- 1. 計算機の基本構造
- 2. 計算機の性能評価
- 3. 命令セットアーキテクチャ(ISA)
- 4. プログラムの翻訳
- 5. データパス(Datapath)
- 6. パイプライン(Pipeline)
- 7. メモリテクノロジ(Memory Hierarchy)
- 8. まとめ
- 9. 参考文献
CS专业课学习笔记
計算機の基本構造
- 入力装置:外部からコンピュータにデータを読み込ませる装置
- 記憶装置:データやプログラムを記憶しておく装置
- 演算装置:四則演算や論理演算を行う装置
- 制御装置:記憶装置から取り出した命令を読解し実行を支持する装置
- 出力装置:処理されたデータをコンピュータの外部に出す装置
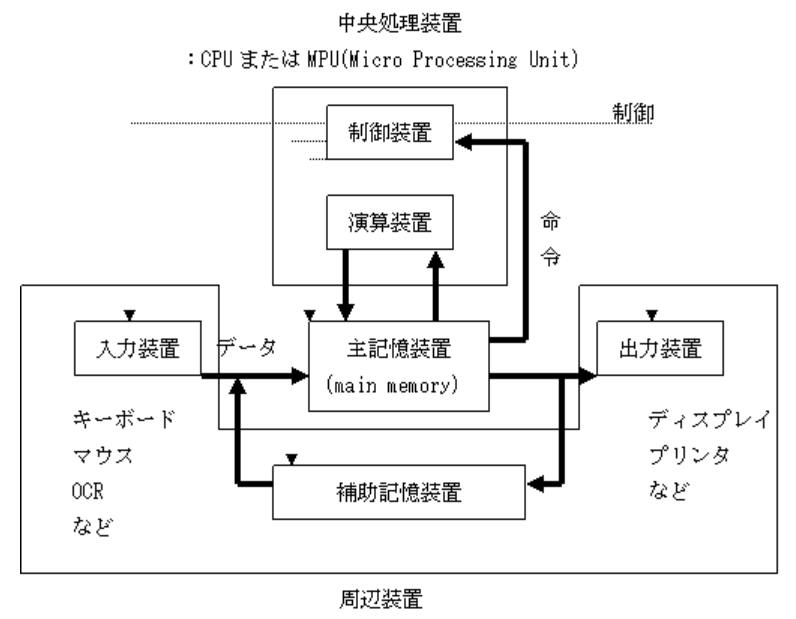
中央処理装置(Central Processing Unit, CPU): 演算装置 + 制御装置
CPUの構成
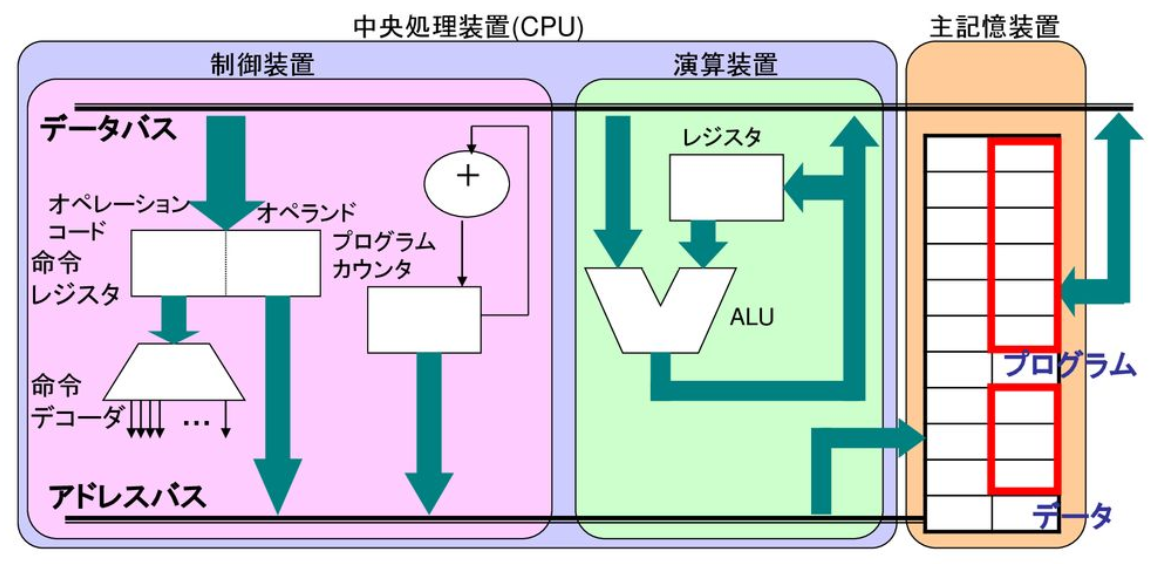
演算装置
- 算術論理演算装置(Arithmetic Logic Unit, ALU): 算術演算や論理演算を行う演算回路
- レジスタ(Register): 演算などに必要なデータを一時格納する
- 汎用レジスタ(General Register, GR): 高速に動作するCPU内の記憶装置、特定の目的を持たず、様々な役割を果たすレジスタ
- フラグレジスタ(Flag Register, FR): ALUの処理結果に基づいた動作を行うレジスタ
フラグレジスタの例:
- オーバフローフラグ(OF): 演算結果がある範囲を超えると1、範囲内だと0
- サインフラグ(SF): 演算結果が負の時1、それ以外の時0
- ゼロフラグ(ZF): 演算結果がゼロの時1、それ以外の時0
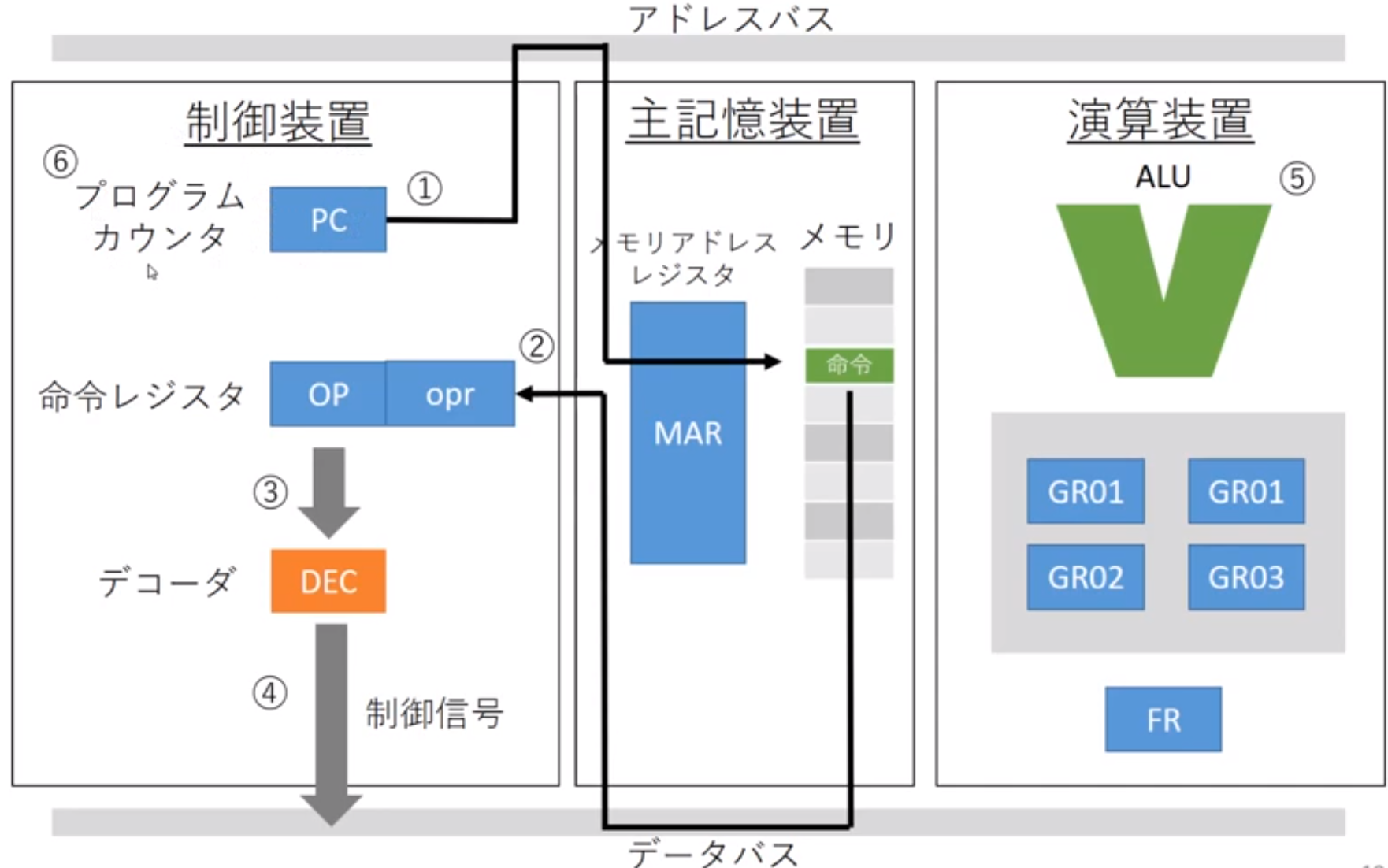
制御装置
- プログラムカウンタ(Program Counter, PC): 命令が格納されているアドレスを示す
- 命令レジスタ(Instruction Register, IR): 読み出された命令を一時格納する
- デコーダ(Decoder, DEC): 命令を解読し、制御信号やアドレスを発生する
命令実行の流れ: メモリに格納されているめいれいを1つ取り出して解読したあと実行する、という動作を繰り返して処理を進める
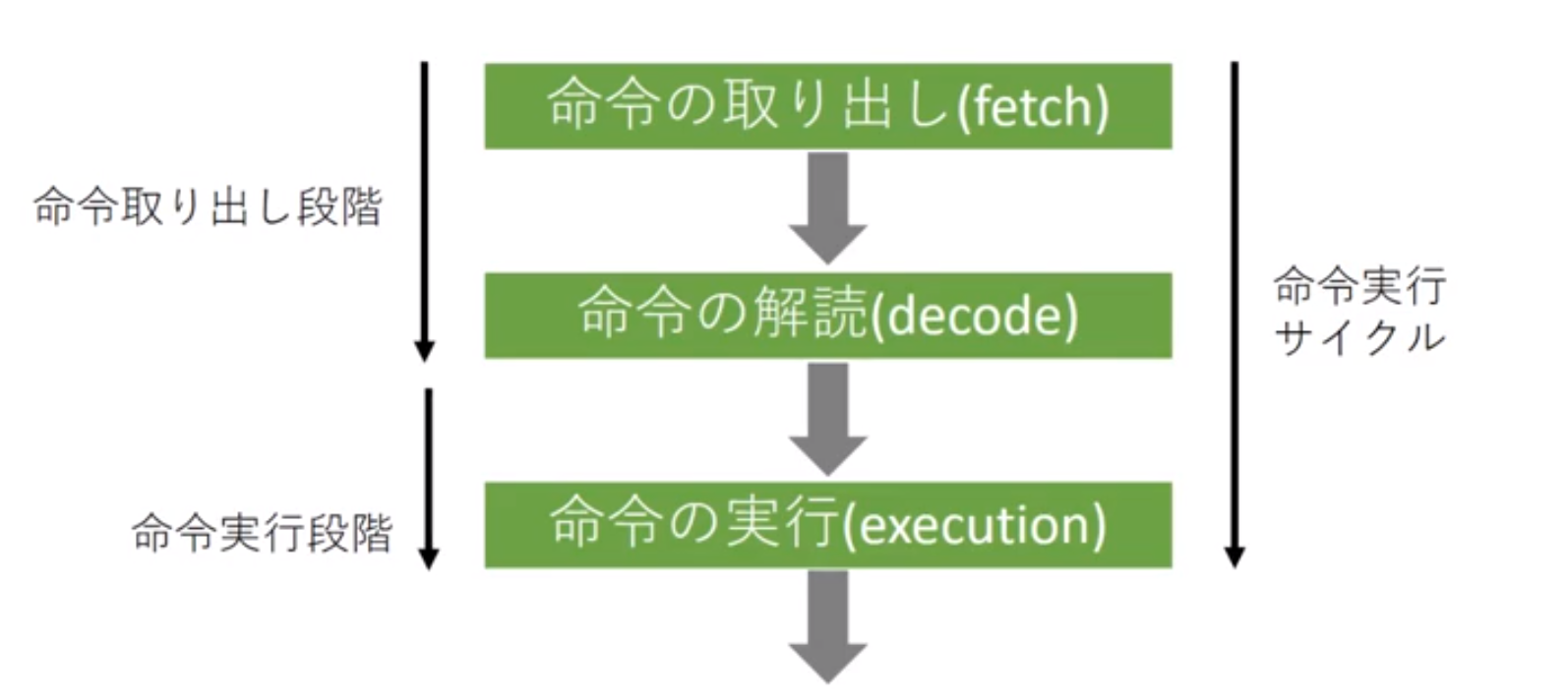
程序计数器:程序计数器是用于存放下一条指令所在单元的地址的地方
当执行一条指令时,首先需要根据PC中存放的指令地址,将指令由内存取到指令寄存器中,此过程称为“取指令”。与此同时,PC中的地址或自动加1或由转移指针给出下一条指令的地址。此后经过分析指令,执行指令。完成第一条指令的执行,而后根据PC取出第二条指令的地址,如此循环,执行每一条指令。
基本動作
プログラム内蔵方式
プログラム内蔵方式はプログラムをメモリに格納するのでプログラムの入力 / 変更が容易
- 単一メモリ方式
- プログラムとデータは同じメモリに数値として格納
- メモリにはアドレスが割り振られている
- 逐次処理方式
- 命令は原則実行順にメモリに格納
- 順序取り出しながら処理
プログラム内蔵方式のボトルネック(bottleneck): 同じメモリにプログラムとデータが共存しているため、メモリへのアクセス速度が遅い場合、全体のパフォーマンスに影響が出る
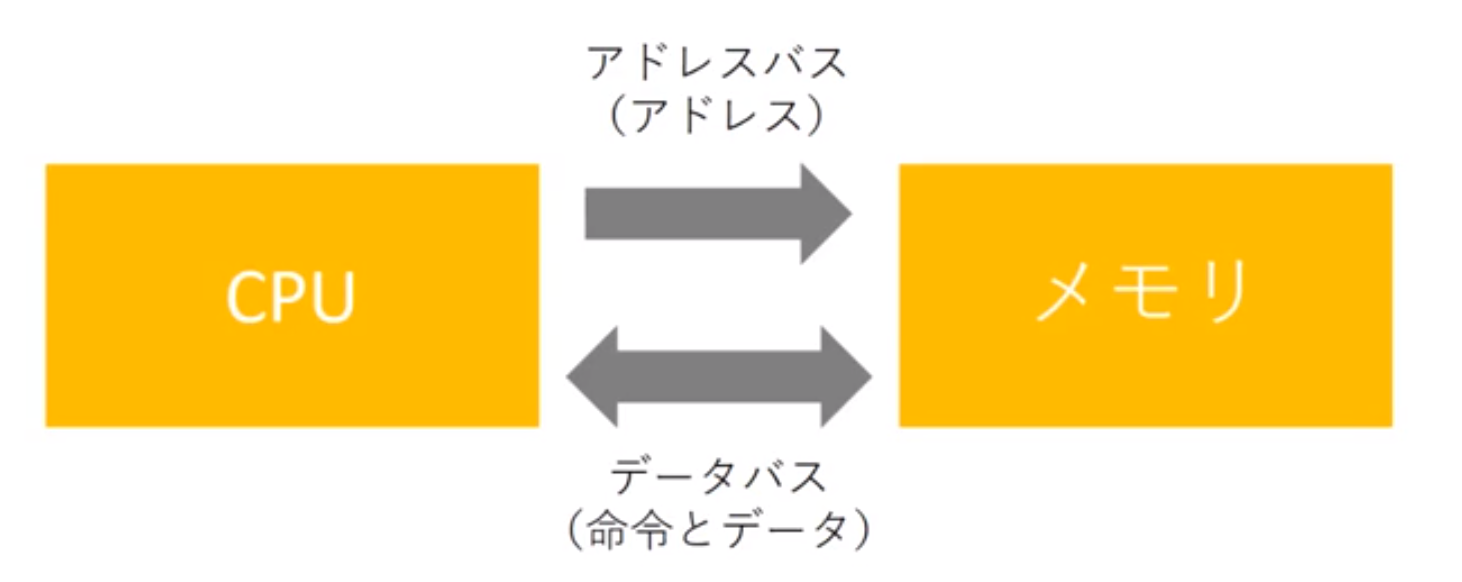
まとめ
- ライプニッツやパスカルによって作られた機械要素によって計算を行う計算機を機械式計算機という
- 1946年にモークリーとエーカットによって弾道計算用として実用化された電子計算機をENIACという.プログラムは内蔵だが書き換えはできなかった
- System/360はアーキテクチャを抽象化した製品群を形成した初の商用コンピュータである
- 1981年にIBMが発表したIBM Personal ComputerはIBM PC互換機の元であり,回答オープンアーキテクチャを採用したことが特徴である.ソフト・ハード両面での膨大な市場形成に寄与した
- 現在の計算機はすべてプログラム内蔵方式(またはノイマン型)の計算機である
- ALUはCPUの構成要素の一つで,算術演算や論理演算を行う装置
- 汎用レジスタはCPUの構成要素の一つで,特定の目的を持たず様々な役割を果たすレジスタ
- プログラムカウンタはCPUの構成要素の一つで,次に実行するプログラムが格納されているメモリのアドレスを記憶しているレジスタ
- デコーダはCPUの構成要素の一つで,命令を複合して実行に必要な制御信号を出力する装置
計算機の性能評価
計算機性能の定義
速度を基準に考える
- 応答時間(response time): 1つのプログラムを実行し終える時間
- 実行を開始してから終了までの時間「実行時間(execution time)」ともいう
- スループット(throughput): 全てのプログラムを実行し終える時間
- 単位時間当たりに終了した作業の量「バンド幅(bandwidth)」ともいう
相対性能
計算機Aは計算機Bよりもn倍速い
実行時間による性能測定
システム性能
- ディスク/メモリアクセス、入出力動作、OSのオーバーヘッド全てを含む応答時間(経過時間)
- CPU(実行)時間 (CPU (execution)time)
- プロセッサが実際に処理に費やした時間
- 他のプログラムを実行するための待ち時間は含まない
CPU時間はさらに2種類に分けられる
- ユーザーCPU時間(user CPU time) CPU性能
- プログラム中で費やされた時間
- システムCPU時間(system CPU time)
- プログラムに代わってOSが処理に費やした時間
CPU性能
クロック・サイクル時間
- 1クロック周期の占める時間
- ハードウェア内で事象を起こすタイミングの最小単位
CPU性能を向上させるためには
- プログラム実行に必要なクロック・サイクル数を減らす
- プロセッサのクロック周波数を上げる
一般来讲,计算机CPU主频速度越高,其计算速度越高。但是,主频并非是决定计算机速度的唯一标准,它与CPU的实际运算能力并没有直接关系。在一定的情况下,会出现主频较高的CPU的实际运算能力较低的情况。
一般来说时钟时间越长,周期数越多,意味着软件运行中这个硬件需要花费的时间就越长,我们就认为这个硬件的性能较低。
CPI一定程度上更加准确的反映了计算机的运算速度。
命令に基づく性能
CPI(clock cycle per instruction): 各命令を実行するのに必要なクロック・サイクル数の平均
一个程序中包含多个指令,不同指令可拥有不同时间周期数,多个指令的时间周期数的平均值就是CPI(Clock Cycles per instruction)
CPI是CPU执行每一条指令所需的时钟周期数
古典的なCPU性能方程式
| プログラム性能を決める要素 | CPU性能を決める要因 |
|---|---|
| アルゴリズム | 命令数、場合によってCPI(アルゴリズムによって低速な命令、高速な命令の使用傾向に差がある) |
| プログラミング言語 | 命令数、CPI(Javaなど抽象化をサポートする言語では間接呼び出しが必要でありCPIが増加する) |
| コンパイラ | 命令数、CPI |
| 命令セット・アーキテクチャ | 命令数、クロック周波数、CPI |
CPUのエネルギーと電力
現代の集積回路の支配的なテクノロジーはCMOS論理回路
- 消費電力が極めて少ない
- 論理値が変化するときだけ電流を消費する
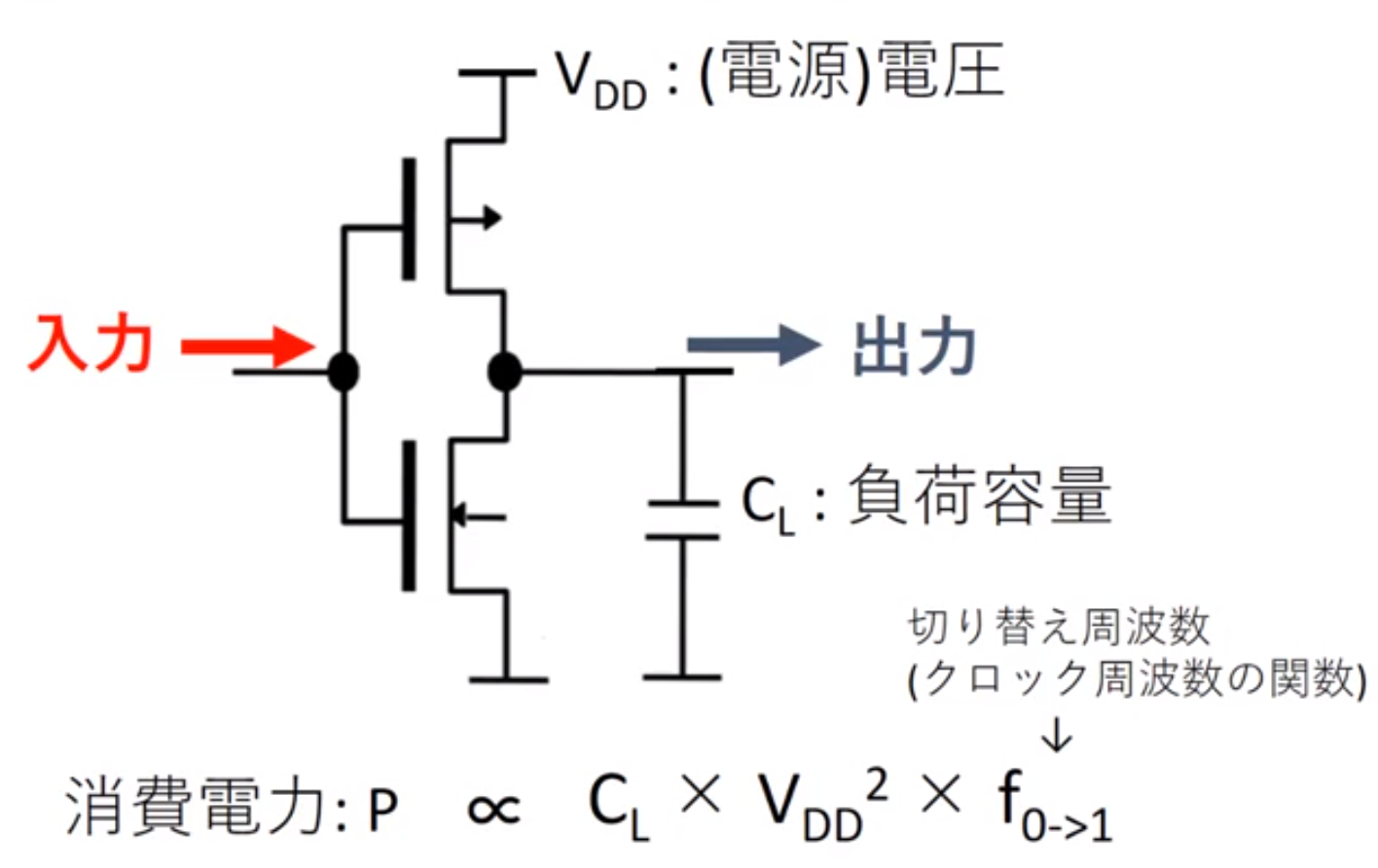
ムーアの法則
集積回路上のトランジスタ数は「18か月(=1.5年)ごとに倍になる」
- n年後の倍率pは
アムダールの法則
処理効率はそれを構成する個々の要素の平均効率で決まるのではなく、一部の非効率部分によって律速される
あるコンピュータ上で実行にTかかるプログラムがある。プログラムは効率化可能部分TPと効率化不可能部分TSからなるとする
TPの部分について、n倍の理想的な効率化ができるとするとその時の実行時間T(n)は
nを無限大にすると
TPの効率をいくら増大させても、TS以上に性能は向上しない
課題2.1
あるプログラムPをあるプロセッサM上で実行すると90億個の命令が実行され,この場合のCPIが0.8であることがわかっている.また,クロック周波数は3.0GHzとする.Pの実行を開始してから終了するまでの実行時間を求めよ.ただし,ここでの実行時間とは,OSがPに割り当てる正味の実行時間,いわゆるユーザCPU時間とする.
- 命令数:
- CPI = 0.8
- クロック周波数:
課題2.2
同じ命令セットを別々に実装したプロセッサX1とX2がある.X1のクロック周波数は4.0GHzであり,X2のクロック周波数は2.0GHzである.表はこの命令セットを3つの命令タイプ(A,B,C)に分類し,X1とX2における各命令タイプごとに求めた平均CPIを示している.この表にはあるプログラムPXに関して3種類のコンパイラ(C1,C2,C3)によって生成される命令の実行回数の割合(命令出現頻度)も示されている.PXに関して,命令の総実行回数は3つのコンパイラとも同じであるが,命令タイプごとの命令実行回数割合は表に示されているとおりであるとする.この条件の下でPXを実行するとき、以下の問いに答えよ。明示してある情報以外の条件は,プロセッサ間およびコンパイラ間で同一とする.
| 命令タイプ | X1上でのCPI | X2上でのCPI | C1での割合 | C2での割合 | C3での割合 |
|---|---|---|---|---|---|
| A | 1 | 0.5 | 50% | 65% | 60% |
| B | 2 | 3 | 40% | 20% | 10% |
| C | 4 | 4 | 10% | 15% | 30% |
(1) X1とX2の両方でC1を使用した場合、X1とX2のどちらがどのくらい速いかを示せ
X1でC1を使う場合、平均CPUクロックサイクル時間は
CPU执行时间 / 时钟时间 = 命令数 * CPI = 时钟周期数
この時のCPU実行時間は,PXの命令総実行回数をNとすると
CPU执行时间 = 程序执行命令数 * CPI / 时钟周期数
同様に、X2でC1を使った場合,0.775N(ns)となる.よって0.775N / 0.425N = 1.82倍
(2) X1で最も高速にPXを実行するには、どのコンパイラを使用するべきか
X1で各コンパイラのCPU実行時間は、
| C1 | C2 | C3 |
|---|---|---|
| 0.425N | 0.4125N | 0.5N |
よって、C2
(3) X2で最も高速にPXを実行するには、どのコンパイラを使用するべきか
X2で各コンパイラのCPU実行時間は、
| C1 | C2 | C3 |
|---|---|---|
| 0.775N | 0.5375N | 0.45N |
よって、C3
(4) PXを最も高速に実行するプロセッサとコンパイラの組み合わせを共に示せ
上の表より、X1、C2が最も速い
課題2.3
Mooreの法則に基づくと、2020年における1チップ上のトランジスタ数は2010年の何倍になるか?(小数点第2位を四捨五入して答えよ)
よって101.6倍
課題2.4
あるアプリケーションを実行しているシングルコアシステムAを同じアーキテクチャの2つのコアを持つシステム(デュアルコアシステム)Bに変更し、電力が節約できないかを検討する.ここでは、電圧は周波数とともに直線的に下げることが可能であるとする
(1) 実行予定のアプリケーションが80%並列化可能であるとする.同じ性能(応答時間)を得るために,どの程度周波数を下げることができるか?
サイクル数をCI,サイクルクロック数をCPIとする.
システムAとBでCIとCPIは変化しないことから、
(2) デュアルコアシステムBを(1)の周波数で実行するとき、シングルコアシステムAに比べて動的電力をどの程度要求するか?
(3) 電圧が元の電圧の75%以下には設定することができないとする.この電圧のことを「下限電圧」と呼び,この電圧より低くするとシステムが動作しなくなる.下限電圧に達してしまう並列化の割合(%)はいくらか?
並列度をxとする. より
ここで、
より、
(4) 下限電圧を考慮した場合,デュアルコアシステムBはシングルコアシステムAに比べてどの程度,動的電力を必要とするか?
CPU性能相关题目-1

- ピーク性能[命令数 / 秒] = クロック周波数[クロック数 / 秒] / CPI[クロック数 / 命令数]
CPU性能相关题目-2
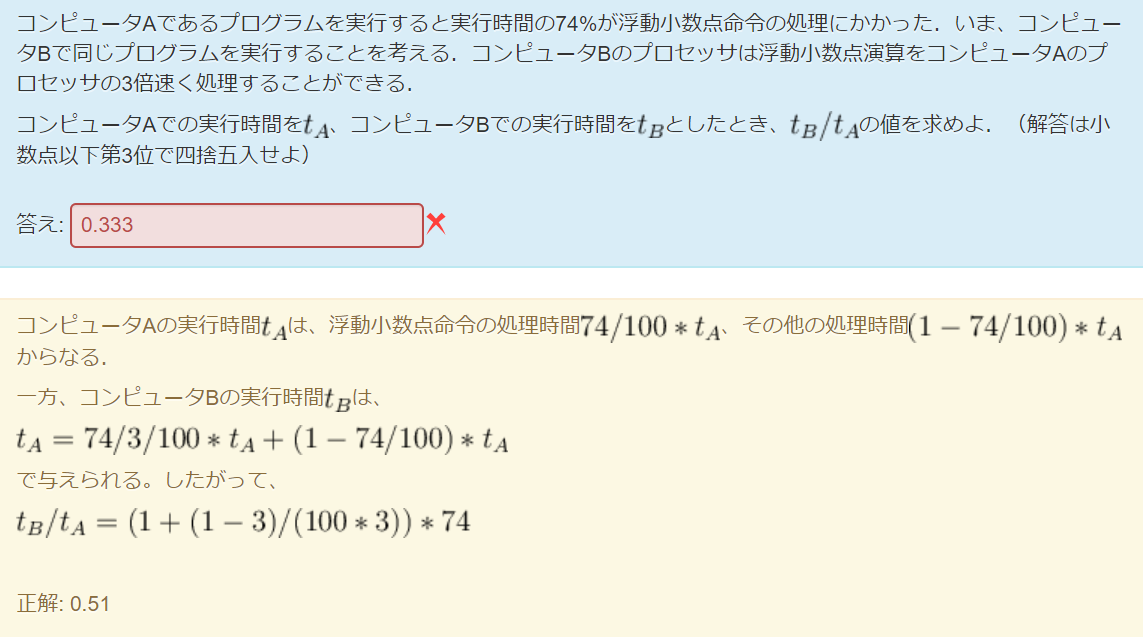
总结-CPU性能公式
基础知识:
- CPU时间:一个程序在CPU上运行的时间(不包括I/O时间)
- 主频,时钟频率:CPU内部主时钟的频率,表示1秒可以完成多少个周期
- 例如:主频为4.1GHz,表示每秒可以完成 个时钟周期
- 时钟周期:时钟周期也成为振荡周期,定义为时钟频率的倒数。时钟周期是计算机中最基本,最小的时间单位。在一个时钟周期内,CPU仅完成一个最基本的动作
- 例如:时钟周期 = 1 / 频率,
- CPU的时钟周期越短,CPU性能越好
- 指令周期:取出并执行一条指令的时间
- 指令周期数CPI:平均每条指令耗费的时钟周期数
CPI = 执行程序所需的时钟周期数 / 所执行的指令条数
由上式变换得
1 | 执行程序所需要的时钟周期数 = CPI * 所执行的指令条数 |
我们约定IC:所执行得指令条数,因此
CPU时间 = CPI * IC * 时钟周期时间
CPU时间 = (CPI * IC) / 时钟频率
命令セットアーキテクチャ(ISA)
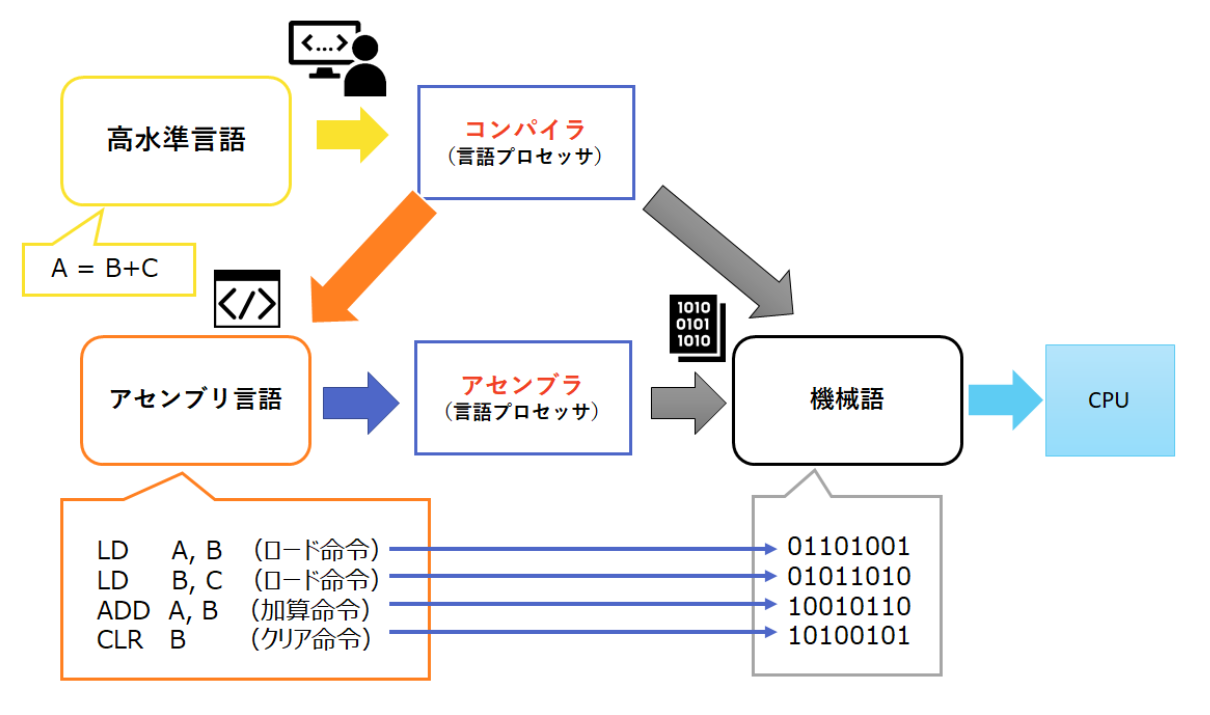
命令セットアーキテクチャ(Instruction Set Architecture, ISA)とは、コンピュータの備えるべき機能とそれを動作させるための命令セットを定めるもの
指令集体系结构(ISA)定义了一台计算机可以执行的所有指令的集合,每条指令规定了计算机执行什么操作,所处理的操作数存放的地址空间以及操作数类型。
- アーキテクチャの実装(ハードウェア)によらない
抽象化に関するその他のアイデア:
- OS
- 低水準システム機能(I/O, メモリ割当)の抽象化 ユーザは機能の詳細を気にする必要がない
- ABI(application binary interface)
- 命令セットだけでなくOSまで含んだ定義 互換ABIのシステムでは同じバイナリファイルが実行可能
应用程序二进制接口(ABI)描述了应用程序和操作系统之间,一个应用和它的库之间,或者应用的组成部分之间的低接口。
代表的なISA
- CISC(Complex Instruction Set Architecture)
- 複雑な一連の処理を少ない命令数で行うことでパフォーマンス向上を目指した命令セットアーキテクチャ
- eg. Intel x86, System/360
- RISC(Reduced Instruction Set Architecture)
- 各命令を単純にして高速に実行することでパフォーマンス向上を目指した命令セットアーキテクチャ
- eg. MIPS, ARM, PowerPC, SPARC
- VLIW(Very Long Instruction Word)
- 複雑な機能が詰め込まれたかなり長い語によって一単位の命令が構成されている命令セットアーキテクチャ
- eg. Itanium, Crusoe
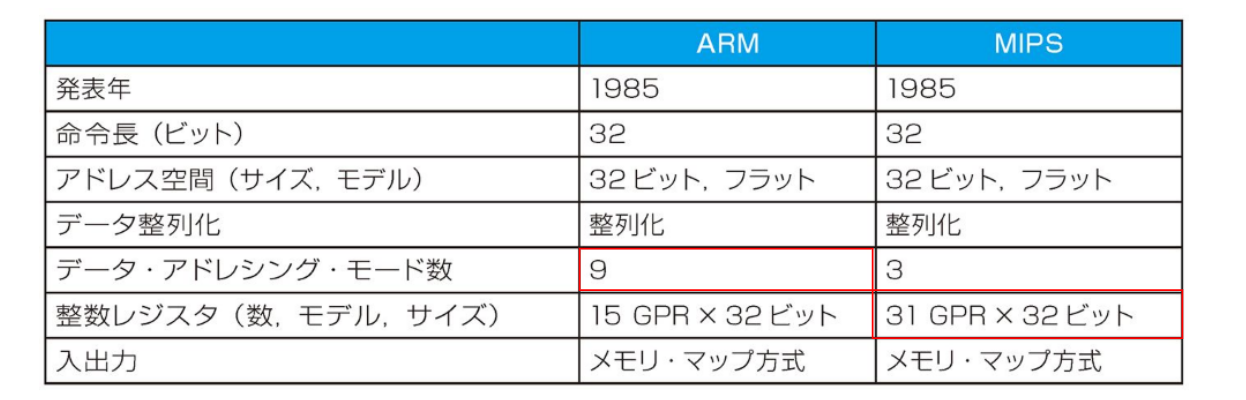
MIPSアーキテクチャ
MIPS Computer System(現MIPS Technologies)が1980年代初頭から設計・開発が行われているRICSマイクロプロセッサ
MIPS I
- レジスタ長は32bit(= 4byte)、32本
- CPU内の記憶装置、容量は少ないが高速
- 命令は32bit(= 4byte)の固定長
- 命令形式は3種類で各命令で行える演算は一つだけ
- メモリアクセスはロード(lw)/ストア(sw)命令のみ
- 3オペランド命令
- eg. add C, A, B
- オペランド = 命令
- 遅延分岐
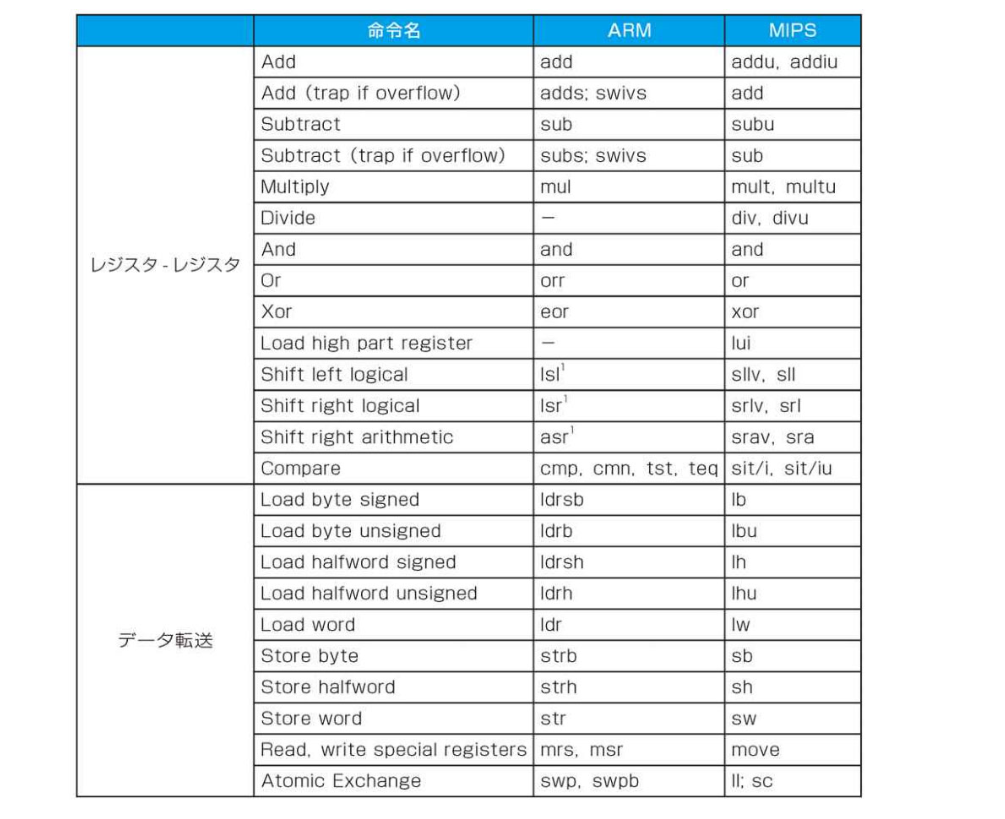
MIPSの代表的な命令セット
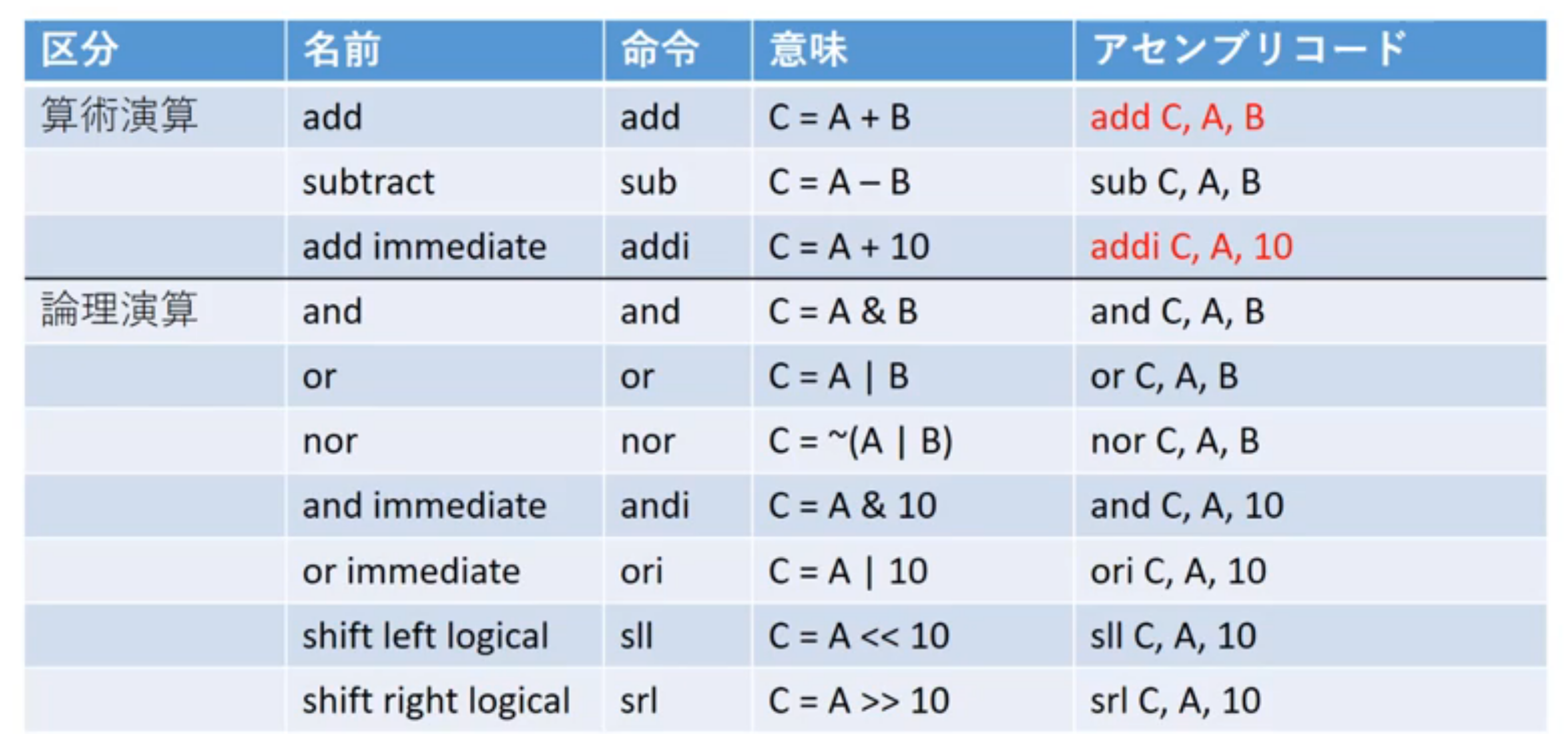
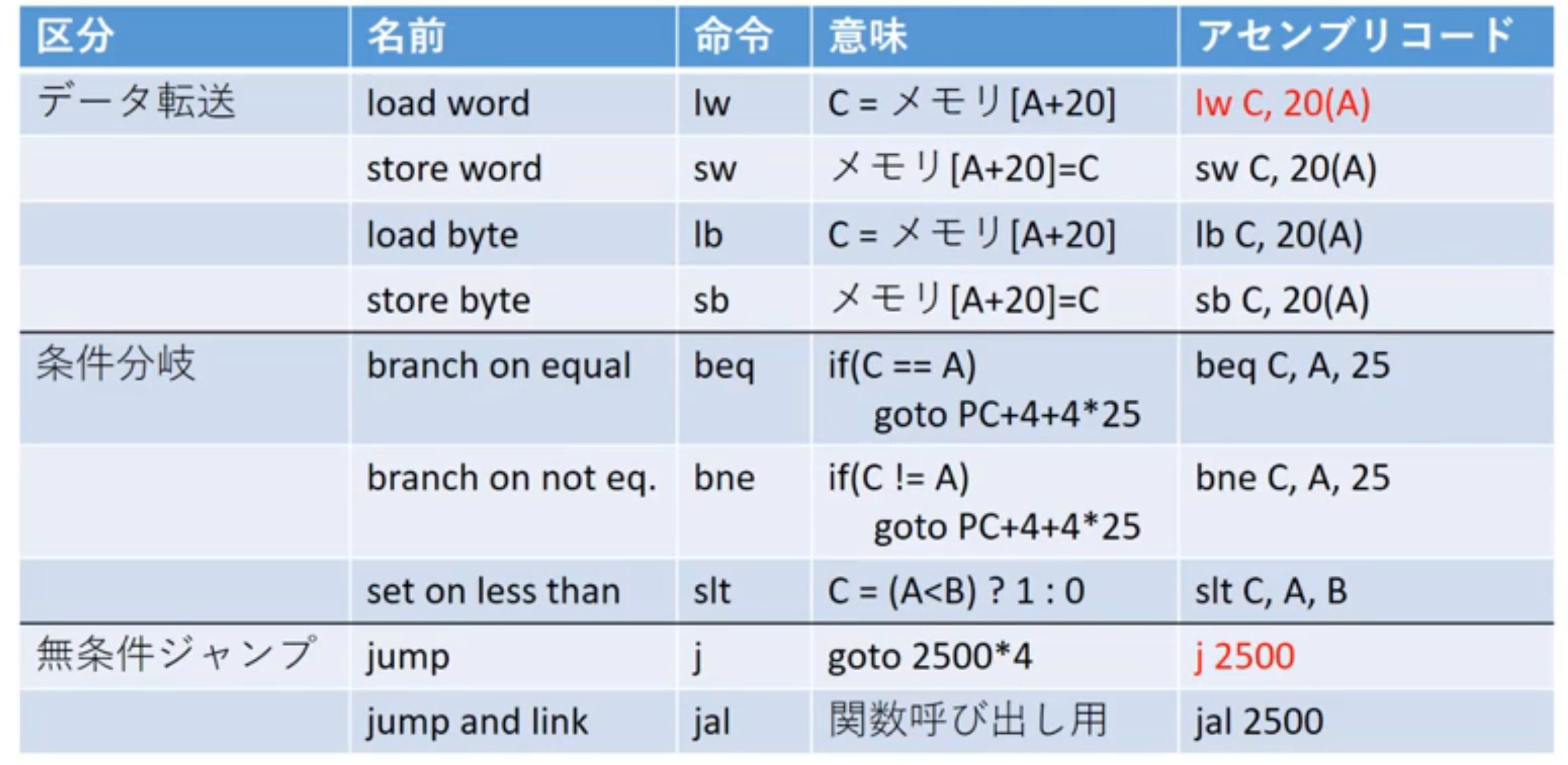
MIPSのオペランド
- $zero: 常にゼロ
- $s0 - $s7: 退避レジスタ(変数に相当)
- $t0 - $t9: 一時レジスタ(一時的なデータ保存用)
- $a0 - $a3: 引数レジスタ(パラメータを渡すために使用)
- $v0 - $v1: 戻り値レジスタ(結果の値を返すために使用)
- $ra: 戻りアドレス・レジスタ(制御を元に戻すために使用)
- $sp: スタック・ポインタ・レジスタ
- $gp: グローバル・ポインタ・レジスタ(静的データへのアクセスに使用)
- $fp: フレーム・ポインタ・レジスタ
- $at: 一時レジスタ(アセンブラ用)
定数
- データ転送命令にのみ出てくる
- アドレスはバイト単位で割り振られるバイトアドレス方式
- MIPSの1命令は4バイト固定長(4バイト = 1語(word))
- 順に並んだ語のアドレスは4バイト刻みでずれる
- プログラムカウンタ(PC)は4刻みで増える
メモリアドレス
按字节寻址:最通俗的理解就是一组地址线的每个不同状态对应一个字节的地址。比如说有24根地址线,按字节寻址,而且每根线有两个状态,那么24根地址线组成的地址信号就有个不同状态,每个状态对应一个字节的地址空间的话,24根地址线的可寻址空间,即16MB。
按字寻址:最通俗的理解就是一组地址线的每个不同状态对应一个字的地址。因为字节是计算机中最基本的计量单位且一个字由若干字节构成,所以计算机在寻址过程中会区分字里面的字节,即会给字里面的字节编址,这样就会占用部分地址线。比如说有24根地址线,按字寻址,字长16位,16位即两个字节,这样就会占用一根地址线用来字内寻址,这样就剩下23根地址线,所以寻址范围是,即8MW,这里W是字长的意思。
- バイトアドレス方式(Byte Addressing)
- 1バイト単位でアドレスを割り振られる
- MIPSの1命令は4バイト固定長(4バイト=1語(word))
- 整列化制約: 各命令のアドレスは4の倍数になる
- PCは4刻みで増える
- 配列のインデックスに4を掛けてバイトに直す必要がある
- 整列化制約: 各命令のアドレスは4の倍数になる
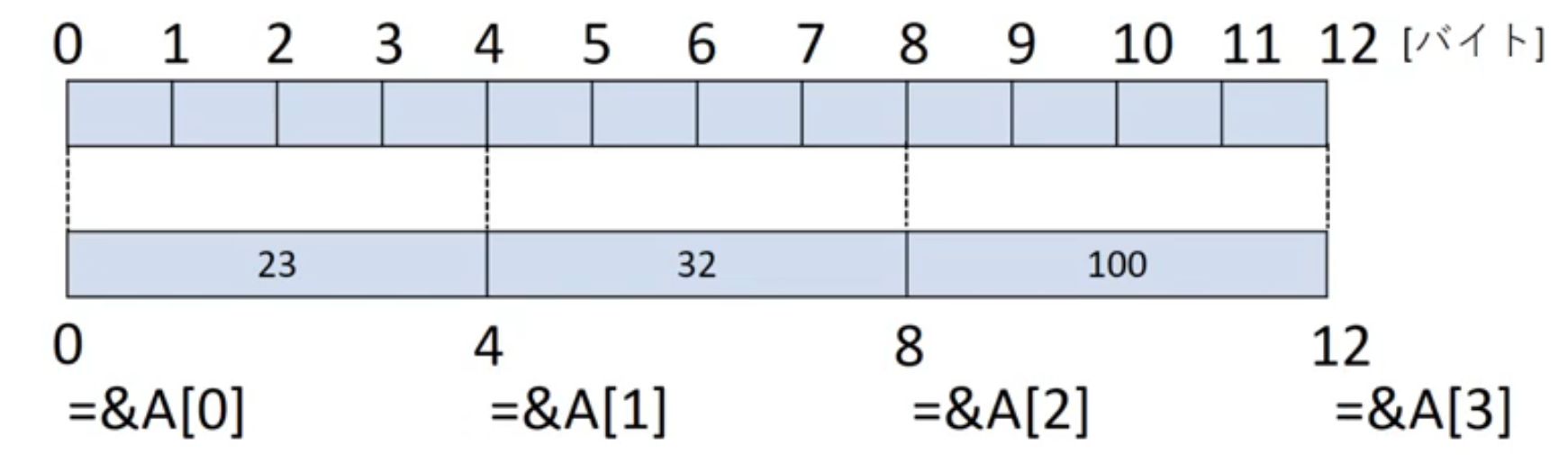
レジスタ使用した演算
例: 次のCステートメントに対応するMIPSアセンブリ・コードを示せ. 変数a, b, c, d, eの値はそれぞれレジスタ$s0, $s1, $s2, $s3, $s4に格納されているとする.
(1) a = b + c; // C code
1 | add $s0, &s1, $s2 |
(2) a = b + c + d + e; // C code
1 | add $s0, &s1, $s2 |
ロードとストア(load/store)
メモリ上のデータを演算命令のオペランドに指定することはできない
演算命令(add)はレジスタの内容を読んで演算結果をレジスタに書き込む メモリ上のデータはレジスタに予めロードする必要がある
例題1: 次のCステートメントに対応するMIPSアセンブリ・コードを示せ. 変数hは$s2, 配列Aの先頭アドレス(&A[0])は$s3に格納されているとする.
(1) A[12] = h + A[8]; // C code
- A[8]をレジスタにロードする
- A[8]のアドレスを求める
- A[8]のデータをレジスタにロードする
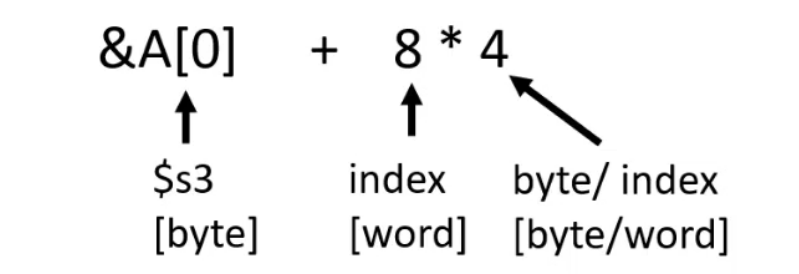
- h + A[8]を計算する
- 計算計算をA[12]にストアする
1 | lw $t0, 32($s3) // A[8]をレジスタにロードする |
例題2:

定数の加算
- 定数を用いて演算はプログラム中に頻出する
例: a = a + 4; // C code
- a, 4 $s1, AddrConstrant4($s2)
1 | lw $t0, AddrConstrant4($s2) // メモリからロード |
メモリから定数をロードするよりも遥かに効率がよい 基本命令形式に変型版を用意する
1 | addi $s1, $s1, 4 |
MIPSの命令形式
命令形式: 命令語のフィールド構成
- MIPS は命令語を32bit 幅で統一している
- MIPS の命令形式は,R形式,I形式,J形式の3種類がある
- どの命令形式かは,op フィールド(命令操作コード)で判別できる
| 指令 | 格式 | op | rs | rt | rd | shamt | fuct | address |
|---|---|---|---|---|---|---|---|---|
| add | R | 0 | register | register | register | 0 | 32 | n.a |
| sub | R | 0 | register | register | register | 0 | 34 | n.a |
| lw | I | 35 | register | register | n.a | n.a | n.a | address |
| sw | I | 43 | register | register | n.a | n.a | n.a | address |
R形式

- op: 命令操作コード
- rs: 第1のソースオペランドのレジスタ
- rt: 第2のソースオペランドのレジスタ
- rd: デスティネーション・オペランド (結果出力) のレジスタ
- shamt: シフト量
- funct: 機能コード. オペランドのバリエーション
I形式


J形式

比較命令

論理演算命令

シフト命令

- 左移1位即乘2
課題3.1
(1) 以下の空欄に当てはまる語句を埋めよ.
- コンピュータを動作させる(機械語の)命令の集まりを命令セットという.
- ハードウェアと最低水準のソフトウェアとの間のインターフェースのことを命令セットアーキテクチャという.
- 機械語の命令を記号で置き換えた言語をアセンブリ言語という.
- CPU内にあり容量は少ないが非常に高速に動作するメモリのことをレジスタという.
- MIPSのレジスタは32本あり,レジスタ長は32bitである.
- MIPSの命令長は32bitの固定長である.
- MIPSの命令フォーマットは3種類あり,Rフォーマット, Iフォーマット, Jフォーマットである.
- 各命令で演算の対象となる変数のことをオペランドという.
- MIPSのメモリアドレスはバイトアドレス方式である.
- MIPSのプログラムカウンタは4刻みで増える.
(2) 以下のC ステートメントに対応するMIPS アセンブリ・コードの空欄を埋めよ.変数f, g, h, i, j はレジスタ$s0, $s1, $s2, $s3, $s4 にそれぞれ割り当てられている.配列A, B の先頭アドレスはレジスタ$s6, $s7 にそれぞれ割り当てられている.一時変数としてレジスタ$t0, $t1 を使用することができる.$zeroは常にゼロとなるレジスタである.
- f = g + (h –10); // C言語
MIPSアセンブリ・コード
1 | addi $s0, $s2, -10 // f = h - 10 |
- B[8] = A[i – j]; // C言語
MIPSアセンブリ・コード
1 | sub $t0, $s3, $s4 // Calc i-j 计算偏移量 |
- f = -g - A[5]; // C言語
MIPSアセンブリ・コード
1 | lw $s0, 20($s6) // Load A[5] into f |
- B[6] = h + A[i - j]; // C言語
MIPSアセンブリ・コード
1 | sub $t0, $s3, $s4 // Calc i-j |
- 计算偏移量(i - j)
- 偏移地址(i - j)*4
- 计算地址(用首地址)
- load数值
- store数值
ループの処理
ループで使う命令:
- beq(branch if equal): beq register1, register2, L1
- レジスタ1とレジスタ2の値が等しい時、L1というラベルの付いたステートメントにプログラムの流れを分岐される
- bne(branch if not equal): bne register1, register2, L1
- レジスタ1とレジスタ2の値が等しくない時、L1というラベルの付いたステートメントにプログラムの流れを分岐される
- j(無条件分岐): j Exit
- プロセッサに必ず分岐を行わせる
- slt(set on less than):
- slt register3, register1, register2 # 符号付き
- sltu register3, register1, register2 # 符号なし
- レジスタ1 < レジスタ2の場合にレジスタ3に1をセットし、そうでない場合に0をセットする
分岐命令
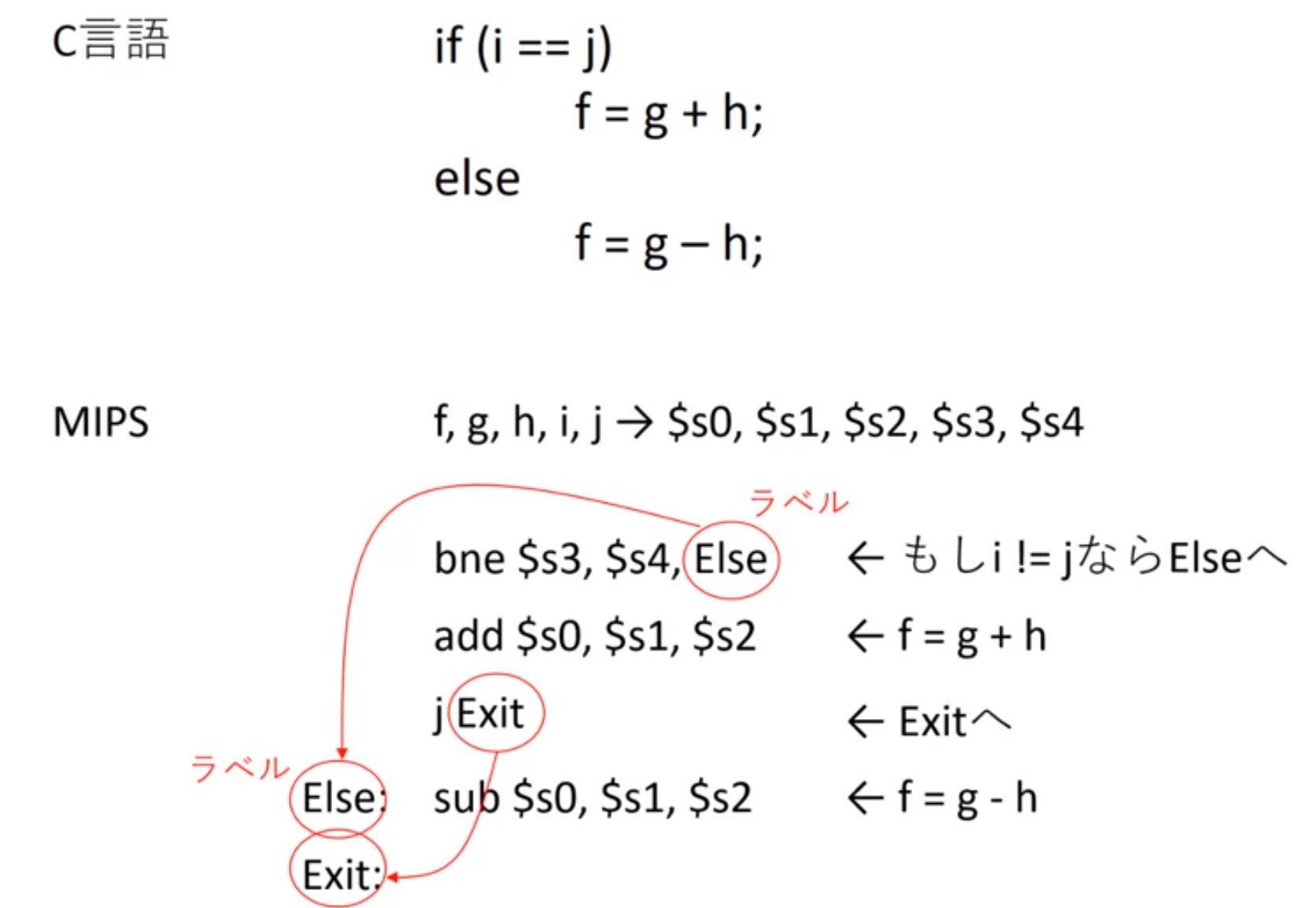
forループ

whileループ

手続き処理
MIPSでの手続き呼び出し
専用レジスタ
- $a0 - $a3: 引数レジスタ(パラメータを渡すために使用)
- $v0 - $v1: 値レジスタ(結果の値を返すために使用)
- $ra: 戻りアドレス・レジスタ(制御を元に戻すために使用)
手続き専用の命令
- j是最简单的跳转
- jr和jal与程序调用函数有关。程序调用函数,当函数调用结束后需要重新继续执行原来的程序,所以在调用函数之前,必须先存储函数返回起始点地址
- jal是跳转到某个地址同时把返回调用点的地址存储在$ra中
- jal[手続きのアドレス]
- jump-and-link命令
- 手続きのアドレスにジャンプすると同時に、次の命令のアドレスをレジスタ$raに退避する
- jr[レジスタ]
- jump-register命令
- レジスタ中に指定されているアドレスに無条件にジャンプする

栈是一种具有特殊访问方式的存储空间。特殊点在于,数据入栈出栈的次序是“先进后出”或者说“后进先出”(LIFO,Last In First Out)。拥有两种操作:入栈(PUSH)和出栈(POP)。
CPU 提供相关的指令来以栈的方式访问内存空间。说明了,我们可以将一段内存当做栈来使用。(其实我们编程在写递归的时候,总是很经常没有考虑递归基的情况就运行程序,导致内存溢出。我们通过前面所说内存被当做栈来使用,推导出:其实就是栈内存被使用了无限次,导致的内存溢出结果。)
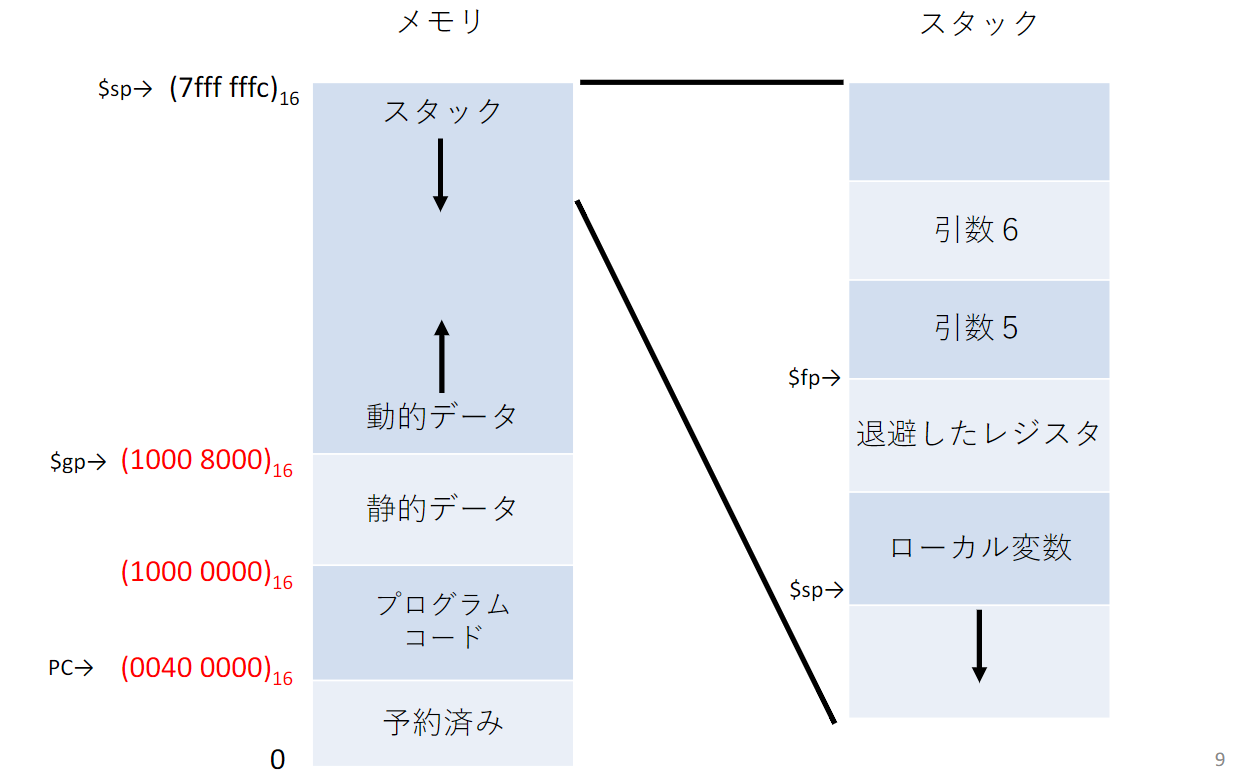
スタックを用いたレジスタのスピル・アウト
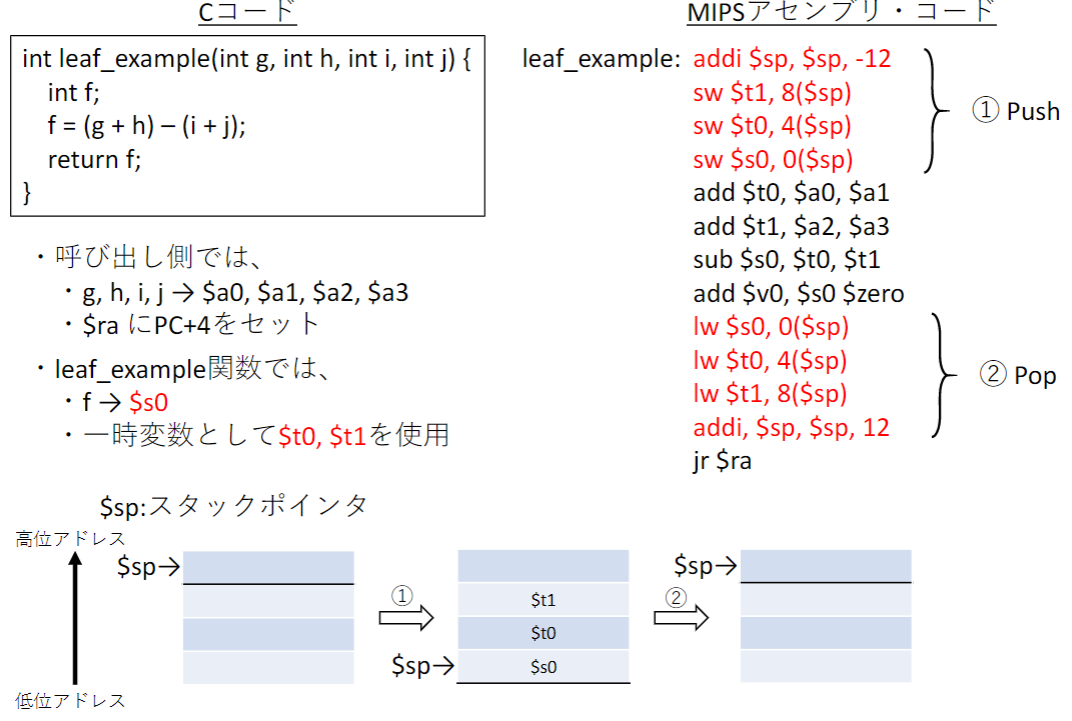
汇编里把一段内存空间定义为一个栈,栈总是先进后出,栈的最大空间为 64K。由于 “栈” 是由高到低使用的,所以新压入的数据的位置更低,ESP 中的指针将一直指向这个新位置,所以 ESP 中的地址数据是动态的。
赤字の三つのレジスタを一時的に退避させておかないと手続き呼び出し前後で状態が変わってしまうことになる
レジスタの内容をメモリに退避させることをスピル・アウトという
例: 再帰(recursion)
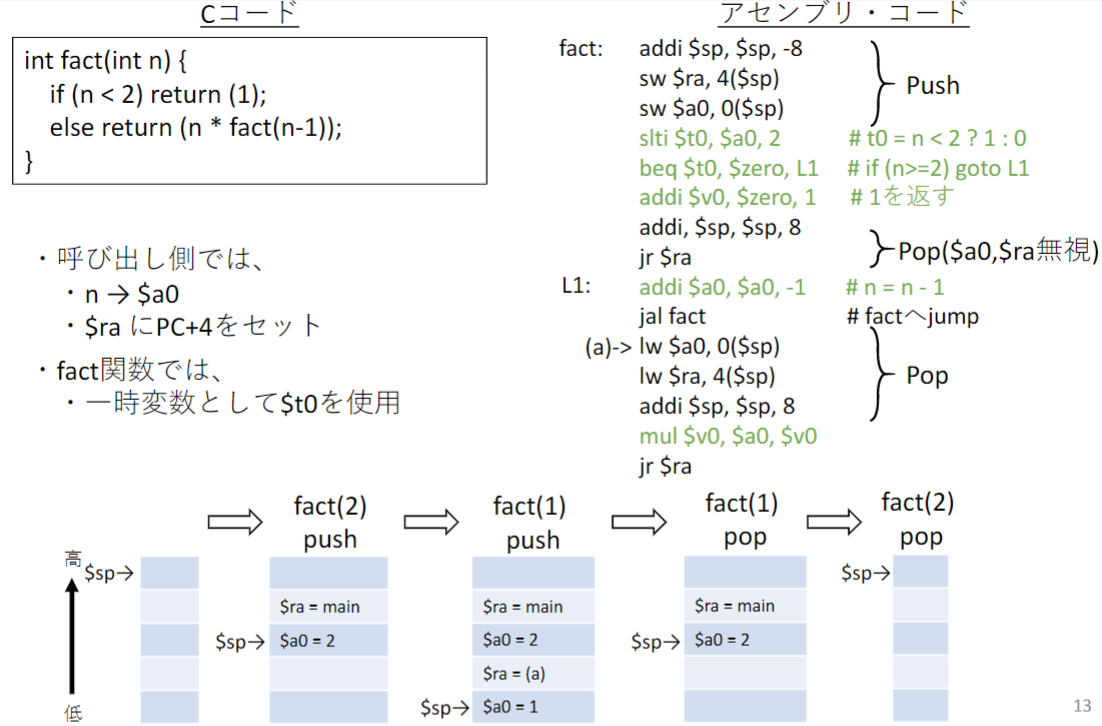
この例ではローカル変数がスタックに退避させる必要がない
在当今多数计算机体系架构中,函数的参数传递、局部变量的分配和释放都是通过操纵栈来实现的。栈还用来存储返回值信息、保存寄存器以供恢复调用前处理机状态。
每次调用一个函数,都要为该次调用的函数实例分配栈空间。为单个函数分配的那部分栈空间就叫做栈帧( Stack Frame )。调用栈( Call Stack )就是正在使用的栈空间,由多个嵌套调用函数所使用的栈帧组成。具体来说,Call Stack 就是指存放某个程序的正在运行的函数的信息的栈。Call Stack 由 Stack Frames 组成,每个 Stack Frame 对应于一个未完成运行的函数。
需要注意的是,在内存中,栈是从高地址向低地址延伸的,即栈底对应高地址,栈顶对应低地址。
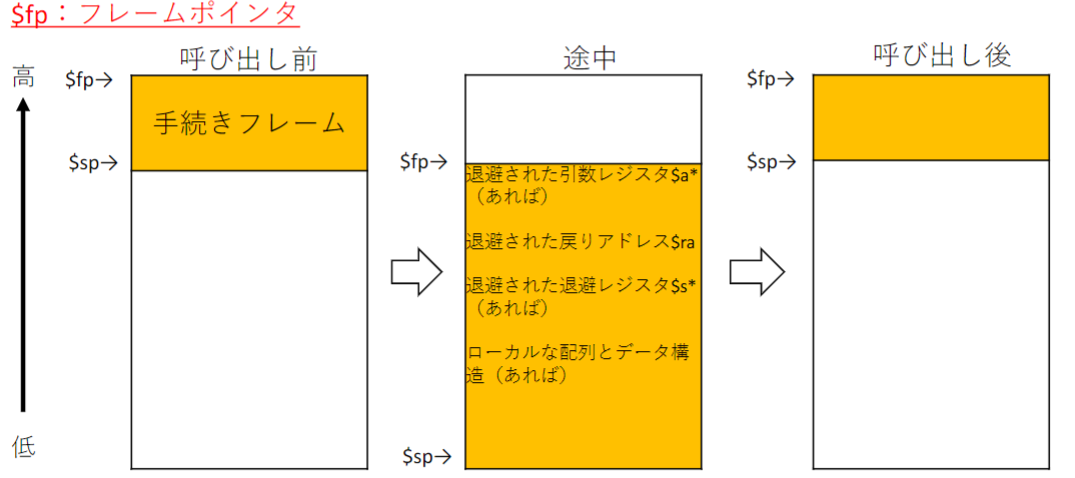
- 手続きフレーム(アクティベーション・レコード): スタックのうちで、手続きによって退避されたレジスタおよびローカル変数が収められている領域
- フレームポインタ: 手続きフレームの先頭の語を指す$spは手続き中変化するが$fpは変化しない
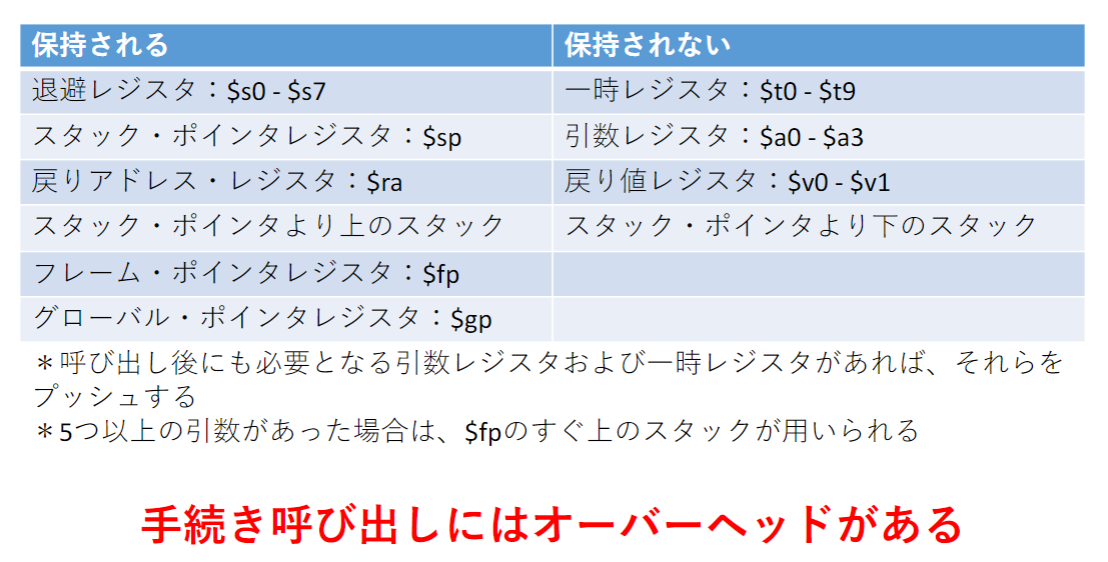
手続き呼び出し中に保持される/されないレジスタ:
アドレシング
アドレシング(Addressing): データの場所を指し示す方法
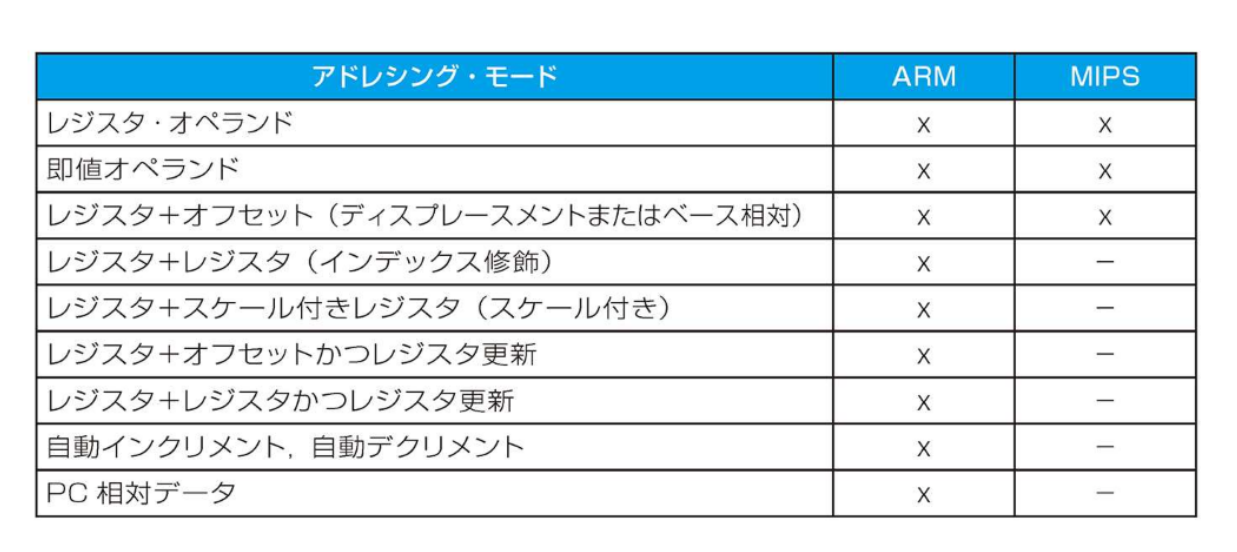
MIPSのアドレシング・モード
- 即値アドレシング: 命令中に指定した定数をオペランドとする
- レジスタ・アドレシング: オペランドにレジスタを取る
- ベース相対アドレシング(ディスプレースメント・アドレシング): 命令中に指定した定数とレジスタの和によって、オペランドが記憶されているメモリの位置を示す
- PC相対アドレシング: PCと命令中に指定した定数との和によってアドレスを示す
- 疑似直接アドレシング: 命令中の26ビットとPCの上位ビットを連結したものがジャンプ・アドレスとなる
即値アドレシング
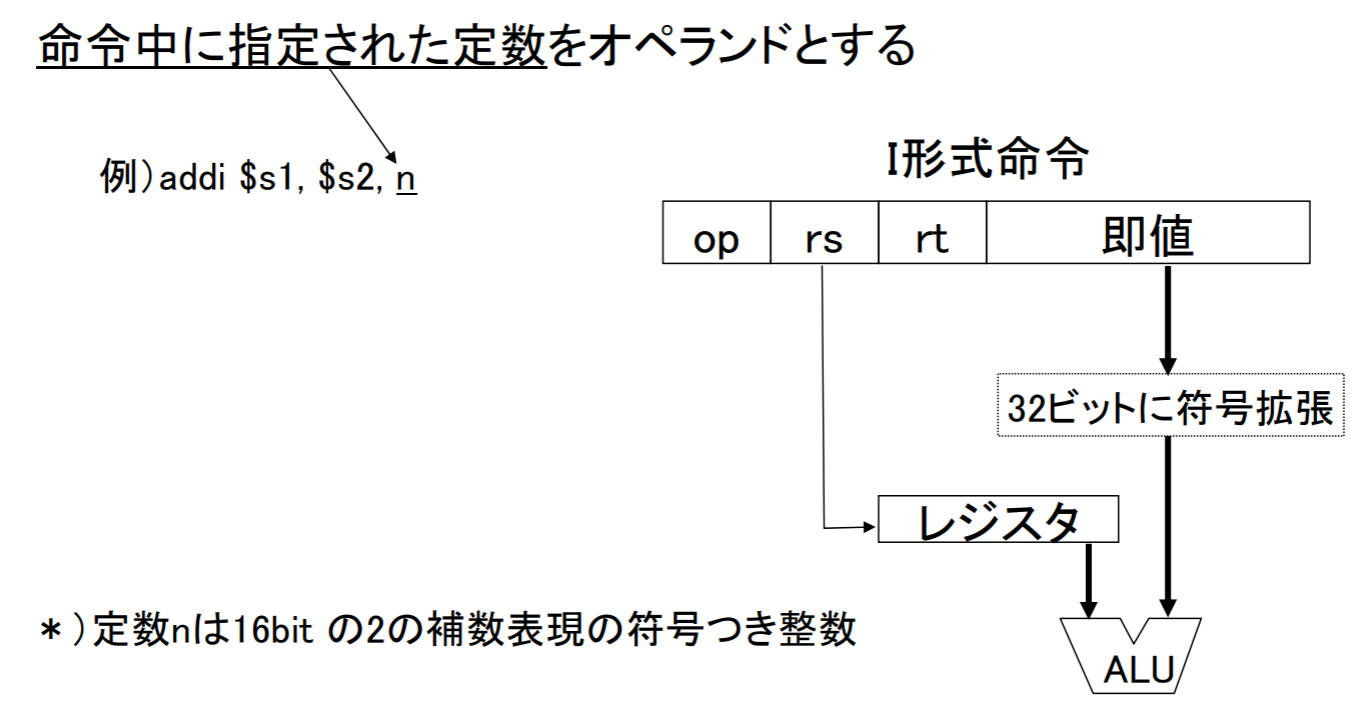
符号拡張(sign extension): レジスタ上位の空きビットに符号ビットを繰り返しコピーして埋める操作

- が16bitにおける符号ビットで、これは赤字の上位ビットにコピー
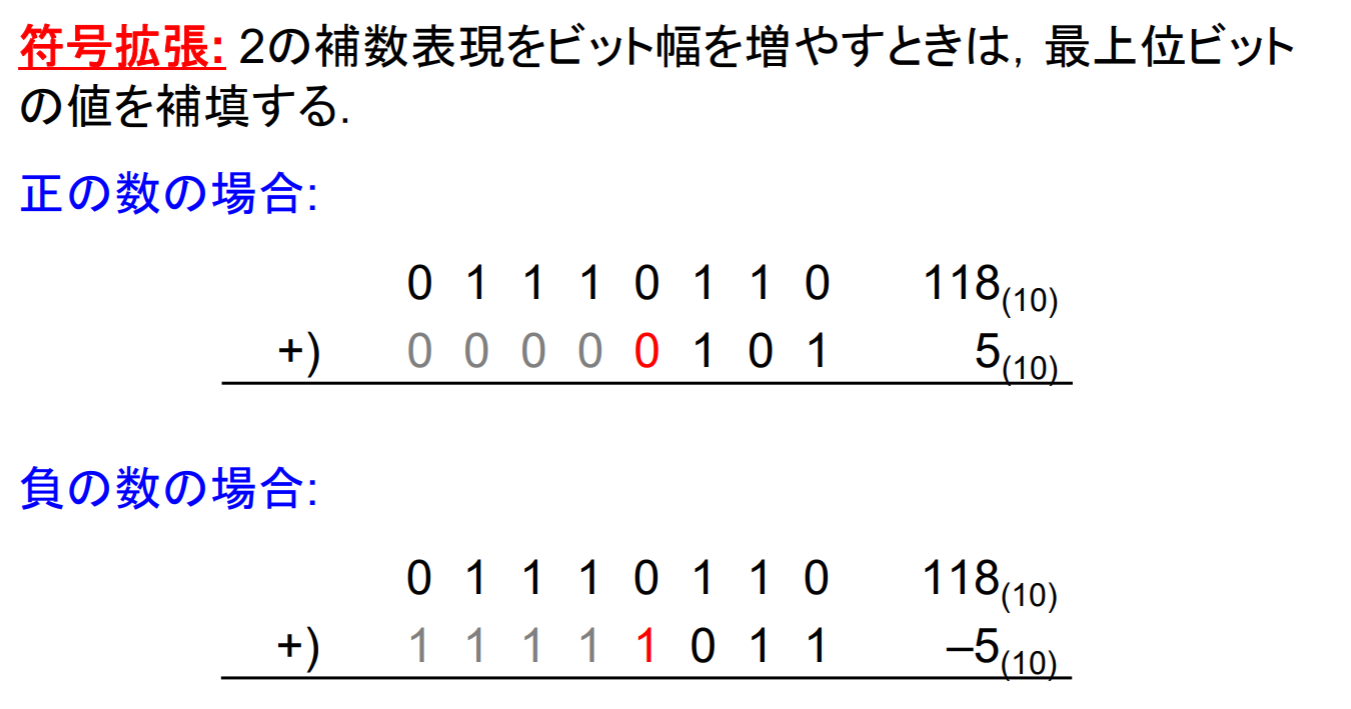
レジスタ・アドレシング
- rs, rt, rd: レジスタ(32bit)
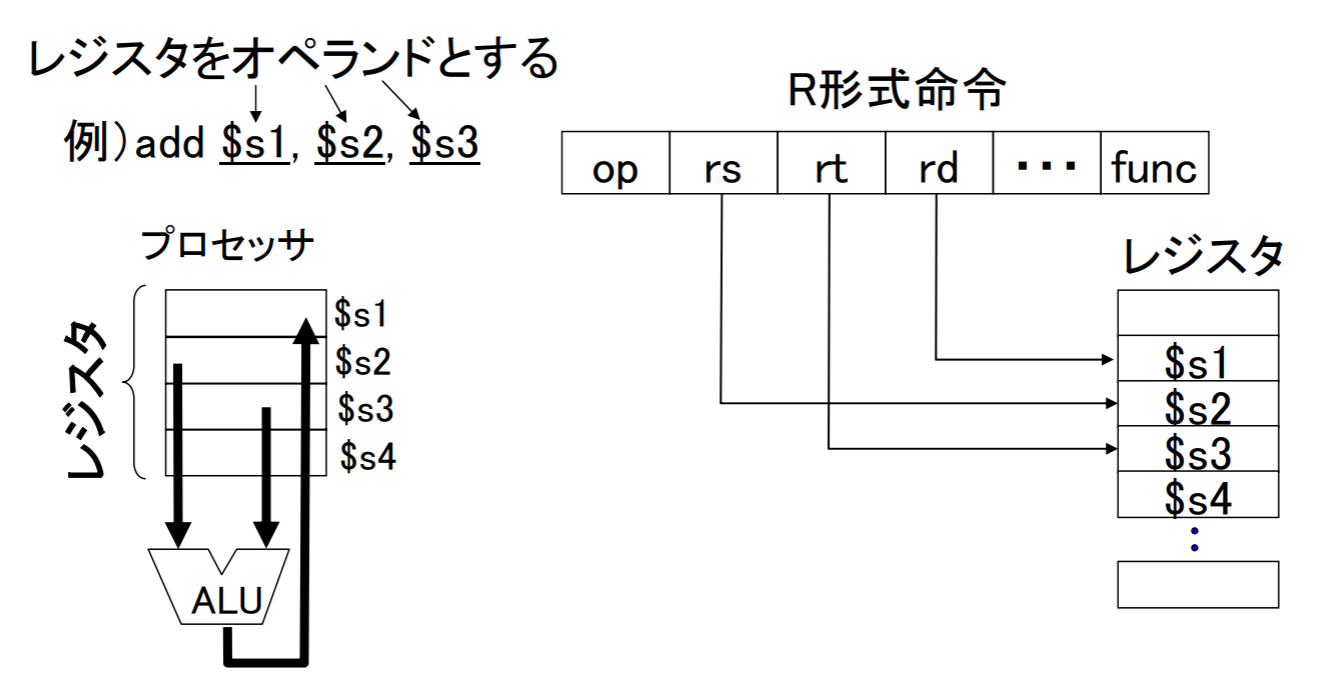
ベース相対アドレシング
- 例: lw, lh, lb
- ロードとストアには語、半語、バイト
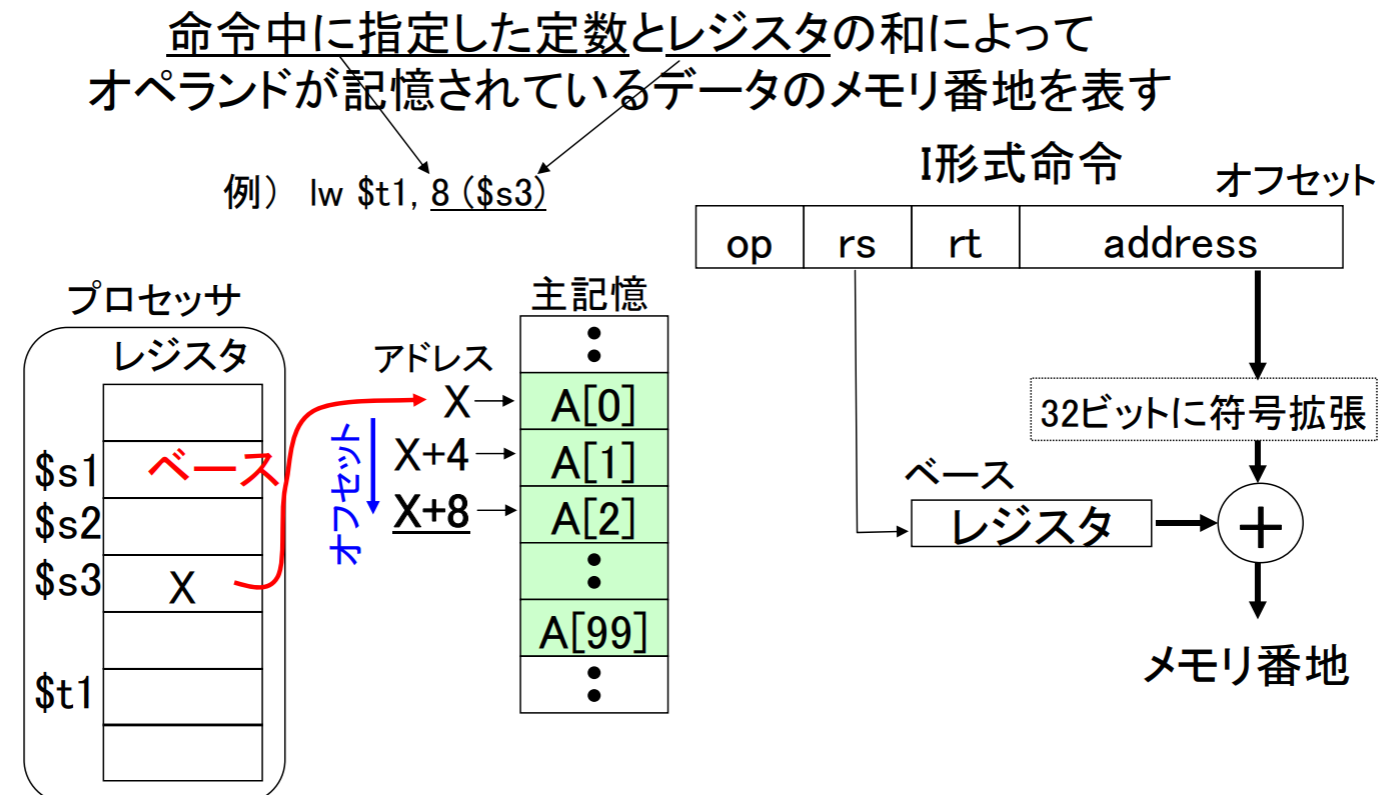
PC相対アドレシング
- 例: beq, bne
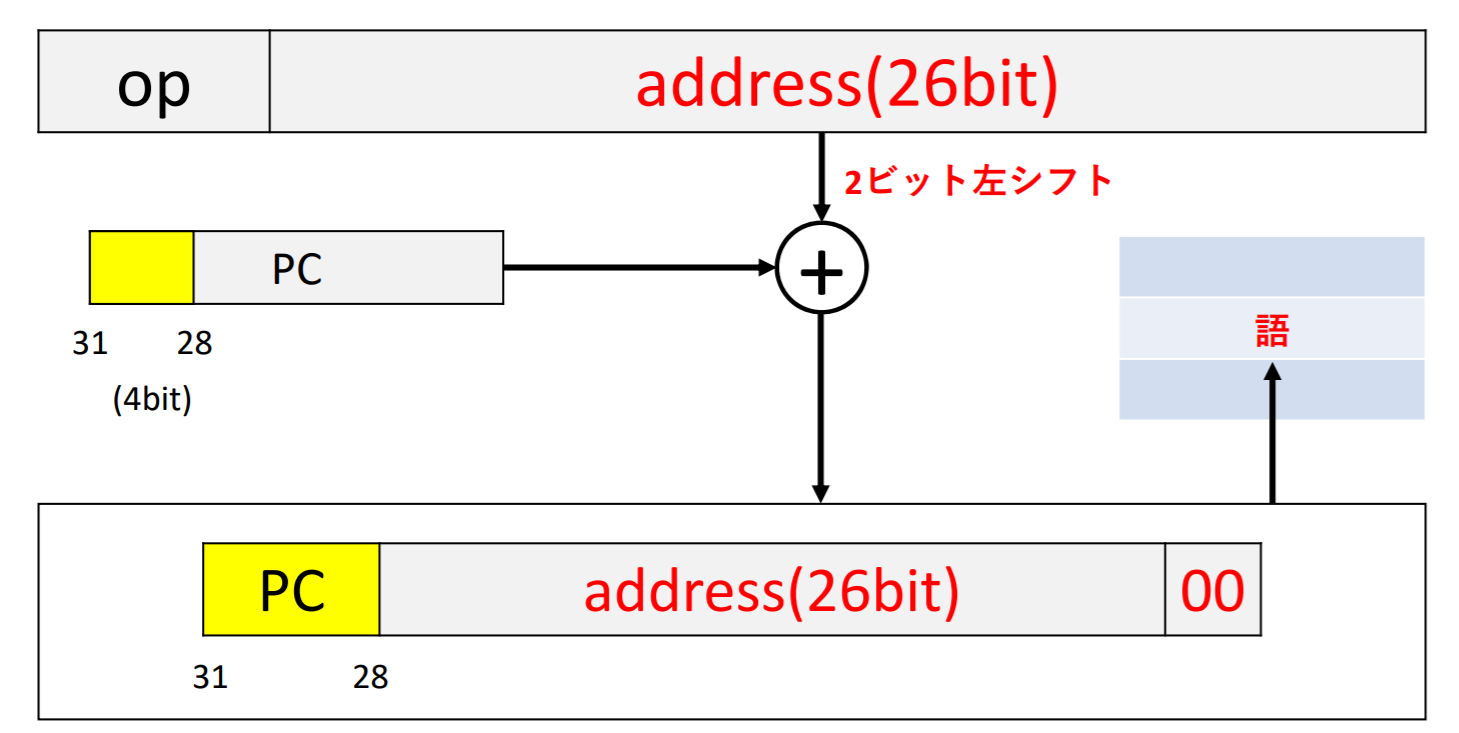
PC相対アドレシングでは、次の命令のバイト数の代わりに語数が使用される。そのため、アドレスフィールドで指定した値はバイトアドレスではなく、語アドレスを指すため、32bit符号拡張するだけでなく、2ビット左シフト演算を行って和が計算される
疑似直接アドレシング
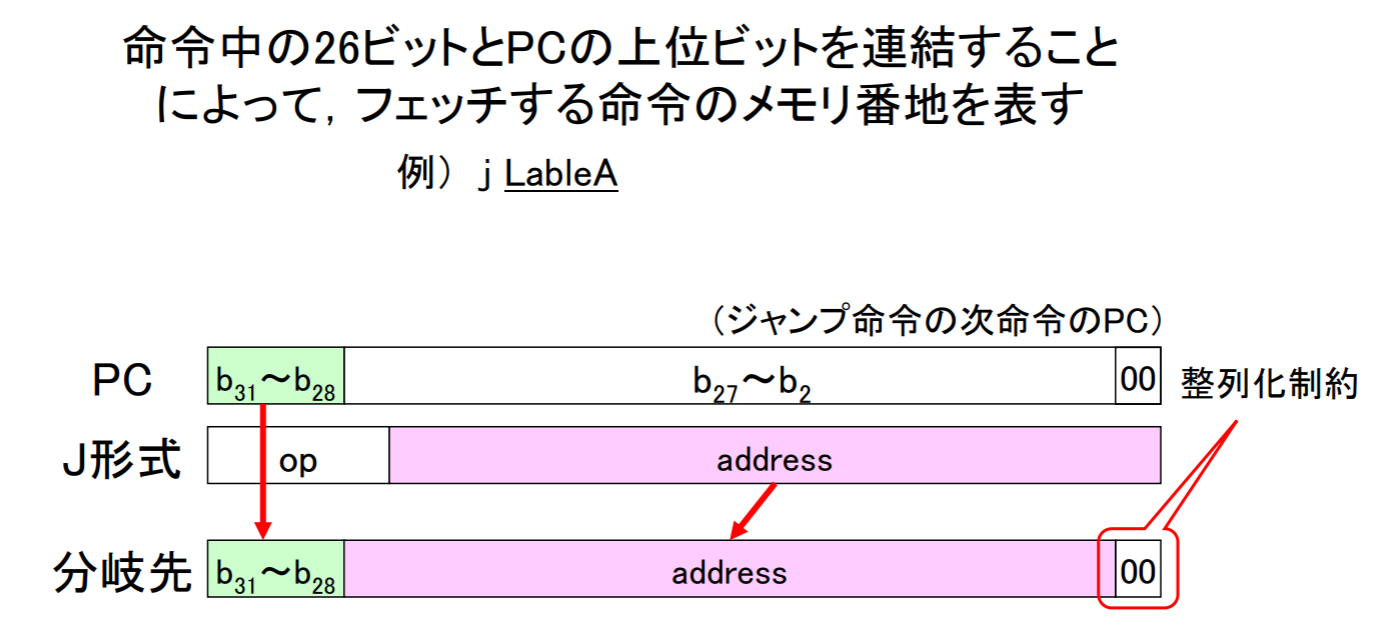
アドレシング例

- beq命令では次の命令アドレス(PC+4)をベースに相対アドレス(2語=2*4バイト)を指定している(PC相対アドレシング)
- j命令ではラベルLoopに対する完全なアドレス(語単位)を指定している
这里使用了PC相对寻址,PCLoop这一行的Exit为了跳到最后一行的Exit,需要求出在address field指定的值(符号扩张),最后记得左移2位即乘以4。
jump目的地地址 = (PC + 4) + 符号扩张 * 4
即需要求出这个符号扩张的值,看命令,执行3步即可到最后一行Exit处,因此,这个值是3。
PC + 4中这个4就是在走下一步,即到达目的地最后一行的Exit处
MIPSの設計規則
- 単純性は規則性につながる
- 命令が固定長
- 小さければ小さいほど高速になる
- レジスタ数が32本
- 優れた設計には適度な妥協が必要である
- 命令長を固定する代わりに複数の命令形式を用いる
- 一般的な場合を高速化する
- PC相対アドレシング
- 即値アドレシング
課題3.2
(1) 在MIPS中条件分支的地址范围(K=1024)是多大?
上位4ビットがPCから得られる256Mのアドレスの範囲内
| op | reg | reg | address |
|---|---|---|---|
| 6位 | 5位 | 5位 | 16位 |
其中后16位用于指定分支地址
MIPS条件分支指令寻址采用PC相对寻址,分支指令的地址为 PC 加上分支地址。PC包含当前指令地址。分支地址有16位,因此可跳转到离当前指令距离为个字(words)(注意是字,因为PC相对寻址是按字寻址),1个字等于4个字节(Bytes),所以条件分支指令的地址范围是
即分支前后地址范围各大约128K,即地址范围为256K。
(2) 在MIPS中跳转和跳转链接指令的地址范围(M=1024K)是多大?
分岐点の前後それぞれ約128Kの範囲のアドレス
| op | adress |
|---|---|
| 6位 | 26位 |
其中后26位用于指定跳转地址,其为字地址,它可以表示为28位的字节地址。MIPS跳转指令寻址采用伪直接寻址,跳转指令的目标地址由当前的PC的高4位与跳转指令的低26位左移2位后相加而成。
所以可跳转的地址范围为。
(3) 以下のMIPS アセンブリ・コードに対応するC ステートメントを簡潔に示せ.
変数a, b, h, i, j はレジスタ$s0, $s1, $s2, $s3, $s4 にそれぞれ割り当てられている.
配列A, B の先頭アドレスはレジスタ$6, $s7 に それぞれ割り当てられている.
一時変数としてレジスタ$t0, $t1 を使用することができる.$zero は常にゼロとなるレジスタである.
MIPSアセンブリ・コード
1 | addi $s3, $zero, $s0 |
1 | for (i = a; i < b; i++){ |
- beq(branch if equal): beq register1, register2, L1
- レジスタ1とレジスタ2の値が等しい時、L1というラベルの付いたステートメントにプログラムの流れを分岐される
- bne(branch if not equal): bne register1, register2, L1
- レジスタ1とレジスタ2の値が等しくない時、L1というラベルの付いたステートメントにプログラムの流れを分岐される
- j(無条件分岐): j Exit
- プロセッサに必ず分岐を行わせる
- slt(set on less than):
- slt register3, register1, register2 # 符号付き
- sltu register3, register1, register2 # 符号なし
- レジスタ1 < レジスタ2の場合にレジスタ3に1をセットし、そうでない場合に0をセットする
(4) 以下のMIPSアセンブリ・コードを実行する.次の問いに答えよ.
1 | slt $t2, $zero, $t0 |
- $t0に0x00101000が保持されているとき、$t2の値はどうなるか
- $
- $t0に0x80001000が保持されているとき、$t2の値はどうなるか
- $
- $
(5) 16ビット固定長の命令セットをもつコンピュータがある。このコンピュータには、30種の命令が規定されており、汎用レジスタの数は4である。また、命令フォーマットでは、命令種別、レジスタ番号、即値を指定するフィールドが規定されており、レジスターレジスタ間の演算命令は3個(ソース2個、デスティネーション1個)、レジスター即値間の演算命令は2個(ソース1個、デスティネーション1個)のレジスタオペランドを取るとする。
レジスター即値間の演算命令において、命令種別及びレジスタオペランドの指定に用いるフィールド以外のビットをすべて即値の表現に使用できるとしたとき、この命令で扱うことができる即値の最大値として最も妥当なのはどれか。
ただし、命令種別を表すフィールドは固定幅とし、そのフィールド以外で命令種別を区別することはできないものとする。また、即値フィールドは符号なし整数として解釈されるものとする。
解答: 127
- 命令数30種であるから0~29で表現できればよい。この時、5bitが必要。
- 汎用レジスタの数4であるから0から3で表現できればよい。このとき、2bitが必要。
- レジスター即値の演算命令で命令とオペランド2つで必要なビット幅は5+2*2=9bitであることから残り7bit。
- rs: ソース, rt: デスティネーション
- 7bitで表現できる数は (通り)であるから、符号なし整数の場合、0から127まで表現することが出来る
汎用レジスタの数是4,可以使用0-3任意一个数字表示其中1个寄存器,0-3中2进制需要2位表示。
如果汎用レジスタの数是8,可以使用0-7任意一个数字表示其中1个寄存器,0-7中2进制需要3位表示。
因此这里是op:5bit, rs:2bit, rt:2bit, 固定长16bit减去5+2*2=7bit, 7bit可以有即可以表示数字0-127,最大数字127
(6) 次のプログラムにおいて,命令Aから命令Bまで実行されるとき,次の問いに答えよ.ただし,$zeroは常にゼロとなるレジスタであり,アドレス100からデータメモリに格納されているワード値は,順番に2,4,6,8,10,⋯とする. また,命令Aは命令アドレス0000A000に置かれているとする.
1 | プログラム: |
- 命令B実行後のレジスタ$s2の値を示せ.
- プログラムのbeq命令を実行するときの符号拡張の出力の値を8桁の16進数で示せ.
PC相対アドレッシング
ジャンプ先アドレス = PC + 4 + (符号拡張, 2ビットシフト)
swから5命令前まで戻ればよい.
1 | 0000 0101 ← 5 |
よって符号拡張した結果はFFFF FFFB
这里要求beq命令执行时候这个loop的值,即符号扩张。所以找到上面loop这一行后再往上一行,即往上5行,这个值位5。
所以求5的符号扩张的值即可。最后转化成16进制
算数演算
整数の加算と減算
加算
- 最下位ビットから順にビットごとに加算し桁上げがあれば次の桁のビットに加える
- 加算によって最上位ビットからの繰り上がりが発生(オーバーフロー)した場合
- 符号あり演算(add,addi,subなど)の場合:例外(割り込み)が発生
- 符号なし演算(addu,addiu,subuなど)の場合:無視する
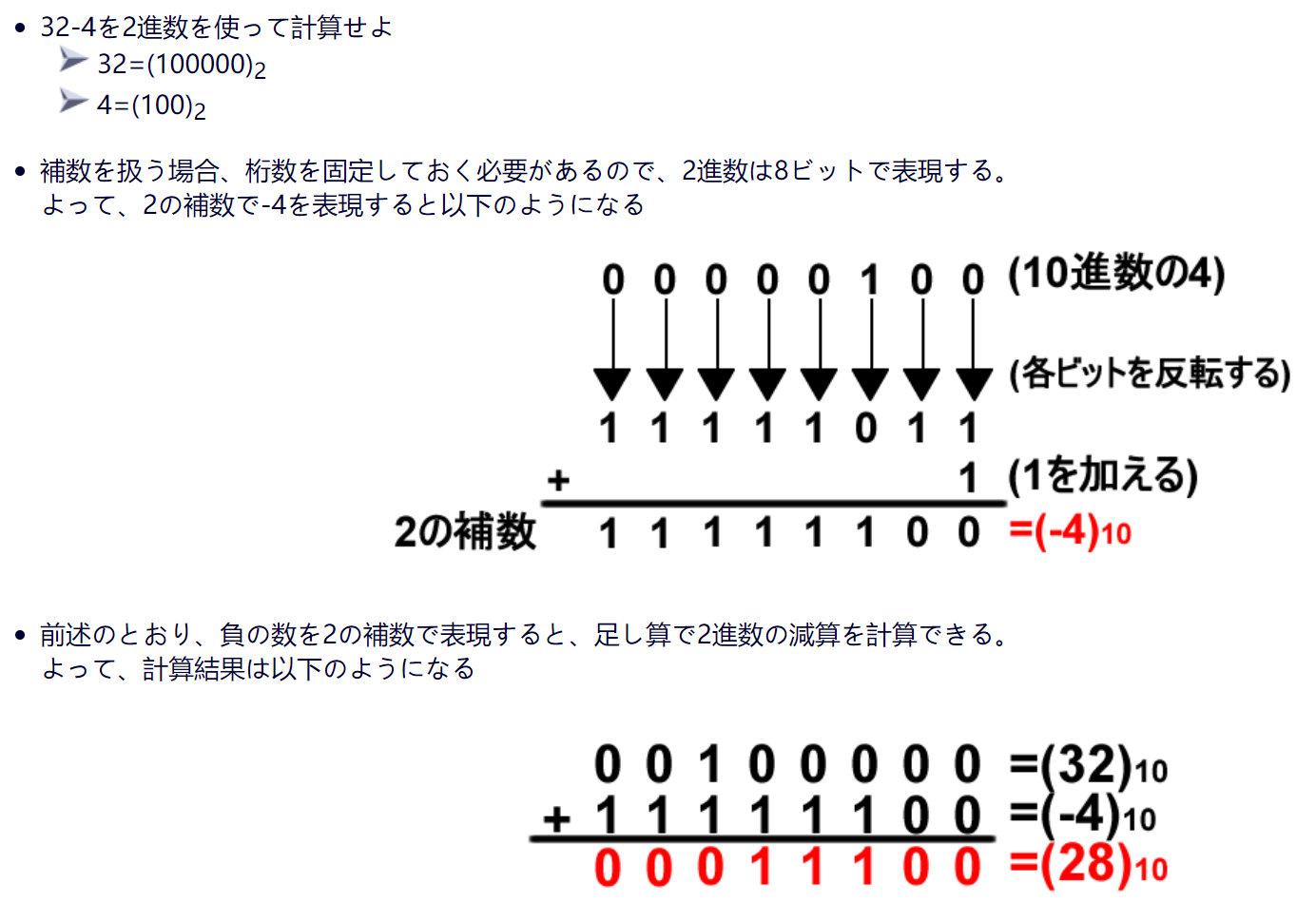
減算
- 引く数を正負反転(2の補数)して加算
オーバーフロー
結果が用意されたハードウェアに収まりきらない場合、オーバーフローが発生する
最上位ビットは符号なので,
- 正の数同士、若しくは負の数同士の加算では、このようなことが起こる
- この例では4ビットなので、計算結果が-8から7に収まらないといけない
オーバーフローが起きないケース:
- 符号が異なる数の加算(正の数 + 負の数)
- 符号が同じ数の減算 = 符号が異なる数の加算
- 正の数 - 正の数 = 正の数 + 負の数
オーバーフローの検出と例外処理
最上位ビット(符号ビット)が値として設定される
- 以下はオーバフロー起きている場合
| 操作 | ペランドA | オペランドB | 結果 |
|---|---|---|---|
| A+B | 正 | 正 | 負 |
| A+B | 負 | 負 | 正 |
| A-B | 正 | 負 | 負 |
| A-B | 負 | 正 | 正 |
例外(割り込み):
- 例外を起こした命令のアドレスをレジスタに退避
- MIPSでは例外プログラムカウンタEPCが用意されている
- 例外処理ルーチンにジャンプ
- mfc0(movefromsystemcontrol)命令でEPCをレジスタにコピーできる(例外処理後、jrで復帰することも可能)
MIPSの加算と減算(まとめ)
- 符号あり整数の加算(add,addi)と減算(sub)
1 | add $s1, $s2, $s3 : $s1 = $s2 + $s3 |
オーバーフローが発生
- 符号なし整数の加算(addu,addiu)と減算(subu)
1 | addu $s1, $s2, $s3 : $s1 = $s2 + $s3 |
オーバーフローが発生
整数の乗算、除算
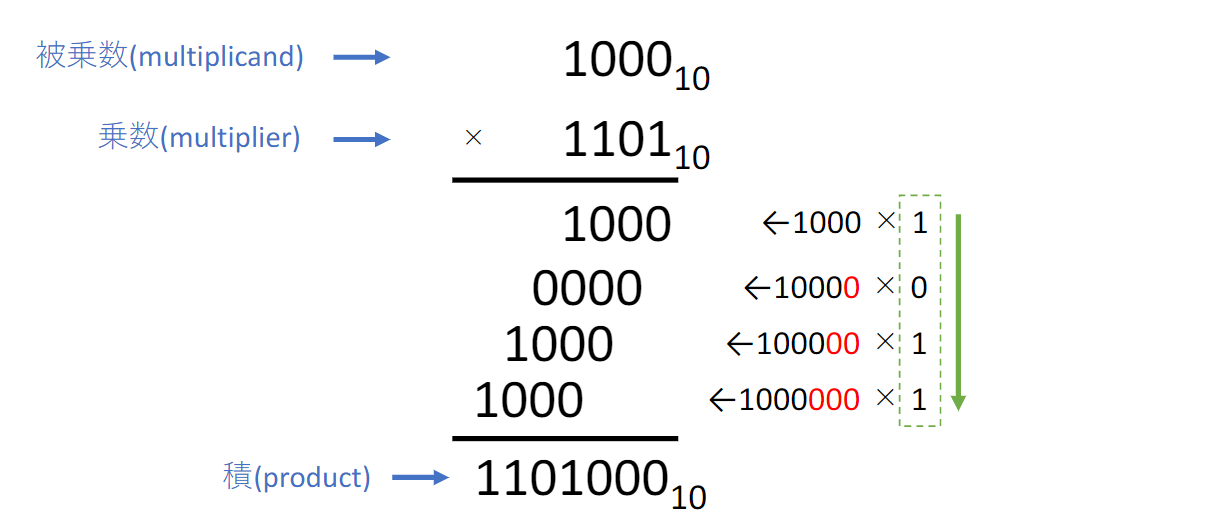
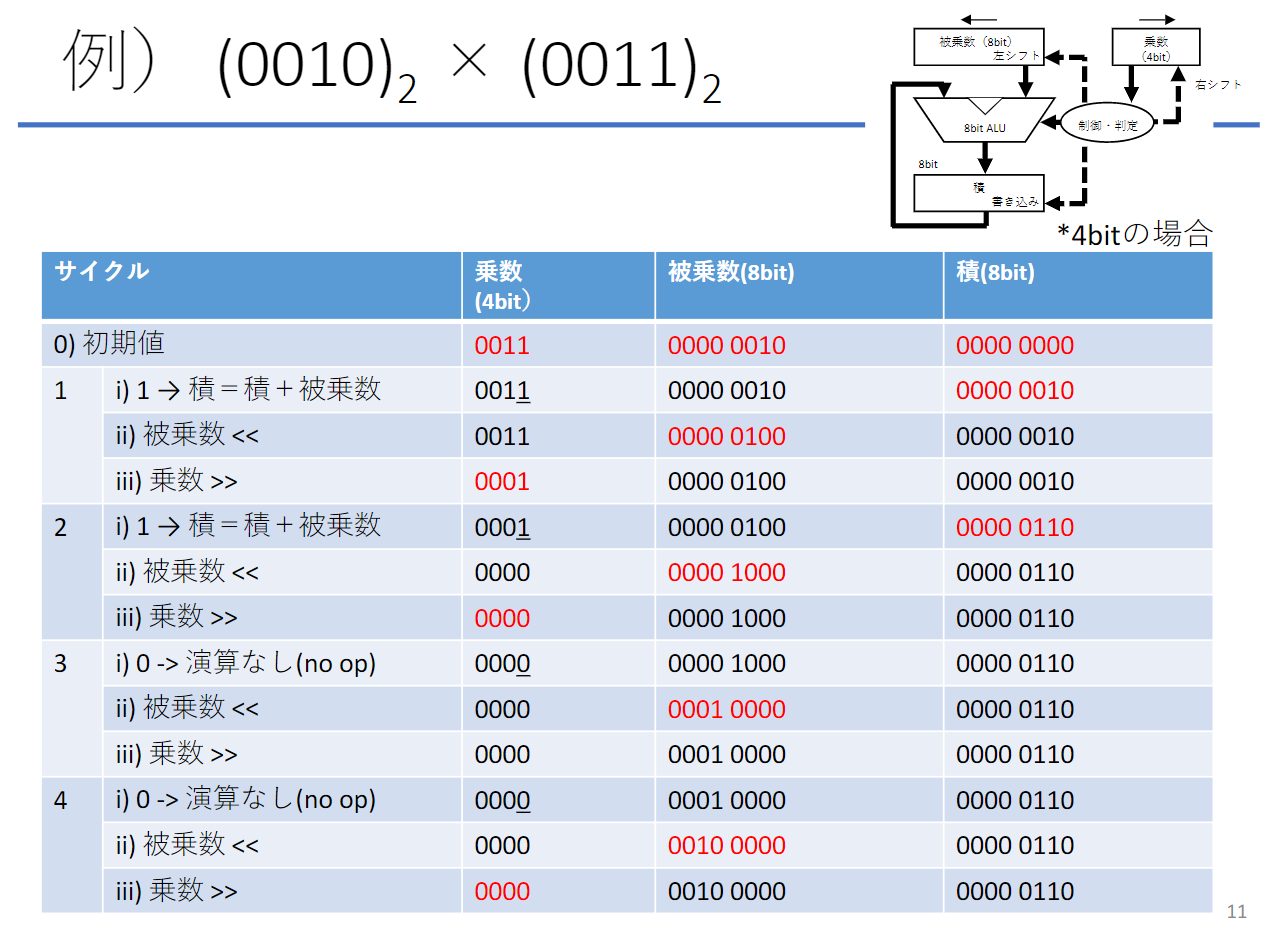
乗算
乗算ハードウェア
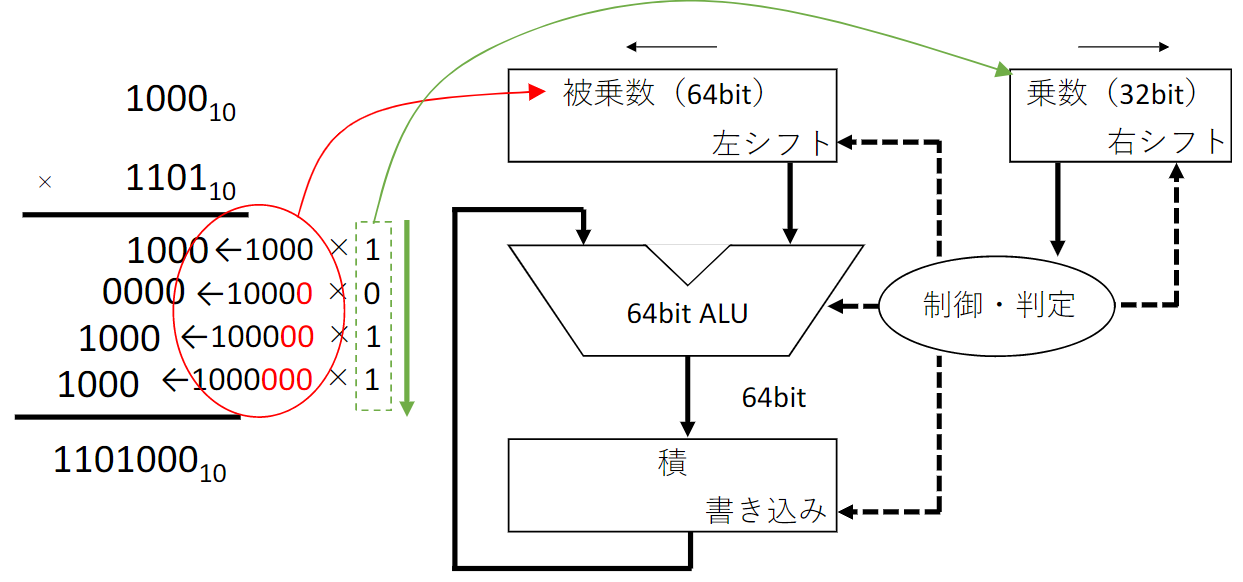
- 乗数の最下位ビットの値に応じて被乗数を積レジスタに加える
- 被乗数レジスタを左シフト
- 乗数レジスタを右シフト
このステップを32回繰り返すことで結果が得られる
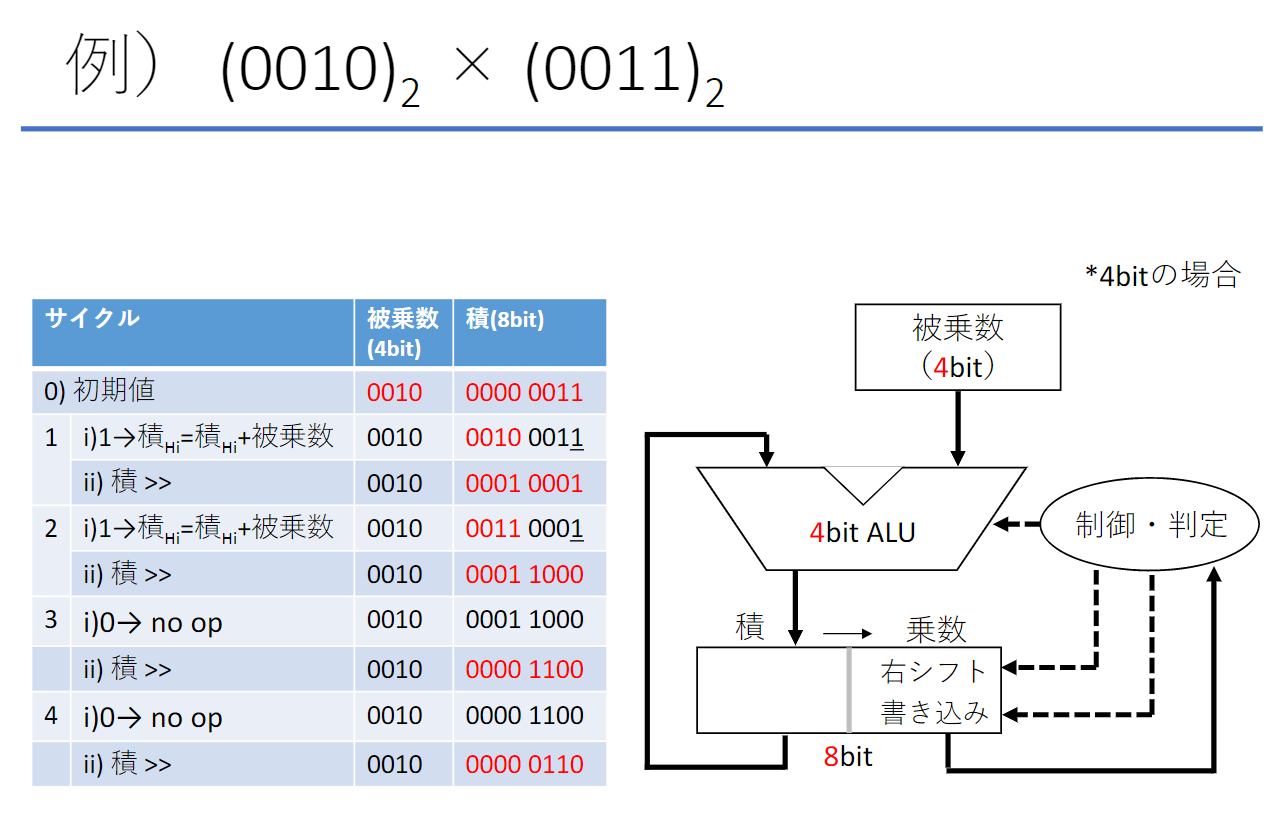
乗算ハードウェアの改良
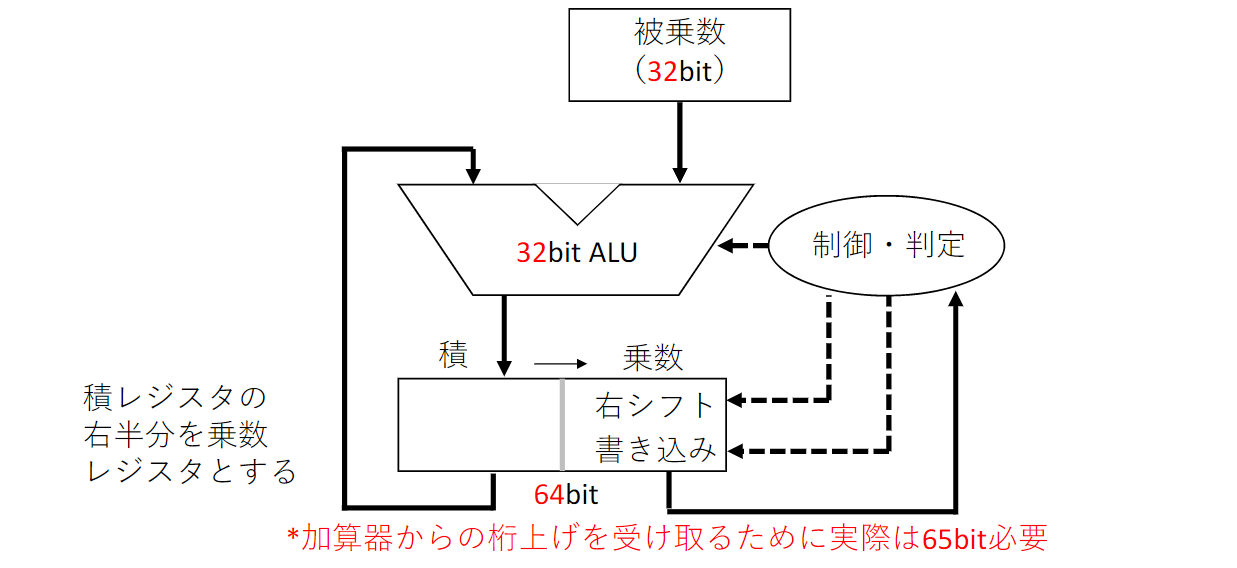
- 乗数の最下位ビットが1の場合、被乗数を積に加算
- 積レジスタ(乗数含む)を右シフトする
このステップを32回繰り返すことで結果が得られる
MIPSにおける乗算命令
- 2つの32bitレジスタ(Hi,Lo)を組で使用
- mult:符号付き乗算
- multu:符号なし乗算
mult $s2, $s3 : Hi, Lo = $s2, $s3 (HiとLoに64bit符号付き積が格納)
結果を取り出す命令:
- mflo(movefromlo):Loの値をレジスタに転送する
- mtlo (movetolo)
- mfhi(movefromhi):Hiの値をレジスタに転送する
- mthi (movetohi)
- mult:Hiの符号がLoと同じであればよい
- multu:Hiが0であればよい
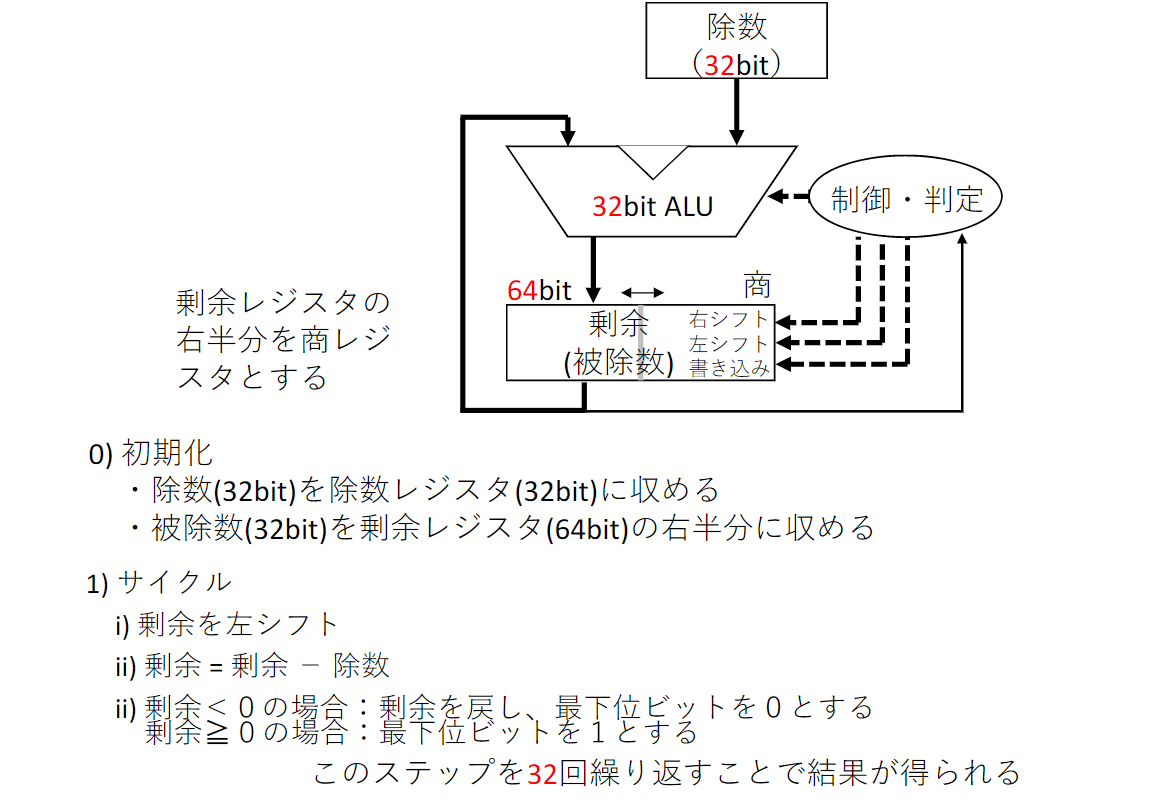
除算

除算ハードウェア
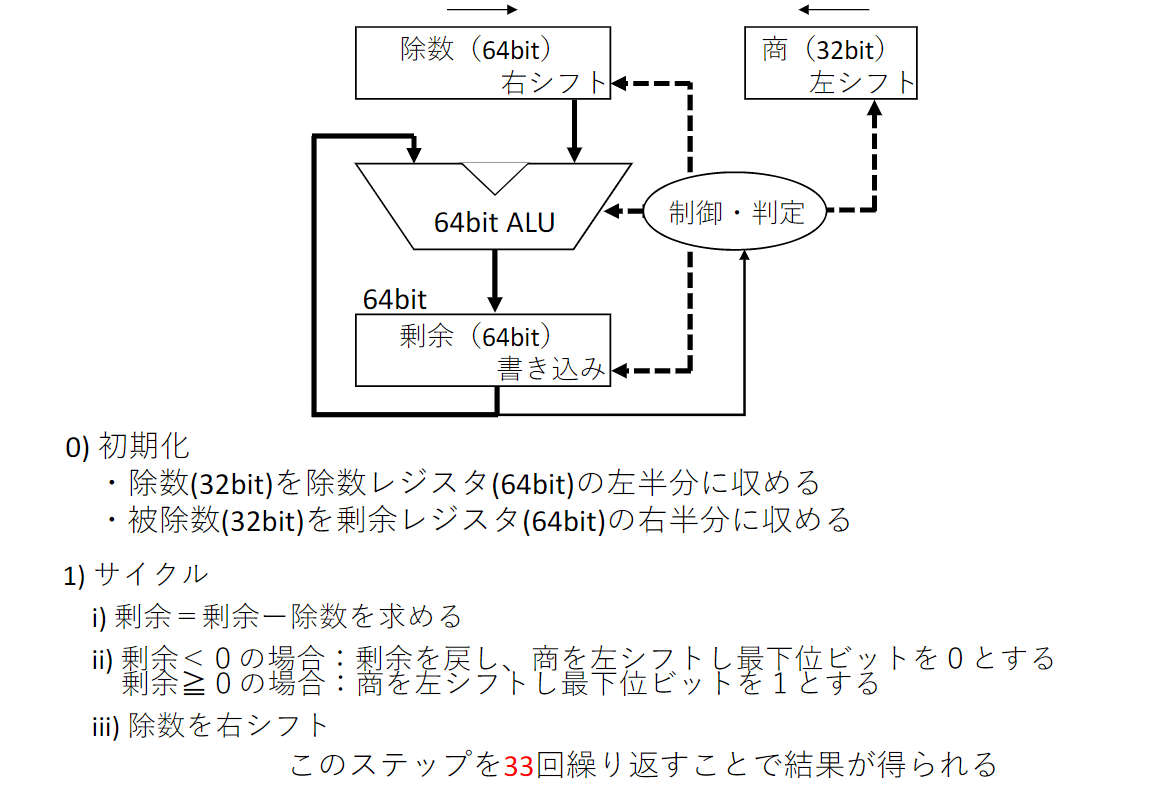
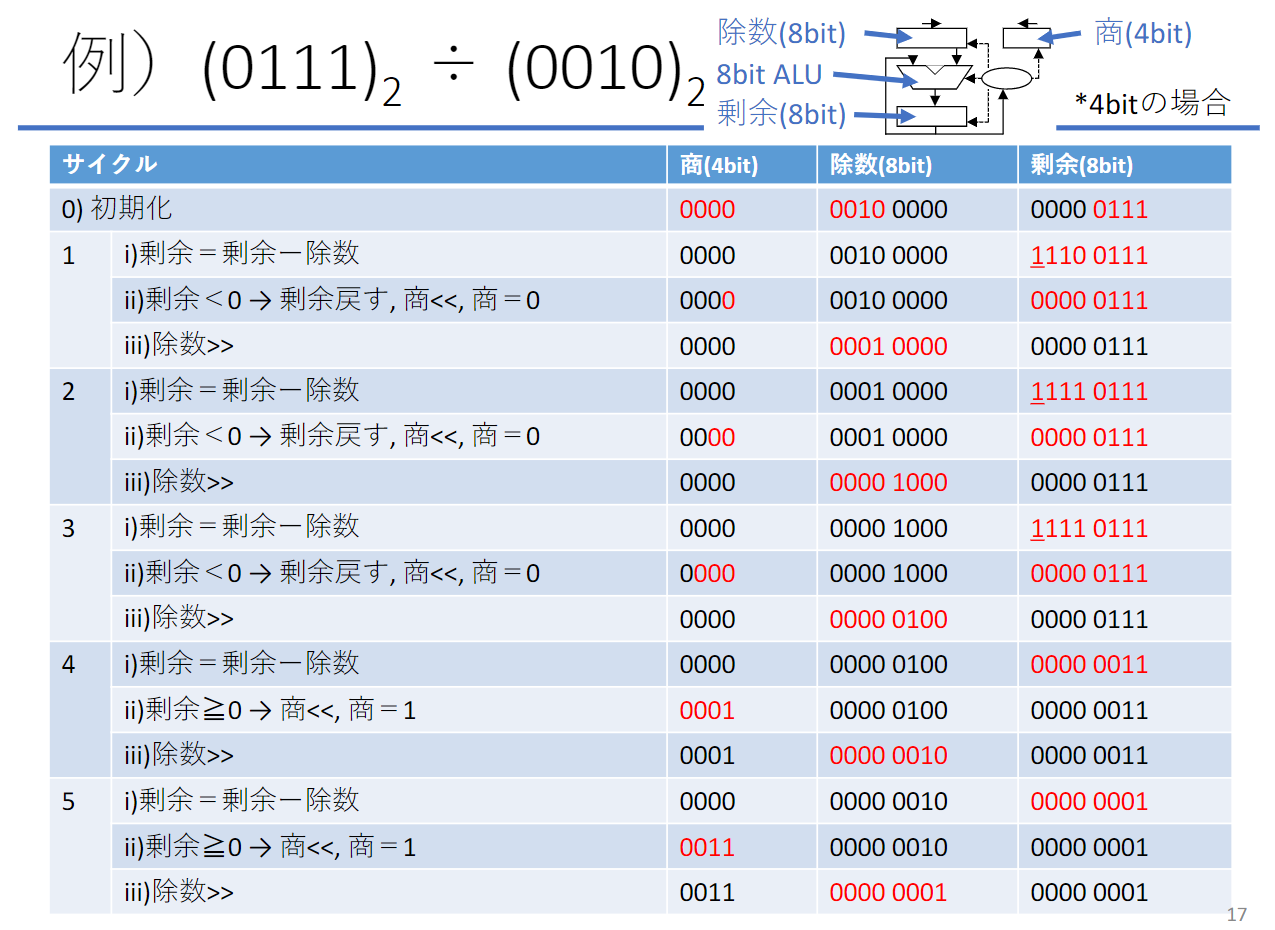
除算ハードウェアの改良
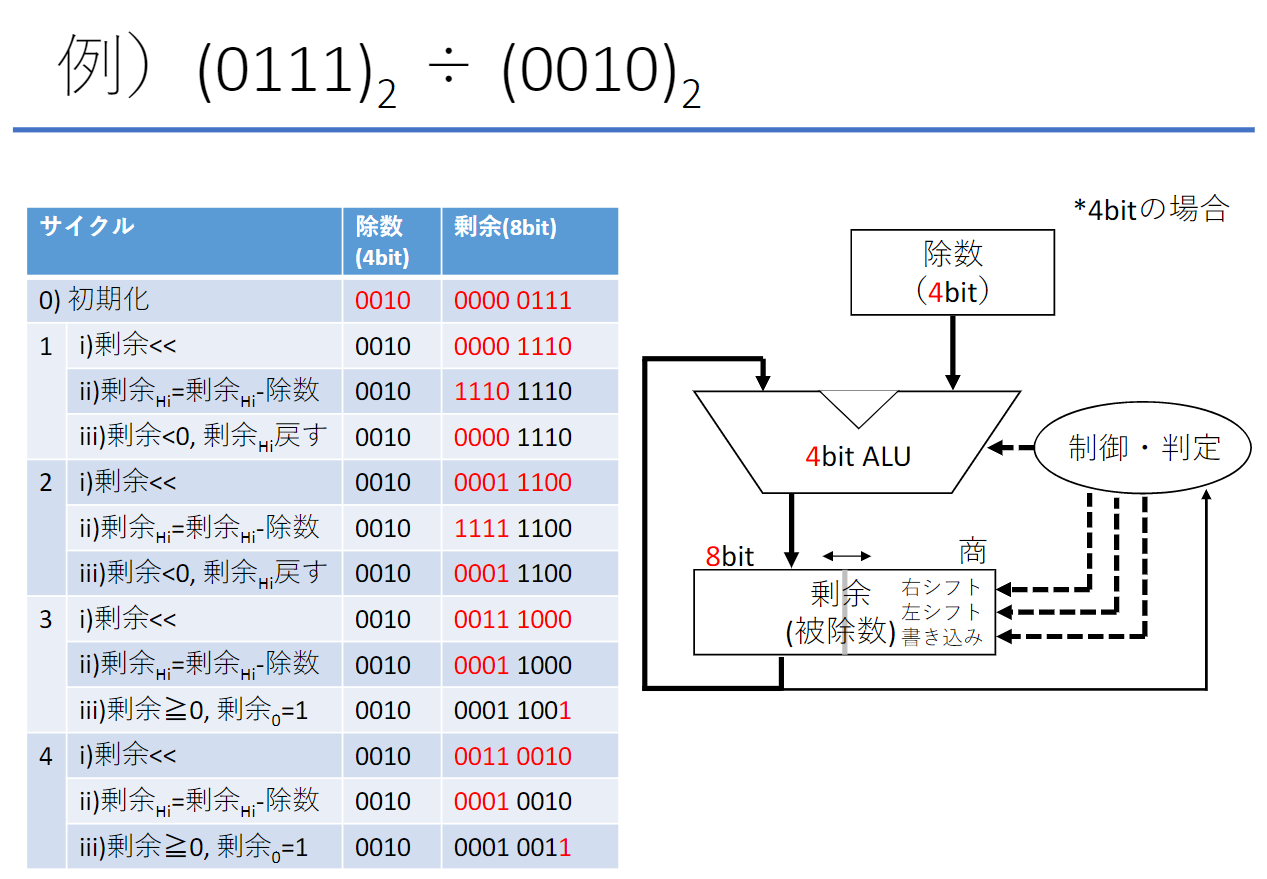
符号付き除算
被除数 = 商 除数 + 剰余
- 商の符号 = 被除数と除数が同符号なら正, 異符号なら負
- 剰余の符号 = 被除数の符号
例:
MIPSによる除算
- 左右にシフト可能な64bitレジスタ
- 加算および減算用の32bitALU
- div:符号付き除算
- divu:符号なし除算
div $s2, $s3 : Lo = $s2 $s3, Hi = $s2 $s3 (Loに商が、Hiに剰余が格納)
- mult:Hiの符号がLoと同じであればよい
- multu:Hiが0であればよい
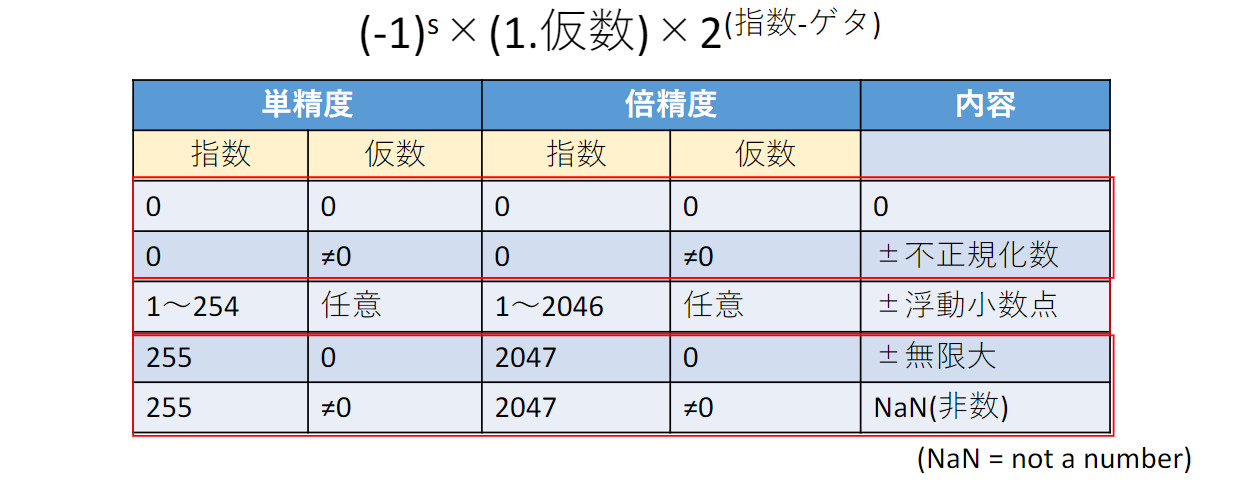
浮動小数点の表現法(IEEE 754)
実数を表す科学記数法
- eg.
- 小数点の左側が一桁でかつ0でないものを正規化数という


IEEE 754のエンコード規則
- オーバーフロー:正の指数が大きすぎて指数部に収まりきらない場合
- アンダーフロー:負の指数が大きすぎて指数部に収まりきらない場合
- いずれも正規化数にすることができない
- ゼロ除算: 非ゼロの数をゼロで割った場合
- 例外処理 or のビットパターンを設定
- 無効演算: , 負の平方根
- 例外処理or NaNのビットパターンを設定

浮動小数点の加算、乗算
浮動小数点の加算

浮動小数点の乗算

MIPSにおける浮動小数点命令
- add.s / add.d: 単/倍精度の加算
- sub.s / sub.d: 単/倍精度の減算
- mul.s / mul.d: 単/倍精度の乗算
- div.s / div.d: 単/倍精度の除算
- c.x.s /c.x.d: 単/倍精度の比較(x=eq,neq,lt,le,gt,ge)
- bclt:浮動小数点形式の条件が真のとき分岐
- bclf:浮動小数点形式の条件が偽のとき分岐
- 汎用レジスタ(整数)と別に浮動小数点レジスタが用意されている ($f0 - $f31)
- 偶奇一組にして倍精度として使う(偶数番のレジスタで指定する)
- eg. $f0, $f1を合わせて$f0(倍精度)
- lwc1: 32ビットのデータを浮動小数点レジスタに転送
- load word coprocessor 1
- swc1: 32ビットの浮動小数点データをメモリに転送
- store word coprocessor 1
課題3.3
(1) 以下の空欄に当てはまる語句を埋めよ.
- 整数の演算で結果が用意されたハードウェアに収まりきらない場合、オーバーフローが発生する.
- 符号が同じ数の減算ではオーバーフローの事象は起こりえない.
- MIPSでは符号なし整数の加算、減算命令はオーバーフローが起きても無視する.無視しないときは例外または割込みが発生する.
- MIPSの符号付き乗算命令はmultであり,HiとLoの2つのレジスタに結果が格納される.
- IEEE 754は浮動小数点演算の標準規格であり,32bitの浮動小数点形式を単精度浮動小数点,64bitの浮動小数点形式を倍精度浮動小数点という.
- 単精度浮動小数点、倍精度浮動小数点のゲタはそれぞれ127, 1023である.
- IEEE 754で小数点の左側が一桁でかつ0でないものを正規化数という.
- IEEE 754で仮数部も指数部も0であるときの値は0である.
(2) IEEE 754標準規格を使用して,10進数の-12.75を単精度浮動小数点フォーマットで表現し,これを16進数で表せ.
であるから、仮数部は1.指数部をEとすると
であるから
- 指数部 = 1000 0010
- 仮数部 = 1001 1000 … 000
となる。
よって、C14C0000
S(1) + 仮数部(1000 0010) + 指数部(1001 1000 … 0000) 然后4位一组转换为16进制
1 | import bitstring |
(3)
IEEE 754形式を使用して,−1/4を表すビットパターンを16進数で示せ.−1/4を正確に表すことができるか.
- ビットパターン: BE800000
- 正確に表すことができる
IEEE 754形式を使用して,1/10を表すビットパターンを16進数で示せ.1/10を正確に表すことができるか.
- ビットパターン: 3DCCCCCC
- 正確に表すことができない
结论:一个十进制小数要能用浮点数精确表示,最后一位必须是5,因为1除以2永远是0.5,当然这是必要条件,并非充分条件。
プログラムの翻訳
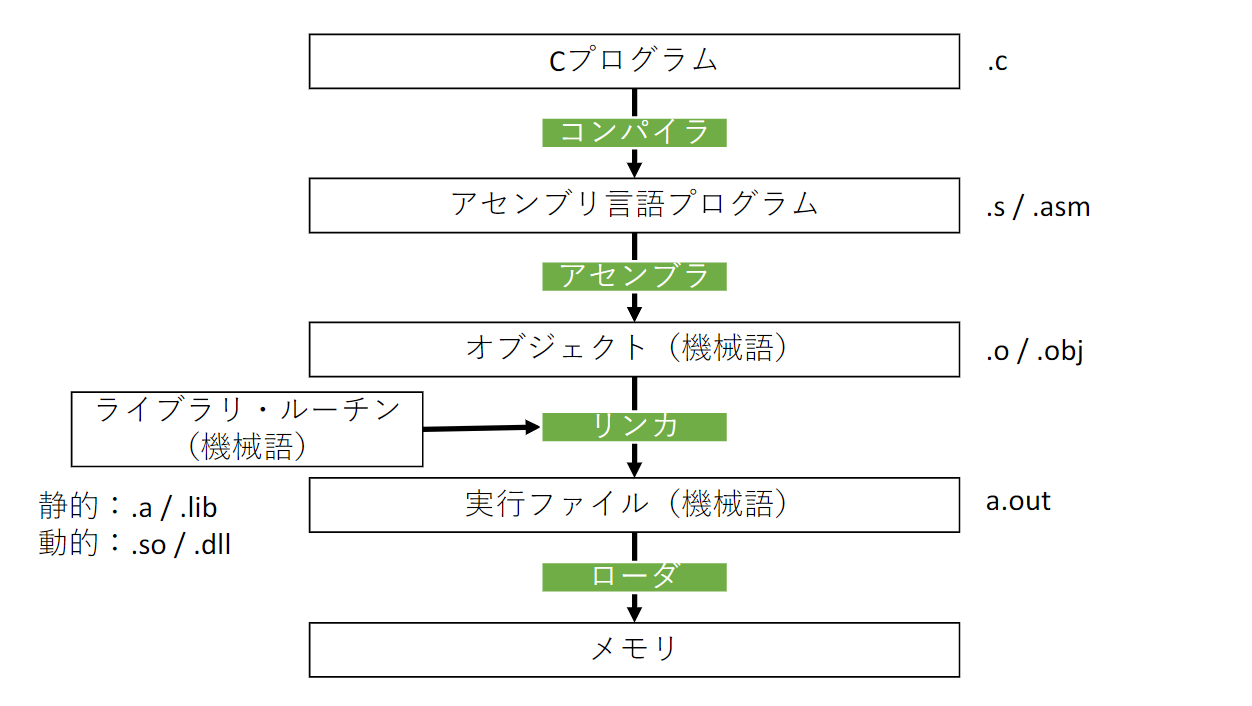
コンパイラ
- プログラムをアセンブリ言語に翻訳する
- オブジェクトファイルを直接生成するものもある
1 | # gccの場合 |

アセンブラ
アセンブリ言語プログラムをオブジェクトに翻訳する
1 | # gccの場合 |

オブジェクト・ファイル
機械語命令、データ、命令をメモリ中に配置するための情報からなるファイル
オブジェクトファイルの構成(UNIXの場合)
- オブジェクト・ファイル・ヘッダー: 残りの部分のサイズと位置
- テキスト・セグメン: プログラム(機械語)
- 静的データ・セグメ: 静的変数など
- リロケーション情報: プログラムをメモリにロードした時の絶対アドレスに依存する命令語およびデータ語
- シンボル・テーブ: 外部参照などの未定義の残りのラベル
- デバッグ情報: どのようにコンパイルしたかの記録
リンカ(リンク・エディタ)
個別に作られたオブジェクトファイルをつなぎあわせて実行ファイルを作成するシステム・プログラム
- メモリ配置の決定
- 各モジュールの再配置(リロケーション)
- 全ての参照先の解明
- モジュール中のリロケーション情報とシンボルテーブルを使用して未解決のラベルをすべて解明する
- コードモジュール、データモジュールをメモリ中に置く
- データ及び命令のラベルのアドレスを判定する
- 内部及び外部の参照先を解明する
- 未解決の参照先を含まないオブジェクト・ファイル
- 「ストリップ済み」実行ファイルはデバッグ情報を含まない
MIPSプログラムのメモリ構造
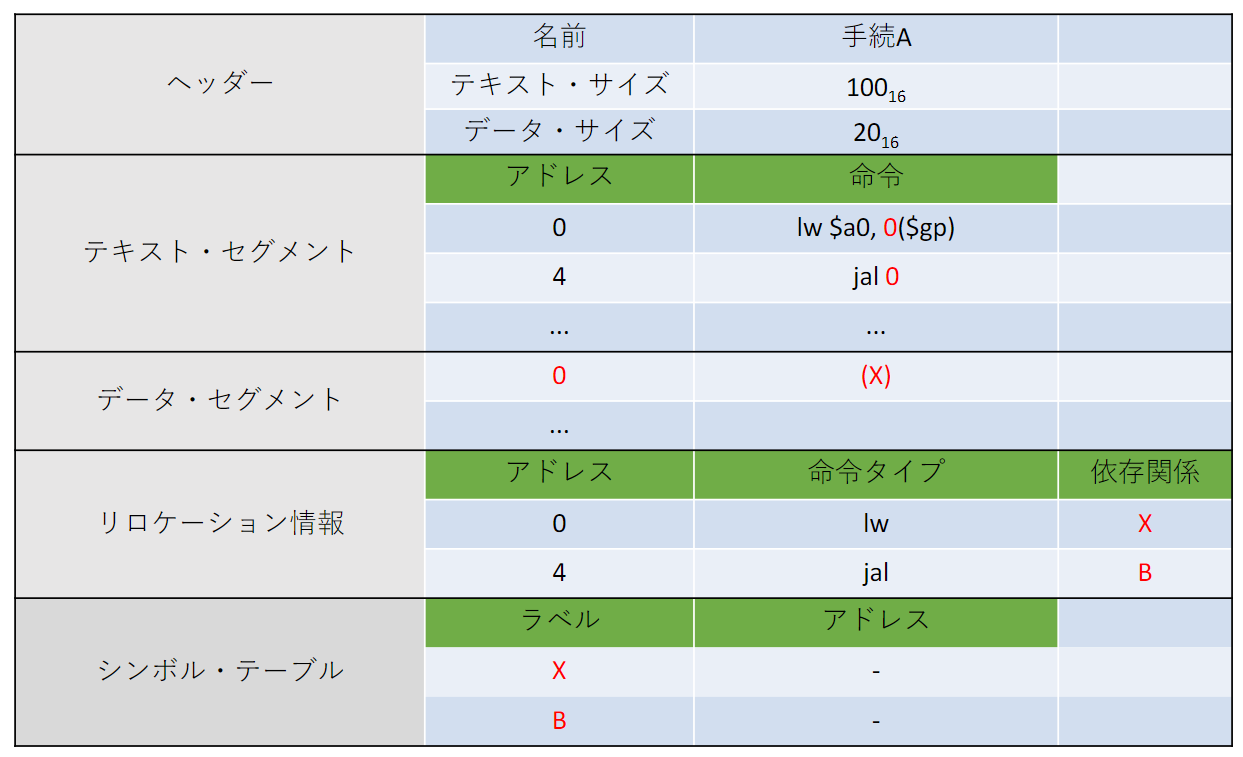
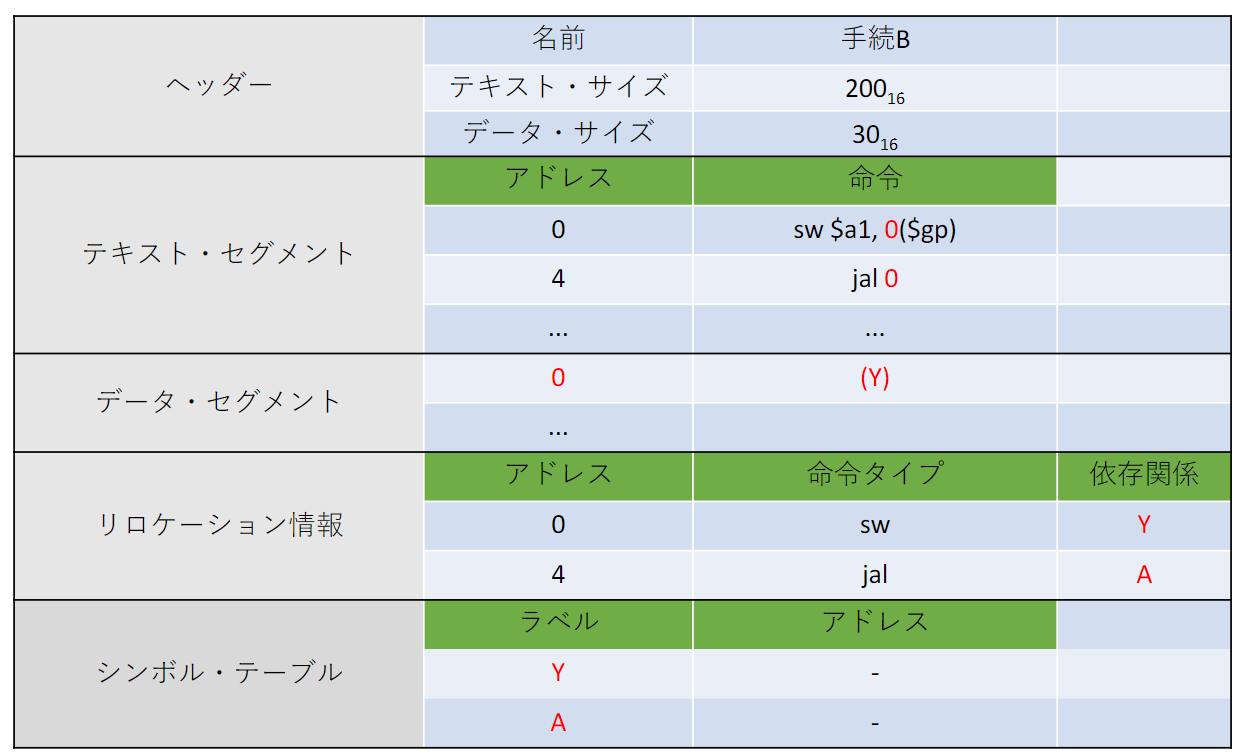
例: 手続きA, Bのリンク
- テキスト・セグメントの開始アドレス:
- データ・セグメントの開始アドレス:
- グローバル・ポインタ($gp):
- 手続A, Bをメモリに配置する
- 変数X、Y手続きA、Bのアドレスが決まる
- 各命令のアドレス・フィールドを更新する
- リンカは命令タイプ・フィールドを参照して更新対象のアドレスのフォーマットを判別する
- load/store命令:$gpに対する相対アドレス
- jal命令:疑似直接アドレッシング, ジャンプ先アドレスが直接書き込めばよい

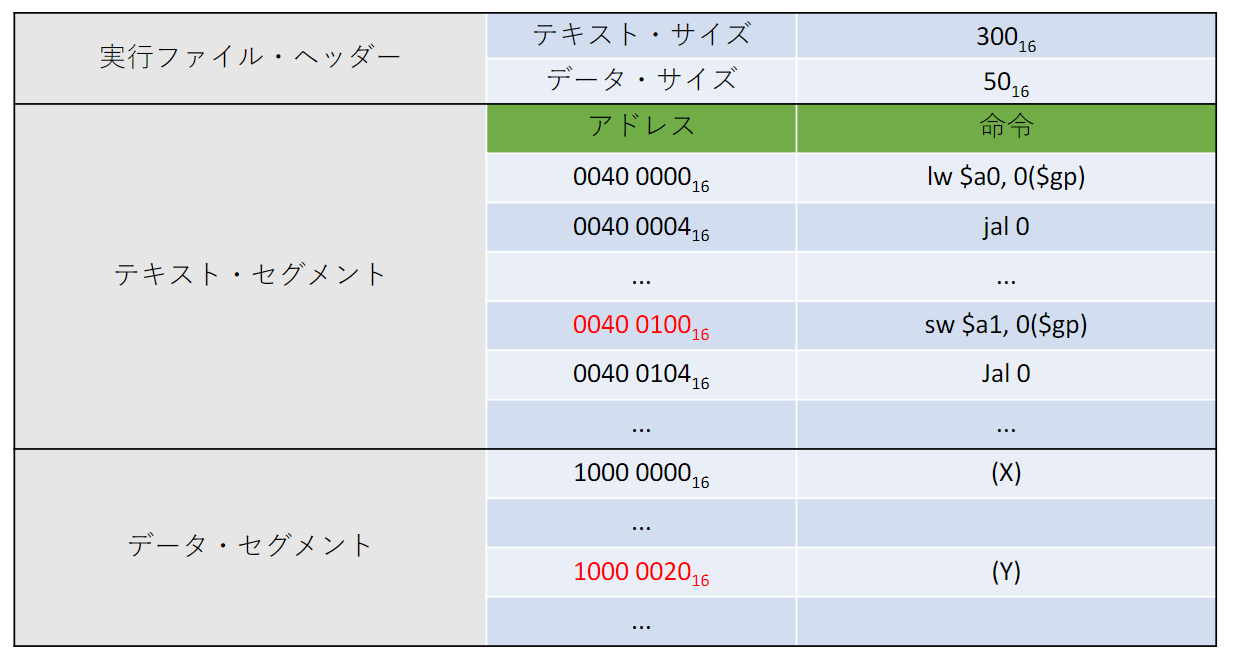
- 手続きAのテキストサイズは100, データサイズは20なので, 手続きBのテキスト解釈アドレス, データ解釈アドレスはそれぞれ赤字に示した.
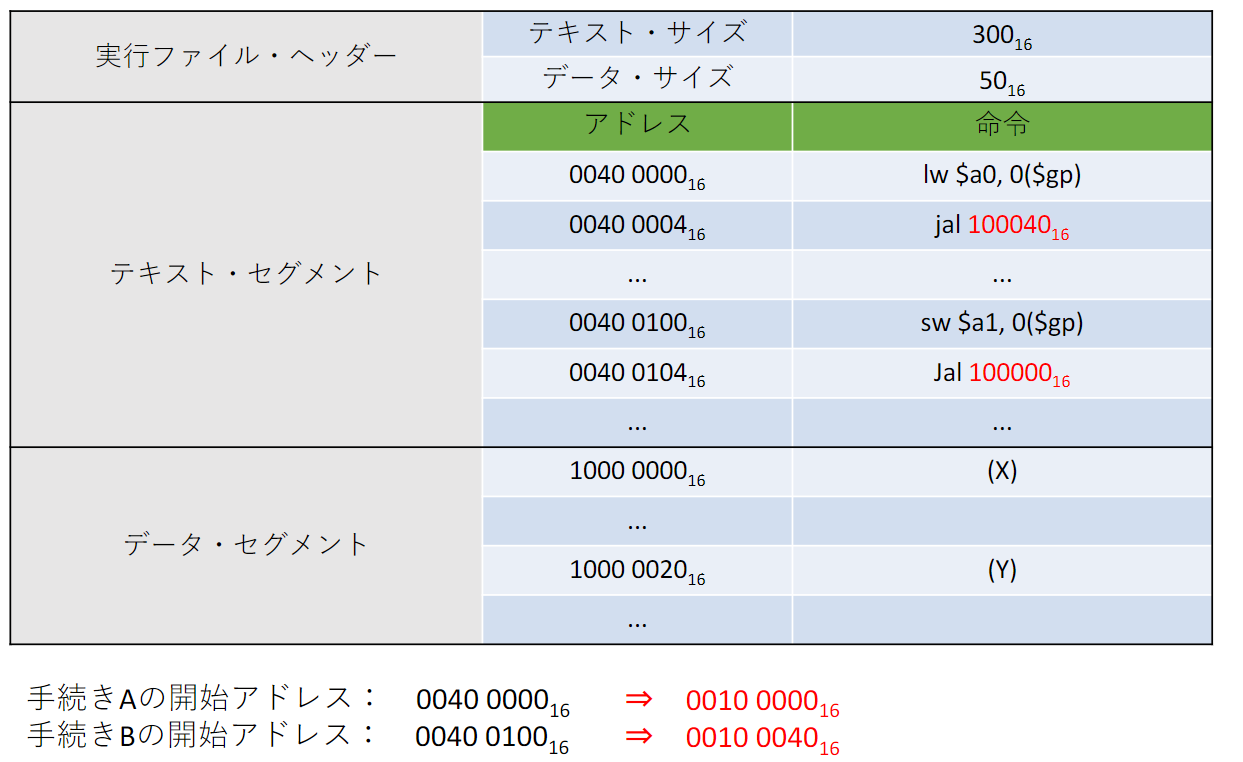
- 続いて, リンカは命令のアドレスフィールドを更新していく.
- まず, jump and link命令jal のjump先アドレスは手続きBの解釈アドレスになるので
- 一方, アドレス jump and link命令jal のjump先アドレスは手続きAの解釈アドレスになるのでになる
- jump and link命令で指定するアドレスが擬似直接アドレシングなので, アドレスフィールド26bitを2bit左shiftして, それがアドレスになる. よって, 実際のアドレスは逆に2bit右shiftしたものになるので, 赤字のように, , になる
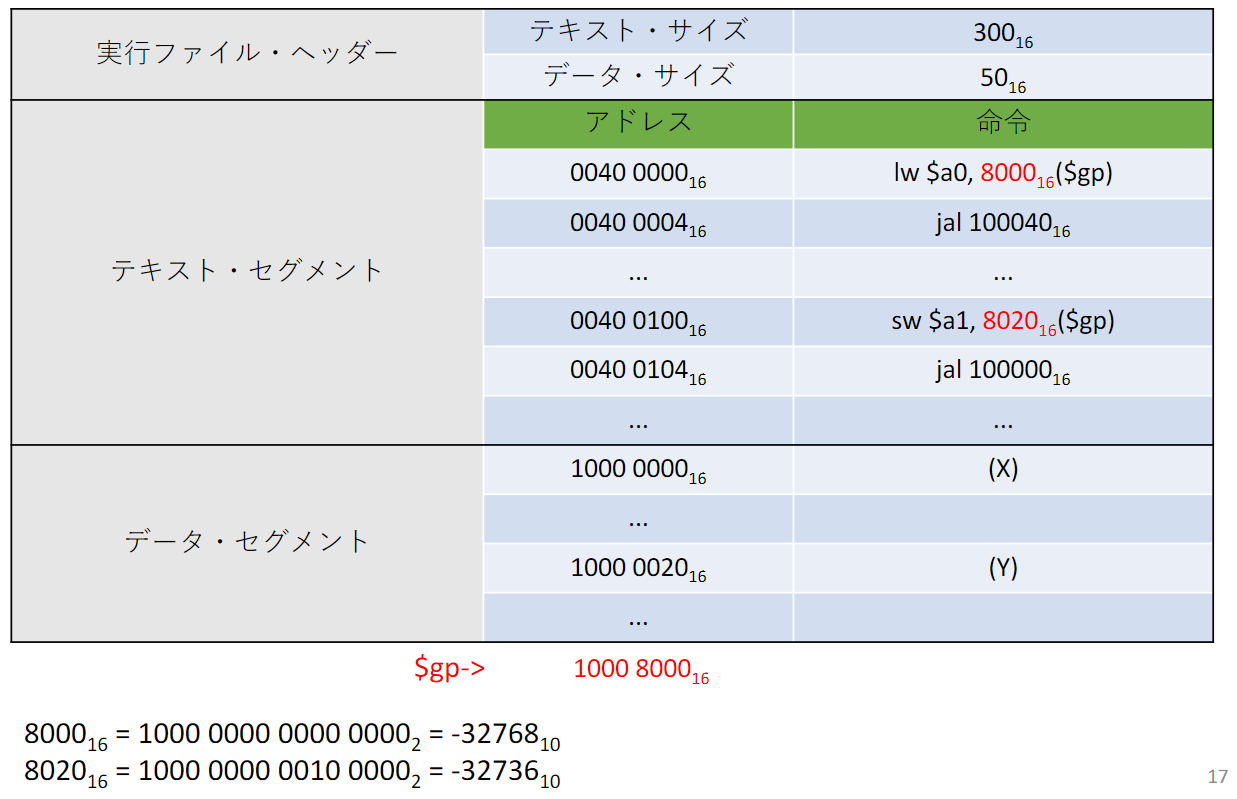
- 次にload命令とstore命令のアドレスフィールドの更新. これらの命令はグローバルポインタに対する相対アドレスが指定される
- グローバルポインタはで初期化されている. 変数Xのアドレスを得るためには, グローバルポインタからを引いてあげると良い. これをload命令のoff setに設定してあげるとXを指定することができる.
- 同様に, 変数Yのアドレスを得るためには, グローバルポインタからを引いてあげると良い. これをload命令のoff setに設定してあげるとYを指定することができる.
- このようにして, データ・セグメントの相対アドレスを解決する
ローダ
プログラムを主記憶に読み込んで実行できるようにするシステム・プログラム
- 実行ファイルのヘッダーを読んで、テキストセグメントとデータセグメントの大きさを判定
- テキストセグメントとデータセグメントを保持するのに十分な大きさのアドレス空間を作成
- 実行ファイルから命令とデータをメモリにコピー
- メインプログラムに渡されるパラメータが存在すれば、スタック上にコピー
- マシンのレジスタを初期化し、スタックポインタに最初の空きロケーションを設定
- 開始ルーチンにジャンプ
- 開始ルーチンはスタックからプログラムの内容をレジスタにコピーしてプログラムのメイン・ルーチンを呼び出す。メインルーチンから処理が戻ると開始ルーチンは終了システムコールを用いてプログラムを終了させる
静的ライブラリ(Static Library)
ライブラリ = 複数のプログラムで使われる共通の機能をまとめたもの
静的ライブラリは、リンク時に実行ファイルの一部に組み込まれる. 拡張子は.a/.lib
1 | # gccの場合 |
静态库,是一个外部函数与变量的集合体。静态库的文件内容,通常包含一堆程序员自定的变量与函数,其内容不像动态链接库那么复杂,在编译期间由编译器与链接器将它集成至应用程序内,并制作成目标文件以及可以独立运作的可执行文件。而这个可执行文件与编译可执行文件的程序,都是一种程序的静态创建(static build)。
動的ライブラリ(DLL,Dynamic Link Library)
静的ライブラリの欠点:
- 実行ファイルの一部に組み込まれるため、新バージョンのライブラリに自動的に更新されない
- 実際に使用されないものも含むため実行ファイルのサイズが大きくなってしまう
動的ライブラリは、プログラムが実行されるときにリンク・ロードされる
- 実行ファイルのサイズを小さくできる
- 初回呼び出しのときのみ負荷がかかるが、2回目以降はかからない
- 动态库和静态库的本质区别是,动态库是在程序运行时链接的,而静态库在编译时把代码加入目标程序,那么程序运行时就不需要了。所以使用静态库时生成的目标程序可以脱离源码运行,而动态库生成的目标程序,还需要先安装库才行
- 使用gcc编译的静态库,在生成目标程序链接的过程中也只能用gcc编译;同理使用g++ 编译的静态库在生成目标程序链接的过程中也只能用g++ 编译。否则会报错"undefined reference to ‘Fun1()’
- 用gcc编译目标程序时,main.c中可以不需要#include “lib.h”,会报warning,但是不会报error;但是用g++ 编译时,一定要加 #include “lib.h”,不然编译不通过,因此用g++ 编译的静态库,还需要它的所有头文件才能使用。
- 当你更改库文件的一些宏定义或者其他东西时,需要重新编译静态库,不然你的修改没有起作用。
ARMv7(32bit)
組み込み機器や低消費電力機器向けに広く用いられている
課題4.1
(1) 次の説明が示す語句を答えなさい.
- 機械語の命令を人間にとってわかりやすい記号に一対一で置き換えた言語: アセンブリ言語
- アセンブラによって生成されるプログラム単位: オブジェクトファイル
- オブジェクトをつなぎ合わせて実行ファイルを作成するシステム・プログラム: リンカ
- デバッグ情報を含まない実行ファイル: ストリップ済み実行ファイル
- 複数のプログラムで使われる共通の機能をまとめたもの: ライブラリ
(2) 次のMIPSアセンブリ・コードについて以下の問に答えよ.
1 | lw $s2 -12($s0) |
- lw命令の第1オペランド、第2オペランドのアドレッシング・モードをそれぞれ答えよ.
第一オペランド:レジスタアドレッシング
第二オペランド:ベース相対アドレッシング
- $s0の値が0x00000100であった.lw命令の第2オペランドの実効アドレスを求めよ.
ベースアドレスにオフセットを足し合わせればよい。
ベースアドレス:0x00000100
オフセット:-12 = 0xFFFFFFF4
より 0x0000 0100 + 0xFFFF FFF4 = 0x0000 00F4
(3) 次の疑似命令を実現するMIPSアセンブリ・コードを1行で示せ.
clear $t0($t0をzeroでクリアする)
- add $t0, $zero, $zero
データパス(Datapath)
コンピュータの速度を決める要因:
- 実行命令数
- 命令セット・アーキテクチャ
- コンパイラ
- クロック・サイクル時間
- プロセッサの実装
- 命令当たりのクロック・サイクル数(CPI)
- プロセッサの実装
影响CPU性能的三个方面:时钟频率、CPI、指令的条数
减少指令的条数可以使得CPU更加简洁、使用较少的寄存器,系统代码也会别的更加简洁。例如 RISC-V。底层的指令减少,上层例如操作系统、汇编程序需要编写的代码亦会变多。
但是因为各种指令使用到的频率和周期内不同信息的访问次数,设计CPU是要考虑到优化指令的执行速度,优化高频访问的指令,分配更多的资源。例如X86。
プロセッサの構成
プロセッサは大別してデータパスと制御で構成される
- データパス:演算処理を行う
- 制御:データパスとメモリに指示を出す
データパス要素:プロセッサ内でデータを処理または保持するために使用する機能ユニット
- eg. 命令メモリ、データメモリ、レジスタ、ALU、加算器
MIPSにおけるデータパスの論理要素
- 状態(ステート)を保持する要素
- 何らかの内部記憶を持つ
eg. メモリ、レジスタなど
- 入力に対して何らかの操作を行う要素
- 入力が同じであれば、出力は同じ(内部記憶を持たない)
eg. ANDゲート、ORゲート、ALUなど
クロック方式(clocking methodology)
データが読み出し可能なタイミング、書き込み可能なタイミングの定義
エッジ・トリガ・クロック方式(edge-triggered clocking): クロック波形のエッジでのみ状態論理要素に記憶されている値を更新する方式
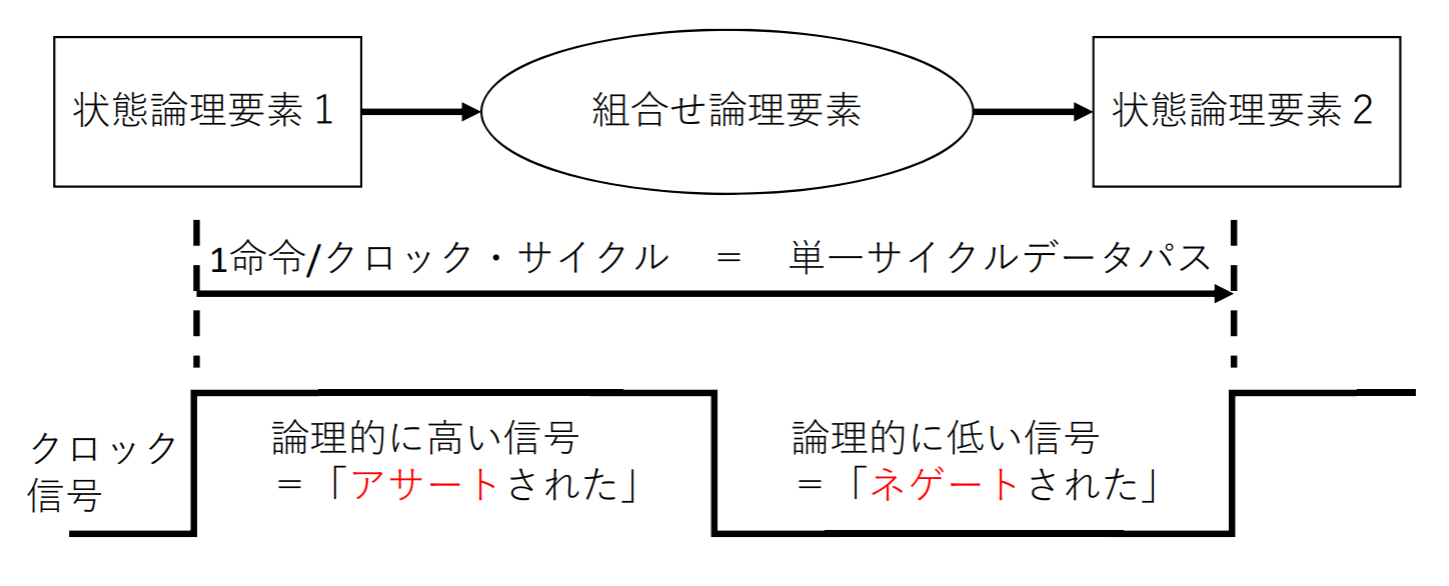
この方式を使うと、レジスタから値を読み出し、何らかの演算を行って、結果はレジスタに書き込むという動作を1クロック・サイクルで実行することができる
The inputs are values that were written in a previous clock cycle, while the outputs are values that can be used in a following clock cycle
MIPS命令のサブセットの実装
実装する命令セット:
- メモリ参照命令:lw、sw
- 算術論理演算命令:add、sub、and、or、slt
- 分岐命令:beq、j
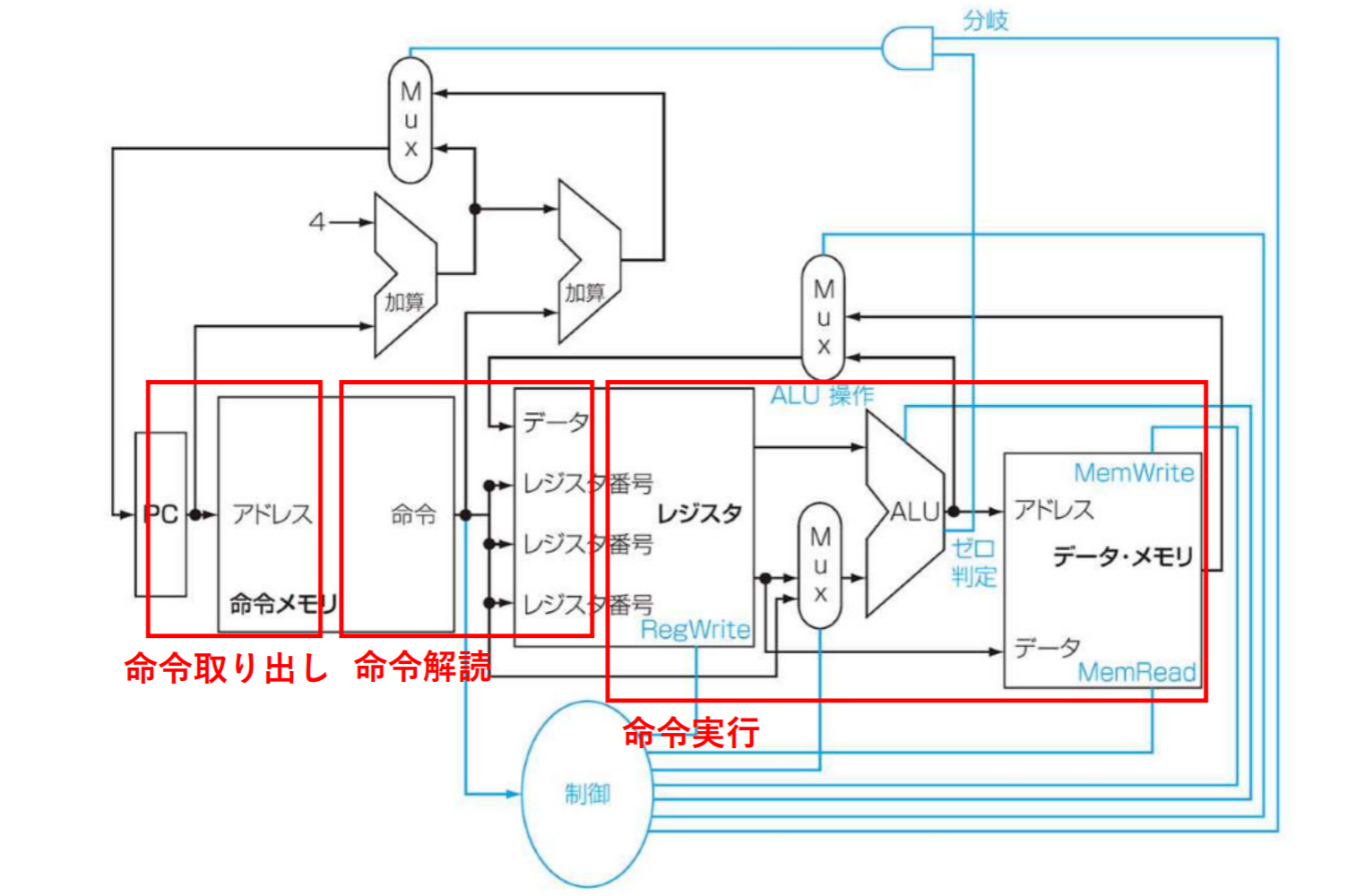
左から: PC(レジスタ)、命令メモリ、レジスタファイル、ALU、データ・メモリ
データパス要素->命令メモリ
実行対象となる命令を格納する
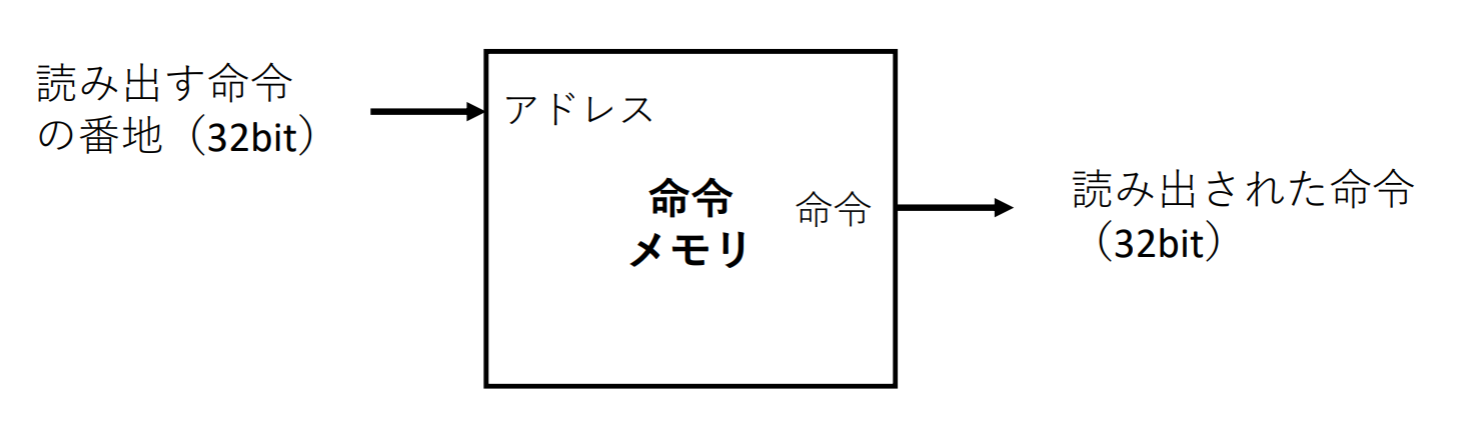
- 命令メモリは読み出し専用でアクセス(データパスが命令メモリに書き込むことはない)
- 常に入力アドレスによって指定された場所の内容を出力する
データパス要素->データメモリ
プログラムの実行で必要となるデータを格納する
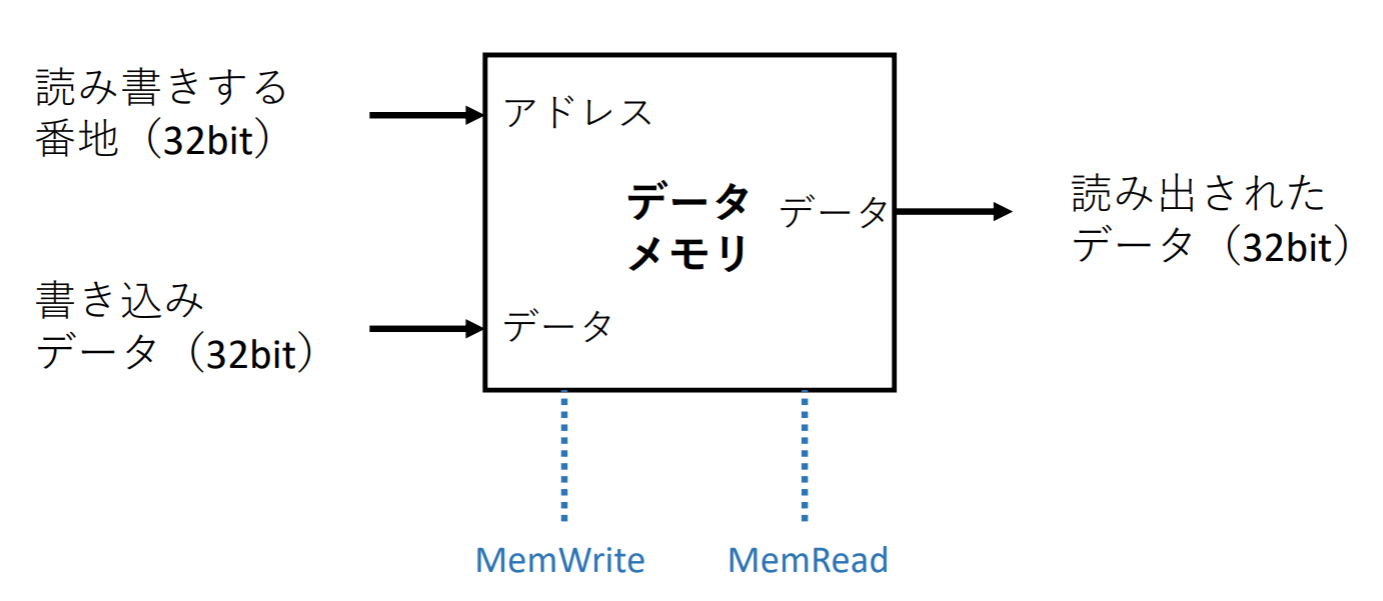
2本の制御信号を持つ:
- MemWrite:書き込み要求(1のとき書き込み)
- MemRead :読み込み要求(1のとき読み込み)
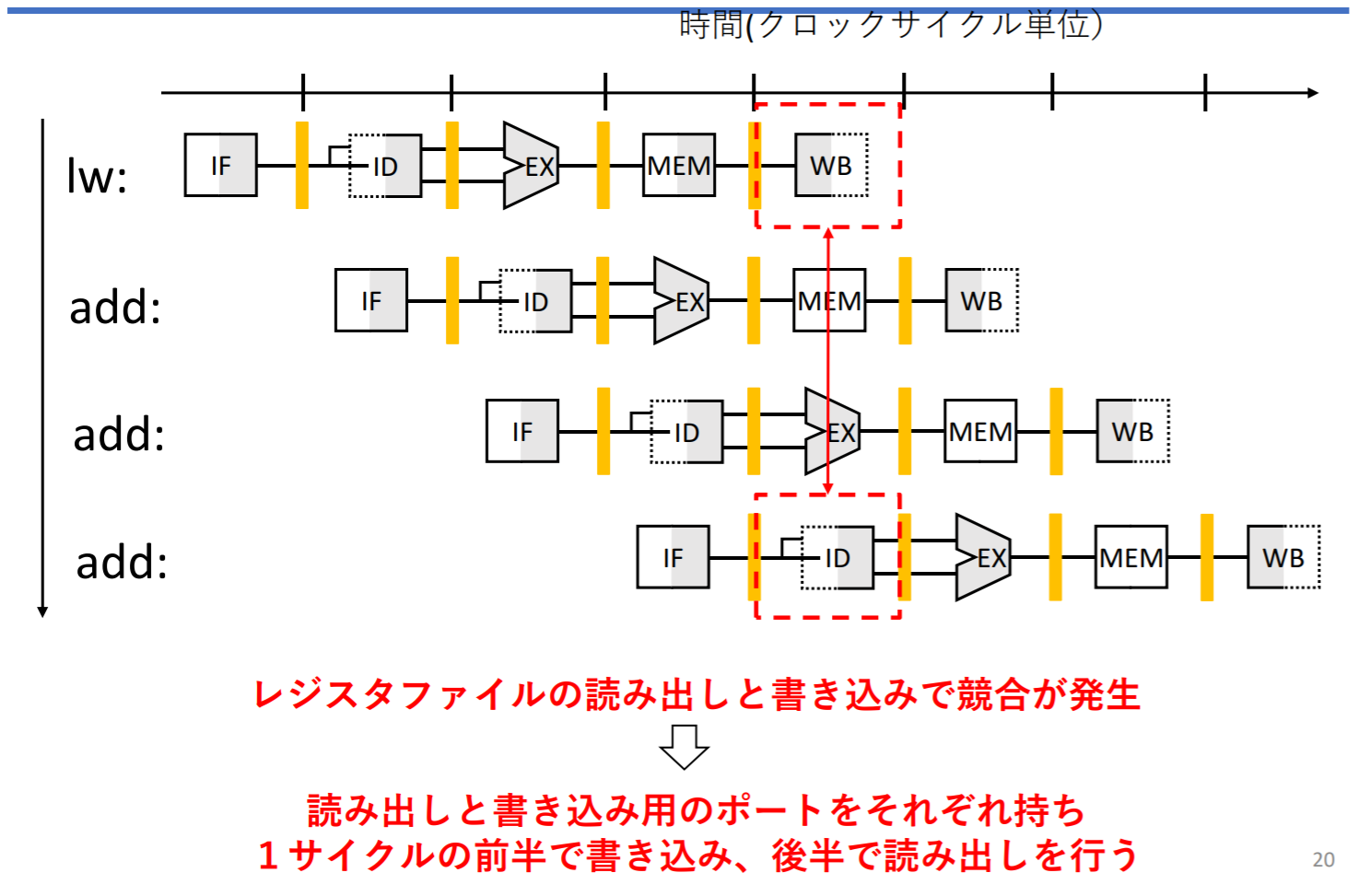
データパス要素->レジスタファイル
複数のレジスタの集合
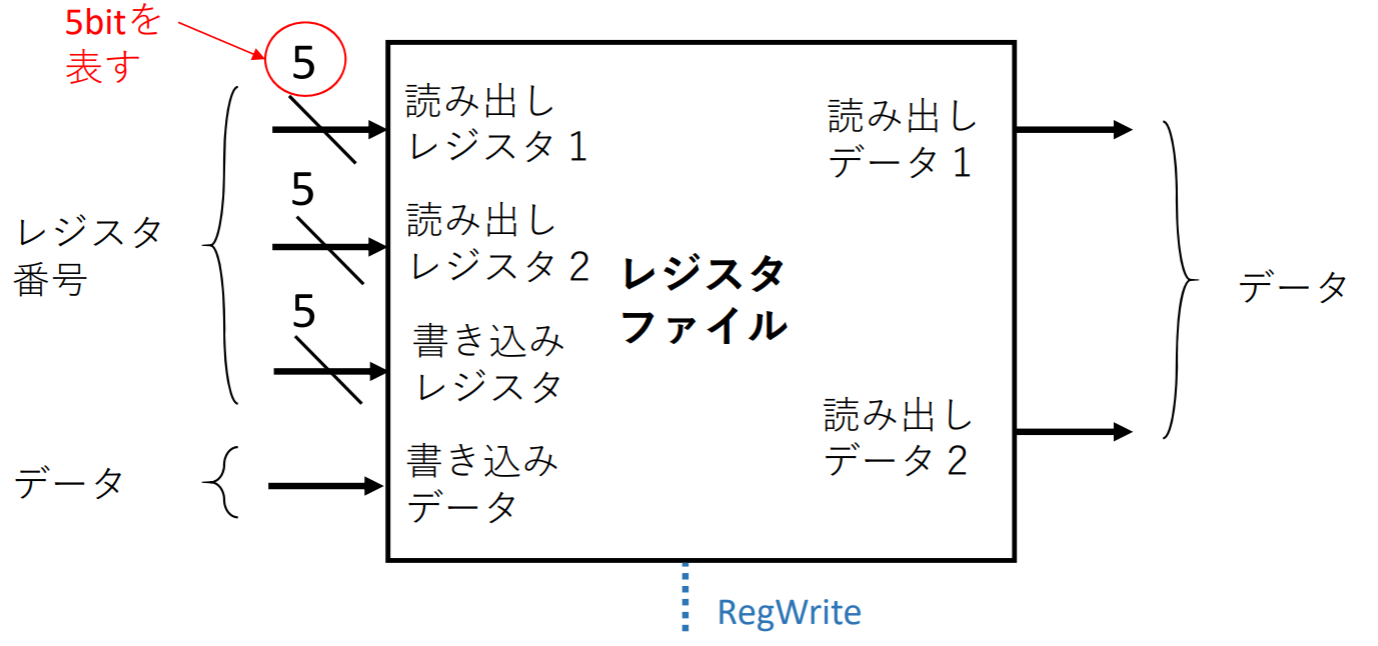
書き込むを行う場合は、制御信号RegWriteがアサートされる必要がある
- レジスタ番号を指定することによって任意のレジスタを読み書きできる
- レジスタの値も保持している
- レジスタファイルは4入力, 2出力になる
- レジスタ番号指定する入力の幅は5bit
- 一方、書き込みデータと読み出しデータのデータの幅は32bit
データパス要素->ALU
指定した算術論理演算を実行する
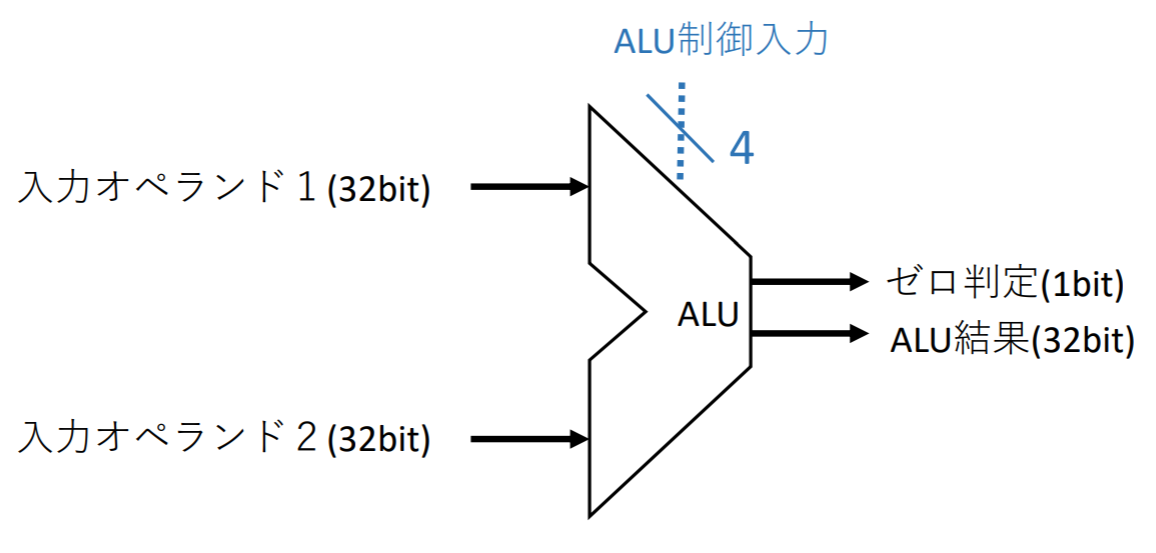
ALU制御入力:
- 0000(AND), 0001(OR), 0010(加算), 0110(減算), 0111(Set on less than), 1100(NOR)
Control logic is used to decide whether the incremented PC or branch target should replace the PC, based on the Zero output of the ALU.
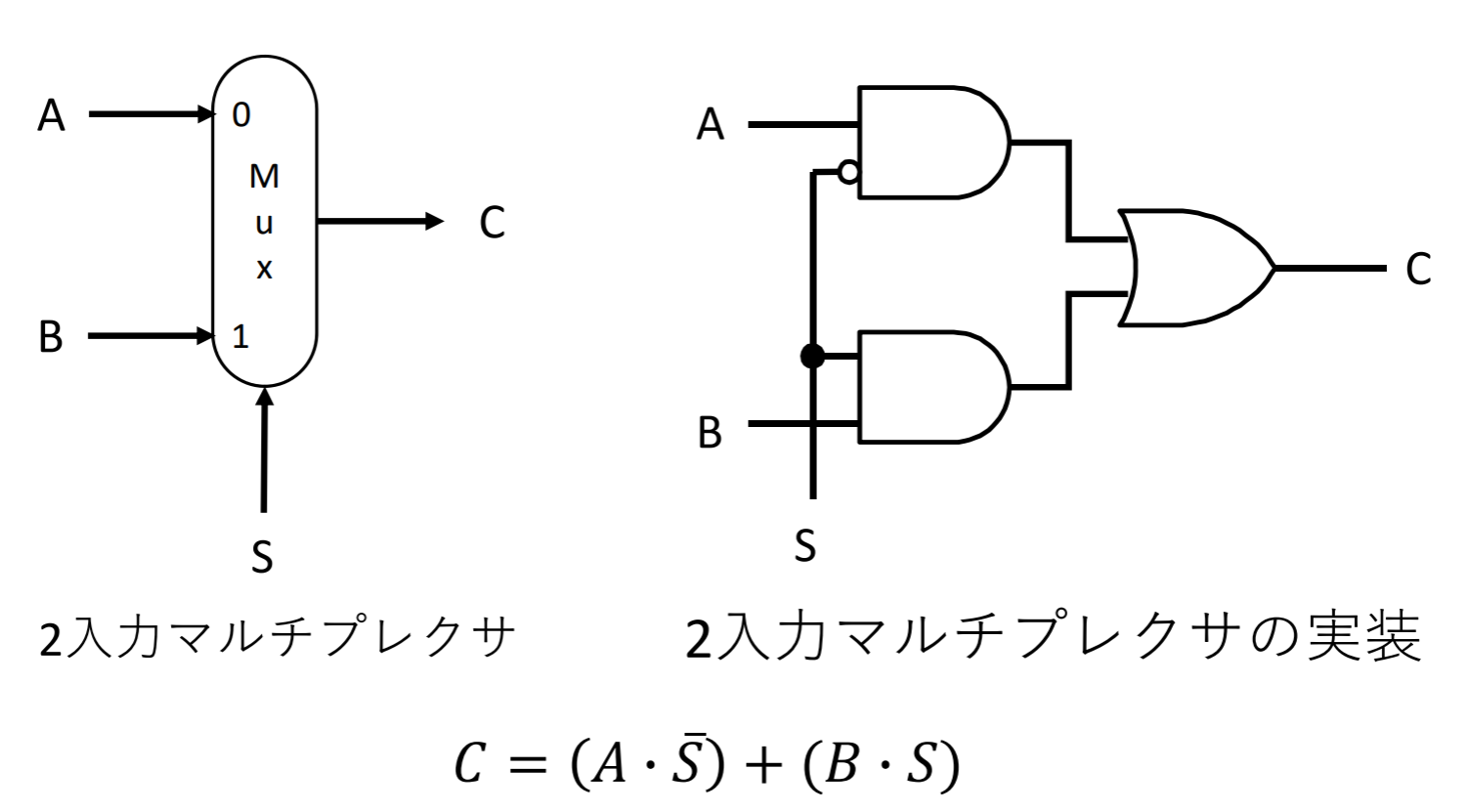
マルチプレクサ(multiplexor)
いくつかの入力の中から⼀つを制御で選択したもの
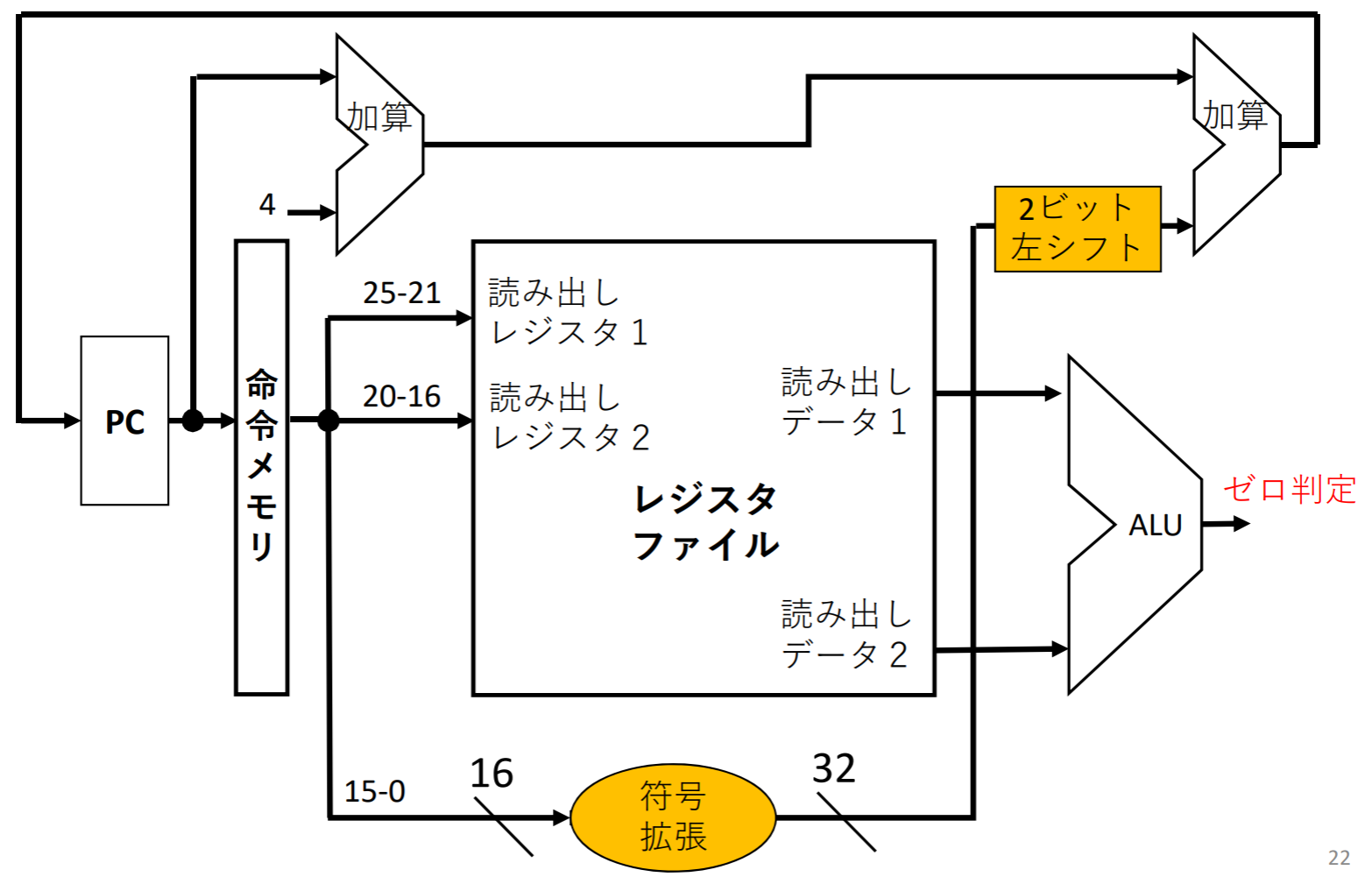
命令の取り出し
PC、命令メモリ、ALUで実装
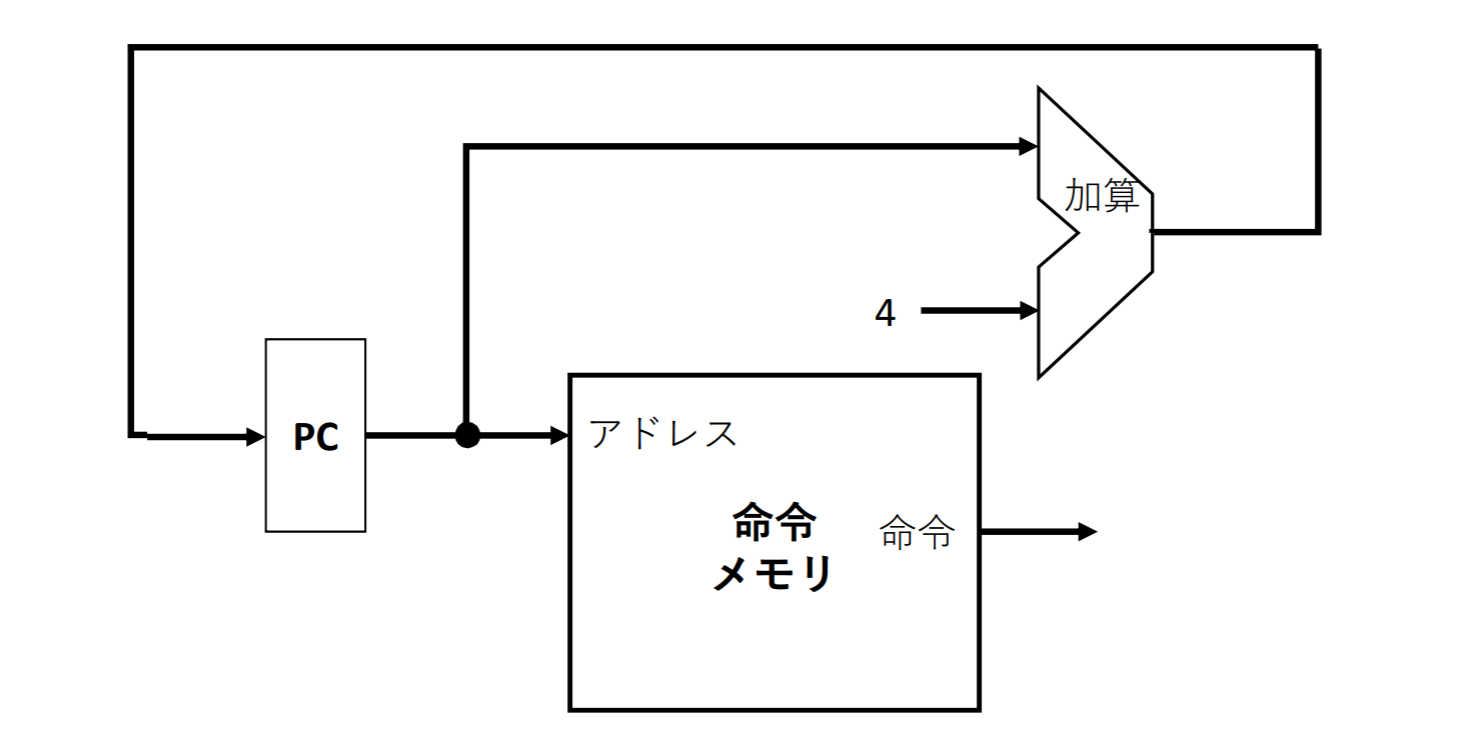
- プログラムカウンタ(PC)は次に実行する命令のアドレスを保持する
- 加算器は加算専用のALUであり、次の命令を指すために4バイト加算する
- 命令の読み出し(フェッチ)と同時にPC繰り上げを行う
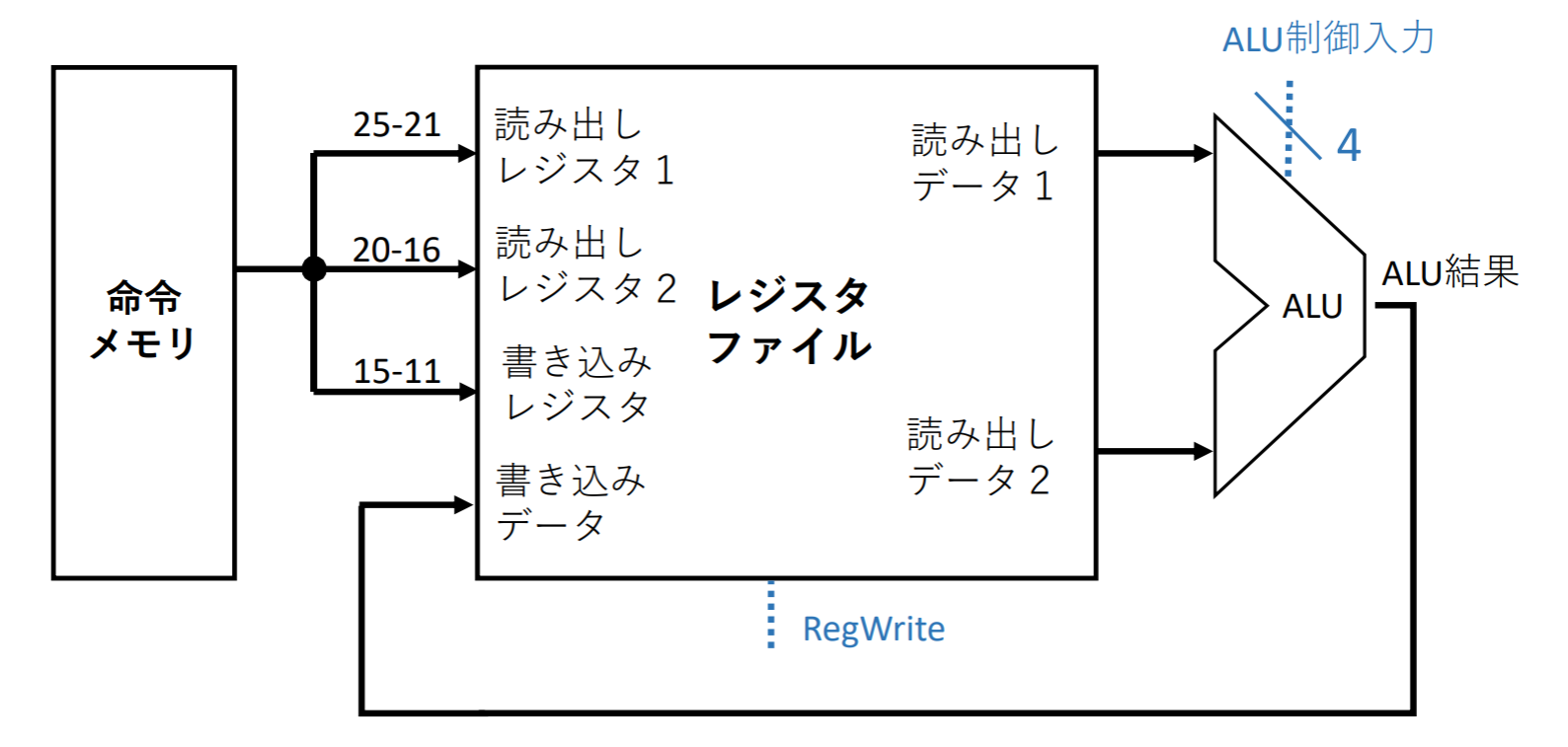
命令の実行(Rフォーマット)
レジスタファイルとALUで実装
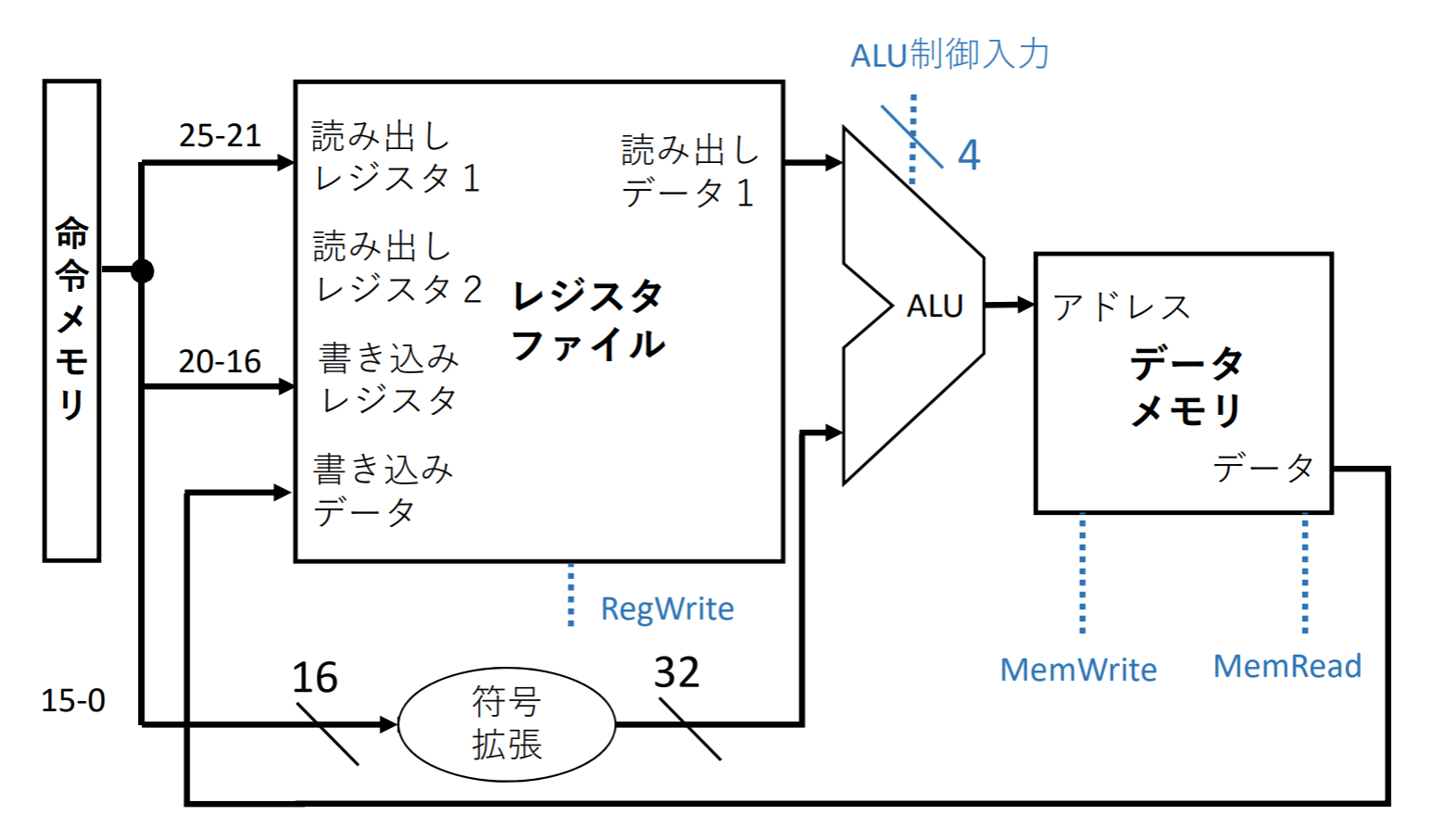
ロード/ストア命令(Iフォーマット)
レジスタファイルとALUで実装
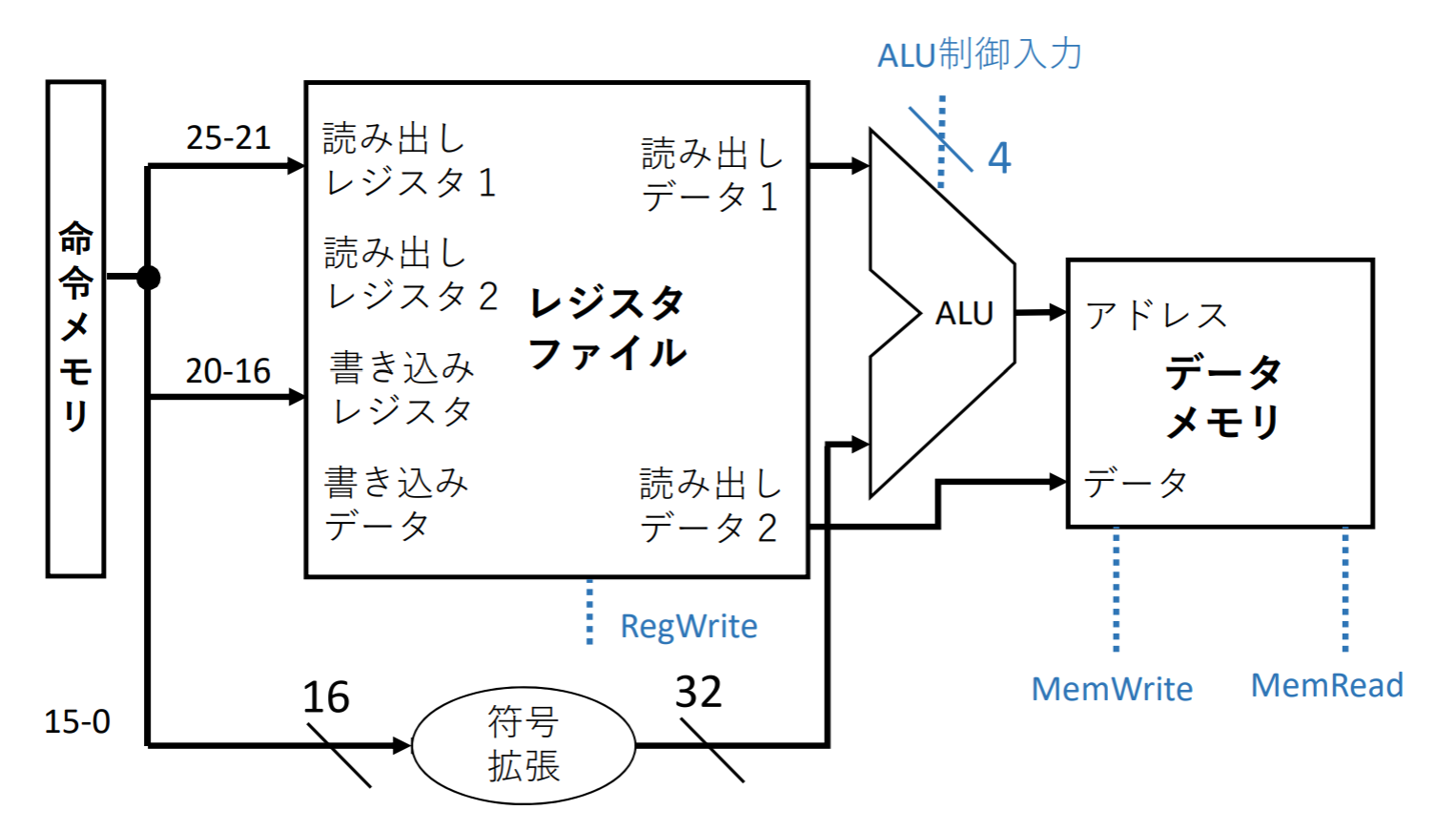
分岐命令(beq)
課題5.1
- MemtoRegはデータをメモリからレジスタファイルに送るように設定しなければならない
- MemtoRegの設定は考慮する必要がある
ALU制御ユニットの設計
ALU制御入力:
- 0000(AND)
- 0001(OR)
- 0010(加算)
- 0110(減算)
- 0111(Set on less than)
- …
load/store命令ではメモリアドレスのに計算にALUが使われるように、各命令でALUはこの五つの機能をどれか一つが実行される
命令が決まるとALUのどの機能を使われるかを分かるので、制御信号も決まる
具体的には、ALUの制御信号は命令の機能コード(funct)制御フィールドから作られる
- 機能コード:Rフォーマット下位6bit
- 各命令の5‐0ビット(6bit)
- ALUOp
- 主制御ユニットで生成される2bitの制御コード
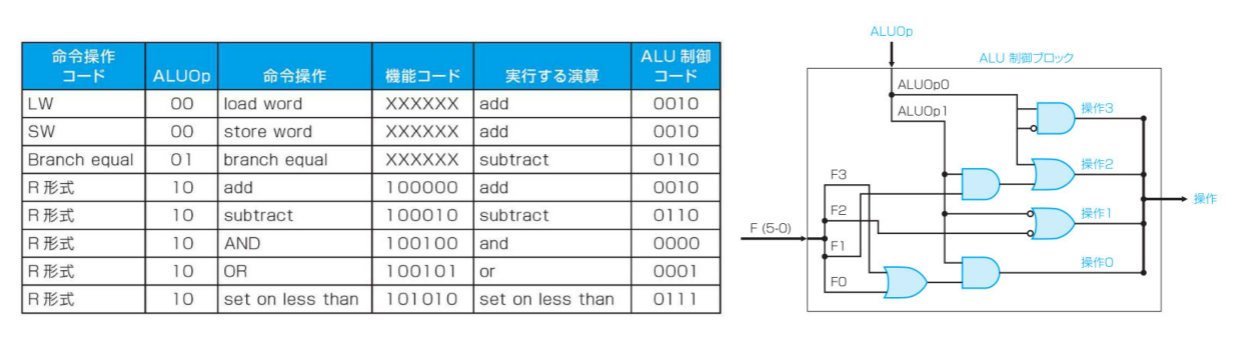
- LW, SWはIフォーマットなので、機能コードがないが、ALUOpのみからALU制御コードから作られる
- ALUOpコードが00:加算
- ALUOpコードが01:減算
- ALUOpコードが10:機能フィールドに応じた演算に対応するALU制御入力が生成される
- 何故ALU制御ユニットを主制御ユニットと別に用意するか?
- 小さな制御ユニットを複数に用意するとはよく行われている。速度の向上を繋がるために、行われることが多い
主制御ユニットの設計

-
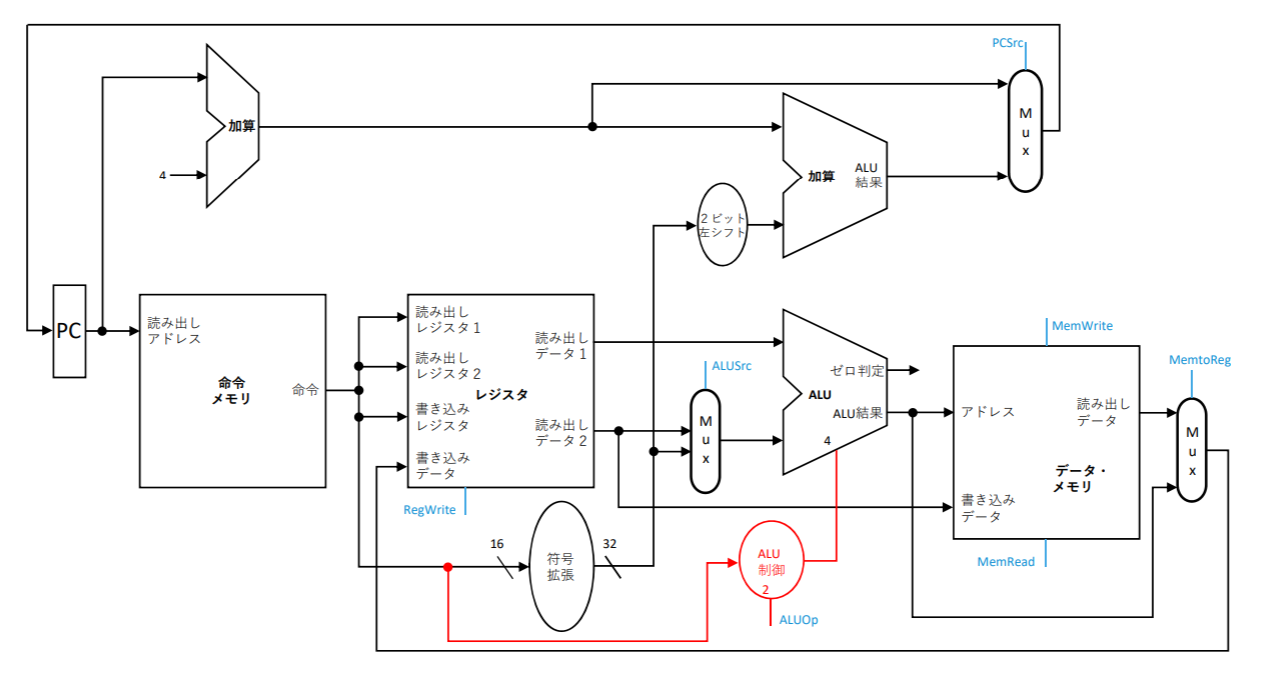
命令操作コードは常にopで指定される(opcode is always contained in bits 31:26)
-
2つの読み出しレジスタは常にrs,rtで指定される
-
ロード/ストア命令のベース・レジスタはrsで指定される
-
branch equal(beq)、ロード/ストアのオフセットはビット15‐0で指定される(The 16-bit off set for branch equal, load, and store is always in positions 15:0)
-
書き込みレジスタは、次の二か所で指定される
- Rフォーマット:rd(ビット15‐11)
- ロード命令:rt(ビット20‐16)
- マルチプレクサによる切り替えが必要
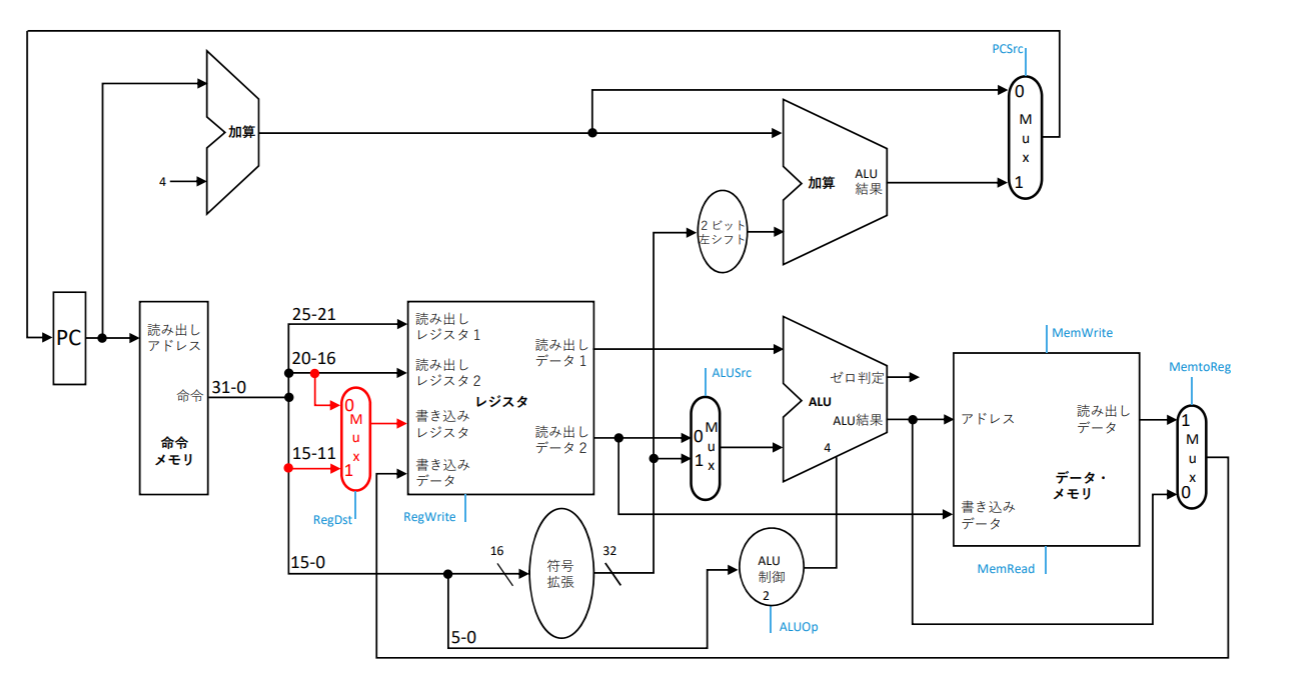
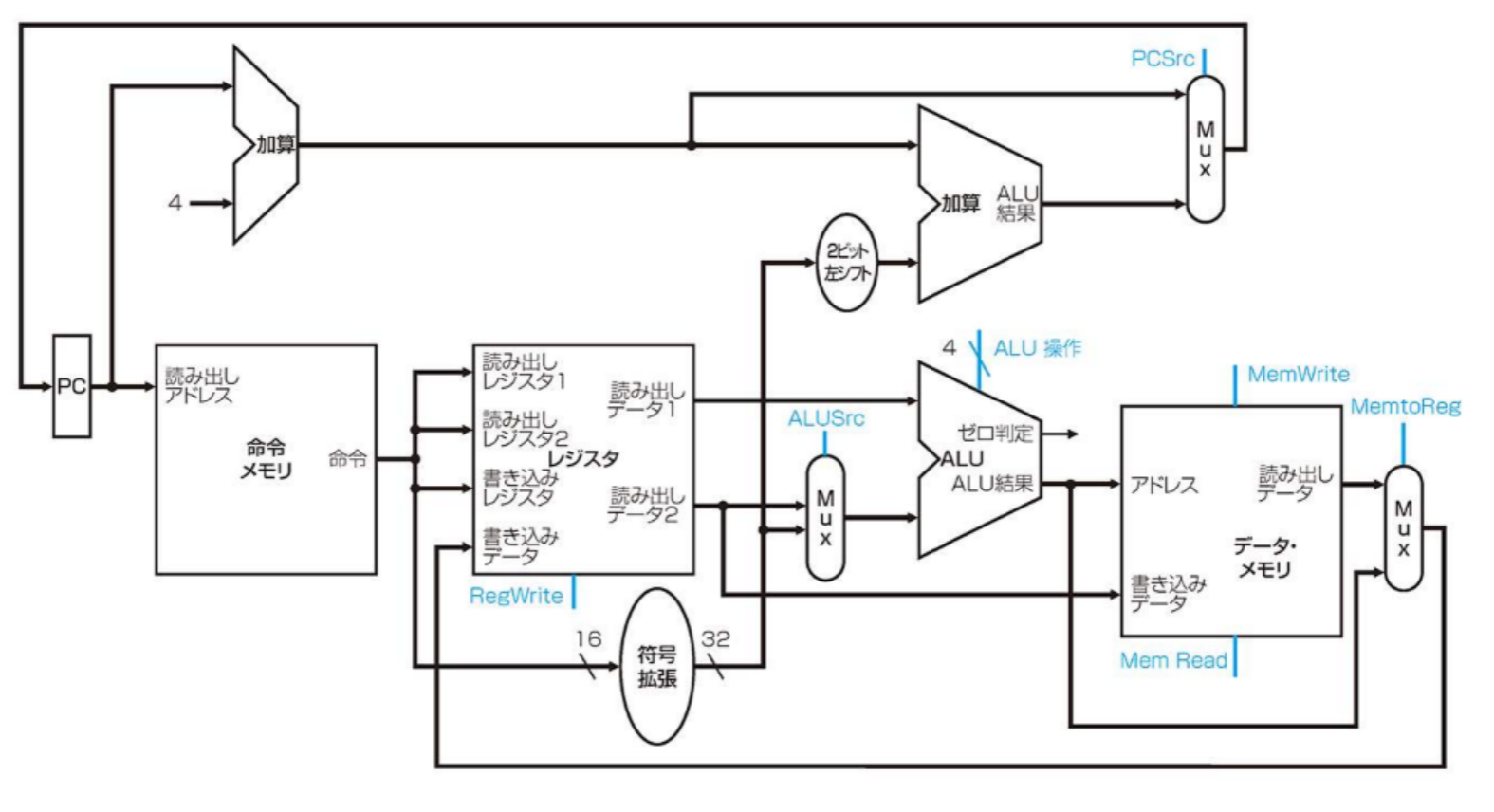
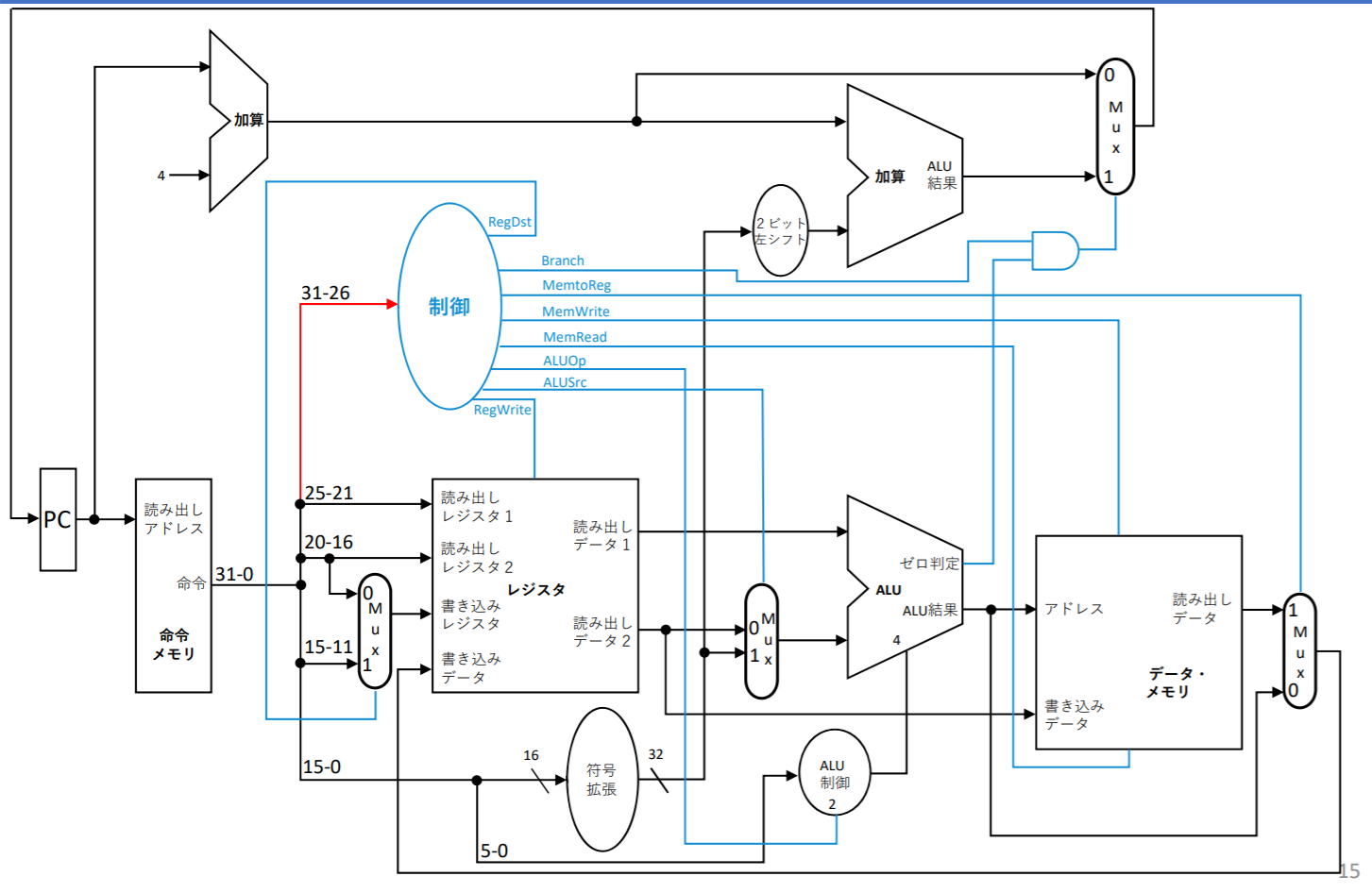
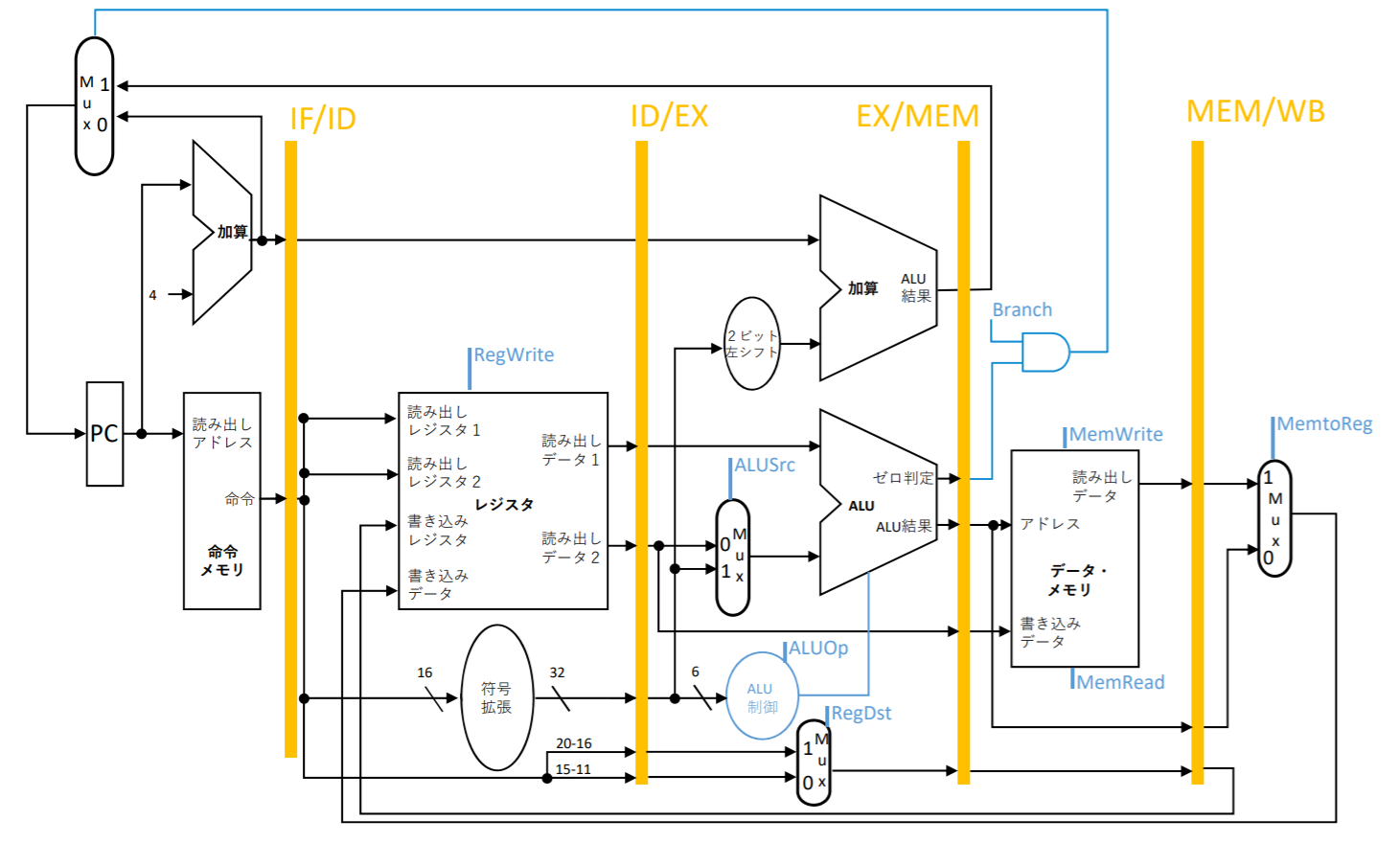
制御信号の役割
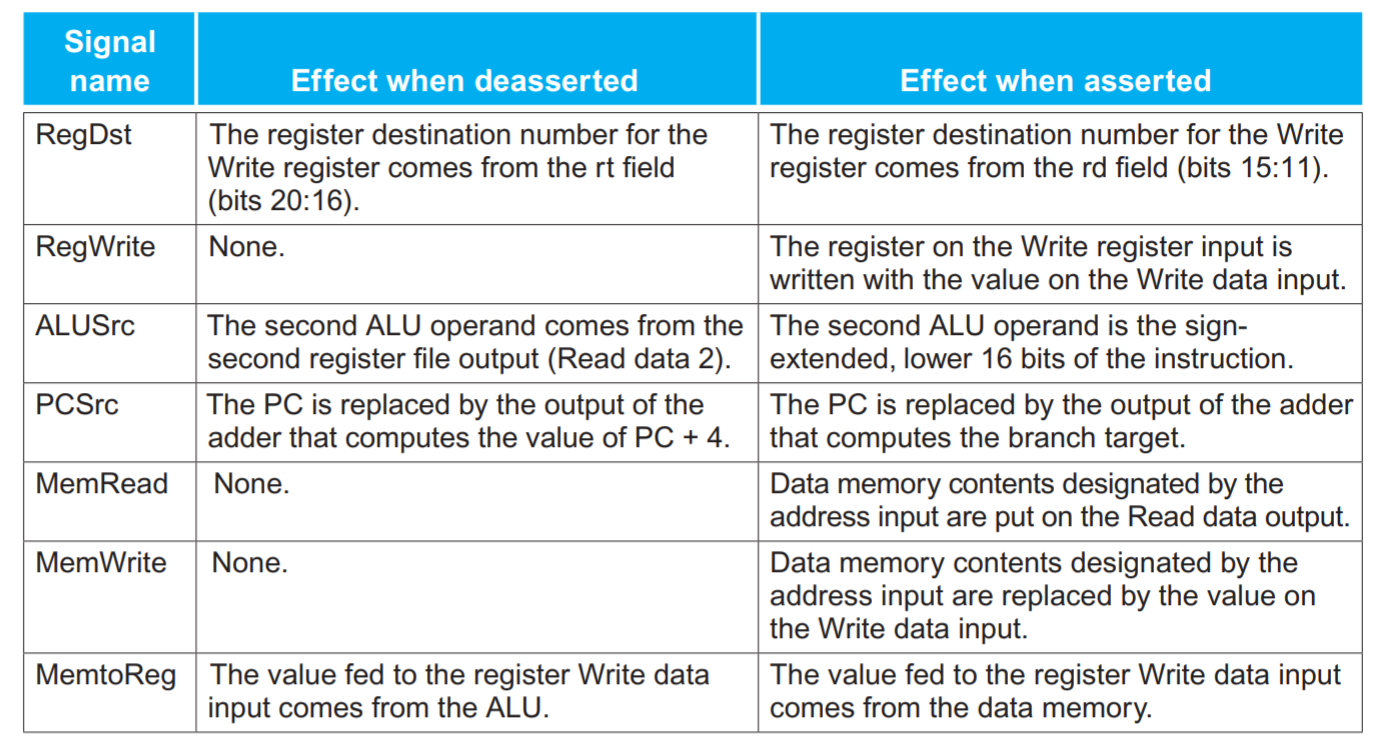
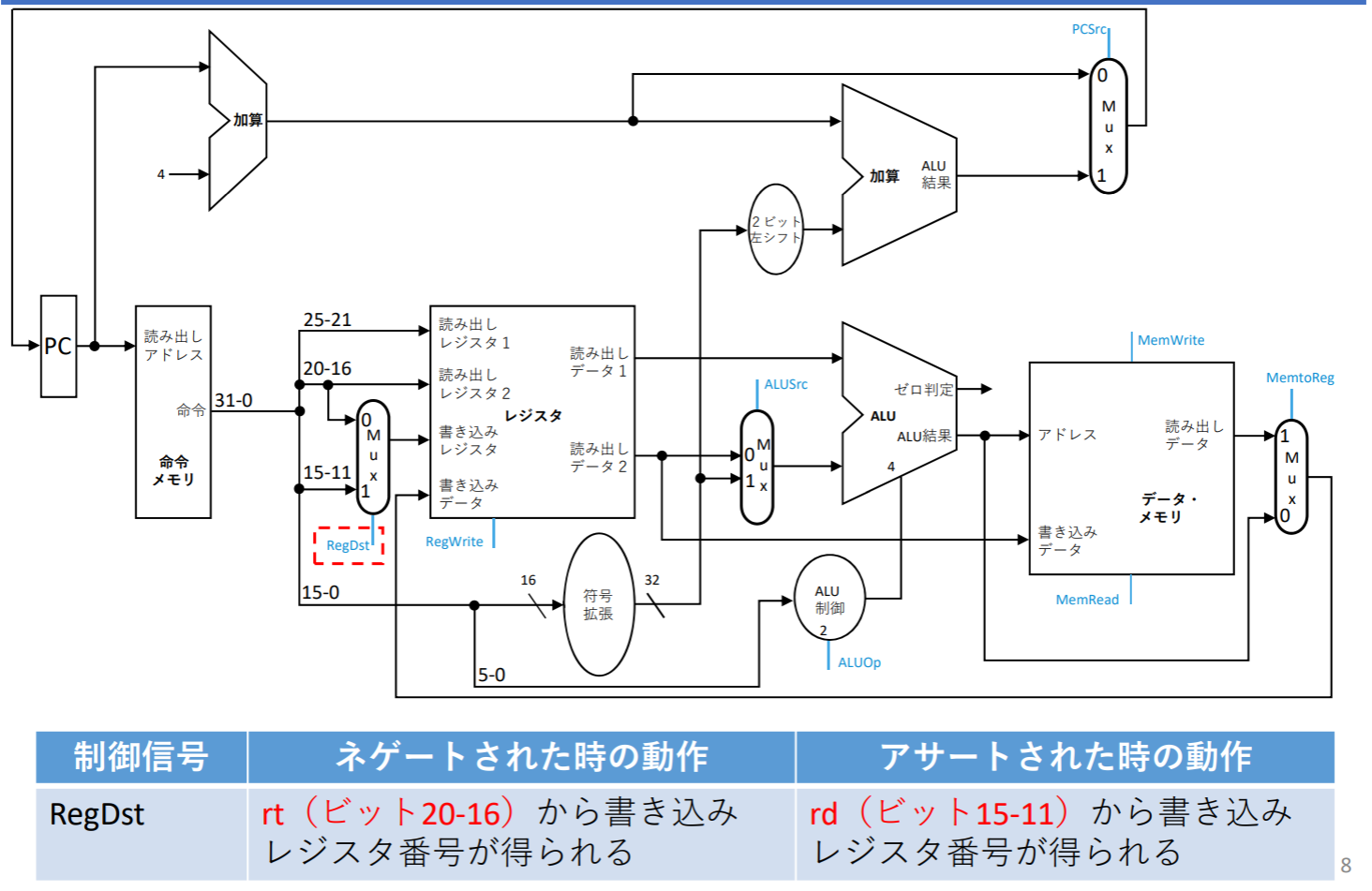
RegDst
RegWrite
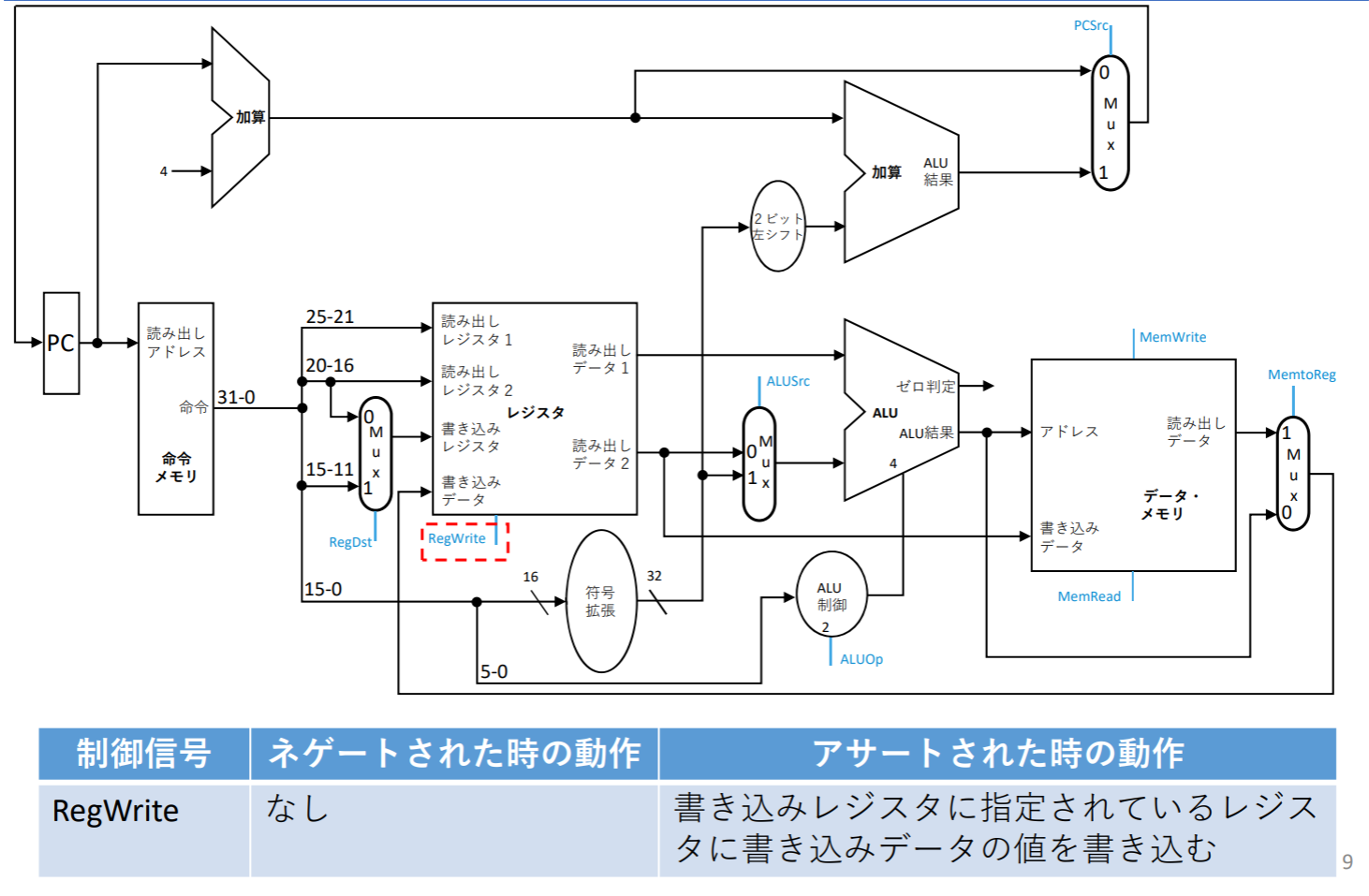
- 書き込むタイミングはクロックで決まる
ALUSrc
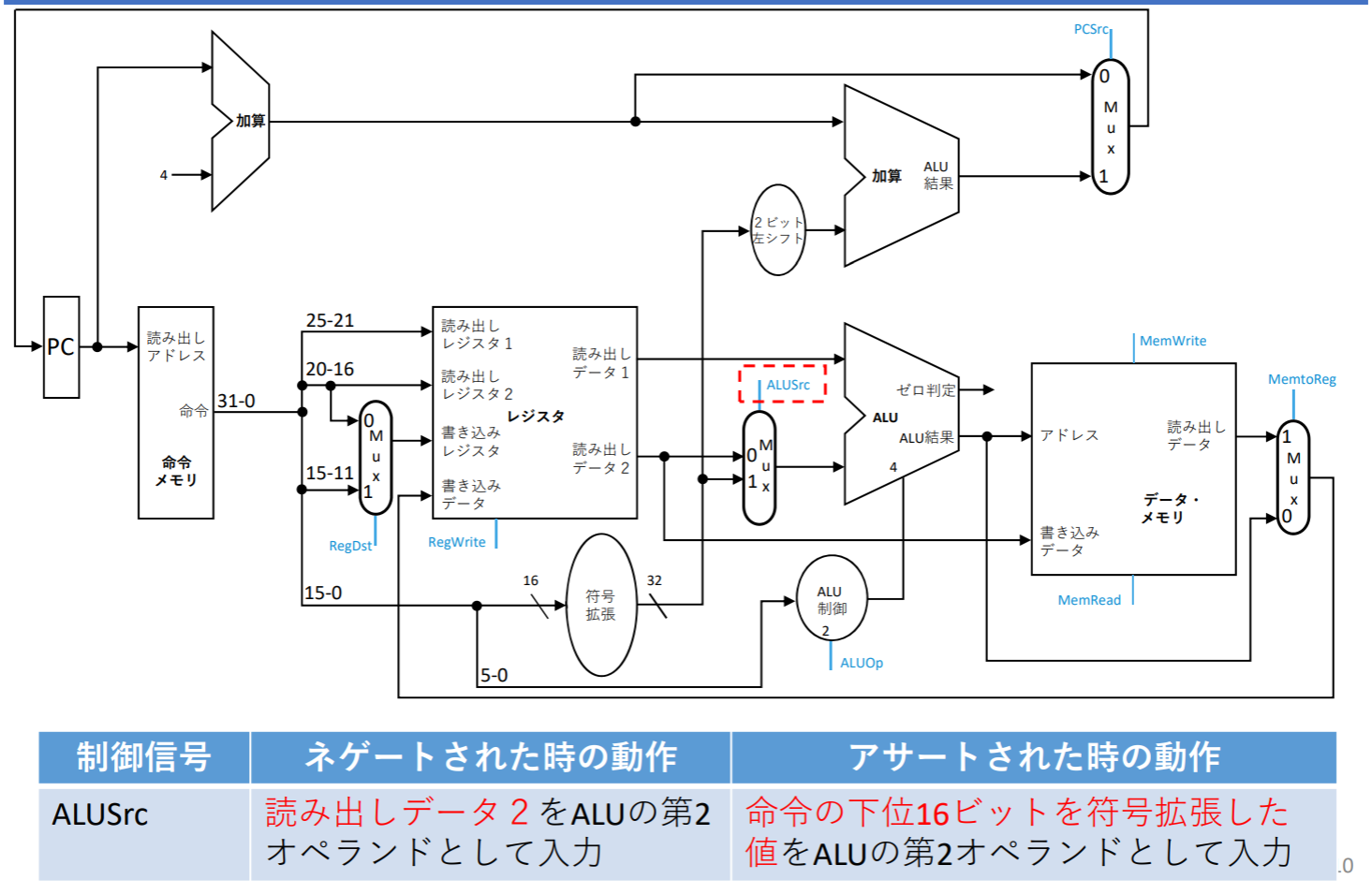
- ALUSrcは、Iフォーマットのアドレス計算や即値を用いた演算で使われる(lw)
PCSrc
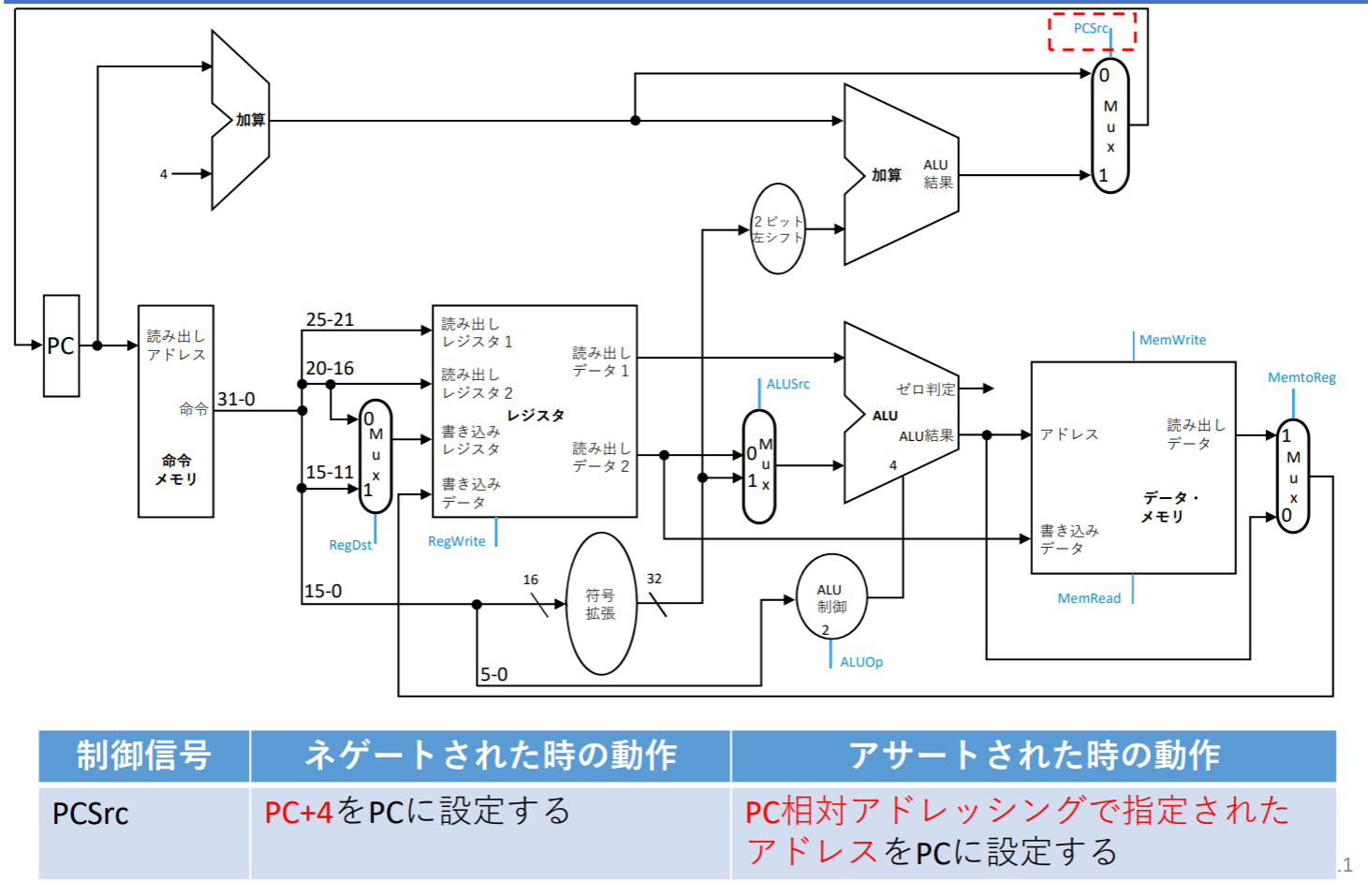
- PCSrcは条件分岐命令で使われる(beq)
MemWrite/MemRead
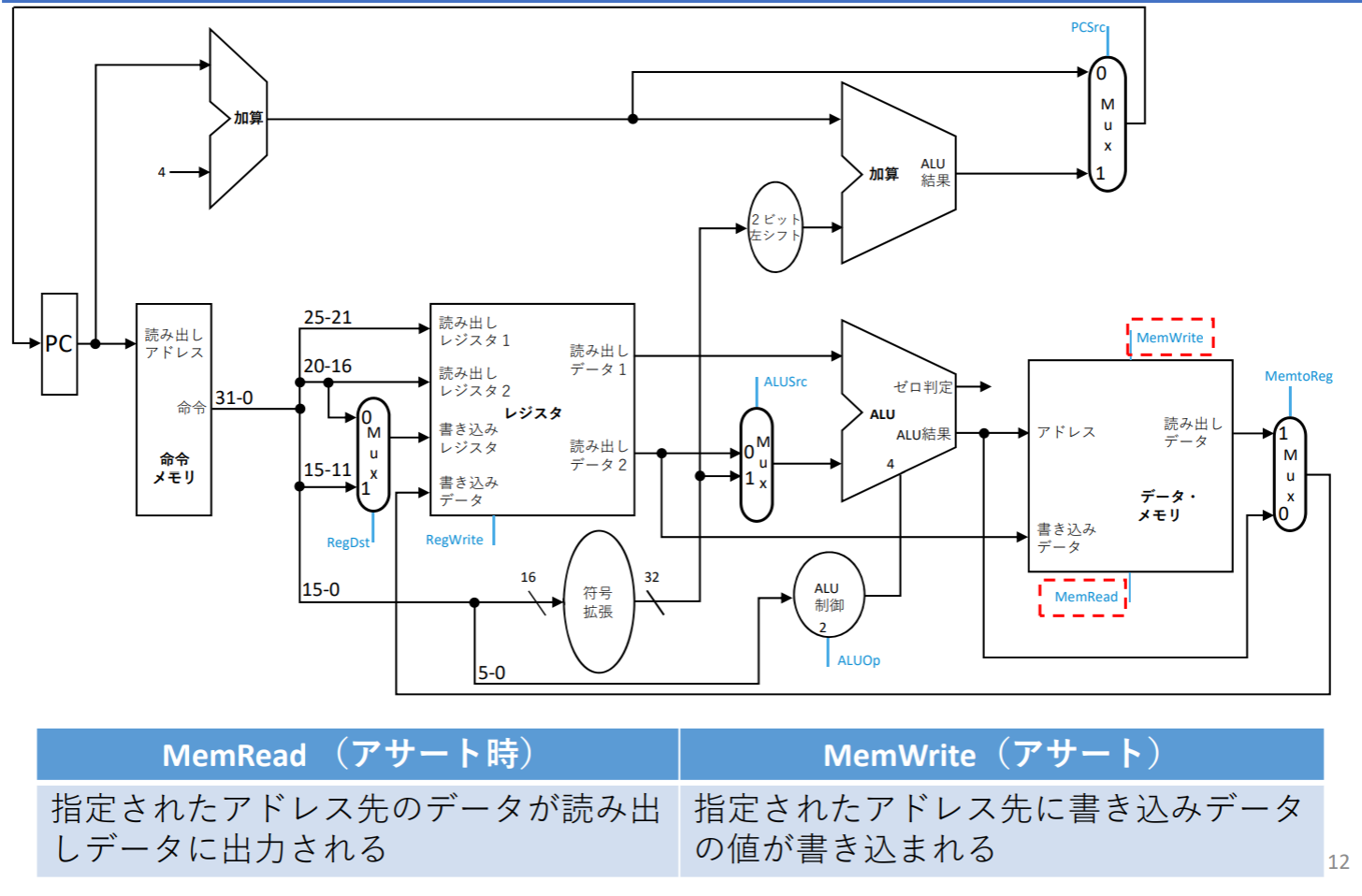
MemtoReg
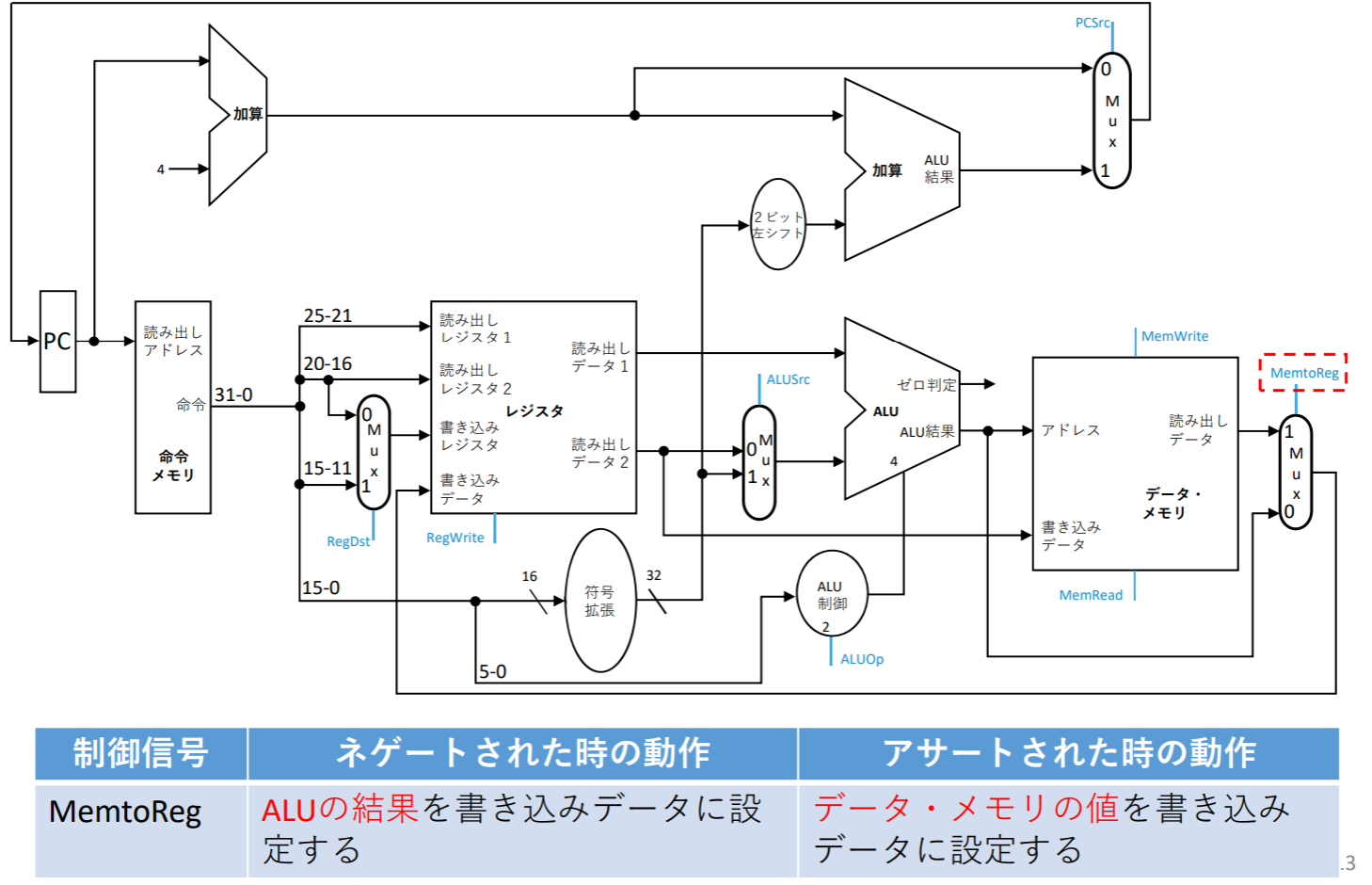
- MemtoRegはメモリから読みだしたデータをレジスタに書き込むときに使われる(lw)
制御信号の設定
上は8本の制御線について説明したが、この制御線の値は何を見て決めれば良いでしょうか?
制御線の値は命令操作コードを用いることで決定できる
| 命令(OP) | RegDst | ALUSrc | MemtoReg | RegWrite | MemRead | MemWrite | Branch(PCSrc) | ALUOp1 | ALUOp0 |
|---|---|---|---|---|---|---|---|---|---|
| R形式(000000) | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| lw(100011) | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| sw(101011) | X | 1 | X | 0 | 0 | 1 | 0 | 0 | 0 |
| beq(000100) | X | 0 | X | 0 | 0 | 0 | 1 | 0 | 1 |
- R形式(add、sub、and、or、slt)
- functからALU制御信号が生成される
- rdが書き込みレジスタに設定され、演算結果が書き込まれる
- lw/sw
- アドレス計算を行うようにALUが設定される
- beq
- Branch、ゼロ判定出力がアサートされていれば分岐先アドレスをPCに設定する
Rフォーマットのデータパス
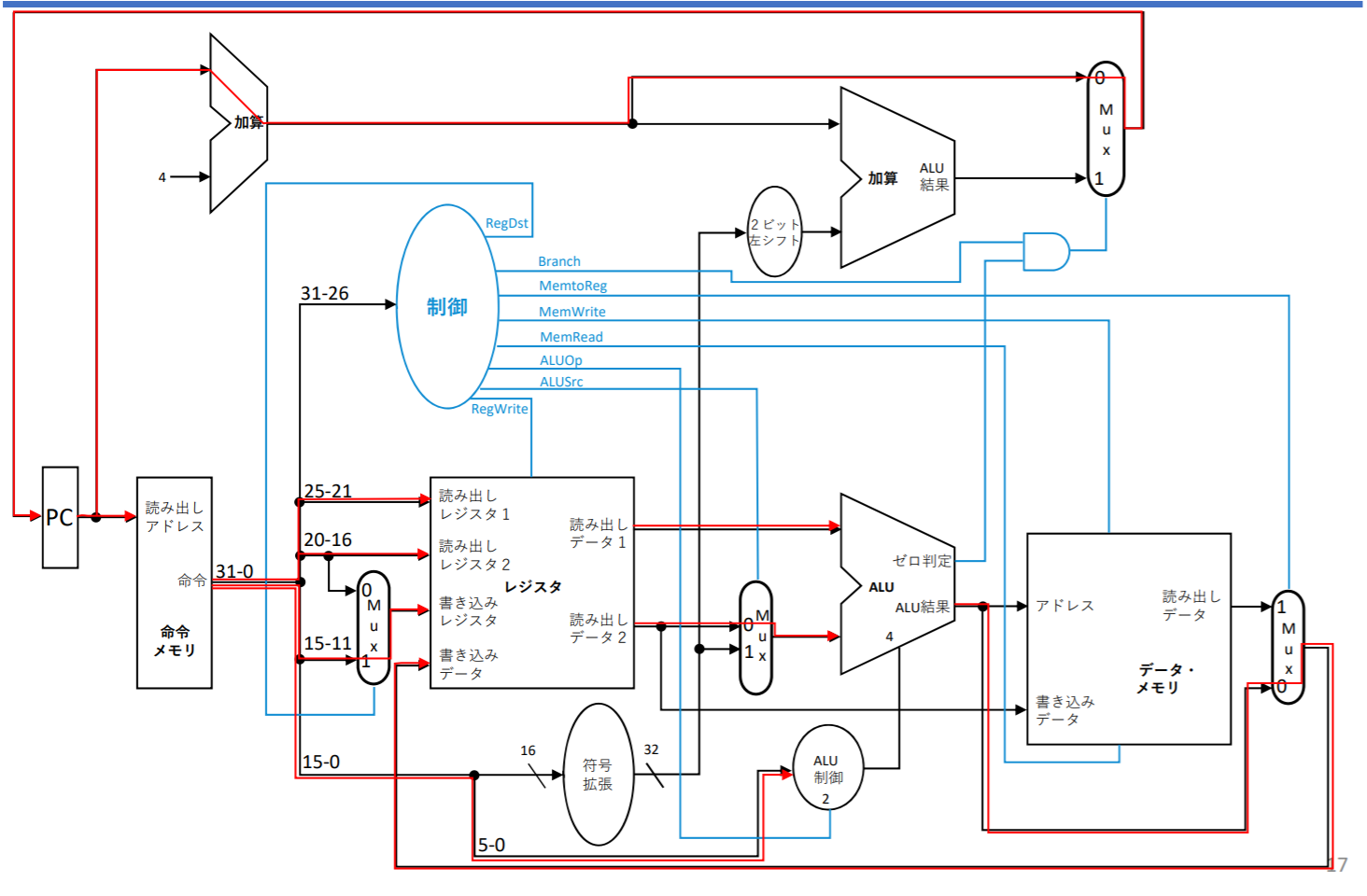
ロード命令のデータパス
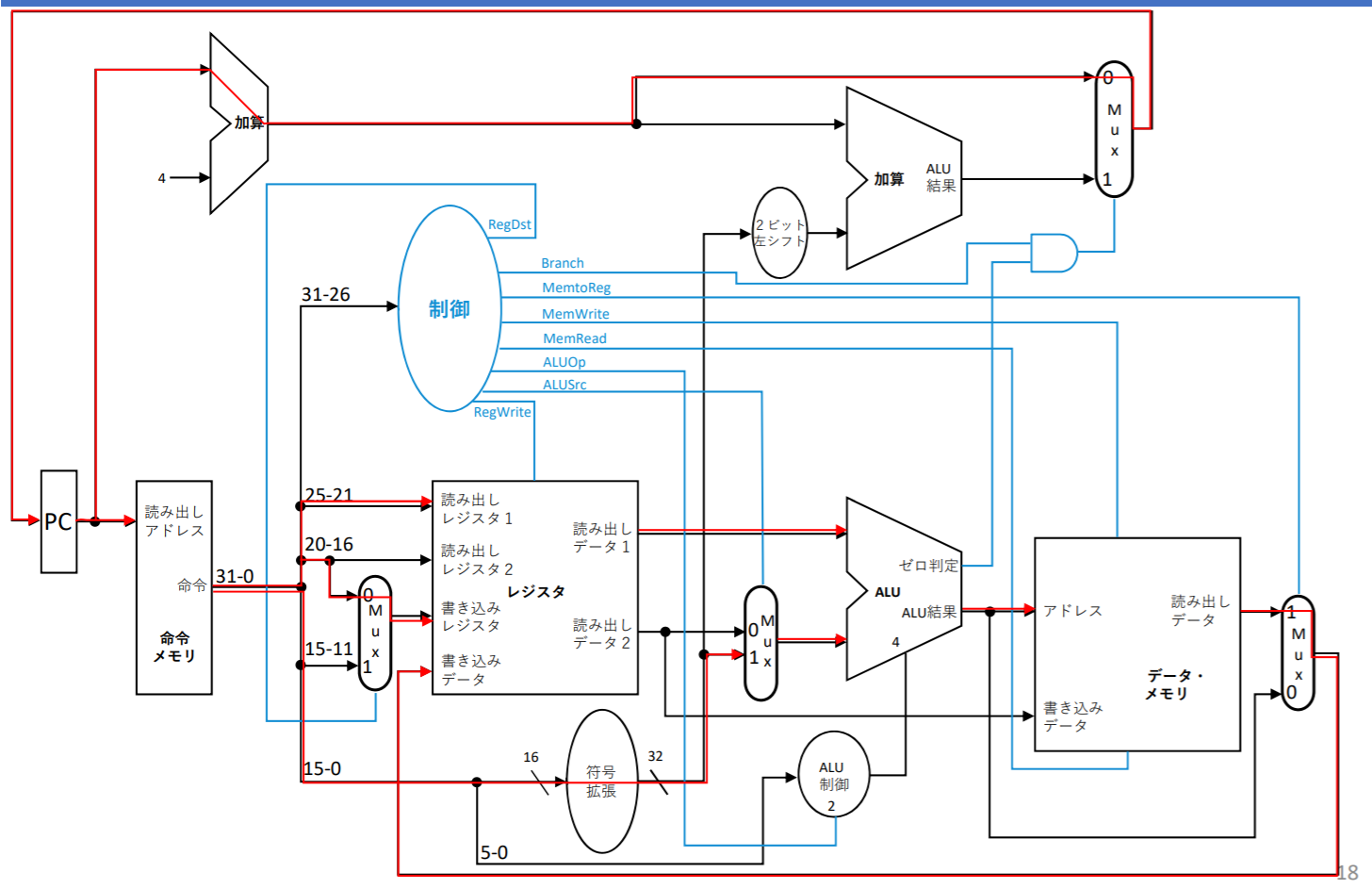
ストア命令のデータパス
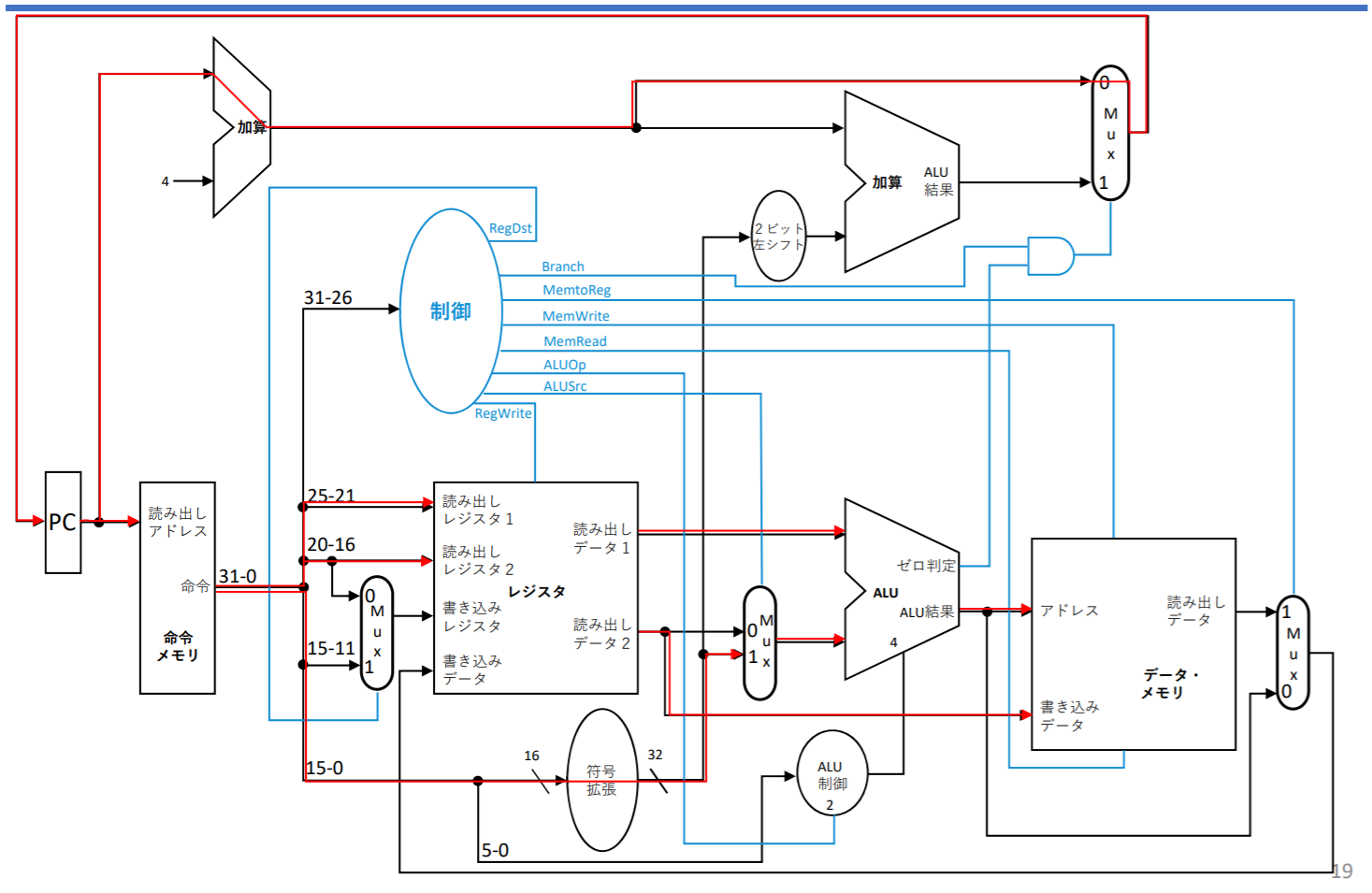
beq命令のデータパス
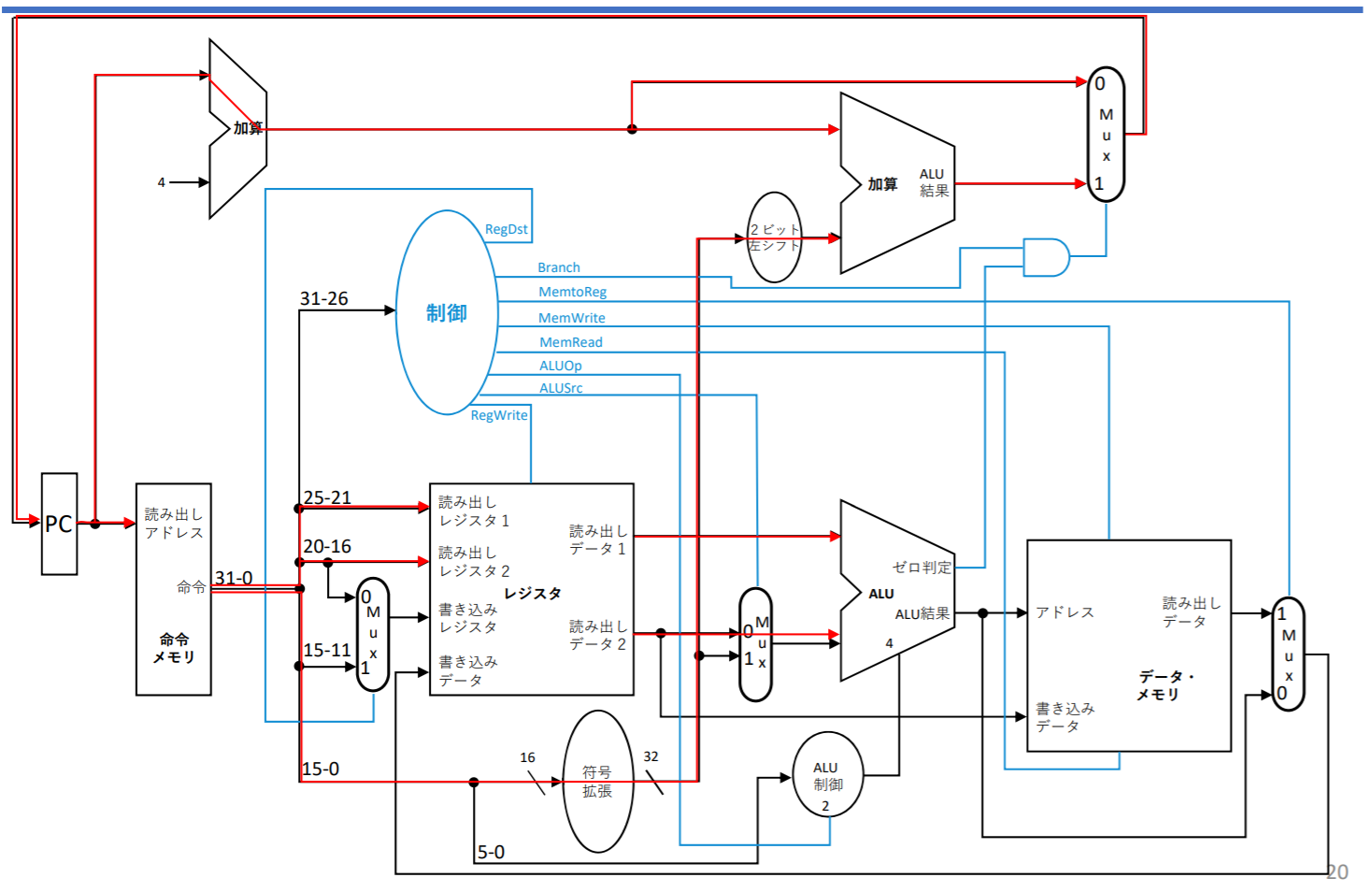
ジャンプ命令(j)の実装
- 疑似直接アドレシング
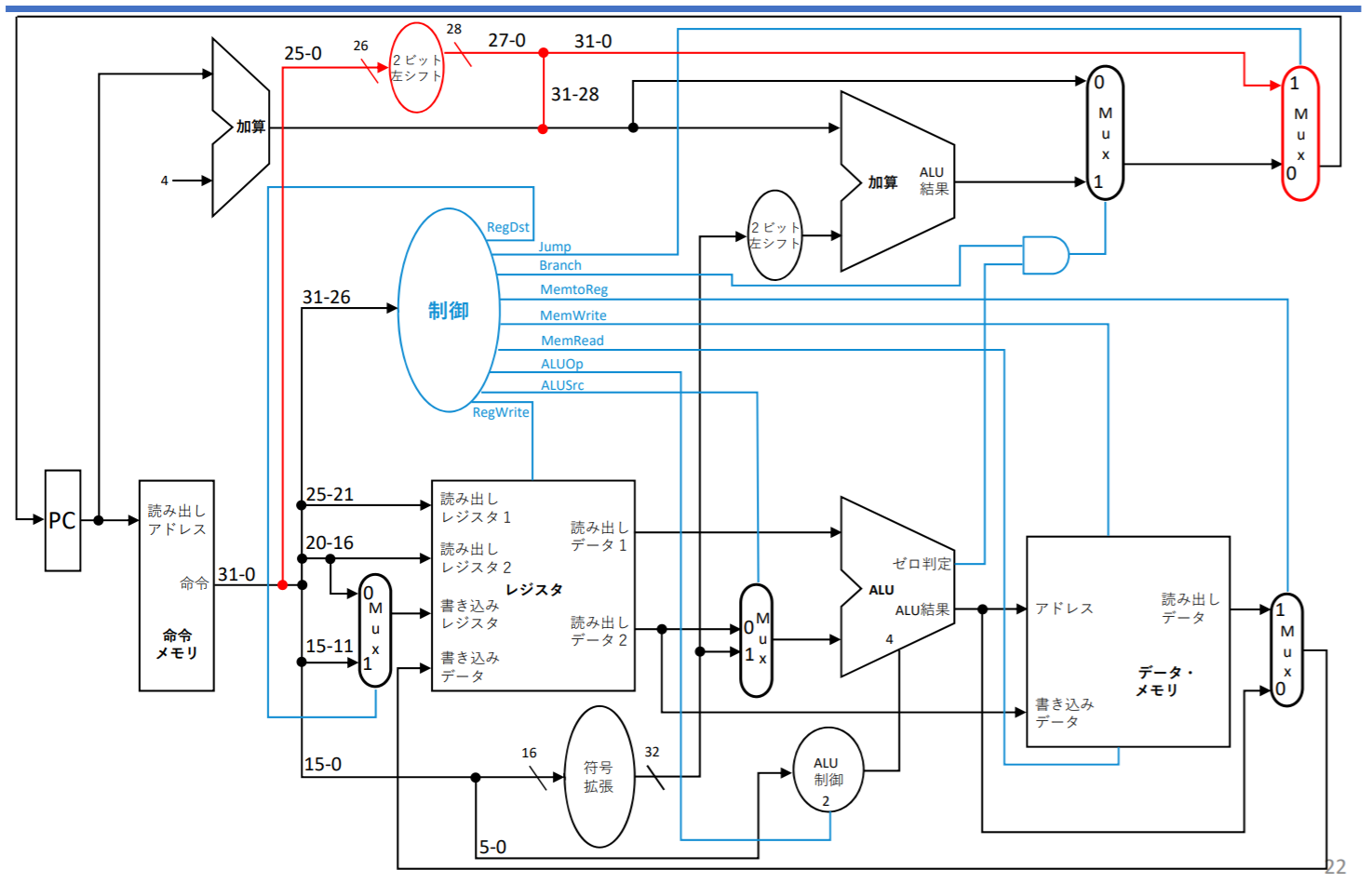
単⼀サイクル・データパスの問題点
- 命令によってデータパスの長さが異なる
- クロック・サイクルは最長パスに合わせなければなければならないため、効率が悪い
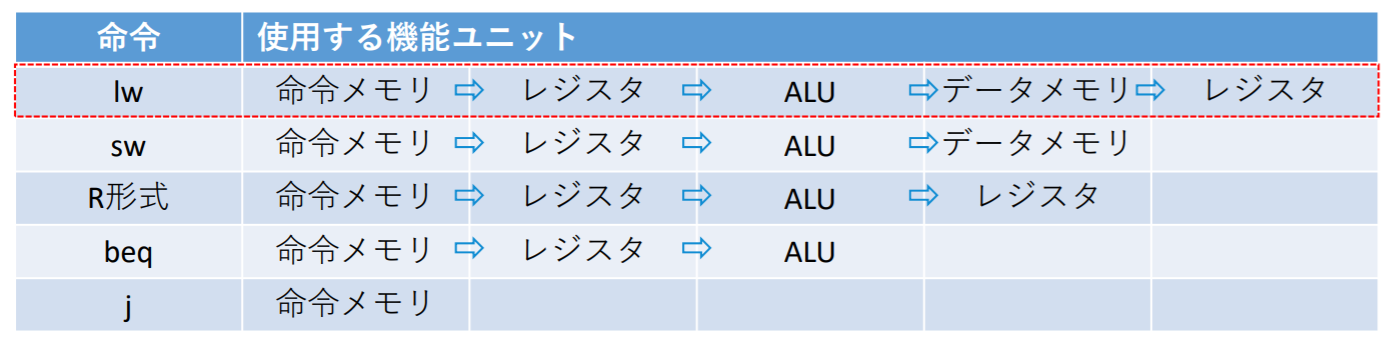
パイプライン(Pipeline)
パイプライン処理: 複数の命令を少しずつずらして同時並行的に実行する実装方式
MIPSの場合, 命令の実行は最大5ステップ(=ステージ)を要する
- メモリから命令をフェッチする
- 命令をデコードしながらレジスタを読み出す
- 命令操作の実行またはアドレスを生成する
- メモリ中のデータにアクセスする
- 結果をレジスタに書き込む
それぞれのステージが単⼀サイクル・データパス上でどこに対応するかを見てくる
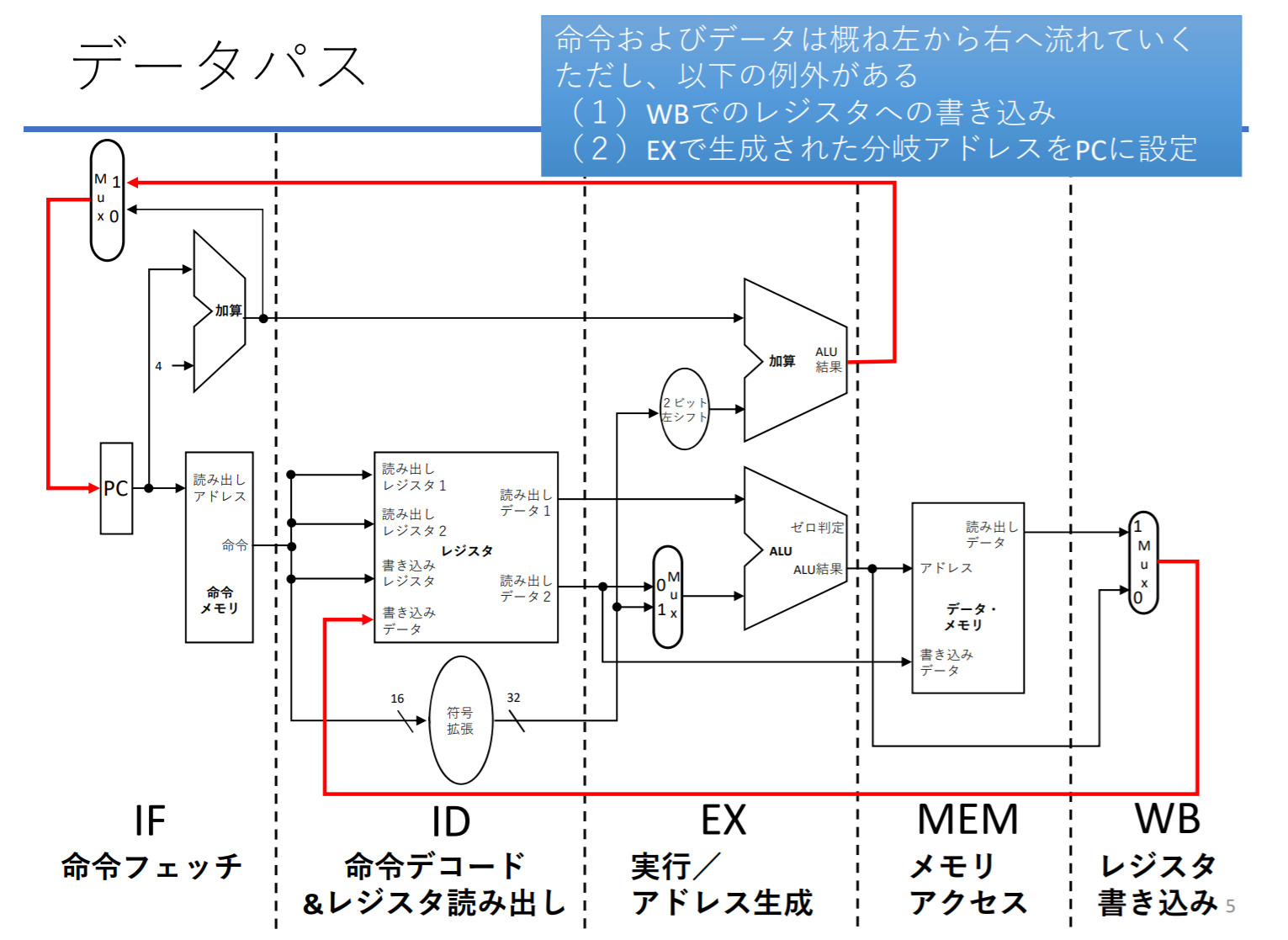
データパスの模式図
5つのステージからなる
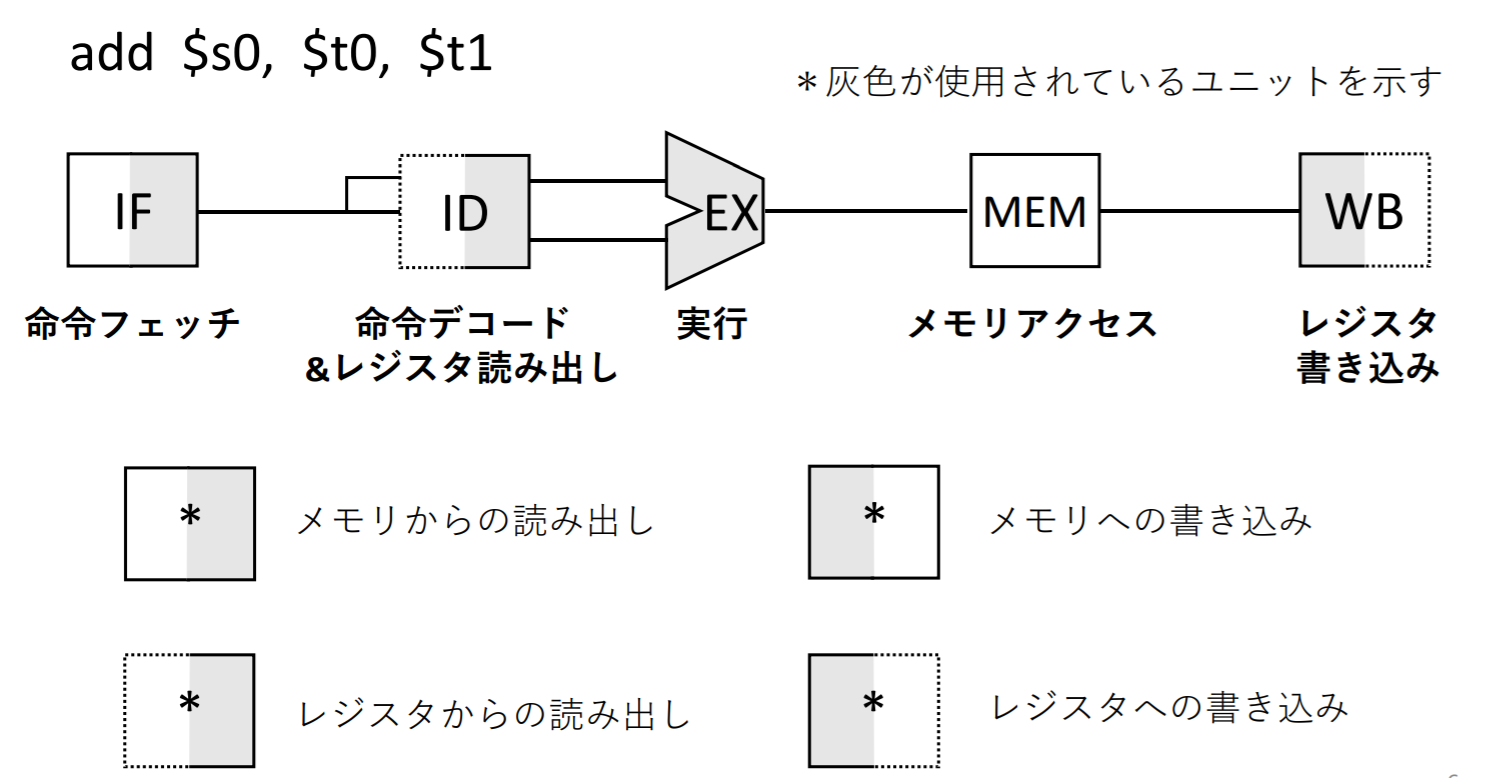
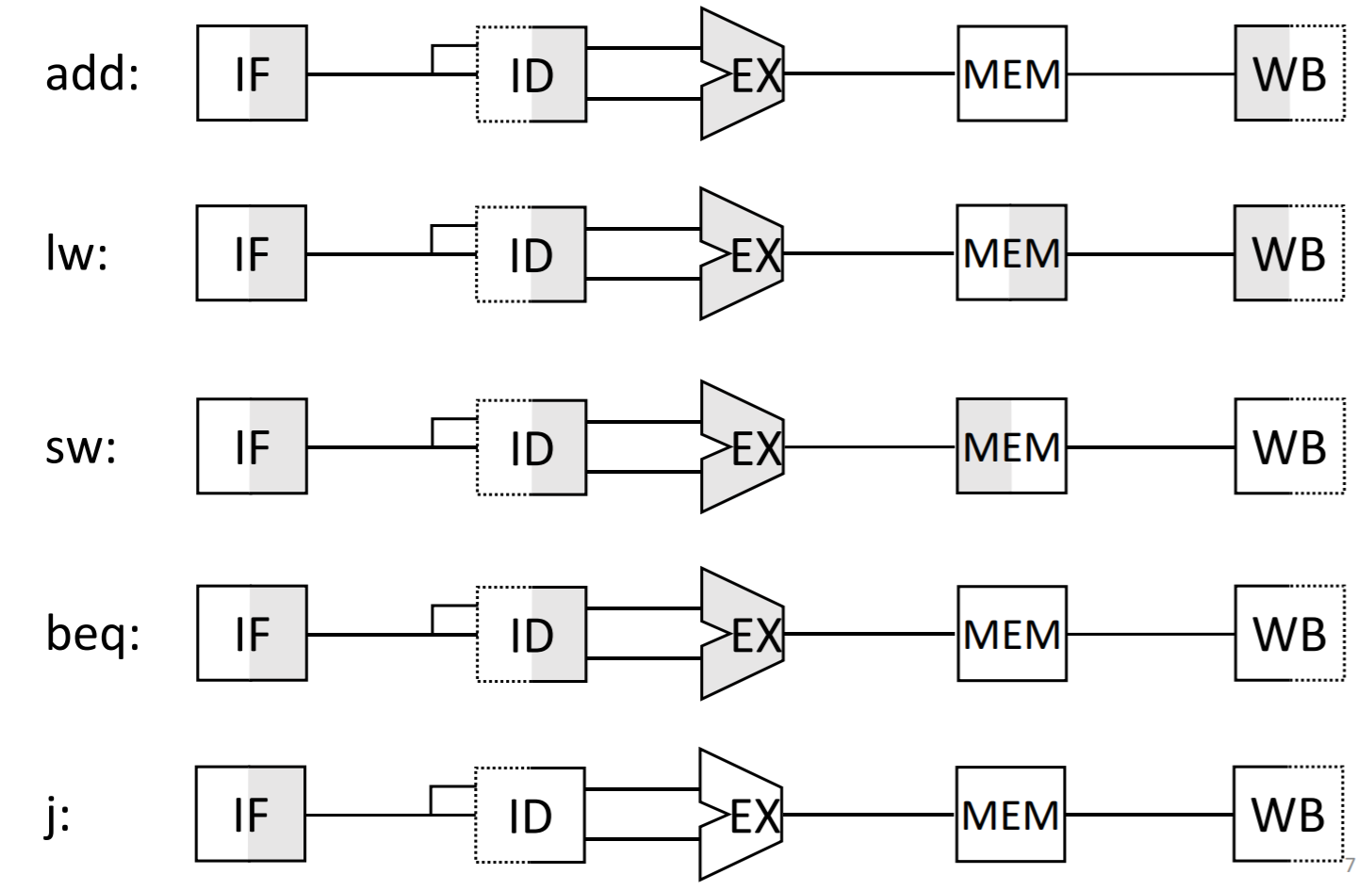
単⼀サイクル方式での実行
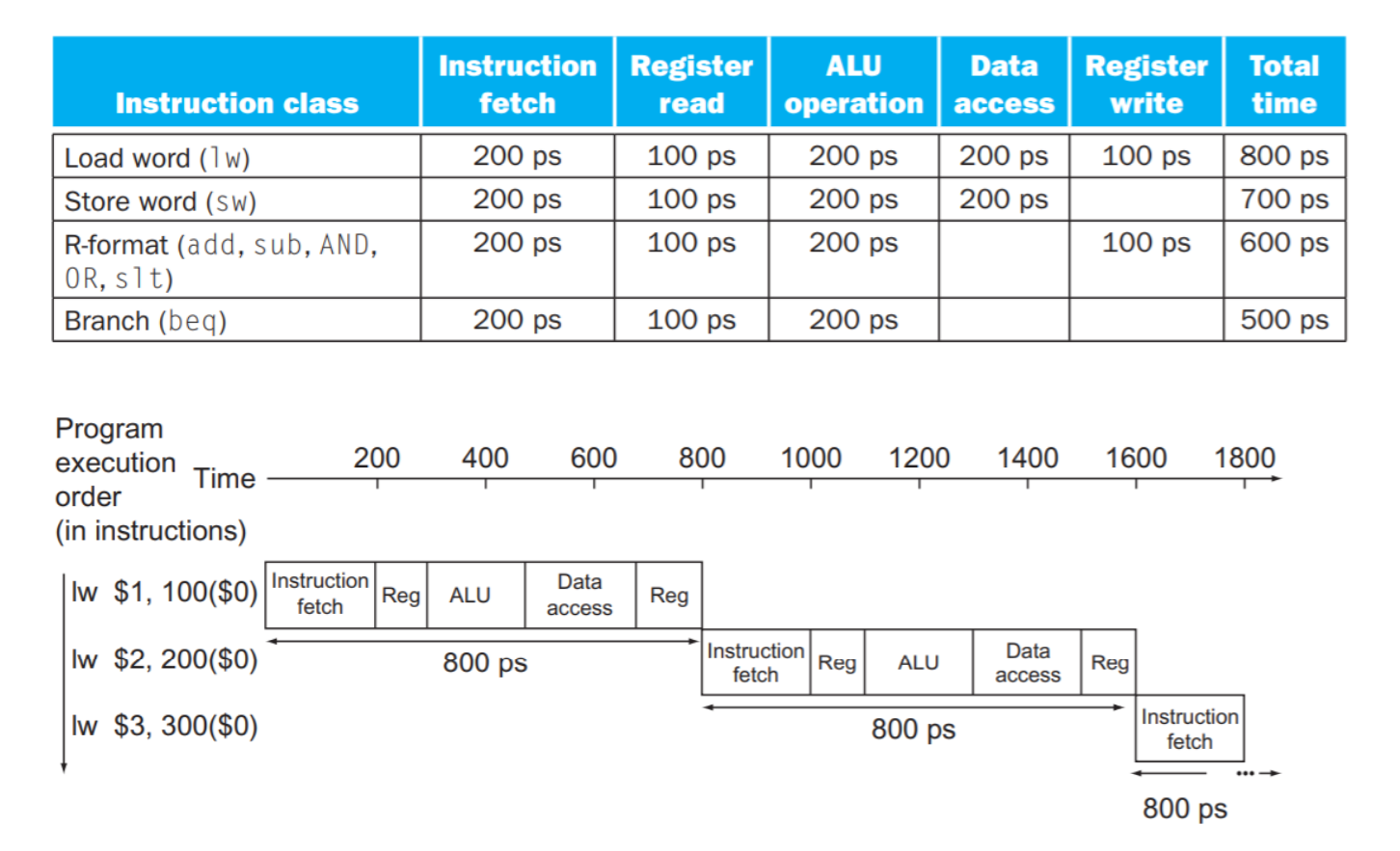
単⼀サイクル方式は全ての命令が1クロック・サイクルで実行されるため、最も遅い命令にクロック・サイクルをあわせなければならない
- ここではマルチプレクサ、制御ユニット、PCアクセス、符号拡張ユニットには遅延がない
- 1つの命令が終わったら次の命令を実行
- ある時刻に動作する機能ユニットは⼀つだけ
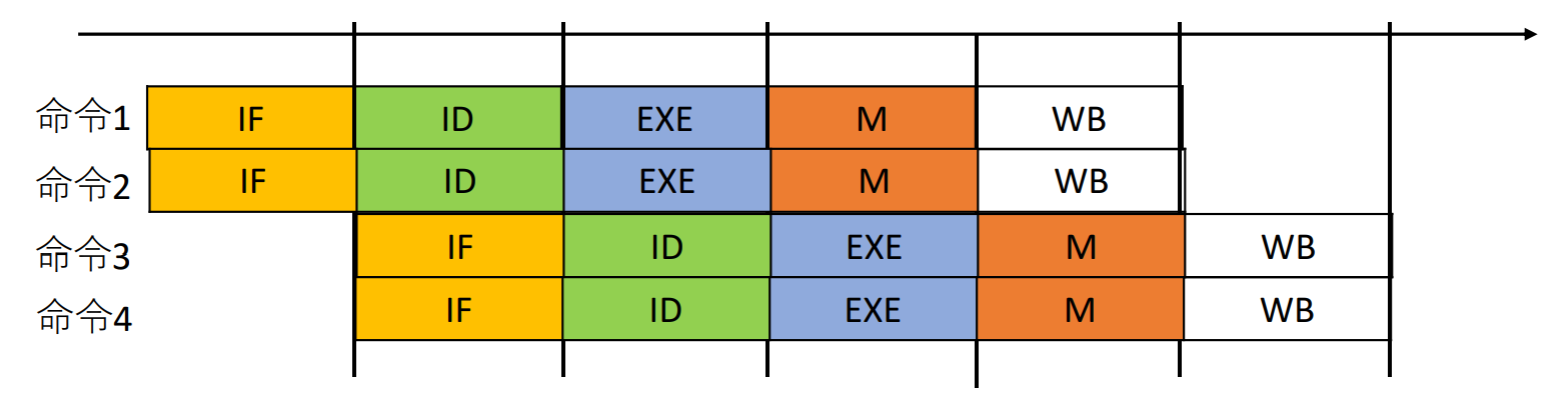
パイプライン方式での実行
複数の命令を少しずつずらして同時並行的に実行
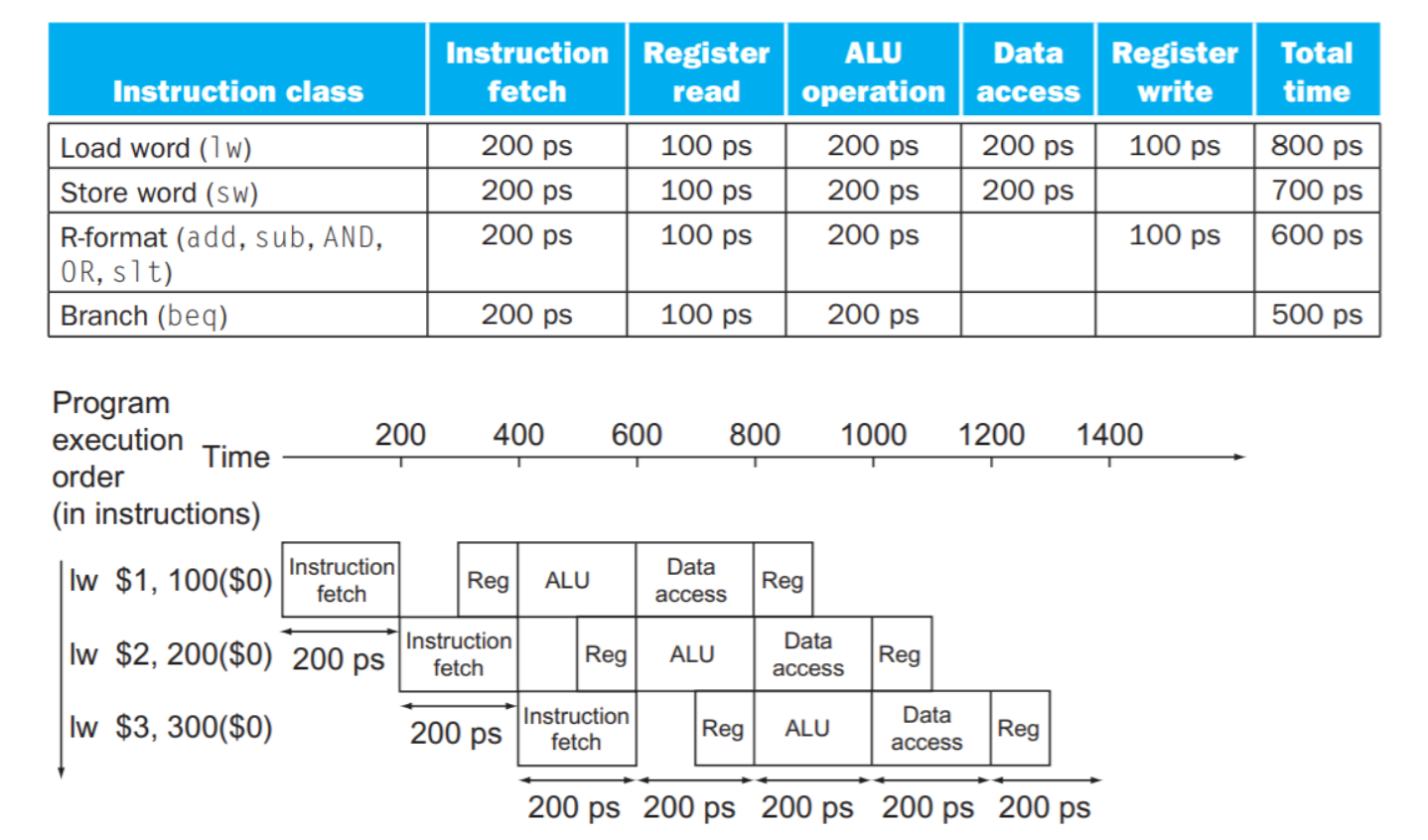
パイプライン方式は各ステージが1クロック・サイクルで実行されるため、最も遅いステージにクロック・サイクルをあわせなければならない
ステージ数は各機能ユニットの使用の有無にかかわらず同じ
単⼀サイクル方式では800psだったので、理想的には5倍速くなる(clock cycle)が期待される。しかし、この例から、実際に200ps、即ち、4倍速くなった。これは完全にステージ時間のバランスが取れていないと示した。
また、3命令実行する場合は、確かに速くなっているが、4倍は速くなっていない。これは、命令数を増やすことで、段々4倍に近づけることができる。
- ここではレジスタの読みだしはクロックサイクルの後半で、レジスタへの書き込みは前半で行われるとする
- レイテンシ(latency):個々の命令を完了させるのにかかる時間
- スループット(throughput):すべての命令を完了させるのにかかる時間
パイプライン処理はレイテンシではなくスループットを向上させる
MIPSにおけるパイプライン処理
- 命令長がすべて同じ
- 命令フェッチおよびデコードが容易
- どの命令形式でもソース・レジスタ(rs)のフィールド位置が同じ
- フェッチされた命令の種別判定と同時に、レジスタ・ファイルの読み出しが可能
- メモリの操作はロード・ストアのみ
- メモリ中のデータを直接演算対象にしないためステージがシンプル
- メモリに整列化制約がある(語アドレス=4の倍数)
- データ転送が効率的
パイプライン・レジスタ:各ステージのデータを記憶しておくレジスタ
ロード命令のデータパス
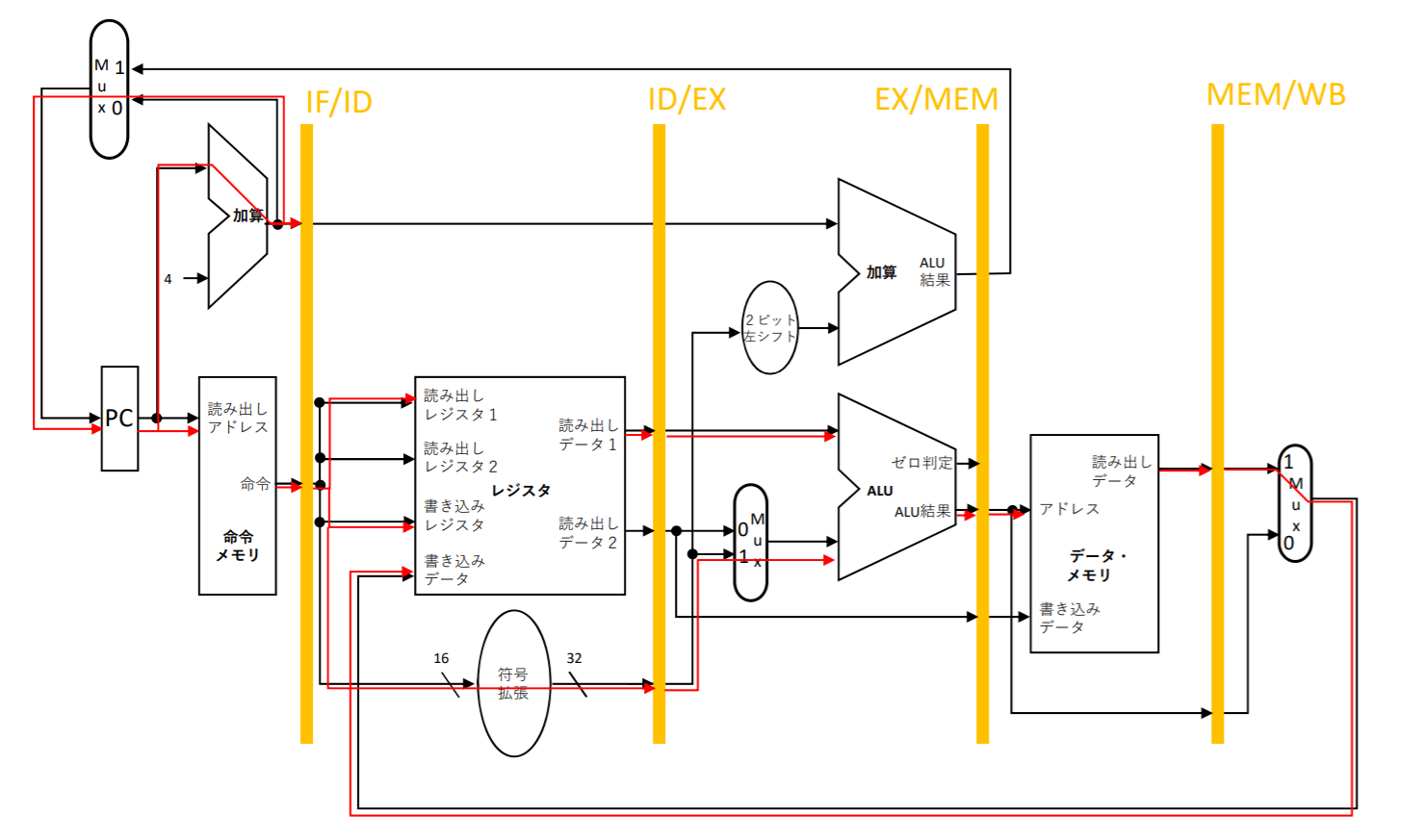
- プログラムカウントPCアドレスは4繰り上げられて、プログラムカウントにはき戻される。そして、次のクロック・サイクルに備えられる
- IF/IDパイプライン・レジスタには命令メモリからのデータと繰り上げられたプログラムカウントの値が保存される。このプログラムカウントの値はロード命令で使わないが、beq命令などで使用するなので保存される
- IF/IDパイプライン・レジスタからレジスタ番号と16ビットの即値フィールドが取り出される。16ビットの即値フィールドが符号拡張が行われて、読み出されたデータと共にID/EXパイプライン・レジスタに保存される
- 次に、読み出されたデータと符号拡張された即値をALUで加算して、結果をEX/MEMパイプライン・レジスタに保存される。beq命令の分岐先アドレスもこのステージで加算され、EX/MEMパイプライン・レジスタに保存される
- そして、加算結果を使って、データ読み出し、MEM/WBパイプライン・レジスタに書き込む
- 最後に、MEM/WBパイプライン・レジスタからデータを読み出して、レジスタに書き込む
実際に、この設計が上手く動かない!ロード命令には最後にレジスタへの書き込みが必要。しかし、ロード命令で実行する時に取り出した書き込みレジスタ番号は最後の書き込む時に失われてしまう。従って、最後の(6)書き込むは実行できない。
以下のように修正する
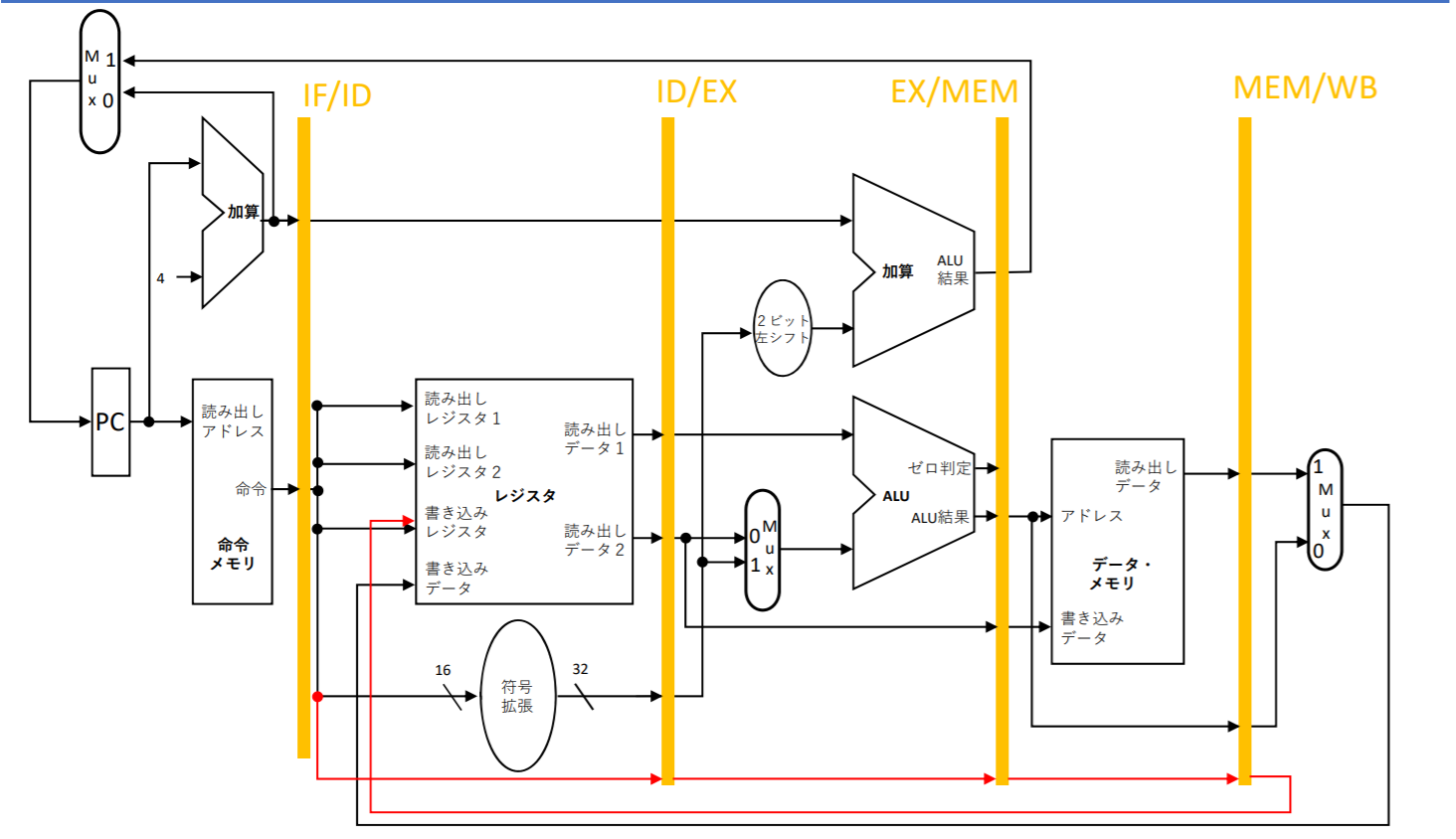
書き込みレジスタ番号をパイプライン・レジスタに次々と渡していく。WBステージで使えるようにする。
パイプライン化したデータパスを共有するためには,以降のステージで使用される命令要素を各パイプライン・レジスタに保存する必要がある
ストア命令のデータパス
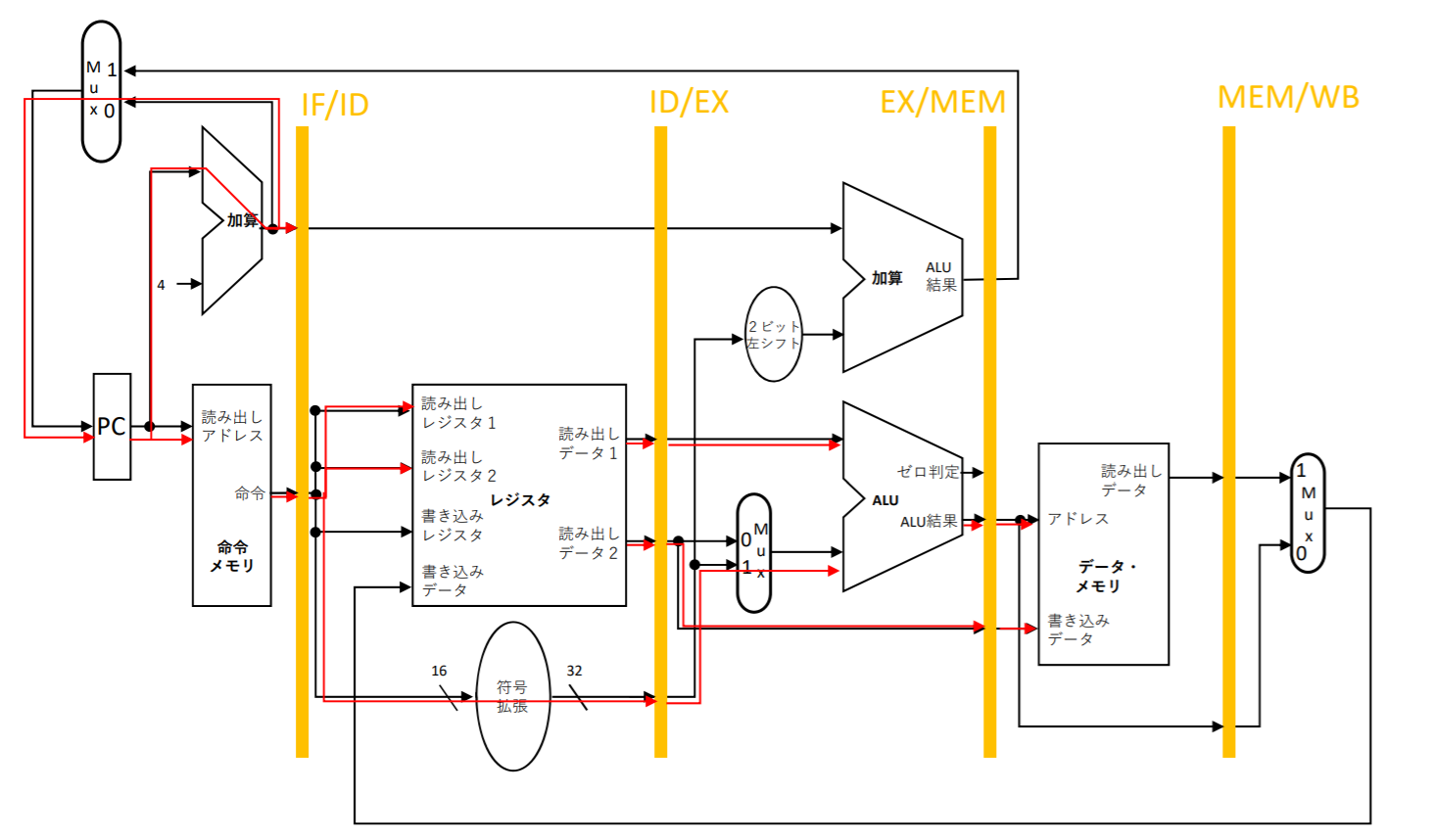
- プログラムカウントPCアドレスは4繰り上げられて、プログラムカウントにはき戻される。そして、次のクロック・サイクルに備えられる
- IF/IDパイプライン・レジスタには命令メモリからのデータと繰り上げられたプログラムカウントの値が保存される。このプログラムカウントの値はロード命令で使わないが、beq命令などで使用するなので保存される
- IF/IDパイプライン・レジスタからレジスタ番号二つと16ビットの即値フィールドが取り出される。16ビットの即値フィールドが符号拡張が行われて、読み出されたデータと共にID/EXパイプライン・レジスタに保存される
- 次に、読み出されたデータと符号拡張された即値をALUで加算して、結果をEX/MEMパイプライン・レジスタに保存される。保存するデータもEX/MEMパイプライン・レジスタに保存される
- そして、メモリにデータが書き込まれる
- ストア命令ではWBステージが既に終わっているので、何も行われない
課題6.1

課題6.2
パイプラインの制御
単一サイクル方式と同様にパイプラインのデータパスに制御を追加するとどうなるでしょうか?
データパスに制御信号を追加するとこのようになる
各パイプライン・ステージで制御信号を設定する
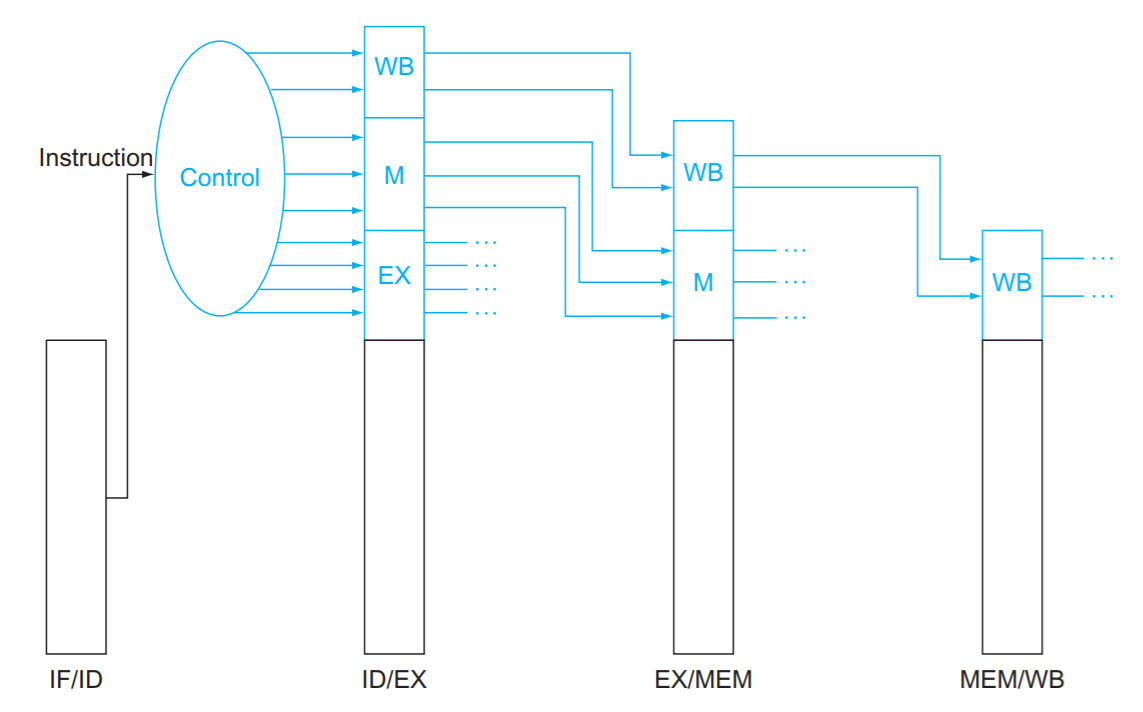
- PCへの書き込み、およびパイプライン・レジスタへの書き込みは各クロック・サイクルで行われるとする
- 制御信号なし
次に、今まで無視したパイプラインの問題点について見ていく
パイプライン・ハザード(Pipeline Hazards)
ハザード: パイプライン処理において次のクロック・サイクルで次の命令を実行できない事態
パイプライン・ハザードの分類
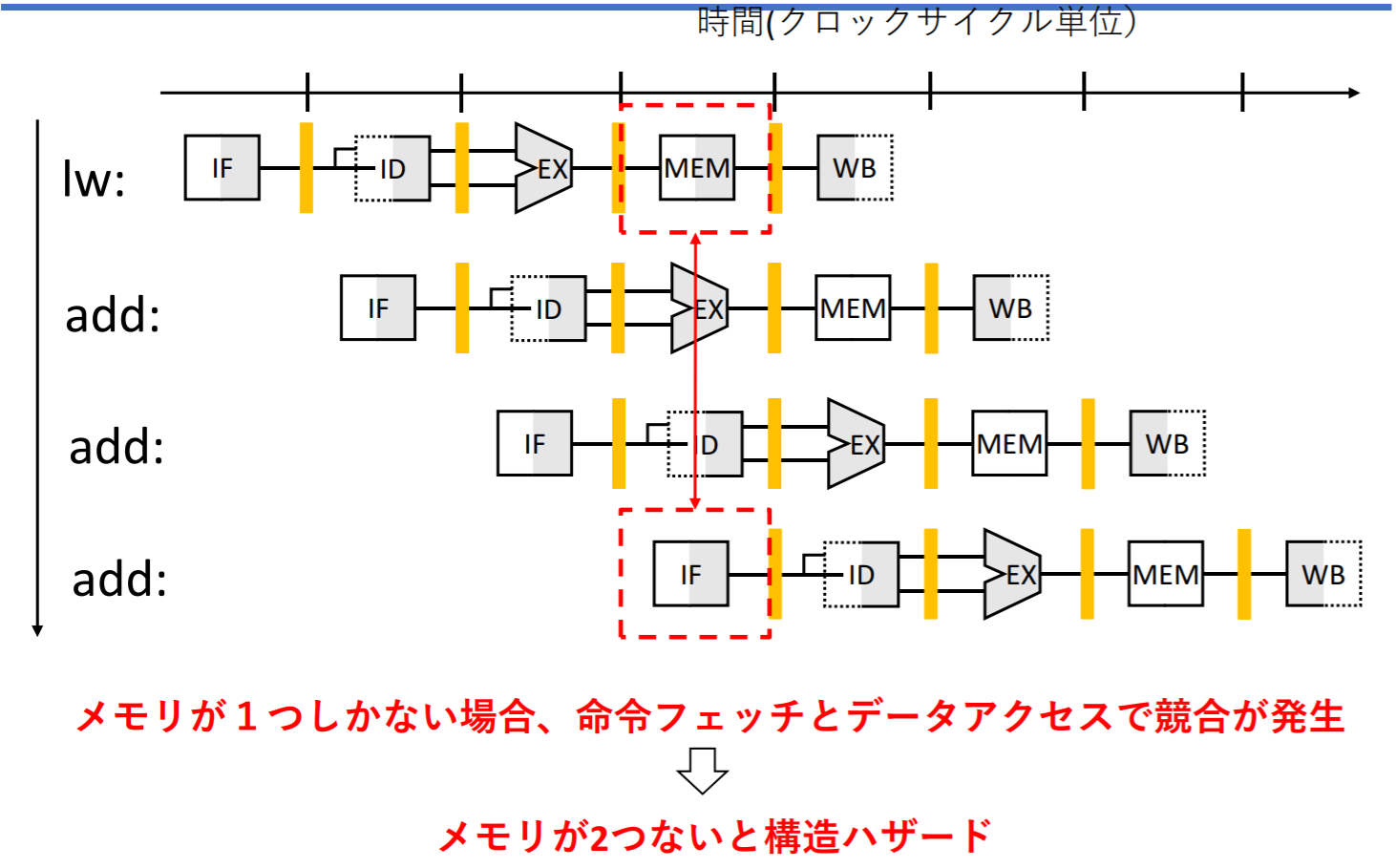
- 構造ハザード: ハードの制約で生じる
- 同じハードに複数の命令から同時にアクセスできない
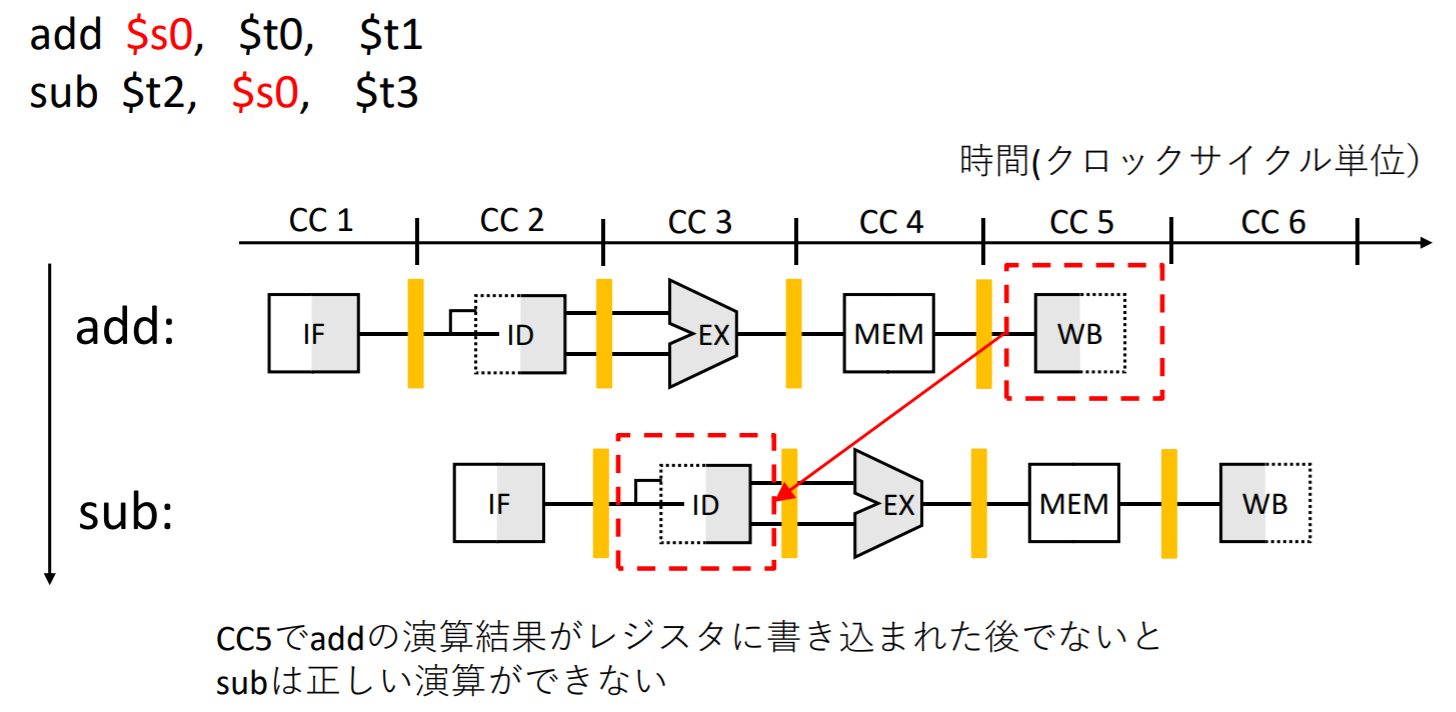
- データ・ハザード: 先行命令に後続の命令が依存している場合に生じる
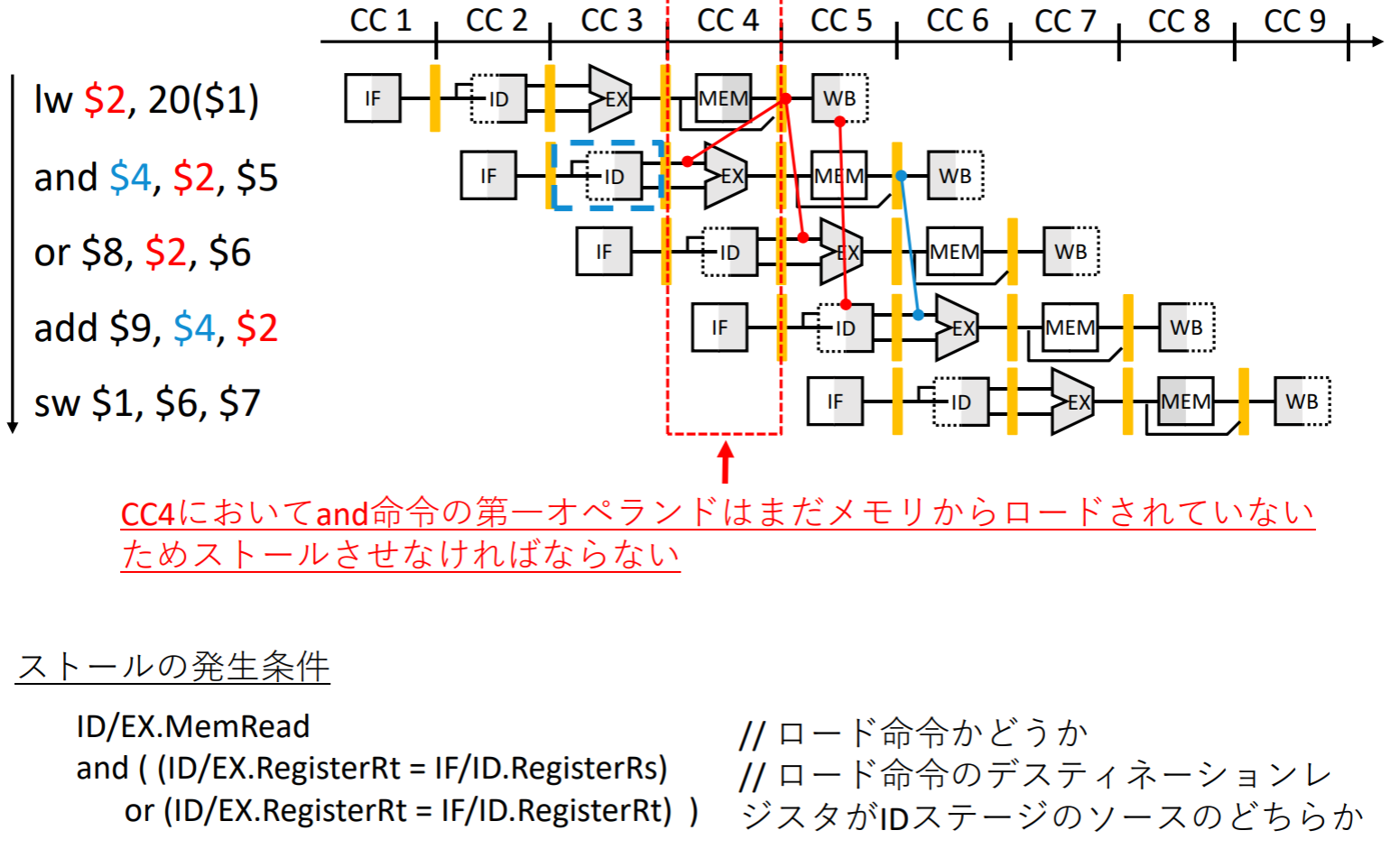
- 被ロード・データ・ハザード: 後続命令のデータが先行命令によってロードされるデータである場合
- パイプライン・ストール(バブルともいわれる、命令処理の⼀時停止)させなければならない
- 制御ハザード(または分岐ハザード): 後続命令の実行判断を先行命令に基づいて行う場合に生じる
- 分岐命令
- ストール、予測を行う
構造ハザードの例
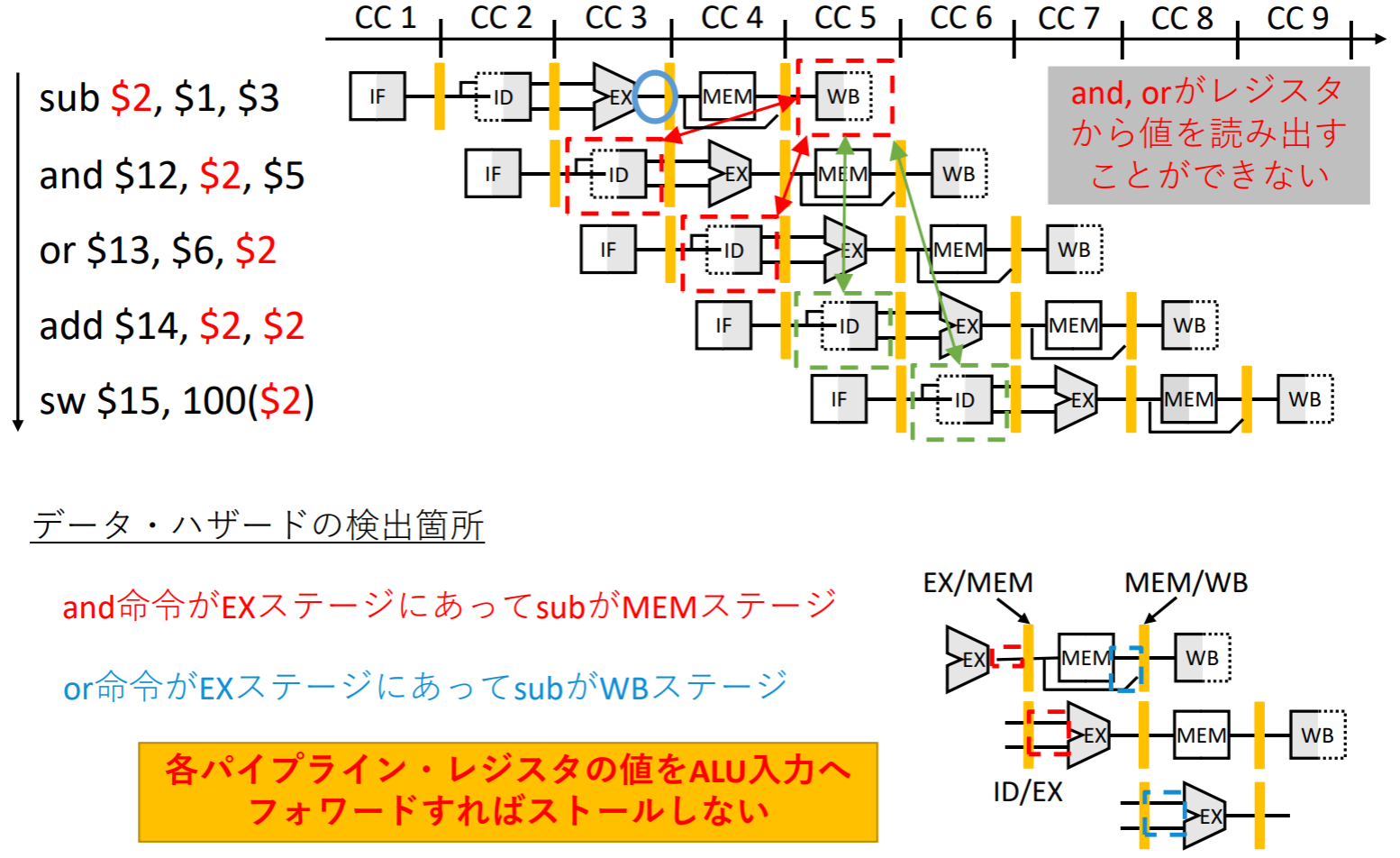
データ・ハザード対策
解决方案一:流水线停顿,增加气泡
解决方案二:数据前递(Forwarding)
フォワーディング(forwarding)又はバイパシング(bypassing)
- データ・ハザードを解消する方法の⼀つ
- レジスタ、メモリに書き込まれる前のデータを使う
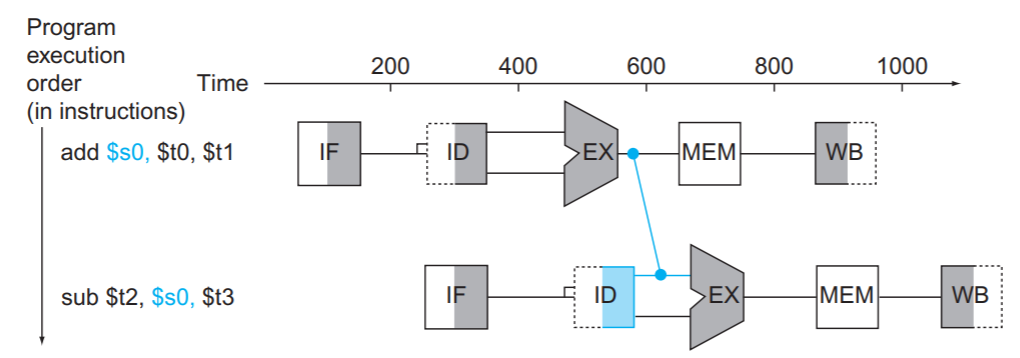
フォワーディング/バイパシング: add命令の計算結果は3サイクル目で求められているため、パイプラインレジスタの値をsub命令が必要とするALUのバイパスすることで、sub命令をストールさせずに実行することができる。
フォワーディング・ユニットを追加したデータパスはこのようになる
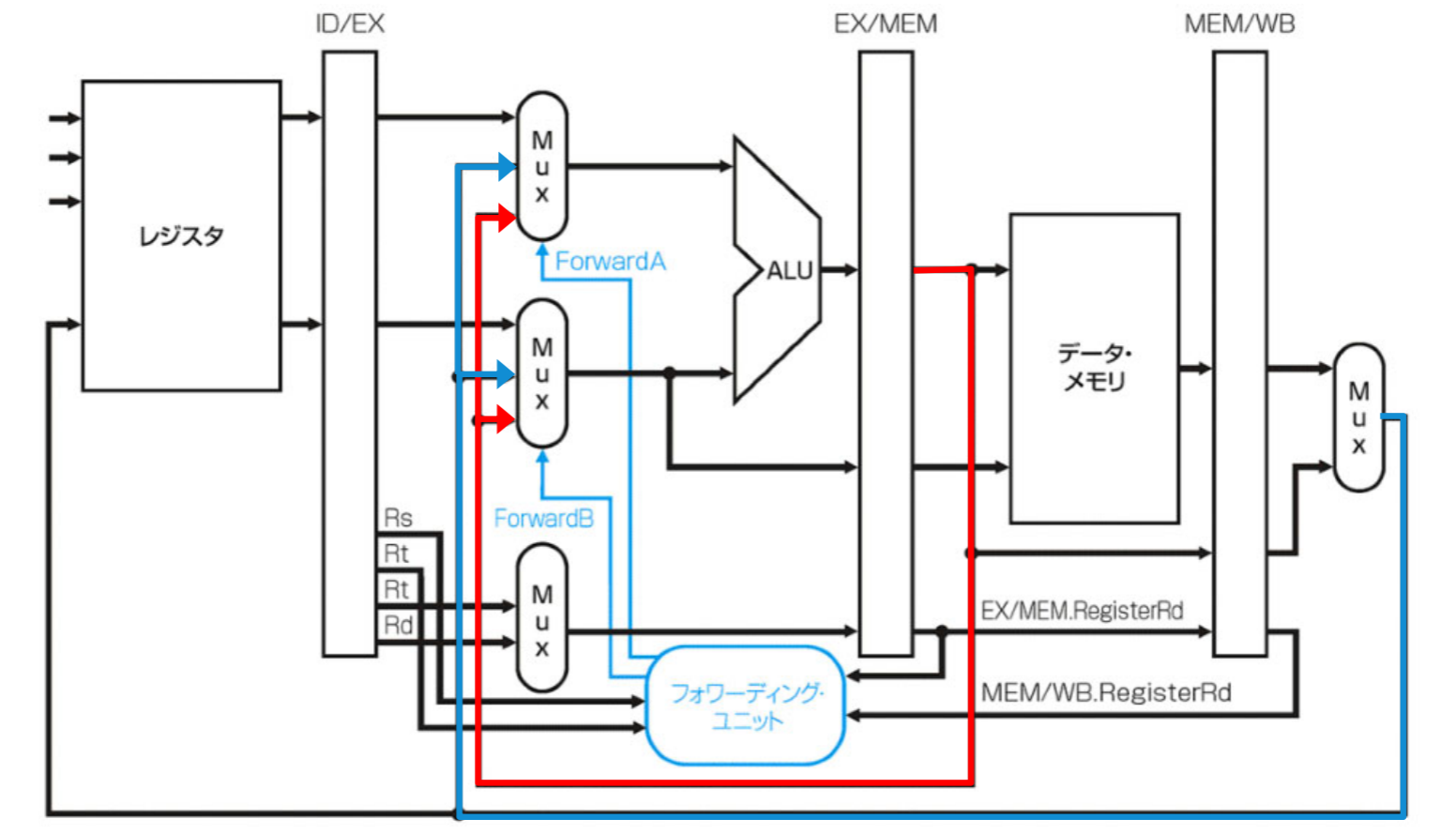
EX/MEMパイプラインレジスタの値をALUの入力としてforwardするパスとMEM/WBパイプラインレジスタの値をALUの入力としてforwardするパスを追加されている
- フォワーディング・ユニットはforwardされた値を使うかどうかを切り替えるマルチプレクサを制御する
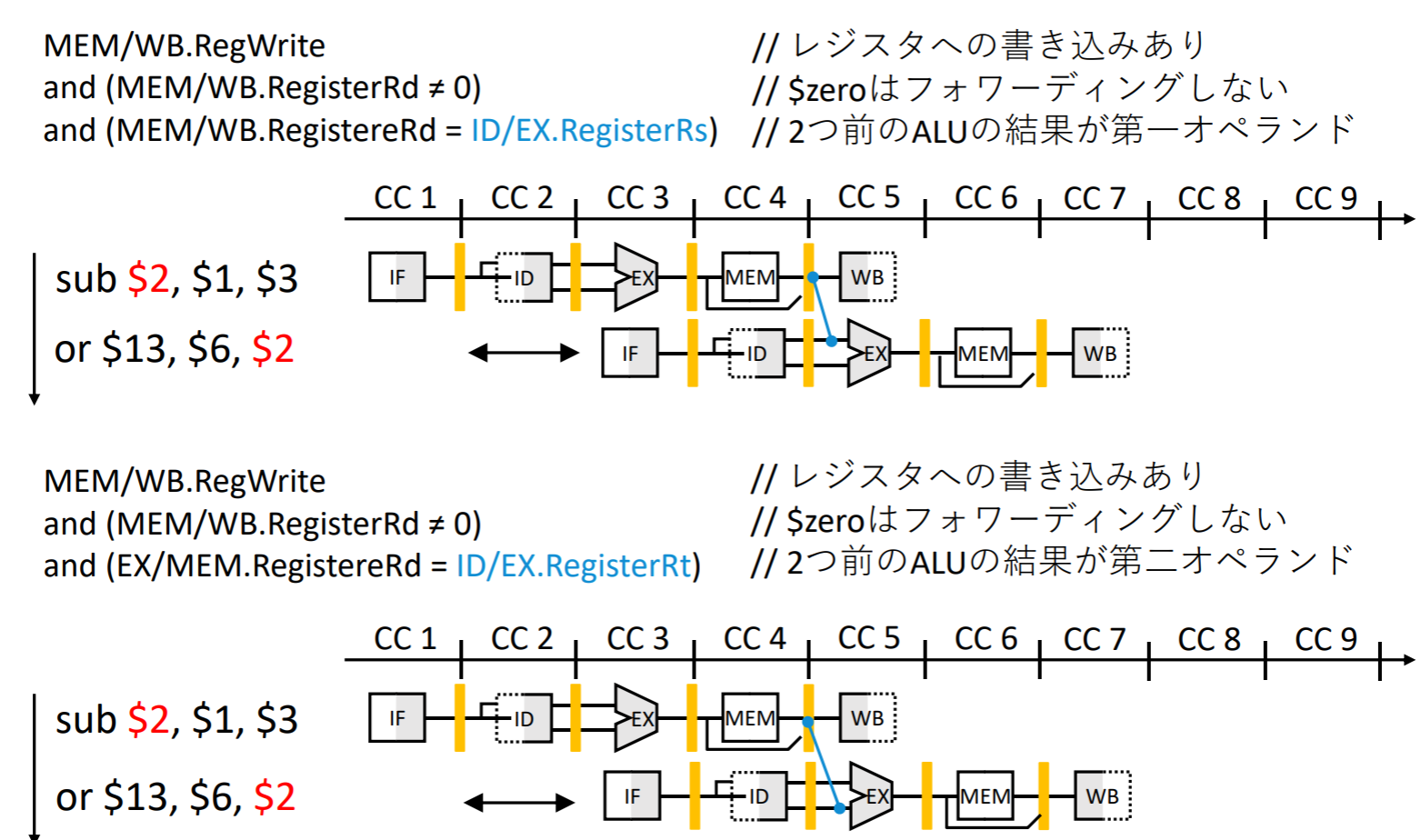
EXハザードの検出条件
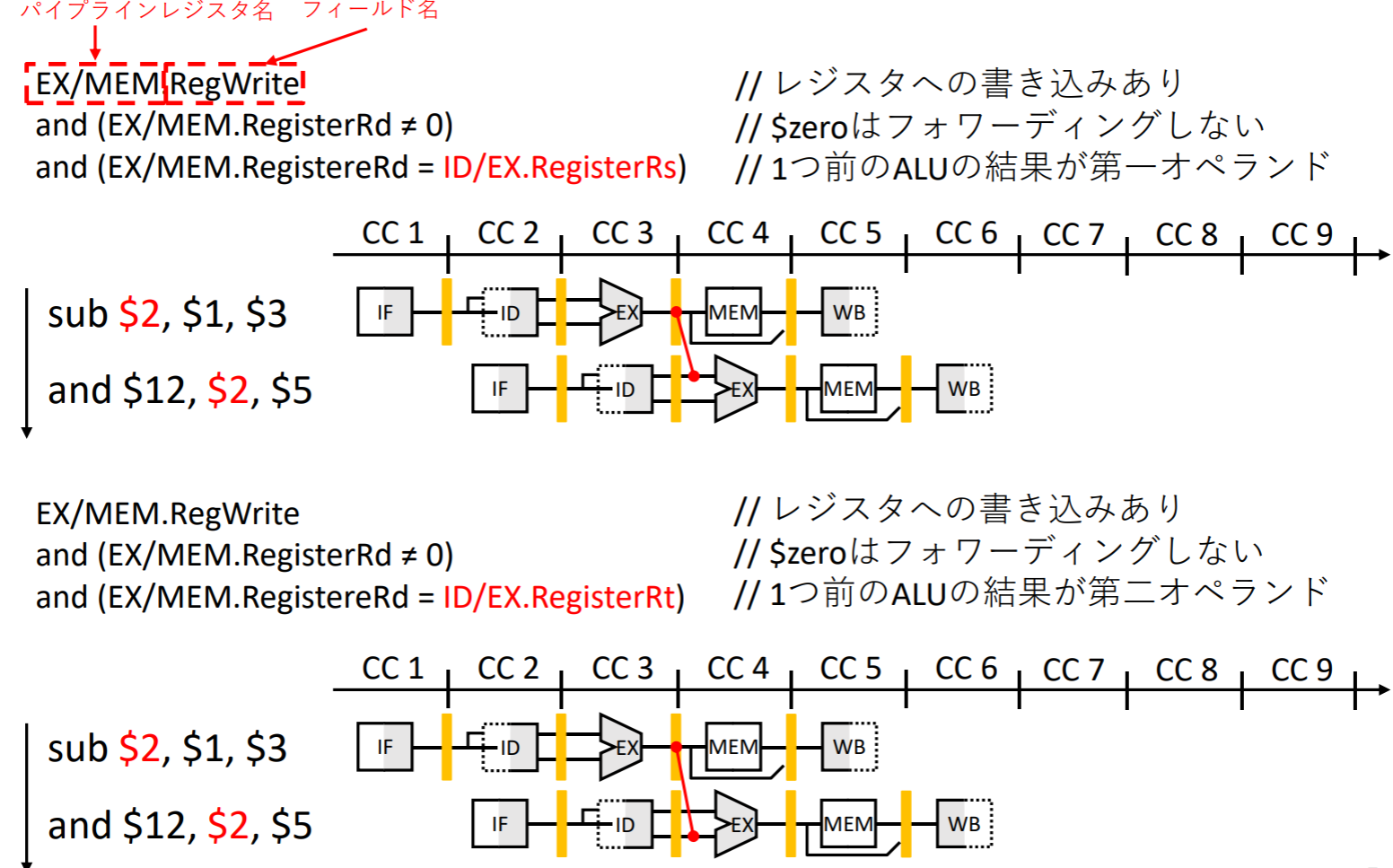
MEMハザードの検出条件
forwardingできない場合
ストールの実装
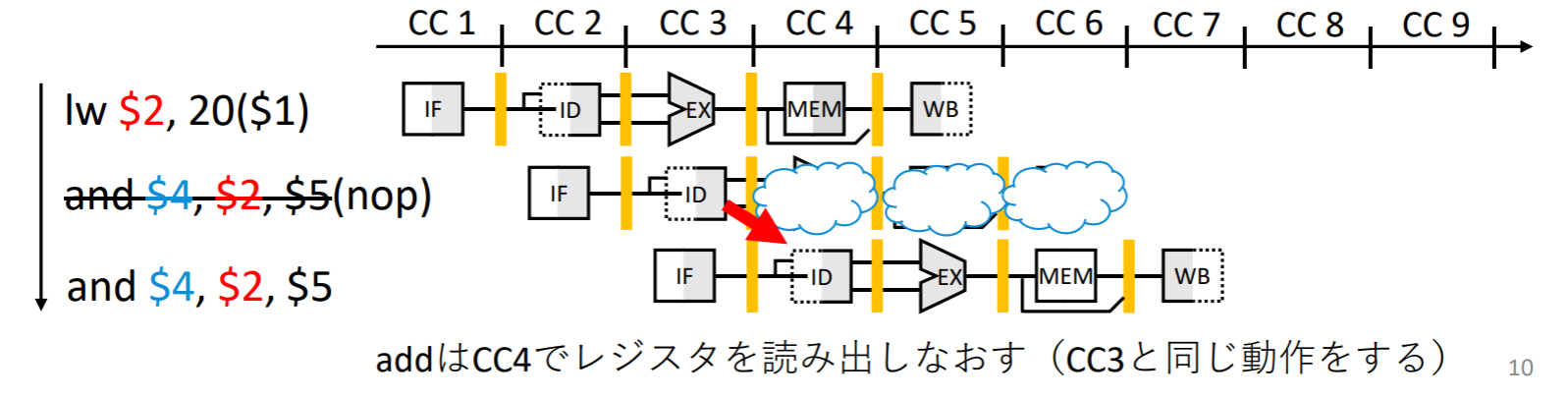
IDステージ上の命令をストールさせる場合、PCレジスタとIF/IDパイプライン・レジスタを変更しないようにすればよい。
EXステージ以降で、何もしない命令nopを実行すればよい。
- ID/EXパイプライン・レジスタ中のEX, MEM, WB制御フィールドを全て0に変更する。このようにして、レジスタにもメモリにも何も書き込まない
制御ハザード対策
- 假设分支不发生
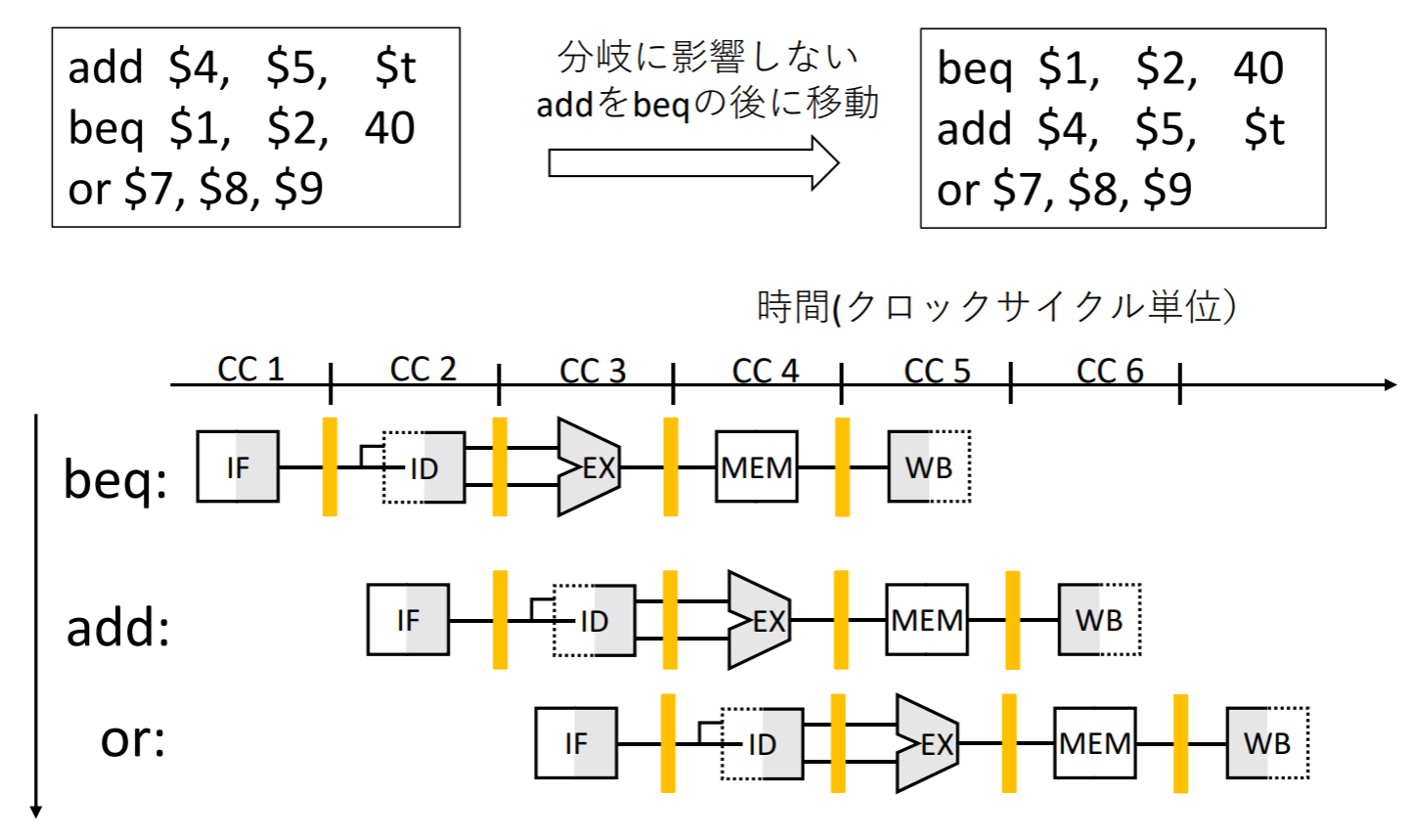
- 缩短分支延迟
- 延迟转移技术
遅延分岐: 分岐直後の命令が常に実行され,分岐は1命令分遅れて実行する
もう一つの対策は静的分岐予測: 分岐が不成立と仮定して後続命令を実行
- 分岐が成立した場合、途中まで進めた命令を破棄
- 分岐不成立の確率と進めた命令の破棄コスト次第
命令破棄の方法(フラッシュ): IF, ID,EXステージ上の制御値を0に変更
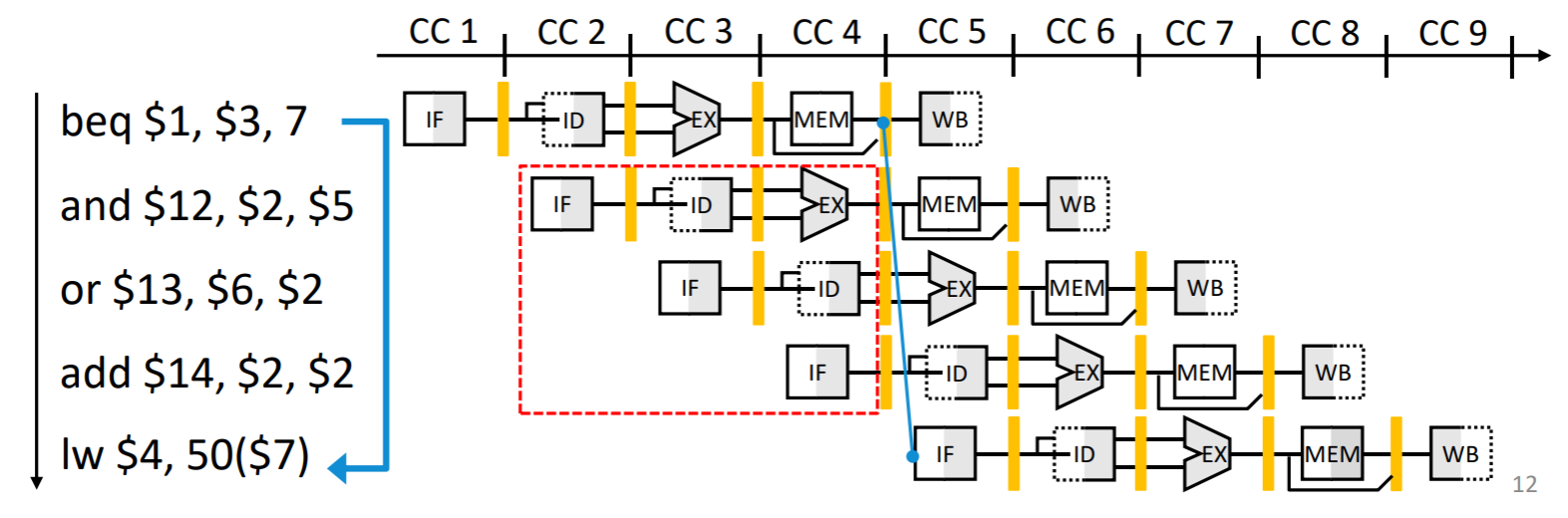
別の対策としては分岐判定を早める
分岐先アドレス計算と分岐判定の評価をIDステージに移すことができれば,分岐成立時のペナルティが現在フェッチ中の命令⼀つに減る。ただしIDステージにハードウェアの追加が必要。
- フォワーディング
- ハザード検出
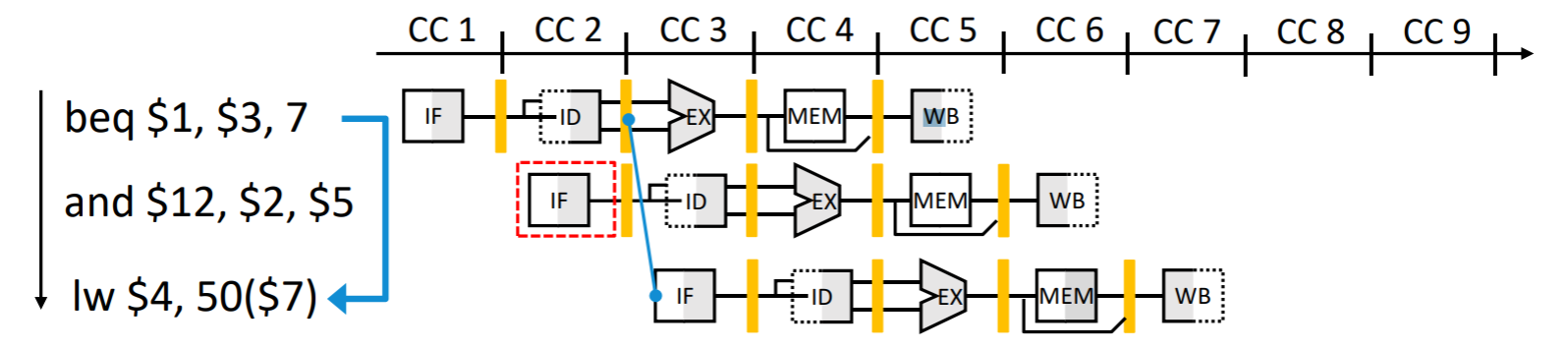
最後の対策は動的分岐予測である
動的分岐予測: ハードウェアを追加して、実行時の情報を使用して分岐予測を行う。追加したハードウェアは分岐予測バッファと呼ばれている小さなメモリである
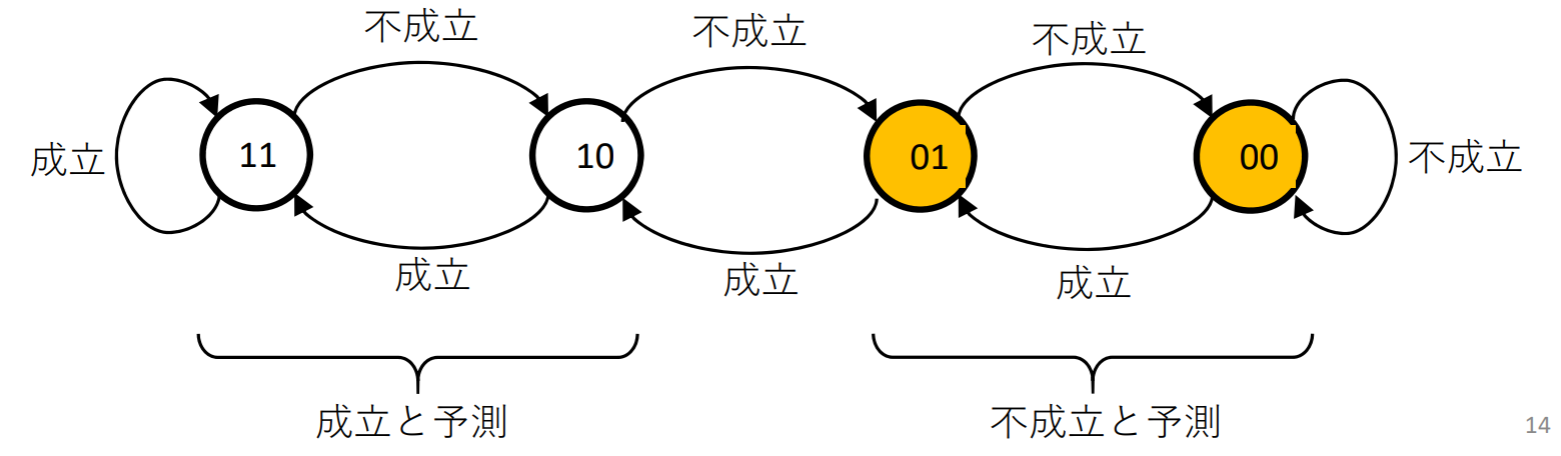
- 1ビット予測方式
- 直近の結果を使って予測
- 予測が1回ではなく2回誤ってしまう場合がある
- 2ビット予測方式
- 予測が2回続けて外れたら予測を変更
- 予測が外れるのは1回だけ
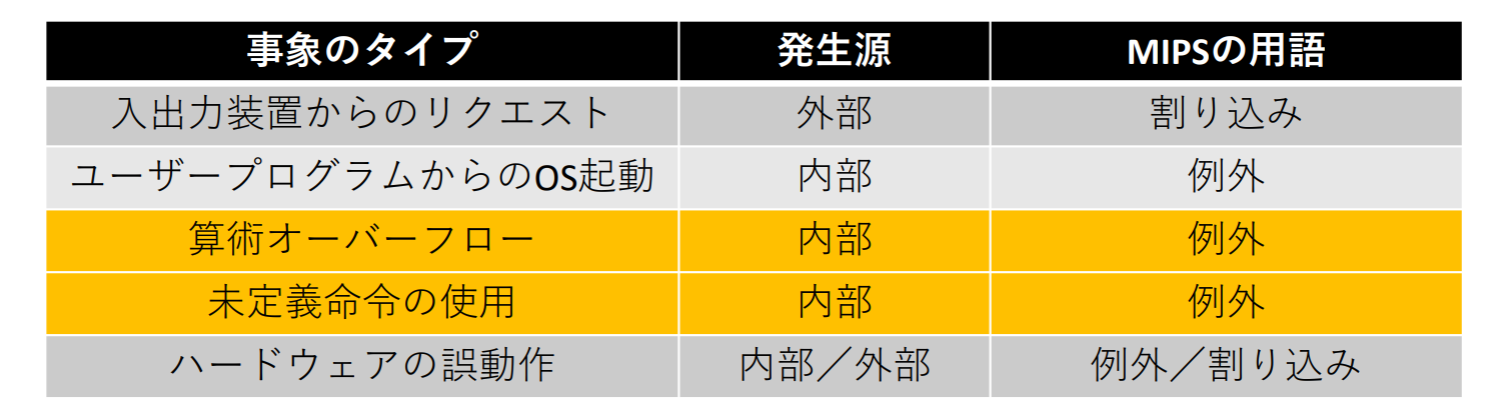
例外と割込み
例外: 制御の流れにおける予期せぬ変更、「割込み」とも言う
割込み: プロセッサの外部から発生した例外
例外が起きた時の対処方法
- 問題を起こしている例外のアドレスを例外プログラムカウンタ(Exception Program Counter: EPC)に退避させ、OSに制御を渡す
- 例外の原因をOSに伝える方法
- ベクタ割込みを使う
- 特定の状態レジスタ(Causeレジスタ、32bit)に例外の原因を記録(MIPSはこっち)
- 例外処理後
- プログラムの実行中止(強制終了)
- プログラムの実行継続
パイプライン方法における例外
例外を制御ハザードの⼀種として扱う
例外が発生すると、
- 続く命令をフラッシュ
- 新しいアドレスの命令をフェッチ
分岐と同じ仕組みが利用可能
例外の原因を常に正しく把握することは難しい
- どの命令で例外が発生したのか
- 複数の例外が発生した場合の対応
命令を通じた並列処理
命令レベル並列性(Instruction‐level parallelism : ILP): パイプライン処理は、命令間の潜在的な並列性を利用している
ILPを高める方法:
- パイプラインの段数を増やす
- スーパーパイプライン
- ハードウェアの構成要素を多重化して各パイプライン・ステージのそれぞれで複数命令が実行できるようにする
- スーパースカラ
- VLIW(Very Long Instruction Word)
スーパーパイプライン
スーパーパイプライン: パイプラインの処理の分割単位をさらに細分化してILPを上げる
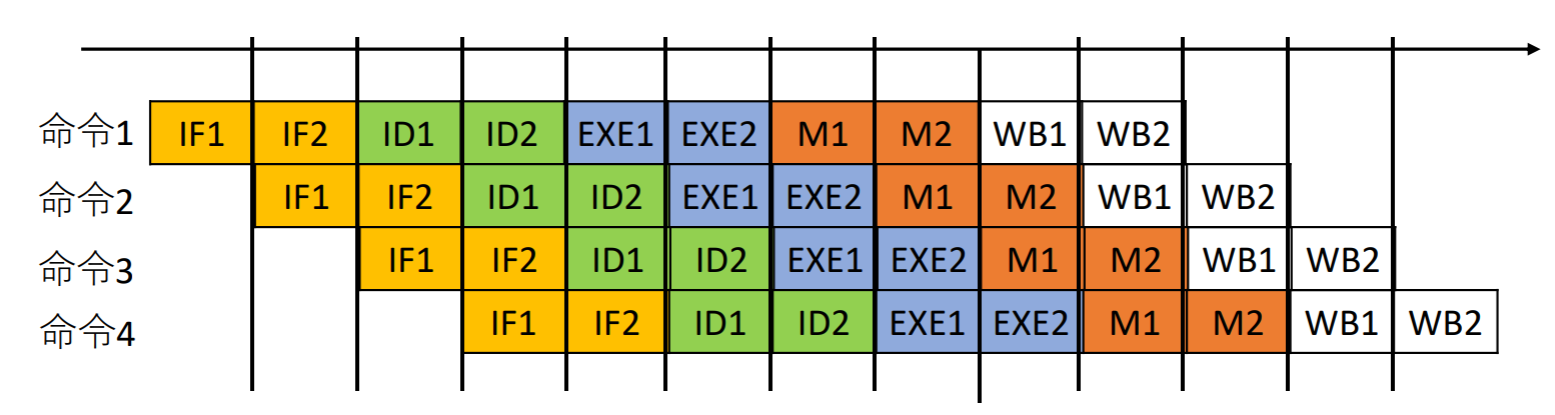
- メリット
- より高い周波数で動作させることができる
- デメリット
- パイプラインレジスタの数が増加するため、予測分岐が外れると多くの命令を破棄しなければならない
スーパースカラ
スーパースカラ(superscalar): ハードウェアを追加し、依存関係のない命令を同時に複数命令を実行することでILPを上げる
動的パイプライン・スケジューリングが取り入れられている(実行順序を再構成してできるだけストールを避ける技術)
- メリット
- 1クロック・サイクルで複数命令を同時に実行できる
- デメリット
- 実行可能な命令数が増えると依存関係の計算コストが増大する
課題6.3
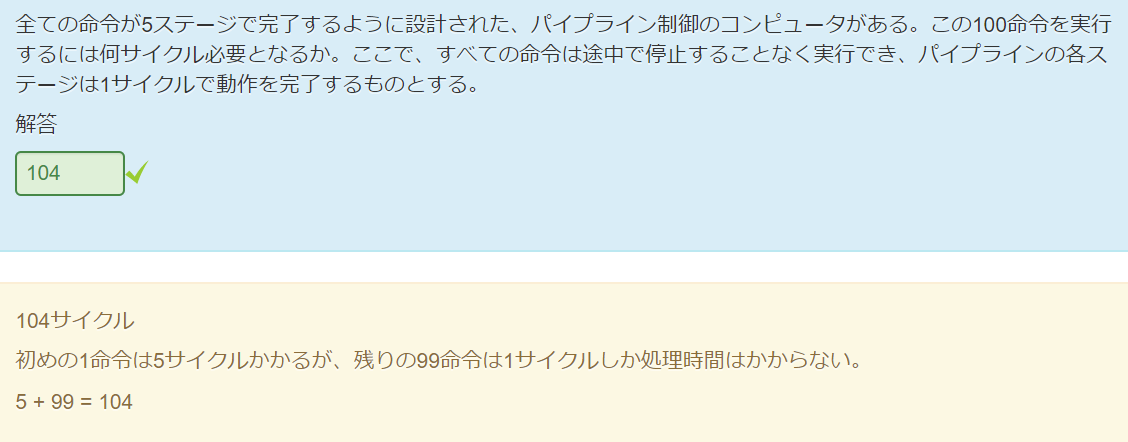
以20条命令为例:

課題6.4
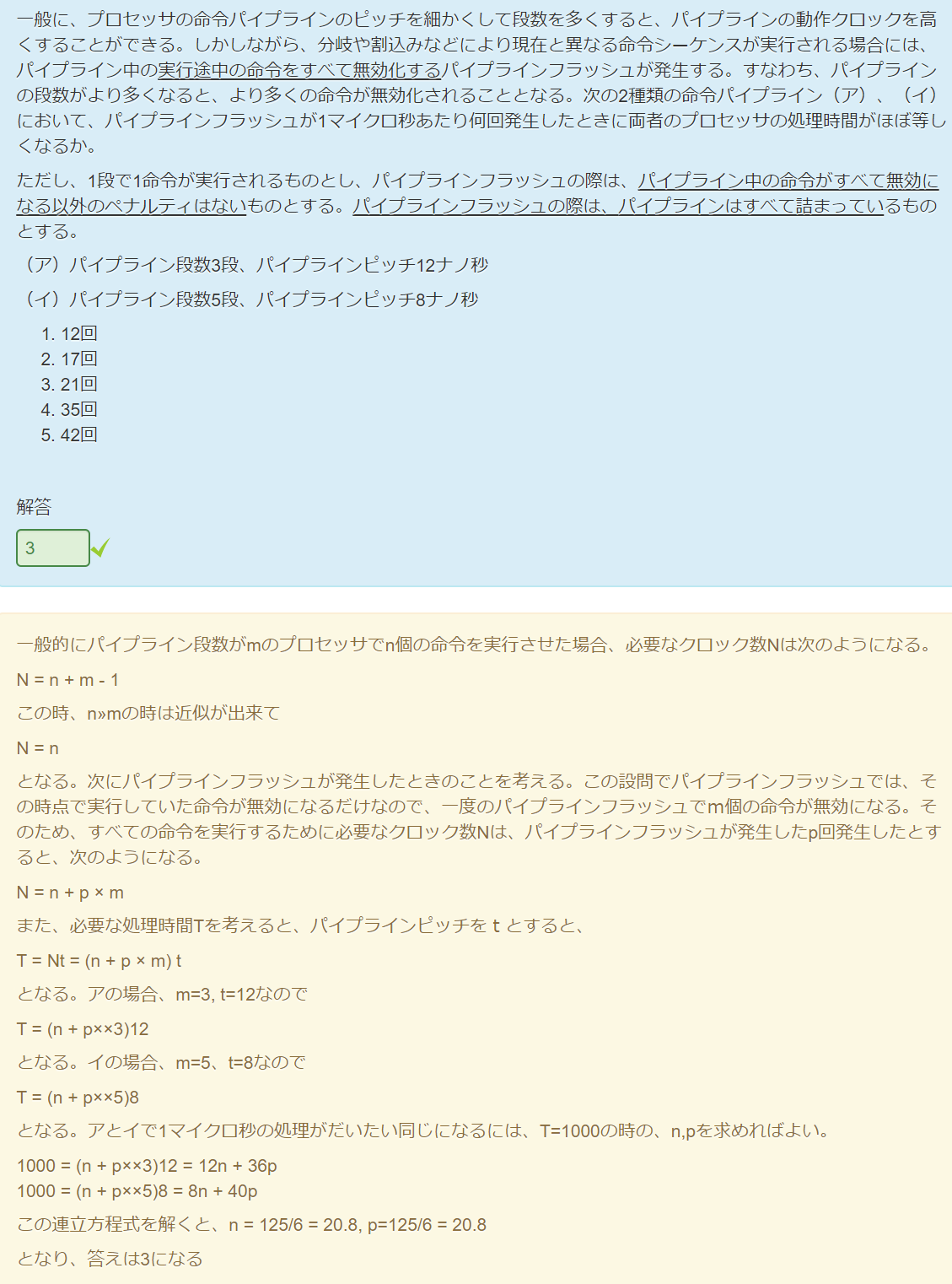
假设不发生flush,即不会有被无效化的指令,分别计算不同pipeline段数在1000ns内执行的指令数:
即不发生flush情况下,3段的pipeline比5段的pipeline多执行了 条指令。再考虑有无效化的情况,3段的pipeline会一次无效3个指令,而5段的pipeline会一次无效5个指令。1000ns内发生 回flush时,两个处理器所执行的时间几乎相等
メモリテクノロジ(Memory Hierarchy)
理想を言えば,無限の容量を備え,いかなる語にも瞬時にアクセスできるような記憶装置が欲しい.
しかし,現実には記憶装置をいくつかの階層に分けて構成せざるを得ない.
記憶階層
記憶階層とは,下の階層に行くほど容量が大きくなるが,アクセスにはより時間がかかるような仕組みである.
記憶階層の利用
記憶階層は「局所性の法則」に基づき構成される
局所性の法則:
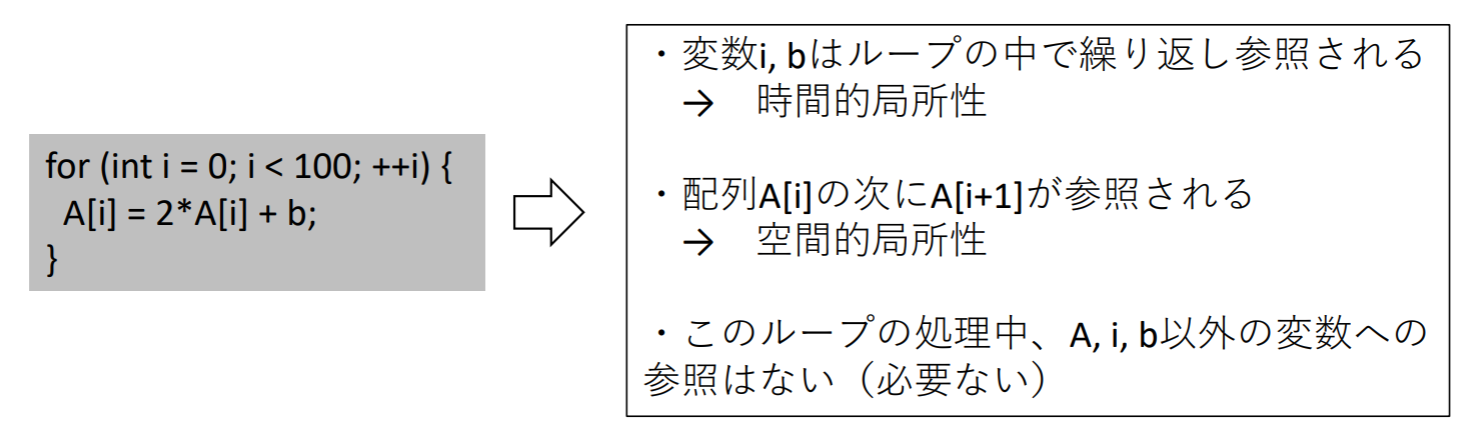
- 時間的局所性: ある項目が参照された場合、その項目がまもなく再び参照される確率が高い
- 空間的局所性: ある項目が参照された場合、その近くにある項目がまもなく再び参照される確率が高い
記憶階層の構造

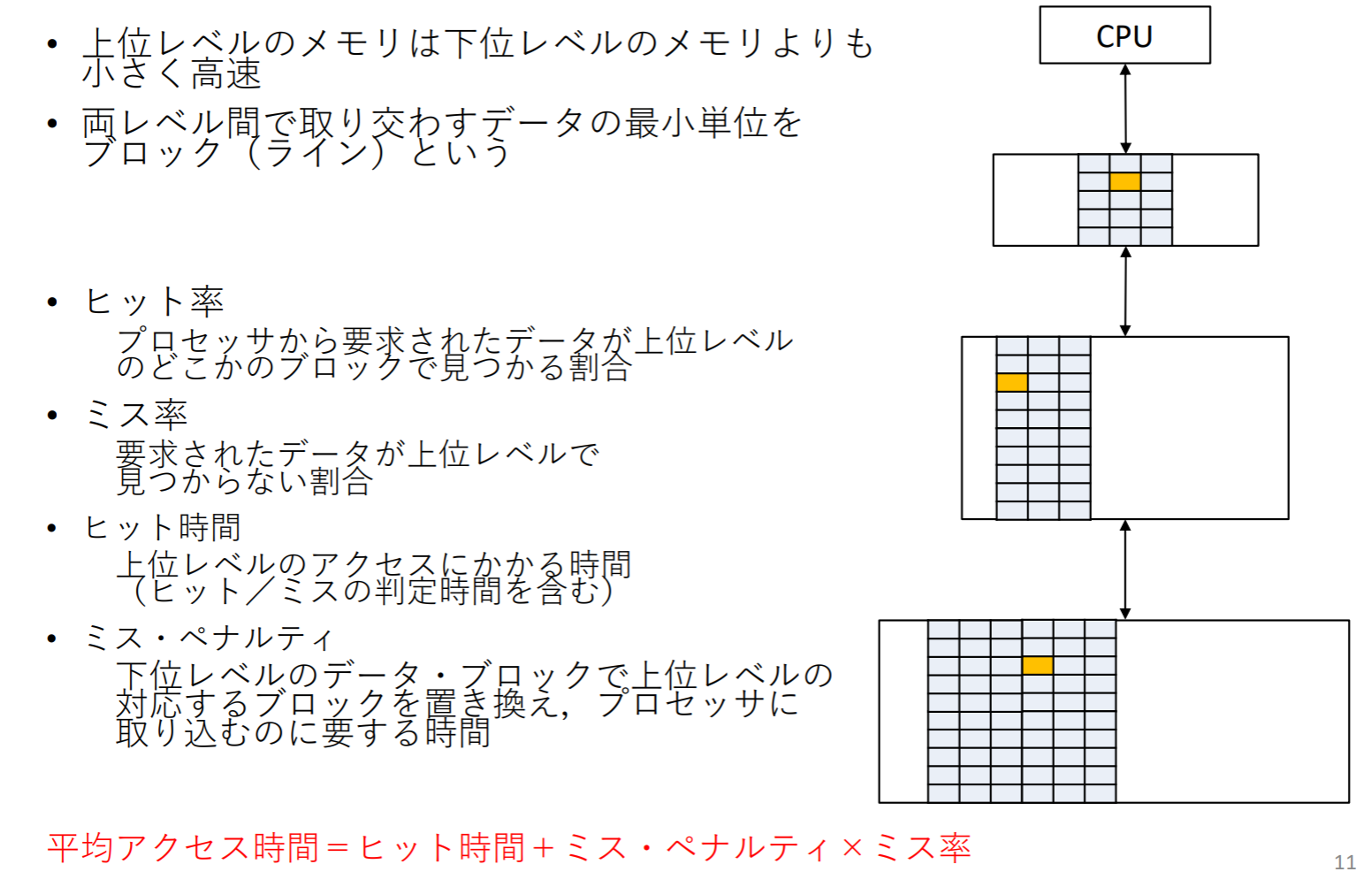
我们把资料一次从存储器下层转移到上层的单位叫做block。如果处理器要求读取某个block的资料,刚好在上层的存储器内,那就称为命中(hit),如果不在上层,记为miss。hit rate就是成功在上层存储器能找到你要的资料的次数比例,hit rate + miss rate = 1
hit time:判断存储器是否hit + 把上层资料搬到处理器的时间
miss penalty:把下层存储器的资料搬到上层 + 上层存储器资料搬到处理器的时间
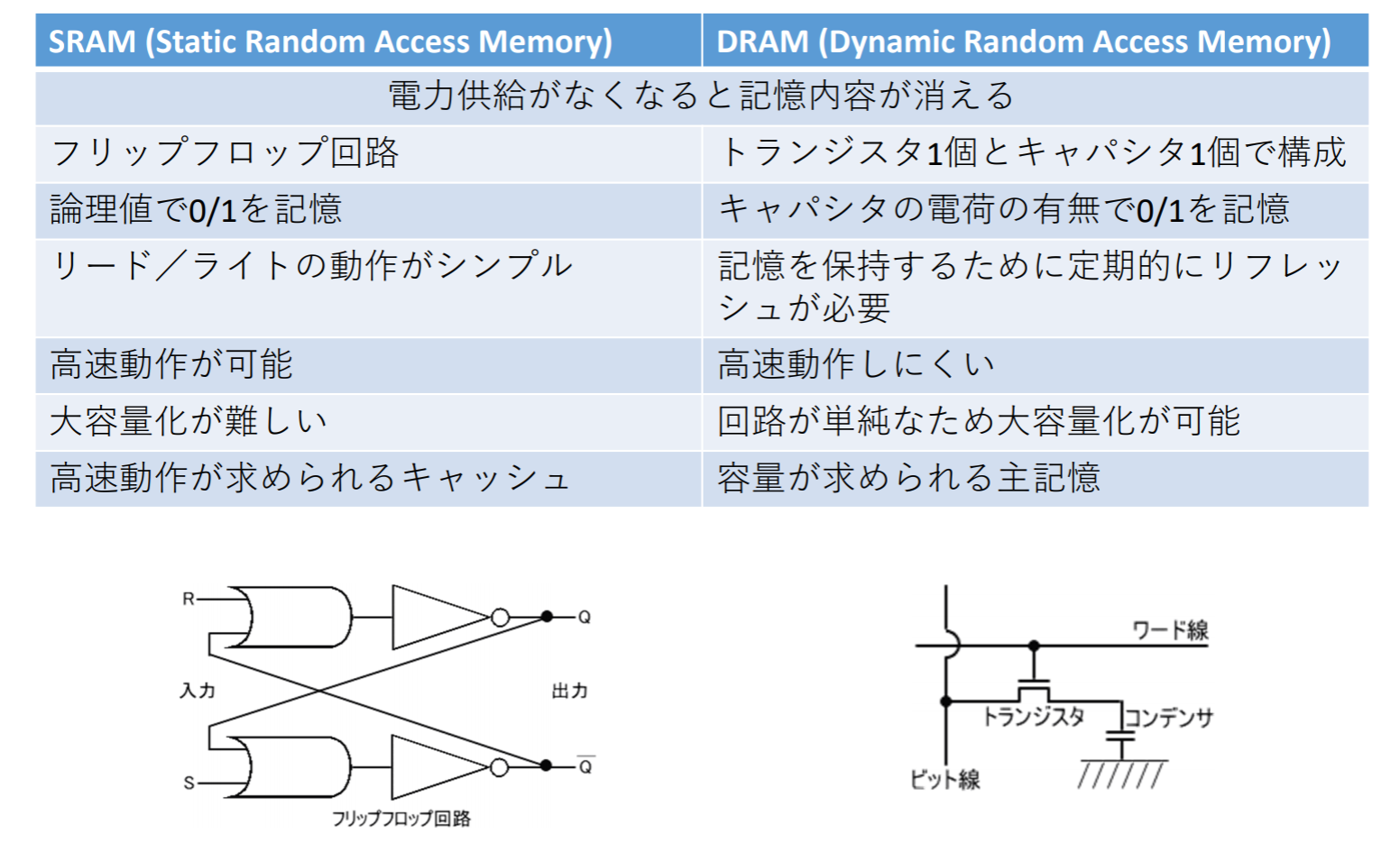
SRAMとDRAM
SSDとHDD

キャッシュ(Cache)
キャッシュ(Cache): プロセッサと主記憶の間に挿入された記憶階層
缓存(cache)在设计的时候,需要先回答一个重要的问题:处理器是怎么知道数据是否在缓存中,并且正确的从缓存中找出想要的资料?
ダイレクト・マップ方式
direct-mapped方式:就是直接根据存储器的位置,把所有的block平均分配给缓存。如下图,内存内的block index结尾只要等与cache index,就代表block可以被放到该缓存的该位置(灰色部分,蓝色部分)
Tag:记录该cache所记录的资料在原本储存器中的位置。tag不需要完整记录该cache存放内容的储存器位置,只需要记录前面几个bit即可
valid bit:此外,cache还需要valid bit来记录cache是否包含有效信息。例如处理器刚启动时,cache内并没有任何东西,此时cache内容全部是无效的,需要过一段时间才能塞满内容
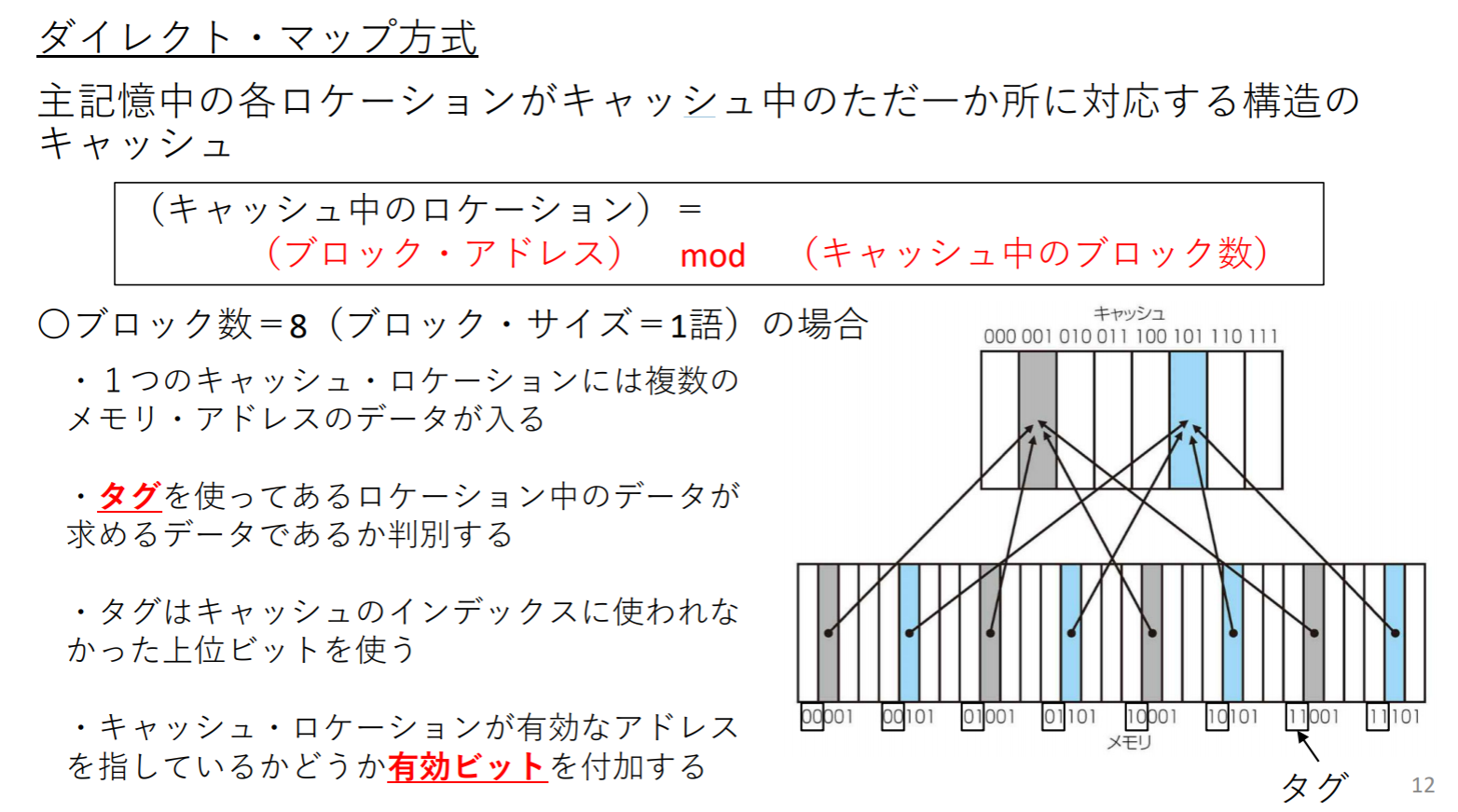
ブロック数 = 8の場合におけるキャッシュの推移
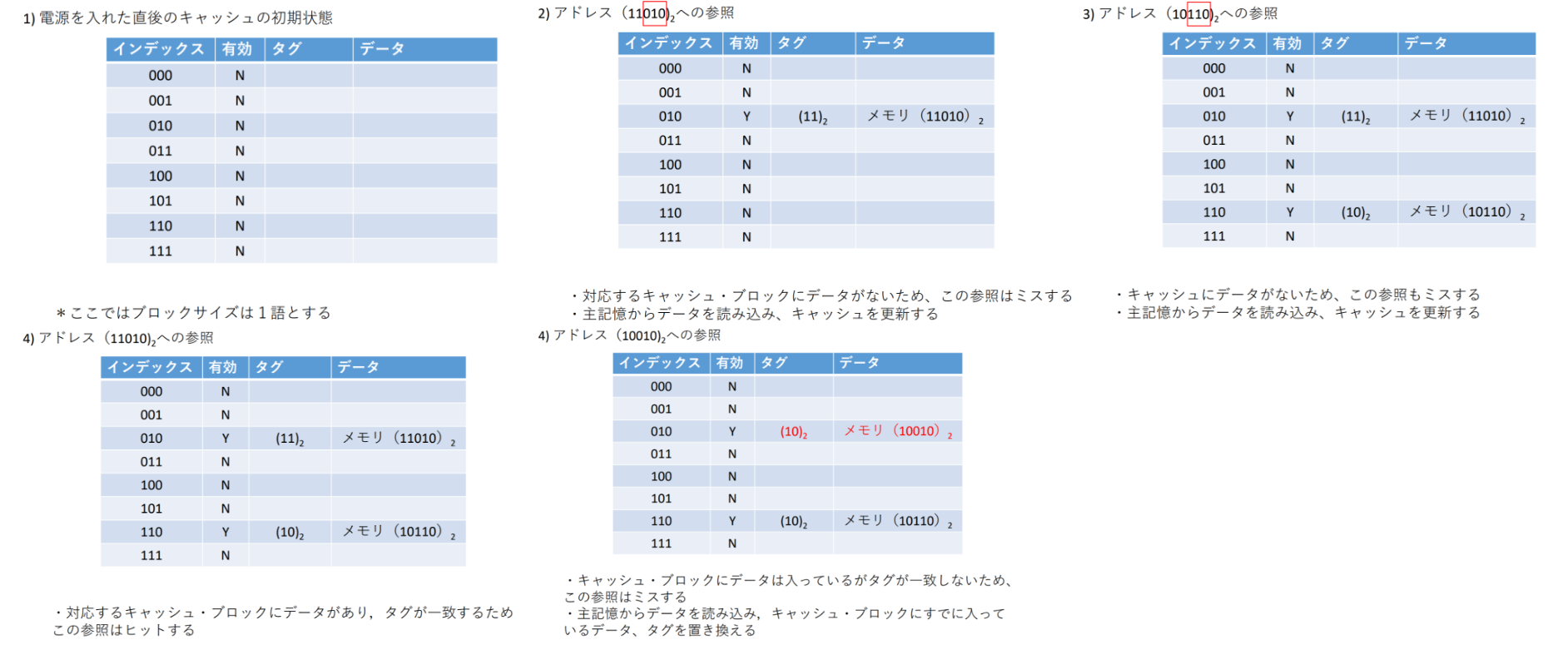
アドレスとキャッシュインデックスの対応は以下の図に示す
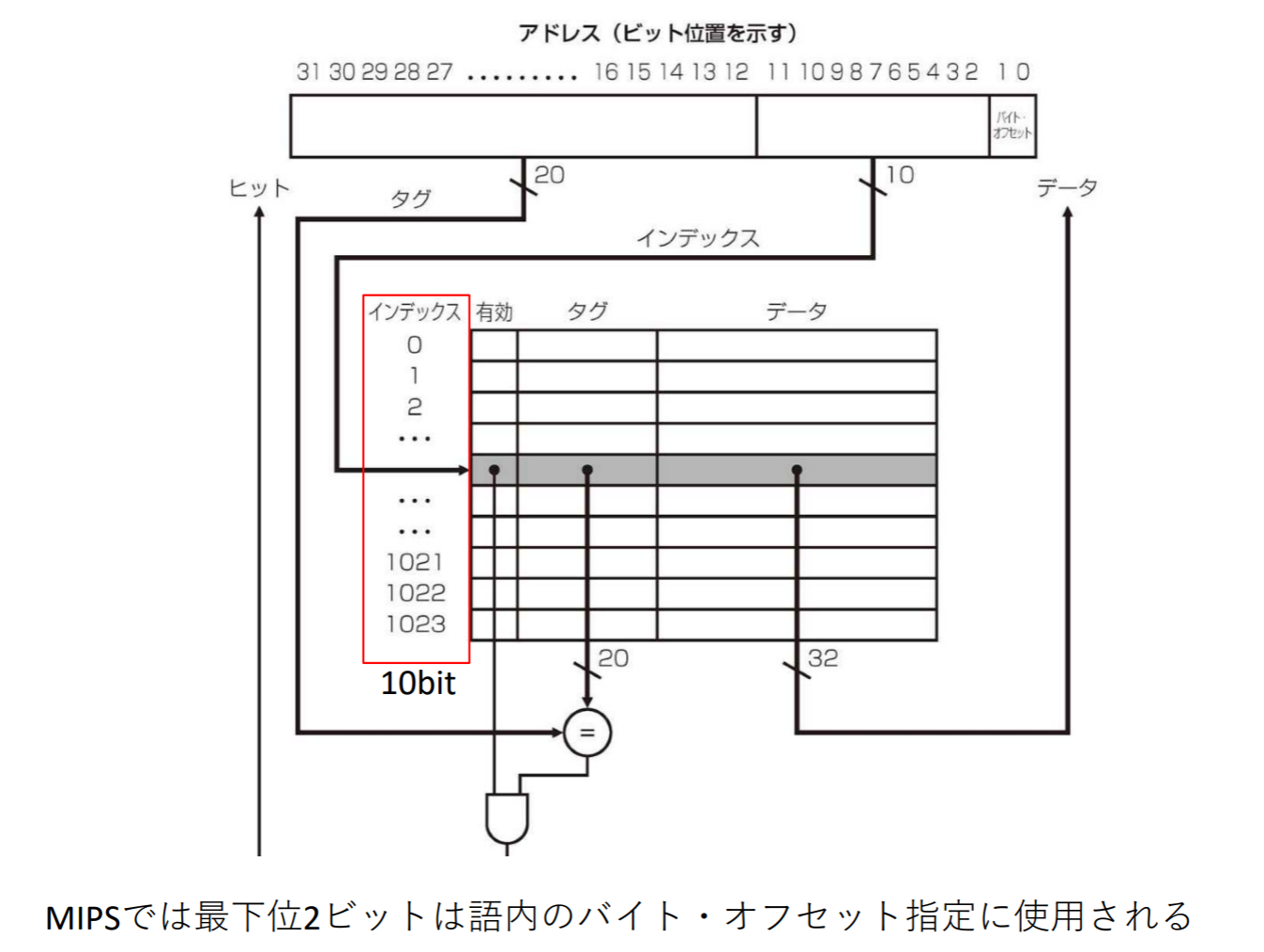
如图,这是一个32bit的address,direct-mapped到1024个block的cache。word是处理器指令存储内存的单位。在MIPS架构中,一个word是4个bytes,因此我们需要2bit来决定到底是该word的哪一个bytes。该图cache内1个block的大小是1个word,总计1024个block,所以需要10bits来表示该缓存的index,剩下的20bits作为tag。因此,此图意为取出2-11bit找到缓存index,并比较tag(12-31bit)决定是否hit,如果hit到就读出资料
实际上,一个block可能存放不只一个word。假设一个block存放 个word,所以1个缓存内有m个bit会被用来找该block的哪个word,有2bit会被用来找该word的哪个byte
キャッシュに必要な総ビット数
- のバイト・アドレス
- ダイレクト・マップ方式のキャッシュ
- キャッシュ容量 = ブロック ( をインデックスに使用)
- ブロック・サイズ = 語 (= )
- タグ・フィールド長 =
- 有効フィールドに が必要
キャッシュの総ビット数は
となり

キャッシュ・ミスの取り扱い
制御ユニットはキャッシュ・ミスを検出した場合、パイプラインをストールさせ、別の制御ユニットを用いて下位のキャッシュからデータを持ってこなければならない
命令呼び出し時のキャッシュ・ミスの対応:
- 元のPC値をメモリに送る
- 主記憶から読み出しを行うよう指示し、その完了を待つ
- キャッシュに該当するブロックに書き込みを行う
- 主記憶から読み出したデータ キャッシュのデータ部分
- アドレスの上位ビット タグ・フィールド
- 有効ビット 1(ON)を設定
- 命令実行を最初のステップから再開する
書き込みの取り扱い
キャッシュと主記憶の「⼀貫性(consistency)」が必要
- ライト・スルー方式: データを書き込む際、キャッシュと主記憶の両方に書き込むようにする方式
- ライト・バッファ: 主記憶に対する書き込み待ちのデータを蓄えておく場所
- ライト・バック方式: データを書き込む際、キャッシュの対応するブロックのみに書きこみ、修正されたブロックが置き換え対象になった時に主記憶に書き込む
課題7.1

キャッシュ性能の測定


平均メモリ・アクセス時間(AMAT)
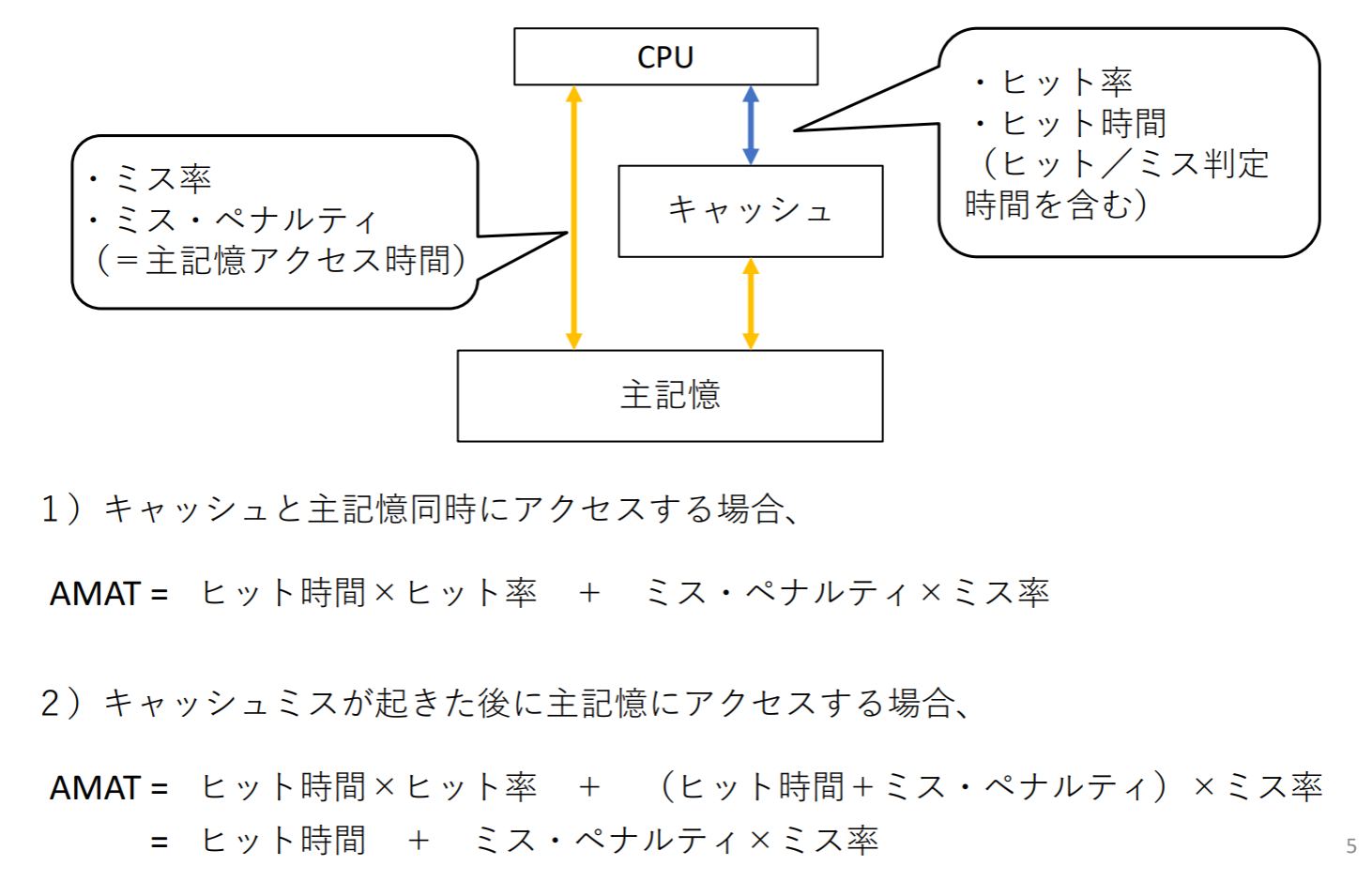

- AMAT = Time for a hit + Miss rate Miss penalty =
キャッシュサイズを増やすとミス率が下がる(ヒット率を上がる)及びヒット時間が増える(検索に時間がかかる)のため, ヒット時間増大の影響がヒット率を上回るとプロセッサの性能低下につながる
ブロック配置の方法
ヒット率を下げるためには, キャッシュサイズを大きくしたい, でもヒット時間大きくしたくない. ヒット時間を抑えつつキャッシュサイズを増やすにはどのようなキャッシュを配置すれば良いでしょうか?
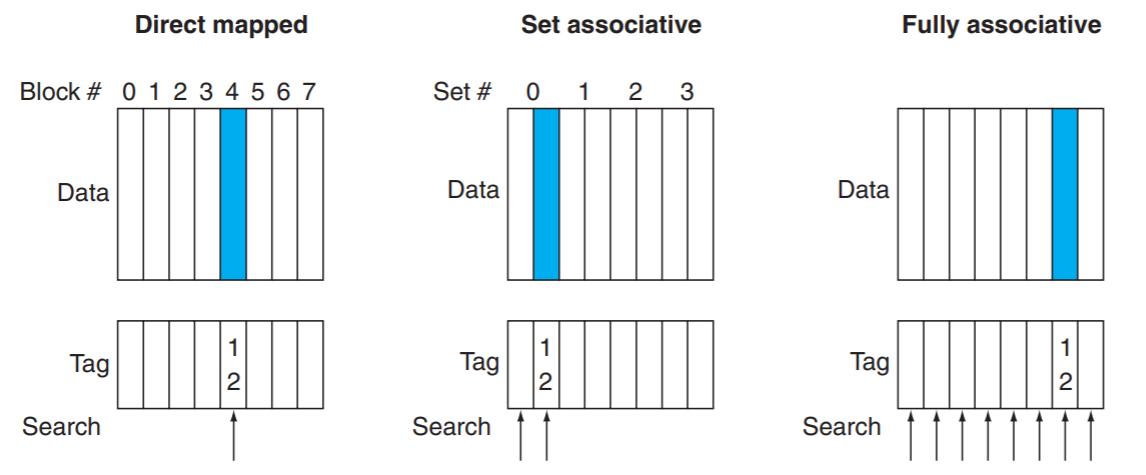
- ダイレクト・マップ方式: 主記憶のブロックが配置されるキャッシュ内のロケーションは一意に決まる
- セット・アソシアティブ方式: 主記憶のブロックが配置されるセット番号は一意に決まるが, セット中の任意のロケーションに配置される
- フル・アソシアティブ方式: 主記憶のブロックが配置されるキャッシュ中の任意のロケーションに配置される
直接映射高速缓存比全关联缓存便宜。因为整个缓存中只有一个标签比较器(Tag Comparator)。这和全关联缓存器中每一条线路都有一个比较器不同。在直接映射高速缓存中,地址冲突是存在的,这可能会影响cache的效果。给出一个内存地址后,index会选择缓存线路。如果目标TAG和缓存中的Tag相等,就达成一次Cache Hit。这条缓存中的数据会被发送给CPU。如果缓存中没有index对应的线路,我们需要去主存,主存中的数据替换了缓存中的index对应的线路的数据。如果线路中的数据是有效的并且被修改过。缓存必须把那个数据写进内存再扔掉。
一个N路组相联缓存由N个路组(N个直接映射高速缓存)组成。数据可以保存在任一路组中。这种模式是上面两种模式的中和。不像全关联缓存要遍历所有Tag,也不像直接映射高速缓存有那么多的数据冲突。(一个index对应N个路组,比只有1个路组冲突要少)。当一个内存地址交给相联高速缓存,index会选择这行中所有的路组的数据,并且比较任何一个tag是否相等,如果达成一个cache hit,这个数据就被送往CPU。如果遍历了所有路组,得到cache miss,我们就去内存中取数据,并且把这个index对应的路组中的某一个位置替换掉,替换的具体策略我们以后会提到。如果这个数据在cache中被写入过,那么这个数据需要被写进内存。
全关联缓存可以把数据放在任何地方。当一个内存地址送给一个全关联内存时,这个地址标签就和Cache中的所有有效线路(Valid Line)进行对比,如果tag相同,算作Cache Hit。这条线路的数据就被发送给CPU,否则算作一次Cache Miss。如果Cache中所有的线路都是有效的(Cache是满的),发生了一次Cache Miss。我们就需要做一次数据替换。如果被线路有效并且被修改过,那我们就必须把这线路中的数据写回主存。如果没被修改过,我们直接覆盖这线路。
セット・アソシアティブ方式
其他还有set associaltive的方式,也就是把cache分成多个set,CPU必须检查指定set内的每个block是否有可用的cache,最极端的情况下就是Fully Associative,也就是CPU要检查所有的block
主記憶のブロックを配置可能なセットが 個あり、各セット 個のブロックからなるセット・アソシアティブ方式をmウェイ・セット・アソシアティブ方式という
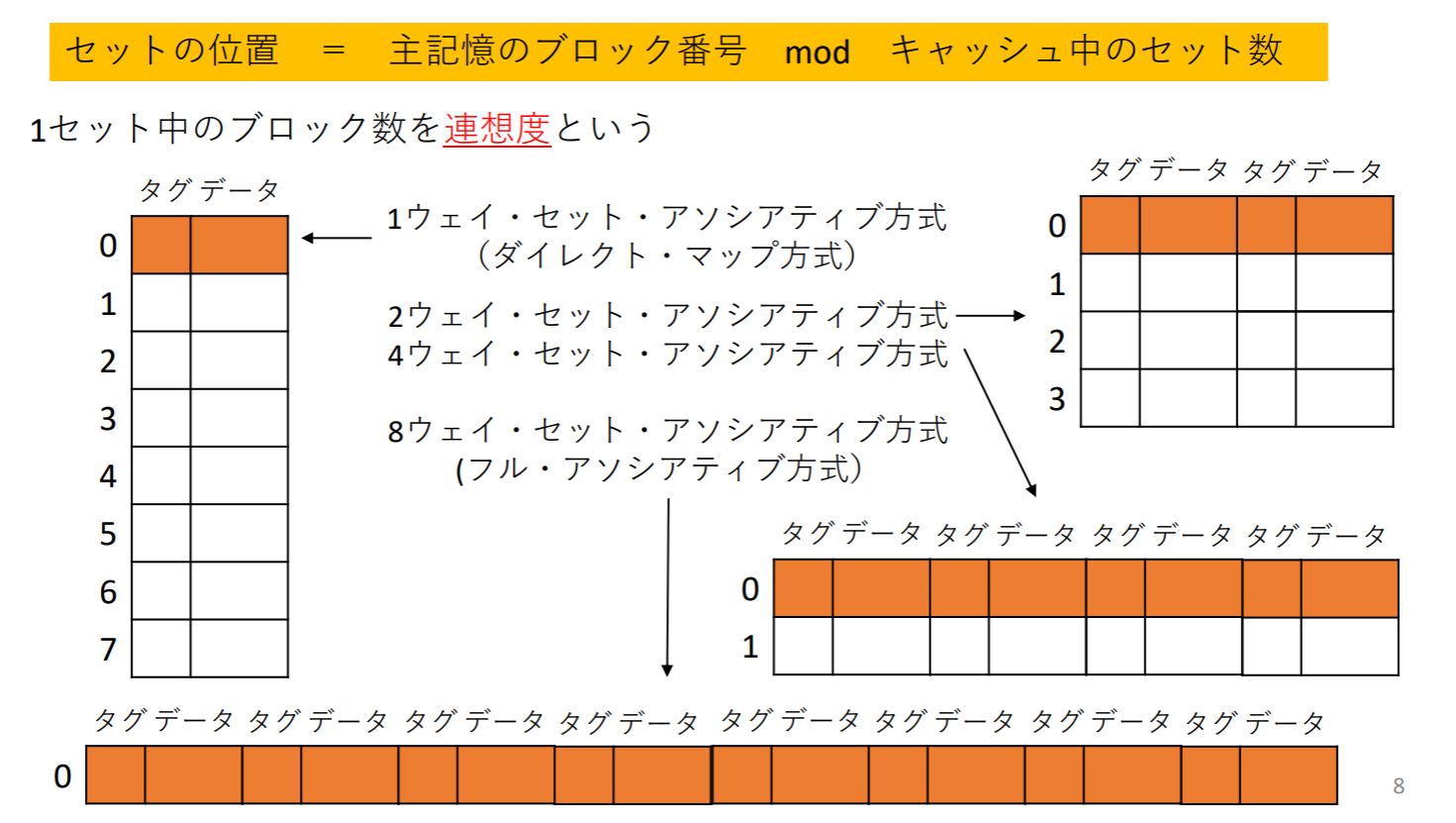
- 2ウェイ・セット・アソシアティブ方式: 連想度2, セット数4
- 4ウェイ・セット・アソシアティブ方式: 連想度4, セット数2
以下は4セット・アソシアティブ方式実装例。連想度4, セット数256からなるキャッシュになっている。セット番号は0-255なので、8bitで表現可能。
メモリアドレスの2-9bit目までの8bitをインデックスとして、10-31bit目までの22bitはタグになる。
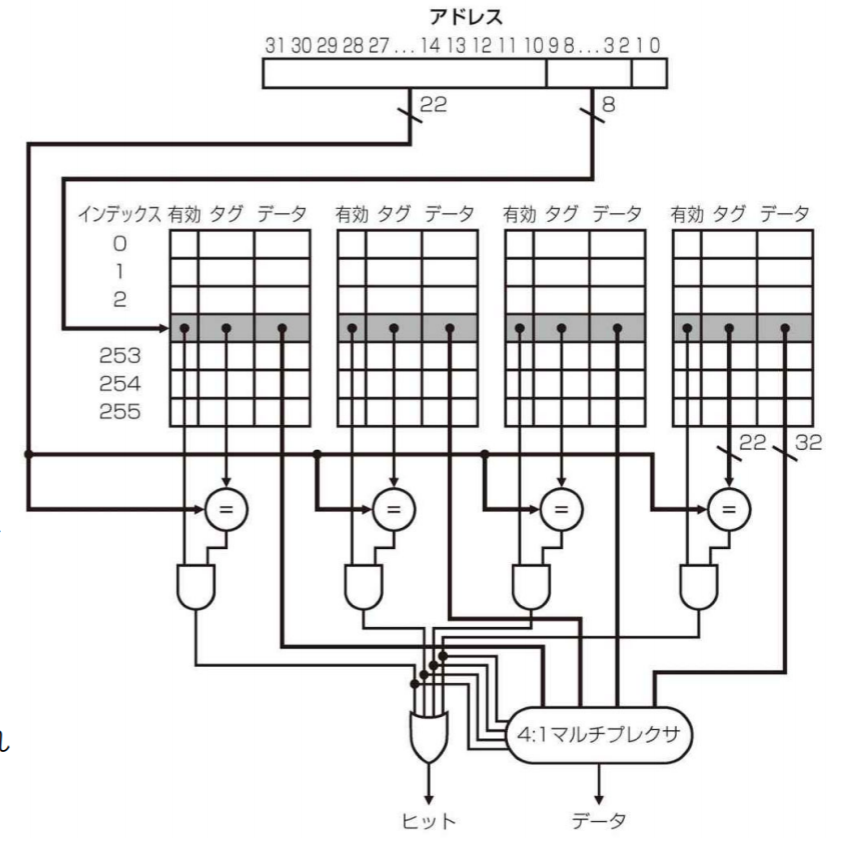
- アドレス構成
- タグ
- インデックス (セットの選択)
- ブロック内オフセット
- ハードウェアのコスト
- 比較器とマルチプレクサ
- 各ブロックにタグ
- 検索コスト
- 該当するセットを選択
- 選択したセットの中から該当タグの検索
- 置き換えブロックの選択
- LRU(Least recently used)法: 使用されずにいた時間が最も長いブロックを置き換える
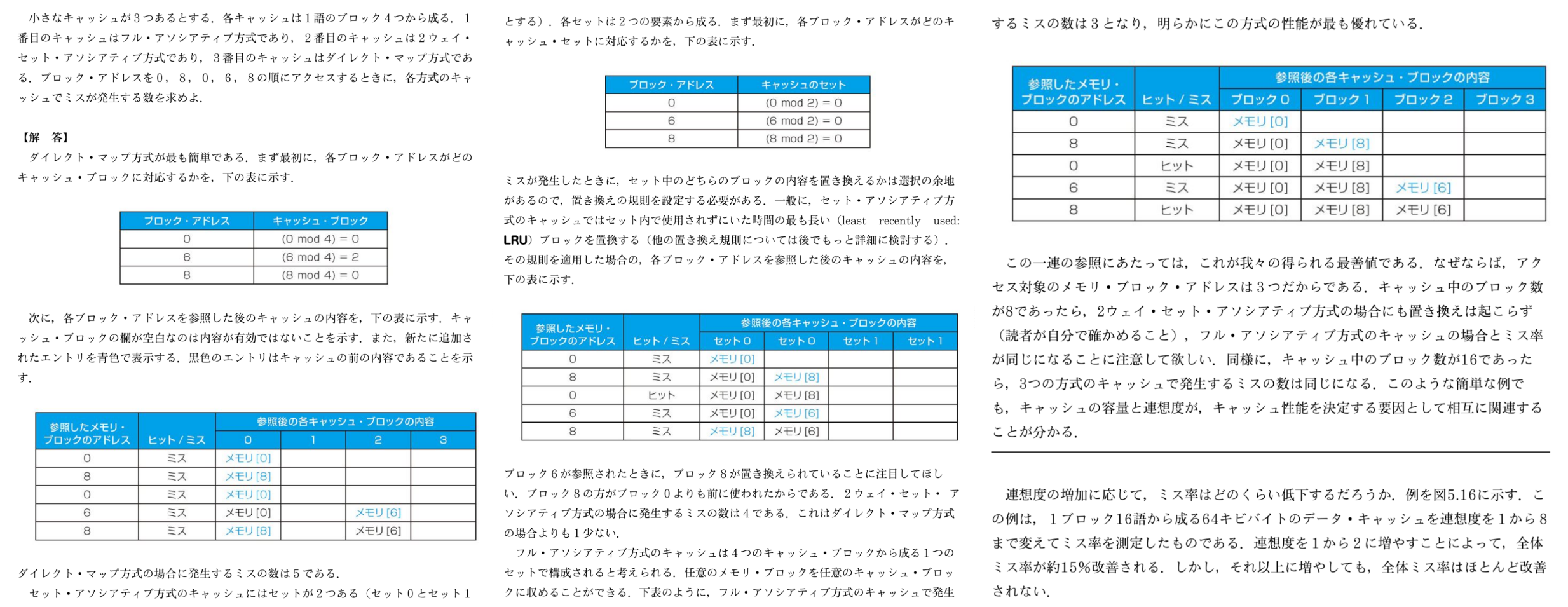
マルチ・レベル・キャッシュ
性能向上のためにプロセッサと主記憶の間に複数レベルのキャッシュを追加
設計指針:
- 1次(L1)キャッシュ
- ヒット時間を最小化
- クロック・サイクルを短縮
- キャッシュ容量、ブロックサイズを小さくする
- クロック・サイクルを短縮
- ヒット時間を最小化
- 2次(L2)キャッシュ
- ミス率を削減
- 主記憶アクセス時の長いミスペナルティを削減
- キャッシュ容量・ブロックサイズ大きくする
- 連想度も高める
- 主記憶アクセス時の長いミスペナルティを削減
- ミス率を削減
仮想記憶(Virtual memory)
仮想記憶: 2次記憶(SSD、磁気ディスク)に対して,主記憶にキャッシュの役割を持たせる仕組み
仮想記憶の目的
- 複数プログラム間でメモリを効率よく共有する
- 主記憶容量の限界に対処するプログラム上の負荷を軽減する
仮想記憶の機能
- 各プログラム独⾃のアドレス空間と物理アドレス空間の変換, プログラム間のアドレス空間の保護
- 主記憶(物理メモリ)と2次記憶とのやり取りの⾃動化
必要なデータを(高速な)主記憶に置き、当面必要ないデータを(低速な)2次記憶に置く
仮想記憶の仕組み
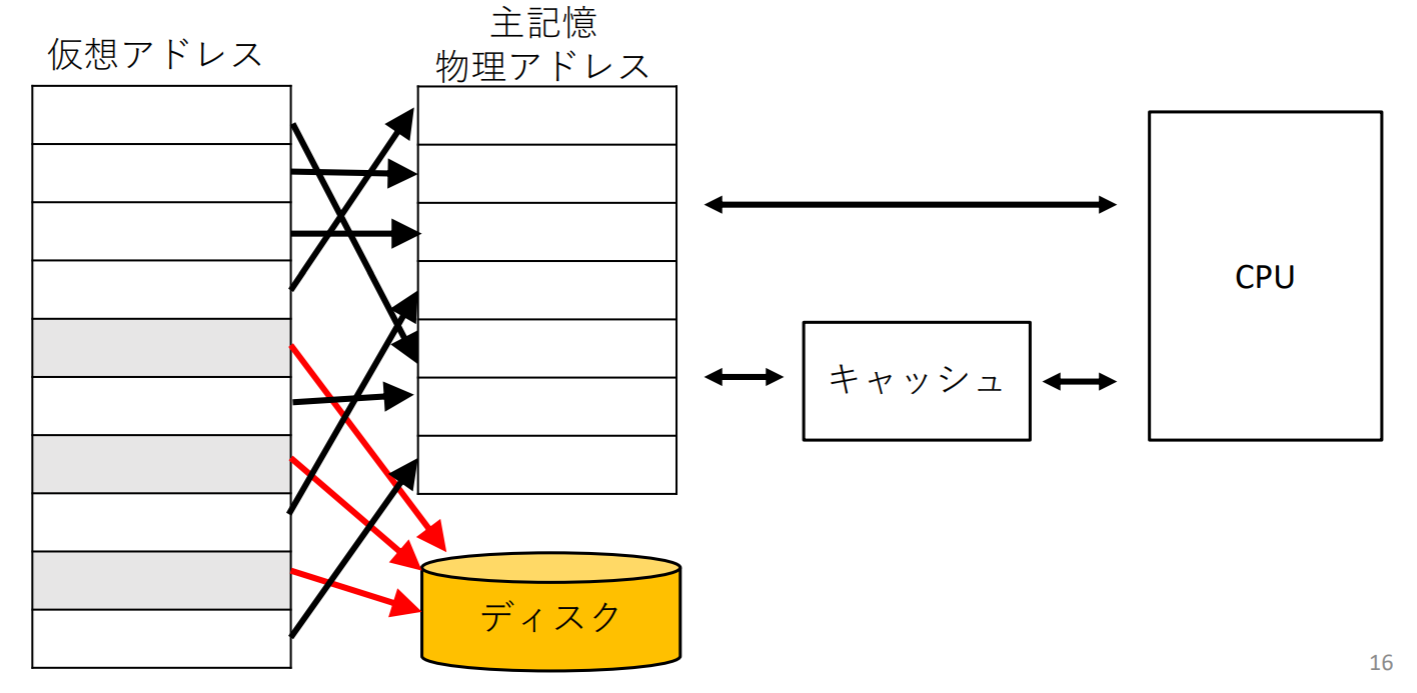
- 各プロセスに対して連続な仮想アドレスが与えられ,アドレス変換(アドレス・マッピング)によって物理アドレスに変換される
- アドレス変換はページ単位で行われる(キャッシュのブロックに相当)
- アクセスするデータが主記憶中にない場合、ページ・フォールトが発生する(キャッシュのミスに相当)
仮想アドレスと物理アドレスの対応
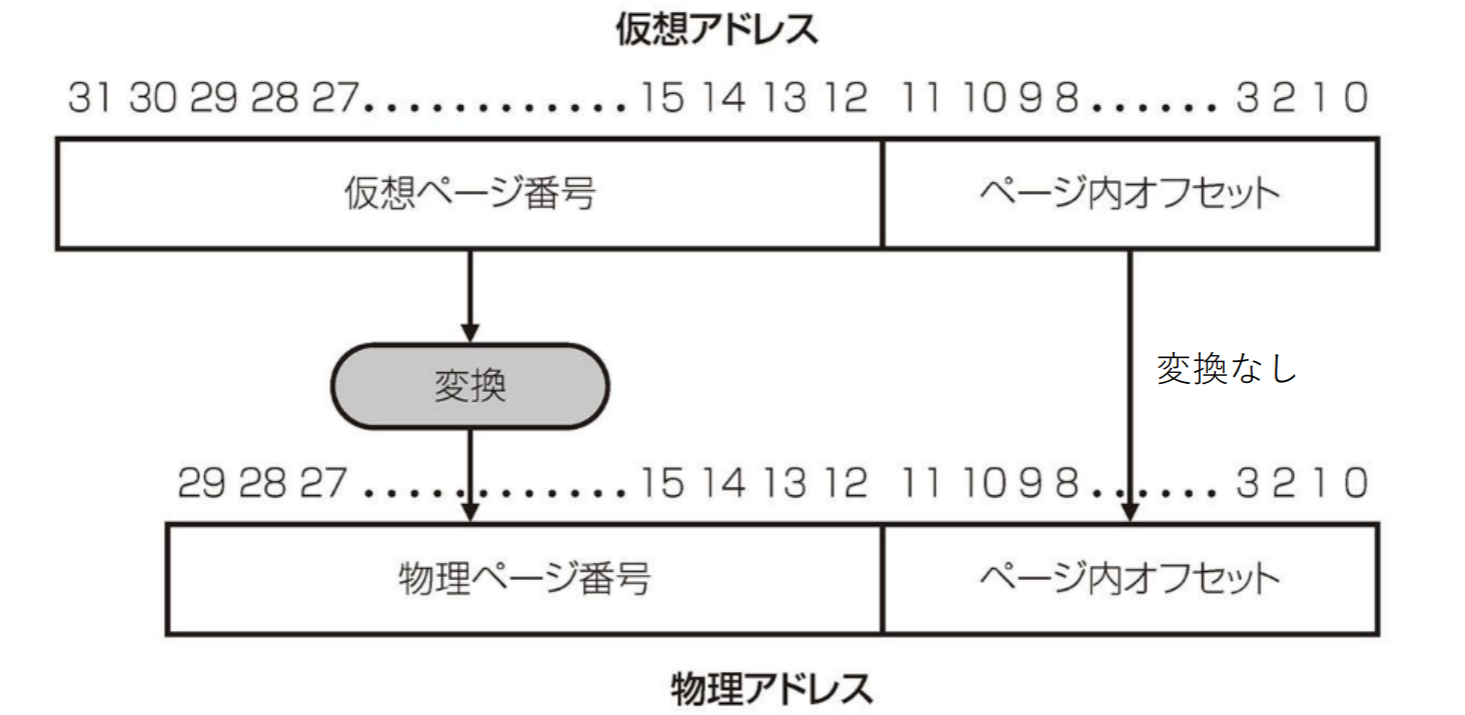
- ページサイズ:ページ内オフセットで決まる
- 物理ページ数:物理ページ番号からきまる
- 物理アドレスの最大容量は (仮想アドレス空間 )
仮想記憶システムの設計
- ページフォールトの発生低減
- ページ配置はフル・アソシアティブ方式
- ページ・テーブルを用いた検索
- ページ・フォールト
- ソフトウェア(OS)で例外処理する
- あらかじめディスク上にプロセスの全仮想記憶空間を予約(スワップ領域)
- あらかじめ各仮想ページがどの物理ページに割り当てられているかを記録するデータ構造を作成
- 割り当てる物理メモリがない時は置き換えるページの選択を行う
- 参照ビット(使用ビット)に基づくLRU
- 割り当てる物理メモリがない時は置き換えるページの選択を行う
- ソフトウェア(OS)で例外処理する
- ディスクへの書き込み回数削減
- ライト・バック方式
- ページ・テーブルにダーティ・ビットと付加
- ダーティ・ビットが付加されたページだけ書き戻す
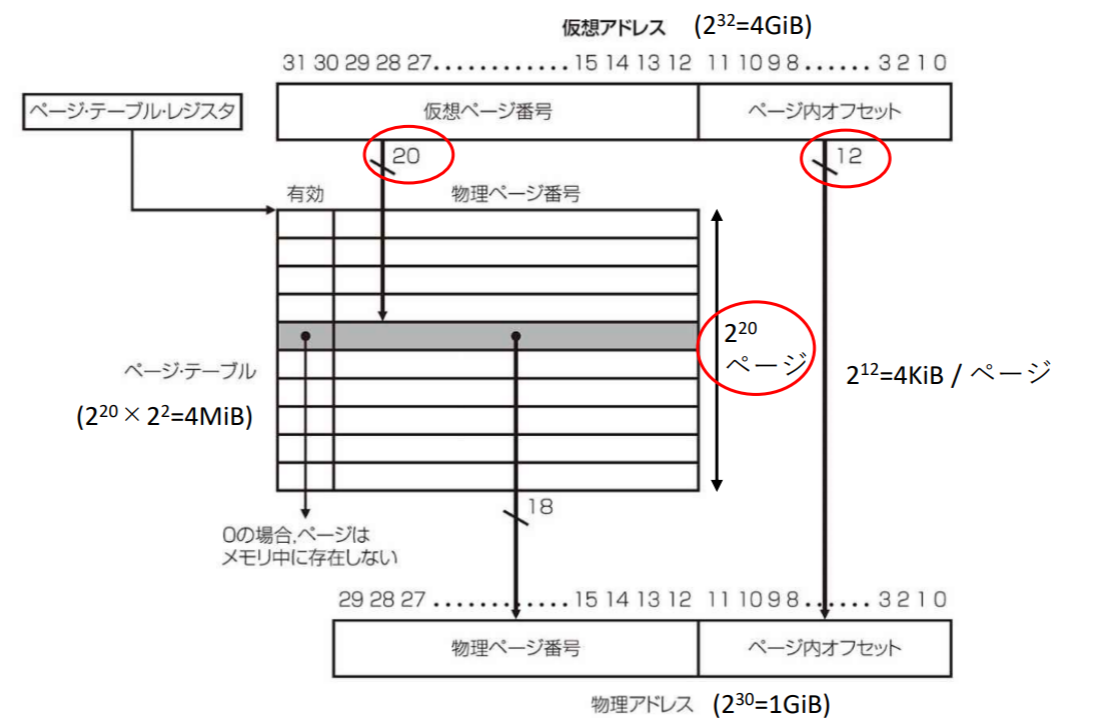
アドレス変換バッファ(TLB)
- ページ・テーブル(フル・アソシアティブ方式)に対するキャッシュ
- 最近使用されたアドレスの対応関係を記録する
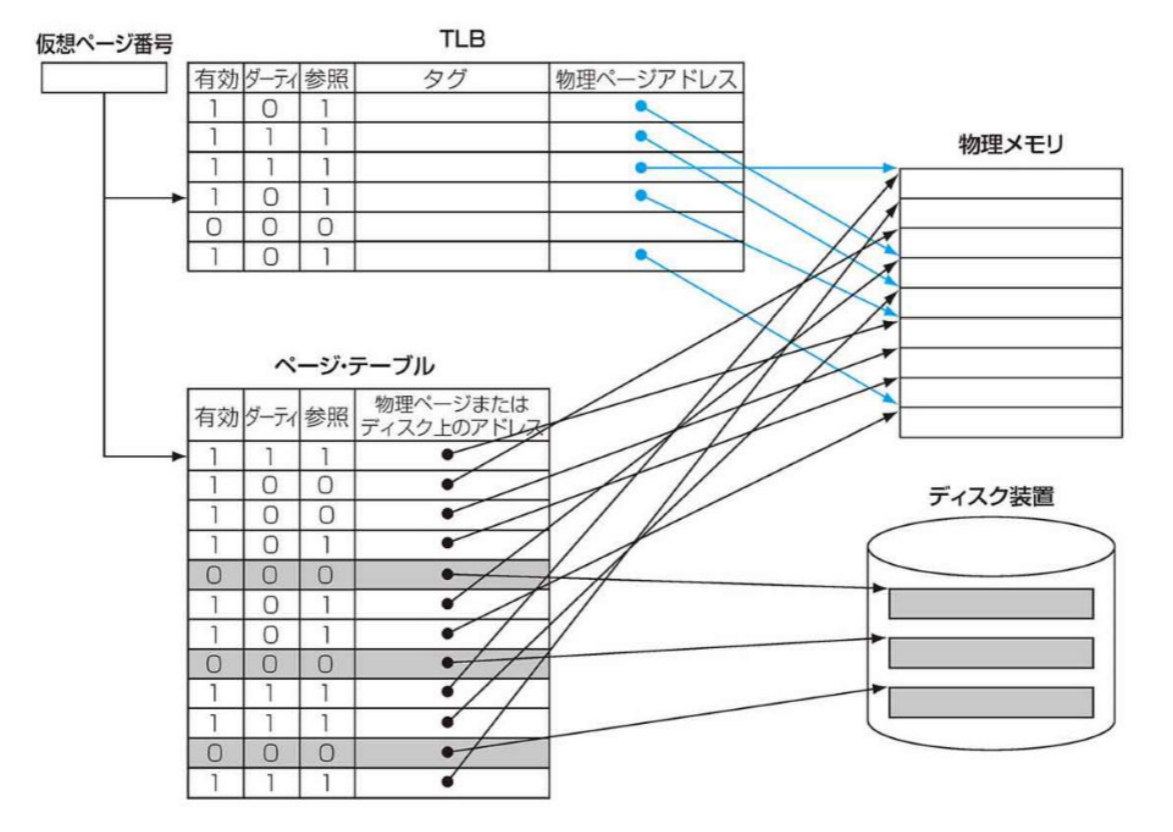
記憶階層の全体的な動作
記憶階層の3要素(TLB,ページテーブル,キャッシュ)の相互作用は次のようになる
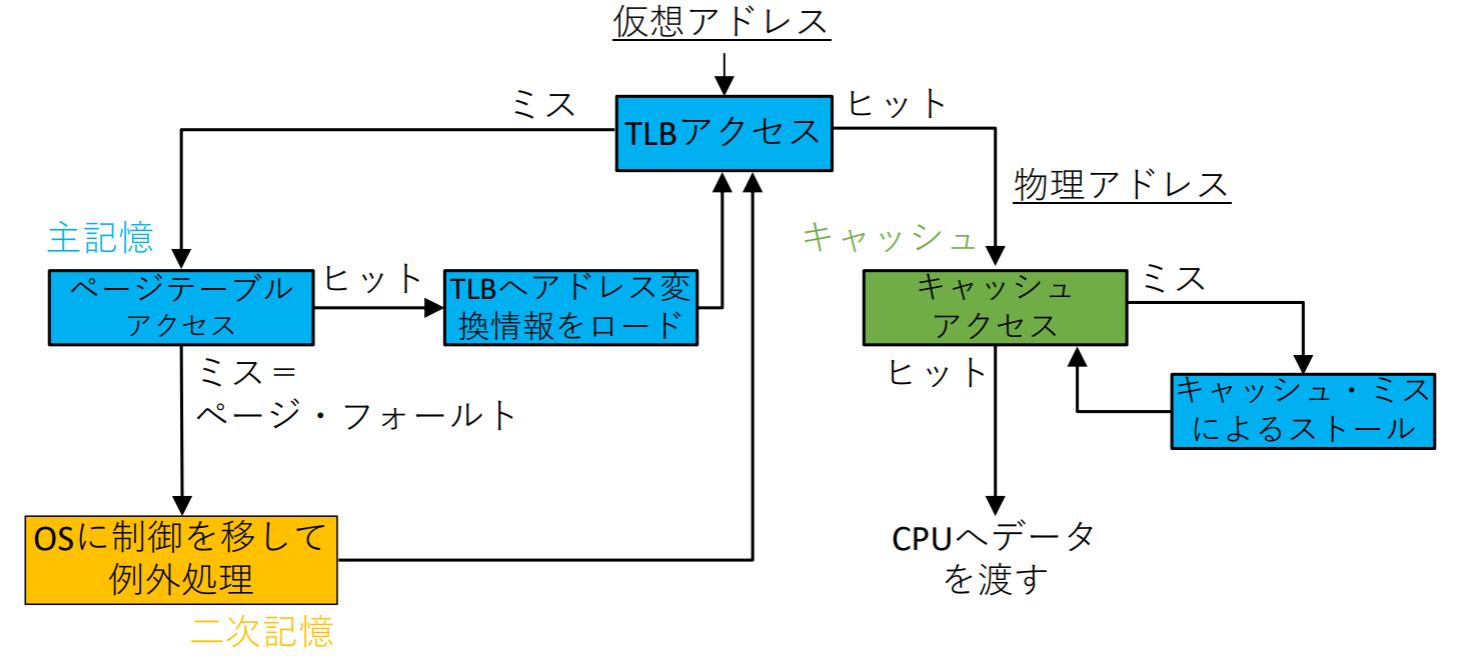
課題7.2

- address长32bit
- data容量:512B
- block size:32B
- block size = 32B = B, offset(2bit-offset + 3block offset)
- block数 = data容量(缓存大小) / block size = 个block
- 因为是2-way set associaltive方式,平均1-way有 个block,即3 bits来表示该缓存的index
- address = tag + index + offset = tag + index + (bit-offset + block offset)可知等下的24bits作为tag
課題7.3

- data容量:32KB = B
- block size:32B
- 由 block size = 32B = B, 计算 offset(2bit-offset + 3block offset)
- 计算block数:data容量(缓存大小) / block size = 个block
- 因为是2-way set associaltive方式,平均1-way有 个block,即9 bits来表示该缓存的index
- address = tag + index + offset = tag + index + (bit-offset + block offset)可知等下的18bits作为tag
課題7.4

- Total CPI = 1 Primary stalls per instruction + Secondary stalls per instruction
まとめ
- 計算機の基本構造
- コンピュータの言葉
- 命令セットアーキテクチャ
- ハードウェアを動作させるための命令、命令セットおよびコンピュータにおける算術演算について学ぶ
- ソフトウェア
- プログラムの翻訳
- 高水準プログラム言語がどのようにして実行プログラムへ変換されるかを学ぶ
- プロセッサ
- データパス
- 例外と割り込み
- パイプライン
- 並列処理
- プロセッサの実装で使われる基本的な原理と技法について学ぶ
- メモリ
- メモリ・テクノロジ
- キャッシュと仮想記憶
- メモリの階層構造、高速化技法について学ぶ
- 性能
- コンピュータの性能評価
- コンピュータの性能を判定する各種の方法について学ぶ
- 仮想化
- 仮想化技術
- 仮想化の実現で用いられる原理と技法について学ぶ
参考文献
- Computer Organization and Design: The Hardware/Software Interface