロックをかけていない場合に限る
ダウングレード:あるトランザクションが既にかけている排他ロック(XL)を共有ロック(SL)に変換
ロックの粒度
粒度(granularity):ロック対象となるデータの単位
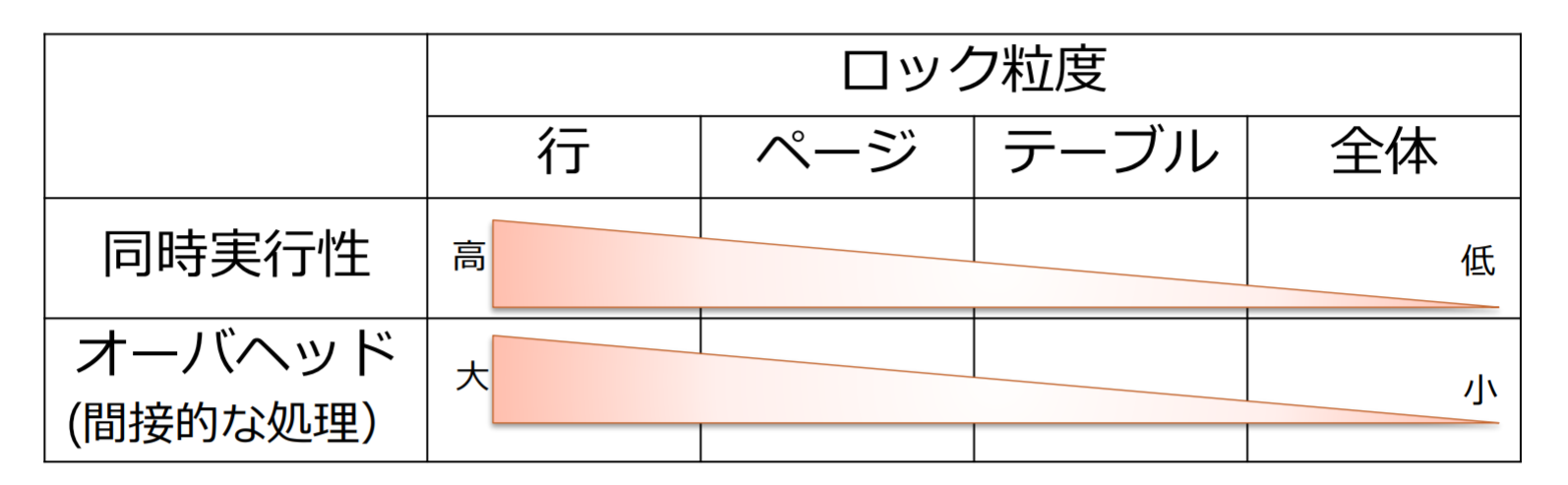
ロックの粒度が大きいとロックの制御が容易(制御に要する間接的な処理量は小さい)になるが、ロックによる待ち時間が長くなる
2相ロッキングプロトコル
ロックをかけるだけでは不整合は防げない
それぞれの読み出し,更新操作の前後でロック,アンロックを行っても不整合が生じる
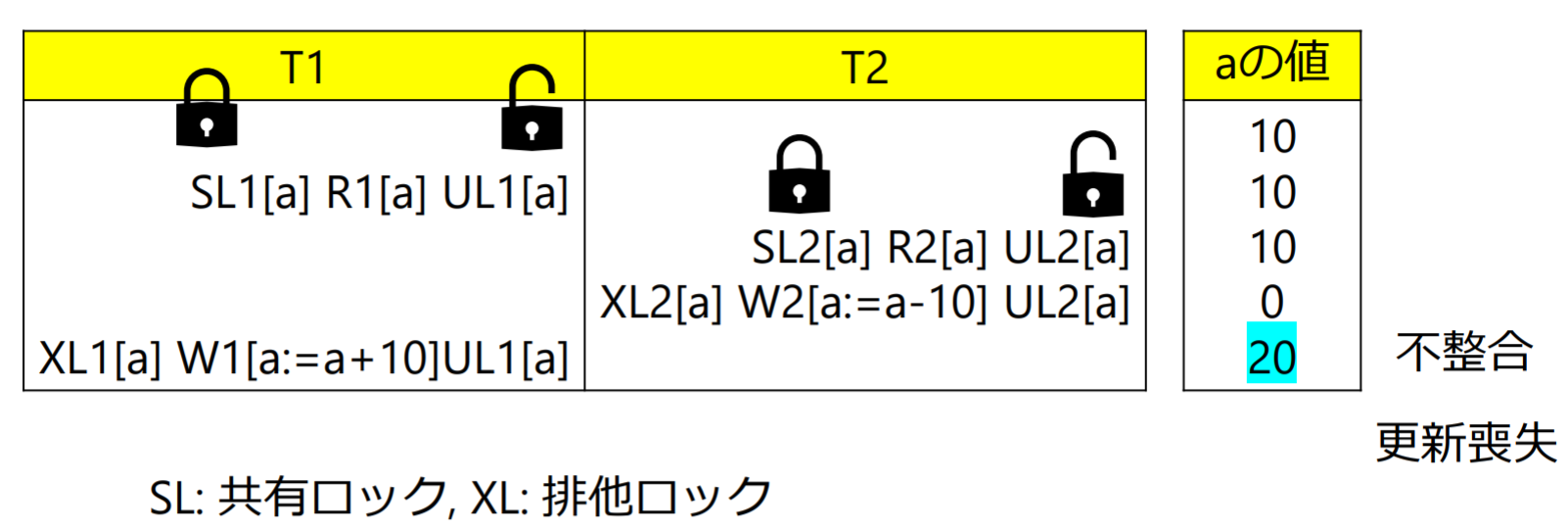
2相ロッキングプロトコル(two-phase locking protocol; 2PL):
- トランザクションはデータの操作を行う前に,対象のデータをロックしなければならない
- ロックしたデータをアンロックした後で,さらにロックしようとしてはならない(必要なデータをすべてロックするまではアンロックしてはならない)
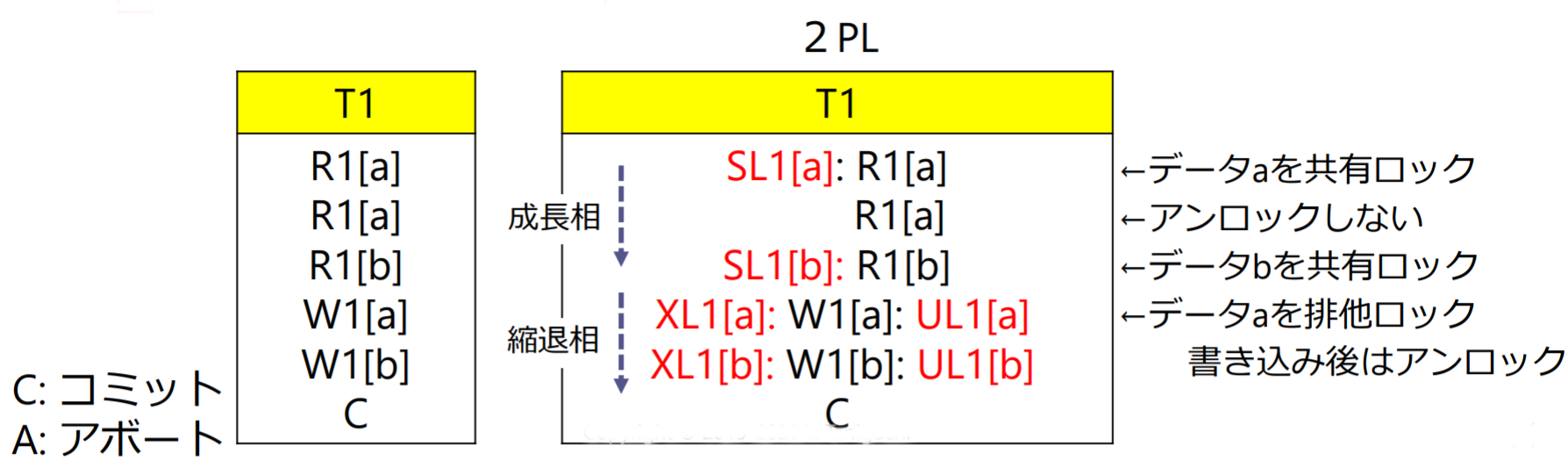
两段锁协议:
- 在对任何数据进行读、写操作之前,事务首先要申请并获得对该数据的封锁
- 在释放一个封锁之后,事务不再申请和获得任何其他封锁
2PLに従うスケジュール
2PLとロック両立性行列に従うスケジュールは競合直列化可能になる

定理:若所有事务均遵守两段锁协议,则这些事务的所有交叉调度都是可串行化的
課題10.4
連鎖的アボート
- 共有ロック(SL)を排他ロック(XL)に変換するとデッドロックが生じる場合あり 更新を前提とした読み出しの場合は排他ロックを使用 (select文のfor update句)
- アンロックのタイミングによっては,連鎖的アボート(cascading abort)が発生する(T1がアボートされるとT2もアボートする)
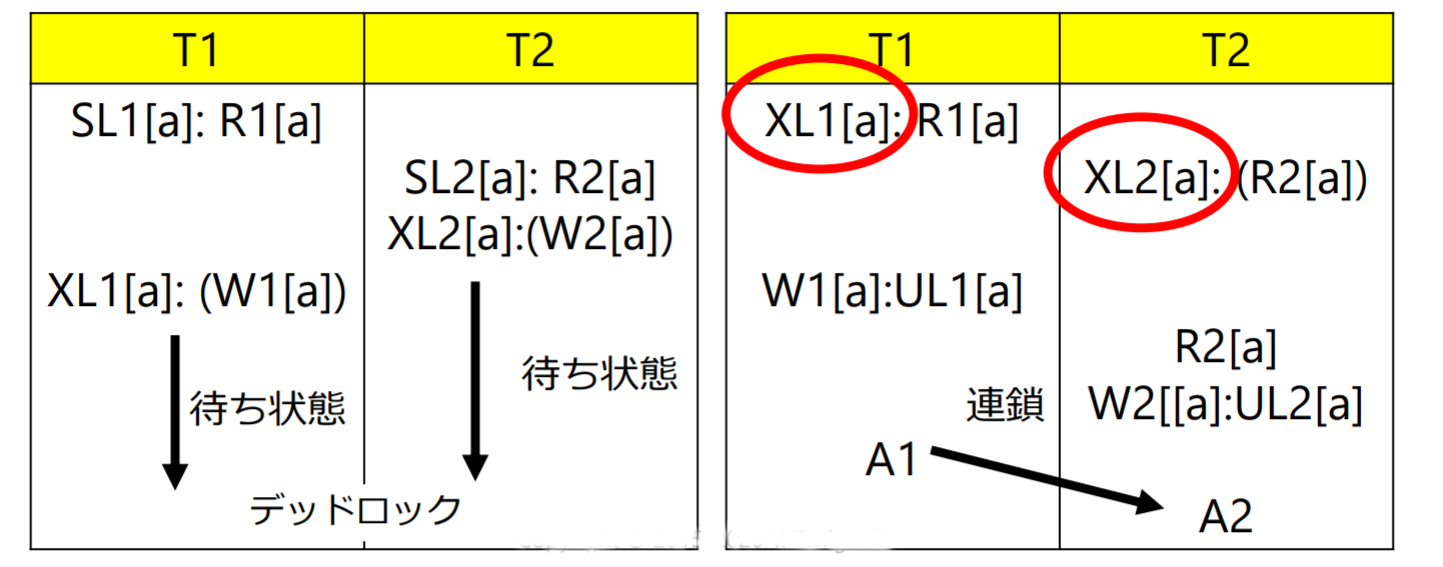
厳格な2相ロッキングプロトコル
厳格な2相ロッキングプロトコル(rigorous 2PL):コミットあるいはアボートまでアンロック操作を保留すること
- 連鎖的アボートは回避できる
- デッドロックは回避できない
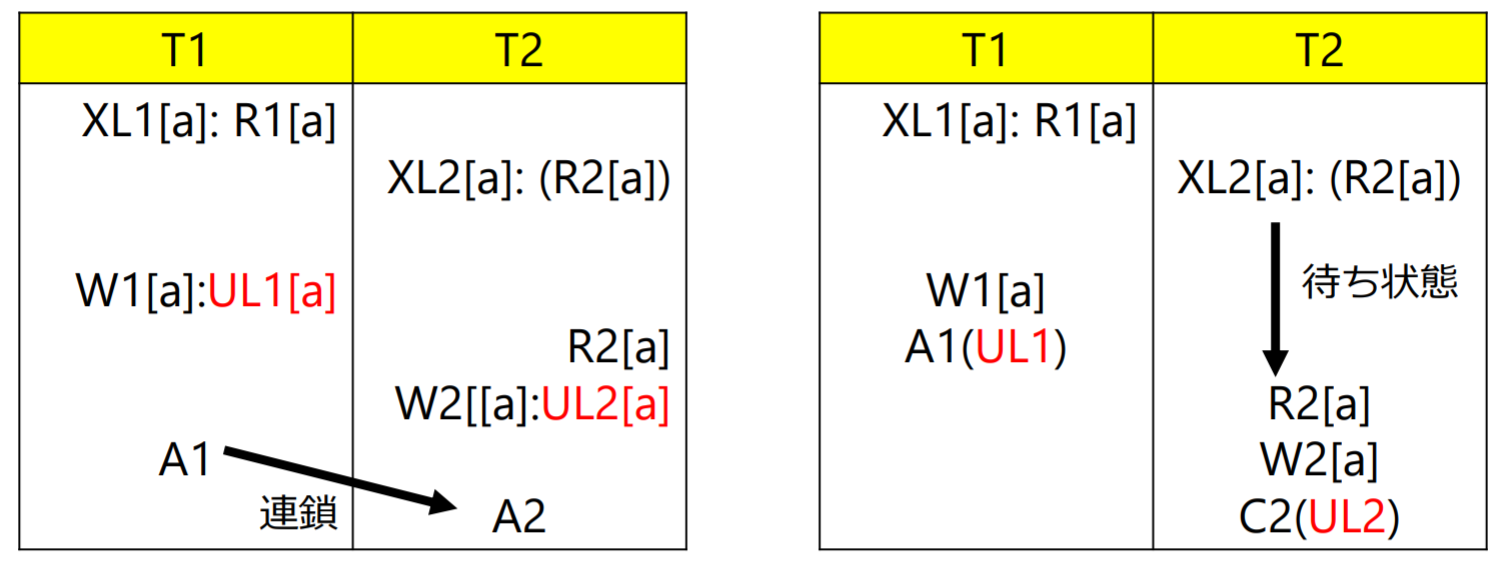
図にアボートと同時にアンロックをかけて、コミットと同時にアンロックをかけるという操作を行うと連鎖的アボートは回避できる
課題10.5
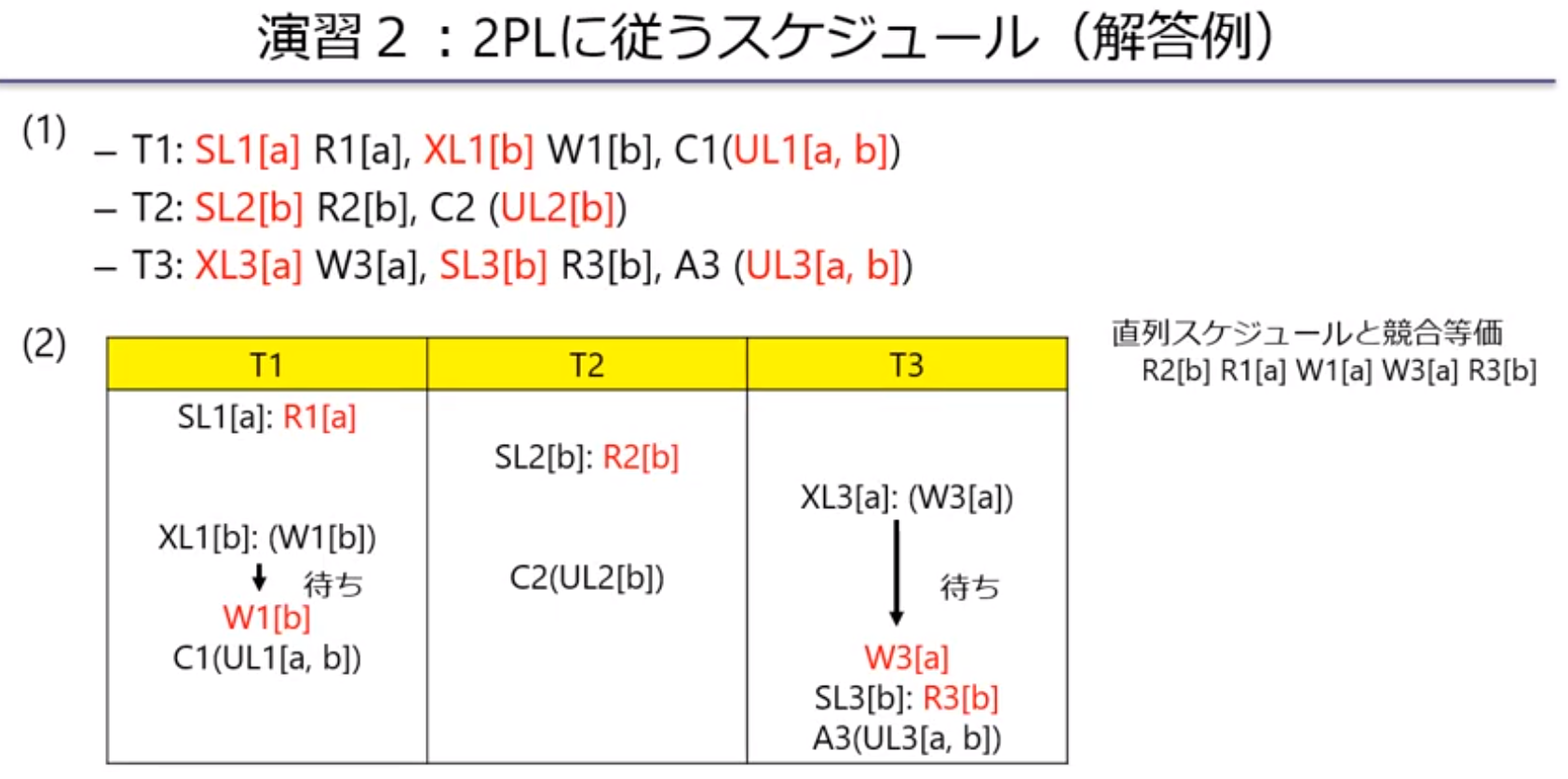
- 三つのトランザクションを考える.厳格な2PLに従うようにロック操作,アンロック操作を挿入しなさい.
- 適当な順序でデータ操作を実行した場合に生成されるスケジュールを示し,競合直列化可能スケジュールになっていること,連鎖的アボートが発生しないことを確認しなさい.
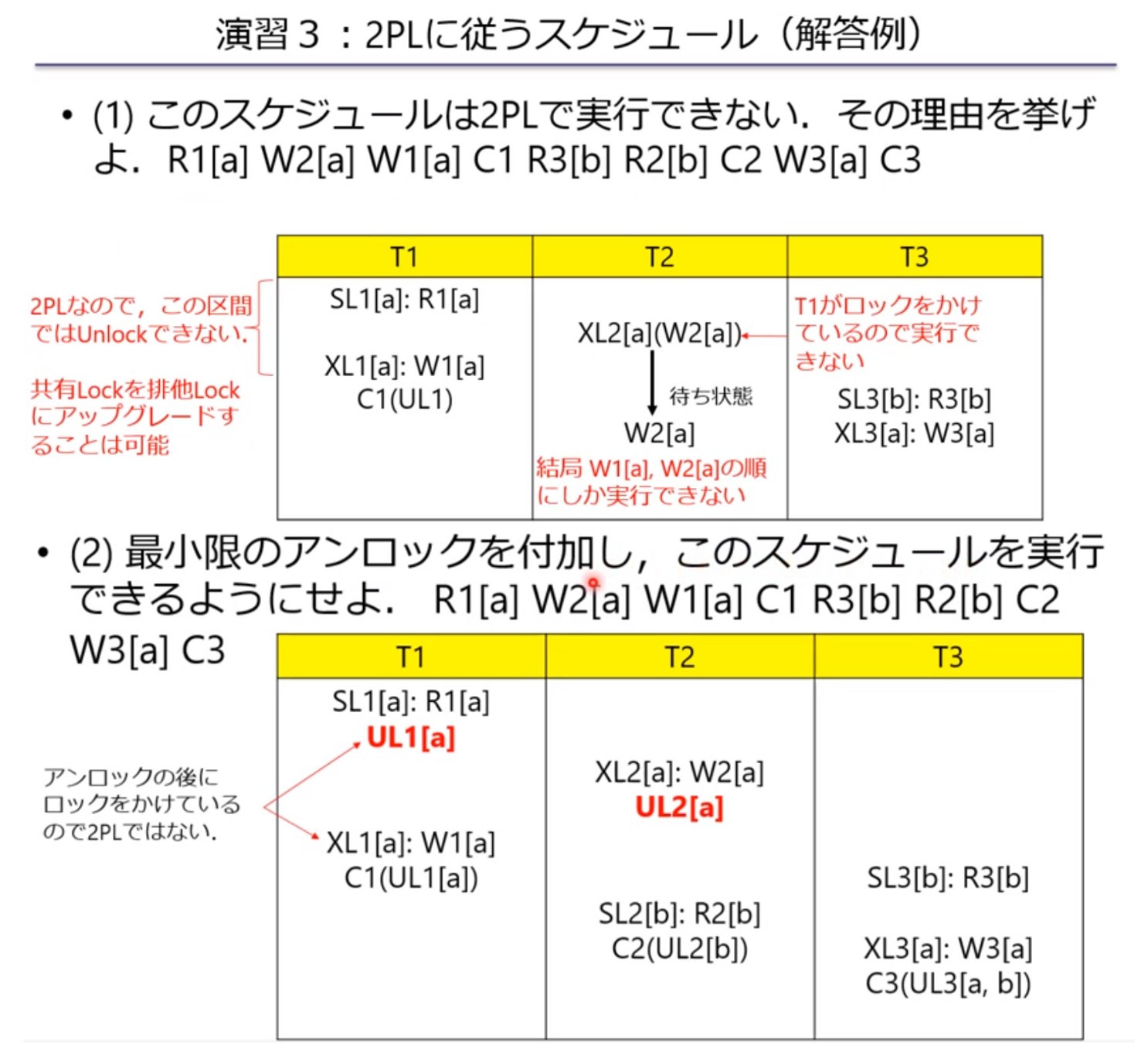
課題10.6
デッドロック
デッドロック(dead lock): 複数のトランザクションが相互に相手が必要とするデータをロックし合い,永遠に相手のアンロックを待つ状態
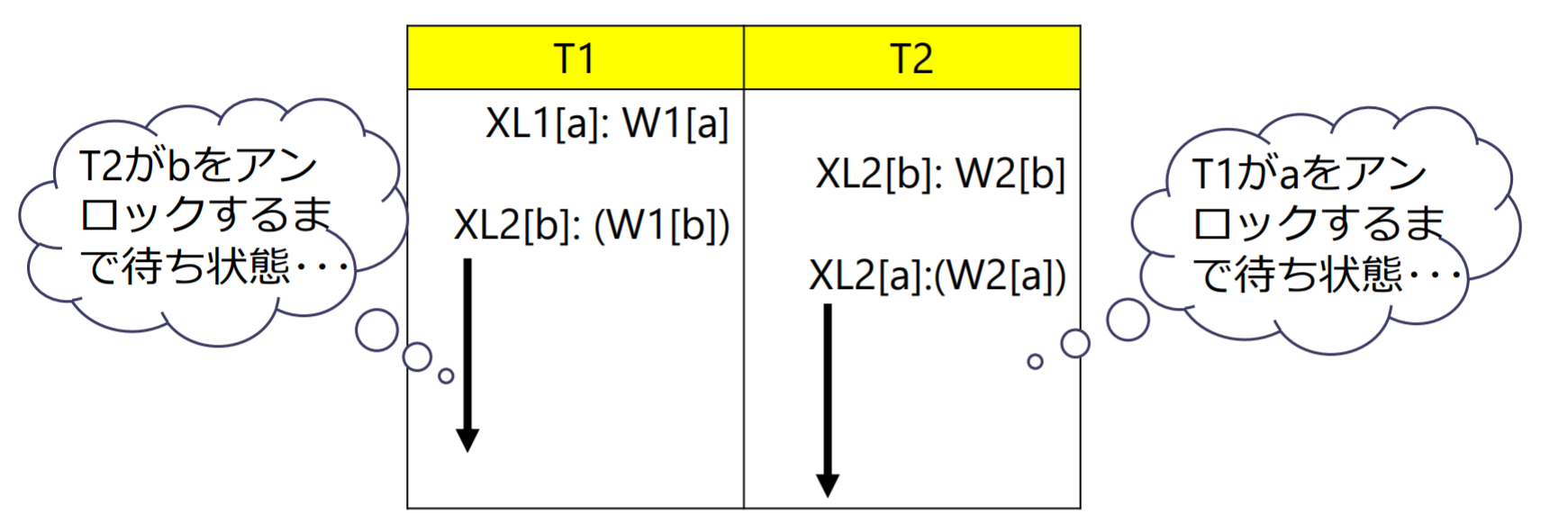
遵循两段锁协议的事务有可能发生死锁。
事务T1 、T2同时处于扩展阶段,两个事务都坚持请求加锁对方已经占有的数据,导致死锁。
为此,又有了一次封锁法。一次封锁法要求事务必须一次性将所有要使用的数据全部加锁,否则就不能继续执行。因此,一次封锁法遵守两段锁协议,但两段锁并不要求事务必须一次性将所有要使用的数据全部加锁,这一点与一次性封锁不同,这就是遵守两段锁协议仍可能发生死锁的原因所在。
デッドロックに対する対処方法:
- デッドロックを検出し,一方のトランザクションをアボートした後で再試行する
- デッドロックを回避するために,一定の規約に従ってロック,アンロックを行う
デッドロックの検出
- タイムアウトによる方法
- 待ち時間を監視し,待ち時間が設定された時間以上になった場合にデッドロックが発生したと判断
- 待ちグラフ(wait-for graph)による方法
- 先行グラフと同じような有向グラフを用いて判定
- デッドロックは3つ以上のトランザクションによっても構成される
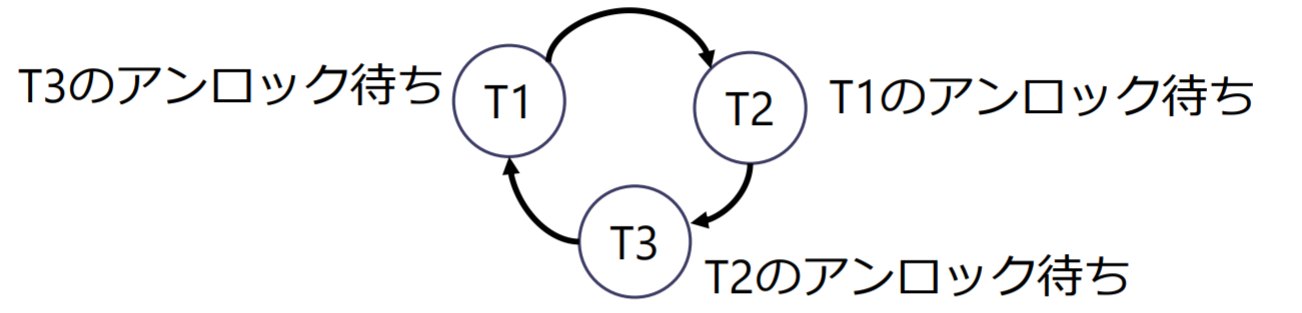
デッドロックを回避
- 事前に必要なすべてのデータをロックする方法:1つでもロックできないデータがあれば,一定時間後に再試行
- スループット低下
- 決まった順序に基づいてロックする方法:データに順序関係を設定しておき,その順にロックしていく
- 時刻印(time stamp)を用いる方法:トランザクションの開始時刻により一意の時刻印を与える
トランザクションT1がロックしようとしたときに,トランザクションT2が既にロックを獲得していたという状況を考える
- ウェイト・ダイ(wait-die)方式:T1の時刻印がT2よりも早い(T1の優先度が高い)場合はT1はT2のアンロックを待つ,遅い(T2の優先度が高い)場合にはT1をアボートする
- ワウンド・ウェイト(wound-wait)方式:T1の時刻印がT2よりも早い(T1の優先度が高い)場合にはT2をアボート(優先度の低い相手をアボートさせる),遅い場合にはT1はT2のアンロックを待つ
分離レベルと多版型同時実行制御
分離レベル
許容する不整合のレベルを分離レベル(isolation level)として設定可能
- デフォルトの分離レベル:MySQL(InnoDB) … REPEATABLE READ, PostgreSQL …READ COMMITTED
| 分離レベル | ダーティリード | 非再現リード | ファントムリード |
|---|---|---|---|
| READ UNCOMMITED | |||
| READ COMMITED | |||
| REPEATABLE READ | |||
| SERIALIZABLE |
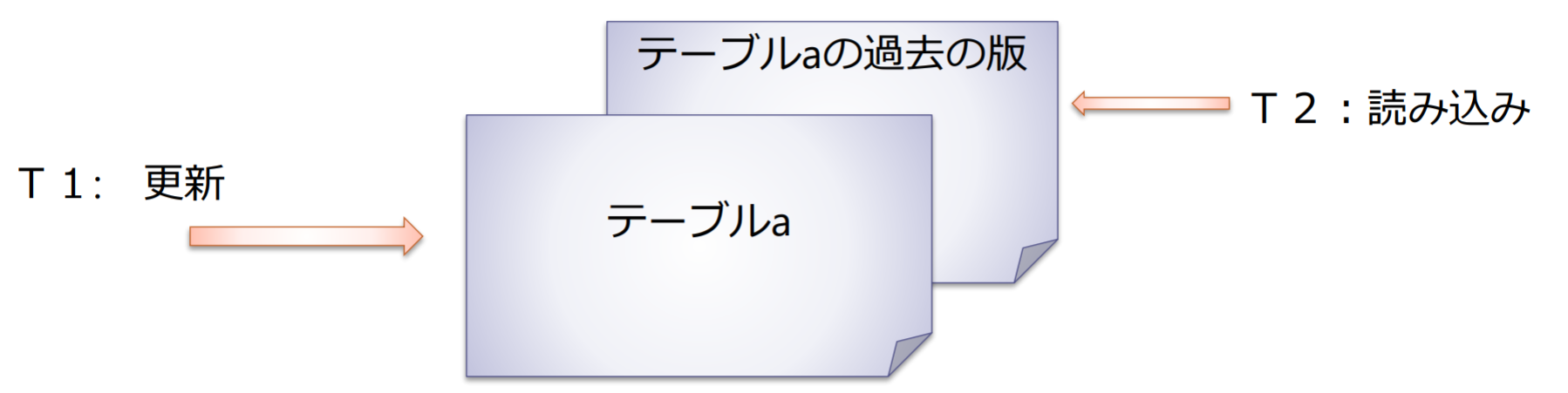
多版型同時実行制御
多版型同時実行制御(multi version concurrency control: MVCC): データベース更新前の過去の版(version)をスナップショット(snapshot)としてとっておき,読み出しはロックせずに実行する
- MVCCを採用しているRDBMS: Oracle, PostgreSQL, MySQLなど
NOSQL
NOSQL: 構築したいアプリケーションによっては必ずしもリレーショナルデータベースが適しているとは限らず,他に適したデータベースの選択肢がある
代表的なNOSQLデータベース:
- Google
- 分散ファイルシステム GFS (Google File System)
- データ格納方式 Bigtable
- 並列データ処理技術 MapReduce
- Amazon
- DynamoDB
- その他
- Apache Cassandra (列指向型データベース; Facebook)
- MongoDB (ドキュメント指向データベース)
- Apache CouchDB (ドキュメント指向データベース)
- Neo4j (グラフ型データベース)
NOSQLデータベースを用いる理由:
- 高い処理性能: 巨大なデータを対象に,大量のクエリを高速に処理する高い処理性能が必要
- 疎なデータ: 欠損値を多く含む疎なデータはRDBで効率的に扱うのが難しい
- 柔軟なスキーマの変更: データ構造が頻繁に変更される場合や,事前にデータ構造が分からない場合はデータ構造を柔軟に変更できるデータベースが望ましい
- データ構造の適性: SNSサイトにおけるユーザの関係はRDBで扱いにくい
インターネット検索の仕組み
インターネット検索エンジン
- クローラ(crawler):Webページの自動巡回プログラム(ロボット)
- インデックス生成:高速・高精度なキーワード検索を実現するために,事前に転置インデックス(reverse index)を作成しておく
- ランキング (ranking):重要度(relevance)に応じてWebページを順位づけ
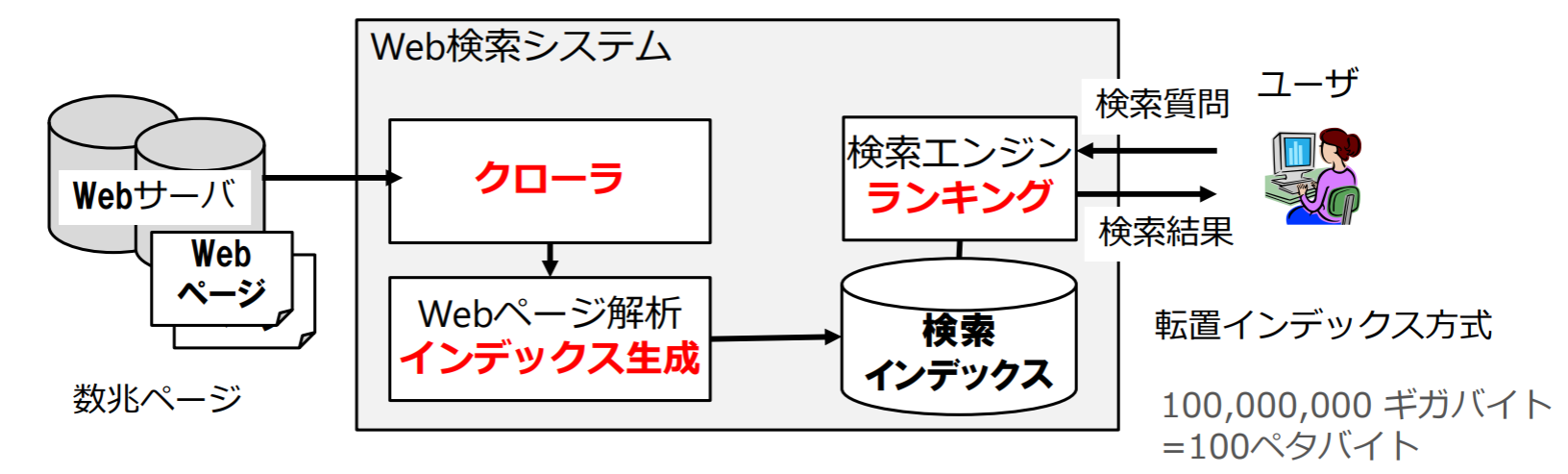
高速化のための工夫:
- 検索インデックスをすべてメモリ上に置く
- ハードディスクの中でもより高速にデータを読み出すことができるディスクの外周部にすぐに読み出す必要のあるデータを配置
- Googleはノンパリティのメモリを使っているため、エラーから回復するためのプログラムを自作し、ディスクスケジューラも自作
ランキング(スコアリング)
- 単語ベースのスコア:検索語の組み合わせから算出
- TF/IDF (1972), Okapi BM25 (1994):他のページには滅多に出てこない単語は重要
- タイトル:Webページのタイトルに含まれる単語は重要
- アンカーテキスト:他ページからリンクするときにリンクに付けられた文字列に含まれる単語は重要
- ページのスコア:各ページ毎にまとめたスコアを予め算出
- ページランク (page rank):重要なページから参照があるページほどより重要
- ログ解析:検索クリック数やユニークユーザ数が大きいページはより重要
複数のスコアを(非公開の)ランキング関数で統合してページのスコアを算出
スケールアップとスケールアウト
スケールアップ(scale up):ハードウェアの性能を向上することで処理性能を上げること
スケールアウト(scale out) :コンピュータを並列化することにより処理性能を上げること
シャーディングとレプリケーション
シャーディング(Sharding):一定の単位でデータ全体を断片に分割して分散管理すること
レプリケーション(replication):データ断片を複製して複数のコンピュータに保持すること
- 機器の故障時にデータを保全
- 同じデータ断片を持つコンピュータ間でクエリの負荷を分散
従来の転置インデックス
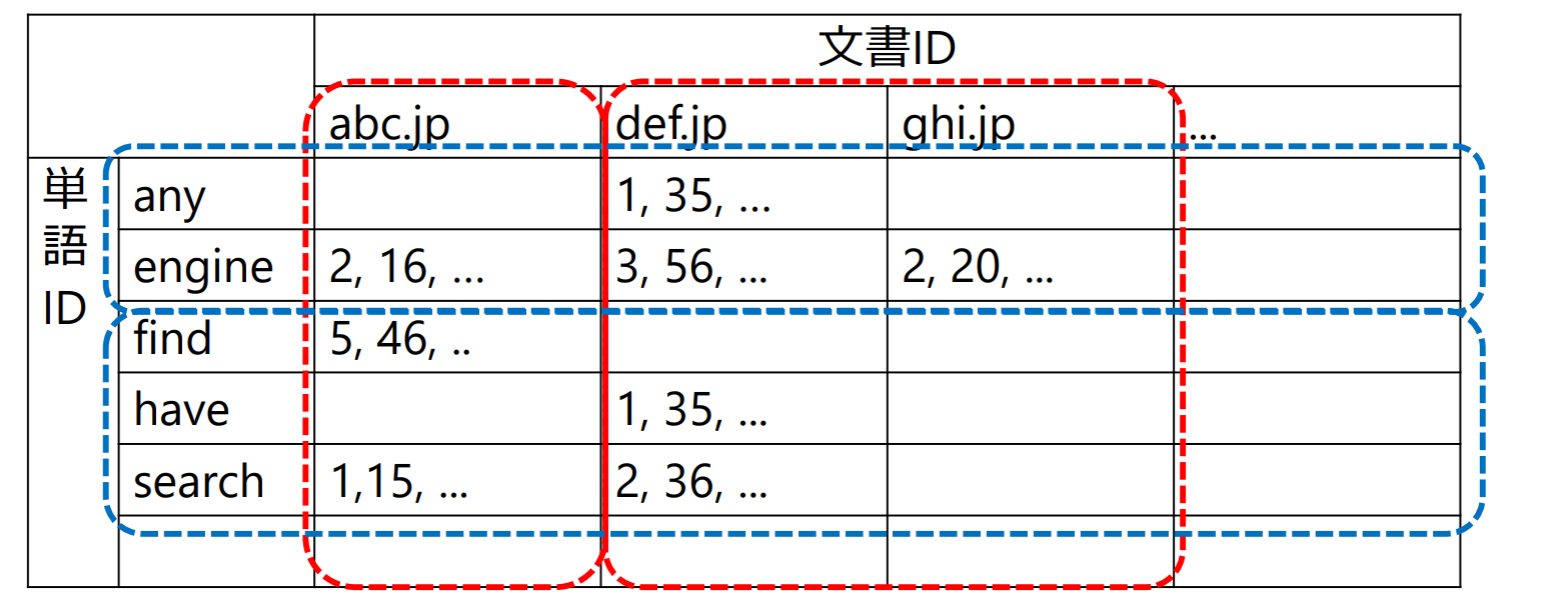
転置インデックス(inverted index):単語をキーとして,単語が出現する”文書”とその”位置”を逆引きできるようにするデータ構造
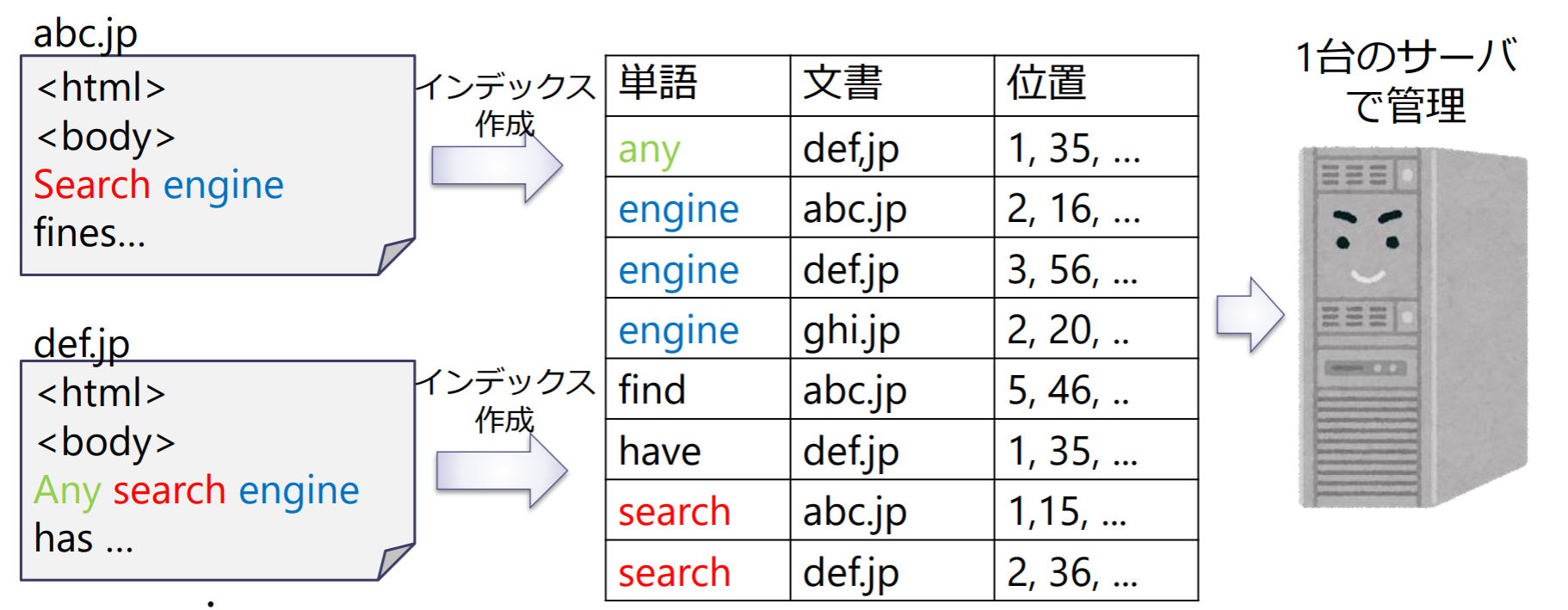
Googleの転置インデックス
“文書分散方式”で転置インデックスを分散管理
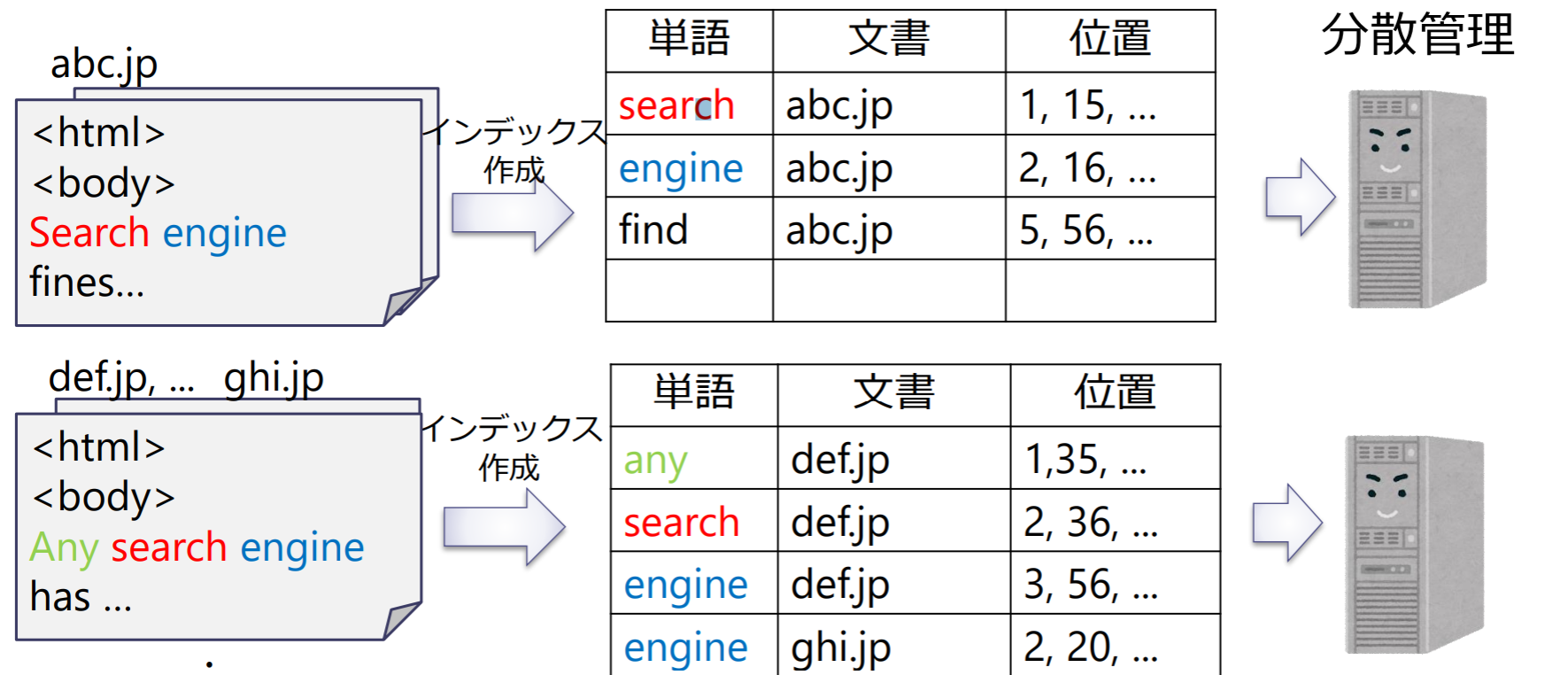
転置インデックスの分散方式
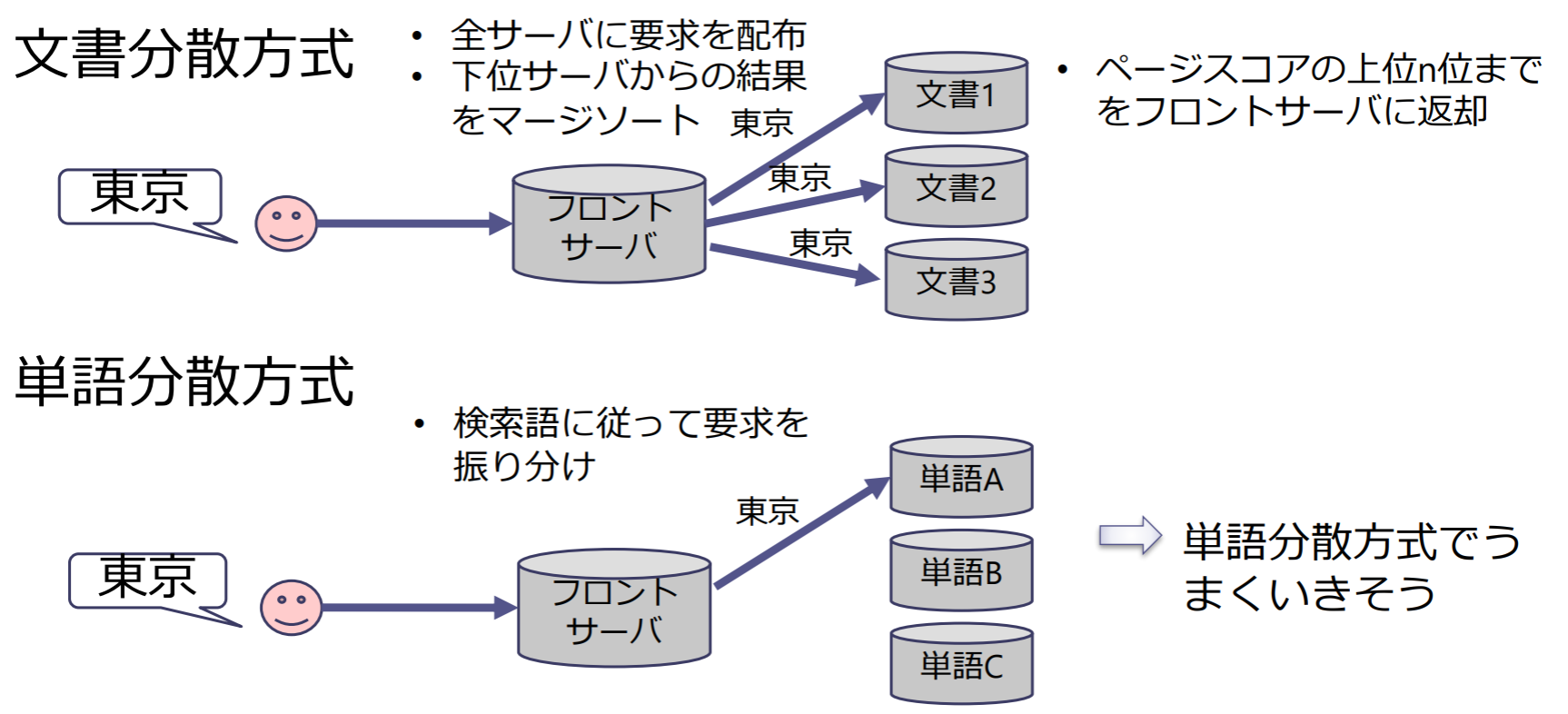
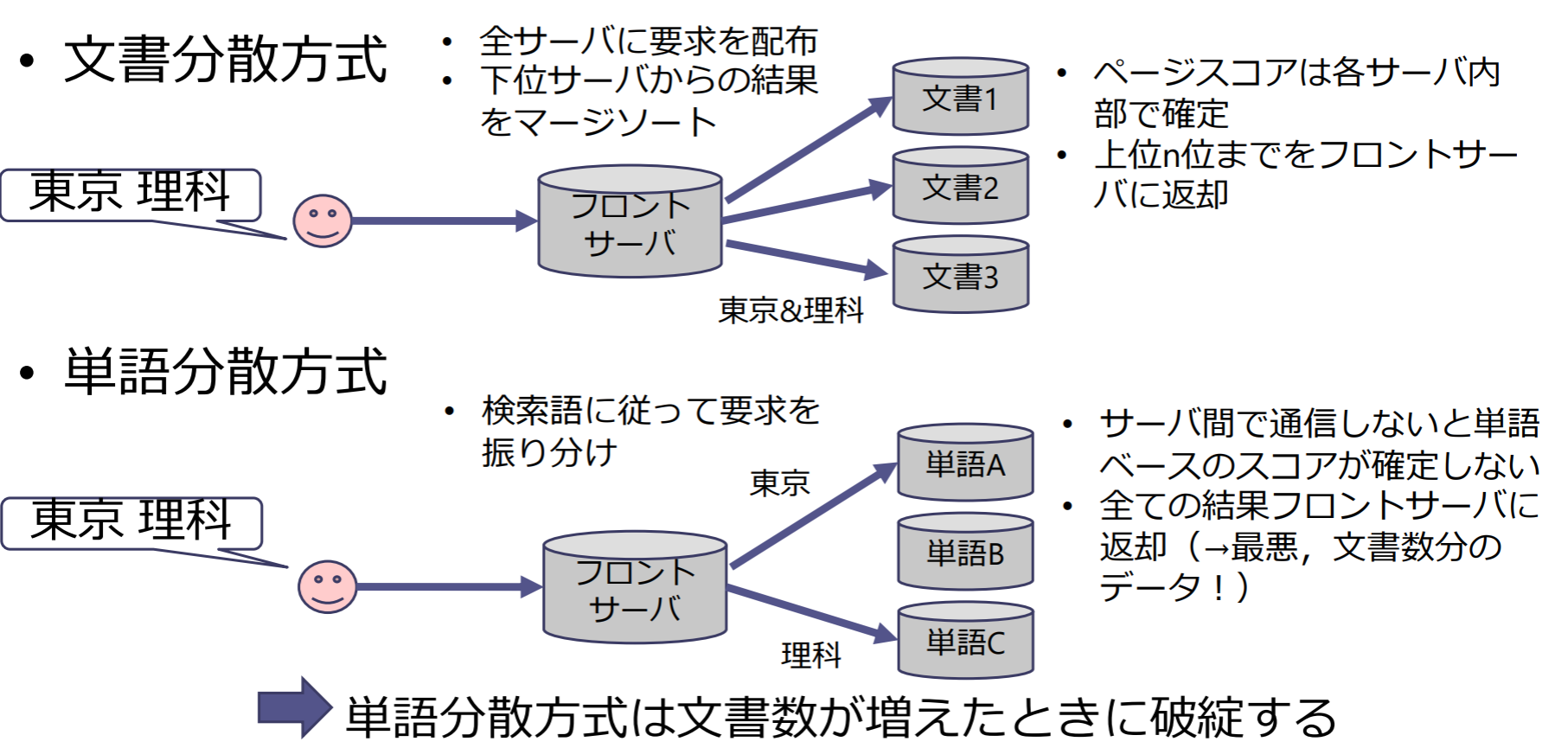
CAP定理
CAP定理:整合性,可用性,分断耐性の特性のうち,同時には二つしか満たすことができない
- 整合性(Consistency):更新クエリを実行した後に実行されるデータ読み出しでは最新のデータを返す特性
- 可用性(Availability):いかなる時刻に到着したクエリでも実行できる特性.更新処理中や,障害で一部のコンピュータ間の通信が途絶した場合でもクエリが実行可能
- 分断耐性(Partition Tolerance):障害によって分散データベースが複数のグループに分断され,互いに通信できない場合であっても,データベースとして動作できる特性.スケーラビリティがある

BASE特性
BASE特性:基本的にはどんなときでも動作し(Basically Available),データの更新は断片の複製を持つノードすべてに徐々に反映されることで(Soft-state),結果的に整合性がとれた状態に至る(Eventual Consistency)という特性
分散データベースのクエリはACID特性もしくはBASE特性のどちらかを満たすべき(Brewer, 2000)
- ACIDにおける整合性は完全な整合性
- BASEにおける整合性は結果整合性(Eventual Consistency)
データの分散管理方式
CP型データベースにおけるデータ分散管理方式
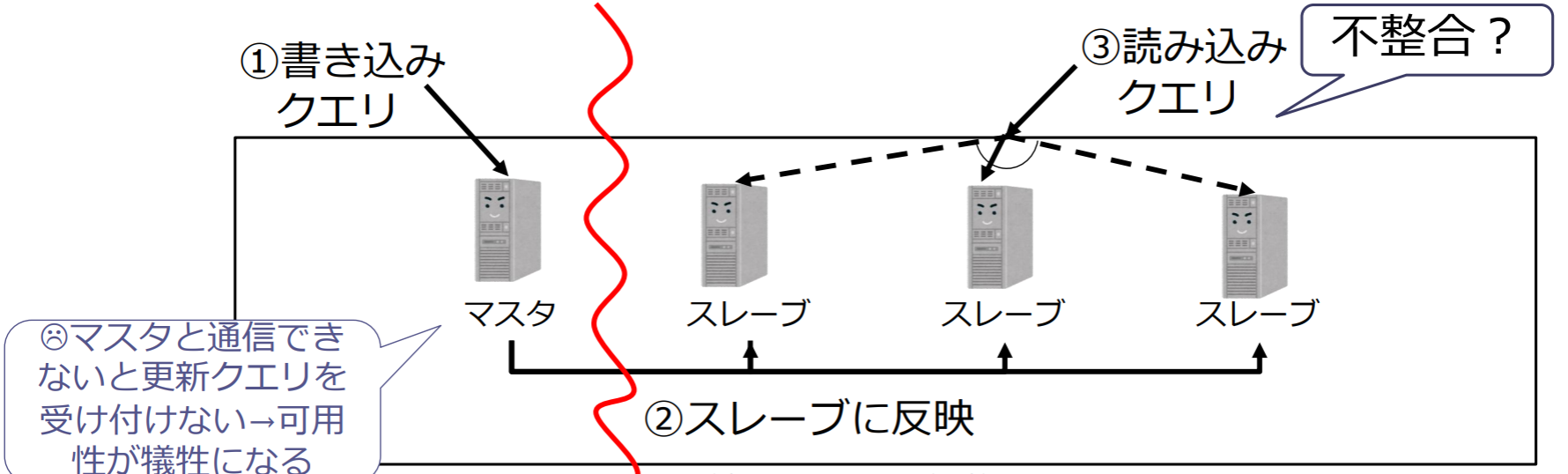
マスタ・スレーブ方式 (Master Slave):
- 書き込みクエリ
- マスターに送られる
- 書き込んだデータは時間をかけてスレーブに反映させる(最新になるまでに時間がかかる)
- 読み込みクエリ
- マスタを介さず最寄りのスレーブが返答
AP型データベースにおけるデータ分散管理方式
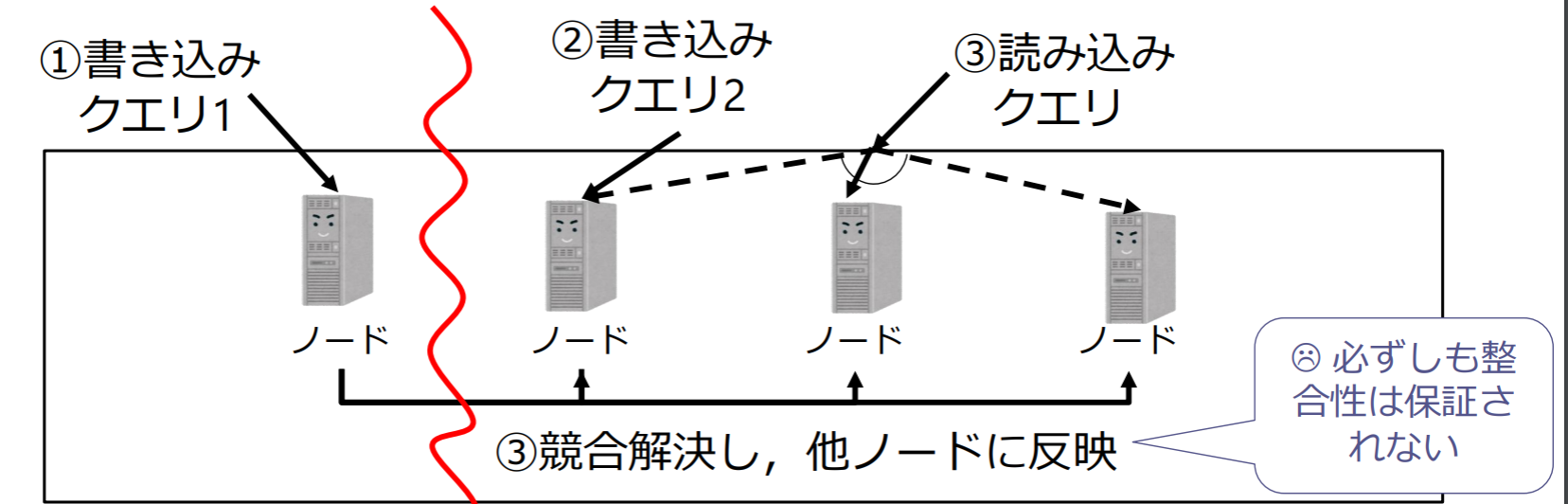
P2P方式(Peer to Peer):
- すべてのノードが対等であり,複数のノードで同時並行にクエリを処理する(障害時にも可用性が保証される)
- 同時に複数の書き込みが発生した場合は,データの競合解決が必要
NOSQLのデータモデル
列指向型データベース
Bigtableの2次元表形式のデータ構造を基にしたデータベース
- 列方向に大量のデータを集計する処理に向いている(例,キーワード検索)
- 列は複数の「列ファミリ」から構成される.列項目は自由に追加可能
- 行IDと列IDによって定まる値にはタイムスタンプを付与
- 原子オブジェクトは行

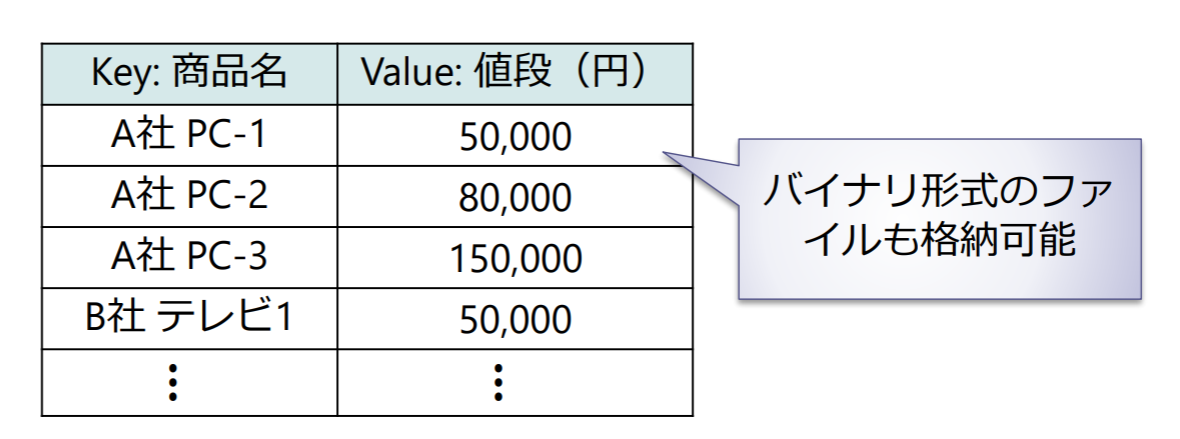
キーバリュー型データベース
キー項目とそれに対応する値のみを持つ2次元の表を管理
- 原子オブジェクトは行
- eg. Dynamo, Memcached
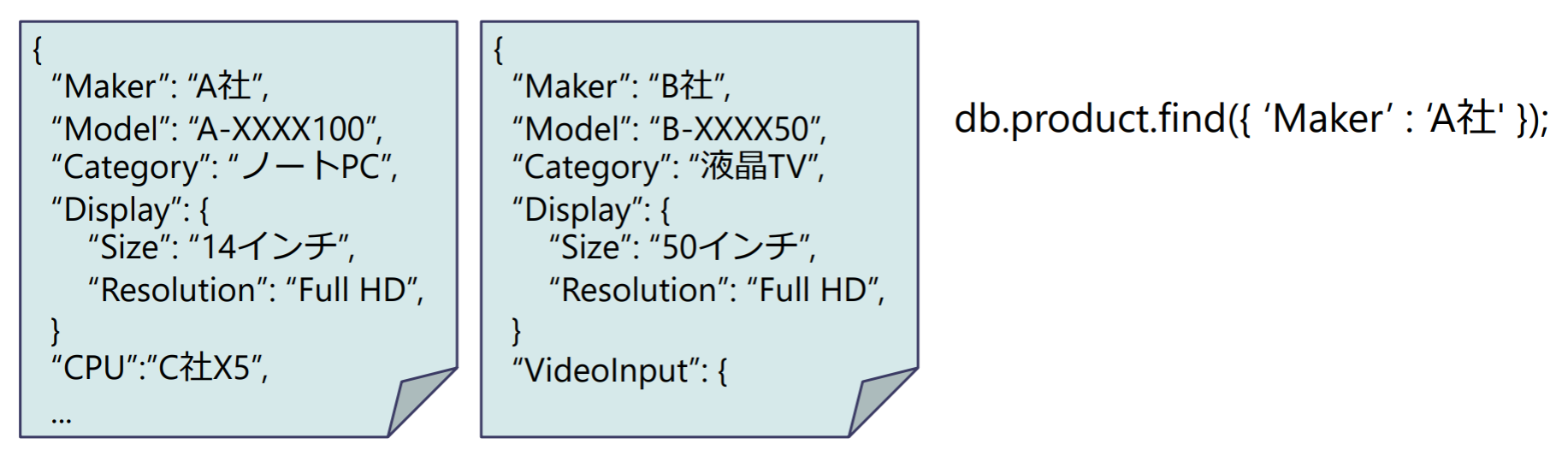
ドキュメント指向型データベース
ドキュメントを単位としてデータを管理
- キー・バリュー型データベースのバリエーション
- ドキュメントはXML, JSONなどの半構造データ
- ドキュメント内の各項目にインデックスが付く
- 原子オブジェクトはドキュメント
グラフ型データベース
データ間の関係をグラフ構造を用いて管理
