CS专业课学习笔记
Pattern recognition紹介
パターン認識は自然情報処理のひとつ。画像・音声などの雑多な情報を含むデータの中から、一定の規則や意味を持つ対象を選別して取り出す処理である
パターン認識が扱う問題
- 前立腺がんのリスク因子を特定する
- 録音された音声を分類する
- 個人属性情報(demographics)や、食習慣、検診記録から心臓発作になるかどうか予測する
- スパムメールを検出する
- 手書きの郵便番号を識別する
- 組織サンプルの遺伝子情報を使って癌のクラスわけを行う
- 衛星写真から、土地の利用目的分類を行う
機械学習・統計的学習とは
機械学習とは、人間が自然に行っている学習能力と同様に機能をコンピュータで実現しようとする技術や手法のこと。
統計的学習はモデリングに重点を置くのに対して、機械学習は、最適化理論からの学習のアプローチである場合は多い。
元々は、人工知能分野の一部として研究されていたが、機械学習は統計学と密接な関わりを持つようになり「統計的学習」と言われるようになった
応用分野:
- パターン認識
- データマイニング
- 自然言語処理
- 音声処理、画像処理
- バイオインフォマティクス(Bioinformatics)
- 脳科学
- 農業
- 経済・金融
パターン認識はICT(information and Computer Technology)の要素技術
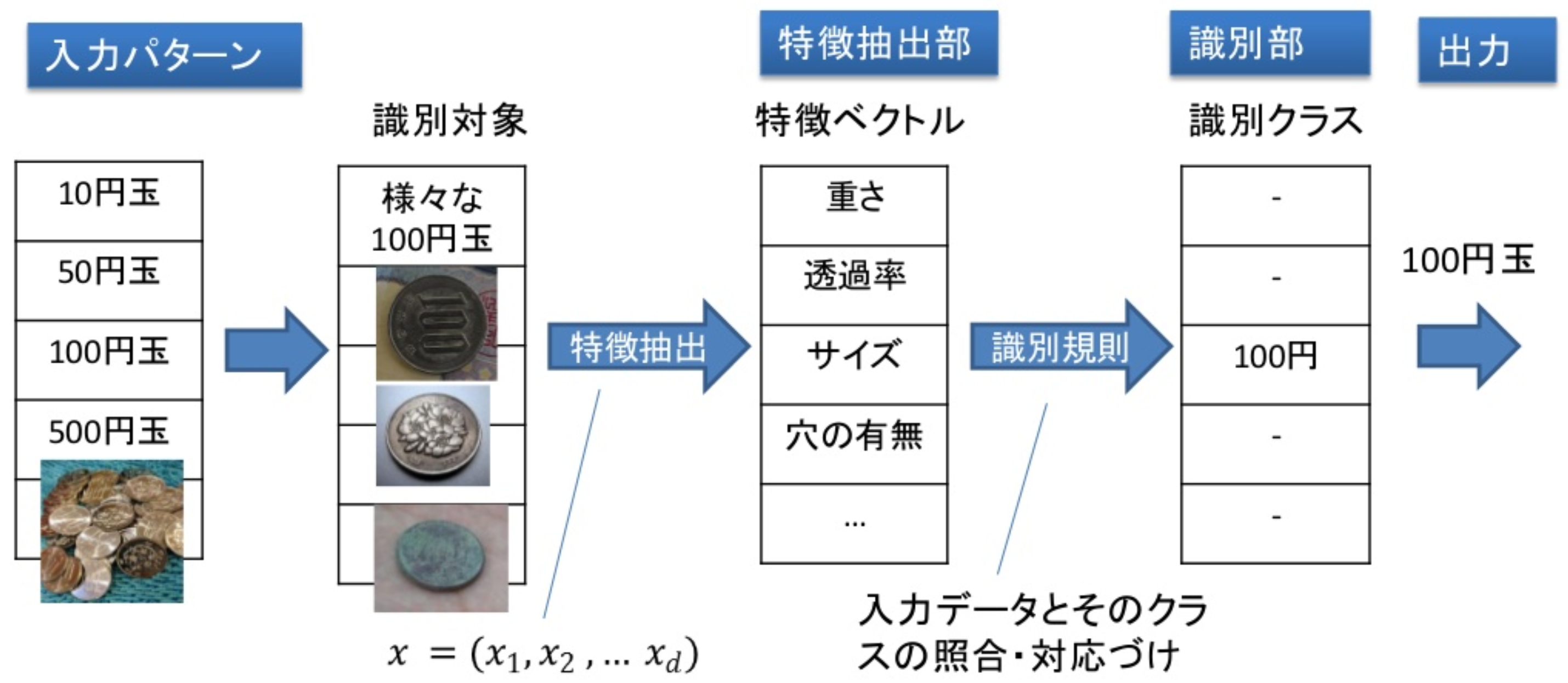
特徴抽出
入力データから抽出されるたくさんの特徴をまとめること
例: 硬貨の識別問題なら、硬貨の重さ、サイズ、穴の有無など
特徴ベクトル
特徴量をベクトルの形に並べたもの
このような特徴量のベクトルを入力として、予め用意しておいた「型・類型」に当てはめること
例: 硬貨の識別問題なら、1, 5, 10, 50, 100, 500円,(それ以外)のどれかの「パターン(型)」に対応させる
この識別(分類分け)するためにの規則のことを識別規則という
識別規則を作るためには、入力データとそのクラスを対にした、たくさんのデータ(学習データ)を学習する必要がある
学習データを用いて設計したシステムが、未知の入力データに対しても正しいクラスを識別できるかが問題で、そのような能力を汎化能力という。汎化性能の高い識別器を作ることが目的
特徴の型
抽出された特徴量は、定性的特徴(非数値データ)と定量的特徴(数値データ)に大別される
- 非数値データはさらに、名義尺度、順序尺度に分類される
- 性別と血液型は順序関係がないから、名義尺度である
- 一方、S, A, Bの成績評価や癌の進行を表すステージは順序関係があるので、順序尺度である
- 数値データもさらに、比例尺度、間隔尺度に分類される
- 比例尺度は長さや重さなどゼロを基準に倍数の意味がある尺度である
- 感覚尺度はテストの点や気温など、数値の間隔が意味を持つ尺度である
定性的な特徴を表現するために、符号を用いる。例えば、二つのクラスラベル([勝・敗])([合格・不合格])を表すのに、「1と-1」や「-1と1」で符号化する
パターン認識で扱う、型や類型などのクラスは定性的特徴である
識別規則と学習法
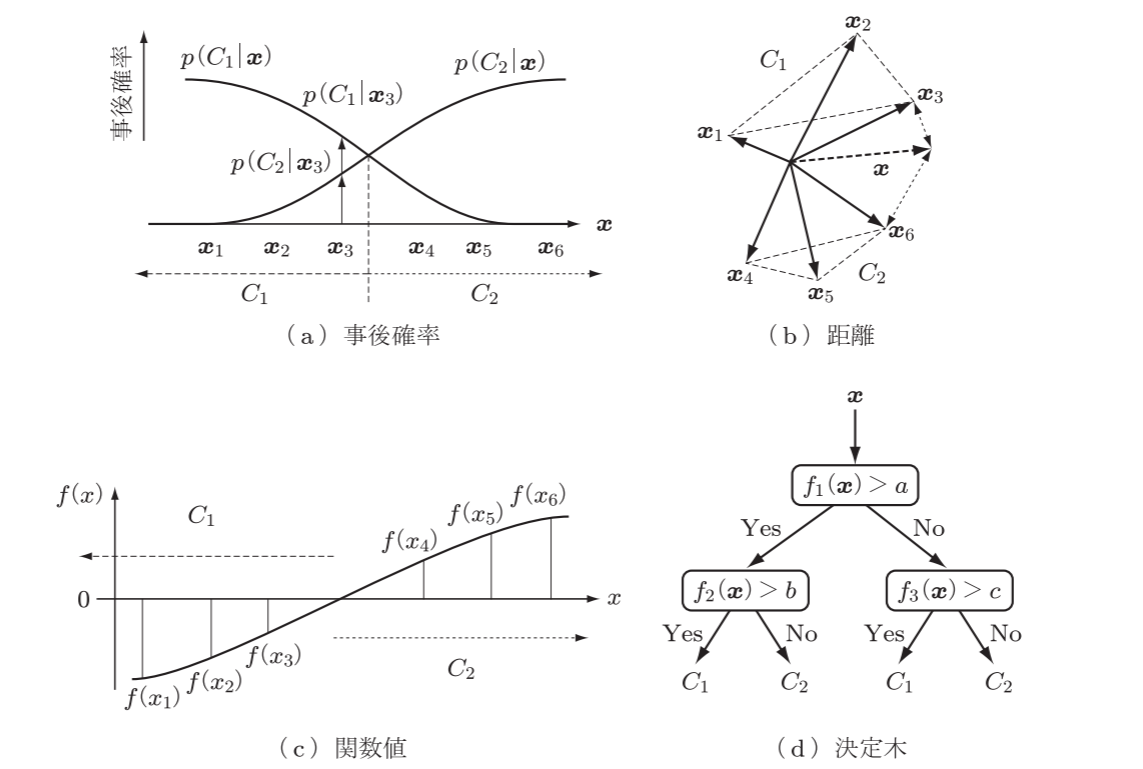
代表的な識別規則の構成法
- 事後確率による方法: ベイズの最大事後確率法(線形判別分析)
- 距離による方法: 最近傍法
- 関数値による方法: パーセプトロン型学習回路(ニューラルネットワーク、ロジスティック回帰)、サポートベクターマシン
- 決定木による方法
識別規則の構成法
入力データxからクラスCi∈ω={C1,⋯,Ck}への写像を識別規則という
代表的な識別規則には、事後確率による方法、距離による方法、関数値による方法、決定木による方法がある
- 事後確率による方法: 特徴ベクトルの空間に確率分布を仮定し、事後確率が最大のクラスに分類する
- ベイズ識別規則が代表例で、線形判別分析もこのクラスに該当する
- 距離による方法: 入力ベクトルxの各クラスの代表ベクトルとの距離を最小にするクラスに分類する
- 関数値による方法: 関数の正負、あるいは最大値(他クラスの場合)でクラスを決める
- パーセプトロン型学習回路(ニューラルネットワーク、ロジスティック回帰)、サポートベクターマシンが代表例
- 決定木による方法: 識別規則の真偽に応じて次の識別規則を順序適用し、決定木でクラスを決める
教師付き学習(Supervised learning)
識別規則が関数値による方法としよう: y=f(x)
2クラス問題の線形識別関数の場合、識別規則は
y=f(x;w)=w1x1+⋯+wdxd=wTx
ここで、xは入力ベクトル(特徴量のベクトル)、wはパラメータで、識別クラスはyの正負によって決まるとする。
学習の目的は、パラメータwを調整すること
学習データは入力データ(特徴ベクトル)xとクラスデータy(教師データ)のペア(x,y)である
2クラスの識別問題を正負の値で識別する場合, クラスデータをt∈{−1,1}で表すとする.
他クラスの場合は, ダミー変数表現を用いてt=(0,1,0,0,0,0,0,0,0,0)Tのように表すと, この表現は, 10クラスある中の2番目のクラスに属していることを表している.
学習データがN個あるとき, 入力データと教師データの対を次のように表す.
(xi,ti),i=1,⋯,N
教師なし学習(unsupervised learning)
入力データのクラスを自動的に生成する場合がある。クラスタリング(Cluster analysis)など。この時、クラスデータyは存在しないので、教師なし学習という。自己組織型学習ともいう
一部のデータに教師を付き、他は教師なしで学習を行うことを半教師付き学習(形質導入学習)という
汎化能力
学習とは、学習データに対する識別関数の出力値と教師データとの誤差が最小になるように、識別関数のパラメータを調整することである。
しかし、学習で得られた識別関数が学習データに含まれていない未知データに対して上手く働くという保証はない。
そこで、学習データから取り除いておいたテストデータを用いて性能評価を行い、未知データに対する動作をテストデータに対する誤り率という形で予測することが行われている。
未知のデータに対する識別能力を汎化能力という
未知のデータに対する識別誤差を汎化誤差という
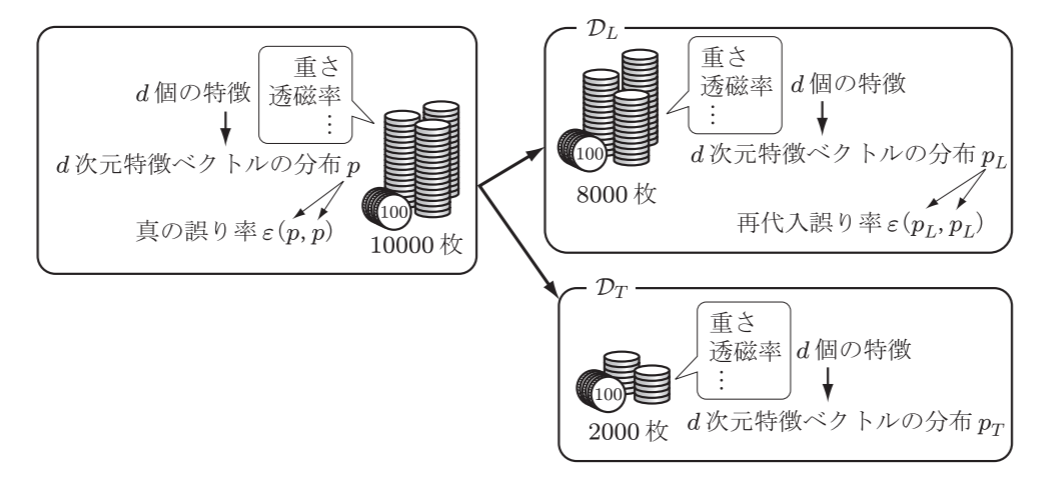
学習データとテストデータの作り方
- 手元にあるデータを分割して学習データセット: DLとテストデータセット: DTを作る
- 特徴量ベクトルはd次元とし, その確率分布をpL,pTと表す
- 学習データセットDLを使って, DTをテストしたときの誤り率をϵ(pL,pT)と表す.
- 母集団の特徴ベクトルの確率分布をpとし, 真の分布とする.
- pLとpTはランダムなサンプルから推定された確率分布なので, 真の分布pの各特徴と同じにならない. このずれを偏り(バイアス))という
- 真の誤り率ϵ(p,p)は真の分布pに従う学習データを用いて識別規則を作成し, 真の分布pに従うテストデータを用いてテストした場合の誤り率を表す
- 再代入誤り率とは, pLからサンプリングしたデータを用いて識別規則を作成し, 同じデータでテストしたときの誤り率である
手元にあるデータを学習用とテスト用に分割する代表的な方法には、次のようなものがある。
ホールドアウト法(Holdout法)
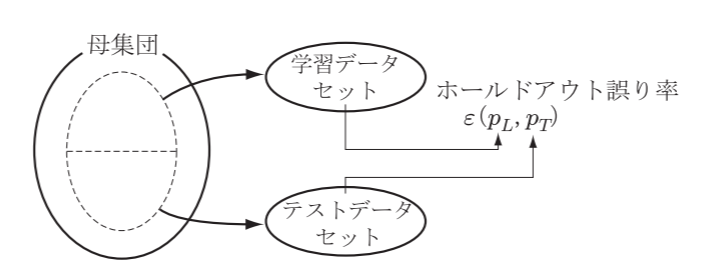
手元のデータを2分割し, 一方を学習データ(pL), もう一方をテスト(pT)のために取り置いて誤り率を推定するために使用する
- ホールドアウト誤り率といい, ϵ(pL,pT)で表す.
真の誤り率と再代入誤り率, ホールドアウト誤り率の関係は次の通り
EDL{ϵ(pL,pL)}≤ϵ(p,p)≤EDT{ϵ(pL,pL)}
手元のデータが大量にある場合を除いて, 良い性能評価を与えない欠点がある
非線形回帰
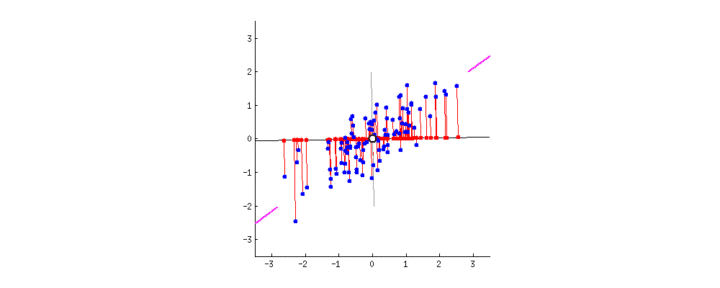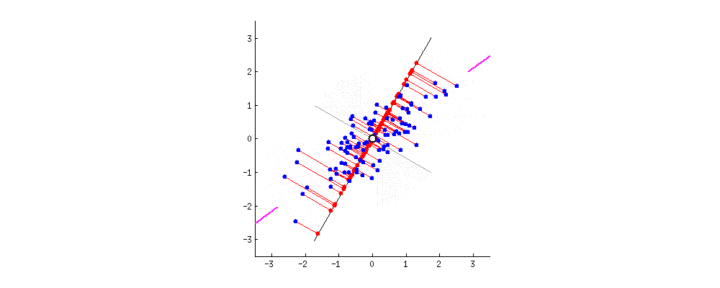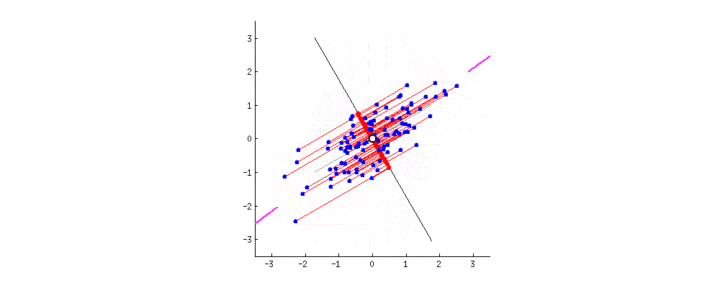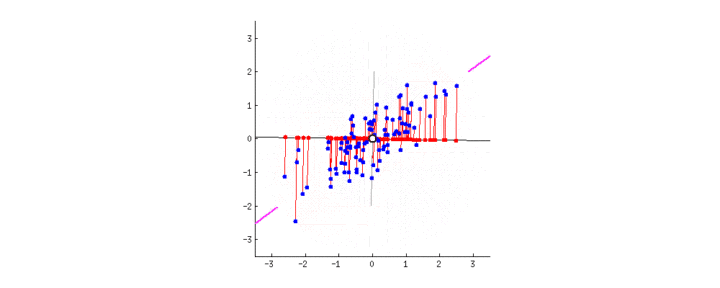
次の関数からデータが生成されているとする
f(x)=0.5+0.4×sin(2πx)+ϵ=h(x)+ϵ
関数h(x)を次のp次多項式で近似する
y(x;a)=a0+a1x+⋯+apxp,a=(a0,⋯,ap)T
近似の良さは平均二乗誤差(MSE; mean square error)で評価する
MSE=∫(y(x;D)−h(x))2p(x)dx=E{(y(x;D)−h(x))2}
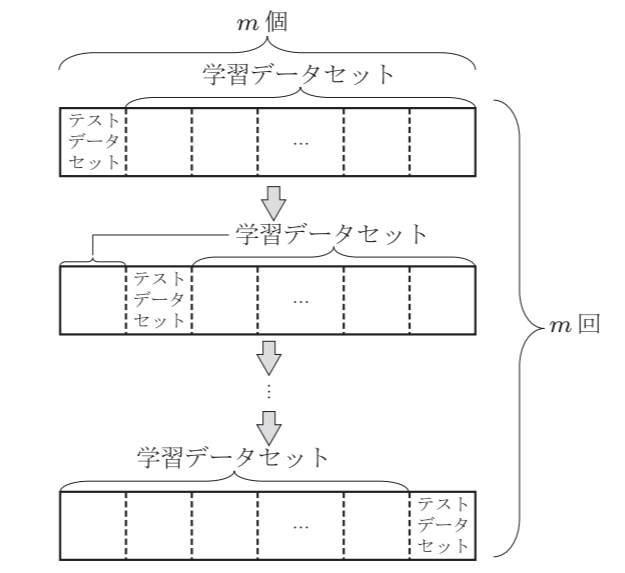
交差確認法(Cross Validation:CV)
手元の各クラスのデータをm個のグループに分割し, m−1個のグループのデータを使って識別器を学習し, 残りの一つのグループでテストを行う.
これをm回繰り返し, それらの誤り率の平均を性能予測値とする.
i番目のグループを除いて学習し, i番目のグループでテストしたときの誤り率をϵ−iとすると, 識別規則の誤り率は
ϵ=m1i=1∑mϵ−i
となる.
K-分割交差検証法(K-fold cross validation)
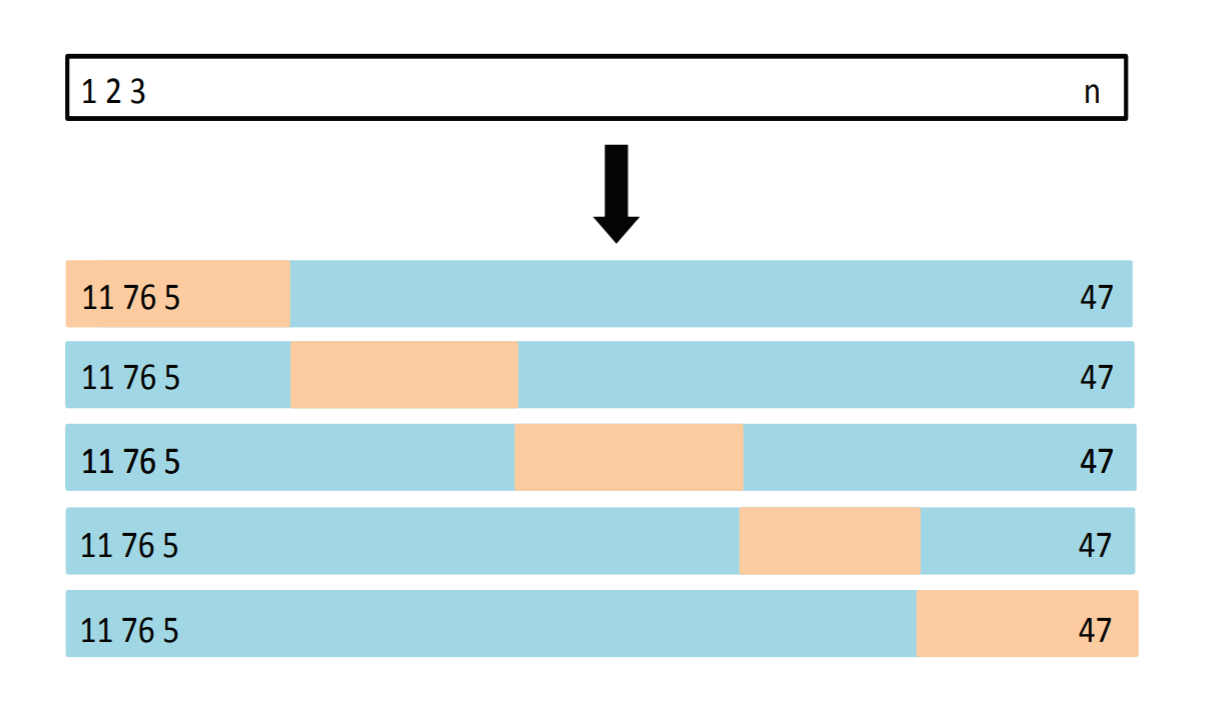
データを均等にK分割する(K=5)
一つ抜き法(LOOCV)
交差検証法において, データの数とグループの数を等しくした場合. ジャックナイフ法ともいう
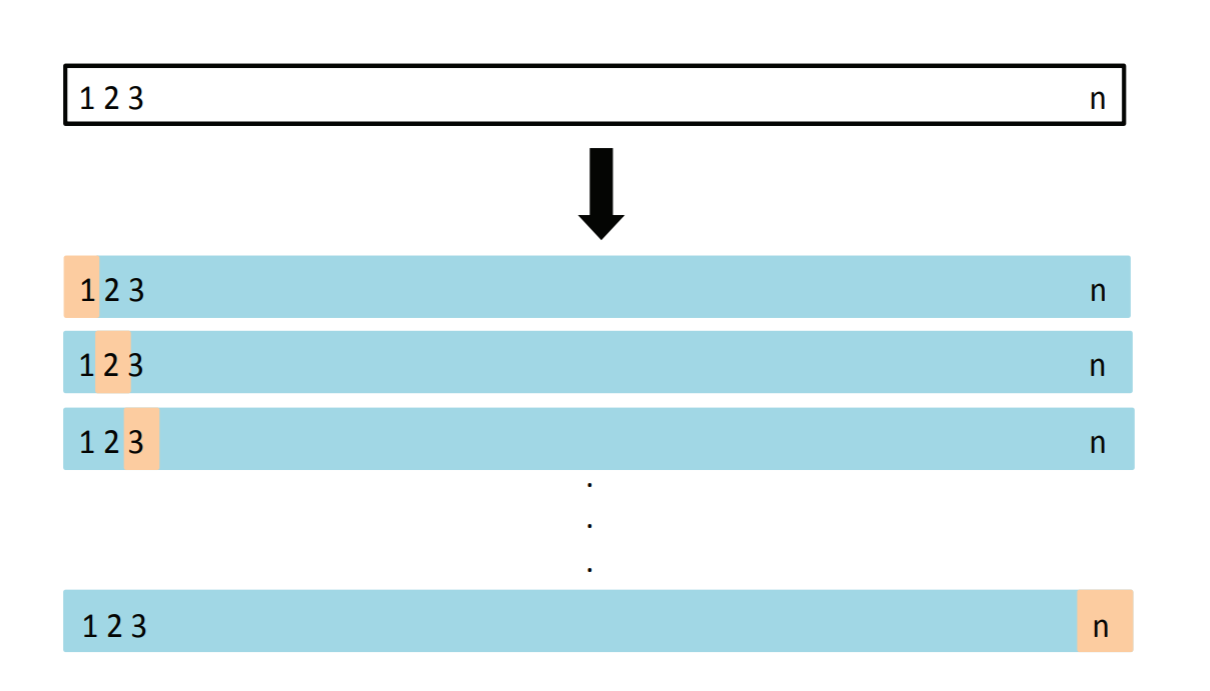
一つ抜き交差確認法 (LOOCV), 学習データ(青いところ)を使ってテストデータ(ベージュ)を予測する. 全部のパターンで計測した予測誤差の平均が CV.
ブートストラップ法(bootstrap)
再代入誤り率のバイアス補正に使用する. N個のデータで学習したデータで再代入誤り率を計算し,ϵ(N,N)と表す
N個のデータからN回復元抽出して, 学習データを作成し, 再代入誤り率を計算し, ϵ(N∗,N∗)とする
バイアスは, 元のデータ集合 N をテストデータとして得られる誤識別率ϵ(N∗,N)との差
bias=ϵ(N∗,N∗)−ϵ(N∗,N)
で推定する. ブートストラップサンプルをいくつも作って, 誤識別率の平均値を計算しそれをbiasとすれば, 誤識別率の予測値ϵは
ϵ=ϵ(N,N)−bias
で与えられる
汎化能力の評価法とモデル選択
学習データによってパラメータ調整を行い、誤り率を評価しても、目標以上の精度が出ない場合は識別関数を変える必要がある。誤り率が最も小さくなるパラメータを選択する方法をモデル選択という
バイアス・分散トレードオフ
近似した関数は目標関数h(x)との誤差の項(バイアス)と訓練データから生まれる誤差の項(分散)に整理できる
- バイアス
- h(x)との誤差
- モデル精度の悪さ
- 分散
- 訓練データから生まれる誤差
- モデル作成の不安定さ(再現性の悪さ)
- モデルが単純
- 性能は良くないが、教師データに対して安定
- 高バイアス・低バリアンス
- モデルが複雑
- 性能は良いが、教師データに対して不安定(過学習など)
- 低バイアス・高バリアンス
- 過学習
- 訓練誤差は小さくなっているが汎化誤差(テスト誤差)が大きく乖離した状態を過適合/過剰適合/過学習と呼ぶ
ベイズ識別規則
医者の診断では, いろんな検査項目をもとに, 健康かそうでないかを判断する. 検査項目の値が高くても健康な人もいるし, 正常の範囲内でも健康でないかもしれない. このように, 検査項目の値の影響は確率的である.
ベイズ識別規則では, 入力データxとクラスyに確率分布を仮定する.
病気の診断では, 検査対象を調べると健康な人と病気の人の割合が大きく異なることが一般的である. このときクラスの学習データのサンプル数に偏りが生じる (不均衡データ; Umbalanced data という).
ROC曲線とは, このようなデータに対して有効な性能評価法である.
ベイズの定理
ベイズ識別規則は, 次の事後確率が最大になるクラスにデータを分類する.
観測データをx, 識別クラスをCi(i−1,⋯,K)とする
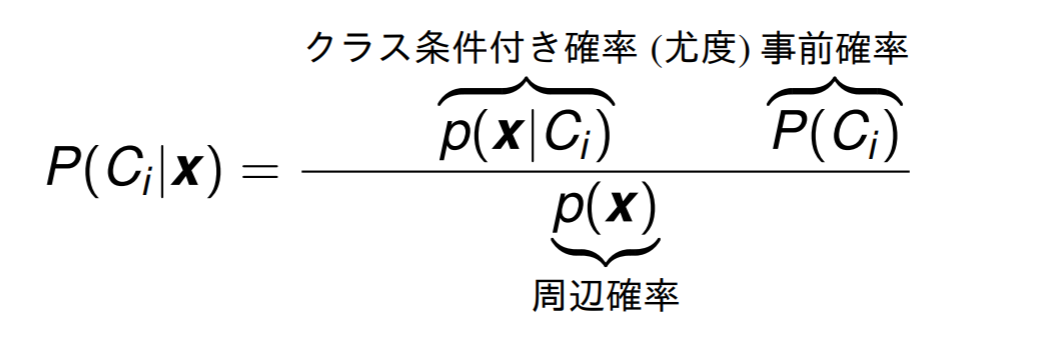
これはベイズの定理と呼ばれる. 同時分布は
p(Ci,x)=p(Ci ∣ x)p(x)=p(x ∣ Ci)P(Ci)
となる.
クラス識別は, 事後確率が最大になるクラスにデータ x を割り付ければ良い, すなわち, 入力データ x に対して, 2クラス Ci,Cj の事後確率を計算し, P(Ci ∣ x)>P(Cj ∣ x) ならば, x は Ci に属すると識別する
多クラスの識別は, 識別クラス = argmaxip(x ∣ Ci)P(Ci) とすれば良い.
事後確率
事後確率 P(Ci ∣ x) は観測データ x が与えられたもとで, そのデータがクラス Ci に属する条件付き確率である
事前確率
事前確率 P(Ci) はデータ分析者は, 各クラス Ci の生起確率を予め用意しないといけない.
尤度
クラス条件付き確率 (尤度) p(x ∣ Ci) はクラスが与えられたもとで,観測データの確率分布を表している.
周辺確率
周辺確率 p(x) は, 観測データ x の生起確率である. 周辺分布は, 同時分布から, 興味のない変数を積分や総和を取ることで消去することで得られた. このような操作を周辺化という.
p(x)=i=1∑Kp(Ci,x)
例題1

以下の手順で健康か否かの事後確率を求める.
- クラス条件付き確率を求める. 周辺分布P(S ∣ G),P(T ∣ G)と同時分布P(S,T ∣ G)の両方で
- 同時確率を求める. P(S,T,G)
- 周辺確率を求める. P(S,T)
- 事後確率を求める. P(G ∣ S,T)
- S と T の間には条件付き独立性を仮定する
- クラス事前確率は表から明らかなので, 次のようにして計算する
P(G=1)=1000800=54,P(G=0)=1000200=51
クラス条件付き確率を求める
S に関するクラス条件付き確率は次の通り
P(S=1 ∣ G=1)=800320=52,P(S=0 ∣ G=1)=800480=53P(S=1 ∣ G=0)=200160=54,P(S=0 ∣ G=0)=20040=51
T に関するクラス条件付き確率は次の通り
P(T=1 ∣ G=1)=800640=54,P(T=0 ∣ G=1)=800160=51P(T=1 ∣ G=0)=20040=51,P(T=0 ∣ G=0)=200160=54
次に、Gを与えた時に、SとTの条件付き同時確率を求める。P(S,T ∣ G)はGが1あるいは0の場合に、SとTの両方の変数の関係性を表している。
ここで、条件付き独立性を仮定しているので、同時確率が周辺確率の積で得られる
P(S=1,T=1 ∣ G=1)=P(S=1 ∣ G=1)⋅P(T=1 ∣ G=1)=258P(S=0,T=1 ∣ G=1)=2512P(S=1,T=0 ∣ G=1)=252P(S=0,T=0 ∣ G=1)=253P(S=1,T=1 ∣ G=0)=254P(S=0,T=1 ∣ G=0)=251P(S=1,T=0 ∣ G=0)=2516P(S=0,T=0 ∣ G=0)=254
同時確率を求める
Gを与えた時のSとTの条件付き確率を求めたので、その確率に周辺確率を乗じることで得ることができる。
P(S=1,T=1,G=1)=P(S=1,T=1 ∣ G=1)⋅P(G=1)=12532P(S=0,T=1,G=1)=12548P(S=1,T=0,G=1)=1258P(S=0,T=0,G=1)=12512P(S=1,T=1,G=0)=1254P(S=0,T=1,G=0)=1251P(S=1,T=0,G=0)=12516P(S=0,T=0,G=0)=1254
周辺分布を求める
先程求めたSとTとGの3変数の同時確率から、変数Gを消去してあげれば、SとTの周辺分布が得られる
Gの消去方法は、Gは離散なのでGの台で総和を取れば良い
P(S=1,T=1)=P(S=1,T=1,G=1)+P(S=1,T=1,G=0)=12536P(S=0,T=1)=P(S=0,T=1,G=1)+P(S=0,T=1,G=0)=12549P(S=1,T=0)=P(S=1,T=0,G=1)+P(S=1,T=0,G=0)=12524P(S=0,T=0)=P(S=0,T=0,G=1)+P(S=0,T=0,G=0)=12516
事後確率を求める
S,T,Gの同時確率をSとTの周辺確率で除せば良い
P(G=1 ∣ S=1,T=1)=P(S=1,T=1)P(S=1,T=1,G=1)=98P(G=1 ∣ S=0,T=1)=P(S=0,T=1)P(S=0,T=1,G=1)=4948P(G=1 ∣ S=1,T=0)=P(S=1,T=0)P(S=1,T=0,G=1)=31P(G=1 ∣ S=0,T=0)=P(S=0,T=0)P(S=0,T=0,G=1)=43P(G=0 ∣ S=1,T=1)=P(S=1,T=1)P(S=1,T=1,G=0)=91P(G=0 ∣ S=0,T=1)=P(S=0,T=1)P(S=0,T=1,G=0)=491P(G=0 ∣ S=1,T=0)=P(S=1,T=0)P(S=1,T=0,G=0)=32P(G=0 ∣ S=0,T=0)=P(S=0,T=0)P(S=0,T=0,G=0)=41
これで、入力データS,Tの情報からGの事後確率を得ることができた。後は、各条件の時に事後確率の大小を比較して識別すれば良い
- 事後確率を次の表にまとめると(赤字が健康と識別された確率)
| (S,T) |
(1, 1) |
(0, 1) |
(1, 0) |
(0, 0) |
| P(G=1∣S,T) |
98 |
4948 |
31 |
43 |
| P(G=0∣S,T) |
91 |
491 |
32 |
41 |
ϵ∗=s,t∈{0,1}∑min{P(G=1 ∣ S,T),P(G=0 ∣ S,T)}⋅pS,T(S,T)=91×12536+491×12549+31×12524+41×12516=12517
- S,T=1の場合、事後確率の高い健康のクラスに識別される
- 喫煙の習慣があって、お酒を飲まない人は事後確率の高い不健康のクラスに識別される
- 喫煙も飲酒の習慣のある人の方が、喫煙も飲酒もしない人よりも健康である確率が高い
喫煙も飲酒の習慣もある人の場合、健康のクラスに識別されるので、91の不健康の人も健康に識別されてしまう。これがS,T=1の場合の誤り率
以下、SとTの全ての場合について誤り率を求めて、その条件の同時確率で重み付けをすれば良い。求めた誤り率は12517≃13.6%
尤度比(事前確率の比率)
クラス条件付き確率と事前確率の積で識別している
⎩⎪⎪⎨⎪⎪⎧p(x ∣ Ci)⋅P(Ci)>p(x ∣ Cj)⋅P(Cj)⇒Cip(x ∣ Ci)⋅P(Ci)<p(x ∣ Cj)⋅P(Cj)⇒Cj
この式より, 尤度比で識別規則を構成してもよい
⎩⎪⎪⎨⎪⎪⎧p(x ∣ Cj)p(x ∣ Ci)>P(Ci)P(Cj)⇒Cip(x ∣ Cj)p(x ∣ Ci)<P(Ci)P(Cj)⇒Cj
尤度比が事前確率の比 P(Cj/Ci)=hij よりも大きければクラス i に識別する.
誤り率最小化
ベイズ識別規則の誤り率 ϵ(x) は事後確率の小さい方なので
ϵ(x)=min{P(C1 ∣ x),P(C2 ∣ x)}
これを条件付きベイズ誤り率という. ベイズ誤り率は条件付きベイズ誤り率の期待値
ϵ∗=E{ϵ(x)}=∫R2p(x ∣ C1)P(C1)dx+∫R1p(x ∣ C2)P(C2)dx
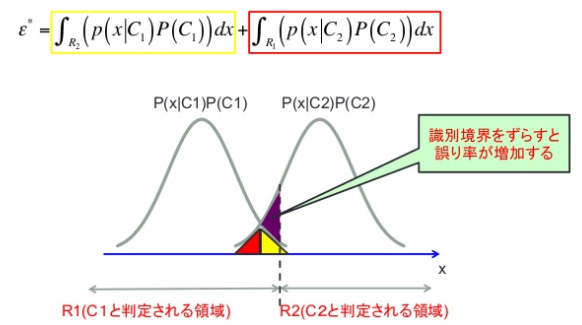
ベイズの識別規則によって識別境界が定められているとすると,
- R2の領域ではP(x ∣ C1)P(C1)<P(x ∣ C2)P(C2)
- R1の領域ではP(x ∣ C2)P(C2)<P(x ∣ C1)P(C1)
最小損失基準
誤りを犯すことによる危険性 (リスク) を考える. 誤りによって発生する危険性はクラス間で対称ではないから.
Lijは真のクラスがCjのときCiと判断することによる損失を表す
データ x をクラス Ci と判断したときの損失は
r(Ci ∣ x)=k=1∑KLikP(Ck ∣ x)
- P(Ck ∣ x)は観測データxをCkと判断する確率
識別規則は, 損失がもっとも小さいクラスに識別する
識別クラス=iargminr(Ci ∣ x)
このとき損失の期待値は
r=E{r(x)}=∫R1+R2min{r(C1 ∣ x),r(C2 ∣ x)}p(x)dx
最小損失基準に基づく識別の例

期待損失最小化
期待損失は次のようにして計算された
r=E{r(x)}=∫R1(L11p(x ∣ C1)P(C1)+L12p(x ∣ C2)P(C2))dx+∫R2(L21p(x ∣ C1)P(C1)+L22p(x ∣ C2)P(C2))dx
期待損失が最小になるクラスに識別すればよいので, 識別規則は次のようになった
L11p(x ∣ C1)P(C1)+L12p(x ∣ C2)P(C2)<L21p(x ∣ C1)P(C1)+L22p(x ∣ C2)P(C2)⇒C1
L11p(x ∣ C1)P(C1)+L12p(x ∣ C2)P(C2)>L21p(x ∣ C1)P(C1)+L22p(x ∣ C2)P(C2)⇒C2
L11,L22 は正しく識別できているので, 損失を考える必要はない, そこで L11<L12,L22<L21 を仮定しよう. すると次の識別規則が得られる.
(L21−L11)p(x ∣ C1)P(C1)>(L12−L21)p(x ∣ C2)P(C2)⇒C1
ROC曲線
識別性能の指標に受信者動作特性曲線 (ROC 曲線) がある
ROC曲線は, 偽陽性率と真陽性率の関係をグラフに表したもの
偽陽性率も真陽性率も, 本来偽 (真) であるものの中から計算されるので, 真のクラスと偽のクラスのデータ数に大きな差があってもROC は大きく影響を受けない.
ベイズ識別規則のように識別境界を移動することで識別クラスを制御できるものがある.
混同行列(Confusion Matrix)
2クラス問題では, 対象 x が1つに属していると判断する場合を p(positive), 属していないと判断する場合を, n (negative) と表記する.
- p∗,n∗はxの真のクラスを表すとする
- この識別の様子を混同行列としてまとめることができる
|
識別クラスp |
識別クラスn |
行和 |
| p∗ |
TP(True Positive): 真陽性 |
FN(False Negative): 偽陰性 |
P=TP+FN |
| n∗ |
FP(False Positive): 偽陽性 |
TN(True Negative): 真陰性 |
N=FP+TN |
- Positive:陽性と判断
- Negative:陰性と判断
- True:判断が正しい
- False:判断が誤り
偽陽性率:健康な人の中で陽性が出てしまった割合
False−Positive−rate=FP+TNFP=NFP
真陽性率:病気の人の中で陽性を正しく出せた割合
True−Positive−rate=TP+FNTP=PTP
正確度:正しく当てられた割合
Accuracy=TP+FP+FN+TNTP+TN
適合率:陽性を出した中でそれが合っていた割合。モデルの正確性を表す
Precision=TP+FPTP
再現率:適合している全文書からどれだけ検索できているかを示す網羅性の指標。真の陽性に対してどれだけ真と答えられたか
Recall=TP+FNTP=PTP
F-値:PrecisionとTrue-Pisitive rateの調和平均。(適合率と再現率はトレードオフの関係にあるから)
Fvalue=Precision+TP−rate2×Precision×TP−rate=Precision1+Recall12
ROCによる性能評価
ROC曲線の下側の面積を ROC曲線下面積(AUC)(area under anROC curve) といい, 識別器の性能評価尺度
- 完全な識別器の ROC 曲線は, 原点, (0,1), (1,1) を通る直線で, AUCは 1 になる.
- 原点と (1,1) を結んだ 45 度線は, ランダムな識別器の ROC 曲線で, AUC は 0.5 となる.
どの識別器も AUC は (0.5, 1) の間の値となり, 大きいほど性能が良い.
動作点の選択
動作点 (真陽性率と偽陽性率の組み合わせ) をどこに選択すべきか?
最小損失識別規則は, L11=L22=0 とすれば,
p(x ∣ n∗)p(x ∣ p∗)>L21P(p∗)L12P(n∗)⇒pp(x ∣ n∗)p(x ∣ p∗)<L21P(p∗)L12P(n∗)⇒n
損失の期待値 r は
r=∫R1(L12p(x ∣ n∗)P(n∗))dx+∫R2(L21p(x ∣ p∗)P(p∗))dx=L12P(n∗)ϵ2+L21P(p∗)ϵ1
となる
ROC空間の定義で書けば,
1−ϵ1=L21P(p∗)L12P(n∗)ϵ2+(1−L21P(p∗)r)=αϵ2+h(r)
となる.
課題3.1
次のデータはある疾病に関して, 病気の人(G=1で表す)100人と, 健康な人(G=0)900人の検査値が一定数以上の場合を S=1, 一定値以下を S=0, 男性を T=1, 女性を T=0 とした 1000 人の仮想的なデータである. 検査値と性別から, 病気であるかどうかを識別したい. S と T の間には条件付き独立性 P(S,T ∣ G)=P(S ∣ G)P(T ∣ G) が成り立つと仮定する. このとき, 以下の問に答えなさい.
|
サンプル数 |
検査値 x がある値以上(S=1) |
性別(T=1) |
| 病気の人(G = 1) |
100 |
80 |
70 |
| 健康な人(G = 0) |
900 |
300 |
180 |
(1) 検査値に関するクラス条件付き確率を P(S ∣ G) を求めよ
S に関するクラス条件付き確率は次の通り
P(S=1 ∣ G=1)=10080=54,P(S=0 ∣ G=1)=10020=51P(S=1 ∣ G=0)=900300=31,P(S=0 ∣ G=0)=900600=32
(2) 事後確率 P(G=1 ∣ S=1,T=1) を計算せよ
T に関するクラス条件付き確率
P(T=1 ∣ G=1)=10070=107
P(S,T ∣ G)のクラス条件付き確率
P(S=1,T=1 ∣ G=1)=54×107=2514
同時確率P(S,T,G)
P(S=1,T=1,G=1)=P(S=1,T=1 ∣ G=1)×P(G=1)=2514×1000100=1257
周辺確率P(S,T)
P(S=1,T=1)=P(S=1,T=1,G=1)+P(S=1,T=1,G=0)=1257+503=25029
事後確率P(G=1 ∣ S=1,T=1)
P(G=1 ∣ S=1,T=1)=P(S=1,T=1)P(S=1,T=1,G=1)=2914
(3) ベイズ誤り率を求めよ.
- 事後確率を次の表にまとめると(赤字が健康と識別された確率)
| (S,T) |
(1, 1) |
(0, 1) |
(1, 0) |
(0, 0) |
| P(G=1∣S,T) |
2914 |
677 |
111 |
811 |
| P(G=0∣S,T) |
2915 |
6760 |
1110 |
8180 |
ϵ∗=s,t∈{0,1}∑min{P(G=1 ∣ S,T),P(G=0 ∣ S,T)}⋅pS,T(S,T)=2914×25029+677×50067+111×12533+811×500243=101
(4) 損失を L11=L22=0,L12=5,L21=10 とした場合の識別結果を求めよ
損失行列は
[L11L21L12L22]=[01050]
L11 は真のクラスが G=0 のとき G=0 と判断するときの損失, L21 は真のクラスが G=0 のとき G=1 と判断するときの損失, L12 は真のクラスが G=1 のとき G=0 と判断するときの損失であるから、識別クラスは事後確率に損失をかけて大きい値のクラスになる.
|
(1,1) |
(0,1) |
(1,0) |
(0,0) |
| L21P(G=1∣S,T) |
29140 |
6770 |
1110 |
8110 |
| L12P(G=0∣S,T) |
2975 |
67300 |
1150 |
81400 |
| 識別クラス |
1 |
0 |
0 |
0 |
最小損失基準に基づく、以下の識別結果になる
- S=1,T=1: 病気の人
- S=0,T=1: 健康な人
- S=1,T=0: 健康な人
- S=0,T=0: 健康な人
課題3.2
次の混同行列から, 偽陽性率, 真陽性率, 適合率, 正確度, F 値を求めよ.
|
識別クラスp |
識別クラスn |
| p∗ |
TP: 20 |
FN: 80 |
| n∗ |
FP: 150 |
TN: 750 |
- 偽陽性率: NFP=150+750150=61
- 真陽性率: PTP=20+8020=51
- 適合率: TP+FPTP=20+15020=172
- 正確度: P+NTP+TN=20+80+150+75020+750=10077
- F値: 1/適合率+1/再現率2=1721+5112=274
確率モデルと識別関数
学習データ xi は, 母集団からのランダムサンプルであるから, 誤差を伴う観測が一般的である. また, 特徴ベクトルは単位や変数変換の仕方によりばらつきが変わったり, 分布の形状が変化する.
そこで, 単位変換や相関係数に依存しない変数変換の方法を学ぶ.
母集団分布を記述する確率モデルを定義し, 確率モデルを使ったベイズ識別規則を紹介する.
観測データの線形変換
平均ベクトル
観測データは, d次元の特徴ベクトル x=(x1,⋯,xd)Tとする. xの確率分布 (密度関数) を p(x) とするとき, 平均ベクトルを次のように表す.
μ=(μ1,⋯,μd)T=(E{x1},⋯,E{xd})T
ここで E{xi} は i 番目の特徴ベクトルの期待値演算で, xが連続型の場合
μi=E{xi}=∫Rdxip(x)dx=∫−∞∞xip(xi)dx
となる.
p(xi) は d次元密度関数p(x)の周辺分布であった.
p(xi)=∫−∞∞⋯∫−∞∞p(x1,⋯,xd)dx1⋯dxi−1dxi+1⋯dxd
共分散行列
観測データの平均ベクトル周りのばらつきの尺度を分散共分散行列で表す
Σ=Var[x]=E{(x−μ)(x−μ)T}=[σij]i.j=1,⋯,d
- σijはxiとxjの平均周りの2次モーメントして以下のようにして計算した
σij=E{(xi−μi)(xj−μj)}=∫−∞∞∫−∞∞(xi−μi)(xj−μj)p(xi,xj)dxidxj
標本平均ベクトルと標本共分散行列
データ分析者は, データの母集団分布p(x)を特定する術がありませんから, 観測データを使って, 母平均ベクトル(μ)や母分散共分散行列(Σ)を推定する必要がある
N個の観測データをx1,⋯,xNと表したとき, 標本平均ベクトルは次の様にして計算した
x=N1i=1∑Nxi
また, 標本分散共分散行列Sの第i,j要素は次のようにして計算する
Sij=N1n=1∑N(xni−xi)(xnj−xj)
xiとxjの関連性の指標を相関係数といい, 母相関係数と標本相関係数は次の様にして定義された
ρij=σiσjσij,rij=SiSjSij
ただし, σi2=σij2またSi2=Siiである.
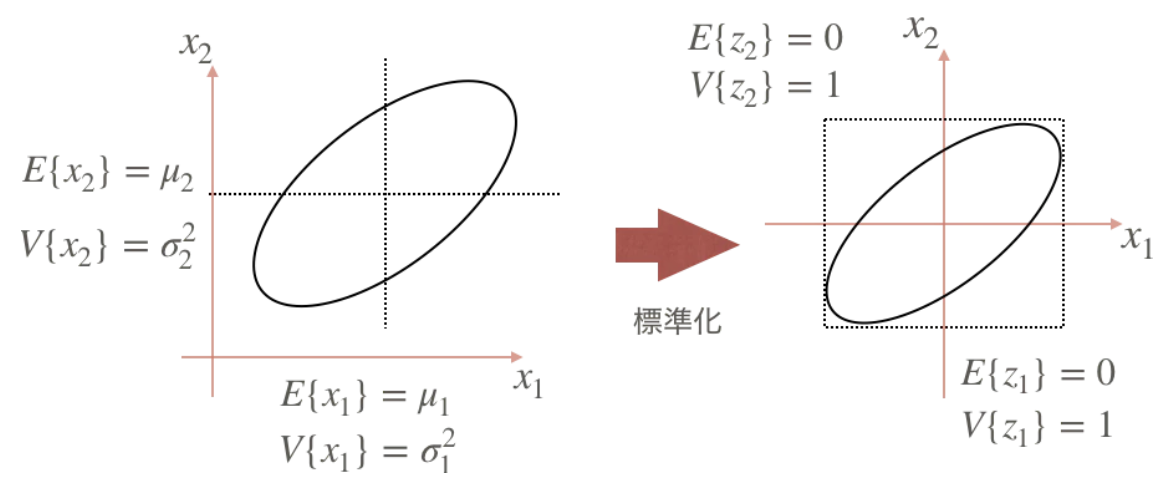
観測データの標準化
観測データの個々の特徴量の分布は, 測定単位のとり方でばらつきが大きくもなるし小さくもなる. そこで, 単位変換の影響を取り除いたデータを用いた方が望ましい分析結果が得られる.
- 個々の特徴量を平均0, 分散1に変換することを標準化という.
平均μ, 分散σ2をもつXの線形変換Y=aX+bの期待値と分散の性質を思い出すと
E(Y)=E(aX+b)=aE(X)+b,Var(Y)=Var(aX+b)=a2Var(X)
変換z=σx−μの期待値と分散は, それぞれ0と1になる.
E(Z)=E(σX−μ)=σE(X)−μ=σμ−μ=0Var(Z)=Var(σX−μ)=σ2Var(Z)=σσ2=1
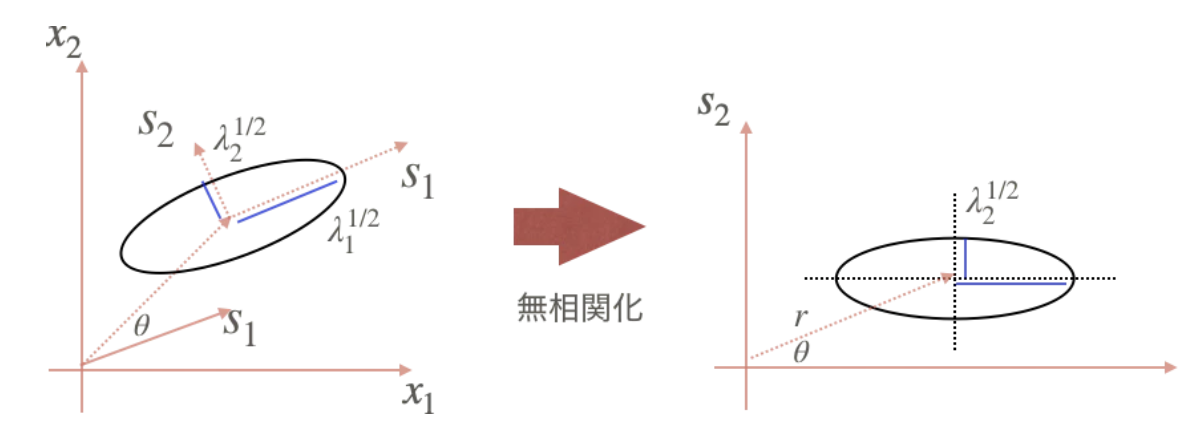
観測データの無相関化
データ間の相関を取り除く処理のことを無相関化という
分散共分散行列Σの固有値をλ1≥λ2≥⋯≥λdとし, その固有値に対応する固有ベクトルをs1,s2,⋯,sdとすると, 対称行列である分散共分散行列Σは次のように対角化された
Σ=SΣST,Λ=STΣS
そこで, データXの線形変換Y=ST(X)を考えると, Yの平均は
E(Y)=E(ST(X))=STμ
であり, 分散共分散行列は
Var(Y)=Var(STX)=E{[ST(X−μ)][ST(X−μ)]T}=STE{(X−μ)(X−μ)T}S=STΣS=Λ
- Λは, 固有値が対角に並んだ対角行列であったので, その非対角要素は0であった.
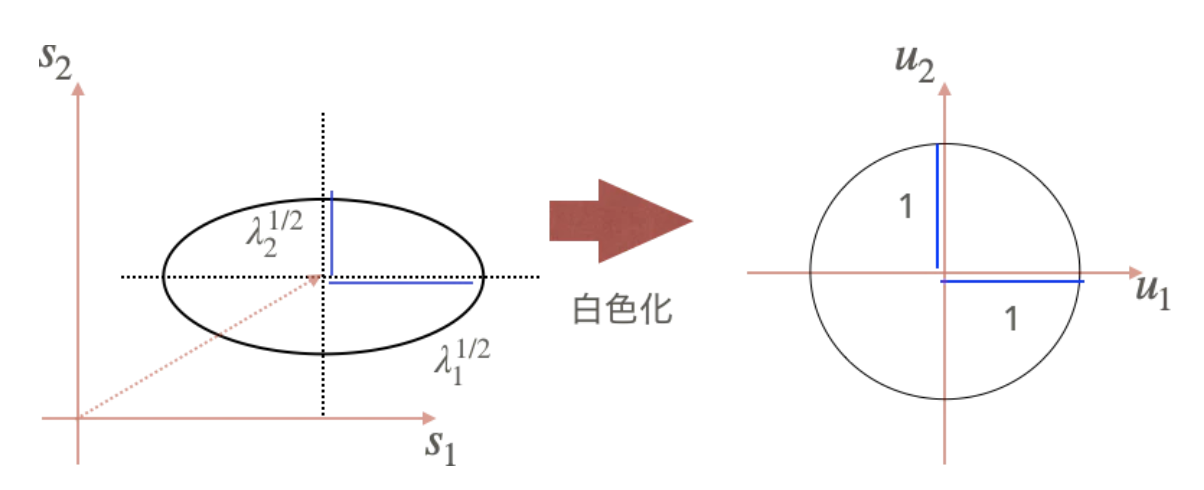
観測データの白色化
全ての特徴量を無相関化かつ標準偏差を1に正規化し, 平均ベクトルを0に中心化する操作を白色化という
白色化の変換公式は以下のように定義すればよい.
u=Λ−21ST(X−μ)
uの平均ベクトルは
E(u)=E(Λ−21ST(X−μ))=Λ−21ST{E(X−μ)=0
となり, 分散共分散行列は
Var(u)=Var(Λ−21ST(X−μ))=E{Λ−21ST(X−μ)(X−μ)TSΛ−21}=Λ−21STΣSΛ−21=Λ−21ΛΛ−21=Λ−21Λ21Λ21Λ−21=Id
確率モデル
パラメトリックモデル: 確率モデルを仮定し, 学習データからその確率モデルのパラメータを推定して識別規則を構成する手法
ノンパラメトリックモデル: 確率モデルを用いずに, 識別規則を構成する手法
- k最近傍法, サポートベクターマシン(SVM), 分類木, ヒストグラム法
1次元正規分布の密度関数は
N(x ∣ μ,σ2)=2πσ1exp(−σ2(x−μ)2)
となり, 平均μ, と標準偏差σ(分散σ2)が形を決める
d次元正規分布関数
d次元正規分布の密度関数は
N(x ∣ μ,Σ)=(2π)d/2∣Σ∣1/21exp(−21(x−μ)TΣ−1(x−μ))
任意の点xとμの間の距離をマハラノビス距離といい, 次のように表す
d(x,μ)=(x−μ)TΣ−1(x−μ)
ユークリッド距離を共分散で割っているので, 各変数のバラつき方を考慮した距離になっている
正規分布から導かれる識別関数
i番目のクラスのクラス条件付き確率がd次元正規分布だと仮定し,ベイズの誤り率最小識別規則を満たす識別関数を求めよう. クラス事前確率をP(Ci)とすると, 事後確率は
P(Ci ∣ x)∝(2π)d/2∣Σ∣1/2P(Ci)exp(−21(x−μ)TΣ−1(x−μ))
各クラスに表れる共通項を省略して整理して, 評価値を表せば,
g(xi)=(x−μi)TΣi−1(x−μi)+ln∣Σi∣−2lnP(Ci)
となるので, 識別クラスとしてこの値の最も小さなクラスを選択すれば良い.
識別クラスは 識別規則 = argmini[gi(x)]となるので, クラスi,jの識別境界は, 次のような2次曲面になる
fij(x)=gi(x)−gj(x)=xTSx+2cTx+F=0
ここで
S=Σi−1−Σj−1,cT=μjTΣj−1−μiTΣi−1F=μiTΣi−1μi−μjTΣj−1μj+ln∣Σj∣∣Σi∣−2lnP(Cj)P(Ci)
- Σi−1=Σj−1を仮定すれば, 線形識別関数fij(x)=2cTx+F=0になる
確率モデルパラメータの最尤推定
最尤法: 確率分布の未知母数の推定する方法
学習データxiはパラメータθをもつ真の分布f(x ∣ θ)から独立に得られた標本とする. 確率モデルの母数θは未知であるから, 学習データから推定しないといけない.
N個の学習データの同時分布を考えると, サンプルの独立性から
f(x1,⋯,xN ∣ θ)=i=1∏Nf(xi ∣ θ)
が成り立つ.
同時分布関数はxiの関数だが, 学習データは既に得られた標本を使えばいいので, 上の関数をθの関数と考えると, 尤度関数が定義できる
L(θ)=f(x1,⋯,xN ∣ θ)
この尤度関数を最大にするθを求めることを最尤法といい, 最尤推定量は次のように定義される
θ^=θargmaxL(θ)=θargmaxL(θ)
ここでL(θ)=lnL(θ)を対数尤度関数という.
正規分布の最尤推定
最尤推定量は, 対数尤度関数の最大化で求まるので, 最大化の1階の条件∂θi∂L(θ)=0を解けば良い
1変量正規分布の母数, θ=(μ,σ2)Tの最尤推定を考えよう.
尤度関数は次のとおり
L(μ,σ2)=i=1∏N2πσ1exp(−2σ2(xi−μ)2)=(2πσ2)−N/2exp(−2σ21i=1∑N(xi−μ)2)
対数尤度関数は次のとおり
L(μ,σ2)=−2Nln(2π)−2Nlnσ2−2σ21−2σ21i=1∑N(xi−μ)2
最大化の1階の条件より, 正規分布のパラメータの最尤推定量は
∂μ∂L(μ,σ2)=σ21i=1∑N(xi−μ)=0⇒μ^=N1i=1∑Nxi∂σ2∂L(μ,σ2)=−2Nσ21+(2σ2)22i=1∑N(xi−μ)2=0⇒σ2^=N1i=1∑N(xi−μ^)2
- 標本平均と標本分散 (不偏分散 (N − 1 で割る方) ではない) になる.
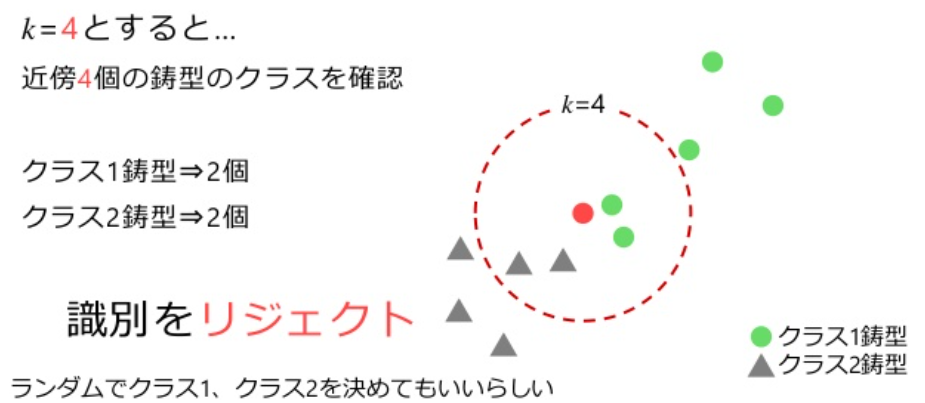
k最近傍法(KNN)
最近傍法: 入力データと全ての学習データ (鋳型; template) との距離を計算し,最も近い鋳型が所属するクラスに識別する方法
k最近傍法KNN: 最も近い鋳型のクラスに識別する代わりに, 最も近いk個の鋳型の所属するクラスの数が最も多いクラスに識別する方法
kNN法は計算量が多いのが欠点だが, その緩和策と近似最近傍探索を勉強する.
最近傍法とボロノイ境界
K個のクラスをΩ={C1,⋯,Ck}とする. i番目のクラスの学習データ数N(i)とし, その集合をSi={x1(i),⋯,xN(i)(i)}と表す.
最近傍法では, 入力データxと各学習データxj(i)の類似度をユークリッド距離d(x,xj(i))=∥x−xj(i)∥で計算する.
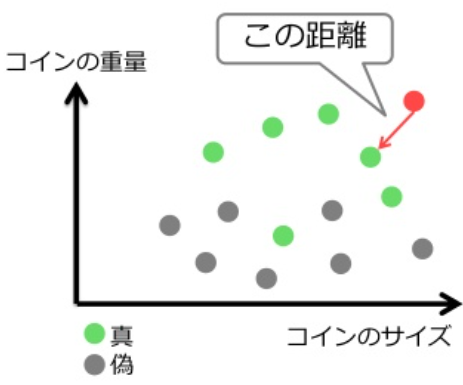
学習データのことを鋳型ともいう. tは学習データとの距離が大きいときにリジェクトするための値である.
リジェクトは誤り率が大きいときに判断を保留することである.
最近傍法の識別規則:
識別クラス={argmini{minjd(x,xj(i))},リジェクト,minjd(x,xj(i))},mini,jd(x,xj(i))<tmini,jd(x,xj(i))≥t
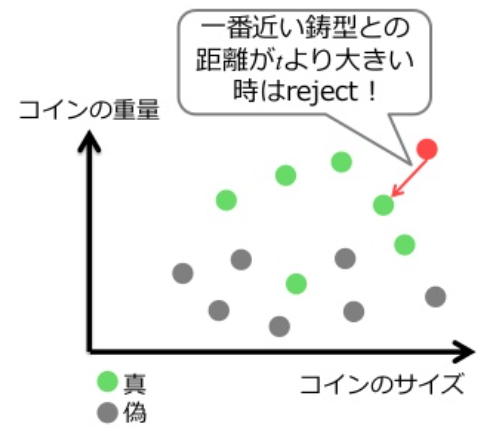
ボロノイ図
最近傍法は入力データに最も近い鋳型を見つけること
各鋳型は隣接する鋳型と等距離にある境界 (ボロノイ境界) で囲まれた支配領域 (ボロノイ領域) をもつ. 入力データが支配領域に入った鋳型が最も近い鋳型になる.
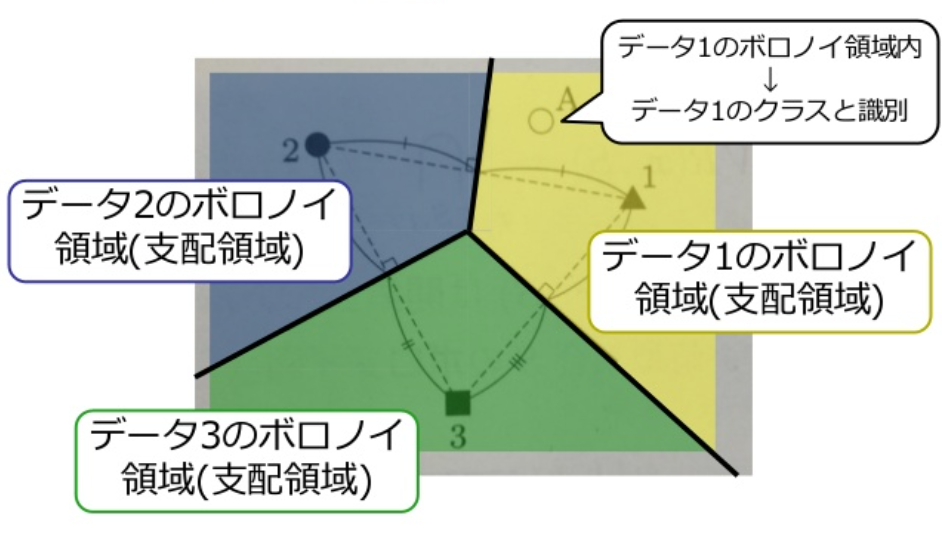
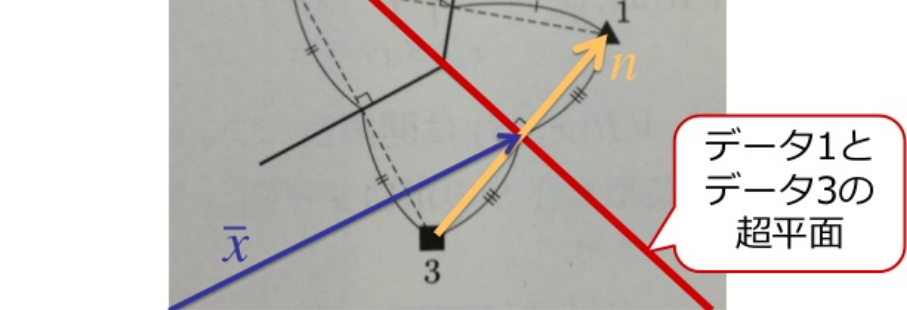
鋳型の集合をS={x1,⋯,xN}とする. ボロノイ境界はxi,xj∈Sから等距離の点の集合である.
B(xi,xj)={x ∣ d(xi,x)=d(xj,x)}
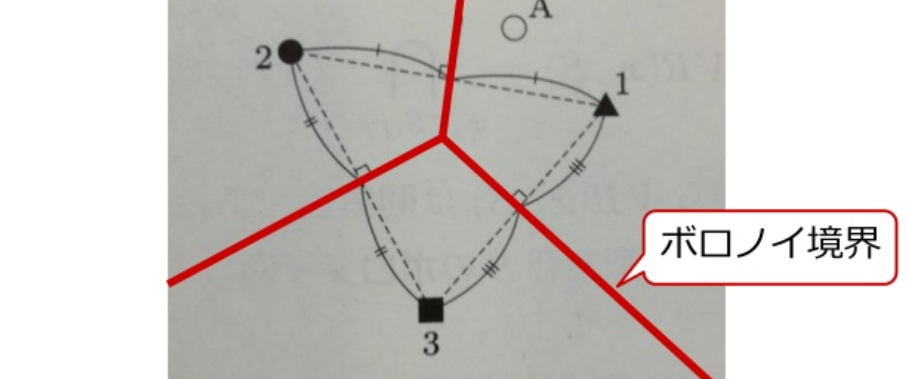
xiとxjを結んだ直線 (法線ベクトルn) の中心xを通り, 直交する超平面になる.
(x−x)Tn=0,x=(xi+xj)/2,n=xi−xj
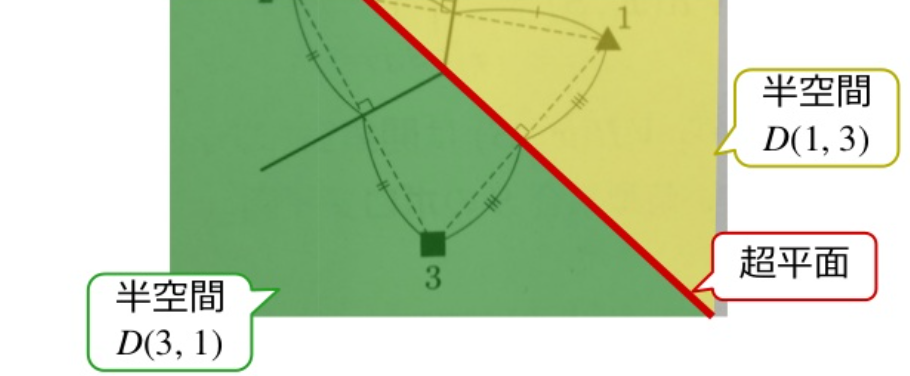
この超平面は,xiを含む半空間とxjを含む半空間に2分割する.
D(xi,xj)={x ∣ d(xi,x)<d(xj,x)}D(xj,xi)={x ∣ d(xj,x)<d(xi,x)}
xiのボロノイ領域の定義は次のとおり
VR(xi,S)=xj∈S,j=i⋂D(xi,xj)
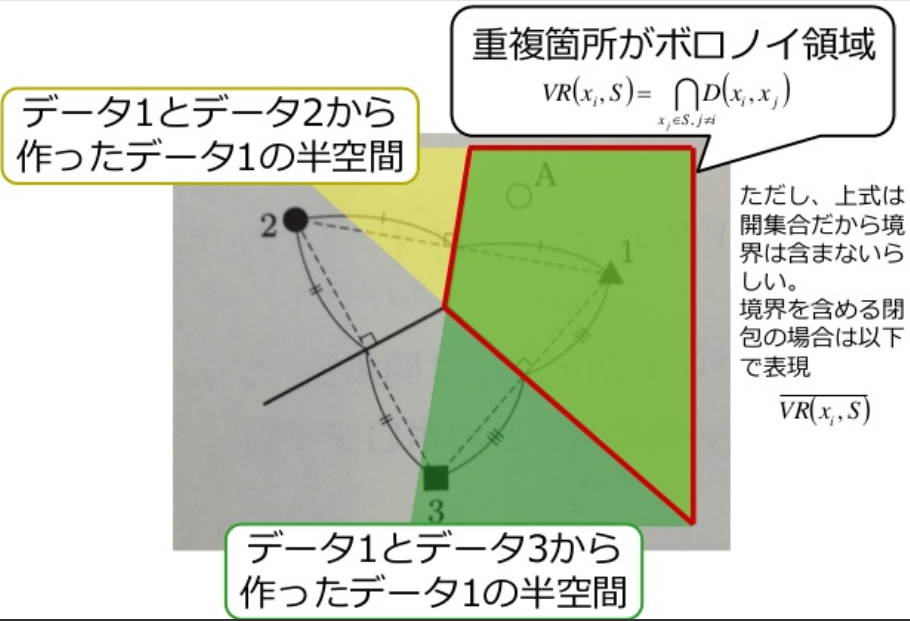
VR(xi,S)は開集合なので, 境界も含めて閉包をVR(xi,S)と表すとボロノイ図は次のように定義される.
V(S)=xi,xj∈S,i=j⋃=VR(xi,S)∩VR(xj,S)
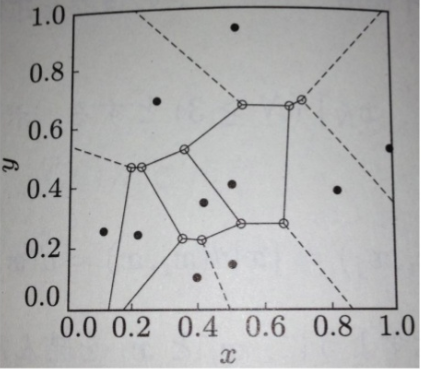
例題:
xi=(1,0)T,x2=(0,1)Tの場合のボロノイ境界を求めよ.
x1,x2の中点:
x=(21,21)T
2点x1とx2を結ぶ法線ベクトル:
n=x1−x2=(01)−(10)=(−11)
従って、法線ベクトルn=(−11)と直交する直線の方程式:
x−y+c=0⇒21−21+c=0⇒c=0
x−y=0
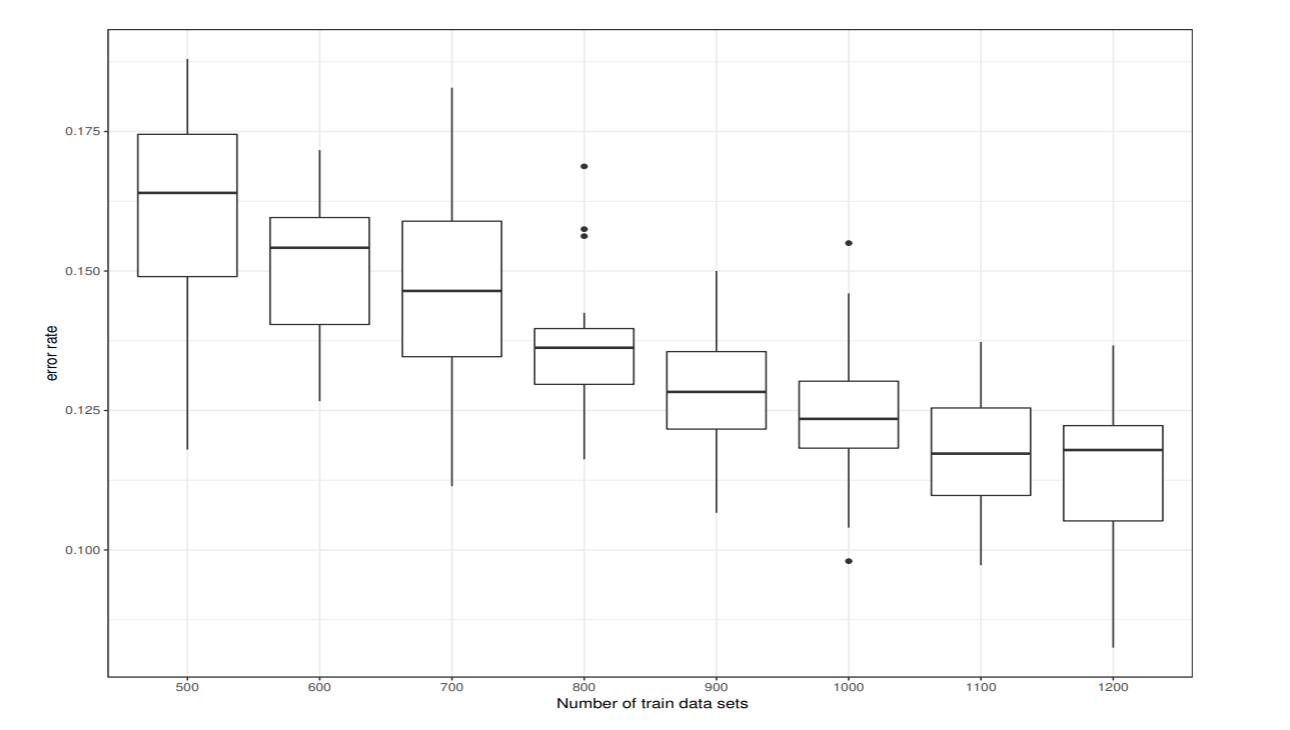
鋳型の数と識別性能
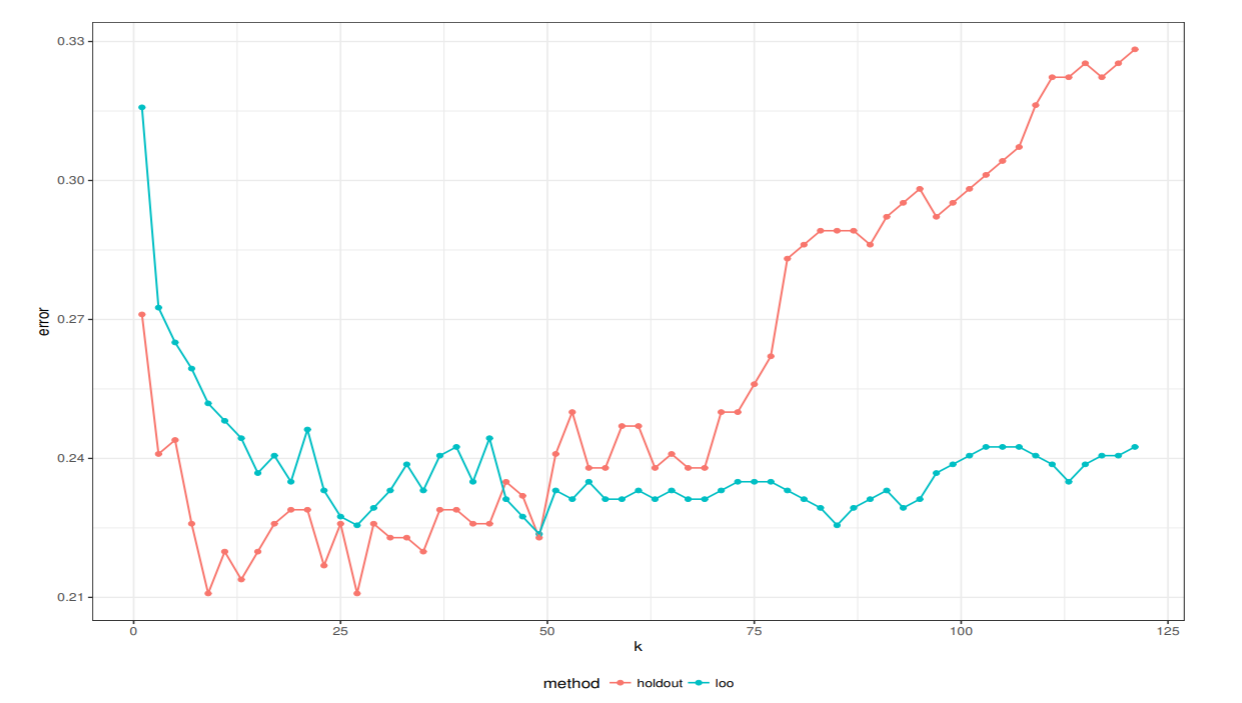
各クラスからM個のデータをランダムに選び, 10×M 個のデータから 1つ抜き法で汎化誤差を推定した. これを20回繰り返したときの鋳型の数と汎化誤差の関係を図示した.
kNN法
最近傍の鋳型をk個取ってきて, それらが最も多く所属するクラスに識別する方法をk最近傍法という
鋳型の集合をTN={x1,⋯,xN},それらが属するクラスの集合をΩ={C1,⋯,CKとする.
入力xにもっとも近いk個の鋳型の集合をk(x)={xi1,⋯,xik}とし, これらの鋳型のうちクラスjに属する鋳型の数をkjとする.k=k1+⋯+kKが成り立つ.
k最近傍法の識別規則:
識別クラス={j,リジェクト,{kj}=max{k1,⋯,kK}{k1,⋯kK}=max{k1,⋯,kK}
- 近傍k個の鋳型の内、数が最も多いクラスjと識別する
- 近傍k個の鋳型の内、数が最も多いクラスが複数存在する場合はrejectする
ピマインディアンデータのk最近傍法による識別境界
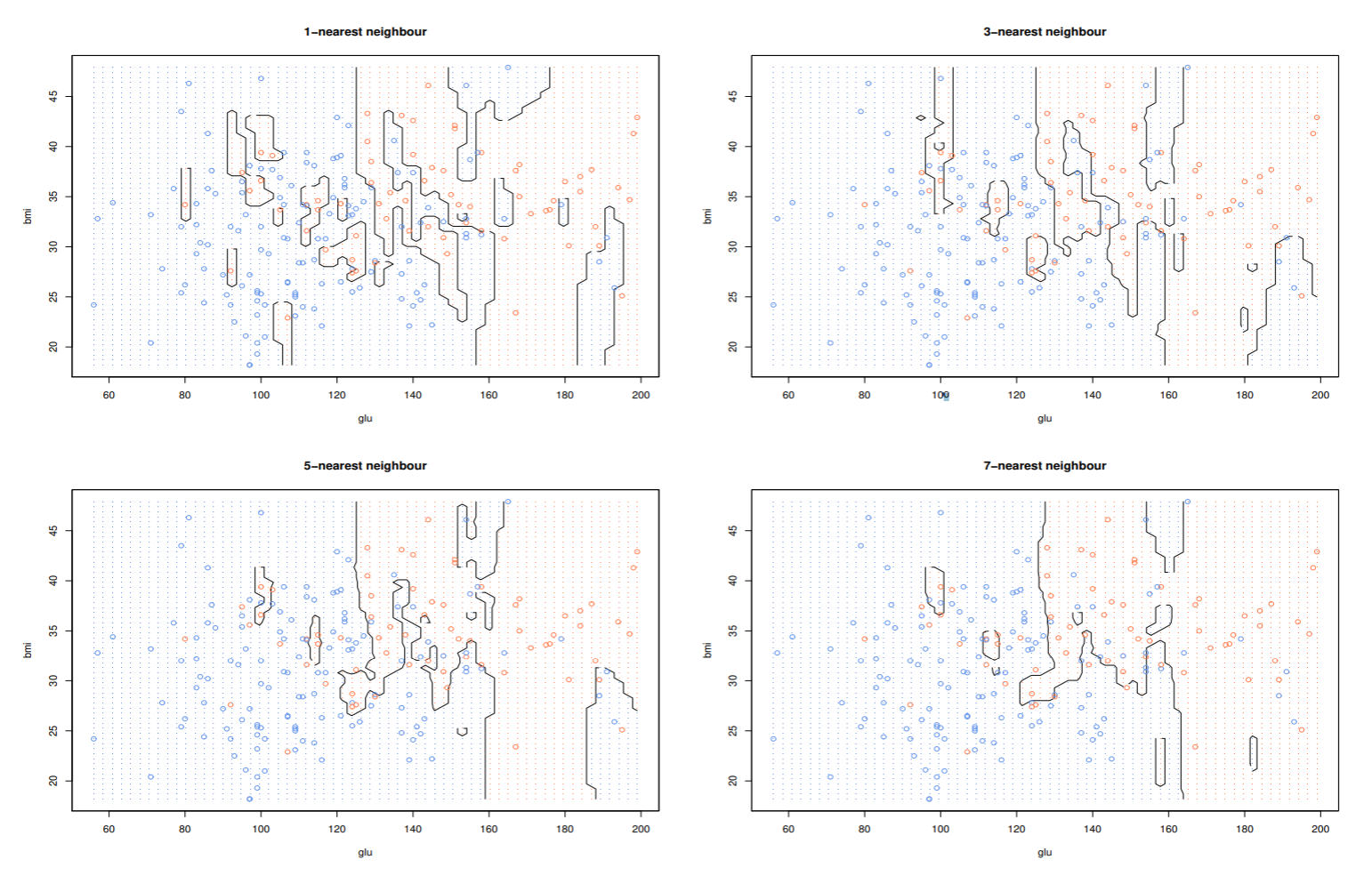
最適な最近傍数kを求める
kNN 法では, 最近傍法と同様に, 学習データ数が多くなれば誤り率は減少する. ピマ・インディアンデータでは, 学習データを大きくすることはできない. 1つ抜き法では, 全ての学習データが利用できるので , kが60以上になるところで安定した誤り率を示す.
漸近仮定とkNN誤り率の期待値
条件付きベイズ誤り率は, 事後確率の小さい方であった.
ϵ(x)=min{P(C1 ∣ x),P(C2 ∣ x)}
ベイズ誤り率は, その期待値
ϵ∗=∫ϵ(x)p(x)dx
入力xの最近傍鋳型をx1NNとする. N個の鋳型の集合をTNとする.
漸近仮定が成り立つとき, kNN誤り率とベイズ誤り率の間には次の関係が成り立つ.
limN→∞TN⇒d(x,x1NN)→0であれば,
- N: 鋳型の数
- TN: N個の鋳型の集合
- d(x,x1NN): 入力xと、最近傍鋳型x1NNの距離
21ϵ∗≤ϵ2NN≤ϵ4NN≤⋯≤ϵ∗≤⋯≤ϵ3NN≤ϵ1NN≤2ϵ∗
- kは偶数の時、誤り率が低い
- kは奇数の時、誤り率が高い

kNN法の改善
誤り削除型KNN法(Edited kNN)
kNNで識別境界を作成した時に、不正解の識別領域に含まれる鋳型を削除する
- 削除すると識別境界が変わるので、最適的に削除を行う
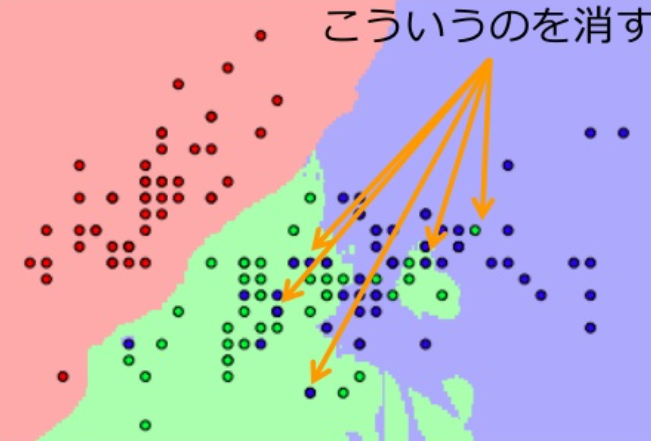
圧縮型kNN(Condensed kNN)
識別に関係ない鋳型を削除する

分枝限定法
分枝法と限定法を用いて、近傍の探索を効率化させる
- 分枝法: クラスタリングによって木構造のように組織化する
- 限定法: 分枝法で作成した木構造をもとに近傍の探索を行う
近似最近傍探索
次元が大きくなると, 制約された時間の中で正確な解を求めるのが困難なため, 近似最近傍探索を行う.
学習データの集合をP={xi}(i=1,⋯,N)とし, 入力データqの最近傍解x∗のϵ-近似解xを次を満たすxとする.
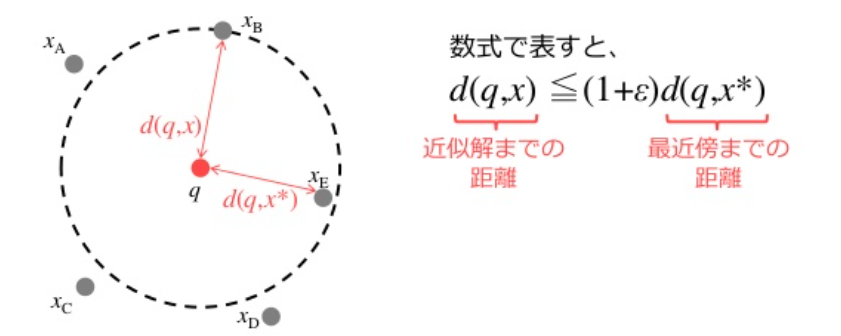
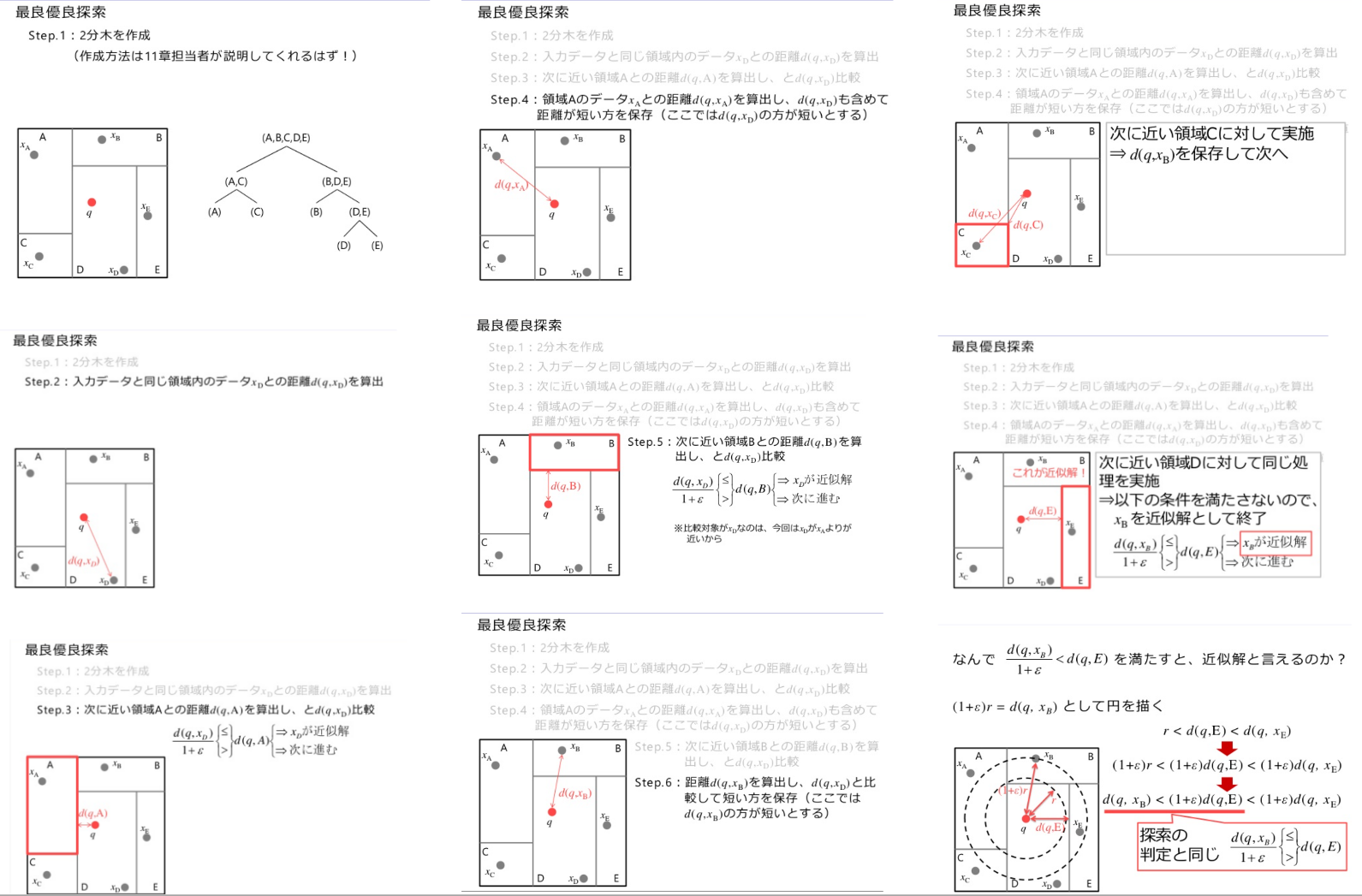
d(q,x∗)の値は, 2分木等の最良優先探索を使って求める.
線形識別関数
線形識別関数はf(x)=wTx+w0と表すことができる. wを線形識別関数の係数ベクトル, w0をバイアスという.
入力データの次元をdとすれば, 識別境界はd−1次元の超平面となる.
線形識別関数の定義の目的:
- 線形識別関数が2つのクラスを超平面で区別
- 多クラス問題への拡張
ここでは, 2乗誤差最小化基準とフィッシャーの判別関数を紹介する.
超平面の方程式
d次元の入力ベクトルをx=(x1,⋯,xd)T, 係数ベクトルをw=(w1,⋯,wd)T,バイアス項をw0とすれば, 2 クラス問題の識別関数は, 次のように表される.
f(x)=wTx+w0
識別境界をf(x)=0とすれば, 識別規則は,
識別クラス={C1,(f(x)≥0)C2,(f(x)<0)
識別境界では, wTx=−w0が成り立つので, 両辺を係数ベクトルのノルム∥w∥で正規化して
∥w∥wTx=−∥w∥w0
となる.
n=∥w∥w,Δw=−∥w∥w0とおけば,
nTx=Δw
となるので, 識別境界は, f(x)=nTx−Δw=0と表される.
識別境界上の任意の点のベクトルPを考えると,
f(P)=nTP−Δw=0
が成り立つので
f(x)=nTx−Δw=nT(x−P)=0
となる.
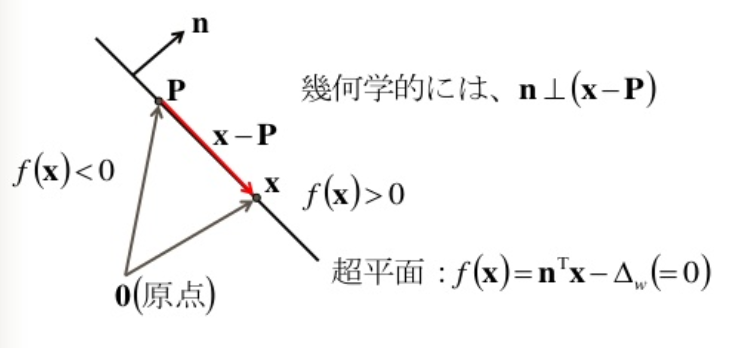
識別境界は単位法線ベクトルnをもつ超平面となる.

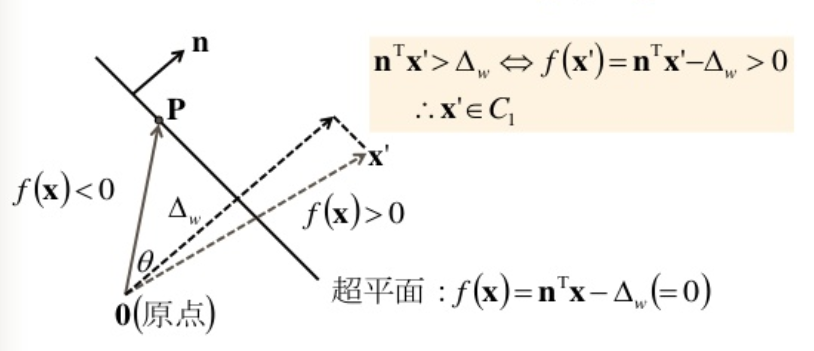
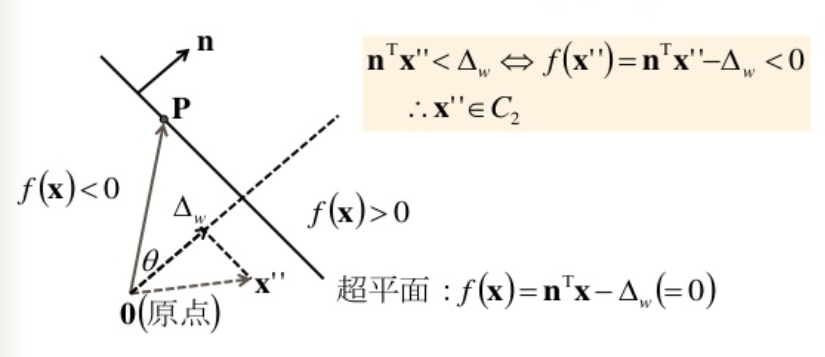
例題:

最小2乗誤差基準によるパラメータの推定
目的:
- 最小2乗誤差基準による線形識別関数のパラメータが正規方程式により得られること
- 多クラス問題への拡張
正規方程式
最小2乗誤差基準は, 識別関数の出力値と教師入力との差を最小にするパラメータを求める手法.
f(x)=w0+w1x1+⋯+wdxd=wTx
入力ベクトルxiが所属するクラスは, 教師入力tiにより, 次のように与える.
ti={+1,x1∈C1−1,x1∈C2
学習データ数をN, 学習用の入力ベクトルを並べた行列をX, 教師入力を並べたベクトルをtとすれば, 出力値の教師入力の差を2乗誤差で評価した評価関数E(w)は次のようになる.
E(w)=i=1∑N(ti−f(xi))2=(t−Xw)T(t−Xw)=tTt−2tTXw+wTXTXw
評価関数E(w)=tTt−2tTXw+wTXTXwは下に凸な関数, 故に, wでの微分が0になるパラメータがE(w)の最小を与える.
評価関数を最小にするwは, 次のようにして求める.
∂w∂E(w)=−2XTt+2XTXw=0
これを解いて,
w^=(XTX)−1XTt
学習データに対する予測値t^は
t^=Xw^=X(XTX)−1XTt
行列X(XTX)−1XTは, 教師データt予測値t^に変換する行列であり, 射影行列(ハット行列)と呼ばれる.
例題:

多クラス問題への拡張
K(> 2)クラスの識別関数の作り方:
一対多
一対多では, 1 つのクラスと他のすべてのクラスを識別するK−1個の2クラス識別関数fj(x),j=1,⋯,K−1を用意する.

一対一
一対一では, クラスi,jを識別するK(K−1)/2個の 2クラス識別関数fij(x),1≤i<j≤Kを用意して, 多数決で識別クラスを決める.

この方法でも識別クラスの矛盾が生じる空白領域のクラスが決定できなかったり, 関係しない識別関数が出るため多数決がとれなくなることもある.
最大識別関数法
最大識別関数法では, K個の識別関数を用意して,
識別クラス=jargmaxfj(x)=jargmaxwjTx+wj0
となるよう, 識別関数値が最大になるクラスに識別すれば良い.
このとき, 識別境界はfi(x)=fj(x)となるので,
fij=(wi−wj)Tx+(wi0−wj0)=0
を満たすK−1個の識別境界ができる.
最大識別関数法では, K個の識別関数fK(x)=wKTxを用意して, 2乗誤差を最小にするパラメータwKを2クラス問題と同様に求めれば良い.

2乗誤差を最小にするパラメータW^は
W^=(XTX)−1XTT
となる.
識別関数は
f(x)=W^x=(w1,⋯,wK)Tx=(f1(x),⋯,fK(x))T
となるので, 識別クラス = argmaxjfj(x)となる.
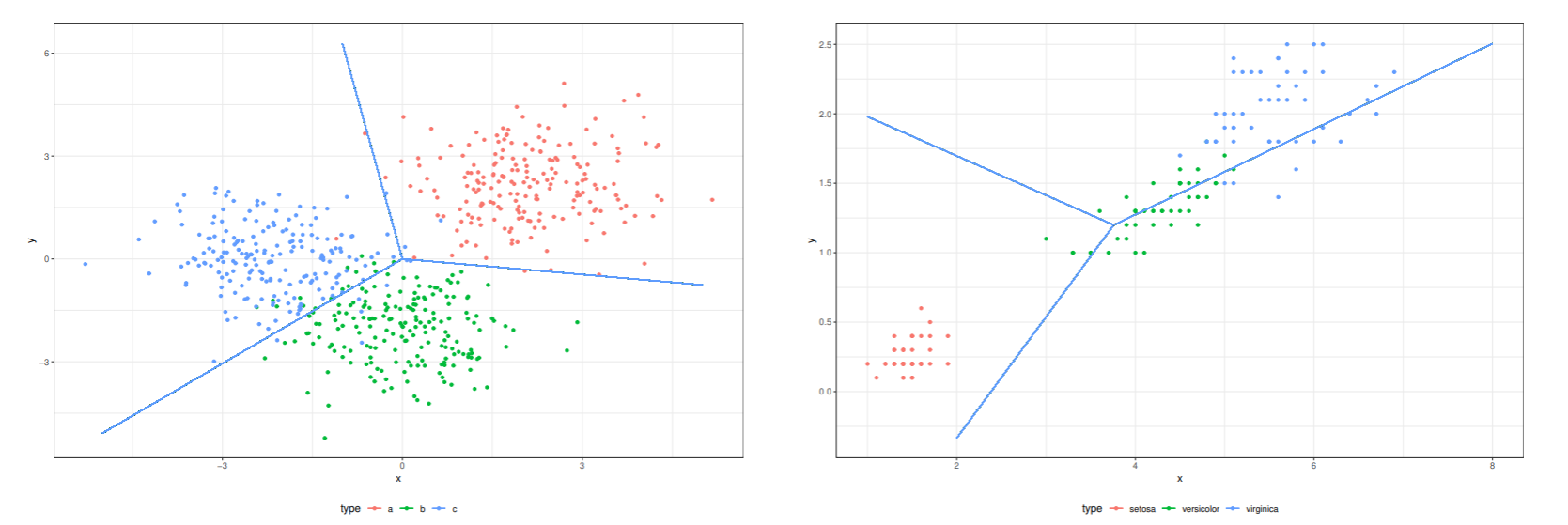
- 線形識別関数を最大識別関数法で求めた場合の識別境界
- うまく構成できる場合 (左) と複数のクラスが一直線上に並んでいる場合はうまく識別できない.
線形判別分析
線形識別関数は, d次元ベクトルxを, ベクトルw上のスカラ関数に写像する.
最小2乗誤差基準では, 教師データに忠実になるように, 線形識別関数を求めた.
線形判別分析では, 1次元に写像されたとき, クラス間ができるだけ重ならないような写像方向を見つける.
重なりの少ない写像を実現するベクトルwを見つけることが大事
フィッシャーの線形判別関数
線形識別関数は, クラス間変動とクラス内変動の比を最大にする軸へ射影する.
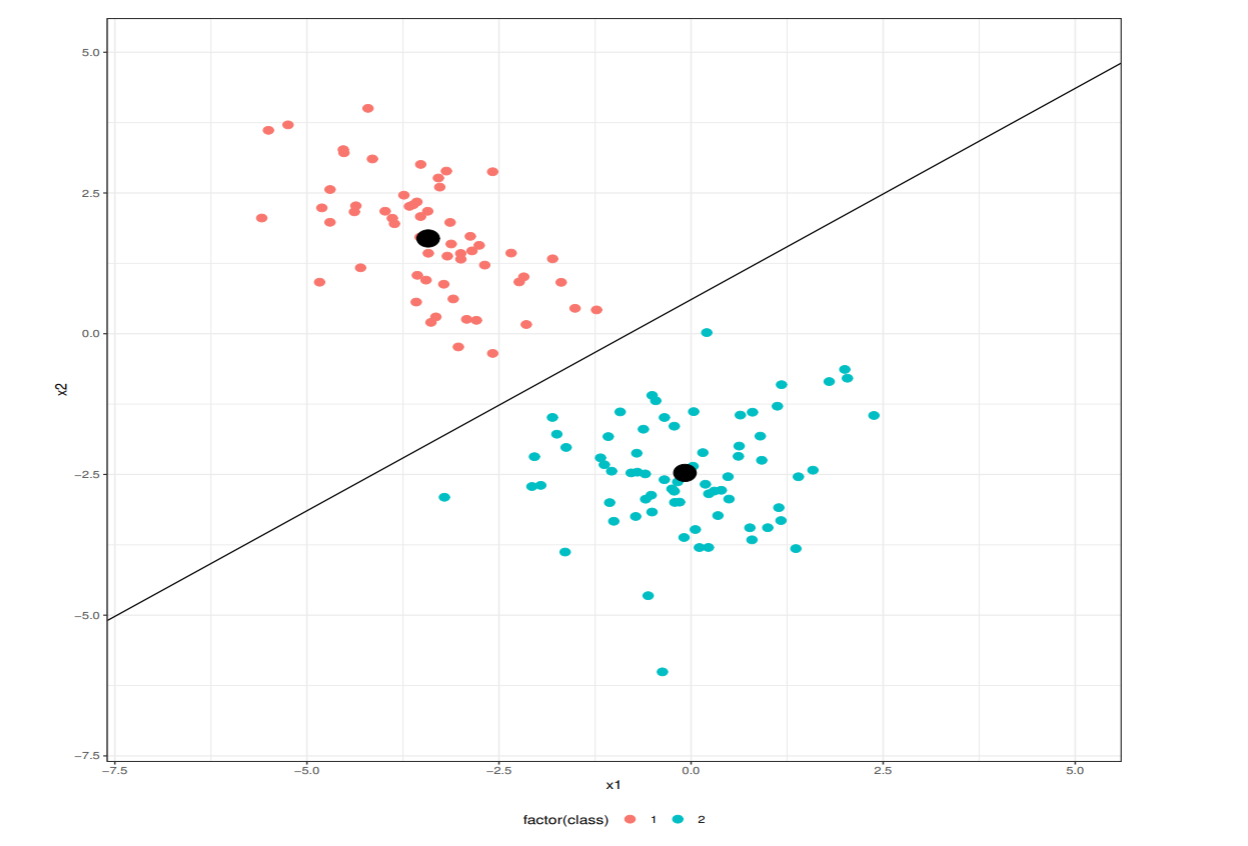
学習データ数が各クラスN1,N2で全データ数がN=N1+N2の2クラス問題を考える.
線形識別関数y=wTxは平均ベクトル
μk=Nk1=i∈Ck∑xi,k=1,2
をmK=wTμkに写像する. この時, 写像した平均の差が大きいほどクラス分離が良くなる
m1−m2=wT(μ1−μ2)
平均差の2乗をクラス間変動(between)という.
また, クラス内の変動は小さい方が重なりも小さくなる.
Sk2=i∈Ck∑(yi−mk)2
これをクラス内変動という. 全クラス内変動はS12+S22である.
フィッシャー基準とは, クラス間変動とクラス間変動の比
J(w)=S12+S22(m1−m2)2
これを最大にするwを求める.
フィッシャー基準は, 次のように表すことができる.
J(w)=wTSWwwTSBw
ここで,
wTSBw=wT(μ1−μ2)(μ1−μ2)TwwTSWw=(i∈Ck∑(xi−μk)(xi−μk)T)w
である.
これを最大にする解wは, 次の一般化固有値問題の解
SBw=λSWw
判別分析法
フィッシャー基準はクラス間変動を用いているため, 線形変換y=wTxのw0を明示的に扱うことが出来ない.そこで, クラス識別のためのバイアス項w0を明示的に扱うような定式化をする.
線形変換後のyの平均と分散は, 各クラスk=1,2について次のようになる.
mk=wTμK+w0,σk2=wTΣkw
ここで,
μk=Nk1i∈Ck∑xiΣk=Nk1i∈Ck∑(xi−μk)(xi−μk)T
である.
クラス分離度の評価関数をh(m1,σ12,m2,σ22)とすると, この評価関数の最大化にするwとw0求める
∂w∂h=∂σ12∂h∂w∂σ12+∂σ22∂h∂w∂σ22+∂m12∂h∂w∂m12+∂m22∂h∂w∂m22=0∂w0∂h=∂σ12∂h∂w0∂σ12+∂σ22∂h∂w0∂σ22+∂m12∂h∂w0∂m12+∂m22∂h∂w0∂m22=0
ここで
∂w∂σk2=2Σkw,∂w0∂σk2=0,∂w∂mk2=μk,∂w0∂mk2=1
を先程の式に代入して整理すれば, 最適なwを求めることができる.
2(∂σ12∂h+∂σ22∂h)(sΣ1+(1−s)Σw)w=∂m1∂h(μ2−μ1)
ベクトルの向きが問題なので, スカラー項は無視して良い. よって, 最適なwは次式となる.
w=(sΣ1+(1−s)Σ2)−1(μ1−μ2)
評価関数をクラス間分散とクラス内分散の比
h=P(C1)σ12+P(C2)σ22P(C1)(m1−m2)+P(C2)(m2−m)2
で定義した判別関数を判別分析法という. mは全データの平均.
s=P(C1)が得られることから, 最適なwは
w=(P(C1)Σ1+P(C2)Σ2)−1(μ1−μ2)
最適なバイアス項は次の通り.
w0=m−wT(P(C1)μ1+P(C2)μ2)
判別分析2値化法
画像の判別分析2値化法を紹介する.
左の図は, 1文字の原画で, 右の図が画像の濃度ヒストグラム.
図 (数字) と地の分布の境界を決定するために判別分析法を用いる.
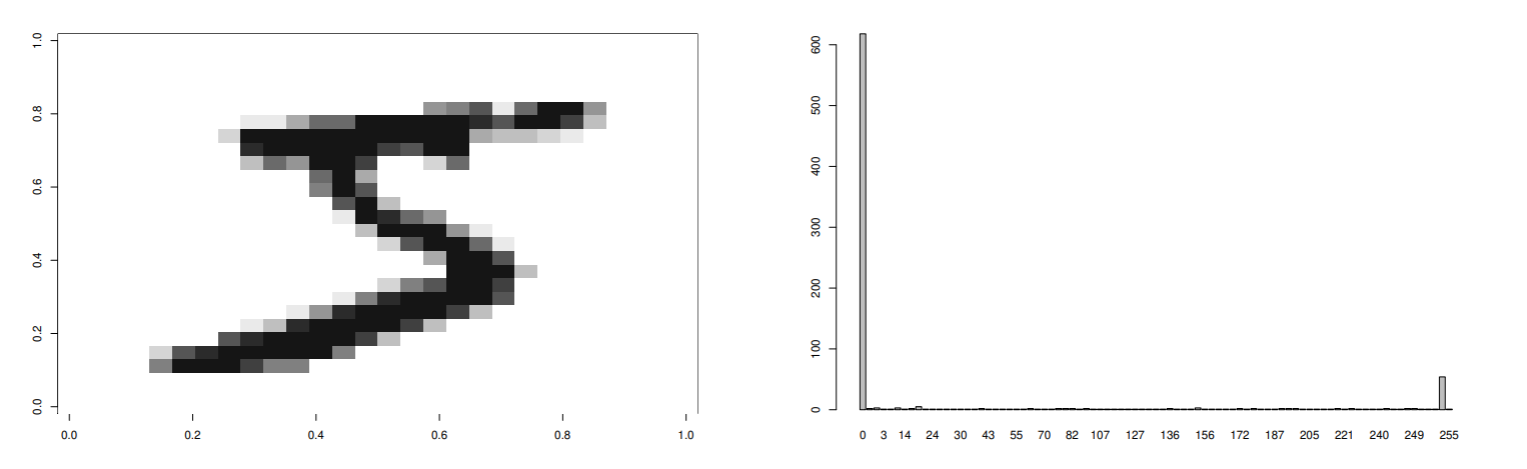
クラス間分散をσB2, クラス内分散をσW2と全分散σT2の関係は以下の様になるから,
σT2=σW2+σB2,h=σW2σB2=σT2/σB2−11
- σB2/σT2を最大にすれば, 分散比hも最大になる.
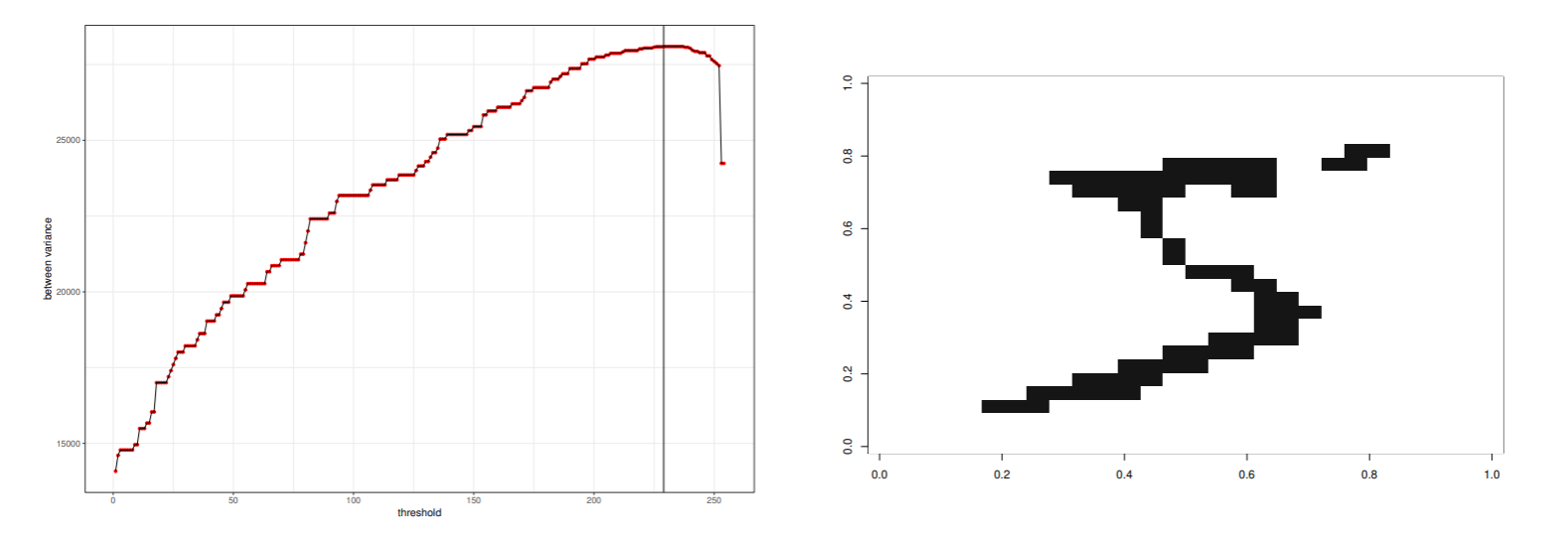
多クラス問題への拡張
フィッシャー基準をK>2の場合に拡張する. 各クラスのデータ数をNk,k=1,⋯,Kとする.
2クラスの場合に識別境界を計算できたが, 多クラスの場合は, d(>K)次元のデータを高々K−1次元の特徴空間に写像する線形変換行列を見つける問題になるので, 識別境界は計算できない.
各クラスのクラス内変動を次のように定義する.
Sk=i∈Ck∑(xi−μk)(xi−μk)T,μk=Nk1i∈Ck∑xi
全クラスのクラス内変動の和をSW=∑i=1KSKとする.
全データの変動の和を, 次のように定義する. (全変動という.)
ST=i=1∑N(xi−μ)(xi−μ)T
全変動STは次のようにクラス内分散SWを含むように分解できる.

d>Kであれば, d次元空間からK−1次元への線形写像
yk=wkTx,k=1,⋯,K−1
を考える. (d: バイアス項を除いたデータの次元)
yW=(y1,⋯,yK−1)T=(w1,⋯,wK−1)
とすれば, K−1個の線形変換は
y=WTx
と書ける.
2クラス問題と同様, 最適な写像行列Wを求める基準は, クラス間変動行列SB~とクラス内変動行列SW~の比を最大にすること.
しかし,行列の比なので何らかのスカラー量に変換しないと, 最大値を求めることができない.
例えば, 次のような基準がある.
J(W)=Tr(SW~−1SB~)=Tr((WTSWW)−1WTSBW)
ここで
SW~=i=1∑Ki∈Ck∑(yi−mk)(yi−mk)T=WTSWWSB~=k=1∑KNk(mk−m)(mk−m)T=WTSBWST~=SW~+SB~
あやめデータの判別空間の構成
あやめデータは3クラス, 4次元データなので, 線型判別関数により4次元特徴空間から2次元判別空間への写像を得ることができる.
図は正規分布を仮定した線形判別関数による識別境界を示した.

課題6.1
識別境界が直線y=−2x+3で表されたとする. この直線の法線ベクトルを求め, 識別境界上の適当な位置ベクトルPを用いて,f(x)=nTx−Δw=nT(x−P))と表現できることを確かめよ.
−2x−y+3=0⇔(−1−2)T(yx)+3=0より, x=(x,y)Tとw=(−2,−1)Tは直交である
∥w∥=(−2)2+(−1)2=5より, 法線ベクトルn=∥w∥w=(5−2,5−1)T
P=(a,b)Tを直線上の任意の点とすると, −2a−b+3=0を満たす
nT(x−P)=(5−2,5−1)(y−bx−a)=51{−2(x−a)−(y−b)}=51(−2x−y+3)
即ち, y=−2x+3をnT(x−P)=0として表現できた.
課題6.2
識別関数をf(x0=1,x1)=w0+w1x1とする. 学習データ対を(t1,x11)=(+1,−2),(t2,x21)=(−1,1)としたとき, 下記の問に答えよ.
(1) w^を求めよ.
データ行列は
X=(x0x0x11x21)=(11−21)
であり, 教師ベクトルt=(t2t1)=(−11)である.
XT=(1−211),XTX=(2−1−15),(XTX)−1=(95919192)
w^=(XTX)−1XTt=(95919192)(1−211)(−11)=(−32−31)
(2) 識別関数を平面に図示せよ.
識別関数f(x)=w^Tx,x=(1,x1)T,w^T=(−31,−32)より
y=f(x)=(−31,−32)(x11)=−31−32x1
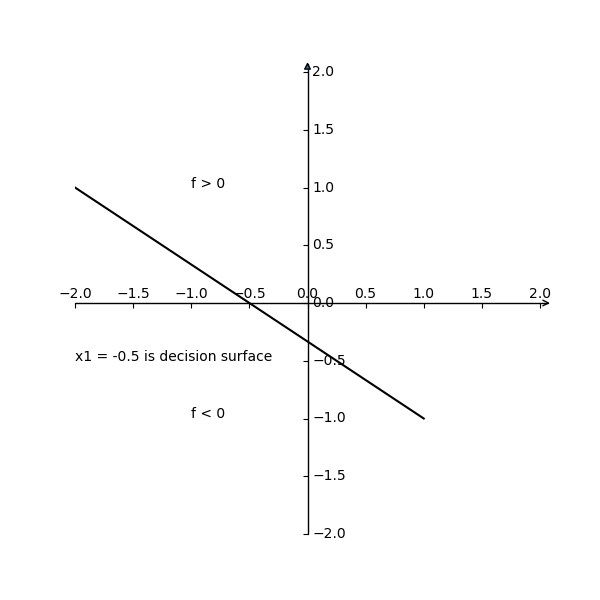
(3) バイアス項への入力を1に固定せず, x0も変数と考え, (x0,x1)平面内に識別関数値が−6,0,6となる等高線を描け.
識別関数f(x)=w^Tx,x=(x0,x1)T,w^T=(−31,−32)より
y=f(x)=(−31,−32)(x1x0)=−31x0−32x1
識別間数値が−6, 0, 6から順:
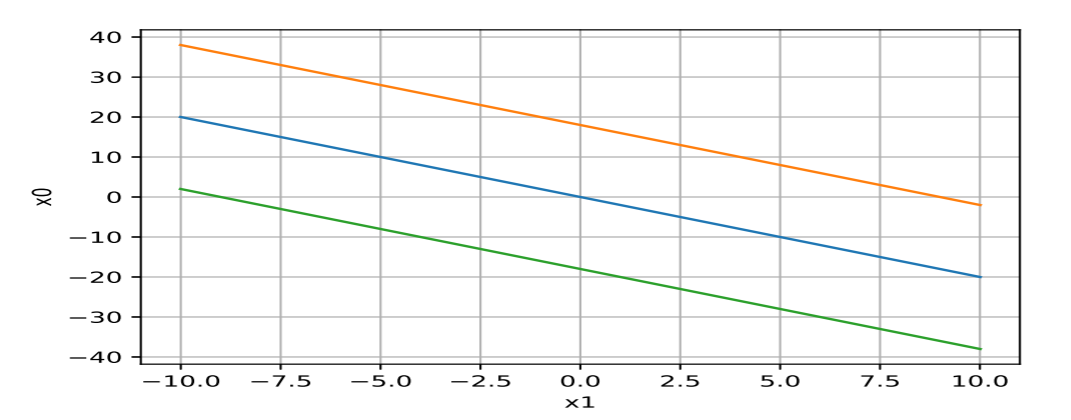
課題6.3

ロジスティック回帰
線形識別関数y=wTxの関数の大きさは、識別境界から離れるに従って線形に上昇し続ける
識別関数値を(0, 1)に制限し, 確率的な解釈を可能にするロジスティック回帰を説明する.
2クラス問題を考える. クラスC1の事後確率P(C1 ∣ x)は
P(C1 ∣ x)=P(x ∣ C1)P(C1)+P(x ∣ C2)P(C2)P(x ∣ C1)P(C1)
であるが,
a=lnP(x ∣ C2)P(C2)P(x ∣ C1)P(C1)
と置けば,
P(C1 ∣ x)=1+exp(−a)1=σ(a)
と表すことができる. 関数σ(a)をロジスティック関数(Sigmoid function)と呼ぶ.
ロジスティック関数の逆関数をロジット関数という
a=ln(1−σ(a)σ(a))=lnP(C2 ∣ x)P(C1 ∣ x)
事後確率の比をオッズ, その対数を対数オッズ (ログオッズ) という.
ロジスティック回帰モデル
ロジスティック回帰モデルは, 2値データ(0, 1)の生起確率をロジスティック関数で表した手法.
喫煙量と肺がんの発症の有無を示す仮想的な例を考える. 喫煙量xの人が肺がんになる確率を
P(1 ∣ x)=f(x)=1+exp(−(w0+w1x))1
とする. パラメータをw=(w0,w1)Tとし, 入力データはx=(1,x)Tとする. a=wTxとすれば,
f(x)=σ(a)=1+exp(−a)1=1+exp(a)exp(a)
となる. このモデルは一般化線形モデルといわれる.
ロジスティック関数の逆関数であるロジット関数とオッズは次のようになる
a=ln1−P(1 ∣ x)P(1 ∣ x)=wTx1−P(1 ∣ x)P(1 ∣ x)=P(0 ∣ x)P(1 ∣ x)=exp(wTx)
喫煙量xと肺がん発生の有無yを示す仮想的な例を下の図に示した
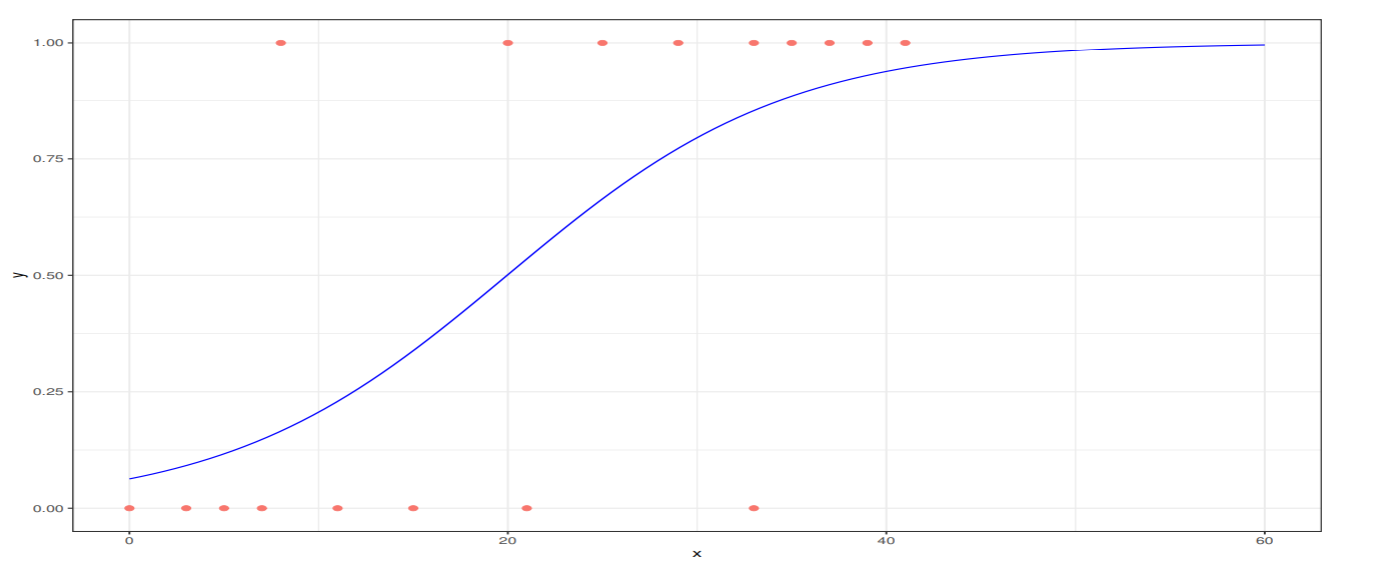
赤い丸が個別事象で, 肺がんの有無を{0,1}の2値で示している.
ロジスティック回帰モデルの係数の最尤推定値は,w0=−2.7,w1=0.135であった.
2クラス識別は, 予測確率が0.5を超えるときにy=1と予測する.
xが1増えた状態を考える. x~=(1,(x+1))T. このときxとx~のオッズ比は,
exp(wTx)exp(wTx~)=exp(w0+w1x)exp(w0+w1(x+1))=exp(w1)
xの1単位の増加はオッズ比がexp(w1)増加する.
オッズ比について
オッズ比の解釈について仮想的な実験を考えよう.
2つの異なる環境で条件を変えて実験を行なった結果を次の図にまとめた.
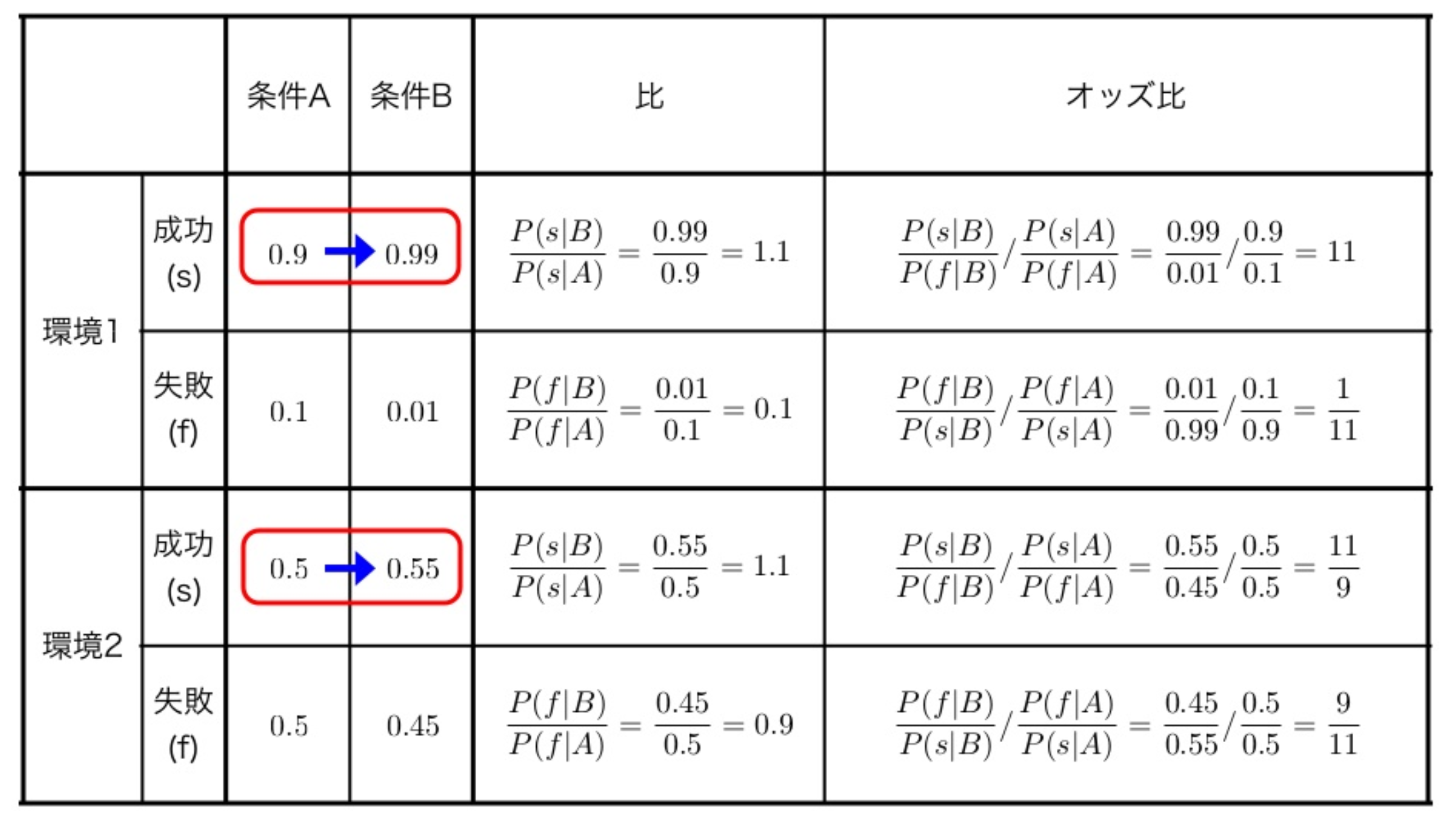
- 環境1と環境2で、条件を変えた時の成功の増加割合は1.1で同じである
- 環境1では成功の割合が殆ど100%に上昇したのに対して、環境2では50%から1割上昇に過ぎない
オッズ比を比べてみると、成功割合の増加についての質的な違いが現れている
パラメータの最尤推定
2クラスロジスティック回帰モデルのパラメータの最尤推定を考える
確率変数tはモデルの出力
- tが1となる確率: P(t=1)=π
- tが0となる確率: P(t=0)=1−π
確率変数tはパラメータαを持つベルヌーイ試行
f(f ∣ π)=πt(1−π)1−t,t=0,1
に従う.
よって、N回の試行に基づく尤度関数は、
L(π1,⋯,πN)=i=1∏Nf(ti ∣ πi)=i=1∏Nπiti(1−πi)1−ti
となる. これを最大化したい.
負の対数尤度関数は、
L(π1,⋯,πN)=lnL(π1,⋯,πN)−i=1∑N(tilnπi+(1−ti)ln(1−πi))
となる. これを最小化したい.
この評価関数は、交差エントロピー型評価関数という
ここで,
πi=σ(xi)=1+exp(wTxi)exp(wTxi)
を代入し整理して,
L(w)=−i=1∑N{tiwTxi−ln(1+exp(wTxi))}
負の対数尤度関数を最小にするパラメータwを得るために、wで微分することを考える。
∂w∂L(w)=−i=1∑N(tixi−1+exp(wTxi)xiexp(wTxi))=i=1∑Nxi(πi−ti)
∑i=1Nxi(πi−ti)=0となるwが解であるが、解析的に解くことは不可能なので、最急降下法やニュートン・ラフソン法で数値的に求める。
多クラス問題への拡張と非線形変換
多クラスK>2への拡張は, 各クラスごとに線形変換ak=wkTxを求め, 事後確率を最大にするクラスに分類すればよい.
P(Ck ∣ x)=πk(x)=∑j=1Kexp(aj)exp(ak)
この関数はソフトマックス関数という.
線形関数でうまく分離できない場合, 非線形関数φ()
φ(x)=(φ0=1,φ1(x),⋯,φM(x))T
とし, 変換したM+1次元空間でロジスティック回帰を行う.
変換されたM+1次元空間でロジスティック回帰をak=wkTφ(x)と行なっても, その空間内での識別境界は超平面になる. このような非線形関数を非線形基底関数という.
クラス数をK, 学習データをX=(x1,⋯,xN)T, 教師データをT=(t1,⋯,tN)Tとする.
i番目のデータxiに対応する教師データtiはダミー変数表現のベクトルで,xiが所属するクラスがkならtikのみが1でそれ以外の要素は0である.
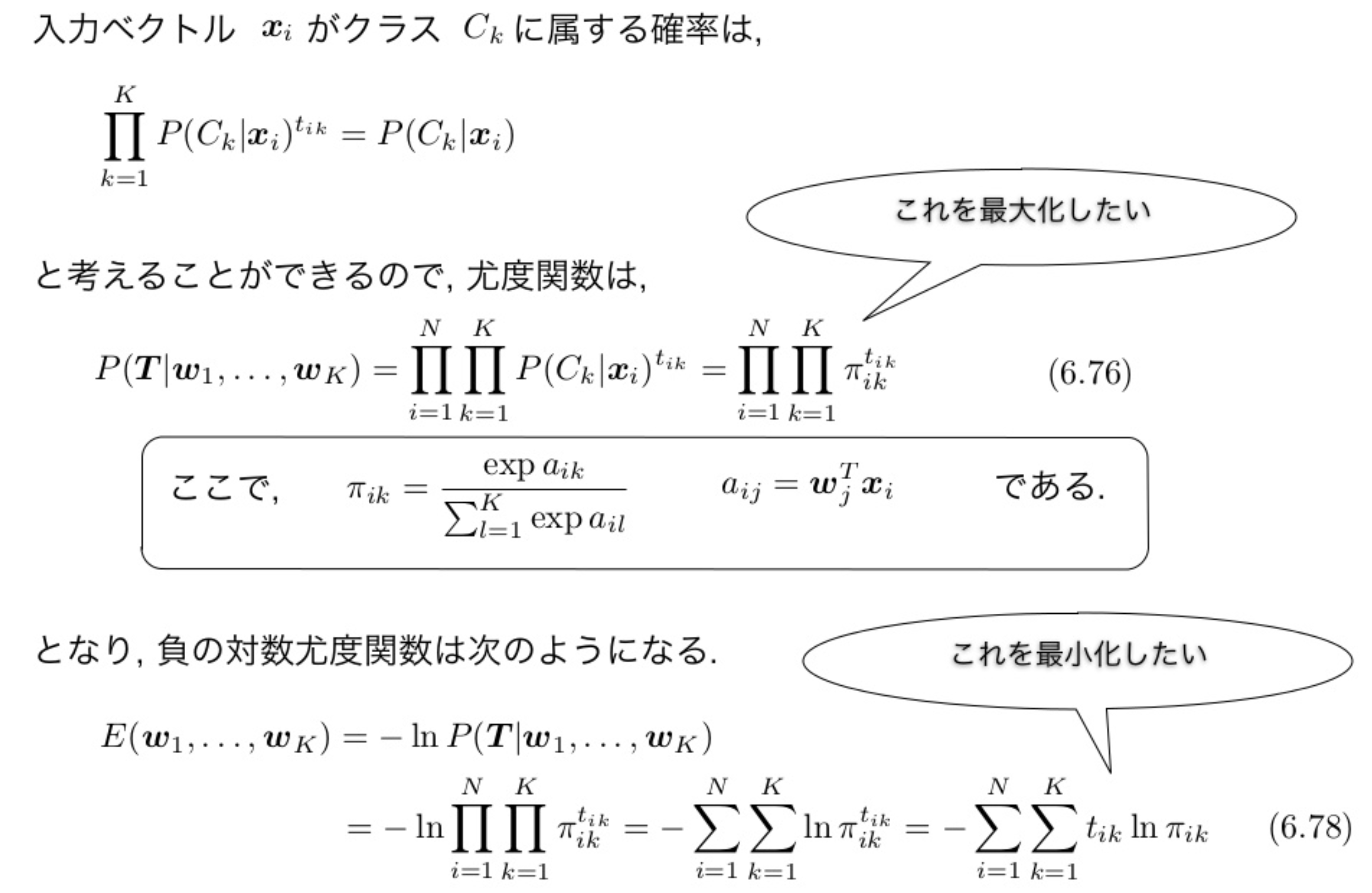
各wjの最尤推定は、評価変数をwjで微分して0とおけば求められる。
ここで、
πik=∑i=1Kexp(aij)exp(aik),aij=wjTxi
よって、
∂wj∂E=−i=1∑Nk=1∑Ktikπik1πij(δjk−πik)xi=i=1∑N(πij−tij)xi=0
同じく解析的に解けないので、2クラスの場合と同様、ニュートン・ラフソン法などを用いて解くことになる。
非線形基底関数による変換とロジスティック回帰
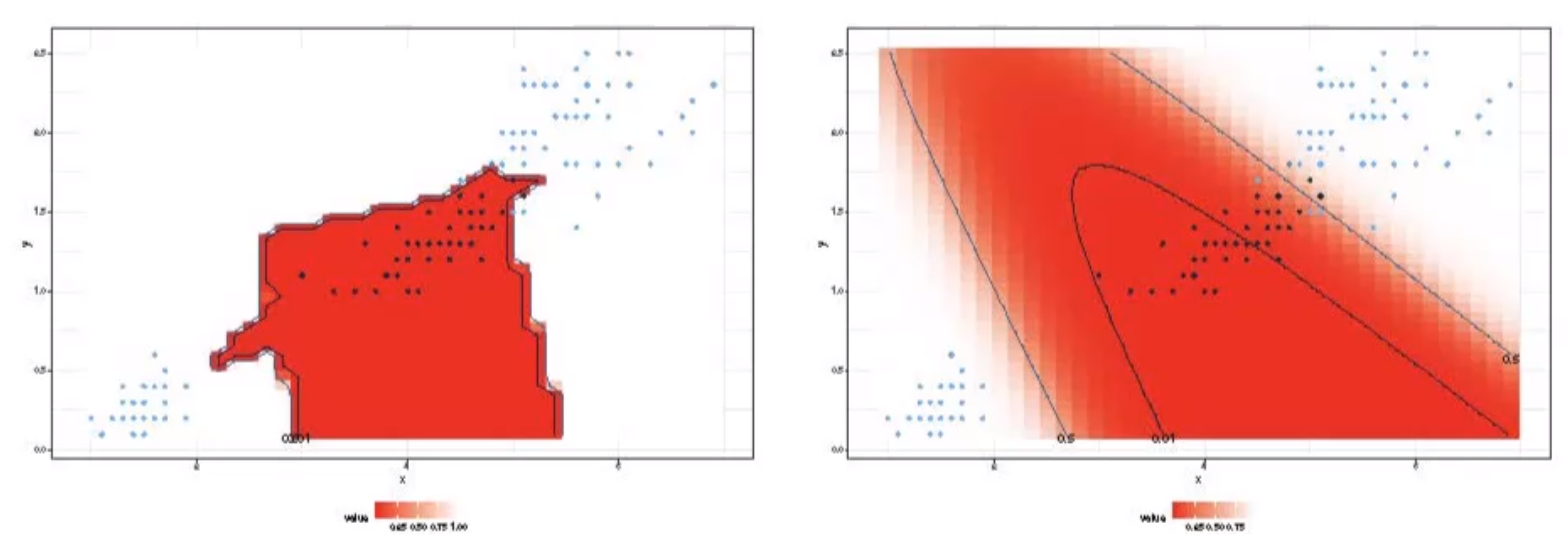
非線形基底関数を使った2クラスロジスティック回帰の分析例を紹介する.
2次元あやめデータの setosa と virginica を1クラスにまとめて, 線形分離不可能な2クラス問題のデータを用意した.

ここでは, ガウス核関数を用いる.
f(x)=exp(−α(x−μ)TΣ−1(x−μ))
ここでαは核関数の広がりを, μは中心を,Σは広がりの形を制御するパラメータ.
Setosaの分布からαs=0.005,
μs=(−7.610.22)T,Σs=(0.72−0.53−0.530.84)
とし, Versicolor の分布からαc=0.1,
μs=(1.83−0.73)T,Σc=(1.070.240.240.76)
以下の図は,ガウス核関数の等高線を示したもの. setosa はfsが大きく, fcが小さな値の領域に, versicolor は fsが小さくfcが大きな領域に, verginica は両方とも小さな値の領域に写像される.
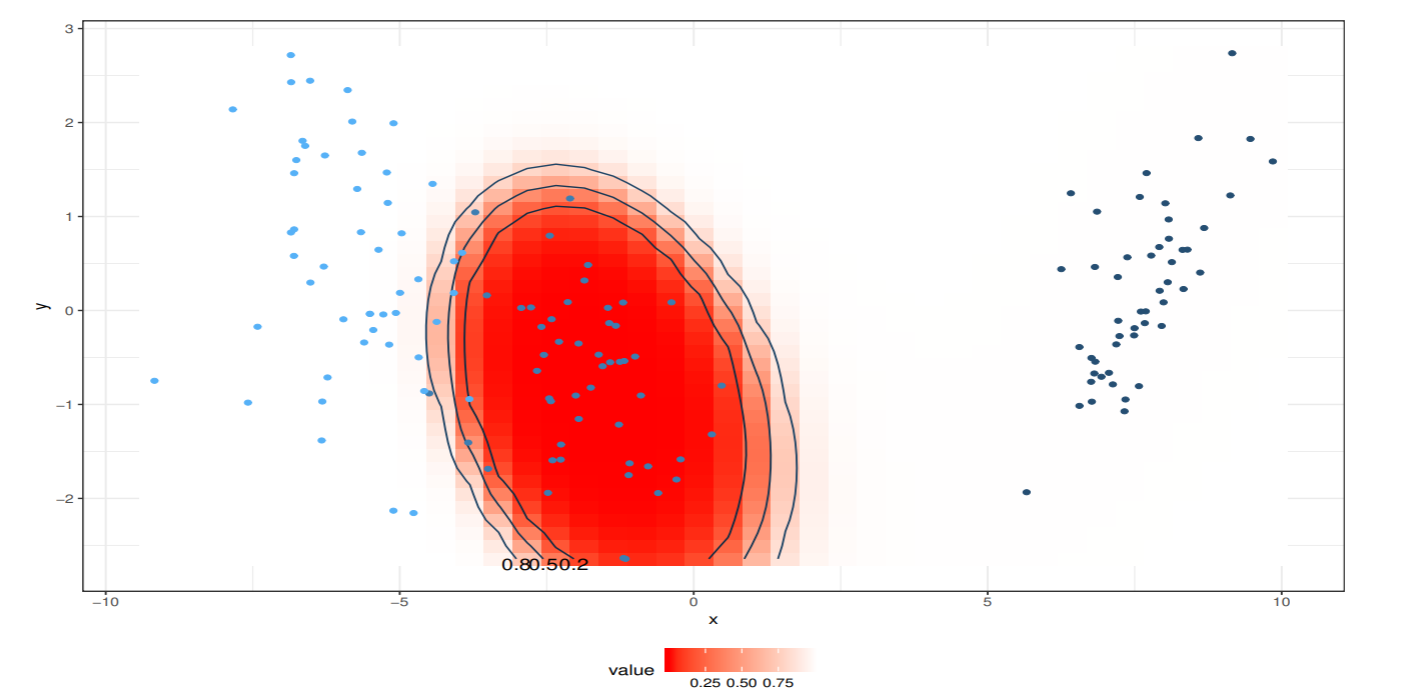
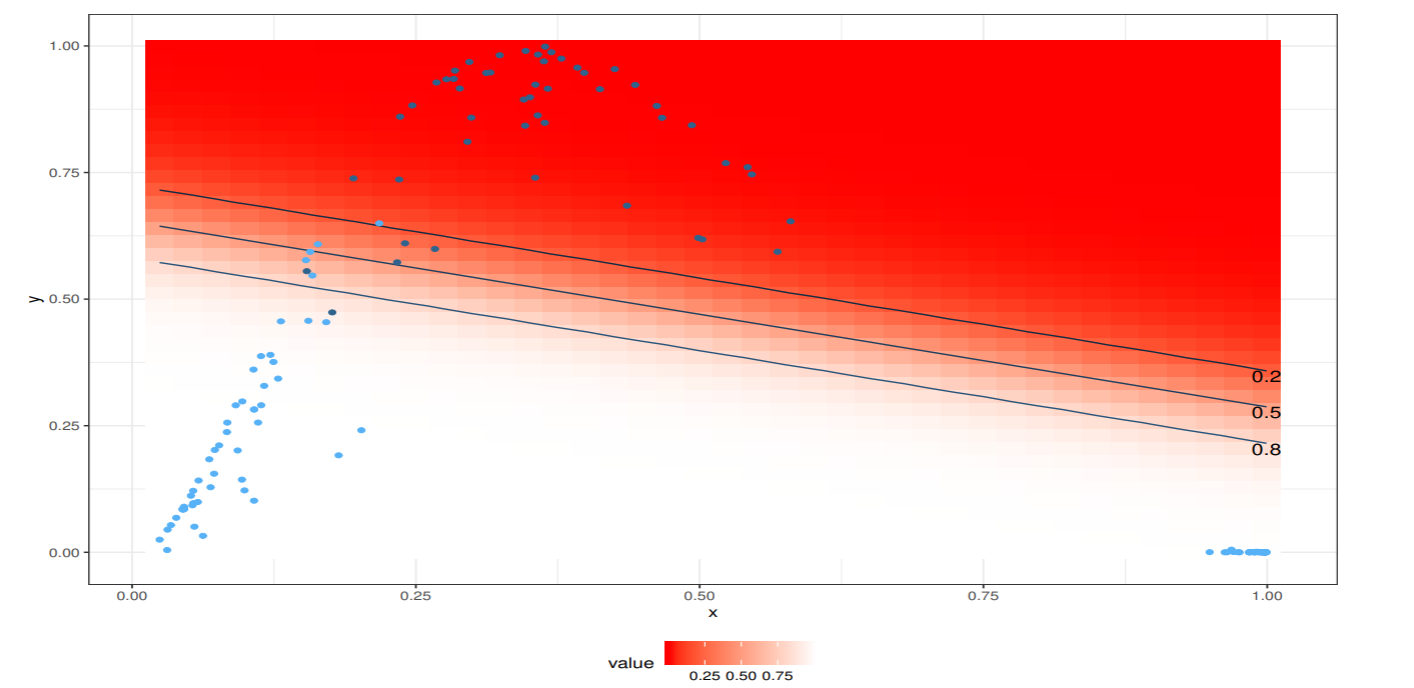
以下の図では, 非線形特徴空間での分布と, 線形ロジスティック回帰モデルによる事後確率が0.2, 0.5, 0.8の等高線を示した.
事後確率が0.5のところが識別境界である.
ピマインディアンデータのロジスティック回帰
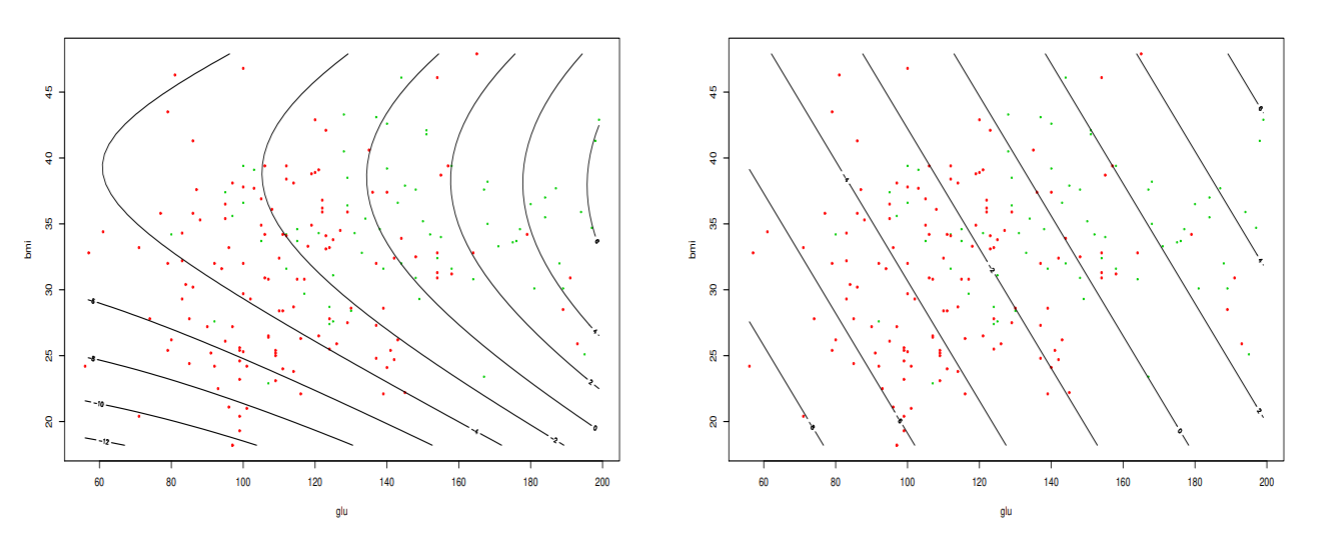
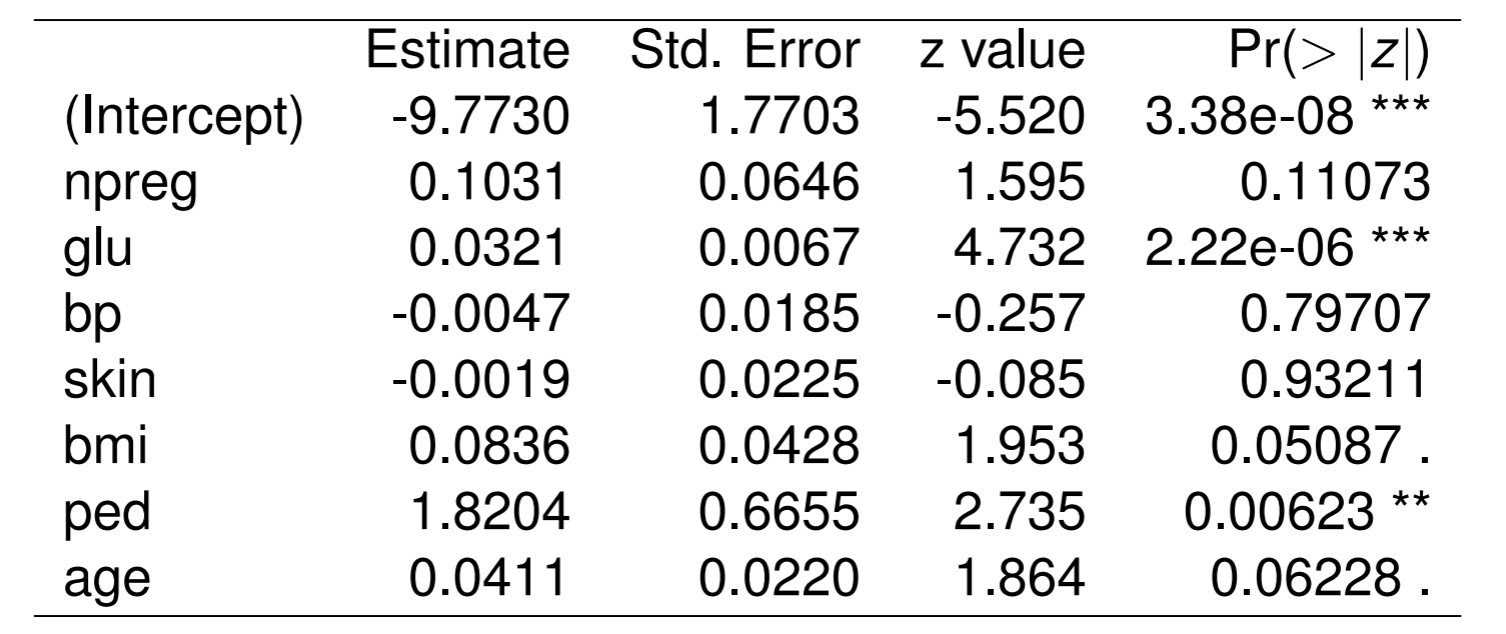
ピマインディアンデータの7変数の特徴量を用いたロジスティック回帰を行う.
入力ベクトルは, 妊娠回数 (npreg), 血漿グルコース濃度 (glu), 血圧(bp), 脂肪厚 (skin), 肥満度 (bmi), 糖尿病家系関数 (ped), 年齢 (age)であった.
係数の推定結果は以下である
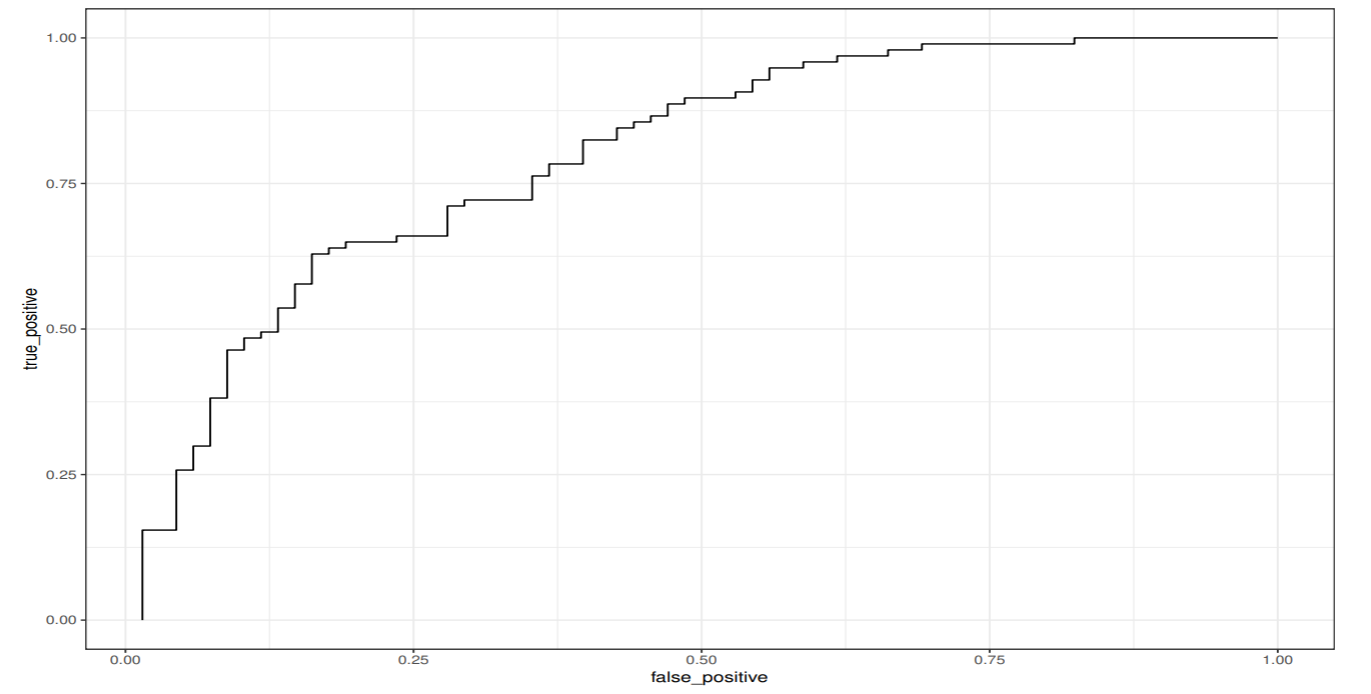
ロジスティック回帰では、事後確率の値を0.5から上下に変更することで識別境界を変えることができる.
このとき, 識別境界を様々な事後確率の値で取ることで, 真陽性率, 偽陽性率が得られる.
パーセプトロン型学習規則(Perceptron)
パーセプトロンの学習規則は2クラスの線形識別関数を求める古典的な方法
パーセプトロンの収束定理: 2クラスが線形分離可能であれば, パーセプトロン学習規則のアルゴリズムは収束する.
パーセプトロンを多層化し, 非線形識別関数を使った, 誤差逆伝搬法(BP)は線形分離可能性の制約を外した手法
局所最適解がたくさんあること, 解の解釈が困難であることがデメリットだが, ディープラーニングへ発展する重要なモデルである.
パーセプトロン
線形識別関数 f(x)=wTx を用いて, f(x)≥0 のとき x∈C1,f(x)<0 のとき x∈C2 とする 2 クラス問題を考える. 同時座標系を用いて w=(w0,⋯,wd)T とする.
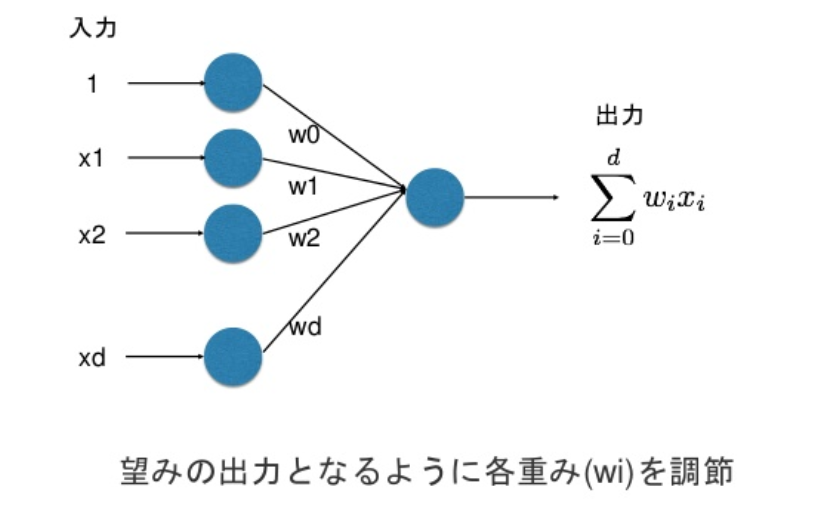
各入力に重みをつけて総和を出力とするネットワークモデルをパーセプトロンと呼ぶ
データが線形分離可能であるとき, 片方のクラスに属するデータの符号を反転させると, どちらのクラスも超平面の同じ側にできる. 分類が正しければ f(x)≥0 となり, 誤っていれば f(x)<0 となる.
学習データの系列を x1,⋯,xi,⋯ とする. パーセプトロンの学習規則は i+1 番目の係数ベクトルを wi+1 を, i 番目の学習データ xi を入力したときの出力 f(xi) に応じて,
{f(xi)≥0,wi+1=wif(xi)<0,wi+1=wi+ηxi
とする.
- η は学習の収束速度を決めるパラメータで, η=1 の場合を固定増分誤り訂正法と呼ぶ.
学習の難しさの尺度
学習データが識別超平面からある値 h>0 (マージンとよぶ) より近い距離であれば誤りとして w を更新するようにすれば, h より小さなノイズに対して正しく識別できるようになる.
ステップ関数
f(a)={1,a>00,a≤0
を用いれば wi の更新量 Δwi は, 符号反転を行った学習データについて
Δwi=ηf(h−wiTxi/∥wi∥)xi={ηxi,0,h>wiTxi/∥wi∥h≤wiTxi/∥wi∥
と書くことができる.
マージンの大きさ
マージンの大きさ D(w) は, C2 の学習データを識別関数の法線ベクトル上に射影した長さの最小値の半分である.
ρ(w)=x∈C1min∥w∥wTx−x∈C2max∥w∥wTx
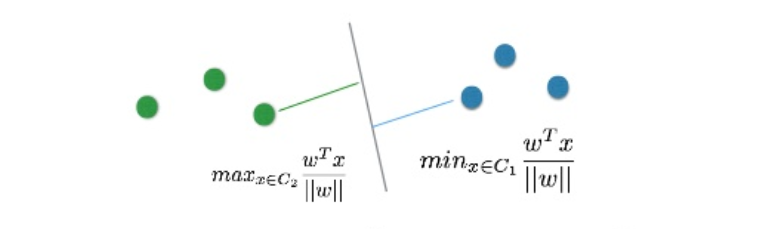
ρ(w) をクラス間マージンとよび, 最大マージンは最大クラス間マージンの半分である.
Dmax=21ρmax(w)
符号反転を行った場合, すべての学習データを超平面の法線ベクトル上に射影した最小値
D(w)=x∈C1,C2min∥w∥wTx
パーセプトロンの収束定理
パーセプトロンの収束定理とは, パーセプトロンの学習規則が有限の学習回数で収束すること.
マージン h は, 次元ごとに α の大きさを取り, h=αd とする. 同次座標系で表現されたデータ xi が学習で使用された回数を Mi とすると, 学習の総数は M=∑iMi となる.
M 回の学習で獲得された係数ベクトル w は, 初期値を 0 として,
w=ηxi∈C1,C2∑Mixi
学習が収束したときの係数ベクトルを w∗ とし, w との内積を計算すると, 内積は M に比例して増加し, 係数ベクトルは解ベクトルに近づく.
wTw∗=ηxi∈C1,C2∑MixiTw∗≥ηMxi∈C1,C2minxiTw∗=ηMD(w∗)∥w∗∥
∥w∥ の上限を求める. 学習データの長さが ∥xi∥2 を満たしていると仮定し, xi による係数ベクトルの変化量を求めると,
Δ∥w∥2=∥w+ηxi∥2−∥w∥2=η2∥xi∥2+2ηwTxi≤η2d+2ηαd=dη(η+2α)
w と w∗ の方向余弦の 2 乗は, ϕ=(wTw∗)2/(∥w∥2∥w∗∥2) となるので, 次が得られる.
Md(η+2α)D2(w∗η)≤ϕ≤1⇒M≤dDmax21+2α/η
学習回数には上限があるので, 学習は収束する. データの次元 d とマージン α が大きくなると, 上限が大きくなるので, 時間がかかる.
Dmax2 に反比例するので, 2 クラス間の距離が大きくなると学習が少なくて済む.
サポートベクトルマシンは, マージンが最大となる線形識別規則を見つける方法.
誤差伝搬法(BP)
多層パーセプトロン
排他的論理和のような線形識別関数では識別出来ないような場合, 別の入力を用意すれば識別できる.
| x1 |
x2 |
出力 |
教師データ |
| 0 |
0 |
0 |
-1 |
| 0 |
1 |
1 |
+1 |
| 0 |
1 |
1 |
+1 |
| 1 |
1 |
0 |
-1 |
第3の素子は, 隠れ素子と呼ばれ, 隠れ素子で構成されるグループを隠れ層という.
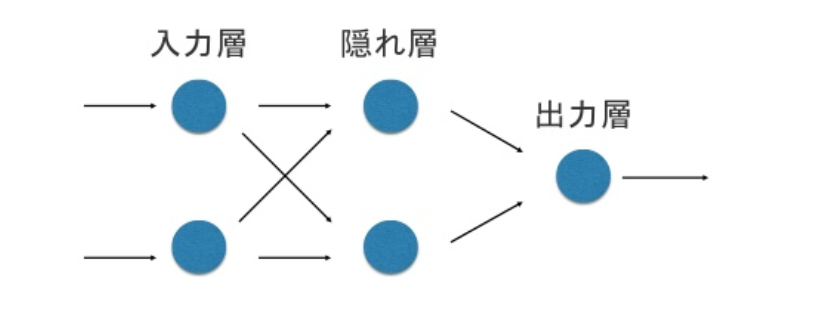
多層回路とは, 隠れ層のみから出力層に入力を与えるような隣り合った層間ネットワークのこと.
多層パーセプトロンの誤差逆伝搬法と呼ばれるパーセプトロン型の学習アルゴリズムを考える.

入力層に学習データ xn(n=1,⋯,N) が与えられている. 学習データの次元を d とする.
バイアス項も含めて n 番目の学習データは xn=(1,x1n,⋯,xdn)T で表す.
n 番目の学習データが入力されると, 隠れ層の素子 Vj=(j=1,⋯,M) には次の入力が入る.
hjn=i=0∑dwjixin=wjTxn
出力関数 g(u) を介して, Vjn=g(hjn) が出力される. g(u) は非線形でなければならない.
g(u) は非線形出力関数とよばれ, u に対して微分可能で, シグモイド関数がよく使用される.
g(u)=1+exp(−βu)1
出力素子 ok(k=1,⋯,K) への入力は, 次のように与えられる.
hkn=j=0∑MwkjVjn=j=0∑Mwkjg(i=0∑dwjixin)
その出力は, 次のように与えられる.
okn=g~(hkn)=g~(j=0∑MwkjVjn)=g~(j=0∑Mwkjg(j=0∑MwkjVjn))
g~(⋅) をソフトマックス関数で表現すると
g~(okn)=∑lKexpolnexpokn(=p(tkn=1 ∣ xn))
確率的な解釈ができる
誤差逆伝搬法の学習規則
隠れ素子から出力素子への結合係数の学習は, 2 乗誤差最小化を最急降下法に従って行う.
n 番目の学習データの評価関数は
En(w)=21k=1∑K(tkn−okn)2=21k=1∑K(tkn−g~(j=0∑Mwkjg(j=0∑MwkjVjn)))2
学習データ全体で E(w)=∑i=1NEn(w) となる.
バッチアルゴリズムでは, 結合係数の修正量を計算し更新することを1エポックという. τ エポックの更新量は,
Δwkj(τ)=n=1∑N(−η∂wkj∂En(w))=−ηn=1∑N(∂okn∂En(w)⋅∂wkj∂okn)=ηn=1∑N(tkn−okn)g~′(hkn)Vjn=ηn=1∑NδknVjn
- δkn は誤差信号で, 出力が 0, 1 に近いときに 0 となり, 学習が進まなくなる.
確率降下法とは n 番目の学習データによる wkj の修正量を次のように与える方法
Δwkjn(τ)=ηδkn(τ)Vjn(τ)
入力素子 xi から隠れ素子 Vj への結合係数 wji の学習のための評価関数は wkj の場合と同じだが, 修正量は次のようになる.
Δwji(τ)=n=1∑N(−η∂wji∂En(w))=ηn=1∑Nk=1∑Kδknwkjg′(hjn)xin
隠れ素子 j の誤差信号を δjn と定義すると, 次の表現を得る.
δjn=g′(hjn)k=1∑Nδknwkj,Δwjk(τ)=ηn=1∑Nδjnxkn
各出力素子で発生した誤差 δkn を結合係数 wkj を介して, 出力素子 k から隠れ素子 j に戻しているので, 誤差逆伝搬法, BP 法 error back probagation 法という.
実行例-手書き数字の学習
MNIST データを使って誤差逆伝搬法による認識実験を行なった. データ数は 1000 とした.
入力層はバイアス項を含めて 14×14+1, 隠れ層の素子数は 10+1 個、出力層はクラス数 10 である.
元のデータは 28×28 の画像だが、縦横 21 に圧縮したものを入力とした.
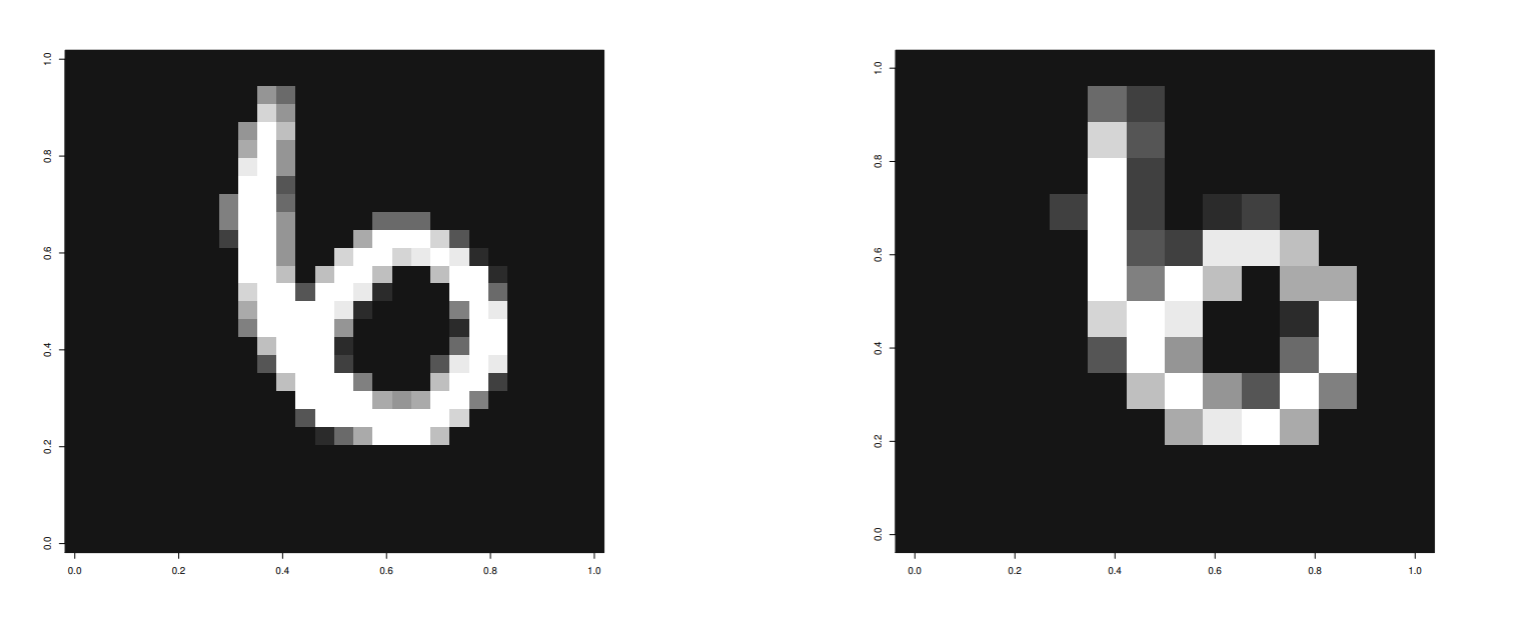
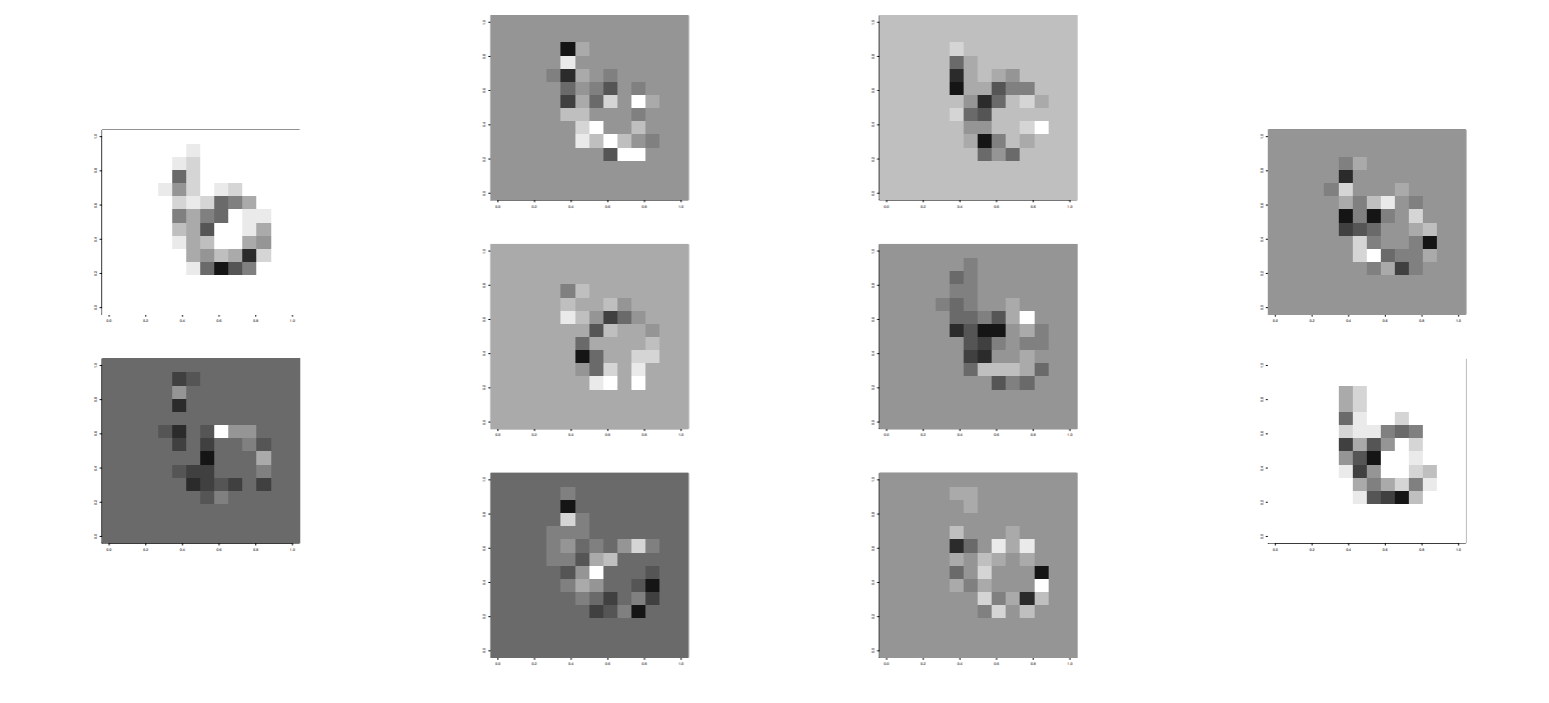
10 個の隠れ素子の画像
出力は 6 の確率が 0.9999988, 8 の確率が 0.0000012, あとの確率は 0 より, 6 と識別された.
隠れ素子数を 10 とした場合、再代入誤り率は 0 で、テストデータの誤り率が 20% 程度であった.
隠れ素子数を 1 から 20 まで変えながら誤り率を計算してプロットした, 汎化誤差を最小にする K は 20 であった. そのときの誤り率は13%であった.
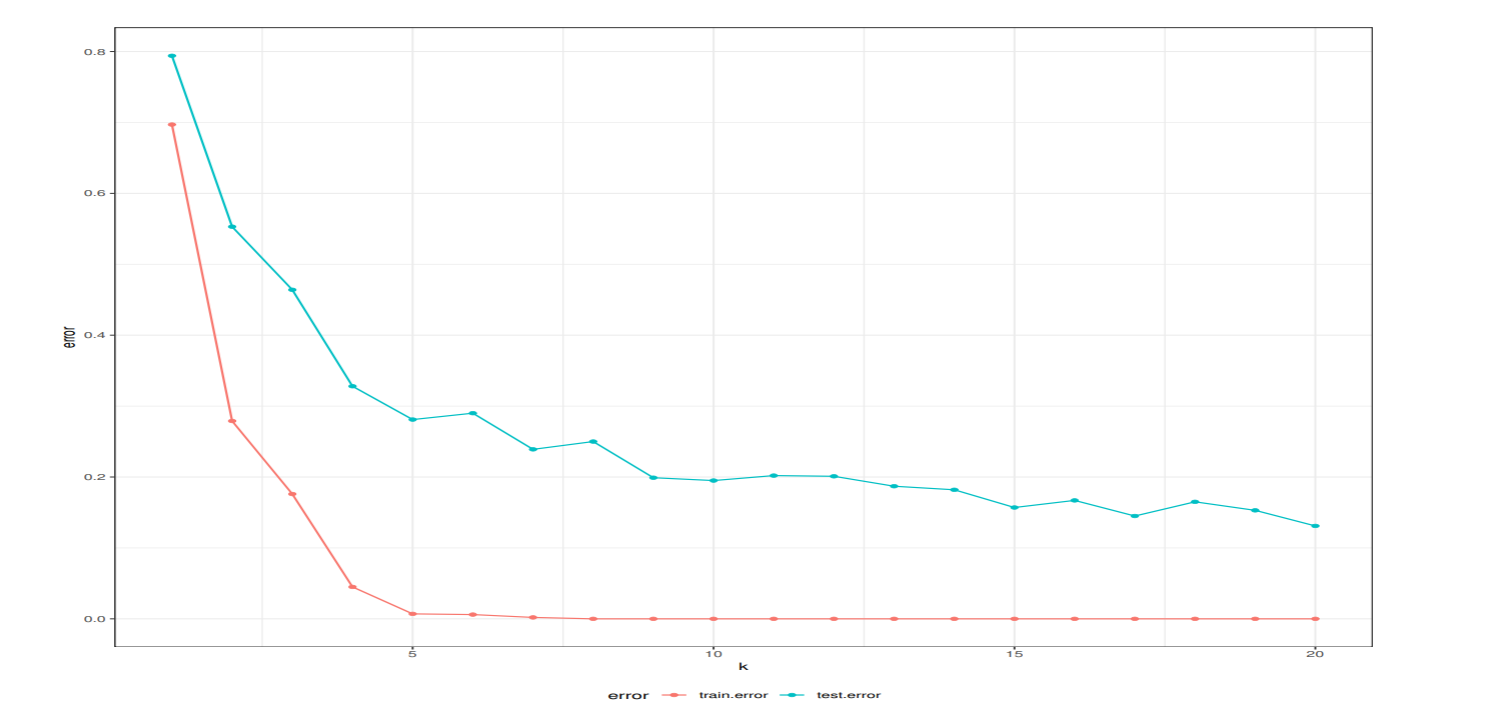
誤差逆伝搬法の学習特性
初期値依存性
初期値依存性: 非線形最適化問題を解く際, 最急降下法や共役勾配法を使う. そのとき, 大域的な最適解を得ることは難しく, 初期値に依存した局所解を学習することがある.
隠れ素子の数
隠れ素子の数は多ければ多いほど良いのであろうか?
実行例-初期値依存性と隠れ素子の数による誤り率の変化
ピマ・インディアンデータを用いて初期値依存性と隠れ素子の数が誤り率にどのように影響を与えるか検証した.
標準化した 7 つの特徴すべてを用いて学習した. 初期値を変えて 20 回学習したときの誤り率をプロットした.
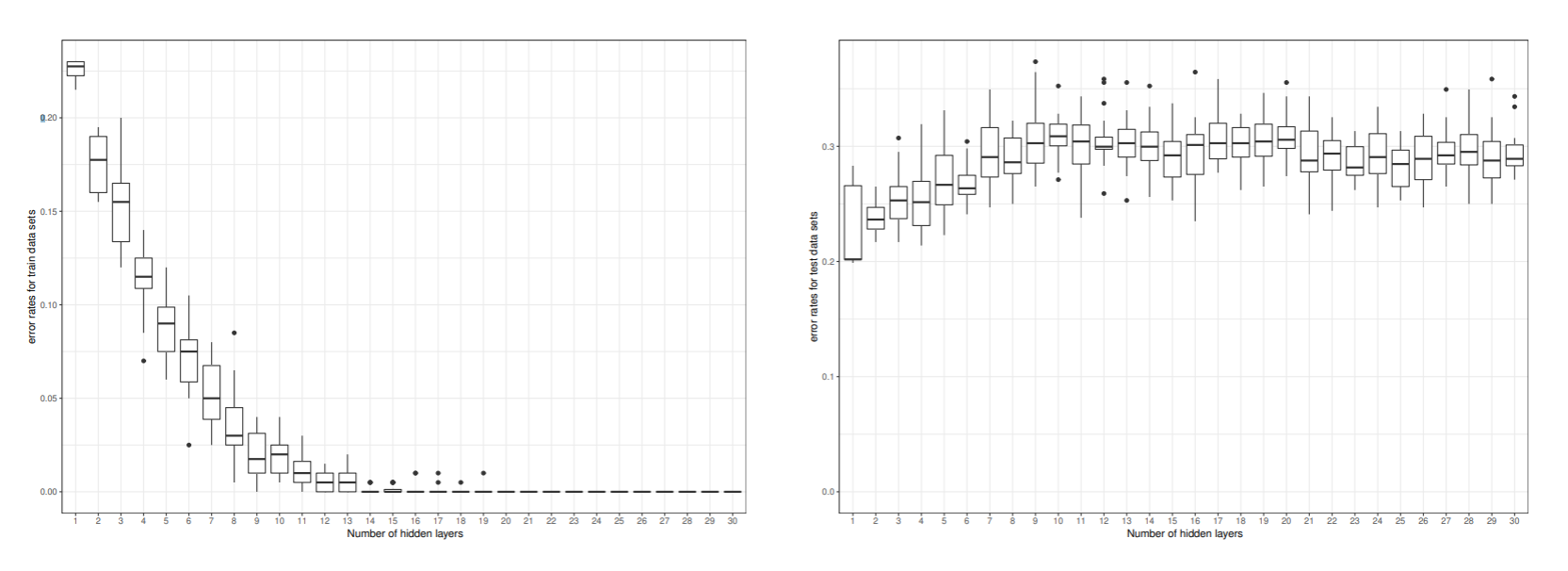
再代入誤りは隠れ素子数が20以上で殆ど0になっているが, 汎化誤差は隠れ素子数が3のところで最も低い値を取っている. 隠れ素子数を更に増やすと, 汎化誤差が次第に増加する. このような現象は, 過学習と言われる.
最適な隠れ素子数はホールドアウト法や交差確認法などで求める必要がある
過学習と正則化
隠れ素子の数が多くなると過学習が起きやすい. また非線形性が強くなっても過学習が起きやすい. 結合係数が大きくならないような正則化法が提案されている.
正則化は, 誤差の評価関数にペナルティ項を加えた次の式で実現される.
E~(w)=E(w)+λR(w)=21n=1∑Nk=1∑K(tkn−okn)2+λ(i=0∑dj=1∑Mwji2+j=0∑Mk=1∑Kwkj2)
- この正則化を荷重減衰ペナルティ(weight decay penalty)という
- λ を正則化パラメータという.
実行例-あやめデータにおける正則化項の効果
setosaとvirginicaを一つのクラスにまとめたあやめデータに対して, 隠れ素子数は10にして学習した
左が正則化項を用いない場合の識別境界で, 右が λ=0.01 としたときの識別境界
結合係数の個数は, 入力層から隠れ層に対して 2×10+10, 隠れそうから出力層に対して 10×2+2 で, 合計 52 個のパラメータ.

結合係数の大きさのヒストグラムより, 正則化項を用いない場合の結合係数は, 用いた場合よりも一桁大きな値になっている.
隠れ層の数と識別能力
隠れ層はいくあってもよい.
- 1層は直線状の識別境界
- 2層なら凸領域
- 3層なら飛び地や穴の空いた領域が表現できる.
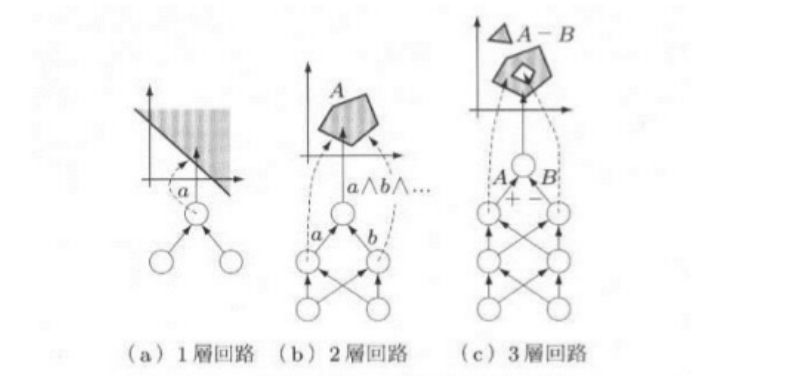
層の数が増えると, 表現できる識別関数は複雑になる
学習回路の尤度
尤度関数を誤差関数として使用すると良い
出力の活性化関数と誤差関数 ⇒ 解くべき問題の型で選択
|
活性化関数(出力関数)g() |
誤差関数E() |
| 回帰問題 |
線形出力関数 |
二乗和誤差 |
| 2クラス分類問題(多数の独立な) |
ロジスティックシグモイド関数 ソフトマックス関数(2クラス) |
二乗和誤差 交差エントロピー誤差関数 |
| 多クラス分類問題 |
ソフトマックス関数 |
多クラス交差エントロピー誤差関数 |
クラス分類問題では, 交差エントロピー誤差関数を使う方が訓練が早く, 同時に汎化能力が高まる
サポートベクトルマシン(SVM)
サポートベクトルマシンは, もっとも広く利用されているパターン認識学習アルゴリズムの一つで, 最大マージンを実現する2クラス問題の線形識別関数構成法.
マージン最大化は, 学習データによって与えられた不等式制約条件下で最適化問題を解くことで得られる. 線形分離不可能な場合もスラック変数の導入により誤り最小の線形識別関数を得ることができる.
線形分離不可能な場合のさらに良い対処法は, 非線形特徴写像により高次元非線形特徴空間に写像し, 線形分離可能にすることである. 高次元空間の内積計算にはカーネルトリックを用いる.
サポートベクトルマシンには様々な変種があるが, υ-サポートベクトルマシンと1クラスサポートベクトルマシンを紹介する.
サポートベクトルマシンの導出
サポートベクトルマシンSVMは最大マージン Dmax を実現する2クラス線形識別関数の学習法である
最適識別超平面
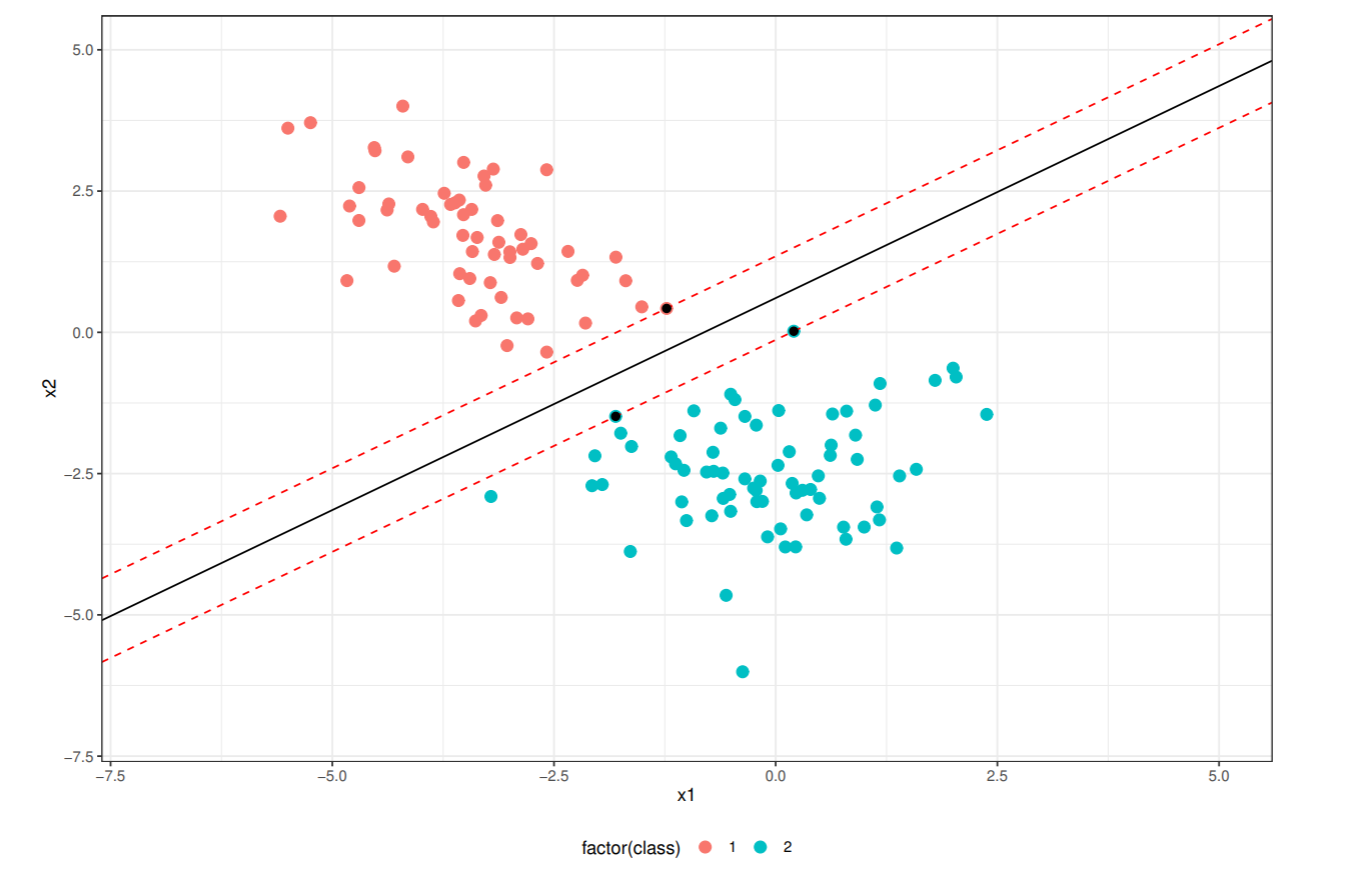
標準座標系を考え, クラスラベル付き学習データの集合を DL={(ti,xi)}(i=1,⋯,N) とする. ti={−1,+1} は教師データであり, 学習データ xi∈Rd がどちらのクラスに属するかを指定する.
線形識別関数のマージンを κ とすれば, すべての学習データに対して, ∣wTx+b∣≥κ が成り立つ. κ で正規化すると線形識別関数は
ti=+1,wTxi+b≥+1ti=−1,wTxi+b≤−1
となる. この場合分けは ti(wTx+b)≥1 とまとめることができる.
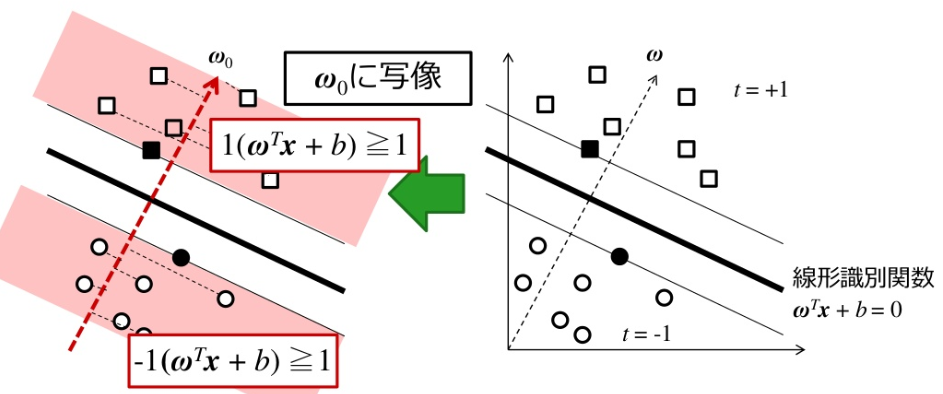
クラス間マージンは, 各クラスのデータを w の方向へ射影した長さの差の最小値で与えられる.
ρ(w,b)=x∈Cy=+1min∥w∥wTx−x∈Cy=−1max∥w∥wTx=∥w∥1−b−∥w∥−1−b=∥w∥2
最適な超平面の式を w0Tx+b0=0 とすれば, この超平面は最大クラス間マージンを与える.
ρ(w0,b0)=wmaxρ(w,b)
最適識別超平面は ti(wTx+b)≥1 の制約下で, w のノルムを最小にする解
w0=min∥w∥
として求めることができる.
KKT条件
KKT条件
マージン最大の最適識別超平面は, 次の不等式制約条件の主問題を解くことで得られる.
主問題 1:
評価関数(最小化)Lp(w)=21wTw不等式制約条件ti(wTxi+b)≥1
この問題は, 次のラグランジュ関数として定式化される.
L~p(w,b,α)=21wTw−i=1∑Nαi(ti(wTxi+b)−1)
ここで α=(α1,⋯,αN)T(αi≥0) はラグランジュ未定乗数である.
この最適化問題の解 w0 と b0 は次のKKT条件を満たす解として得られる.

KKT条件(1)より, 最適解は
w0=i=1∑Nαitixi
となるので, 最適解は有効な不等式制約条件をもつ学習データの線形結合となる. この解とKKT条件(2)をラグランジュ関数に代入すれば
Ld(α)=21w0Tw0−i=1∑Nαitiw0Txi−bi=1∑Nαiti+i=1∑Nαi=i=1∑Nαi−21w0Tw0=i=1∑Nαi−21i=1∑Nj=1∑NαiαjtitjxiTxj
が得られる. 最適解が学習データの線形結合で表現されることから係数 αi を求める問題に置き換えることができる.
最適な αi は Ld(α) を最大にする α により得られる. これを主問題に対する双対問題という.
N 個の1を並べたベクトルを 1=(1,⋯,1)T, 学習データから作られる行列を H={Hij=titjxiTxj}, 教師データベクトルを t=(t1,⋯,tN)T とする
双対問題1
評価関数(最大化)Ld(α)=αT1−21αTHα制約条件αTt=0
と表現できる. 従って, 双対問題のラグランジュ関数 L~d(α) は, ラグランジュ未定乗数を β とすれば
L~d(α,β)=21αTHα−βαTt
となる.
サポートベクトル
KKT条件(5)より, αi(ti(wTxi+b)−1)=0 がすべての i=1,⋯,N で成り立てばよいので
ti(wTxi+b)−1)=0,αi>0ti(wTxi+b)−1)=0,αi=0
となる. αi>0 となる xi をサポートベクトルといい, 最適識別超平面を構成する要素となる.
ラグランジュ乗数法による最適解を α~=(α~1,⋯,α~N)T とすれば
w0Tw0=i=1∑Nα~itixiTw0=i=1∑Nα~(1−tib0)=i=1∑Nα~i
となるので, 最大マージンは
Dmax=∥w0∥1=w0Tw01=∑i=1Nα~i1
線形分離可能な場合
ワインデータから2クラスを選択し, 線形判別分析を使い2次元に射影したデータを使う.
線形分離可能でない場合への拡張
線形分離可能でない場合, 制約条件をすべて満たす解は求まらない. 次のような変数 ξi を導入し, ti(xiTw0+b)−1+ξi≥0
ξi=0,マージン内で正しく識別できる場合0<ξi<1,マージン境界を超えるが正しく識別できる場合ξi>1,識別境界を超えて誤識別される場合
とすると, 制約条件を満たすことができる. 変数 ξi をスラック変数といい, このような手法をソフトマージン識別器という.
ξi は
ξi=max[0,1−ti(wTxi+b)]=f+(1−ti(wTxi+b))
のように表現することもできる. 識別器の損失を表現しているので損失関数と呼ばれる. f+ は
f+(x)={x,x>00,x≤0
で定義される.
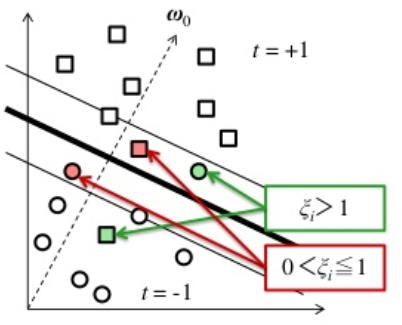
すべての学習データのスラック変数の和 ∑i=1Nξi(ξi≥0) は, 誤識別の上限を数える.
ソフトマージン識別器の主問題2
評価関数(最小化)Lp(w)=21wTw+Ci=1∑Nξi不等式制約条件ti(wTxi+b)−1+ξi≥0,ξi≥0
パラメータ C は誤識別数に対するペナルティの強さを表す. 適切な C は交差確認法などで実験的に選ぶ.
パラメータ C を使うので, C-SVM(C-support vector machine) と略称されている.
KKT条件
ξi≥0 を強制するラグランジュ未定乗数を μi≥0, 誤識別数の上限を抑えるペナルティ定数を C とする.

ソフトマージン最大化
KKT条件(3)から, αi=C となる. このようなサポートベクトルを上限サポートベクトル(bounded SV)という.
ξi=0 で, 0<αi<C となっているサポートベクトルを自由サポートベクトル(free SV)という.
ソフトマージン識別器の双対問題2
評価関数(最大化)Ld(α)=αT1−21αTHα制約条件0≤αi≤C,αTt=0
解ベクトルは, w0=∑i=1Nαitixi で得られ, αi=0 の要素がサポートベクトルである.
線形分離可能でない場合
ワインデータから2クラスを選択し, 特異値分解により2次元に射影したデータを使う.
非線形特徴写像
SVMは解が学習データの線形結合で表される識別超平面となる. 識別境界が学習データの線形関数では表せないような場合には, 誤差逆伝搬法のような非線形識別関数を直接構成することも一つの方法である.
ここでは, 非線形特徴写像を用いて非線形特徴空間に写像し, その空間内で線形識別関数を用いる方法を紹介する.
d 次元の学習データ x∈Rd と, その非線形写像の集合 {φj(x)}j=1,⋯,M を考える.
非線形写像空間のベクトルを, 次のように表す. φ0(x)=1 はバイアス項である.
φ(x)=(φ0(x)=1,φ1(x),⋯,φM(x))T
非線形特徴空間での線形識別関数を次のように表す.
h(φ(x))=j=0∑Mwjφj(x)=wTφ(x)
この非線形空間内でSVMを考えれば, 最適識別超平面は次のようになる.
w0=i=1∑Nαitiφ(xi)
識別関数が
h(φ(x))=w0Tφ(x)=i=1∑NαitiφT(xi)φ(xi)=i=1∑NαitiK(xi,x)
のように, 元の空間のベクトル関数 K(xi,x) を用いて表せれば都合が良い.
このような関数 K(xi,x) を核関数, カーネル関数という.
ソフトマージン識別器のラグランジュ未定乗数 αi は, 次の双対問題を解くことによって得られる.
K(xi,x)=φT(xiT)φ(xj) を (i,j) 要素とする N×N 対称行列 K(X,X) をグラム行列という. X=(x1,⋯,xN)T はデータ行列である.
双対問題3
評価関数(最大化)Ld(α)=i=1∑Nαi−21i=1∑Nj=1∑NαiαjtitjφT(xiT)φ(xj)=i=1∑Nαi−21i=1∑Nj=1∑NαiαjtitjK(xi,x)
制約条件0≤αi≤C,αTt=0
多項式カーネル
実定数 α≥0 に対して, p 次の多項式カーネルを次のように定義する.
Kp(u,v)=(α+uTv)p
u=(u1,u2)T,v=(v1,v2)T とする. α=1 とし, 2次の多項式カーネルを次のように定義する.
K2(u,v)=(1+uTv)2=(1+u1v1+u2v2)2=1+2u1v1+2u2v2+2u1u2v1v2+u12v12+u22v22
u と v に由来する項に分離する
φ(u)=(1,u12,2u1u2,u22,2u1,2u2)Tφ(v)=(1,v12,2v1v2,v22,2v1,2v2)T
すると, K2(u,v)=φ(u)Tφ(v) と表現できる.
動径基底関数カーネル
動径基底関数カーネル, RBFカーネルは次式で定義される.
Kσ(u,v)=exp(−2σ21∥u−v∥2)
σ はカーネル関数の広がりを制御するパラメータである.
動径基底関数カーネルの非線形特徴ベクトルは無限次元となる.
Kσ(u,v)=exp(−2σ21∥u−v∥2)=exp(−2σ2∥u∥2)exp(−2σ2∥v∥2)exp(σ2uTv)=g(u)g(v)exp(σ2K1(u,v))
g(u) と g(v) は最初の二つの指数関数である.
exp(σ2K1(u,v))=i=1∏dexp(σuiσvi)exp(σuiσvi)=n=0∑∞n!1(σuiσvi)n=uiTvi
ピマインディアンデータのSVMによる識別
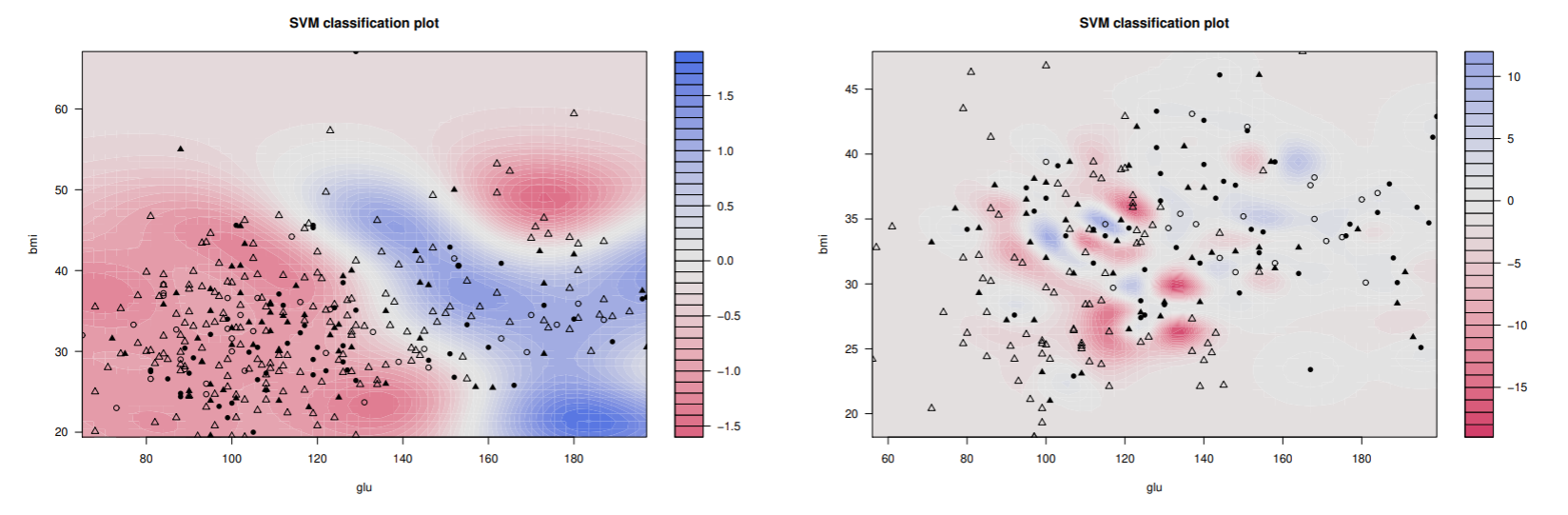
Pima.trデータからgluとbmiを使いSVMによる識別を考えよう.
動径基底関数(RBF)カーネルを使い, σ=0.2,0.4,0.8,4,8 とし, αi の上限を決定するためのパラメータは C=10i,i=0,1,2,3,4 とした.
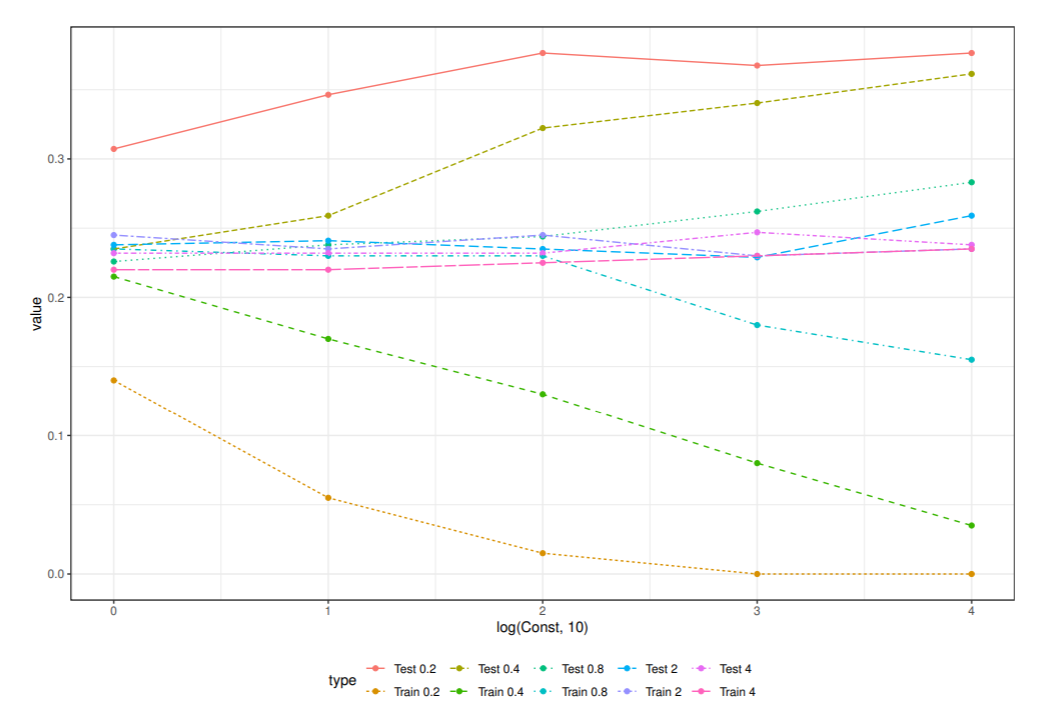
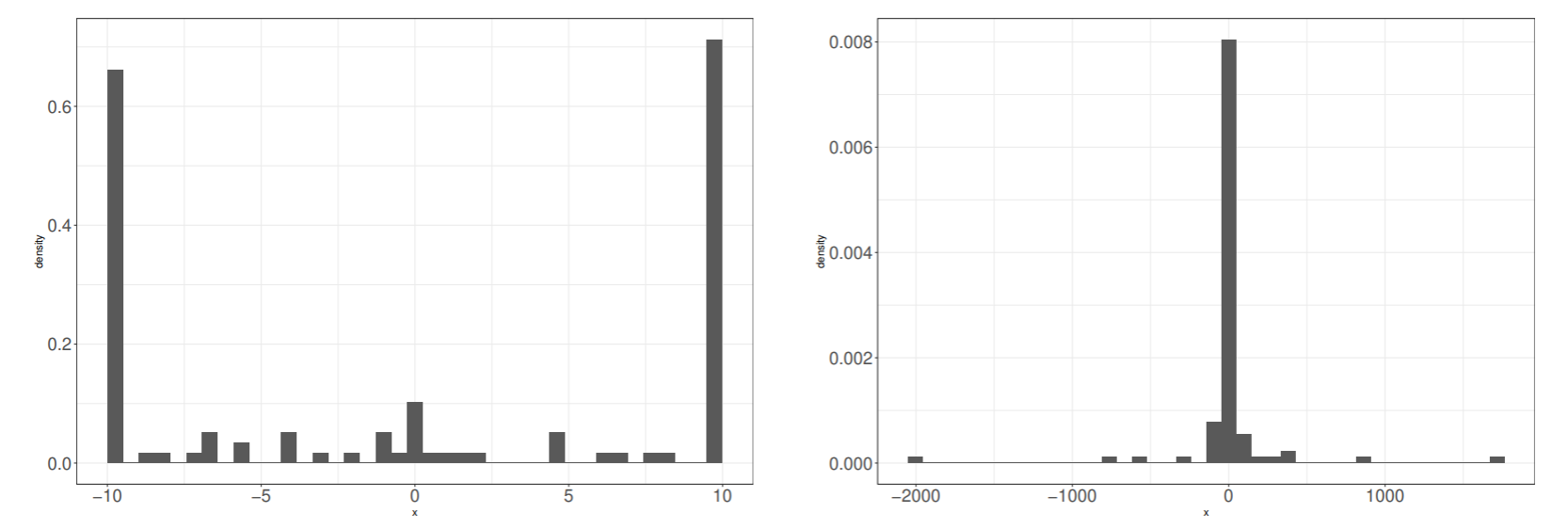
識別関数が学習パラメータによってどのように変わるか見るために,汎化誤差が最小になった場合と訓練誤差が最小になった場合の識別関数とサポートベクトルの分布をプロットした.
汎化誤差が最小になった場合と訓練誤差が最小になった場合のサポートベクトルの係数 tiαi のヒストグラムを示した.
ν-サポートベクトルマシン
ソフトマージン識別器では, C が誤識別数に対するペナルティ係数として導入され, C が αi の上限を決めた. 誤識別数を学習データで割った誤識別率にした方が, 学習データが変わった場合にも対応でき便利.
そこで, 学習器の複雑さと誤り率のトレードオフを ν を介して取り入れたものが, ν-サポートベクトルマシンである.
サポートベクトルマシンの損失関数は
ξi=f+(1−ti(wTxi+b))
であり, 非線形特徴写像を用いた場合, f(xi)=wTφ(xi)+b とすれば,
ξi=f+(1−tif(xi))
となる. ここで損失を
ξi=f+(ρ−tif(xi))
と変更し, ρ の値も最適化することを考える.
最適化問題は, 損失が小さくなるように学習するので, 損失関数から見れば, ρ は小さい方が良い.
一方, マージン ρ が小さいと最適化問題が難しくなり, 結合係数 w のノルムが大きくなる.
そこで, マージンが小さくなりすぎないように評価関数に −ρ に比例した項を加えて最適化問題にする.
主問題4
評価関数(最小化)Lp(w,ρ,ξ)=21wTw−vρ+N1i=1∑Nξi不等式制約条件ti(wTφ(xi)+b)−ρ+ξi≥0,ξi≥0
v=∑i=1Nαi≤N1× サポートベクトルであるから, vはサポートベクトルの割合の下限と上限サポートベクトルの割合の上限を与えている.
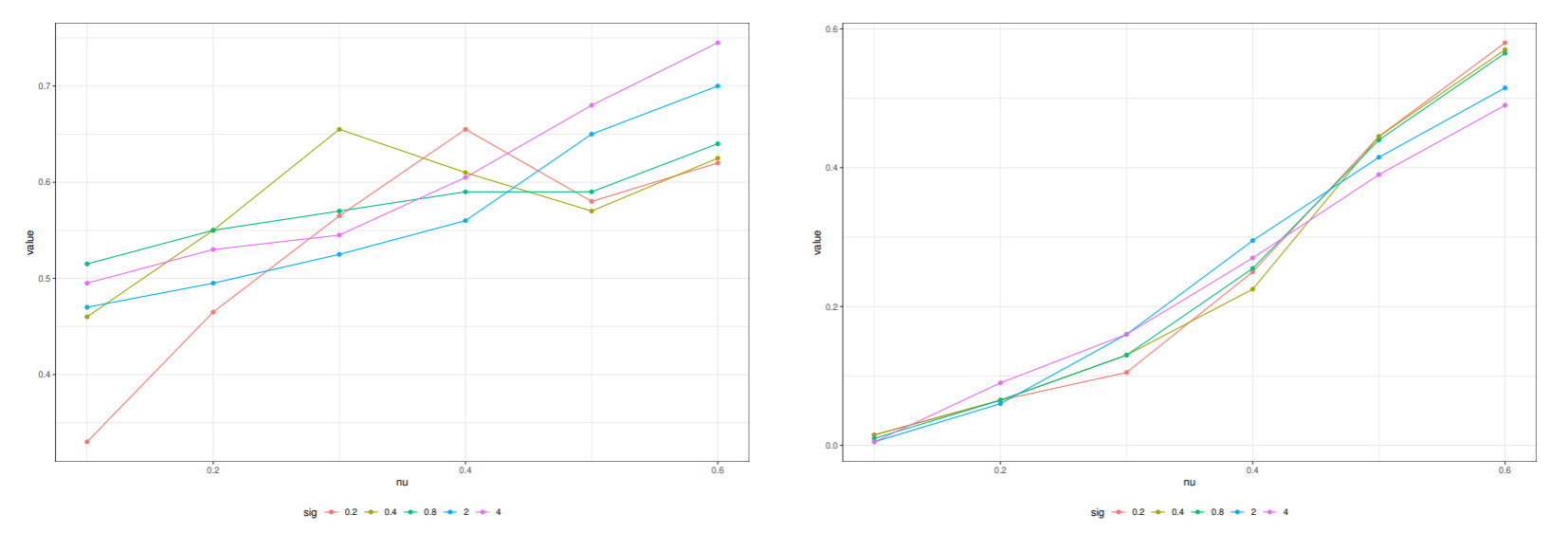
ピマインディアンデータへのν-SVMの適用
ピマインディアンデータの場合 N+=68,N1=132 なので, vmax=0.68 である.
ν を0.1から0.6まで変化させ, 上限サポートベクトルの割合をRBFカーネルのパラメータ σ を変えてプロットした.
1クラスサポートベクトルマシン
サポートベクトルマシンは, 2クラスの識別関数を構成するためのものであったが, 1クラスのみの学習に用い, 入力データがそのクラスに入るか入らないかのみを判断する方法が提案されている. 新規性判断や例外検出, 外れ値検出に利用できる.
主問題5
評価関数(最小化)Lp(w,ξ)=21wTw−ρ+vN1i=1∑Nξi不等式制約条件wTφ(xi)−ρ+ξi≥0,ξi≥0
正例か外れ値かの識別関数は, 次のように与えられ, f(x)=1 のとき正例, f(x)=−1 のとき外れ値である.
f(x)=sgn(i=1∑NαiK(xi,x)−ρ),sgn(a)=⎩⎪⎪⎨⎪⎪⎧+1,0,−1,a>0a=0a<0
ピマインディアンの外れ値検出
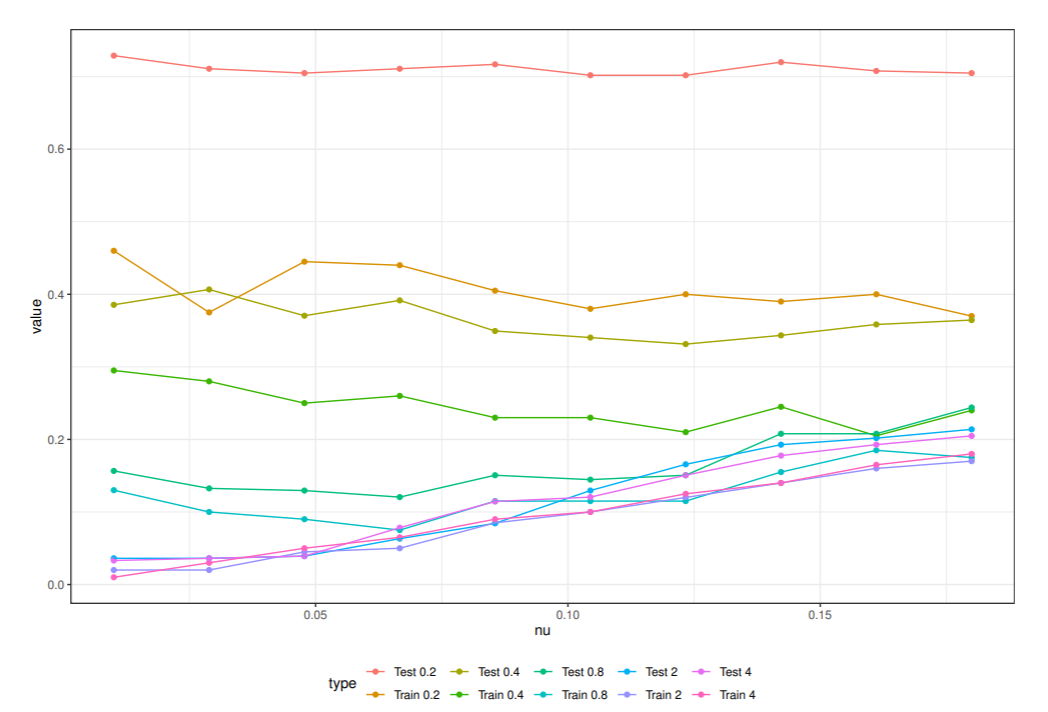
Pima.trを用いて学習したときの外れ値検出率と Pima.te を用いたときの外れ値検出率を図に示した.
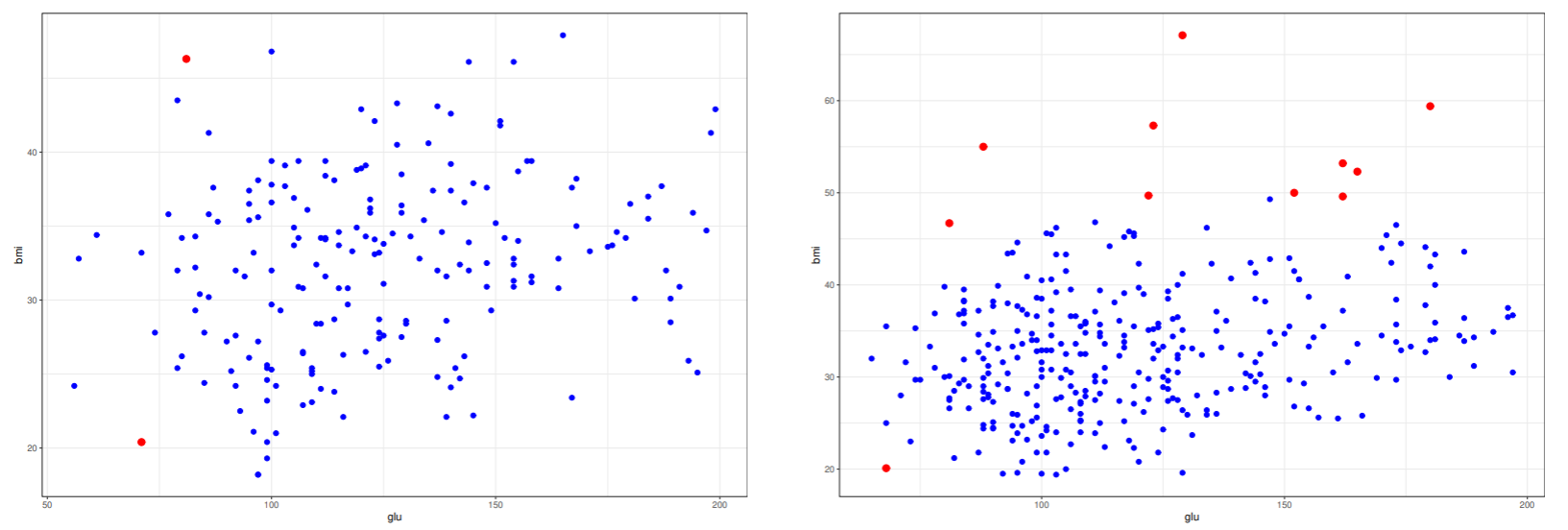
外れ値検出率が最も小さかったパラメータを用いて学習したときのサポートベクトルの位置と, テストデータで外れ値と判断されたデータを図に示した.
部分空間法
計算コストを抑える目的のためにも, 解釈可能な識別器を構成するためにも, データの次元数は少ないほうが良い. ここでは, d 次元特徴ベクトル空間を重要な情報をもつ r(≤d) 次元空間に縮約する方法を紹介する.
主成分分析では, 共分散行列の固有値問題を解き, 大きな固有値に対応する固有ベクトルで部分空間を構成し, 元の情報の低次元で近似する.
クラスごとに主成分分析を行い, それそれのクラスのデータで部分空間を構成して識別器を構成する方法を部分空間法という. 部分空間法は, 多クラス問題への拡張が容易なこと, 識別能力が高いことから, 広く利用されている. カーネル法を取り入れた, カーネル主成分分析やカーネル部分空間法を紹介する.
部分空間
d 次元ベクトル空間 V の部分空間は次のように定義された.
x1,⋯,xr,(r≤d) を V のベクトルとすると
W={a1x1+⋯+arxr ∣ ai∈R,i=1,⋯,r}
は V の部分空間となる.
W が x1,⋯,xr で張られる r 次元の部分空間であるとは, x1,⋯,xr が一次独立であることであった.
W が V の部分空間であるための必要十分条件は以下が成り立つことである.
- W=0
- x,y∈W⇒x+y∈W
- x∈W,λ∈R⇒λx∈W
MNIST 手書き数字を用いて, 28×28 次元ベクトル空間の 10 次元の部分空間を作ってプロットした

ベクトル空間 V は, 部分空間 S とそれと直交する部分空間 S⊥ に分解できた. V=S∪S⊥,S∩S⊥=∅ が成り立つので, 任意のベクトル x は, x=xS+xS⊥ と分解できた.
直交座標系に変換するには, グラムーシュミットの正規直交化を使う.
10 次元部分空間からQR分解によりグラムーシュミットの正規直交基底を作成した.

主成分分析(Principal Component Analysis PCA)
主成分分析方法,是一种使用最广泛的数据降维算法。PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。PCA的工作就是从原始的空间中顺序地找一组相互正交的坐标轴,新的坐标轴的选择与数据本身是密切相关的。其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,第三个轴是与第1,2个轴正交的平面中方差最大的。依次类推,可以得到n个这样的坐标轴。通过这种方式获得的新的坐标轴,我们发现,大部分方差都包含在前面k个坐标轴中,后面的坐标轴所含的方差几乎为0。于是,我们可以忽略余下的坐标轴,只保留前面k个含有绝大部分方差的坐标轴。事实上,这相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,实现对数据特征的降维处理。
主成分分析は, 学習データ xi=(xi1,⋯,xid)T(i=1,⋯,N) の分散が最大になる方向への線形変換を求める手法である
N 個のデータからデータ行列 X=(x1,⋯,xN)T の平均ベクトル x=(x1,⋯,xN)T を求める. x を引いたデータ行列を X=(x1−x,⋯,xN−x)T とし, データの分散共分散行列を次のようにして定義する.
Σ=Var(X)=N1XTX
N 個のデータ xi−x を係数ベクトル aj=(aj1,⋯,ajd)T,(j=1,⋯,d) を用いて線形変換すれば,
sj=(s1j,⋯,sNj)T=Xaj
が得られる. このとき, sj の分散は
Var(sj)=N1sTsj=N1(Xaj)T(Xaj)=N1ajTXTXaj=ajTVar(X)aj
線形変換 sj の分散が最大になる射影ベクトル aj は, ラグランジュ関数
E(aj)=ajTVar(X)aj−λ(ajTaj−1)
を最大にする aj を見つければ良い.
aj で微分して 0 とおけば
∂aj∂E(aj)=2Var(X)aj−2λaj=0⇔Var(X)aj=λaj
aj はデータの分散共分散行列の固有値問題を解けば良い
分散共分散行列が実対称行列なので, 非ゼロの固有値は分散共分散行列のランクで, 最大 d である. 固有ベクトルは直交する.
aiTaj=δij={1,i=j0,i=j
最大固有値が線形変換したデータの分散になる.
Var(sj)=a1TVar(X)a1=λ1a1Ta1=λ1
最大固有値に対応する固有ベクトル a1 を第1主成分という. データの分散は, 固有値の合計になる.
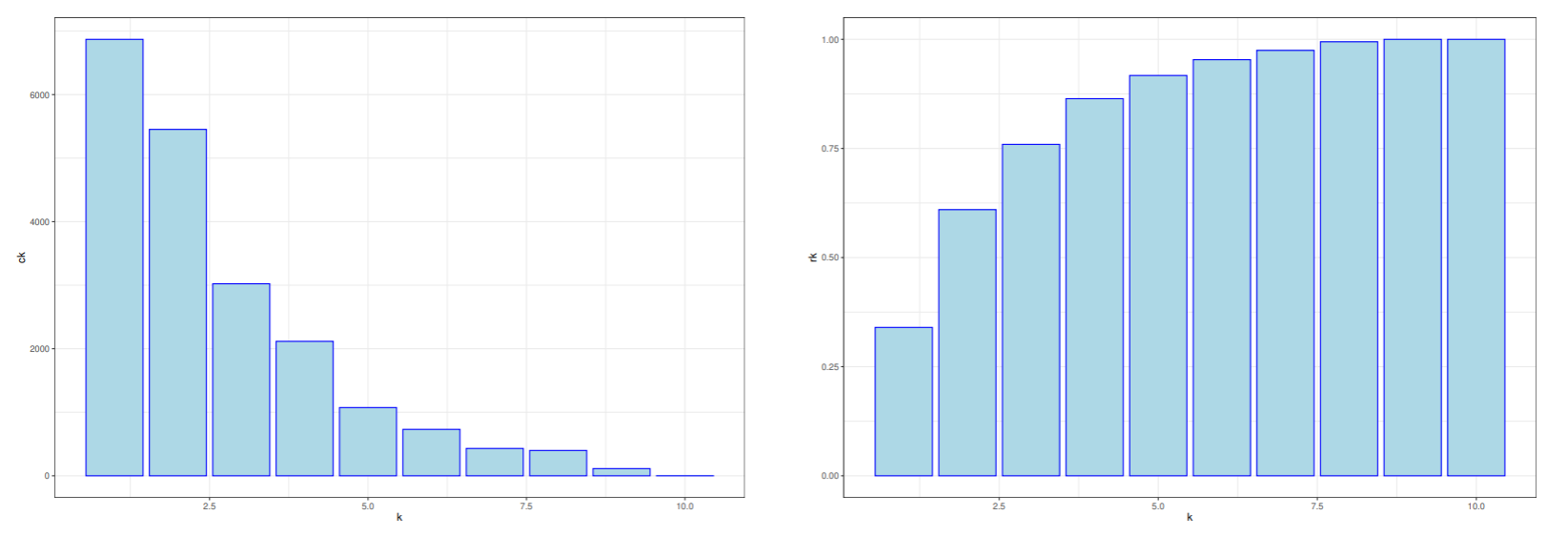
Vtotal=i=1∑dλi
第 k 主成分の全分散に対する割合 (cj=λk/Vtotal) を第 k 主成分の寄与率といい, 第 k 主成分までの累積寄与率は rk=∑i=1kck で表す.
画像データの主成分分析
10枚の画像の主成分分析を行う. 中心化を行うため, xi が一次独立でなくなるため, 最大ランクが9になる. 主成分も9個. 第1主成分から第9主成分までの固有ベクトルを下の図に示した.

寄与率と累積寄与率をプロットした.
特異値分解
行列を複数の行列の積に分析する方法として, グラム-シュミットの正規直交基底を得るためのQR分解がある. 一方, 主成分分析に密接に関連した行列の分解法に, 特異値分解(SVD)がある.
特異値分解とは, 任意の n×p 行列 X を
X=UΛVT=(u1,⋯,up)⎝⎜⎜⎜⎜⎛λ10⋮00λ2⋮0⋯⋯⋱⋯00⋮λp⎠⎟⎟⎟⎟⎞⎝⎜⎜⎜⎜⎛v1Tv2T⋮vpT⎠⎟⎟⎟⎟⎞
のように分解することができる.
- U は XXT の非ゼロ固有値に対応する固有ベクトルで, n×p の正規直交行列.
- V は XTX の非ゼロ固有値に対応する固有ベクトルで, p×p の正規直交行列.
- Λ は, XXT または, XTX の非ゼロ固有値の平方根(特異値)である.
特異値分解と主成分分析の関係は X=UΛVT から XV=UΛ が成り立つので
(Xv1 Xv2 ⋯ Xvp)=(λ1u1 λ2u2 ⋯ λpup)
データ行列 X を v1 で線形変換したベクトルが λ1u1 になるので,
分散をとれば
Var(Xv1)=λ1
となるので, Xvj が第1主成分になっている.
第1主成分から第 q 主成分までの vi で構成された部分空間 V~ と射影 XV~ を考えると,
V~=(v1 ⋯ vq)
共分散行列が Var(XV~)=Λq2 となるから, 行列分解 X~=UΛqVT=∑i=1qλiuiviT はランク q の誤差最小の意味での最良近似になっている.
部分空間法
部分空間法とは, クラスごとに部分空間を構成する正規直交基底を求め, 入力データを各クラスの部分空間に射影して識別する手法のこと.
クラスごとに独立に部分空間を構成できるから, 多クラスの識別器が容易に構成できる.
部分空間法には, 相関行列を使う方法と共分散行列を使う方法があり, 相関行列を使う方法にはCLAFIC法がある.
CLAFIC法
データ x∈Rd は K 個のクラスのどれかに属しているとする. クラスごとの部分空間を S1,⋯,SK とし, クラス i の部分空間を張る基底ベクトルを次のように表す.
{ui1,⋯,uidi}
部分空間 Si へ正射影した長さの期待値を uij=1 の制約の下で最大にするようにする.
E{xTPix ∣ x∈Ci}=E{xT(j=1∑diuijuijT)x}
行列 Pi は射影行列という.
識別規則は全ての j=i について, xTPjx<xTPix ならば x∈Ci
手書き数字の部分空間法による認識
28×28 の数字画像のベクトルの長さを1にそろえた各クラス1000個の学習データを用いる. クラスごとの部分空間の次元数 di(i=1,⋯,10) は忠実度 κ が0.75となる次元を採用した.
a(di−1)≤κ≤a(di),a(di)=j=1∑diλij
学習データの誤識別率は 4.98%, テストデータの誤識別率は 8.89%であった. 次のようになった.
カーネル主成分分析
カーネル法を用いて非線形特徴空間で主成分分析を考える. xi∈Rd(i=1,⋯,N) を学習データ, 非線形特徴変換を φ(Xi):xi∈Rd→φ(xi)∈RM(M>d) とする.
∑i=1Nφ(xi)=0 なら, M×M 分散共分散行列
C=N1i=1∑Nφ(xi)φ(xi)T
の固有値問題 Cνm=λmνm を解いて, 主成分 λm と固有ベクトル νm を得ることができる.
非線形変換の平均を0にするためには, 次のようにする.
φ~(xi)=φ(xi)−N1j=1∑Nφ(xj)
平均を0にしたグラム行列 K~ のは, 全要素が N1 とする N×N 行列を1NNとすれば
K~=K−1NNK−K1NN+1NNK1NN
と計算すれば平均を0にすることができる.
元のデータの次元 d での計算は次のように考えれば良い. 非線形変換の学習データを次のようにする.
Xφ~=(φ~(x1),⋯,φ~(xN))∈RM×N
Xφ~ の共分散行列 C~=N1Xφ~Xφ~T∈RM×M なので, Xφ~Xφ~T の固有値を λ1≥⋯≥λN とし,Λ は r 個の固有値の平方根を対角要素に並べた行列とすると, Xφ~=UΛVT と分解できる.
U=Xφ~VΛ−1 より
ui=λi1Xφ~vi
が成り立つので, 入力ベクトル Xφ~ の ui 方向への射影は
uiφ~(x)=(λi1Xφ~vi)Tφ~(x)=λi1viK~(X,x)
となるので, d 次元空間での内積カーネルの計算と r 回の N 次元ベクトルの内積計算で求めることができる.
カーネル部分空間法
CLAFIC 法の内積カーネルを使った非線形特徴空間内の部分空間法を考える.
クラス i の学習データを Xi=(xi1,⋯,xiNi) とし, その非線形特徴写像による変換を Xiφ=(φ(xi1),⋯,φ(xiNi)) とする.
Xiφ の特異値分解を Xiφ=UiΛiViT とする. クラス忠実度を満たす di 個の固有値を λi1,⋯,λidi とすれば, di 次元の比線型部分空間を構成できる.
φ(X) を U^i に射影したときのベクトルの長さは, 次のようになる.
li2(x)=j=1∑di(uijTφ(x))2=∥Λi^−1V^TK(X,x)∥2
識別規則は 識別クラス = argmaxili2(x),i=1,⋯,K である
クラスタリング(Cluster analysis)
前章までの学習データには, 入力データの教師ラベルが付与されていた.
本章では教師なしデータに対しては, 類似度や非類似度を手がかりに, データのグループ分けを行う. このような, 教師なしデータのグループ分けをクラスタリング(Cluster analysis)という
クラスタリングには, 非階層的な手法と階層的な手法がある. いずれもデータやクラスタ間の距離や類似度に基づく方法で, 各データはどれか一つのクラスタのみに属する.
一方, データが確率分布に従い, 全体をそれらの混合分布で表現するクラスタリングがある. 異なるクラスのデータが混在したことを確率分布の混合分布で表す場合もある. 混合分布モデルの推定には, EMアルゴリズムという画期的な手法を使う.
教師なし学習の応用例:
- 遺伝子表現データから乳がん患者のグループ分け
- ユーザのウェブページの閲覧履歴と購入履歴からグループ分け
- 映画視聴者のレーティングによる映画のグループ分け
- コメントや感想からその人の感情を自動的に評価する取り組み
- 計算機実験などから得られるラベルなしデータは, 人手が介入する必要があるラベルありデータに比べて入手しやすい
類似度と非類似度
距離の公理
クラスタリングでは, データやクラス間の類似度あるいは非類似度を使って, 似たようなデータを集めてクラスタを作る.
データやクラスタ間の類似度を測るに距離を導入する. 2つのベクトル x と y の距離 d(x,y) を定義するためには, 距離の公理を満たさないといけない.
距離の公理
- 非負性: d(x,y)≥0
- 反射率: d(x,y)=0 となるのは, x=y のときのみ
- 対称性: d(x,y)=d(y,x)
- 三角不等式: d(x,z)≤d(x,y)+d(y,z)
ミンコフスキー距離(Minkowski distance)
N 個の d 次元データの i 番目のデータを xi=(xi1,⋯,xid)T とする. 2つのベクトル xi と xj のミンコフスキー距離は,
d(xi,xj)=(∑k=1d∣xik−xjk∣a)1/b
で定義する. a は特徴間の差の重みを調整するパラメータで, b は特徴間の差の a 乗の重みを調整するパラメータ.
a=b=1 のときは市街地距離(マンハッタン距離)で, 四角いマス目状の道路で移動する距離
d(xi,xj)=k=1∑d∣xik−xjk∣
a=b=2 の場合はユークリッド距離
d(xi,xj)=(∑k=1d∣xik−xjk∣2)1/2
a=2,b=1 の場合, ユークリッド距離の2乗
d(xi,xj)=k=1∑d∣xik−xjk∣2
a=b=∞ の場合, チェビシェフ距離
d(xi,xj)=(∑k=1d∣xik−xjk∣a)1/aa→∞lim=kmax∣xik−xjk∣
データ間の類似度を測るその他の代表的な尺度には, 次のものがある
キャンベラ尺度: データの正規化する仕組みを入れた尺度
d(xi,xj)=k=1∑d∣xik∣+∣xjk∣∣∣xik−xjk∣
方向余弦ベクトル間の角度を用いた距離
d(xi,xj)=(∑k=1dxik2)(∑k=1dxjk2)∑k=1dxikxjk
非階層型クラスタリング(K-平均法)
k-平均聚类的目的是:把n个点(可以是样本的一次观察或一个实例)划分到k个聚类中,使得每个点都属于离他最近的均值(此即聚类中心)对应的聚类,以之作为聚类的标准
这个问题在计算上是NP困难的,不过存在高效的启发式算法。一般情况下,都使用效率比较高的启发式算法,它们能够快速收敛于一个局部最优解。这些算法通常类似于通过迭代优化方法处理高斯混合分布的最大期望算法(EM算法)
d 次元データ D={x1,⋯,xN} をあらかじめ定めた K 個のクラスタに割り当てる手法.
各クラスの代表ベクトルの集合を M={μ1,⋯,μK} とし, 代表ベクトルが支配する領域を M(μk) とする. i 番目のデータがクラス k に帰属するかどうかを表す変数を qik とする.
qik={1,xi∈M(uk)0,xi∈/M(uk)
K 平均法の評価関数を次のように定義する. 各クラスの代表ベクトルはそのクラスの平均ベクトルになる.
J(qik,μk)=i=1∑Nj=1∑Kqik∥xi−μk∥2
アルゴリズムK-平均法
初期化: N 個のデータをランダムに K 個のクラスタに分け, そのクラスタの平均ベクトルを求める.
- qik に関する最適化: μk を固定したもとで, qik を次のように求める.
qik={1,k=argminj∥xi−μj∥20,k=argminj∥xi−μj∥2
- μk の最適化: qik を固定し, セントロイド μk を求める
- 繰り返し: クラスタが変化しなくなるまで (1), (2) を繰り返す
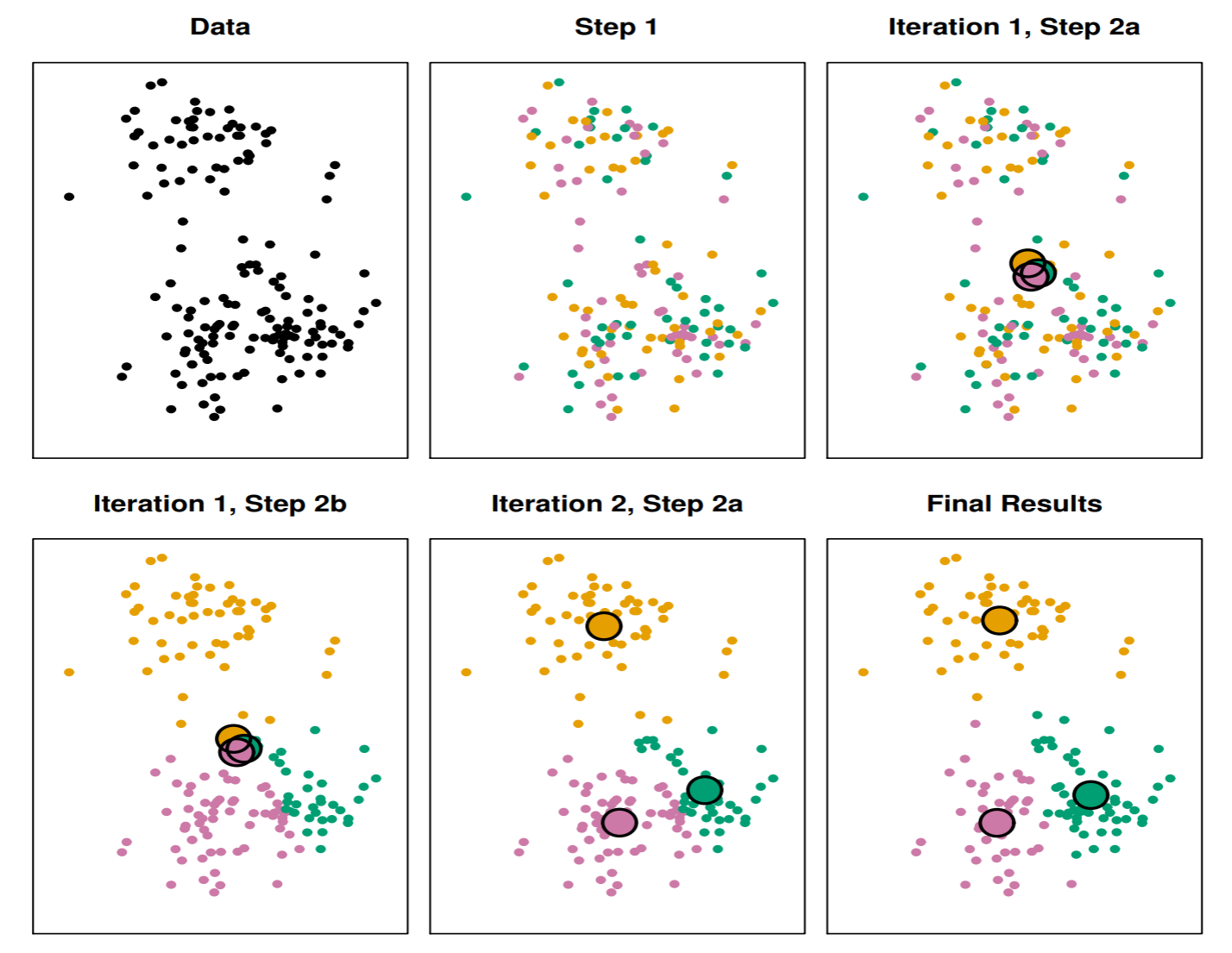
K 平均法のアルゴリズムは初期値に依存するので, 最適解を得るためには何回か初期値を変えて実行する必要がある.
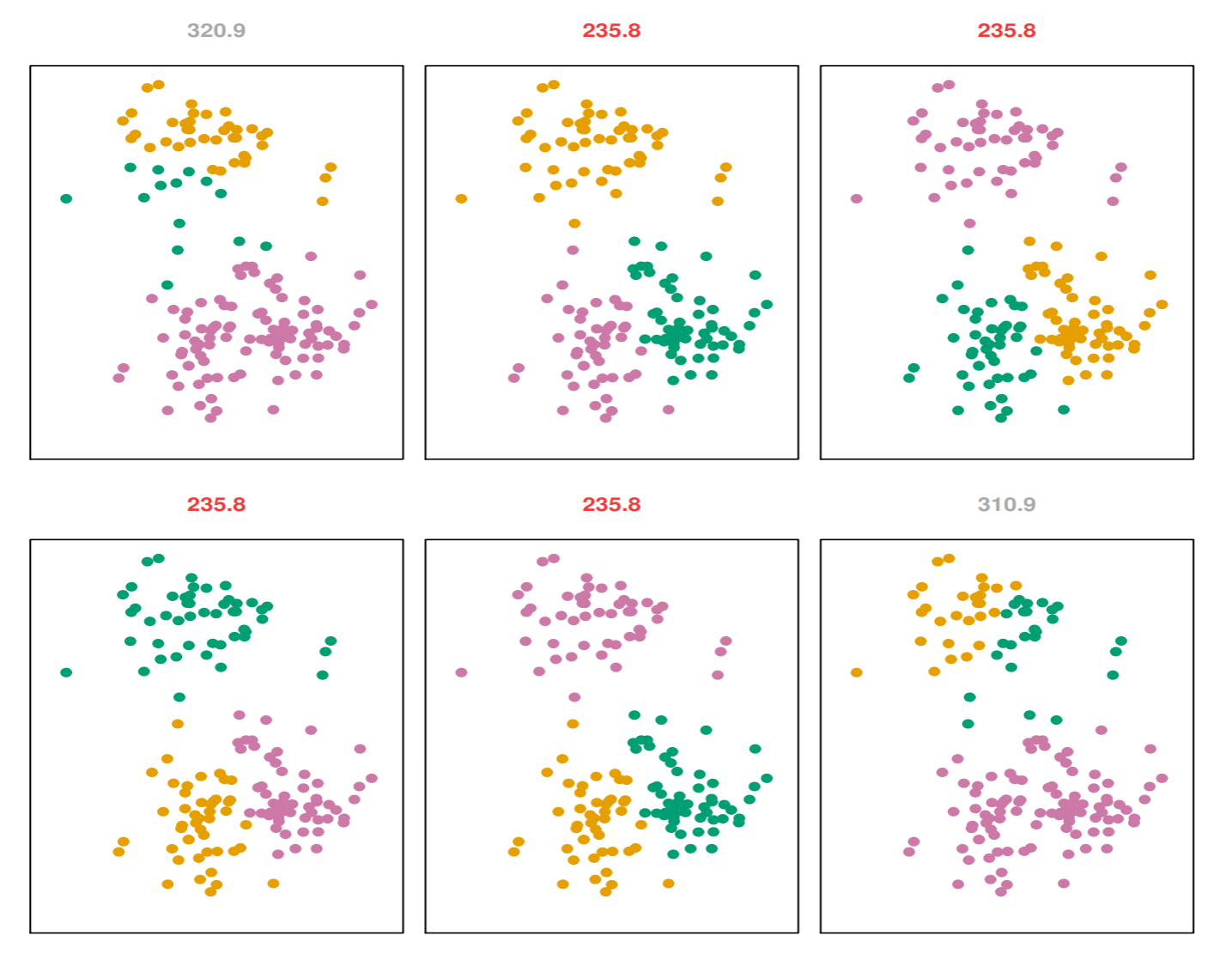
この図は初期値を変えながら6回K平均法を実行した時の結果である. 図の上にある数字は評価関数値で, 小さい値の方が良くクラス分けができていることを示している. 6回中3回は同じ結果で評価関数値が235.8となり, この結果を採用する.
階層型クラスタリング(融合法)
K 平均法では, 事前に決定したクラスタ数 K に応じた分割を行った. 階層的クラスタリングでは, クラスタ数は決定する必要はない.
階層的クラスタリングのボトムアップ法, 融合法を説明する. 葉を結合して幹にする. この図を樹状図, デンドログラムという.
アルゴリズム融合法
- n=N とする
- n×n の距離行列を作る
- 最も距離が近い二つのデータやクラスタをまとめて, 一つのクラスタにする
- n=n−1 にする
- n>1 であれば, (2) へ, n=1 であれば終了する
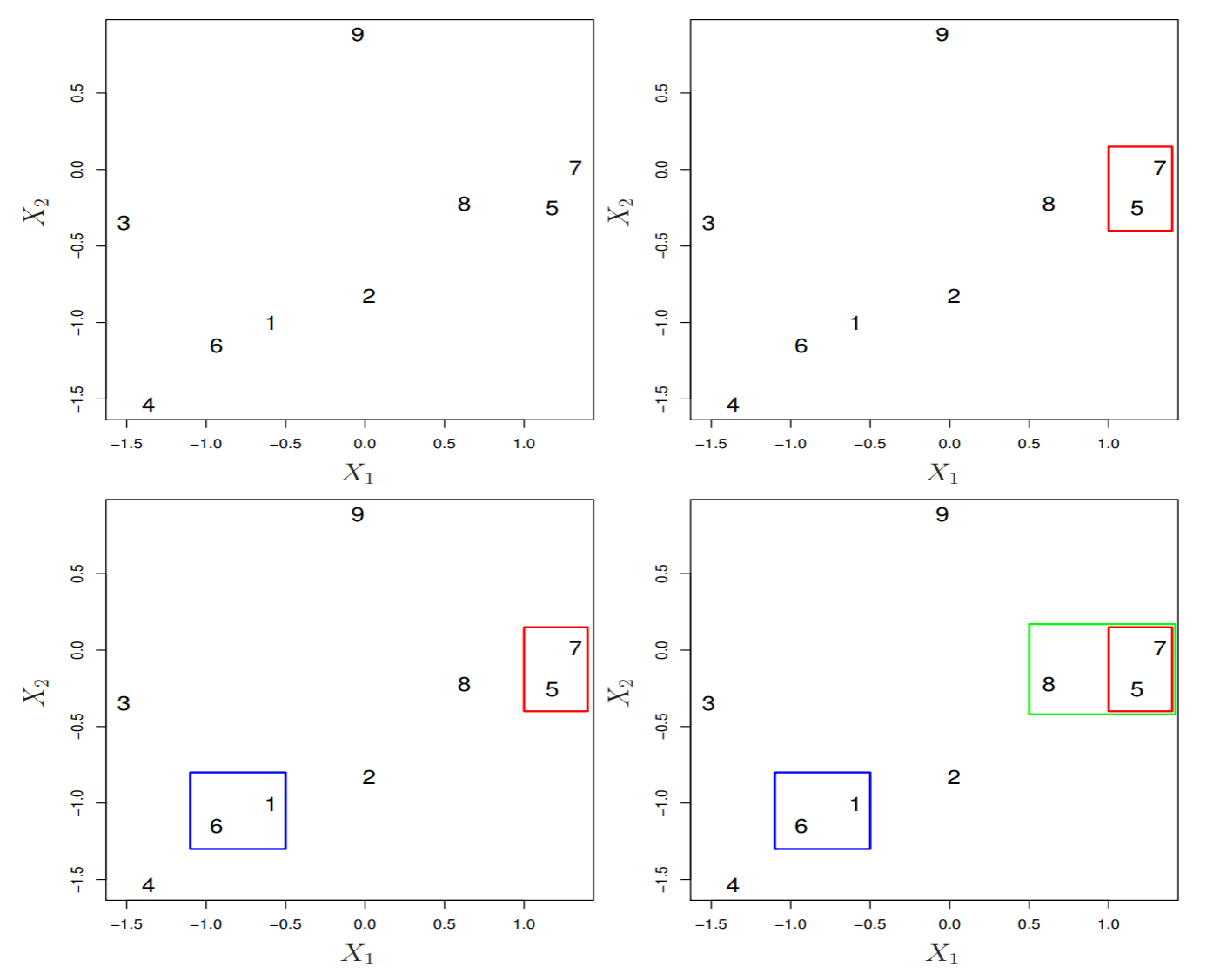
この5と7が結合された距離を記録し, デンドログラムの縦軸に高さで示す.
データの連結方法
完全連結法(最長距離法): クラスター内の非類似性が最大になるような方法. クラスタ A と B の観測値の非類似性を全てのペアで計算し非類似性が最大になるものを記録していく.
単連結法(最短距離法): クラスタ内の非類似性が最小になるような方法. クラスタ A と B の観測値の非類似性を全てのペアで計算し非類似性が最小になるものを記録していく.
群平均法: クラスタ内の非類似性の平均で距離を計算する方法. クラスタ A と B の観測値の非類似性を全てのペアで計算し非類似性の平均を記録していく.
重心法: クラスタ内の非類似性の重心で距離を計算する方法. クラスタ A と B の観測値の非類似性を全てのペアで計算し非類似性の平均を記録していく.
ウォード法: クラスタ A と B を融合したときに, クラスタ内変動の増分が小さくなるようにクラスタを融合する方法.
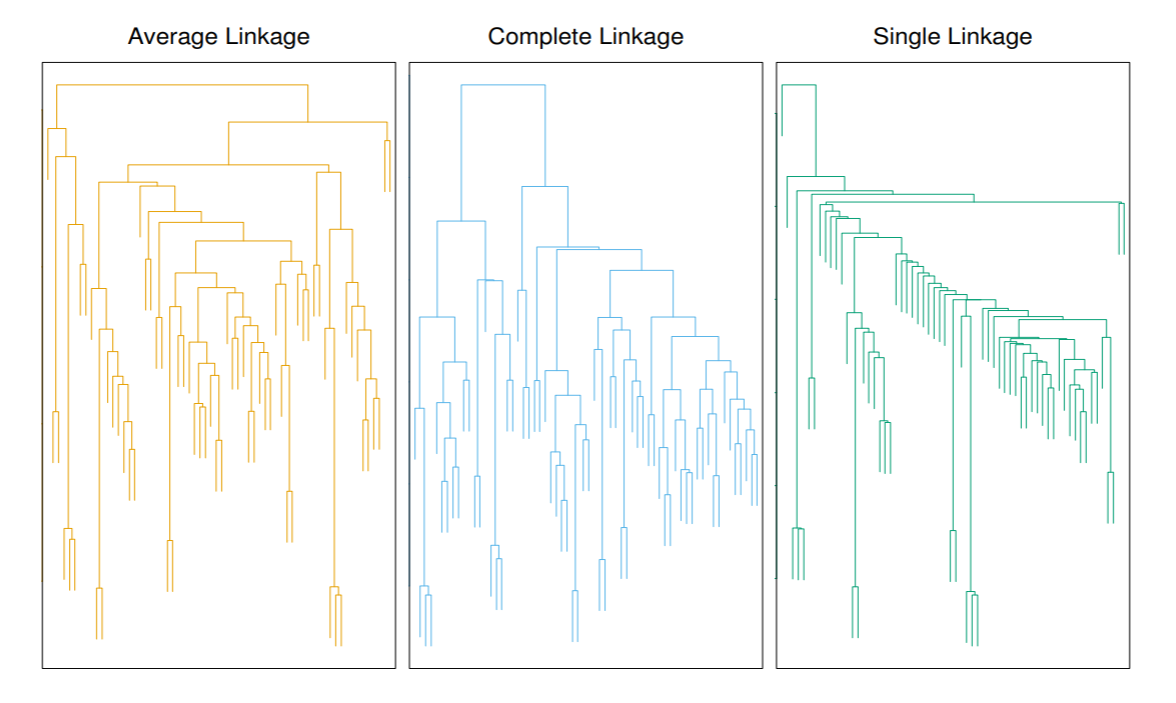
左から右にかけて, 群平均法, 完全連結法, 単連結法である.
単連結法では, 連結されたクラスタが新たなデータを取り込んでクラスタを形成するため, クラスタ形成の様子が鎖効果となって表れるため, 距離によってクラスを分割する時に, 特徴のあるデータのまとまりとしてクラスを形成することが困難になることがある.
階層的クラスタリングの分析例
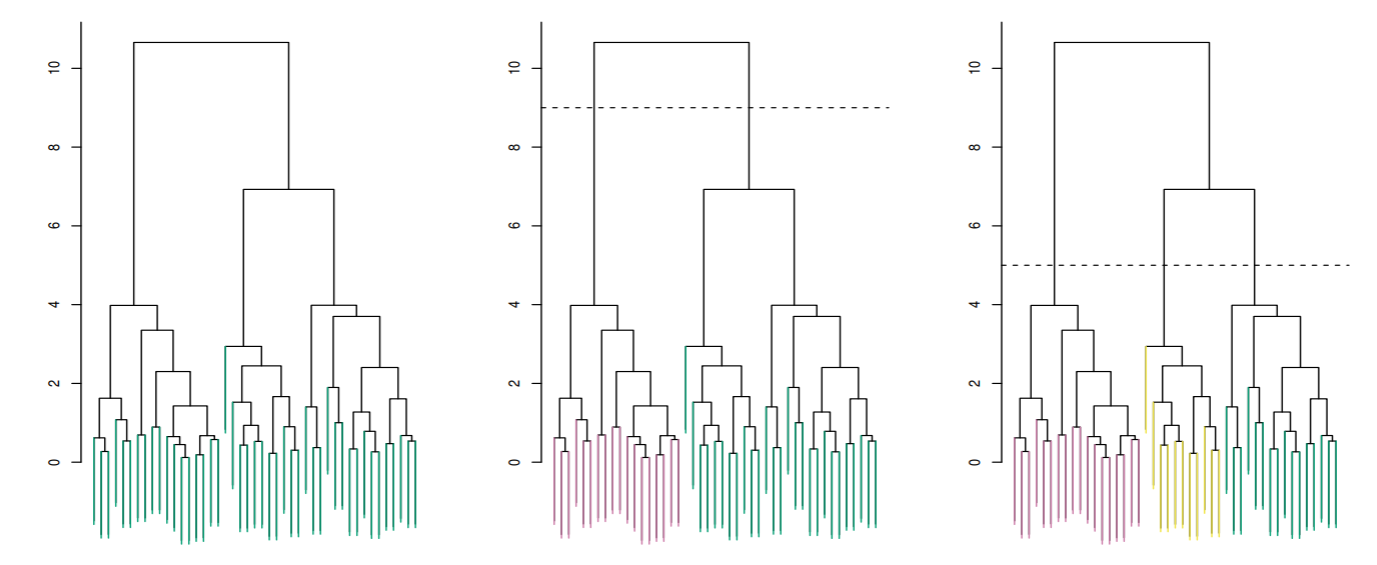
左: 階層的クラスタリングのデンドログラム: ユークリッド距離と完全連結法(complete linkage).
中: 左のデンドロクラムをクラスタ数が2になるように分類した結果. 点線は距離9を指している.
右: のデンドロクラムをクラスタ数が3になるように分類した結果. 点線は距離5を指している.
確率モデルによるクラスタリング
K-平均法や融合法によるクラスタリングでは, 一つのデータは一つのクラスタにのみ分類されるので, ハードクラスタリングとも呼ばれる. 階層的クラスタリングやK平均法では, データに基づいた簡便法なので確率モデルの推論ができない.
主にクラスタリングが, 探索的データ解析に用いられるなら問題ではない.
確率的クラスタリングやモデルに基づいたクラスタリングは, 確率的にデータをグルーピングする手法. データ構造を解釈しやすい.
混合分布モデル
有限な潜在クラスの異質性を扱うモデル. 有限混合分布モデルは, 潜在クラスモデル, 教師なし学習モデルと考えて良い. 有限混合分布モデルは, 分類問題, クラスタリング, 分類学に応用される.
クラスが異なるから効果(応答)も異なると考える.
- 異なるブドウ品種のワインの特性
- 健康な人か病気の人
- 株式市場, “bull”, "bear"マーケット
K-コンポーネントの確率分布 f1,f2,⋯,fK の混合モデルを次のように定義する.
f(x)=k=1∑Kλkfk(x)
ここで λk を混合比率といい, λk>0,∑kλk=1 を満たす.
データの生成は次のように考える.
Z∼Mult(λ1,⋯,λk)X∣Z∼fZ
確率分布 f は任意の分布を考えても良いが, 正規分布がよく用いられる.
k-コンポーネントのパラメータベクトルを θk とすると
f(x)=k=1∑Kλkfk(x;θk)
となり, 混合分布モデルのすべてのパラメータベクトルは, θ=(λ1,⋯,λk,θ1T,⋯,θKT)T となる.
識別可能性
各コンポーネントのパラメータベクトル θ の次元を d とする (θ∈Rd).
このとき混合分布モデルのパラメータの次元は, θ∈RD,D=dK+K であるが, 実際は, ∑i=1Kλi=1 の制約から, ラムダの自由度が1つ減るため, D=dK+K−1 になる.
確率モデルがパラメータ θ に対して一意に定まることを識別可能という.
θ1=θ2⇔f(x;θ1)=f(x;θ2)
例えば, ラベルスイッチングがあり, K=2.λ1=0.3,λ2=0.7,θ1=(μ1,σ1)T,θ2=(μ2,σ2)T と λ1=0.7,λ2=0.3,θ1=(μ2,σ2)T,θ2=(μ1,σ1)T 混合比率と確率モデルを入れ替えて表現した確率モデルが同じモデルになるため, 識別可能ではない。
黒線: N(0,12), 赤線: N(5,22)
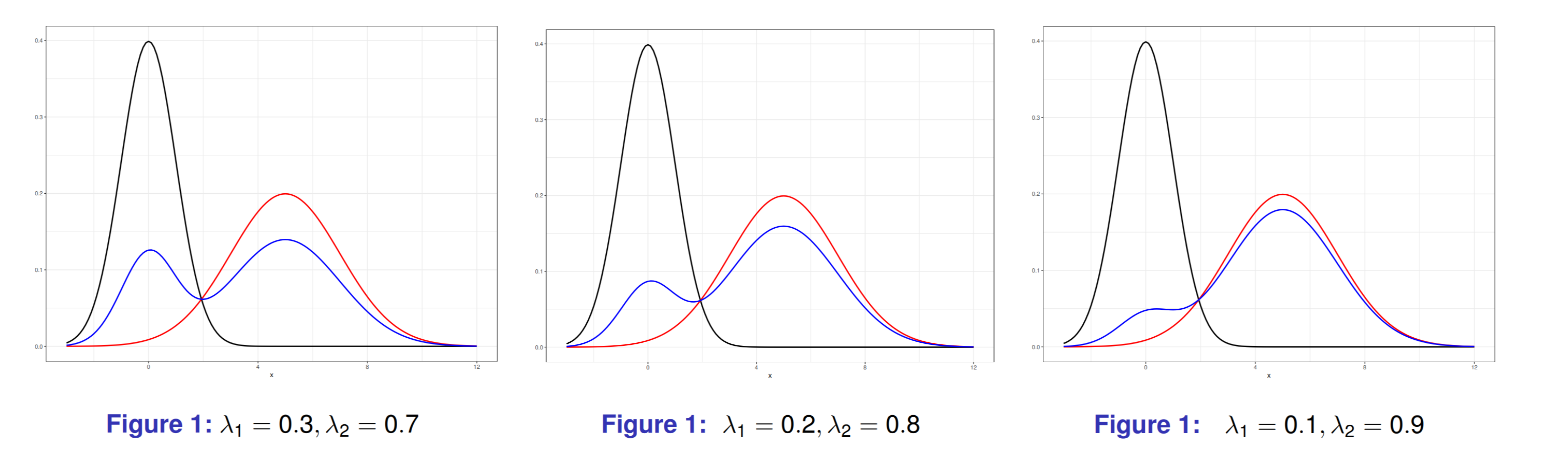
混合比率 λ を変えることで, 様々な形状の2峰分布を得ることができる. 図はそれぞれ第1コンポーネントの割合を0.3, 0.2, 0.1とした場合.
第1コンポーネントの割合を0.1とした場合は, このような2峰性ではなく, 非対称性を表している.
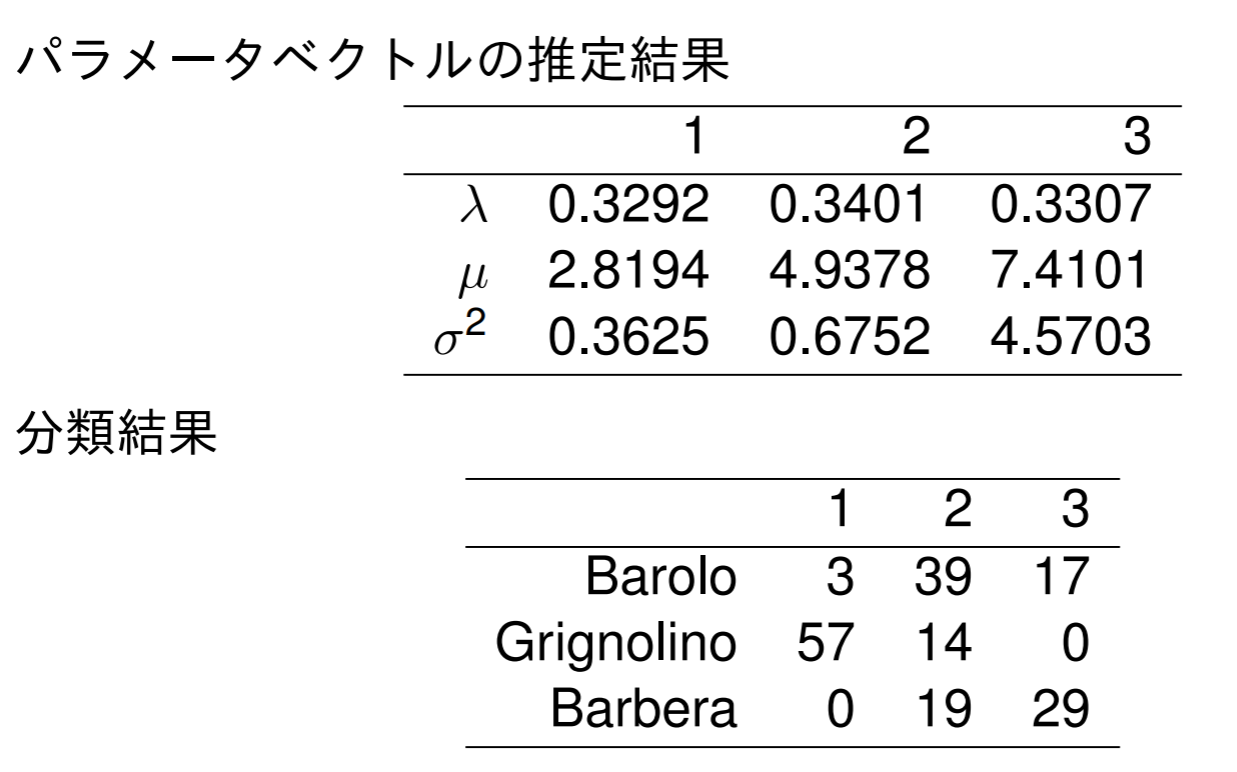
色彩強度の混合モデルによる推定
ワインデータは3個のクラスで構成されたデータ. 色彩強度(color intensity)のみを特徴量とした.
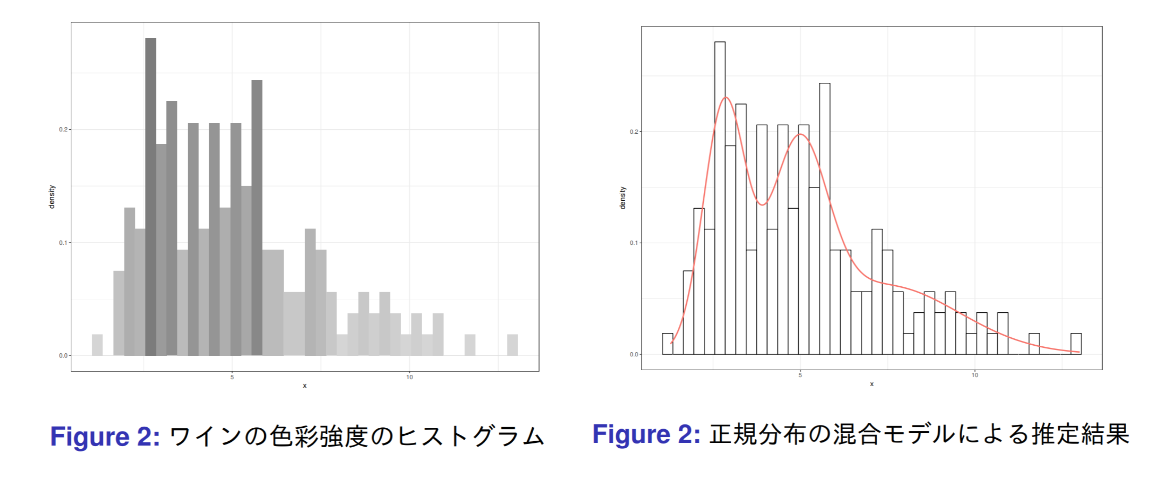
色彩強度の分布を三つの正規分布の混合モデルで表現できたことが分かった.
完全データの対数尤度
観測値のベクトルを X=(X1,⋯,Xn) とし, 潜在変数のベクトルを Z=(Z1,⋯,Zn) とする.
h(x,z∣θ) を Z と Z の同時密度とし, k(z∣θ,x) を観測値が与えられたときの潜在変数の条件付き密度とする. g(x) を X の同時密度とすれば, 条件付き密度関数の定義から k(z∣θ,x) は次のように与えられる.
k(z∣θ,x)=g(x)h(x,z∣θ)
観測値に基づく尤度関数を L(θ∣x)=g(x∣θ) とし, 完全尤度を次のように定義する.
Lc(θ∣x,z)=h(x,z∣θ)
完全尤度の情報を使って, 尤度関数を最大化するパラメータ θ を求めたい
EMアルゴリズム(Expectation-Maximum)
θ0∈Ω に対して,
logL(θ∣x)=Eθ0[logLc(θ∣x,Z)∣θ0,x]−Eθ0[logk(Z∣θ,x)∣θ0,x]
最後の期待値は条件付き密度 k(z∣θ0,x)dz の下で計算している.
上式の第1項を
Q(θ∣θ0,x)=Eθ0[logLc(θ∣x,Z)∣θ0,x]
と定義すれば, これはEMアルゴリズムにおけるE-ステップに相当する.
問題は, 尤度 L(θ∣x) の最大化だった. このことは, E-ステップを最大化することで到達可能. これをEMアルゴリズムにおけるM-ステップという.
初期値ベクトル θ(0) から始めて, Q(θ∣θ(0),x) を最大にする θ を θ^(1) とし, 収束するまで繰り返すアルゴリズムをEMアルゴリズムという.
EMアルゴリズム: m 番目の推定値を θ^(m) とする. (m+1) 番目の推定値は次のようにして計算する.
Eステップ: 次を計算する.
Q(θ∣θ^(m),x)=Eθ^(m)[logLc(θ∣x,Z)∣θ^(m),x]
Mステップ:
θ^(m+1)=argmaxQ(θ∣θ^(m),x)
次の定理は, ステップを繰り返すことに尤度は必ず増加することを述べたもの.
EMアルゴリズムによって得られる推定値の系列 θ^(m) は必ず L(θ^(m+1)∣x)≥L(θ^(m)∣x) を満たす
2コンポーネントの正規混合モデルの推定
確率変数 Y1 は N(μ1,σ12) に従い, Y2 は N(μ2,σ22) に従うとする. Z は Y1,Y2 と独立はベルヌーイ試行を表す確率変数とし, その成功確率を π=P(Z=1) とする. 観測値は, 2コンポーネントの混合正規分布モデルで X=(1−Z)Y1+ZY2 とする.
推定すべきパラメータベクトルは θ=(μ1,μ2,σ12,σ22,π) である.
標準正規分布の密度関数を ϕ(z) とすると, X の密度関数は次のとおり
f(x)=(1−π)f1(x)+πf2(x),fj=σj1ϕ(σjx−μj)
標本データ X=(X1,⋯,Xn) を得たき対数尤度関数は次のとおり
l(θ∣x)=i=1∑nlog[(1−π)f1(xi)+πf2(xi)]
i 番目の観測値に対応する潜在変数を次のように定義する.
Zi={0,Xiが密度関数f1(x)を持つ時1,Xiが密度関数f2(x)を持つ時
完全尤度は次のようになる.
Lc(θ∣x,z)=Zi=0∏f1(xi)Zi=1∏f2(xi)
これより, 対数完全尤度関数は次のとおり
lc(θ∣x,z)=Zi=0∑logf1(xi)+Zi=1∑logf2(xi)=i=1∑n[(1−zi)logf1(x1)+zilogf2(xi)]
Eステップでは, θ(0) の下で, x を与えたときに, Zi の条件付き期待値を計算しないといけない.
Eθ0[Zi∣θ(0),x]=P(Zi=1∣θ(0),x)
この期待値の推定量には次のものを用いる.
γi=(1−π^)f1(xi∣θ(0))+π^f2(xi∣θ(0))π^f2(xi∣θ(0))
zi の代わりに γi を使えば, Mステップの目的関数は次のようになる.
Q(θ∣θ(0),x)=i=1∑n[(1−γi)logf1(xi)+γilogf2(xi)]
この最大化は, μ1 に関して偏微分係数を計算し, それが0となる μ1 について解けば陽に解が得られる.
∂μ1∂Q=i=1∑n(1−γi)(−2σ121)(−2)(xi−μ1)
これより, Mステップで得られる解は,
μ1^=∑i=1n(1−γi)∑i=1n(1−γi)xi,μ2^=∑i=1nγi∑i=1nγixi
σ12^=∑i=1n(1−γi)∑i=1n(1−γi)(xi−μ1^)2,σ22^=∑i=1nγi∑i=1nγi(xi−μ2^)2
γi は P(Zi=1∣θ(0),x) の推定値なので, その平均 π^=n−1∑i=1nγi は π=P(Zi=1) の推定値である.
識別器の組み合わせによる性能評価
最近, 複数の識別器を組み合わせる方法が提案されていて, 本章では, 決定木を組み合わせた方法を紹介する.
組み合わせ方法には, 学習データのブートストラップを用いて複数の識別器を構成し, それらの多数決で識別するバギングという手法がある. もう一つは, 誤った学習データを次の識別器で重点的に学習させ, これを逐次行うアダブーストという手法を紹介する.
ランダムフォレストは決定木のノードをランダムに選択する手法でバギングを改良する.
ノーフリーランチ定理
ノーフリーランチ定理: すべての識別問題に対して, ほかの識別機より識別性能が良い識別器は存在しない
決定木
階層(stratifying)や区分(segment)を使って特徴ベクトルの空間を簡単な領域に分割する. 領域に分割する法則が木構造になるので, 決定木(desicion-tree)による方法という.
木を構成する要素はノードとノードを結ぶリンク. 木の一番上にあるノードを, 木の始まりという意味で根ノードという. 終端ノードあるいは葉ノードは, 分岐の最終ノードのこと.
学習方法は, ボトムアップ的な手法とトップダウン的な手法がある.
決定木と線形モデル
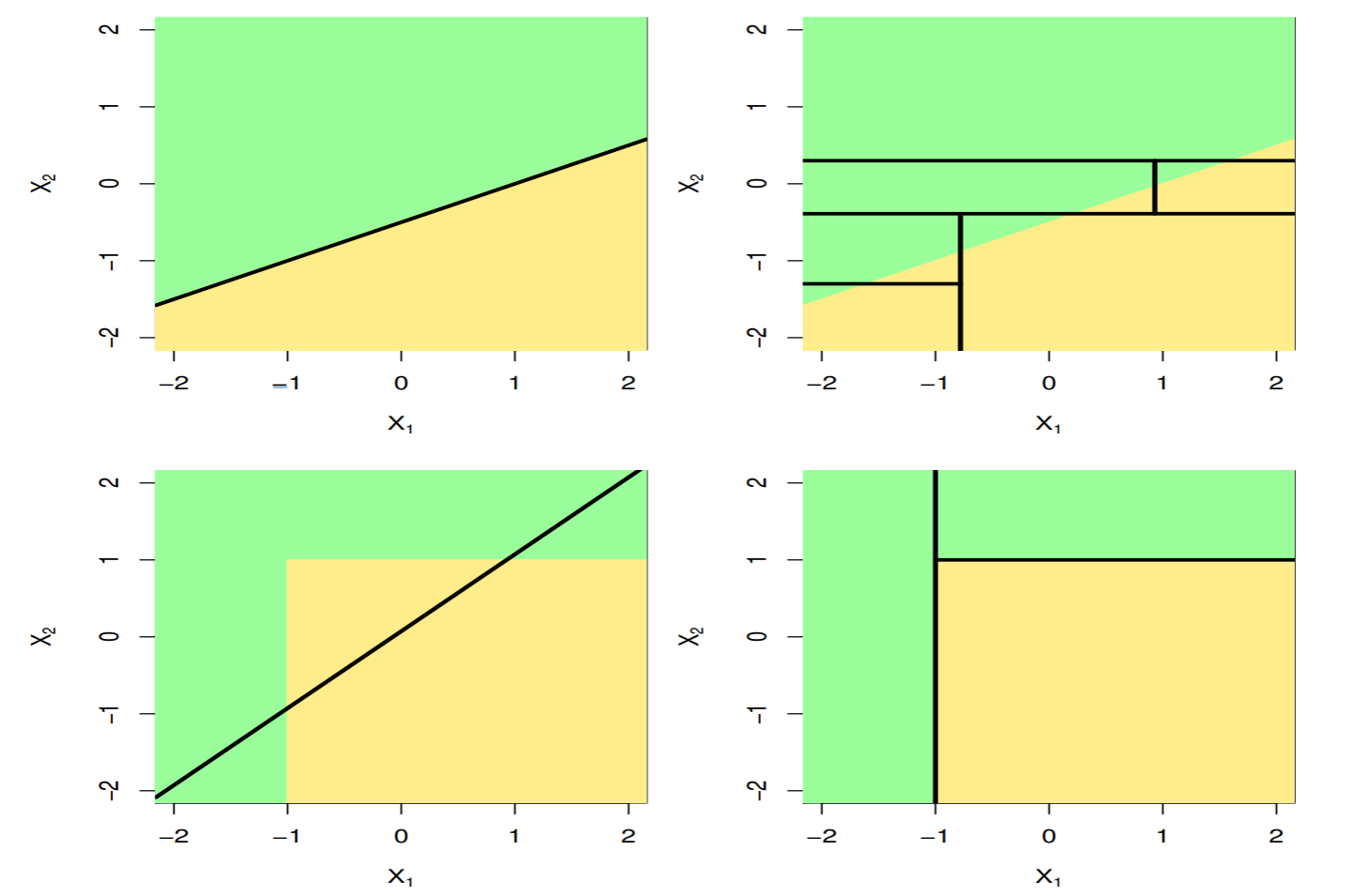
心臓病データ
胸痛(chest pain)を訴える303患者のHDの2値データ. Yesは血管造影(angiographic)テストによる心臓疾患の持ち主で, Noは心臓疾患ではない患者. 心臓や肺機能に関するデータや, Age, Sex, Chol 等の13個の予測子がある. 交差確認法より6個の最終節を持つ木が選択された.
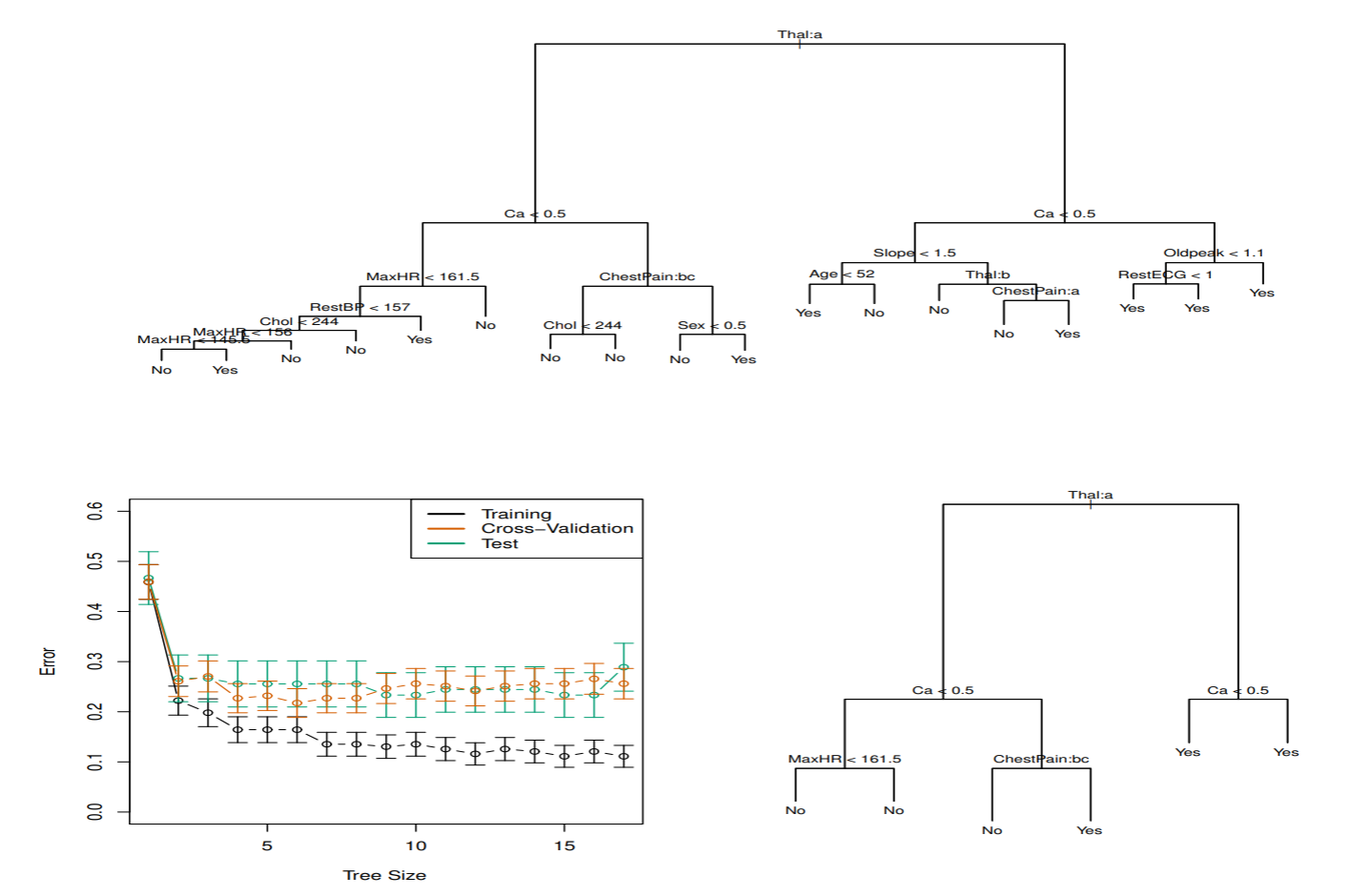
トップダウン的な手法
トップダウン的な手法は, まず根ノードですべての学習データをできるだけ誤りの少ないようにクラス分けできる特徴軸を探して特徴空間を 2分割する規則を求める. さらに分割された空間を2分割する規則を求めることを繰り返す手法. 分割統治法と呼ばれる.
トップダウン的な手法で決定木を学習データから構成するためには, 次の要素について考える必要がある.
- トップダウン法に必要な要素
- 各ノードにおいて特徴空間分割規則構成するための特徴軸としきい値の選択
- 終端ノードの決定. 大きくなった木の剪定をどこまで行うか?
- 終端ノードに対する多数決によるクラスの割当
決定木の学習方法には, CART, ID3, C4.5と呼ばれるものがある. ここではCARTを中心に説明する.
決定木に関する諸定義
木は, 0でない有限個の正の整数からなる有限の集合 T と, t∈T から T∪{0} への2つの関数left() と right() で構成される. lerft() と right() は左側, 右側の次ノード番号を与える関数.
木が満たす性質:
- 各 t∈T について, left(t) = right(t) = 0 (最終ノード) か, left(t) > t かつ right(t) > t(非最終ノード) のいずれかが成り立つ.
- 各 t∈T について, T 内の最小数 (根ノード) を除いて, t = left(s) または t = right(s) のどちらかを満たすただ一つの s∈T が存在する. s を親ノード, t を子ノードといい, s = parent(t) で表す.
ノード分割規則
各ノードにおける d 次元特徴空間の最適な分割は, 特徴軸ごとに可能な考えうる分割を不純度とよばれる評価関数で評価して選択する.
ノード t の不純度を
I=ϕ(P(C1 ∣ t),⋯,P(Ck ∣ t))
で定義する. ここで関数 ϕ(z1,⋯,zK) は, zi≥0,∑i=1Kzi=1 で, 次の3つを満たす.
- ϕ() はすべての i=1,⋯,K に対して, zi=1/K のときに最大になる.
- ϕ() は, ある i について zi=1 となり, j=i のときはすべて zj=0, ただ一つのクラスに定まるとき最小になる.
- ϕ() は z1,⋯,zK に関して対称な関数である.
ノード t における誤り率
I(t)=1=tmaxP(Ci ∣ t)
交差エントロピーまたは逸脱度
I(t)=−i=1∑KP(Ci ∣ t)lnP(Ci ∣ t)
ジニ係数
I(t)=1−i=1∑KP2(Ci ∣ t)=i=1∑KP(Ci ∣ t)(1−P(Ci ∣ t))
ノード t で分割を作るとき, 不純度の減り方が一番大きな分割を選べば良い
木の剪定
不純度が最小, あるいは十分小さくなるまで木を成長させ, 次に誤り率と木の複雑さできまる許容範囲まで木を剪定する.
終端ノード t∈T~ における誤り数 M(t) は終端ノードに属する学習データのうち事後確率を最大にしない学習データ数なので, このノードの誤り率は R(t)=NM(t) である. N は総学習データ数.
木全体での誤り率は次のようになる
R(T)=t∈T~∑R(t)
木の複雑さを終端ノードの数で評価する: 木 T のノード数を ∣T∣ とすると, 終端ノード数は ∣T~∣ となる.
複雑さのコストを α とすれば, 一つの終端ノードにおける誤り率と複雑さのコストの和で木全体のコストを評価できる.
Rα(T)=t∈T~∑Rα(t)=R(T)+α∣T~∣
木のコスト Rα(T) を最小にすれば良い.
バギング(bagging)
Bagging:用的是随机有放回的选择训练数据然后构造分类器,最后组合
バギングは, 学習データのブートストラップサンプルを用いて複数の学習器を学習させ, それらの識別器の多数決で入力データのクラスを予測する.
個々の識別器の性能はランダム識別器よりも少し良ければいいので, 弱識別器と呼ばれる.
複数の決定木から多数決をとることで, 決定木よりも安定した精度の良い識別器が構成できる.
決定木は, 学習データの少しの変化で識別器の性能が大きく変化してしまう不安定な識別器だった.
識別器のバラツキはブートストラップサンプルのバラツキが反映されるので, 決定木間の相関が高くなり, 性能が似る.
アダブースト(AdaBoost)
AdaBoost是英文"Adaptive Boosting"(自适应增强)的缩写,它的自适应在于:前一个基本分类器被错误分类的样本的权值会增大,而正确分类的样本的权值会减小,并再次用来训练下一个基本分类器。同时,在每一轮迭代中,加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数才确定最终的强分类器。
ブースティングは, 複数の弱識別器を用意して, 学習を直列的にし,前の弱識別器の学習結果を参考にしながら, 一つずつ弱識別器を学習する方法.
各弱識別器は, 学習データに対する誤り率が ϵ≤21−γ(γ>0) を満たすように学習が行われる. 代表的なブースティングアルゴリズムにアダブーストがある.
アダブーストでは, 弱識別器の学習結果に従って学習データに重みが付く. 誤った学習データに対して重みを大きくし, 正しく識別された学習データに対する重みを小さくすることで, 集中的に誤りの多い学習データを学習する.

- Em は誤った学習データの正規化された重みの和なので, 誤差が小さいほど大きな値になる
- (3)の YM(x) の計算では, 誤りの小さな ym(x) に大きな重みを与えている
- 重みの更新では, 正しく識別された学習データの重みは更新されないが, 誤った学習データの重みが expαm>1 倍になる.
- 評価関数 Em を変えることで, 勾配ブースティングなどに発展していく.
AdaBoost的优点:
- Adaboost提供一种框架,在框架内可以使用各种方法构建子分类器。可以使用简单的弱分类器,不用对特征进行筛选,也不存在过拟合的现象
- Adaboost算法不需要弱分类器的先验知识,最后得到的强分类器的分类精度依赖于所有弱分类器。无论是应用于人造数据还是真实数据,Adaboost都能显著的提高学习精度
- Adaboost算法不需要预先知道弱分类器的错误率上限,且最后得到的强分类器的分类精度依赖于所有弱分类器的分类精度,可以深挖分类器的能力。Adaboost可以根据弱分类器的反馈,自适应地调整假定的错误率,执行的效率高
- Adaboost对同一个训练样本集训练不同的弱分类器,按照一定的方法把这些弱分类器集合起来,构造一个分类能力很强的强分类器,即“三个臭皮匠赛过一个诸葛亮”
AdaBoost的缺点:
- 在Adaboost训练过程中,Adaboost会使得难于分类样本的权值呈指数增长,训练将会过于偏向这类困难的样本,导致Adaboost算法易受噪声干扰。此外,Adaboost依赖于弱分类器,而弱分类器的训练时间往往很长
ランダムフォレスト(random forests)
随机森林在bagging基础上做了修改。基本思路是:
- 从样本集中用Bootstrap采样(有放回的采样)选出n个样本(重采样)
- 从所有属性中随机选择k个属性,选择最佳分割属性作为节点建立CART决策树
- 重复以上两步m次,即建立了m棵CART决策树
- 这m个CART形成随机森林,通过投票表决结果,决定数据属于哪一类
随机性在于n个样本的随机,及其k个特征属性的选择,这两个随机
バギングの問題点として, ブートストラップサンプルによる生成のため決定木間の相関が高くなる.
M 個の確率変数の任意の2つの確率変数間に正の相関 ρ がある場合, 標本平均の分散は
Var(X)=M1−ρσ2+ρσ2
となる. ブートストラップサンプル数の M を増やせば, 第1項は減少するが第2項は減少しない.
ランダムフォレストは ρ を減らす仕組みを入れてバギングを強化した手法.
ランダムフォレストの学習アルゴリズムは, 決定木の各非最終ノードにおいて, 識別に用いる特徴をあらかじめ決められた数だけランダムに選択すること.
ランダムフォレストを用いると, 森のサイズによる誤り率の変化や, 特徴の重要さに関する情報, 学習データ間の近さに関する情報を得ることができる.

ランダムフォレストによるデータ解析
Out-of-Bag(OOB)誤り率とは, 学習に使われなかった決定木を集めて部分木を構成して, その学習データをテストデータにして誤り率を評価したものである.
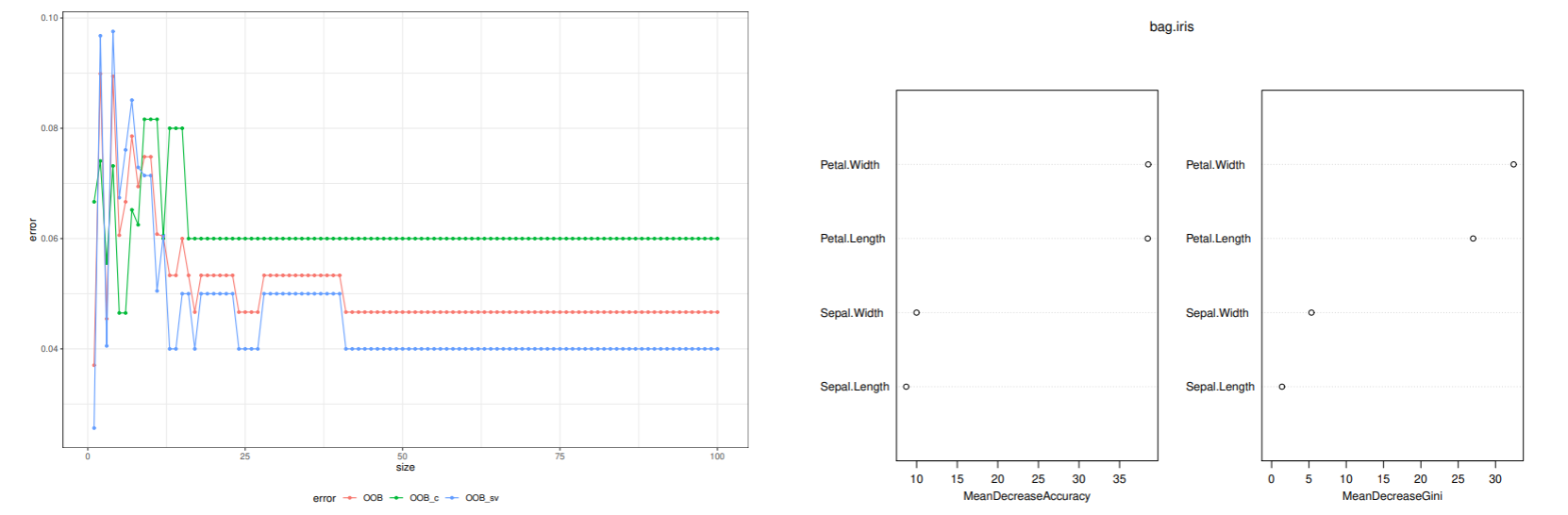
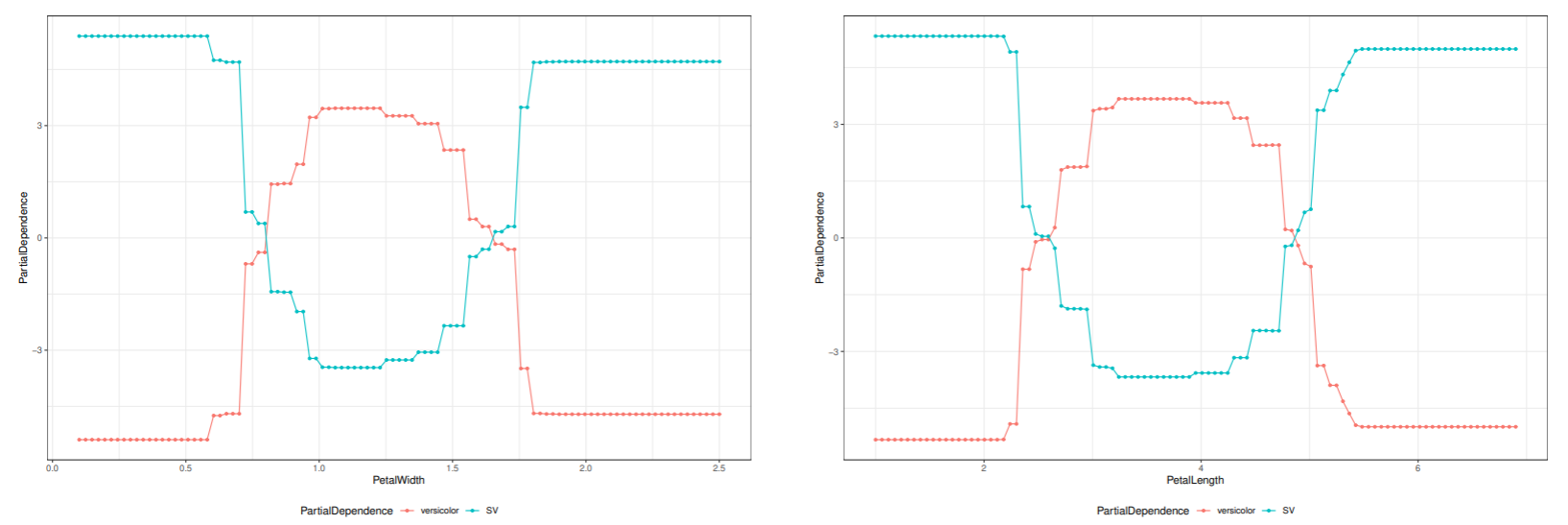
特徴量 x が識別にどのように寄与しているかを調べるのに部分依存グラフを使う.
i 番目の学習データの分析対象の変数を x と置き換えて, 以下を計算する.
fk(x)=i=1∑N(lnpk(xi(x))−K1j=1∑Nlnpj(xi(x)))
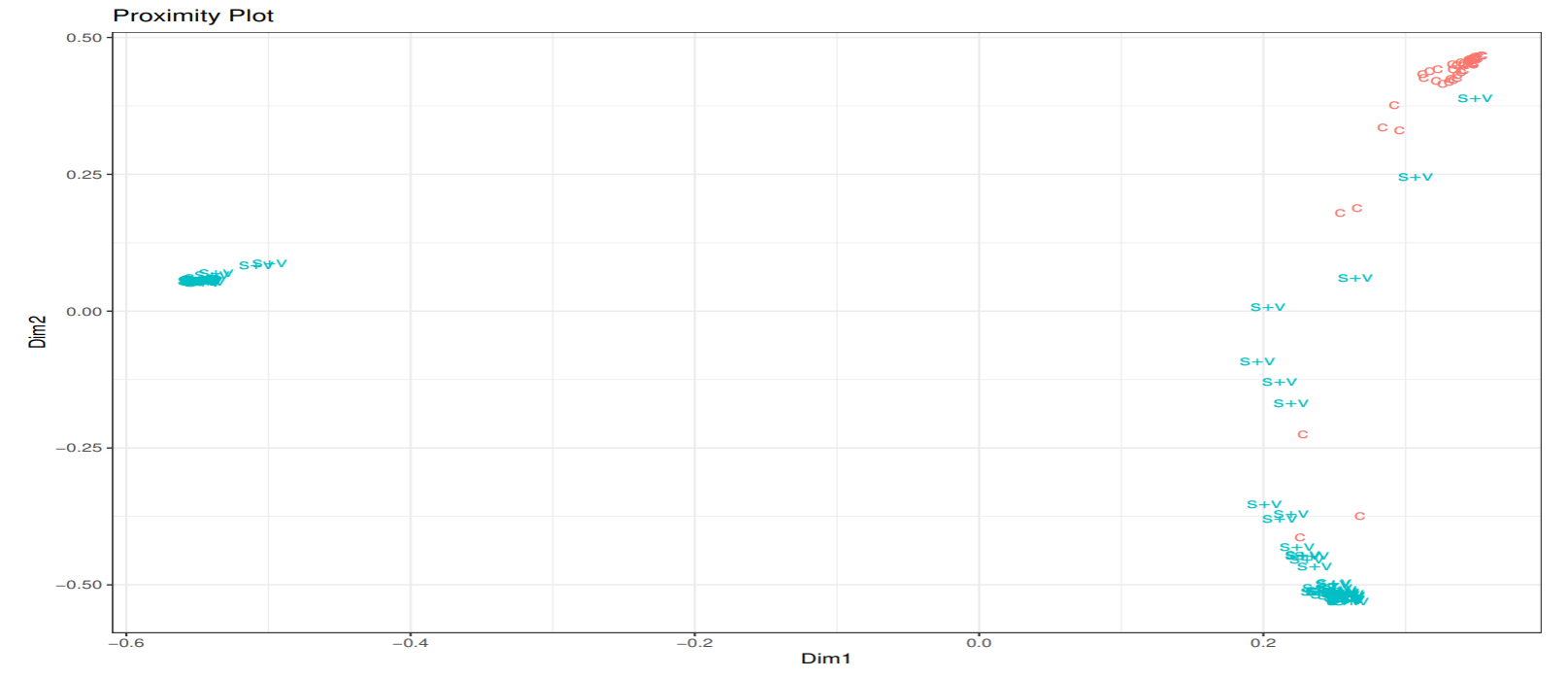
i 番目と j 番目の学習データが, OOB で同じ終端ノードに分類される木であれば, N××N の近接行列の (i,j),(j,i) 要素に1を加える.
この近接行列を多次元尺度構成法により2次元に射影する. アヤメデータについて学習データ間の近さを表す近接グラフをプロットした
あやめデータによる性能評価
setosa と virginica を1つのクラスに, versicolor をもう1つのクラスにした2クラスの識別問題を考える. 特徴量は, 4変数すべて使い, 10分割交差検証法による汎化誤差を推定した.
|
決定木 |
バギング |
アダブースト |
ランダムフォレスト |
| 誤り率 |
0.16 |
0.053 |
0.04 |
0.04 |
どの手法でも木は最大に成長させ, 剪定はしていない. アダブーストとランダムフォレストが最も良い結果となっている.
总结-机器学习与数据挖掘
问题
- 分类
- 聚类
- 回归
- 异常检测
- 自动机器学习
- 关联规则
- 强化学习
- 结构预测
- 特征学习
- 线上机器学习
- 无监督学习
- 半监督学习
- 排序学习
- 语法归纳
监督式学习(分类・回归)
- 决策树
- 集成(装袋,提升,随机森林)
- k-NN
- 线性回归
- 朴素贝叶斯
- 神经网络
- 逻辑回归
- 感知器
- 支持向量机(SVM)
- 相关向量机(RVM)
聚类
- BIRCH
- 层次
- k-平均
- 期望最大化(EM)
- DBSCAN
- OPTICS
- 均值飘移
降维
- 因子分析
- CCA
- ICA
- LDA
- NMF
- PCA
- LASSO
- t-SNE
结构预测
异常检测
神经网络
- 自编码
- 深度学习
- 多层感知机
- RNN
- 受限玻尔兹曼机
- SOM
- CNN
强化学习
理论
- 偏差/方差困境
- 计算学习理论
- 经验风险最小化
- PAC学习
- 统计学习
- VC理论
参考文献