An open-source programming language supported by Google.
Go 代码编译成机器码不仅非常迅速,还具有方便的垃圾收集机制和强大的运行时反射机制。它是一个快速的、静态类型的编译型语言 ,感觉却像动态类型的解释型语言。
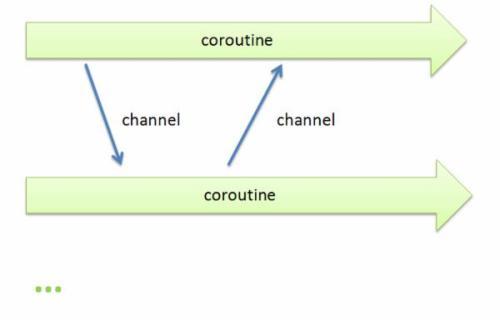
Go语言最大的亮点和特性当属并发编程 ,不同于传统的多进程或多线程,golang的并发执行单元是一种称为goroutine的协程
协程又称微线程,比线程更轻量,开销更小,性能更高。协程间一般由应用程序显式实现调度,上下文切换无需下到内核层,高效不少,协程间的通信靠独有的channel机制实现
从C到C++,从程序性能的角度来考虑,这两种语言允许程序员自己管理内存,包括内存的申请和释放等。因为没有垃圾回收机制所以 C/C++ 运行起来速度很快,但是随着而来的是程序员对内存使用上的很谨小慎微的考虑。因为哪怕一点不小心就可能会导致“内存泄露”使得资源浪费或者“野指针”使得程序崩溃等,尽管C++11后来使用了智能指针的概念,但是程序员仍然需要很小心的使用。后来为了提高程序开发的速度以及程序的健壮性,java和C#等高级语言引入了GC机制,即程序员不需要再考虑内存的回收等,而是由语言特性提供垃圾回收器来回收内存。但是随之而来的可能是程序运行效率的降低。
内存自动回收,再也不需要开发人员管理内存
开发人员专注业务实现,降低了心智负担
只需要new分配内存,不需要释放
初始化阶段直接分配一块大内存区域
大内存被切分成各个大小等级的块,放入不同的空闲list中
对象分配空间时从空闲list中取出大小合适的内存块
内存回收时,会把不用的内存重放回空闲list
空闲内存会按照一定策略合并,以减少碎片
目前Golang具有两种编译器,一种是建立在GCC基础上的Gccgo,另外一种是分别针对64位x64和32位x86计算机的一套编译器(6g和8g)
依赖管理方面,由于golang绝大多数第三方开源库都在github上,在代码的import中加上对应的github路径就可以使用了,库会默认下载到工程的pkg目录下
由于golang诞生在互联网时代,因此它天生具备了去中心化、分布式等特性,具体表现之一就是提供了丰富便捷的网络编程接口,比如
socket用net.Dial(基于tcp/udp,封装了传统的connect、listen、accept等接口)
http用http.Get/Post()
rpc用client.Call(‘class_name.method_name’, args, &reply)
Go语言还有一个很重要的能力:自带高性能HTTP Server ,通过几行代码调用,就可以得到一个基于协程的高性能web服务,更重要的是维护成本极低,没有任何依赖
defer:函数结束后进行,呈先进后出panic:程序出现无法修复的错误时使用,但会让defer执行完recover:会修复错误,不至于程序终止。当不确定函数会不会出错时使用defer + recover
函数多返回值
语言交互性:本语言是否能和其他语言交互,比如可以调用其他语言编译的库
类型推导
接口interface:一个类型只要实现了某个interface的所有方法,即可实现该interface,无需显式去继承
不能循环引用
defer机制:在Go语言中,提供关键字defer,可以通过该关键字指定需要延迟执行的逻辑体,即在函数体return前或出现panic时执行。这种机制非常适合善后逻辑处理,比如可以尽早避免可能出现的资源泄漏问题
"包"的概念
交叉编译
使用:
定义:变量的声明
变量的访问,赋值,取值
1 2 3 4 5 6 7 8 var num1 int num1 = 30 fmt.Printf("num1: %d\n" , num1) var num2 int = 15 fmt.Printf("num2: %d\n" , num2)
由于Go语言是静态语言,也就是是强类型语言 ,也就是在定义变量的时候要声明变量的类型,且赋值时要与声明类型一致,否则编译不会通过(go,java,c++,c#)
与此相对,动态语言(弱类型语言)有:js,php,python,ruby等
1 2 3 4 5 var word = "hello" fmt.Printf("类型是: %T, 数值是: %s\n" , word, word)
1 2 3 sum := 100 fmt.Println(sum)
多变量声明时,也可以通过集合类型声明:
1 2 3 4 var ( name1 type1 name2 type2 )
常量是一个简单值的标识符,在程序运行时,不会被修改的量
1 2 3 4 5 const b string = "abc" const b = "abc"
常量的注意事项:
常量中的数据类型只可以是布尔型、数字型(整数型、浮点型和复数)和字符串型,不可为map,切片等
不曾使用的常量,在编译的时候,是不会报错的
常量组中如不指定类型和初始化值,则与上一行非空常量右值相同
常量可以作为枚举,常量组
iota:特殊常量,可以认为是一个可以被编译器修改的常量
每当定义一个const,iota的初始值为0
每当定义一个常量,就会自动累加1
直到下一个const出现,清零
1 2 3 4 5 6 7 8 9 const ( a = iota b = iota c = iota ) fmt.Println(a) fmt.Println(b) fmt.Println(c)
1 2 3 4 5 6 7 8 fmt.Print() fmt.Printf() fmt.Println()
fmt包读取键盘输入:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package mainimport ( "fmt" ) func main () var x int var y float64 fmt.Println("请输入一个整数,一个浮点类型:" ) fmt.Scanln(&x, &y) fmt.Printf("x的数值:%d,y的数值:%f\n" , x, y) fmt.Scanf("%d, %f" , &x, &y) fmt.Printf("x:%d, y:%f\n" , x, y) }
也可以使用bufio包读取
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package mainimport ( "fmt" "os" "bufio" ) func main () fmt.Println("请输入一个字符串:" ) reader := bufio.NewReader(os.Stdin) s1, err := reader.ReadString('\n' ) fmt.Println("读到的数据:" , s1) }
如果是想从文件中读取输入:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package mainimport ( "fmt" "os" "bufio" ) func main () scanner := bufio.NewScanner(os.Stdin) scanner.Scan() lines := scanner.Text() fmt.Println(lines) }
关于if的变体语句:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package mainimport ( "fmt" ) func main () if num := 10 ; num % 2 == 0 { fmt.Println(num, "is even" ) } else { fmt.Println(num, "is odd" ) } }
Go里面switch默认相当于每个case最后带有break,匹配成功后不会自动向下执行其他case,而是跳出整个switch, 但是可以使用fallthrough强制执行后面的case代码
switch中的fallthrough:当switch中某个case匹配成功后,就执行该case语句,如果遇到fallthrough,那么后面紧跟的一个 case语句无需匹配,可以直接执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 package mainimport ( "fmt" ) func main () n := 2 switch n { case 1 : fmt.Println("我是老大" ) case 2 : fmt.Println("我是老二" ) fallthrough case 3 : fmt.Println("我是老三" ) case 4 : fmt.Println("我是老四" ) } } 我是老二 我是老三
switch 语句还可以被用于 type-switch 来判断某个 interface 变量中实际存储的变量类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package mainimport "fmt" func main () var x interface {} switch i := x.(type ) { case nil : fmt.Printf(" x 的类型 :%T" ,i) case int : fmt.Printf("x 是 int 型" ) case float64 : fmt.Printf("x 是 float64 型" ) case func (int ) float64 : fmt.Printf("x 是 func(int) 型" ) case bool , string : fmt.Printf("x 是 bool 或 string 型" ) default : fmt.Printf("未知型" ) } } x 的类型 :<nil >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package mainimport ( "fmt" ) func main () for i := 1 ; i <= 10 ; i++ { if i == 1 { fmt.Printf("%d" ,i) } else { fmt.Printf(" %d" ,i) } } } 1 2 3 4 5 6 7 8 9 10
数组是具有相同唯一类型的一组已编号且长度固定的数据项序列,数组一旦定义后,大小不能更改
1 2 var balance [10 ]float32 var balance = [5 ]float32 {1000.0 , 2.0 , 3.4 , 7.0 , 50.0 }
初始化数组中 {} 中的元素个数不能大于 [] 中的数字。 如果忽略 [] 中的数字不设置数组大小,Go 语言会根据元素的个数来设置数组的大小:
1 var balance = []float32 {1000.0 , 2.0 , 3.4 , 7.0 , 50.0 }
其他写法:
1 2 f := [...] int {0 : 1 , 4 : 1 , 9 : 1 } fmt.Println(f)
多维数组:
1 2 3 4 5 a = [3 ][4 ]int { {0 , 1 , 2 , 3 } , {4 , 5 , 6 , 7 } , {8 , 9 , 10 , 11 } }
使用range遍历数组:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 package mainimport "fmt" func main () a := [...]float64 {67.7 , 89.8 , 21 , 78 } sum := float64 (0 ) for i, v := range a { fmt.Printf("%d the element of a is %.2f\n" , i, v) sum += v } fmt.Println("\nsum of all elements of a" ,sum) } 0 the element of a is 67.70 1 the element of a is 89.80 2 the element of a is 21.00 3 the element of a is 78.00 sum of all elements of a 256.5
数组是值类型 Go中的数组是值类型 ,而不是引用类型。这意味着当它们被分配给一个新变量时,将把原始数组的副本分配给新变量。如果对新变量进行了更改,则不会在原始数组中反映
值类型:理解为存储的数值本身,将数据传递给其他的变量,传递的是数据的副本(备份)
值类型有:int, float, string, bool, array
引用类型:理解为存储的数据的内存地址
这里以用冒泡排序为例,依次比较两个相邻的元素,如果他们的顺序(如从大到小)就把他们交换过来
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 package mainimport "fmt" func main () arr := []int {15 , 23 , 8 , 10 , 7 } for i := 1 ; i < len (arr); i++ { for j := 0 ; j < len (arr) - i; j++ { if arr[j] > arr[j + 1 ] { arr[j], arr[j + 1 ] = arr[j + 1 ], arr[j] } } fmt.Println(arr) } } [15 8 10 7 23 ] [8 10 7 15 23 ] [8 7 10 15 23 ] [7 8 10 15 23 ]
Go 数组的长度不可改变,在特定场景中这样的集合就不太适用,与数组相比切片的长度是不固定的 ,可以追加元素,在追加时可能使切片的容量增大。切片与数组相比,不需要设定长度,在[]中不用设定值,相对来说比较自由
切片不需要说明长度。 或使用make()函数来创建切片:
make函数:
第一个参数:类型(slice,map,channel)
第二个参数:长度len,实际存储元素的数量
第三个参数:容量cap,最多能够存储的元素的数量
1 2 3 4 var slice1 []type = make ([]type , len )slice1 := make ([]type , len )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package mainimport "fmt" func main () s := make ([]int , 0 , 5 ) fmt.Println(s) s = append (s, 1 , 2 ) fmt.Println(s) } [] [1 2 ]
每一个切片引用了一个底层数组
切片本身不存储任何数据,都是这个底层数组存储,所以修改切片也就是修改这个数组中的数据
当向切片中添加数据时,如果没有超过容量,直接添加,如果超过容量,自动扩容(成倍增长)
切片一旦扩容,就是重新指向一个新的底层数组(内存地址发生改变)
切片是引用类型:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package mainimport "fmt" func main () a1 := [4 ]int {1 , 2 , 3 , 4 } a2 := a1 a1[0 ] = 100 fmt.Println(a1, a2) fmt.Println("---------------------" ) s1 := []int {1 , 2 , 3 , 4 } s2 := s1 fmt.Println(s1, s2) s1[0 ] = 100 fmt.Println(s1, s2) } [100 2 3 4 ] [1 2 3 4 ] --------------------- [1 2 3 4 ] [1 2 3 4 ] [100 2 3 4 ] [100 2 3 4 ]
深拷贝:拷贝的是数据本身。值类型数据,默认都是深拷贝
浅拷贝:拷贝的是数据的地址,导致多个变量指向同一块内存。引用类型的数据,默认都是浅拷贝
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package mainimport "fmt" func main () s1 := []int {1 , 2 , 3 , 4 } s2 := make ([]int , 0 ) for i := 0 ; i < len (s1); i++ { s2 = append (s2, s1[i]) } fmt.Println(s1) fmt.Println(s2) s1[0 ] = 100 fmt.Println(s1) fmt.Println(s2) } [1 2 3 4 ] [1 2 3 4 ] [100 2 3 4 ] [1 2 3 4 ]
首先创建了s1对应的底层数组,假设地址为0x12345,然后创建s1切片,里面存储的是它对应的底层数组的地址0x12345,所以s1指向那块内存
然后通过make方法创建了s2切片,里面存储的是对应的底层数组,然后向s2添加元素,导致数组扩容,每次扩容都是重新创建数组,最后一次s2指向最新的底层数组
这是改变s1,是不影响s2的
除了这种方式,go语言中提供了copy(),专门用来给切片深拷贝的
使用map过程中需要注意的几点:
map是无序的 ,每次打印出来的map都会不一样,它不能通过index获取,而必须通过key获取
map的长度是不固定的,也就是和slice一样,也是一种引用类型
内置的len函数同样适用于map,返回map拥有的key的数量
map的key可以是所有可比较的类型,如布尔型、整数型、浮点型、复杂型、字符串型等
储存特点:
存储的是无序的 键值对
键不能重复,并且和value值一一对应,map中的kep如果重复,那么新的value会覆盖原来的,程序不会报错
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 var map1 map [int ]string var map2 = make (map [int ]string ) var map3 = map [string ]int {"Go" : 98 , "Python" : 89 , "Java" : 79 }fmt.Println(map1) fmt.Println(map2) fmt.Println(map3) fmt.Println(map1 == nil ) fmt.Println(map2 == nil ) fmt.Println(map3 == nil ) map []map []map [Go:98 Java:79 Python:89 ]true false false
如果不初始化 map,那么就会创建一个 nil map。nil map 不能用来存放键值对。引用类型的默认值是nil,类似于其他语言的null
delete(map, key) 函数用于删除集合的元素, 参数为 map 和其对应的 key。删除函数不返回任何值
我们可以通过key获取map中对应的value值:map[key]
但是当key如果不存在的时候,我们会得到该value值类型的默认值,比如string类型得到空字符串,int类型得到0。但是程序不会报错,所以我们可以使用ok-idiom获取值,可知道key/value是否存在:value, ok := map[key]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package mainimport ( "fmt" ) func main () m := make (map [string ]int ) m["a" ] = 1 x, ok := m["b" ] fmt.Println(x, ok) x, ok = m["a" ] fmt.Println(x, ok) } 0 false 1 true
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 package mainimport ( "fmt" ) func main () map1 := make (map [int ]string ) map1[1 ] = "烤肉" map1[2 ] = "炒菜" map1[3 ] = "汤" for k, v := range map1 { fmt.Println(k, v) } } 2 炒菜3 汤1 烤肉
可以看出,golang的map在遍历的时候是无序的,当我们想要遍历为有序的时候,需要排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 package mainimport ( "fmt" "sort" ) func slove (m map [int ]string ) var s []int for k := range m { s = append (s, k) } sort.Ints(s) for _, v := range s { fmt.Println(v, m[v]) } } func main () var map1 = map [int ]string { 1 : "烤肉" , 2 : "炒菜" , 3 : "汤" , } slove(map1) } 1 烤肉2 炒菜3 汤
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 package mainimport ( "fmt" ) func main () map1 := make (map [string ]string ) map1["name" ] = "张三" map1["age" ] = "20" map1["sex" ] = "男性" fmt.Println(map1) map2 := map [string ]string {"name" :"李四" , "age" :"30" , "sex" :"女性" } fmt.Println(map2) s1 := make ([]map [string ]string , 0 , 3 ) s1 = append (s1, map1) s1 = append (s1, map2) for i, val := range s1 { fmt.Printf("第 %d 个人的信息是:\n" , i+1 ) fmt.Printf("姓名:%s\n" , val["name" ]) fmt.Printf("年龄:%s\n" , val["age" ]) fmt.Printf("性别:%s\n" , val["sex" ]) } } map [age:20 name:张三 sex:男性]map [age:30 name:李四 sex:女性]第 1 个人的信息是: 姓名:张三 年龄:20 性别:男性 第 2 个人的信息是: 姓名:李四 年龄:30 性别:女性
Go函数支持变参。接受变参的函数是有着不定数量的参数的。为了做到这点,首先需要定义函数使其接受变参:
1 func myfunc (arg ... int )
在Go语言中,使用defer关键字来延迟一个函数或者方法的执行
defer函数的用法:
对象文件的close(),临时文件的删除都可以使用,例如:打开一个文件文件.open(),进行读写操作,最后关闭文件close(),为了防止忘记关闭文件,打开文件之后就可以加上defer close(),然后再进行读写操作
go语言中关于异常的处理,使用panic()和recover()
当一个函数有多个延迟调用时,它们被添加到一个堆栈 中,并在Last In First Out(LIFO)后进先出的顺序中执行。即先延迟的后执行,后延迟的先执行
defer函数传递参数的时候:defer函数调用时,就已经传递了参数数据了,只是暂时不执行函数中的代码而已
defer注意点:
当外围函数中的语句正常执行完毕时,只有其中所有的延迟函数都执行完毕,外围函数才会真正的结束执行
当执行外围函数中的return语句时,只有其中所有的延迟函数都执行完毕后,外围函数才会真正返回 当外围函数中的代码引发运行恐慌时,只有其中所有的延迟函数都执行完毕后,该运行时恐慌才会真正被扩展至调用函数
定义一个匿名函数,直接进行调用,通常只能使用一次。也可以使用匿名函数赋值给某个函数变量,那么就可以调用多次了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package mainimport ( "fmt" ) func main () func () fmt.Println("我是匿名函数" ) }() } 我是匿名函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package mainimport ( "fmt" ) func main () res1 := oper(10 , 20 , add) fmt.Println(res1) } func add (a, b int ) int { return a + b } func oper (a, b int , fun func (int , int ) int ) int { fmt.Println(a, b, fun) res := fun(a, b) return res } 10 20 0x499140 30
在这个例子中,add()对于oper()来说就是一个回调函数
一个外层函数中,有内层函数,该内层函数中,会操作外层函数的局部变量(外层函数中的参数,或者外层函数中直接定义的变量),并且该外层函数的返回值就是这个内层函数
局部变量的生命周期发生改变,正常的局部变量随着函数调用而创建,随着函数的结束而销毁。但是闭包结构中的外层函数的局部变量并不会随着外层函数的结束而销毁 ,因为内层函数还要继续使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 package mainimport ( "fmt" ) func main () res1 := increment() fmt.Println(res1) v1 := res1() fmt.Println(v1) fmt.Println(res1()) } func increment () func () int { i := 0 fun := func () int { i++ return i } return fun } 0x4992a0 1 2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 *[5 ]float64 [5 ]*float64 *[5 ]*float64 **[4 ]string **[4 ]*string
数组指针(*[size]Type):首先是一个指针,一个数组的地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package mainimport ( "fmt" ) func main () arr1 := [4 ]int {1 , 2 , 3 , 4 } var p1 *[4 ]int p1 = &arr1 (*p1)[0 ] = 100 fmt.Println(arr1) p1[0 ] = 200 fmt.Println(arr1) } [100 2 3 4 ] [200 2 3 4 ]
指针数组([size]*Type):首先是一个数组,存储的数据类型是指针
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 package mainimport ( "fmt" ) func main () a := 1 b := 2 c := 3 d := 4 arr2 := [4 ]int {a, b, c, d} arr3 := [4 ]*int {&a, &b, &c, &d} arr2[0 ] = 100 fmt.Println(arr2) fmt.Println(a) *arr3[0 ] = 200 fmt.Println(arr3) fmt.Println(a) b = 1000 fmt.Println(arr2) for i := 0 ; i < len (arr3); i++ { fmt.Println(*arr3[i]) } } [100 2 3 4 ] 1 [0xc0000b6010 0xc0000b6018 0xc0000b6020 0xc0000b6028 ] 200 [100 2 3 4 ] 200 1000 3 4
函数指针:一个指针,指向了一个函数的指针,在go语言中,function默认看作一个指针,没有*
指针函数:一个函数,该函数的返回值是一个指针
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 package mainimport ( "fmt" ) func main () arr1 := fun1() fmt.Printf("arr1的类型是: %T, 地址是: %p, 数值是: %v\n" , arr1, &arr1, arr1) arr2 := fun2() fmt.Printf("arr2的类型是: %T, 地址是: %p, 数值是: %v\n" , arr2, &arr2, arr2) } func fun2 () 4 ]int { arr := [4 ]int {5 , 6 , 7 , 8 } return &arr } func fun1 () 4 ]int { arr := [4 ]int {1 , 2 , 3 , 4 } return arr } arr1的类型是: [4 ]int , 地址是: 0xc000014020 , 数值是: [1 2 3 4 ] arr2的类型是: *[4 ]int , 地址是: 0xc00000e030 , 数值是: &[5 6 7 8 ]
1 2 3 4 5 6 type struct_variable_type struct { member definition; member definition; ... member definition; }
1 2 3 4 5 6 7 P := person{"Tom" , 25 } P := person{age:24 , name:"Tom" } p := new (person) p.age=24
1 2 3 4 5 6 7 s2 := struct { name string age int }{ name:"李四" age:19 }
结构体嵌套最好使用结构体指针,这样会发生引用传递,传递的是数据的地址,不用将数据备份一次浪费内存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 type Book struct { bookName string price float64 } type Student struct { name string age int book Book } type Student2 struct { name string age int book *Book }
go并不是一个纯面向对象的编程语言。在go中的面向对象,结构体替换了类
Go并没有提供类class,但是它提供了结构体struct,方法method,可以在结构体上添加。提供了捆绑数据和方法的行为,这些数据和方法与类类似
Go语言的结构体嵌套总结如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 type A struct { field } type B struct { A } type C struct { field } type D struct { c C }
首先先看未使用提升字段的结构体嵌套示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 package mainimport ( "fmt" ) type Address struct { country, state string } type Person struct { name string age int address Address } func main () var p Person p.name = "Juliet" p.age = 18 p.address = Address{ country: "Italy" , state: "Veneto" } fmt.Println("Name:" , p.name) fmt.Println("Age:" , p.age) fmt.Println("Country:" , p.address.country) fmt.Println("State:" , p.address.state) } Name: Juliet Age: 18 Country: Italy State: Veneto
在结构体中属于匿名结构体的字段称为提升字段 ,因为它们可以被访问,就好像它们属于拥有匿名结构字段的结构一样。以下是使用提升字段示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 package mainimport ( "fmt" ) type Address struct { country, state string } type Person struct { name string age int Address } func main () var p Person p.name = "Juliet" p.age = 18 p.Address = Address{ country: "Italy" , state: "Veneto" } fmt.Println("Name:" , p.name) fmt.Println("Age:" , p.age) fmt.Println("Country:" , p.country) fmt.Println("State:" , p.state) } Name: Juliet Age: 18 Country: Italy State: Veneto
如果结构体类型以大写字母 开头,那么它是一个导出类型,可以从其他包访问它。类似地,如果结构体的字段以大写开头 ,则可以从其他包访问它们
一个方法就是一个包含了接受者的函数 ,接受者可以是命名类型或者结构体类型的一个值或者是一个指针 。所有给定类型的方法属于该类型的方法集
方法能给用户自定义的类型添加新的行为。它和函数的区别在于方法有一个接收者,给一个函数添加一个接收者,那么它就变成了方法。接收者可以是值接收者,也可以是指针接收者
函数可以直接调用,而方法必须由指定接收者调用 ,谁调用谁就是接收者
1 2 3 4 5 6 7 func (t Type) return list) { } func funcName (parameter list) return list){ }
实例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 package mainimport ( "fmt" ) func main () w1 := Worker{name:"张三" , age:24 , sex:"男" } w1.work() w2 := &Worker{name:"李四" , age:36 , sex:"女" } fmt.Printf("%T\n" , w2) w2.work() w2.rest() w1.rest() } type Worker struct { name string age int sex string } func (w Worker) fmt.Println(w.name, "在工作..." ) } func (p *Worker) fmt.Println(p.name, "在休息..." ) } 张三 在工作... *main.Worker 李四 在工作... 李四 在休息... 张三 在休息...
对比函数:
意义:
方法:某个类别的行为功能,需要指定的接收者调用
函数:一段独立功能的代码,可以直接调用
语法:
方法:方法名可以相同,只要接收者不同
函数:命名不可冲突
既然我们已经有了函数,为什么还要使用方法?
Go不是一种纯粹面向对象的编程语言,它不支持类。因此,类型的方法是一种实现类似于类的行为的方法
相同名称的方法可以在不同的类型上定义,而具有相同名称的函数是不允许的
method是可以继承的,如果匿名字段实现了一个method,那么包含这个匿名字段的struct也能调用该method
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 package mainimport ( "fmt" ) func main () p1 := Person{name:"张三" , age:18 } fmt.Println(p1.name, p1.age) p1.eat() s1 := Student{Person{"ruby" , 30 }, "bilibili" } fmt.Println(s1.name) fmt.Println(s1.age) fmt.Println(s1.school) s1.eat() s1.study() s1.eat() } type Person struct { name string age int } type Student struct { Person school string } func (p Person) fmt.Println("父类的方法:吃汉堡" ) } func (s Student) fmt.Println("子类新增的方法:学习" ) } func (s Student) fmt.Println("子类重写的方法:吃炸鸡" ) } 张三 18 父类的方法:吃汉堡 ruby 30 bilibili 子类重写的方法:吃炸鸡 子类新增的方法:学习 子类重写的方法:吃炸鸡
面向对象世界中的接口的一般定义是"接口定义对象的行为"。它表示让指定对象应该做什么。实现这种行为的方法(实现细节)是针对对象的
在Go中,接口是一组方法签名 。当类型为接口中的所有方法 提供定义时,它被称为实现接口
它把所有的具有共性的方法定义在一起,任何其他类型只要实现了这些方法就是实现了这个接口。接口定义了一组方法,如果某个对象实现了某个接口的所有方法,则此对象就实现了该接口
定义接口:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 type interface_name interface { method_name1 [return_type] method_name2 [return_type] method_name3 [return_type] ... method_namen [return_type] } type struct_name struct { } func (struct_name_variable struct_name) } ... func (struct_name_variable struct_name) }
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 package mainimport ( "fmt" ) func main () m1 := Mouse{"罗技小红" } fmt.Println(m1.name) f1 := FlashDisk{"闪迪64G" } fmt.Println(f1.name) testInterface(m1) testInterface(f1) } type USB interface { start() end() } type Mouse struct { name string } type FlashDisk struct { name string } func (m Mouse) fmt.Println(m.name, "鼠标准备就绪" ) } func (m Mouse) fmt.Println(m.name, "鼠标结束工作" ) } func (f FlashDisk) fmt.Println(f.name, "U盘准备就绪" ) } func (f FlashDisk) fmt.Println(f.name, "U盘结束工作" ) } func testInterface (usb USB) usb.start() usb.end() } 罗技小红 闪迪64 G 罗技小红 鼠标准备就绪 罗技小红 鼠标结束工作 闪迪64 G U盘准备就绪 闪迪64 G U盘结束工作
需要注意的是,var m1 Mouse, m1 = Mouse{}时,m1可以访问name,start(),end(),但是var usb USB, usb = m1时,usb可以访问start(),end(),但是不能访问name,对于USB接口来说,没有name属性
接口最大的意义就是解耦合 ,接口的本质就是把功能的定义和功能的实现分离开。谁实现了接口的方法,那么谁就是这个接口的实现
Go语言通过接口模拟多态,就一个接口的实现:
看出实现本身的类型,能够访问类中的属性和方法
看成是对应的接口类型,那就只能够访问接口中的方法
接口的用法:
一个函数如果能够接受接口类型作为参数,那么实际上可以传入该接口的任意实现类型对象作为参数
定义一个类型为接口,实际上可以赋值为任意实现类的对象
假设有一个接口A,里面有一个方法test1(),有一个接口B,里面有一个方法test2(),如果接口C既继承了A又继承了B,同时还有自己新增的方法test3()。
如果设计一个类,用来实现接口A,那么只需要接口A中的test1方法即可,同理B,但是如果设计一个类,用来实现接口C,要实现接口test1(), test2(), test3()的方法才能算做接口C的实现类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 package mainimport ( "fmt" ) func main () var cat = Cat{} cat.test1() cat.test2() cat.test3() fmt.Println("----------------" ) var a1 = cat a1.test1() fmt.Println("----------------" ) var b1 = cat b1.test2() fmt.Println("----------------" ) var c1 = cat c1.test1() c1.test2() c1.test3() fmt.Println("----------------" ) } type A interface { test1() } type B interface { test2() } type C interface { A B test3() } type Cat struct {} func (c Cat) fmt.Println("test1()..." ) } func (c Cat) fmt.Println("test2()..." ) } func (c Cat) fmt.Println("test3()..." ) } test1()... test2()... test3()... ---------------- test1()... ---------------- test2()... ---------------- test1()... test2()... test3()... ----------------
因为空接口interface{}没有定义任何函数,因此 Go 中所有类型都实现了空接口。当一个函数的形参是interface{},那么在函数中,需要对形参进行断言,从而得到它的真实类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 1. interface := 接口对象.(实际类型) 2. interface , ok := 接口对象.(实际类型) switch instance := 接口对象.(type ) {case 实际类型1 : ... case 实际类型2 : ... ... } switch ins := s.(type ) { case Triangle: fmt.Println("三角形。。。" ,ins.a,ins.b,ins.c) case Circle: fmt.Println("圆形。。。。" ,ins.radius) case int : fmt.Println("整型数据。。" ) }
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 package mainimport ( "fmt" "math" ) func main () var t1 = Triangle{3 , 4 , 5 } fmt.Println(t1.peri()) fmt.Println(t1.area()) fmt.Println(t1.a, t1.b, t1.c) fmt.Println("----------------" ) var c1 = Circle{4 } fmt.Println(c1.peri()) fmt.Println(c1.area()) fmt.Println(c1.radius) fmt.Println("----------------" ) getType(t1) getType(c1) } func getType (s Shape) if ins, ok := s.(Triangle) ; ok { fmt.Println("是三角形,三边是:" , ins.a, ins.b, ins.c) } else if ins, ok := s.(Circle) ; ok { fmt.Println("是圆形,半径是:" , ins.radius) } else { fmt.Println("我也不知道了..." ) } } type Shape interface { peri() float64 area() float64 } type Triangle struct { a, b, c float64 } func (t Triangle) float64 { return t.a + t.b + t.c } func (t Triangle) float64 { p := t.peri() / 2 s := math.Sqrt(p * (p - t.a) * (p - t.b) * (p - t.c)) return s } type Circle struct { radius float64 } func (c Circle) float64 { return c.radius * 2 * math.Pi } func (c Circle) float64 { return math.Pow(c.radius, 2 ) * math.Pi } 12 6 3 4 5 ---------------- 25.132741228718345 50.26548245743669 4 ---------------- 是三角形,三边是: 3 4 5 是圆形,半径是: 4
错误 指的是可能出现问题的地方出现了问题。比如打开一个文件时失败,这种情况在人们的意料之中
而异常 指的是不应该出现问题的地方出现了问题。比如引用了空指针,这种情况在人们的意料之外。可见,错误是业务过程的一部分,而异常不是
创建自定义错误可以使用errors包下的New()函数,以及fmt包下的:Errorf()函数
1 2 3 4 5 func New (text string ) error {}func Errorf (format string , a ...interface {}) error {}
实例代码:计算一个圆的面积,如果半径为负,将返回一个错误
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package mainimport ( "errors" "fmt" "math" ) func circleArea (radius float64 ) float64 , error ) { if radius < 0 { return 0 , errors.New("Area calculation failed, radius is less than zero" ) } return math.Pi * radius * radius, nil } func main () radius := -20.0 area, err := circleArea(radius) if err != nil { fmt.Println(err) return } fmt.Printf("Area of circle %0.2f" , area) } Area calculation failed, radius is less than zero
什么情况下用错误表达,什么情况下用异常表达,就得有一套规则,否则很容易出现一切皆错误或一切皆异常的情况
panic:
内建函数
假如函数F中书写了panic语句,会终止其后要执行的代码,在panic所在函数F内如果存在要执行的defer函数列表,按照defer的逆序 执行
返回函数F的调用者G,在G中,调用函数F语句之后的代码不会执行,假如函数G中存在要执行的defer函数列表,按照defer的逆序执行,这里的defer 有点类似 try-catch-finally 中的 finally
直到goroutine整个退出,并报告错误
当外围函数的代码中发生了运行panic,只有其中所有的已经defer的函数全部执行完毕后,该运行的panic才会真正被扩展至调用处
recover:
内建函数
用来控制一个goroutine的panicking行为,捕获panic,从而影响应用的行为
一般的调用建议 a). 在defer函数中,通过recever来终止一个gojroutine的panicking过程,从而恢复正常代码的执行 b). 可以获取通过panic传递的error
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 package mainimport ( "fmt" ) func main () GO() PHP() PYTHON() } func GO () fmt.Println("我是GO,现在没有发生异常,我是正常执行的。" ) } func PHP () defer func () if err := recover (); err != nil { fmt.Println("终于捕获到了panic产生的异常:" , err) fmt.Println("我是defer里的匿名函数,我捕获到panic的异常了,我要recover,恢复过来了。" ) } }() panic ("我是PHP,我要抛出一个异常了,等下defer会通过recover捕获这个异常,捕获到我时,在PHP里是不会输出的,会在defer里被捕获输出,然后正常处理,使后续程序正常运行。但是注意的是,在PHP函数里,排在panic后面的代码也不会执行的。" ) fmt.Println("我是PHP里panic后面要打印出的内容。但是我是永远也打印不出来了。因为逻辑并不会恢复到panic那个点去,函数还是会在defer之后返回,也就是说执行到defer后,程序直接返回到main()里,接下来开始执行PYTHON()" ) } func PYTHON () fmt.Println("我是PYTHON,没有defer来recover捕获panic的异常,我是不会被正常执行的。" ) } 我是GO,现在没有发生异常,我是正常执行的。 终于捕获到了panic 产生的异常: 我是PHP,我要抛出一个异常了,等下defer 会通过recover 捕获这个异常,捕获到我时,在PHP里是不会输出的,会在defer 里被捕获输出,然后正常处理,使后续程序正常运行。但是注意的是,在PHP函数里,排在panic 后面的代码也不会执行的。 我是defer 里的匿名函数,我捕获到panic 的异常了,我要recover ,恢复过来了。 我是PYTHON,没有defer 来recover 捕获panic 的异常,我是不会被正常执行的。
以下给出异常处理的作用域(场景):
空指针引用
下标越界
除数为0
不应该出现的分支,比如default
输入不应该引起函数错误
make用于内建类型(map、slice 和channel)的内存分配。new用于各种类型的内存分配
内建函数new本质上说跟其它语言中的同名函数功能一样:new(T)分配了零值填充的T类型的内存空间,并且返回其地址,即一个*T类型的值。用Go的术语说,它返回了一个指针 ,指向新分配的类型T的零值。有一点非常重要:new返回指针
内建函数make(T, args)与new(T)有着不同的功能,make只能创建slice、map和channel,并且返回一个有初始值(非零)的T类型,而不是*T
本质来讲,导致这三个类型有所不同的原因是指向数据结构的引用在使用前必须被初始化 。例如,一个slice,是一个包含指向数据(内部array)的指针、长度和容量的三项描述符;在这些项目被初始化之前,slice为nil。对于slice、map和channel来说,make初始化了内部的数据结构,填充适当的值
make返回初始化后的(非零)值
关于包的使用:
一个目录下的统计文件归属第一个包,package的声明要一致
package声明的包和对应的目录名可以不一致,但习惯上还是写成一致的包可以嵌套
同包下的函数不需要导入包,可以直接使用
main包,main()函数所在的包,其他的包不能使用导入包的时候,路径要从src下开始写
init(), main()函数在go语言中的区别如下:
相同点:
两个函数在定义的时候不能有任何的参数和返回值
该函数只能由go程序自动调用,不可以被调用
不同点:
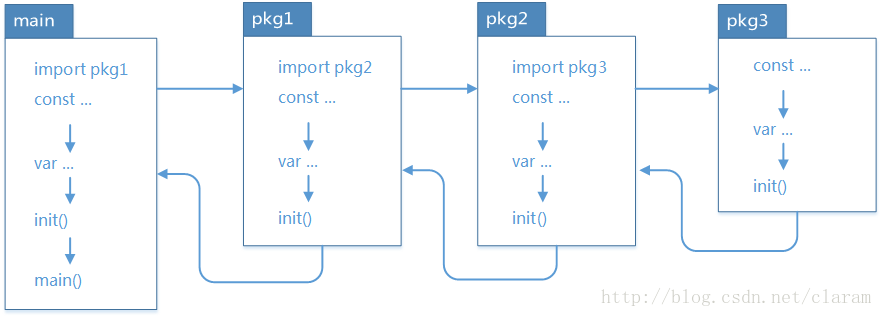
init()函数可以应用与任意包中,且可以重复定义多个main()函数只能用于main包中,且只能定义一个
两个函数的执行顺序:
在main包中的go文件默认总是会被执行
对同一个go文件的init()调用顺序是从上到下的
对同一个package中的不同文件,将文件名按字符串进行"从小到大"排序,之后顺序调用各文件中的init()函数
对于不同的package,如果不相互依赖的话,按照main包中import的顺序调用其包中的init()函数
如果 package 存在依赖,调用顺序为最后被依赖的最先被初始化:
注意:避免出现循环 import,例如:A –> B –> C –> A
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 package mainimport ( "fmt" "time" ) func main () t1 := time.Now() fmt.Println(t1) fmt.Println("----------------" ) t2 := time.Date(2008 , 7 , 15 , 16 , 30 , 28 , 0 , time.Local) fmt.Println(t2) fmt.Println("----------------" ) s1 := t1.Format("2006-1-2 15:04:05" ) fmt.Println(s1) s3 := "1999年10月10日" t3, err := time.Parse("2006年01月02日" , s3) if err != nil { fmt.Println("err: " , err) } fmt.Println(t3) fmt.Println("----------------" ) year, month, day := t1.Date() fmt.Println(year, month, day) hour, min, sec := t1.Clock() fmt.Println(hour, min, sec) fmt.Println("----------------" ) t4 := time.Date(2021 , 2 , 7 , 0 , 0 , 0 , 0 , time.UTC) timeStamp := t4.Unix() fmt.Println(timeStamp) fmt.Println("----------------" ) 2009 -11 -10 23 :00 :00 +0000 UTC m=+0.000000001 ---------------- 2008 -07 -15 16 :30 :28 +0000 UTC---------------- 2009 -11 -10 23 :00 :00 1999 -10 -10 00 :00 :00 +0000 UTC---------------- 2009 November 10 23 0 0 ---------------- 1612656000 ---------------- }
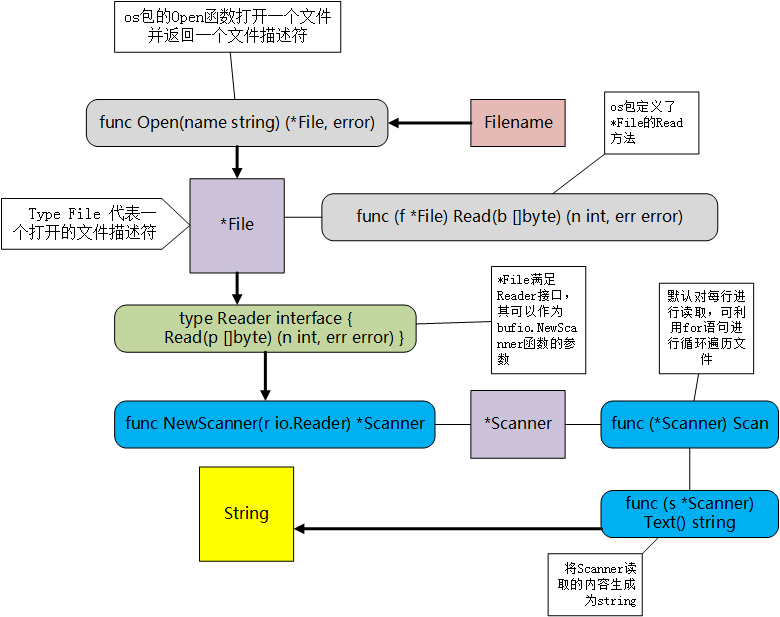
file类是在os包中的,封装了底层的文件描述符和相关信息,同时封装了Read和Write的实现
FileInfo接口中定义了File信息相关的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 package mainimport ( "os" "fmt" ) func main () fileInfo,err := os.Stat("/Users/ruby/Documents/pro/a/aa.txt" ) if err != nil { fmt.Println("err :" ,err) return } fmt.Printf("%T\n" ,fileInfo) fmt.Println(fileInfo.Name()) fmt.Println(fileInfo.Size()) fmt.Println(fileInfo.IsDir()) fmt.Println(fileInfo.ModTime()) fmt.Println(fileInfo.Mode()) }
linux下有2种文件权限表示方式,即"符号表示"和"八进制表示"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 (1)符号表示方式: - --- --- --- type owner group others 文件的权限是这样子分配的 读 写 可执行 分别对应的是 r w x 如果没有那一个权限,用 - 代替 (-文件 d目录 |连接符号) 例如:-rwxr-xr-x (2)八进制表示方式 r ——> 004 w ——> 002 x ——> 001 - ——> 000 0755 0777 0555 0444 0666
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 os.MkDir() os.MkDirAll() os.Create() os.Open(filename) os.OpenFile(filename, mode, perm) file.Close() os.Remove() os.RemoveAll()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 package mainimport ( "os" "fmt" "io" ) func main () fileName := "/Users/xxxx/Documents/test.txt" file, err := os.Open(fileName) if err != nil { fmt.Println("err:" , err) return } defer file.Close() bs := make ([]byte , 4 , 4 ) n := -1 for { n, err = file.Read(bs) if n == 0 || err == io.EOF{ fmt.Println("读取到了文件的末尾,结束读取操作。。" ) break } fmt.Println(string (bs[:n])) } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package mainimport ( "fmt" "os" ) func main () fileName := "/Users/xxxx/Documents/test.txt" file, err := os.OpenFile(fileName, os.O_CREATE|os.O_WRONLY|os.O_APPEND, os.ModePerm) if err != nil { fmt.Println(err) return } defer file.Close() bs :=[] byte {97 , 98 , 99 , 100 } file.WriteString("\n" ) }
可以直接使用io包下的Copy()方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 func copyFile (srcFile, destFile string ) int64 , error ){ file1, err := os.Open(srcFile) if err != nil { return 0 , err } file2, err := os.OpenFile(destFile, os.O_WRONLY|os.O_CREATE, os.ModePerm) if err != nil { return 0 , err } defer file1.Close() defer file2.Close() return io.Copy(file2, file1) }
还可以用ioutil包中的ioutil.WriteFile()和ioutil.ReadFile(),但由于使用一次性读取文件,再一次性写入文件的方式,所以该方法不适用于大文件,容易内存溢出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 func copyFile2 (srcFile, destFile string ) int , error ){ input, err := ioutil.ReadFile(srcFile) if err != nil { fmt.Println(err) return 0 , err } err = ioutil.WriteFile(destFile, input, 0644 ) if err != nil { fmt.Println("操作失败:" , destFile) fmt.Println(err) return 0 , err } return len (input), nil }
Seeker是包装基本Seek方法的接口,seek(offset,whence),设置指针光标的位置,随机读写文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 type Seeker interface { Seek(offset int64 , whence int ) (int64 , error ) } file,_:=os.OpenFile("/Users/xxx/Documents/test.txt" , os.O_RDWR, 0 ) defer file.Close()bs :=[]byte {0 } file.Read(bs) fmt.Println(string (bs)) file.Seek(4 ,io.SeekStart) file.Read(bs) fmt.Println(string (bs))
首先思考几个问题:
如果你要传的文件,比较大,那么是否有方法可以缩短耗时?
如果在文件传递过程中,程序因各种原因被迫中断了,那么下次再重启时,文件是否还需要重头开始?
传递文件的时候,支持暂停和恢复么?即使这两个操作分布在程序进程被杀前后
思路:想实现断点续传,主要就是记住上一次已经传递了多少数据,那我们可以创建一个临时文件temp.txt,记录已经传递的数据量,当恢复传递的时候,先从临时文件中读取上次已经传递的数据量,然后通过Seek()方法,设置到该读和该写的位置,再继续传递数据
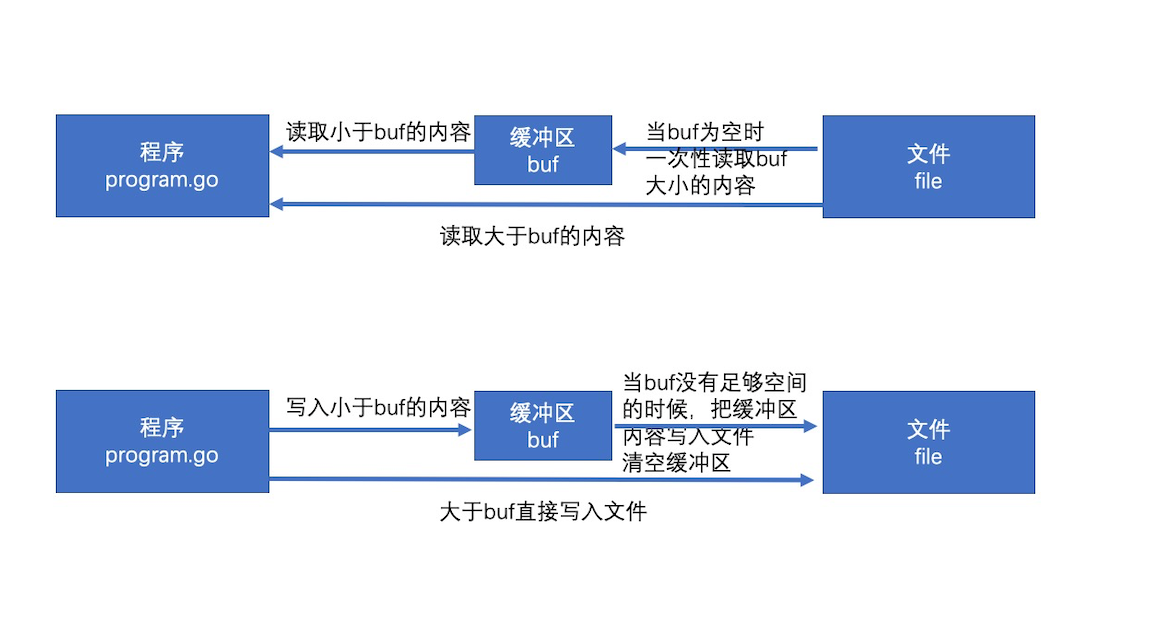
bufio是通过缓冲来提高效率。io操作本身的效率并不低,低的是频繁的访问本地磁盘的文件。所以bufio就提供了缓冲区(分配一块内存),读和写都先在缓冲区中,最后再读写文件,来降低访问本地磁盘的次数,从而提高效率
1 2 3 4 5 6 7 8 9 10 ReadBytes() ReadString() ReadLine() func (b *Writer) byte ) (nn int , err error ) func (b *Writer) byte ) error func (b *Writer) rune ) (size int , err error ) func (b *Writer) string ) (int , error )
除了io包可以读写数据,Go语言中还提供了一个辅助的工具包就是ioutil
1 2 3 4 5 import "io/ioutil" ReadFile() WriteFile() ReadDir()
可以使用ioutil包下的readDir()方法,这个方法可以获取指定目录下的内容,返回文件和子目录
因为文件夹下还有子文件夹,而ioutil包的ReadDir()只能获取一层目录,所以我们需要自己去设计算法来实现,最容易实现的思路就是使用递归
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 package mainimport ( "io/ioutil" "fmt" "log" ) func main () dirname := "/Users/xxx/Documents/aaaaaa" listFiles(dirname, 0 ) } func listFiles (dirname string , level int ) s := "|--" for i := 0 ; i < level; i++ { s = "| " + s } fileInfos, err := ioutil.ReadDir(dirname) if err != nil { log.Fatal(err) } for _, fi := range fileInfos { filename := dirname + "/" + fi.Name() fmt.Printf("%s%s\n" , s, filename) if fi.IsDir() { listFiles(filename, level+1 ) } } }
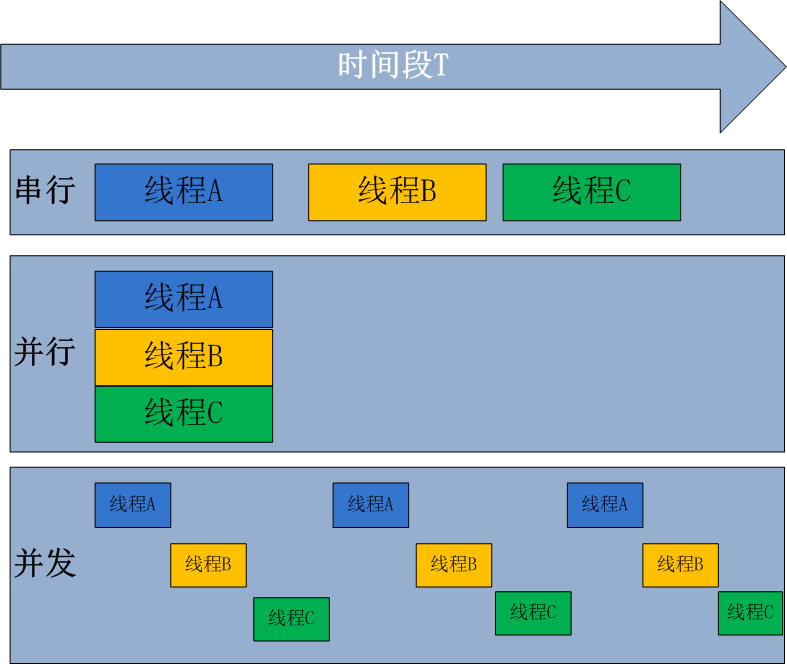
线程可以理解为轻量级的进程,而协程可以理解为轻量级的进程
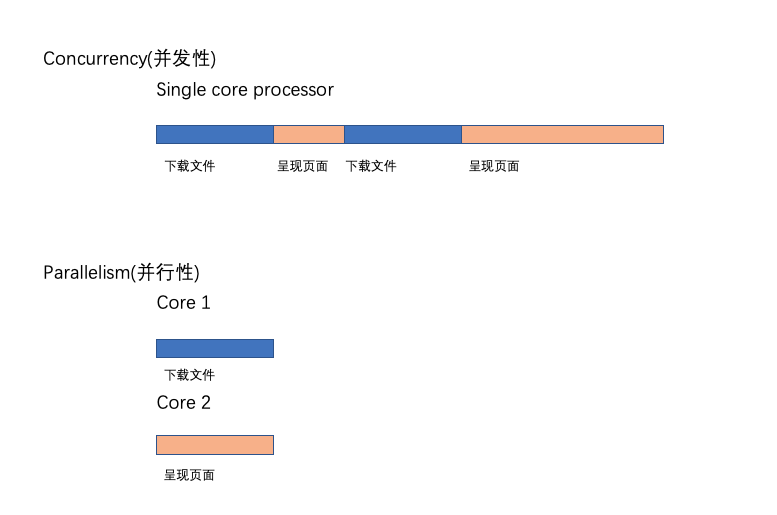
并发性(Concurrency)和并行性(parallelism):一种技术上的观点
假设我们正在编写一个web浏览器。web浏览器有各种组件。其中两个是web页面呈现区域和下载文件从internet下载的下载器。假设我们以这样的方式构建了浏览器的代码,这样每个组件都可以独立地执行。当这个浏览器运行在单个核处理器 中时,处理器将在浏览器的两个组件之间进行上下文切换。它可能会下载一个文件一段时间,然后它可能会切换到呈现用户请求的网页的html。这就是所谓的并发性 。并发进程从不同的时间点开始,它们的执行周期重叠。在这种情况下,下载和呈现从不同的时间点开始,它们的执行重叠
假设同一浏览器运行在多核处理器 上。在这种情况下,文件下载组件和HTML呈现组件可能同时在不同的内核中运行。这就是所谓的并行性
并行性Parallelism不会总是导致更快的执行时间。这是因为并行运行的组件可能需要相互通信
例如,在我们的浏览器中,当文件下载完成时,应该将其传递给用户,比如使用弹出窗口。这种通信发生在负责下载的组件和负责呈现用户界面的组件之间。这种通信开销在并发concurrent 系统中很低。当组件在多个内核中并行concurrent 运行时,这种通信开销很高。因此,并行程序并不总是导致更快的执行时间 !
进程(Process) :是一个程序在一个数据集中的一次动态执行过程,可以简单理解为"正在执行的程序",它是CPU资源分配和调度的独立单位。进程一般由程序、数据集、进程控制块 三部分组成:
我们编写的程序 用来描述进程要完成哪些功能以及如何完成;
数据集 则是程序在执行过程中所需要使用的资源;进程控制块 用来记录进程的外部特征,描述进程的执行变化过程,系统可以利用它来控制和管理进程,它是系统感知进程存在的唯一标志。
进程的局限是创建、撤销和切换的开销比较大
线程(Thread) :是在进程之后发展出来的概念。线程也叫轻量级进程,它是一个基本的CPU执行单元,也是程序执行过程中的最小单元,由线程ID、程序计数器、寄存器集合和堆栈 共同组成。一个进程可以包含多个线程
线程的优点 :是减小了程序并发执行时的开销,提高了操作系统的并发性能,缺点 :是线程没有自己的系统资源,只拥有在运行时必不可少的资源,但同一进程的各线程可以共享进程所拥有的系统资源,如果把进程比作一个车间,那么线程就好比是车间里面的工人。不过对于某些独占性资源存在锁机制,处理不当可能会产生"死锁"
协程(Coroutine) :是一种用户态的轻量级线程,又称微线程,协程的调度完全由用户控制。人们通常将协程和子程序(函数)比较着理解。子程序调用总是一个入口,一次返回,一旦退出即完成了子程序的执行
与传统的系统级线程和进程相比,协程的最大优势在于其"轻量级",可以轻松创建上百万个而不会导致系统资源衰竭,而线程和进程通常最多也不能超过1万的。这也是协程也叫轻量级线程的原因
协程与多线程相比,其优势体现在:协程的执行效率极高。因为子程序切换不是线程切换,而是由程序自身控制 ,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显
与线程相比,创建Goroutine的成本很小,他就是一段代码,一个函数入口,以及在堆上为其分配的一个堆栈(初始大小为4K,会随着程序的执行自动增长删除)。因此非常廉价,go应用程序可以并发运行数千个Goroutine
主Goroutine首先要做的:设定每一个主Goroutine所能申请的栈空间的最大尺寸。(32位计算机系统此尺寸为250MB,而64位计算机系统为1GB)。如果有某个主Goroutine的栈空间的尺寸大于这个限制,那么运行时系统会引发一个栈溢出 的运行时恐慌,随后这个go程序的运行也会终止
此后,主Goroutine会进行一系列的初始化工作,涉及的工作内容大致如下:
创建一个特殊的defer语句,用于在主Goroutine退出时做必要的善后处理,因为主Goroutine也可能非正常的结束
启动专用于在后台清扫内存垃圾的Goroutine,并设置GC可用的标识
执行main包中的init函数
执行main函数
执行完main函数后,它还会检查主Goroutine是否引发了运行时恐慌,并进行必要的处理,最后主Goroutine会结束自己以及当前进程的运行
在函数或方法调用前面加上关键字go,将会同时运行一个新的Goroutine
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package mainimport ( "fmt" ) func main () go hello() fmt.Println("Main function" ) } func hello () fmt.Println("Hello world Goroutine" ) }
需要注意的是:
当一个新的Goroutine开始时,Goroutine调用立即返回,与函数不同,go不等待Goroutine执行结束。当Goroutine调用,并且Goroutine的任何返回值被忽略之后,go立即执行到下一行代码
main的Goroutine应该为其他的Goroutine执行,如果main的Goroutine终止了,程序将被终止,而其他Goroutine将不会运行
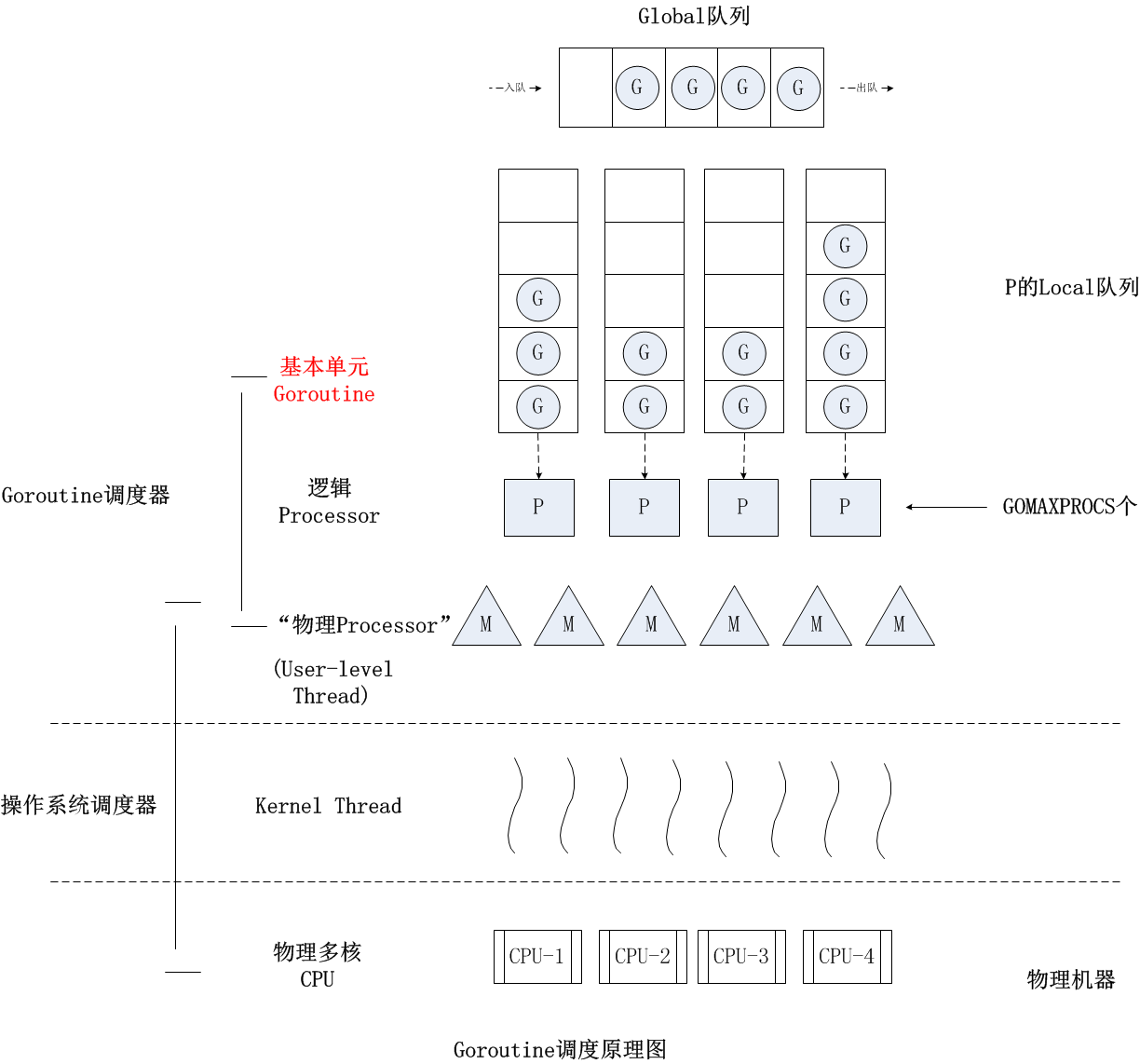
在操作系统提供的内核线程之上,Go搭建了一个特有的两级线程模型。goroutine机制实现了M : N的线程模型,goroutine机制是协程(coroutine)的一种实现,golang内置的调度器 ,可以让多核CPU中每个CPU执行一个协程
理解goroutine机制的原理,关键是理解Go语言scheduler的实现
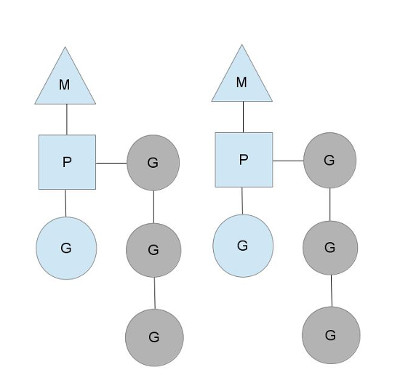
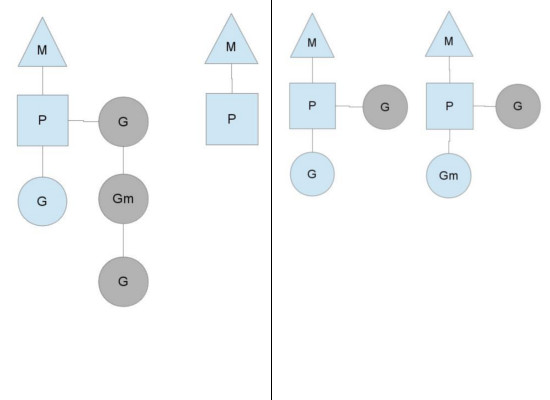
Go语言中支撑整个scheduler实现的主要有4个重要结构,分别是M、G、P、Sched, 前三个定义在runtime.h中,Sched定义在proc.c中
Sched结构就是调度器 ,它维护有存储M和G的队列以及调度器的一些状态信息等
G是goroutine实现的核心结构,它包含了栈,指令指针,以及其他对调度goroutine很重要的信息 ,例如其阻塞的channelP结构是Processor,处理器,它的主要用途就是用来执行goroutine的,它维护了一个goroutine队列 ,即runqueue。Processor是让我们从N:1调度到M:N调度的重要部分
M结构是Machine,系统线程,它由操作系统管理的,goroutine就是跑在M之上的;M是一个很大的结构,里面维护小对象内存cache(mcache)、当前执行的goroutine、随机数发生器等等非常多的信息
在单核处理器 的场景下,所有goroutine运行在同一个M系统线程中,每一个M系统线程维护一个Processor。任何时刻,一个Processor中只有一个goroutine,其他goroutine在runqueue中等待。一个goroutine运行完自己的时间片后,让出上下文,回到runqueue中
多核处理器 的场景下,为了运行goroutines,每个M系统线程会持有一个Processor
如图:当前程序有两个M,如果两个M都在一个CPU上运行,那么这是并发 ,如果两个M在不同的CPU上运行,那么这是并行 :
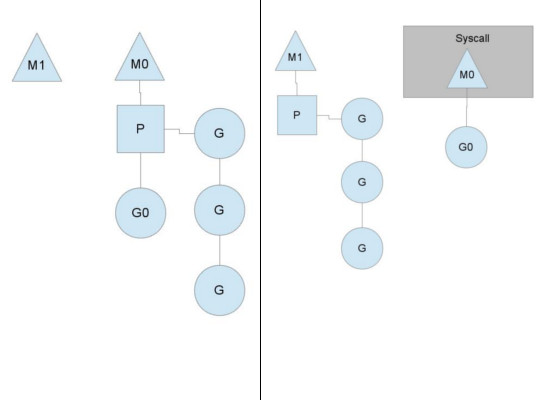
在正常情况下,scheduler会按照上面的流程进行调度,但是线程会发生阻塞 等情况。goroutine对线程阻塞等的处理如下:
当正在运行的goroutine阻塞的时候,例如进行系统调用,会再创建一个系统线程(M1),当前的M线程放弃了它的Processor,P转到新的线程中去运行:
原来是M0作为内核线程正在执行G0,而在P当中有三个协程正在等待。如果G0这个协程阻塞了(例如读取文件,数据库操作等等),这个时候就会创建M1这个线程,并且会将P的上下文环境与M1关联,队列中等待的3个协程会在M1下执行,而M0下面的G0仍然执行阻塞操作
当其中一个Processor的runqueue为空,没有goroutine可以调度时,它会从另外一个上下文偷取一半的goroutine
Go运行时系统通过构造G-P-M对象模型实现了一套用户态的并发调度系统,可以自己管理和调度自己的并发任务,所以可以说Go语言原生支持并发。自己实现的调度器负责将并发任务分配到不同的内核线程上运行,然后内核调度器接管内核线程在CPU上的执行与调度
某一个goroutine在访问某个数据资源的时候,按照数值,已经判断好了条件,然后又被其他的goroutine抢占了资源,并修改了数值,等这个goroutine再继续访问这个数据的时候,数值已经不对了
要想解决临界资源安全的问题,很多编程语言的解决方案都是同步。通过上锁 的方式,某一时间段,只能允许一个goroutine来访问这个共享数据,当前goroutine访问完毕,解锁后,其他的goroutine才能来访问
当然可以借助于sync包下的锁操作
不要以共享内存的方式去通信,而要以通信的方式去共享内存
在Go语言中并不鼓励用锁保护共享状态的方式在不同的Goroutine中分享信息(以共享内存的方式去通信),而是鼓励通过channel将共享状态或共享状态的变化在各个Goroutine之间传递 (以通信的方式去共享内存),这样同样能像用锁一样保证在同一的时间只有一个Goroutine访问共享状态
sync叫做同步包。这里提供了基本同步的操作,比如互斥锁等等。这里除了Once和WaitGroup类型之外,大多数类型都是供低级库例程使用的。更高级别的同步最好通过channel通道和communication通信来完成
WaitGroup,叫做同步等待组 。在类型上,它是一个结构体。一个WaitGroup的用途是等待一个goroutine的集合执行完成
主goroutine调用了Add()方法来设置要等待的goroutine的数量。然后,每个goroutine都会执行并且执行完成后调用Done()这个方法。与此同时,可以使用Wait()方法来阻塞,直到所有的goroutine都执行完成
Add() :用来设置到WaitGroup的计数器的值。可以理解为每个waitgroup中都有一个计数器,用来表示这个同步等待组中要执行的goroutin的数量 ,如果计数器的数值变为0,那么就表示等待时被阻塞的goroutine都被释放,如果计数器的数值为负数,那么就会引发panicDone() :当WaitGroup同步等待组中的某个goroutine执行完毕后,设置这个WaitGroup的counter数值减1Wait() :表示让当前的goroutine等待,进入阻塞状态。一直到WaitGroup的计数器为零。才能解除阻塞 ,这个goroutine才能继续执行
示例代码:创建并启动两个goroutine,来打印数字和字母,并在main goroutine中,将这两个子goroutine加入到一个WaitGroup中,同时让main goroutine进入Wait(),让两个子goroutine先执行。当每个子goroutine执行完毕后,调用Done()方法,设置WaitGroup的counter减1。当两条子goroutine都执行完毕后,WaitGroup中的counter的数值为零,解除main goroutine的阻塞
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 package mainimport ( "fmt" "sync" ) var wg sync.WaitGroup func main () wg.Add(2 ) go fun1() go fun2() fmt.Println("main进入阻塞状态。。。等待wg中的子goroutine结束。。" ) wg.Wait() fmt.Println("main,解除阻塞。。" ) } func fun1 () for i:=1 ;i<=10 ;i++{ fmt.Println("fun1.。。i:" ,i) } wg.Done() } func fun2 () defer wg.Done() for j:=1 ;j<=10 ;j++{ fmt.Println("\tfun2..j," ,j) } }
在并发程序中,会存在临界资源问题。就是当多个协程来访问共享的数据资源,那么这个共享资源是不安全的 。为了解决协程同步的问题我们使用了channel,但是Go语言也提供了传统的同步工具,即互斥锁
锁,就是某个协程(线程)在访问某个资源时先上锁,防止其它协程的访问,等访问完毕解锁后其他协程再来加锁进行访问。一般用于处理并发中的临界资源问题
Mutex互斥锁:当一个goroutine获得了Mutex后,其他goroutine就只能等到这个goroutine释放该Mutex。每个资源都对应于一个可称为"互斥锁"的标记,这个标记用来保证在任意时刻,只能有一个协程(线程)访问该资源。其它的协程只能等待
互斥锁是传统并发编程对共享资源进行访问控制的主要手段,它由标准库sync中的Mutex结构体类型表示。sync.Mutex类型只有两个公开的指针方法,Lock和Unlock。Lock锁定当前的共享资源,Unlock进行解锁
Lock() :锁定m,如果该锁已在使用中,则调用goroutine将阻塞,直到互斥体可用Unlock() :解锁m,如果m未在要解锁的条目上锁定,则为运行时错误
在使用互斥锁时,需要注意:对资源操作完成后,一定要解锁 ,否则会出现流程执行异常,死锁等问题。通常借助defer。锁定后,立即使用defer语句保证互斥锁及时解锁
示例代码:使用goroutine,模拟4个售票口出售火车票的案例。4个售票口同时卖票,会发生临界资源数据安全问题(售出了0票和负数票)。这里使用互斥锁解决:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 package mainimport ( "fmt" "time" "math/rand" "sync" ) var ticket = 10 var mutex sync.Mutex var wg sync.WaitGroup func main () wg.Add(4 ) go saleTickets("售票口1" ) go saleTickets("售票口2" ) go saleTickets("售票口3" ) go saleTickets("售票口4" ) wg.Wait() fmt.Println("程序结束了。。。" ) } func saleTickets (name string ) rand.Seed(time.Now().UnixNano()) defer wg.Done() for { mutex.Lock() if ticket > 0 { time.Sleep(time.Duration(rand.Intn(1000 ))*time.Millisecond) fmt.Println(name,"售出:" ,ticket) ticket-- }else { mutex.Unlock() fmt.Println(name,"售罄,没有票了。。" ) break } mutex.Unlock() } } 售票口4 售出: 10 售票口4 售出: 9 售票口2 售出: 8 售票口1 售出: 7 售票口3 售出: 6 售票口4 售出: 5 售票口2 售出: 4 售票口1 售出: 3 售票口3 售出: 2 售票口4 售出: 1 售票口2 售罄,没有票了。。 售票口1 售罄,没有票了。。 售票口3 售罄,没有票了。。 售票口4 售罄,没有票了。。 程序结束了。。。
一旦上锁,意味着上锁和解锁中间的代码是同步的,即一次只能被1条goroutine访问,中间不可被其他goroutine打断执行
当有一个goroutine获得写锁定 ,其它无论是读锁定还是写锁定都将阻塞直到写解锁;当有一个goroutine获得读锁定 ,其它读锁定仍然可以继续;当有一个或任意多个读锁定,写锁定将等待所有读锁定解锁之后才能够进行写锁定
RLock() :读锁,当有写锁时,无法加载读锁,当只有读锁或者没有锁时,可以加载读锁,读锁可以加载多个,所以适用于“读多写少”的场景RUnlock() :读锁解锁,RUnlock 撤销单次RLock调用,它对于其它同时存在的读取器则没有效果。若rw并没有为读取而锁定,调用RUnlock就会引发一个运行时错Lock() :写锁,如果在添加写锁之前已经有其他的读锁和写锁,则Lock就会阻塞直到该锁可用,为确保该锁最终可用,已阻塞的Lock调用会从获得的锁中排除新的读取锁,即写锁权限高于读锁,有写锁时优先进行写锁定 Unlock() :写锁解锁,如果没有进行写锁定,则就会引起一个运行时错误
基本遵循两大原则:
可以随便读,多个goroutine同时读 写的时候,什么也不能干。不能读也不能写
RWMutex(读写锁)
读锁不能阻塞读锁
读锁需要阻塞写锁,直到所有读锁都释放
写锁需要阻塞读锁,直到所有写锁都释放
写锁需要阻塞写锁
这句话的解释为:Go语言中,要传递某个数据给另一个goroutine(协程),可以把这个数据封装成一个对象,然后把这个对象的指针传入某个channel中,另外一个goroutine从这个channel中读出这个指针,并处理其指向的内存对象。Go从语言层面保证同一个时间只有一个goroutine能够访问channel里面的数据,为开发者提供了一种优雅简单的工具,所以Go的做法就是使用channel来通信,通过通信来传递内存数据,使得内存数据在不同的goroutine中传递,而不是使用共享内存来通信
每个通道都有与其相关的类型。该类型是通道允许传输的数据类型。(通道的零值为nil。nil通道没有任何用处,因此通道必须使用类似于map和切片的方法来定义。)
1 2 3 4 5 6 7 8 var 通道名 chan 数据类型通道名 = make (chan 数据类型) a := make (chan int )
每个channel都有相关联的数据类型, nil chan不能使用,类似于nil map,不能直接存储键值对
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package mainimport "fmt" func main () var a chan int fmt.Println("%T, %v\n" , a, a) if a == nil { fmt.Println("channel是nil的, 不能使用,需要先创建通道" ) a = make (chan int ) fmt.Printf(a) } } chan int , <nil >channel是nil 的, 不能使用,需要先创建通道 0xc00009e000
channel是引用类型 的数据,在作为参数传递的时候,传递的是内存地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package mainimport ( "fmt" ) func main () ch1 := make (chan int ) fmt.Printf("%T, %p\n" , ch1, ch1) test1(ch1) } func test1 (ch chan int ) fmt.Printf("%T, %p\n" , ch, ch) } chan int , 0xc00008e000 chan int , 0xc00008e000
1 2 3 data := <- a a <- data
这里默认是没有缓冲区的通道
一个通道发送和接收数据,默认是阻塞的。当一个数据被发送到通道时,在发送语句中被阻塞,直到另一个Goroutine从该通道读取数据。相对地,当从通道读取数据时,读取被阻塞,直到一个Goroutine将数据写入该通道
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 package mainimport ( "fmt" "time" ) func main () ch1 := make (chan int ) go func () fmt.Println("子goroutine执行" ) time.Sleep(3 * time.Second) data := <-ch1 fmt.Println("data:" , data) }() time.Sleep(5 * time.Second) ch1 <- 10 fmt.Println("main。。over" ) } 子goroutine执行 data:10 main。。over
使用通道时要考虑的一个重要因素是死锁。以下2种情况会发生死锁:
有读操作,但是没有写操作与其对应
有写操作,但是没有读操作与其对应
因为无法解除阻塞,程序无法正常向下执行
发送者可以通过关闭信道,来通知接收方不会有更多的数据被发送到channel上
接收者可以在接收来自通道的数据时使用额外的变量来检查通道是否已经关闭
用于goroutine,传递消息的。
通道,每个都有相关联的数据类型, nil chan,不能使用,类似于nil map,不能直接存储键值对
使用通道传递数据:<-
chan <- data,发送数据到通道。向通道中写数据
data <- chan,从通道中获取数据。从通道中读数据
阻塞:
发送数据:chan <- data,阻塞的,直到另一条goroutine,读取数据来解除阻塞
读取数据:data <- chan,也是阻塞的。直到另一条goroutine,写出数据解除阻塞。
本身channel就是同步的,意味着同一时间,只能有一条goroutine来操作
通道是goroutine之间的连接,所以通道的发送和接收必须处在不同的goroutine中
1 2 3 4 5 6 7 8 9 10 11 12 package mainimport ( "fmt" ) func main () }
Go 1.18 引入了泛型 ,这是 Go 语言历史上最重要的特性之一。泛型允许你编写更加灵活、可复用的代码,同时保持类型安全。
在泛型出现之前,如果想写一个通用的函数(比如查找切片中的元素),有以下几种方式:
为每种类型写一个函数 :代码重复,维护困难使用 interface{} :失去类型安全,需要类型断言使用反射 :性能较差,代码复杂
泛型解决了这些问题,让你可以写出类型安全且高效的通用代码。
使用方括号 [] 定义类型参数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 func PrintInt (s []int ) for _, v := range s { fmt.Println(v) } } func PrintString (s []string ) for _, v := range s { fmt.Println(v) } } func Print [T any ](s []T) for _, v := range s { fmt.Println(v) } } func main () Print([]int {1 , 2 , 3 }) Print([]string {"a" , "b" , "c" }) Print[float64 ]([]float64 {1.1 , 2.2 }) }
使用接口定义类型约束,限制泛型参数的类型范围:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 type Number interface { int | int8 | int16 | int32 | int64 | float32 | float64 } func Sum [T Number ](numbers []T) var total T for _, n := range numbers { total += n } return total } func main () fmt.Println(Sum([]int {1 , 2 , 3 , 4 })) fmt.Println(Sum([]float64 {1.1 , 2.2 , 3.3 })) }
Go 提供了一些内置的约束类型,在 constraints 包中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import "golang.org/x/exp/constraints" func Min [T constraints .Ordered ](a, b T) if a < b { return a } return b } func main () fmt.Println(Min(10 , 20 )) fmt.Println(Min(3.14 , 2.71 )) fmt.Println(Min("apple" , "banana" )) }
常用内置约束:
any:任意类型(等价于 interface{})comparable:可以使用 == 和 != 比较的类型constraints.Ordered:可以比较大小的类型constraints.Integer:所有整数类型constraints.Float:所有浮点类型constraints.Complex:所有复数类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 type Stack[T any] struct { items []T } func (s *Stack[T]) s.items = append (s.items, item) } func (s *Stack[T]) bool ) { if len (s.items) == 0 { var zero T return zero, false } item := s.items[len (s.items)-1 ] s.items = s.items[:len (s.items)-1 ] return item, true } func (s *Stack[T]) bool { return len (s.items) == 0 } func main () intStack := Stack[int ]{} intStack.Push(1 ) intStack.Push(2 ) intStack.Push(3 ) val, ok := intStack.Pop() fmt.Println(val, ok) strStack := Stack[string ]{} strStack.Push("hello" ) strStack.Push("world" ) str, ok := strStack.Pop() fmt.Println(str, ok) }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 func Index [T comparable ](s []T, target T) int { for i, v := range s { if v == target { return i } } return -1 } func Filter [T any ](s []T, predicate func (T) bool ) []T { result := []T{} for _, v := range s { if predicate(v) { result = append (result, v) } } return result } func Map [T , U any ](s []T, mapper func (T) result := make ([]U, len (s)) for i, v := range s { result[i] = mapper(v) } return result } func main () nums := []int {1 , 2 , 3 , 4 , 5 } fmt.Println(Index(nums, 3 )) evens := Filter(nums, func (n int ) bool { return n%2 == 0 }) fmt.Println(evens) strs := Map(nums, func (n int ) string { return fmt.Sprintf("num_%d" , n) }) fmt.Println(strs) }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 func Keys [K comparable , V any ](m map [K]V) keys := make ([]K, 0 , len (m)) for k := range m { keys = append (keys, k) } return keys } func Values [K comparable , V any ](m map [K]V) values := make ([]V, 0 , len (m)) for _, v := range m { values = append (values, v) } return values } func main () ages := map [string ]int { "Alice" : 30 , "Bob" : 25 , "Carol" : 35 , } fmt.Println(Keys(ages)) fmt.Println(Values(ages)) }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 type Container[T any] interface { Add(item T) Remove() (T, bool ) Size() int } type Queue[T any] struct { items []T } func (q *Queue[T]) q.items = append (q.items, item) } func (q *Queue[T]) bool ) { if len (q.items) == 0 { var zero T return zero, false } item := q.items[0 ] q.items = q.items[1 :] return item, true } func (q *Queue[T]) int { return len (q.items) } func ProcessContainer [T any ](c Container[T], items []T) for _, item := range items { c.Add(item) } fmt.Printf("Container size: %d\n" , c.Size()) } func main () queue := &Queue[string ]{} ProcessContainer(queue, []string {"a" , "b" , "c" }) }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 import ( "sync" "time" ) type Cache[K comparable, V any] struct { mu sync.RWMutex items map [K]cacheItem[V] } type cacheItem[V any] struct { value V expiration time.Time } func NewCache [K comparable , V any ]() return &Cache[K, V]{ items: make (map [K]cacheItem[V]), } } func (c *Cache[K, V]) c.mu.Lock() defer c.mu.Unlock() c.items[key] = cacheItem[V]{ value: value, expiration: time.Now().Add(duration), } } func (c *Cache[K, V]) bool ) { c.mu.RLock() defer c.mu.RUnlock() item, exists := c.items[key] if !exists || time.Now().After(item.expiration) { var zero V return zero, false } return item.value, true } func (c *Cache[K, V]) c.mu.Lock() defer c.mu.Unlock() delete (c.items, key) } func main () strCache := NewCache[string , string ]() strCache.Set("user:1" , "Alice" , 5 *time.Second) if val, ok := strCache.Get("user:1" ); ok { fmt.Println("Found:" , val) } type User struct { ID int Name string } userCache := NewCache[int , User]() userCache.Set(1 , User{ID: 1 , Name: "Bob" }, 10 *time.Second) if user, ok := userCache.Get(1 ); ok { fmt.Printf("User: %+v\n" , user) } }
优先使用具体类型 :只有在确实需要复用代码时才使用泛型选择合适的约束 :
需要比较?使用 comparable
需要排序?使用 constraints.Ordered
任意类型?使用 any
避免过度泛型化 :泛型会增加代码复杂度,权衡利弊方法不能声明额外的类型参数 :只能使用类型定义时的参数泛型性能 :与非泛型代码性能相当,编译器会进行优化
泛型方法不能有额外的类型参数(只能使用类型声明的参数)
类型参数不能用于类型断言和类型选择
不支持泛型的运算符重载
某些复杂的类型约束可能难以表达
Go 1.23 引入了 range over function 特性,允许你在 for-range 循环中直接使用函数作为迭代目标。这个特性极大地增强了迭代器的灵活性和表达能力。
在 Go 1.23 之前,for-range 只能遍历以下类型:
如果想要自定义迭代逻辑,需要:
创建 channel 并用 goroutine 发送数据(开销大)
返回切片(需要一次性生成所有数据)
使用迭代器模式(代码冗长)
range over function 让你可以直接定义迭代逻辑,实现惰性求值和自定义迭代器。
迭代器函数的签名必须符合以下格式之一:
1 2 3 4 5 func (yield func (V) bool )func (yield func (K, V) bool )
yield 函数用于"产出"值,返回 false 表示停止迭代。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 package mainimport "fmt" func Counter (max int ) func (func (int ) bool ) { return func (yield func (int ) bool ) { for i := 0 ; i < max; i++ { if !yield(i) { return } } } } func main () for i := range Counter(5 ) { fmt.Println(i) } for i := range Counter(10 ) { if i >= 3 { break } fmt.Println(i) } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 func Fibonacci (max int ) func (func (int ) bool ) { return func (yield func (int ) bool ) { a, b := 0 , 1 for i := 0 ; i < max; i++ { if !yield(a) { return } a, b = b, a+b } } } func main () fmt.Println("前 10 个斐波那契数:" ) for num := range Fibonacci(10 ) { fmt.Print(num, " " ) } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import ( "bufio" "fmt" "os" ) func Lines (filename string ) func (func (string ) bool ) { return func (yield func (string ) bool ) { file, err := os.Open(filename) if err != nil { return } defer file.Close() scanner := bufio.NewScanner(file) for scanner.Scan() { if !yield(scanner.Text()) { return } } } } func main () for line := range Lines("data.txt" ) { fmt.Println(line) } count := 0 for line := range Lines("data.txt" ) { fmt.Println(line) count++ if count >= 5 { break } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 type TreeNode struct { Value int Left *TreeNode Right *TreeNode } func (t *TreeNode) func (func (int ) bool ) { return func (yield func (int ) bool ) { var traverse func (*TreeNode) bool traverse = func (node *TreeNode) bool { if node == nil { return true } if !traverse(node.Left) { return false } if !yield(node.Value) { return false } return traverse(node.Right) } traverse(t) } } func main () tree := &TreeNode{ Value: 4 , Left: &TreeNode{ Value: 2 , Left: &TreeNode{Value: 1 }, Right: &TreeNode{Value: 3 }, }, Right: &TreeNode{ Value: 6 , Left: &TreeNode{Value: 5 }, Right: &TreeNode{Value: 7 }, }, } fmt.Println("中序遍历:" ) for val := range tree.InOrder() { fmt.Print(val, " " ) } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 func FilterMap [K comparable , V any ](m map [K]V, predicate func (K, V) bool ) func (func (K, V) bool ) { return func (yield func (K, V) bool ) { for k, v := range m { if predicate(k, v) { if !yield(k, v) { return } } } } } func main () ages := map [string ]int { "Alice" : 30 , "Bob" : 17 , "Carol" : 25 , "David" : 16 , } fmt.Println("成年人:" ) for name, age := range FilterMap(ages, func (k string , v int ) bool { return v >= 18 }) { fmt.Printf("%s: %d\n" , name, age) } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 func Enumerate [T any ](slice []T) func (func (int , T) bool ) { return func (yield func (int , T) bool ) { for i, v := range slice { if !yield(i, v) { return } } } } func main () fruits := []string {"apple" , "banana" , "cherry" } for i, fruit := range Enumerate(fruits) { fmt.Printf("%d: %s\n" , i, fruit) } }
range over function 支持惰性求值,非常适合处理无限序列:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 func Integers () func (func (int ) bool ) { return func (yield func (int ) bool ) { i := 0 for { if !yield(i) { return } i++ } } } func Map [T , U any ](iter func (func (T) bool ), mapper func (T) func (func (U) bool ) { return func (yield func (U) bool ) { iter(func (v T) bool { return yield(mapper(v)) }) } } func Filter [T any ](iter func (func (T) bool ), predicate func (T) bool ) func (func (T) bool ) { return func (yield func (T) bool ) { iter(func (v T) bool { if predicate(v) { return yield(v) } return true }) } } func Take [T any ](iter func (func (T) bool ), n int ) func (func (T) bool ) { return func (yield func (T) bool ) { count := 0 iter(func (v T) bool { if count >= n { return false } count++ return yield(v) }) } } func main () evenSquares := Take( Map( Filter(Integers(), func (n int ) bool { return n%2 == 0 }), func (n int ) int { return n * n }, ), 10 , ) for num := range evenSquares { fmt.Print(num, " " ) } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 import ( "fmt" "time" ) type Page struct { Items []string HasNext bool } func fetchPage (pageNum int ) time.Sleep(100 * time.Millisecond) if pageNum > 3 { return Page{Items: []string {}, HasNext: false } } items := []string { fmt.Sprintf("item_%d_1" , pageNum), fmt.Sprintf("item_%d_2" , pageNum), fmt.Sprintf("item_%d_3" , pageNum), } return Page{Items: items, HasNext: pageNum < 3 } } func PaginatedData () func (func (string ) bool ) { return func (yield func (string ) bool ) { pageNum := 1 for { page := fetchPage(pageNum) for _, item := range page.Items { if !yield(item) { return } } if !page.HasNext { break } pageNum++ } } } func main () fmt.Println("遍历所有分页数据:" ) for item := range PaginatedData() { fmt.Println(item) } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 func Chain [T any ](iters ...func (func (T) bool )) func (func (T) bool ) { return func (yield func (T) bool ) { for _, iter := range iters { iter(func (v T) bool { return yield(v) }) } } } func Zip [T , U any ](iter1 func (func (T) bool ), iter2 func (func (U) bool )) func (func (T, U) bool ) { return func (yield func (T, U) bool ) { var values1 []T var values2 []U iter1(func (v T) bool { values1 = append (values1, v) return true }) iter2(func (v U) bool { values2 = append (values2, v) return true }) minLen := len (values1) if len (values2) < minLen { minLen = len (values2) } for i := 0 ; i < minLen; i++ { if !yield(values1[i], values2[i]) { return } } } } func main () iter1 := Counter(3 ) iter2 := Counter(3 ) fmt.Println("Chain 连接两个迭代器:" ) for i := range Chain(iter1, iter2) { fmt.Print(i, " " ) } names := func (yield func (string ) bool ) { for _, name := range []string {"Alice" , "Bob" , "Carol" } { if !yield(name) { return } } } ages := func (yield func (int ) bool ) { for _, age := range []int {30 , 25 , 35 } { if !yield(age) { return } } } fmt.Println("\nZip 组合两个迭代器:" ) for name, age := range Zip(names, ages) { fmt.Printf("%s: %d\n" , name, age) } }
Go 1.23 引入了 iter 标准库包,提供了迭代器的标准类型定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import "iter" func CounterWithIter (max int ) int ] { return func (yield func (int ) bool ) { for i := 0 ; i < max; i++ { if !yield(i) { return } } } } func EnumerateWithIter [T any ](slice []T) int , T] { return func (yield func (int , T) bool ) { for i, v := range slice { if !yield(i, v) { return } } } } func main () for i := range CounterWithIter(5 ) { fmt.Println(i) } fruits := []string {"apple" , "banana" , "cherry" } for i, fruit := range EnumerateWithIter(fruits) { fmt.Printf("%d: %s\n" , i, fruit) } }
遵循 yield 返回值 :当 yield 返回 false 时立即返回,尊重调用者的停止意图使用 iter 包类型 :使用 iter.Seq[V] 和 iter.Seq2[K, V] 提高代码可读性惰性求值 :只在需要时计算值,避免一次性生成所有数据资源清理 :在迭代器函数中使用 defer 确保资源正确释放组合迭代器 :构建小的、可复用的迭代器函数,然后组合它们
内存效率 :无需一次性生成所有数据提前退出 :可以在任何时候停止迭代惰性计算 :只计算实际需要的值零分配 (在某些场景下):相比返回切片,可以减少内存分配
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 for item := range Items() { fmt.Println(item) } for item in items(): print (item) for (const item of items()) { console.log(item) } for item in items() { println !("{}" , item); }
Go 的 range over function 提供了类似其他现代语言的迭代器体验,同时保持了 Go 的简洁性。
Gin特点和特性:
速度 :Gin之所以被很多企业和团队所采用,第一个原因是因为其速度快,性能表现出众中间件 :和iris类似,gin在处理请求时,支持中间件操作,方便编码处理路由 :在gin中可以非常简单的实现路由解析的功能,并包含路由解析功能内置渲染 :gin支持JSON,XML和HTML等多种数据格式的渲染,并提供了方便的操作API
1 2 3 4 5 6 7 8 9 10 11 12 package mainimport ( "fmt" ) func main () }
下面是一个包含 Go 所有核心概念的完整示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 package mainimport ( "context" "errors" "fmt" "sync" "time" ) type Movable interface { Move() string GetSpeed() float64 } type Soundable interface { MakeSound() string } type Animal interface { Soundable Eat() string Sleep() string GetName() string GetAge() int } type BaseAnimal struct { name string age int } var animalCount int = 0 func (b BaseAnimal) string { return b.name } func (b BaseAnimal) int { return b.age } func (b BaseAnimal) string { return fmt.Sprintf("%s 正在睡觉" , b.name) } func (b *BaseAnimal) string ) { b.name = name } func (b *BaseAnimal) int ) error { if age < 0 || age > 100 { return errors.New("年龄必须在 0-100 之间" ) } b.age = age return nil } type Dog struct { BaseAnimal breed string speed float64 mu sync.Mutex } func NewDog (name string , age int , breed string ) animalCount++ return &Dog{ BaseAnimal: BaseAnimal{name: name, age: age}, breed: breed, speed: 0.0 , } } func (d *Dog) string { return fmt.Sprintf("%s 汪汪叫" , d.name) } func (d *Dog) string { return fmt.Sprintf("%s 正在吃骨头" , d.name) } func (d *Dog) string { parentMsg := d.BaseAnimal.Sleep() return fmt.Sprintf("%s,睡得很香" , parentMsg) } func (d *Dog) string { return fmt.Sprintf("%s 正在奔跑,速度: %.1fkm/h" , d.name, d.speed) } func (d *Dog) float64 { d.mu.Lock() defer d.mu.Unlock() return d.speed } func (d *Dog) float64 ) { d.mu.Lock() defer d.mu.Unlock() d.speed = speed } func (d *Dog) fmt.Printf("%s 汪!\n" , d.name) } func (d *Dog) int ) { for i := 0 ; i < times; i++ { fmt.Printf("%s 汪!\n" , d.name) } } func (d *Dog) string ) { fmt.Printf("%s 说: %s\n" , d.name, message) } func (d *Dog) string { return fmt.Sprintf("Dog{name: %s, age: %d, breed: %s}" , d.name, d.age, d.breed) } type Cat struct { BaseAnimal } func NewCat (name string , age int ) animalCount++ return &Cat{ BaseAnimal: BaseAnimal{name: name, age: age}, } } func (c *Cat) string { return fmt.Sprintf("%s 喵喵叫" , c.name) } func (c *Cat) string { return fmt.Sprintf("%s 正在吃鱼" , c.name) } type AnimalShelter[T Animal] struct { animals []T mu sync.RWMutex } func NewAnimalShelter [T Animal ]() return &AnimalShelter[T]{ animals: make ([]T, 0 ), } } func (s *AnimalShelter[T]) s.mu.Lock() defer s.mu.Unlock() s.animals = append (s.animals, animal) } func (s *AnimalShelter[T]) s.mu.RLock() defer s.mu.RUnlock() result := make ([]T, len (s.animals)) copy (result, s.animals) return result } func (s *AnimalShelter[T]) int { s.mu.RLock() defer s.mu.RUnlock() return len (s.animals) } type AnimalError struct { Animal string Message string } func (e *AnimalError) string { return fmt.Sprintf("AnimalError[%s]: %s" , e.Animal, e.Message) } func ValidateAnimal (a Animal) error { if a.GetName() == "" { return &AnimalError{Animal: "Unknown" , Message: "名字不能为空" } } if a.GetAge() < 0 { return &AnimalError{Animal: a.GetName(), Message: "年龄不能为负数" } } return nil } func DescribeAnimal (a Animal) fmt.Printf("动物: %s, 年龄: %d\n" , a.GetName(), a.GetAge()) if dog, ok := a.(*Dog); ok { fmt.Printf(" 这是一只 %s 品种的狗\n" , dog.breed) } else if cat, ok := a.(*Cat); ok { fmt.Printf(" 这是一只猫: %v\n" , cat) } switch v := a.(type ) { case *Dog: fmt.Printf(" 类型: Dog, 品种: %s\n" , v.breed) case *Cat: fmt.Printf(" 类型: Cat\n" ) default : fmt.Printf(" 未知类型\n" ) } } func MapAnimals (animals []Animal, fn func (Animal) string ) []string { result := make ([]string , len (animals)) for i, a := range animals { result[i] = fn(a) } return result } func FilterAnimals (animals []Animal, predicate func (Animal) bool ) []Animal { result := make ([]Animal, 0 ) for _, a := range animals { if predicate(a) { result = append (result, a) } } return result } func MakeMultiplier (factor int ) func (int ) int { return func (x int ) int { return x * factor } } func BarkConcurrently (dogs []*Dog, times int ) done := make (chan bool , len (dogs)) for _, dog := range dogs { go func (d *Dog) for i := 0 ; i < times; i++ { fmt.Printf("[Goroutine] %s 汪!\n" , d.GetName()) time.Sleep(100 * time.Millisecond) } done <- true }(dog) } for i := 0 ; i < len (dogs); i++ { <-done } close (done) } func AnimalChannel () chan Animal { ch := make (chan Animal, 3 ) go func () ch <- NewDog("旺财" , 3 , "金毛" ) ch <- NewCat("小咪" , 2 ) ch <- NewDog("大黄" , 5 , "哈士奇" ) close (ch) }() return ch } func ProcessWithContext (ctx context.Context, name string ) error { select { case <-time.After(2 * time.Second): fmt.Printf("%s 处理完成\n" , name) return nil case <-ctx.Done(): return fmt.Errorf("%s 处理被取消: %v" , name, ctx.Err()) } } func SafeOperation () defer func () if r := recover (); r != nil { fmt.Printf("捕获 panic: %v\n" , r) } }() var arr []int fmt.Println(arr[10 ]) } func main () fmt.Println("=== Go 核心概念综合演示 ===\n" ) fmt.Println("1. 结构体和方法:" ) dog := NewDog("旺财" , 3 , "金毛" ) cat := NewCat("小咪" , 2 ) fmt.Printf("创建了: %s\n" , dog) fmt.Printf("创建了: Cat{name: %s, age: %d}\n" , cat.GetName(), cat.GetAge()) fmt.Println("\n2. 指针接收者(可修改):" ) fmt.Printf("狗的名字: %s\n" , dog.GetName()) dog.SetName("大黄" ) fmt.Printf("修改后: %s\n" , dog.GetName()) fmt.Println("\n3. 接口和多态:" ) animals := []Animal{dog, cat} for _, animal := range animals { fmt.Println(animal.MakeSound()) fmt.Println(animal.Eat()) } fmt.Println("\n4. 类型断言和类型选择:" ) DescribeAnimal(dog) fmt.Println("\n5. 泛型:" ) shelter := NewAnimalShelter[*Dog]() shelter.Add(dog) shelter.Add(NewDog("小黑" , 2 , "哈士奇" )) fmt.Printf("收容所有 %d 只狗\n" , shelter.Len()) fmt.Println("\n6. 错误处理:" ) if err := ValidateAnimal(dog); err != nil { fmt.Printf("验证失败: %v\n" , err) } else { fmt.Println("验证通过" ) } badDog := &Dog{BaseAnimal: BaseAnimal{name: "" , age: -1 }} if err := ValidateAnimal(badDog); err != nil { fmt.Printf("验证失败: %v\n" , err) } fmt.Println("\n7. Defer(延迟执行):" ) fmt.Println("开始" ) defer fmt.Println("第一个 defer" ) defer fmt.Println("第二个 defer" ) fmt.Println("结束" ) fmt.Println("\n8. 高阶函数:" ) names := MapAnimals(animals, func (a Animal) string { return a.GetName() }) fmt.Printf("动物名字: %v\n" , names) youngAnimals := FilterAnimals(animals, func (a Animal) bool { return a.GetAge() < 3 }) fmt.Printf("年轻动物数量: %d\n" , len (youngAnimals)) fmt.Println("\n9. 闭包:" ) timesThree := MakeMultiplier(3 ) fmt.Printf("3 * 4 = %d\n" , timesThree(4 )) fmt.Println("\n10. Goroutine 和 Channel:" ) dogs := []*Dog{dog, NewDog("小黑" , 2 , "柯基" )} BarkConcurrently(dogs, 2 ) fmt.Println("\n11. Channel 接收数据:" ) animalCh := AnimalChannel() for a := range animalCh { fmt.Printf("从 channel 收到: %s\n" , a.GetName()) } fmt.Println("\n12. Context (超时控制):" ) ctx, cancel := context.WithTimeout(context.Background(), 1 *time.Second) defer cancel() if err := ProcessWithContext(ctx, "任务1" ); err != nil { fmt.Printf("错误: %v\n" , err) } fmt.Println("\n13. Panic 和 Recover:" ) SafeOperation() fmt.Println("程序继续运行" ) fmt.Println("\n14. Slice 操作:" ) numbers := []int {1 , 2 , 3 , 4 , 5 } fmt.Printf("原始: %v\n" , numbers) fmt.Printf("切片 [1:3]: %v\n" , numbers[1 :3 ]) numbers = append (numbers, 6 , 7 ) fmt.Printf("追加后: %v\n" , numbers) fmt.Println("\n15. Map 操作:" ) animalMap := make (map [string ]int ) animalMap["旺财" ] = dog.GetAge() animalMap["小咪" ] = cat.GetAge() for name, age := range animalMap { fmt.Printf("%s: %d岁\n" , name, age) } if age, exists := animalMap["旺财" ]; exists { fmt.Printf("旺财存在,年龄: %d\n" , age) } fmt.Println("\n16. 匿名函数:" ) func (msg string ) fmt.Println(msg) }("这是一个匿名函数" ) fmt.Println("\n17. 变参函数:" ) fmt.Printf("总和: %d\n" , sum(1 , 2 , 3 , 4 , 5 )) fmt.Println("\n=== 演示完成 ===" ) fmt.Printf("总共创建了 %d 只动物\n" , animalCount) } func sum (numbers ...int ) int { total := 0 for _, n := range numbers { total += n } return total }
这个示例代码包含了以下所有 Go 核心概念:
结构体 (struct) :BaseAnimal、Dog、Cat 等结构体定义接口 (interface) :Movable、Soundable、Animal 接口接口组合 :Animal 接口组合了 Soundable 接口方法 :值接收者和指针接收者方法结构体嵌入(组合) :Dog 和 Cat 嵌入 BaseAnimal构造函数 :NewDog、NewCat 等工厂函数封装 :小写字段名表示私有,大写表示公开多态 :通过接口实现多态类型断言 :a.(*Dog) 类型断言类型选择 (type switch) :switch v := a.(type)泛型 (Go 1.18+) :AnimalShelter[T Animal]错误处理 :error 接口和自定义错误类型Defer :延迟执行函数Panic 和 Recover :异常处理机制Goroutine :并发执行Channel :goroutine 间通信Context :上下文和超时控制互斥锁 (Mutex) :sync.Mutex 和 sync.RWMutex闭包 :函数返回函数高阶函数 :函数作为参数传递匿名函数 :内联函数定义变参函数 :…int 可变参数Slice :动态数组操作Map :键值对集合Range :遍历集合