微服务之父Martin先生给微服务的定义:将一个单体应用拆分成一组微小的服务组件,每个微小的服务组件运行在自己的进程上,组件之间通过如RESTful API这样的轻量级机制进行交互,这些服务以业务能力为核心,用自动化部署机制独立部署,另外,这些服务可以用不同的语言进行研发,用不同技术来存储数据
微服务简介
微服务实践要解决的问题
- 客户端如何访问这些服务?
添加一个网关API Gateway,网关的作用主要包括:
- 提供统一服务入口,让微服务对前台透明
- 聚合后台的服务,节省流量,提升性能
- 提供安全,过滤,流控等API管理功能
- 每个服务之间如何进行通信?
所有的微服务都是独立部署,运行在自己的进程容器中,所以微服务与微服务之间的通信就是IPC(Inter Process Communication),翻译为进程间通信。最常见的有两大类:同步调用、异步消息调用
同步调用有:REST(REST基于HTTP,实现更容易,各种语言都支持,同时能够跨客户端,对客户端没有特殊的要求,只要具备HTTP的网络请求库功能就能使用)和RPC(RPC的特点是传输效率高,安全性可控,在系统内部调用实现时使用的较多)
向系统外部暴露采用REST,向系统内部暴露调用采用RPC方式
异步调用是消息队列方式,常见的异步消息调用的框架有:Kafaka、Notify、MessageQueue
- 多个微服务,应如何实现?
使用服务管理框架:Zookeeper等,具体来说:当服务上线时,服务提供者将自己的服务注册信息注册到某个专门的框架中,并通过心跳维持长链接,实时更新链接信息。服务调用者通过服务管理框架进行寻址,根据特定的算法,找到对应的服务,或者将服务的注册信息缓存到本地,这样提高性能。当服务下线时,服务管理框架会发送服务下线的通知给其他服务
- 如果服务出现异常宕机,该如何解决?
重试机制,限流,熔断机制,负载均衡,降级(本地缓存)等
Protobuf简介
RPC通信
对于单独部署,独立运行的微服务实例而言,在业务需要时,需要与其他服务进行通信,这种通信方式是进程之间的通讯方式(inter-process communication,简称IPC)。IPC有两种实现方式,分别为:同步过程调用、异步消息调用。在同步过程调用的具体实现中,有一种实现方式为RPC通信方式,远程过程调用(Remote Procedure Call,缩写为 RPC)
远程过程调用是一个计算机通信协议。该协议允许运行于一台计算机的程序调用另一台计算机的子程序,而程序员无需额外地为这个交互作用编程。如果涉及的软件采用面向对象编程,那么远程过程调用亦可称作远程调用或远程方法调用
简单地说就是能使应用像调用本地方法一样的调用远程的过程或服务。很显然,这是一种client-server的交互形式,调用者(caller)是client,执行者(executor)是server。典型的实现方式就是request–response通讯机制
一个正常的RPC过程可以分为一下几个步骤:
- client调用
client stub,这是一次本地过程调用 client stub将参数打包成一个消息,然后发送这个消息。打包过程也叫做marshalling- client所在的系统将消息发送给server
- server的系统将收到的包传给
server stub server stub解包得到参数。解包也被称作unmarshallingserver stub调用服务过程。返回结果按照相反的步骤传给client
Protobuf协议语法
Protobuf协议规定:使用该协议进行数据序列化和反序列化操作时,首先定义传输数据的格式,并命名为以.proto为扩展名的消息定义文件
- message:Protobuf中定义一个数据结构需要用到关键字message,与Go语言中的struct类似
- 标识号: 在消息的定义中,每个字段等号后面都有唯一的标识号,用于在反序列化过程中识别各个字段的,一旦开始使用就不能改变。标识号从整数1开始,依次递增,每次增加1,标识号的范围为 ,其中
19000-19999为Protobuf协议预留字段,开发者不建议使用该范围的标识号;一旦使用,在编译时Protoc编译器会报出警告 - 字段规则:字段规则有三种,注意:proto3版本不支持!
required:该规则规定,消息体中该字段的值是必须要设置的optional:消息体中该规则的字段的值可以存在,也可以为空,optional的字段可以根据defalut设置默认值repeated:消息体中该规则字段可以存在多个(包括0个),该规则对应java的数组或者go语言的slice
- 数据类型:常见的数据类型与protoc协议中的数据类型映射如下
| .proto类型 | Java类型 | C++类型 | Go语言类型 | 备注 |
|---|---|---|---|---|
| double | double | double | float64 | 双精度 |
| float | float | float | float32 | 单精度 |
| int32 | int | int | int32 | 可变长编码方式。编码负数时不够高效,如果字段可能包含负数,可以使用sint32 |
| int64 | long | int64 | int64 | 可变长编码方式。编码负数时不够高效,如果字段可能包含负数,使用sint64 |
| uint32 | int[1] | uint32 | uint32 | |
| uint64 | uint64 | uint64 | ||
| sint32 | int | int32 | int32 | 可变长编码方式,有符号的整形值。编码时比int32效率高 |
| sint64 | long | int64 | int64 | 可变长编码方式,有符号的整形值,编码时比int64效率高 |
| fixed32 | int[1] | uint32 | uint32 | 总是4个字节。如果所有数值均比大,该种编码方式比uint32高效 |
| fixed64 | long[1] | uint64 | uint64 | 总是8个字节。如果所有数值均比大,此种编码方式比uint64高效 |
| sfixed32 | int | uint32 | int32 | 总是4个字节 |
| sfixed64 | long | uint64 | int64 | 总是8个字节 |
| bool | boolean | bool | bool | |
| string | String | String | string |
- 枚举类型:可以使用
enum关键字定义在.proto文件中 - 字段默认值:
.proto文件支持在进行message定义时设置字段的默认值,可以通过default进行设置:required sint32 id = 1 [default = 1];注意:proto3版本不支持! - 导入:如果需要引用的
message是写在别的.proto文件中,可以通过import "xxx.proto"来进行引入 - 嵌套:message与message之间可以嵌套定义,与go语言结构体嵌套一样
- message更新规则:message定义以后如果需要进行修改,为了保证之前的序列化和反序列化能够兼容新的message,message的修改需要满足以下规则:
- 不可以修改已存在域中的标识号
- 所有新增添的域必须是
optional或者repeated - 非required域可以被删除。但是这些被删除域的标识号不可以再次被使用
- 非required域可以被转化,转化时可能发生扩展或者截断,此时标识号和名称都是不变的
- sint32和sint64是相互兼容的
- fixed32兼容sfixed32。 fixed64兼容sfixed64
- optional兼容repeated。发送端发送repeated域,用户使用optional域读取,将会读取repeated域的最后一个元素
总结
微服务需要解决的一个问题是:服务之间如何进行通信。前面说了可以采用:
- 同步过程调用:REST API,RPC
- RPC过程调用中需要解决的三个问题:
- Call ID的映射:例如服务A要提供一个a方法,服务B要访问服务A的方法a的话,需要知道一个id来映射这个方法
- 序列化与反序列化(Protubuf):服务B要向服务A发起调用,这个过程需要通信,通信需要传输数据结构,这个数据结构在传输过程中需要涉及序列化与反序列化,采用
Protubuf协议是因为它是二进制形式来进行数据传输,效率高于XML - 网络传输:序列化和反序列化后,数据需要在网络间传输,涉及到网络层,这里需要使用grpc框架
- RPC过程调用中需要解决的三个问题:
- 异步消息调用
微服务管理
微服务还需要解决一个问题:多个服务如何实现,前面说过需要一个服务管理框架
服务实例需要动态分配网络地址,而且,一组服务实例可能会因为自动扩展、失败或者升级发生动态变化,因此客户端代码应该使用更加精细的服务发现机制。在生产实践中,主要有两种服务发现机制:客户端发现和服务端发现
客户端发现模式
服务实例的网络地址在服务启动的时候被登记到服务注册表中,当实例终止服务时从服务注册表中移除。服务实例的注册一般是通过心跳机制阶段性的进行刷新
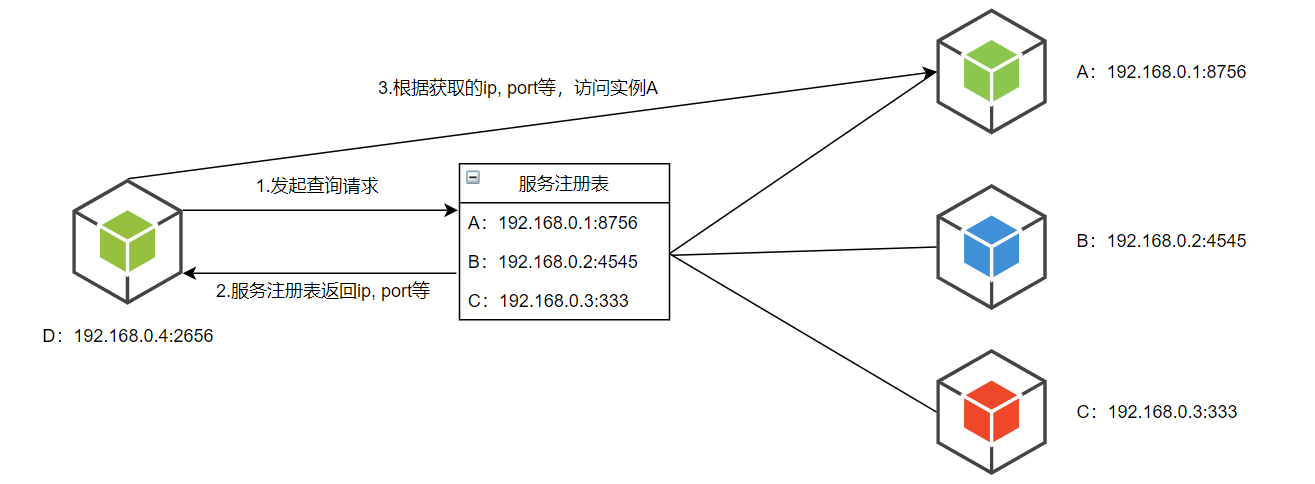
- 客户端发现机制的优势:
- 该模式中只增加了服务注册表,整体架构也相对简单
- 客户端可以使用更加智能的,特定于应用的负载均衡机制,如一致性哈希
- 客户端发现机制的缺点:
- 客户端发发现机制中,客户端与服务注册表紧密耦合在一起,开发者必须为每一种消费服务的客户端对应的编程语言和框架版本都实现服务发现逻辑
往往大公司会采用客户端发现机制来实现服务的发现与注册的模式
服务端发现模式
客户端通过一个负载均衡器向服务发送请求,负载均衡器查询服务注册表并把请求路由到一台可用的服务实例上。和客户端发现一样,服务实例通过服务注册表进行服务的注册和注销
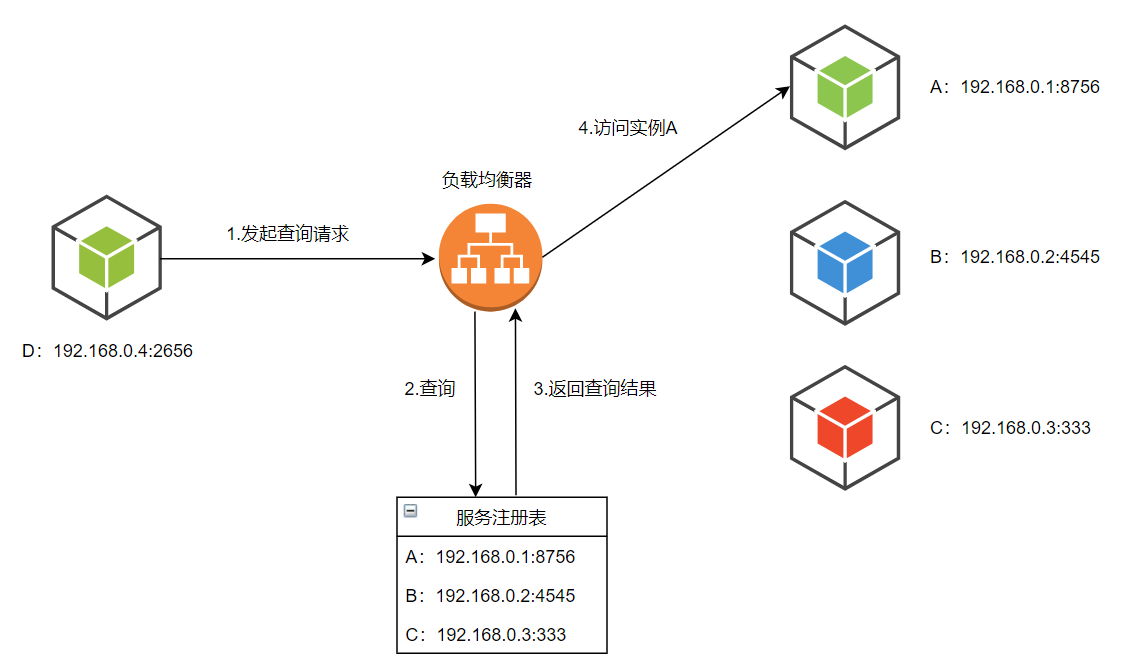
- 服务端发现机制的优势:
- 服务发现的细节对客户端来说是抽象的,客户端仅需向负载均衡器发送请求即可
- 这种方式减少了为消费服务的不同编程语言与框架实现服务发现逻辑的麻烦。很多部署环境已经提供了该功能
- 服务端发现机制的缺点:
- 除非部署环境已经提供了负载均衡器,否则这又是一个需要额外设置和管理的可高可用的系统组件
服务注册表
服务注册表是服务发现的关键部分,它是一个包含服务实例网络地址的的数据库。一个服务注册表需要高可用和实时更新,客户端可以缓存从服务注册表获取的网络地址。然而,这样的话缓存的信息最终会过期,客户端不能再根据该信息发现服务实例。因此,服务注册表对集群中的服务实例使用复制协议来维护一致性
例如:Netflix Eureka是典型的服务注册表的案例实现,它为服务实例的注册与查询提供了REST API:一个服务实例可以使用POST来注册自己的网络地址,它必须每30秒通过PUT去刷新,服务实例可以直接或者在服务实例注册超时的时候使用DELETE删除注册表中的信息,另外客户端可以使用HTTP GET获取注册实例的信息
除Netflix Eureka外还有:
- etcd:一个高可用、分布式、一致性、
key-value方式的存储,被用在分享配置和服务发现中。两个著名的项目使用了它:Kubernetes和Cloud Foundry - consul:一个发现和配置服务的工具,为客户端注册和发现服务提供了API,
Consul还可以通过执行健康检查决定服务的可用性 - Apache Zookeeper:
Zookeeper是一个广泛使用、高性能的针对分布式应用的协调服务。Apache Zookeeper本来是Hadoop的子工程,现在已经是顶级工程了
服务注册方式
服务实例必须使用服务注册表来进行服务的注册和注销,在实践过程中有不同的方式来实现服务的注册和注销:
- self-registration模式:服务实例自己负责通过服务注册表对自己进行注册和注销,另外如何有必要的话,服务实例可以通过发送心跳包请求防止注册过期
- 优势:相对简单,而且不强制使用其他的系统组件
- 劣势:使得服务实例和服务注册表强耦合,你必须在每一个使用服务的客户端编程语言和架构代码中实现注册逻辑
- third-party registration模式:服务实例本身并不负责通过服务注册表注册自己,相反的,通过另一个被称作
service registrar系统组件来处理注册。service registrar通过轮询或者订阅事件来检测一些运行实例的变化,当它检测到一个新的可用服务实例时就把该实例注册到服务注册表中去,service registrar还负责注销已经被终止的服务实例- 优势:使得服务从服务注册表中被解耦,不必为开发者使用的每种开发语言和框架实现服务注册的逻辑,相反,服务实例的注册被一个专有服务以集中式的方式处理
- 劣势:除非它被内置在部署环境中,不然这又是一个需要被设置和管理的高可用系统组件
总结
在一个微服务应用中,一组运行的服务实例是动态变化的,实例有动态分配的网络地址,因此,为了使得客户端能够向服务发起请求,必须要有服务发现机制
服务发现的关键是服务注册表,服务注册表是可用服务实例的数据库,它提供了管理和查询使用的API。服务实例使用这些管理API进行服务的注册和注销,系统组件使用查询API来发现可用的服务实例
- 客户端发现的案例:Eureka,ZooKeeper
- 服务端发现的案例:consul+nigix
RPC远程调用机制
RPC简介及原理介绍
远程过程调用(RPC)指的是调用远程服务器上的程序的方法整个过程
RPC技术架构
- 客户端(Client):服务调用发起方,又称为服务消费者
- 服务器(Server):远端服务器机器上运行的程序,其中包括客户端要调用和访问的方法
- 客户端存根(Client Stub):存放服务端的地址,端口消息。将客户端的请求参数打包成网络消息,发送到服务方。接受服务方返回的数据包。该段程序运行在客户端
- 服务端存根(Server Stub):接受客户端发送的数据包,解析数据包,调用具体的服务方法。将调用结果打包发送给客户端一方。该段程序运行在服务端
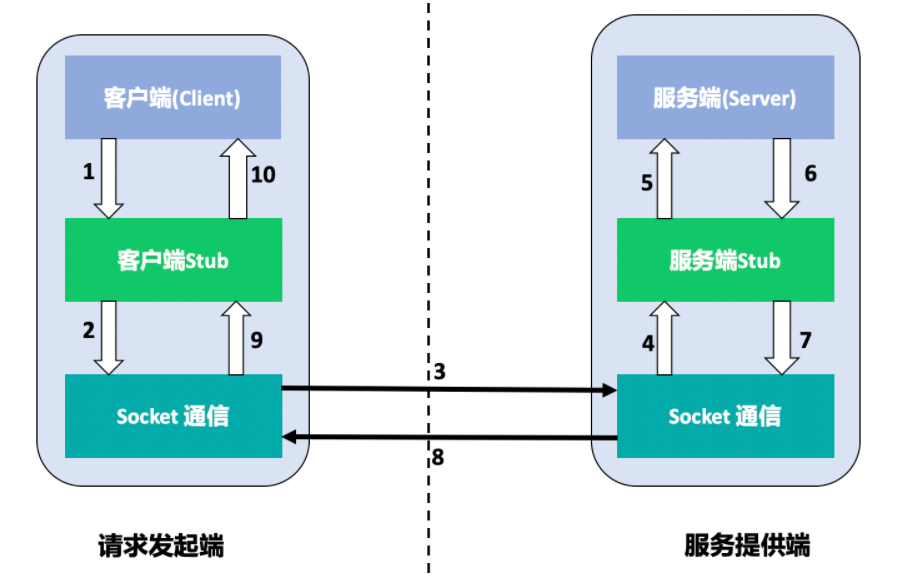
可以看到RPC是一系列操作的集合,其中涉及到很多对数据的操作,以及网络通信,RPC中涉及到的技术有:
- 动态代理技术:
Client Stub和Sever Stub程序,在具体的编码和开发实践过程中,都是使用动态代理技术自动生成的一段程序 - 序列化和反序列化:在互联网上,所有的数据都是以字节的形式进行传输的。而我们在编程的过程中,往往都是使用数据对象,因此想要在网络上将数据对象和相关变量进行传输,就需要对数据对象做序列化和反序列化的操作
- 序列化:把对象转换为字节序列的过程称为对象的序列化,也就是编码的过程
- 反序列化:把字节序列恢复为对象的过程称为对象的反序列化,也就是解码的过程
Go语言实现RPC编程
Go语言官方网站的pkg说明中,提供了官方支持的rpc包,链接net/rpc,里面详细讲述了net/rpc库实现RPC调用编程:
对服务端:
- 服务定义及暴露
- 注册服务及监听请求
对客户端:
- 完成对服务端的调用
RPC与Protobuf结合使用
RPC与Protobuf结合使用大致分为以下四部:
- 在
.proto文件中定义传输数据格式 - 编译proto文件,自动生成对应结构体的Go语言文件
- 服务端:服务的定义,服务的注册和处理
- 客户端:RPC客户端调用实现
gRPC微服务框架
gRPC介绍和安装
gRPC介绍
gRPC是由Google公司开源的一款高性能的远程过程调用(RPC)框架,可以在任何环境下运行。该框架提供了负载均衡,跟踪,智能监控,身份验证等功能,可以实现系统间的高效连接。另外,在分布式系统中,gRPC框架也有有广泛应用,实现移动社会,浏览器等和服务器的连接
gRPC调用执行过程
gRPC支持多种语言的实现,因此gRPC支持客户端与服务器在多种语言环境中部署运行和互相调用

gRPC中默认采用的数据格式化方式是protocol buffers
grpc-go安装
grpc-go库是gRPC库的Golang语言实现版本
gRPC框架使用
gRPC框架使用大致分为4步:
- 定义服务:
.proto文件定义 - 编译
.proto文件 - 服务端:服务接口实现 + gRPC实现服务端
- 客户端:gRPC实现客户端
定义服务
与RPC标准库稍微不同的是,gRPC通过proto文件定义了数据结构的同时,还定义了要实现的服务接口
1 | syntax = "proto3"; |
编译.proto文件
编译.proto文件的基本用法:
1 | protoc --go_out=. *.proto |
gRPC编译支持:开发者可以采用protocol-gen-go库提供的插件编译功能,生成兼容gRPC框架的golang语言代码。只需要在基本编译命令的基础上,指定插件的参数,告知protoc编译器即可
1 | protoc --go_out=plugins=grpc:. *.proto |
gRPC实现RPC编程
在.proto定义好服务接口并生成对应的go语言文件后,需要对服务接口做具体的实现,与使用RPC标准库时相比,不同点是服务接口参数的变化,这里需要查看生成的go文件中接口参数的规定
gRPC调用
上一小节,在客户端与服务端之间通过消息结构体定义的方式来传递数据,我们称之为单项RPC,也称之为简单模式(Simple RPC)。除此之外,gRPC中还有数据流模式的RPC调用实现
服务端流模式
在Server-side streaming RPC的实现中,服务端得到客户端请求后,处理结束返回一个数据应答流。在发送完所有的客户端请求的应答数据后,服务端的状态详情和可选的跟踪元数据发送给客户端
服务接口定义
1 | // 订单服务service定义 |
与之前简单模式下的数据作为服务接口的参数和返回值不同的是,此处服务接口的返回值使用了stream进行修饰。通过stream修饰的方式表示该接口调用时,服务端会以数据流的形式将数据返回给客户端
编译.proto文件
使用gRPC插件编译命令编译.proto文件:
1 | protoc --go_out=plugins=grpc:. message.proto |
自动生成文件的变化
与数据结构体发送携带数据实现不同的时,流模式下的数据发送和接收使用新的功能方法完成。在自动生成的go代码程序当中,每一个流模式对应的服务接口,都会自动生成对应的单独的client和server程序,以及对应的结构体实现
服务端自动生成代码部分:
1 | type OrderService_GetOrderInfosServer interface { |
服务端流模式下,服务接口的服务端提供Send()方法,将数据以流的形式进行发送
客户端自动生成代码部分:
1 | type OrderService_GetOrderInfosClient interface { |
服务端流模式下,服务接口的客户端提供Recv()方法接收服务端发送的流数据
客户端流模式
在Client-side streaming RPC的实现中,客户端进行数据请求时,以流的形式发送请求数据的形式
服务接口的定义
使用stream修饰服务接口的接收参数
1 | // 订单服务service定义 |
自动生成文件的变化
客户端流模式下,服务端要接受从客户端传入流数据,使用其Recv()方法接收客户端消息,并使用其SendAndClose()方法返回其单个响应
客户端流模式下,客户端要向服务端发送流数据,使用Send()将客户端的请求写入流后,我们需要在流上调用CloseAndRecv()以让gRPC知道我们已完成写入并期待收到响应
双向流模式
在Bidirectional streaming RPC中,客户端发送数据的时候以流数据发送,服务端返回数据也以流的形式进行发送
双向流服务的定义
1 | // 订单服务service定义 |
双向流模式下,服务端要接受从客户端传入流数据,使用其Recv()方法接收客户端消息,使用Send()将客户端的请求写入流。尽管每一方总是按照写入的顺序获取对方的消息,但客户端和服务器都可以按任意顺序读写——流完全独立运行
双向流模式下,客户端要向服务端发送流数据,使用Send()将客户端的请求写入流,使用其Recv()方法接收客户端消息。在完成调用后使用流的CloseSend()方法,尽管每一方总是按照写入的顺序获取对方的消息,但客户端和服务器都可以按任意顺序读写——流完全独立运行
TLS验证和Token认证
在实际的生产环境中,一个功能完整的服务,不仅包含基本的方法调用和数据交互的功能,还包括授权认证,数据追踪,负载均衡等方面
gRPC中默认支持两种授权方式,分别是:SSL/TLS认证方式、基于Token的认证方式
SSL/TLS认证方式
SSL/TLS是一种用于网络通信中加密的安全协议
SSL(Secure Sockets Layer),又被称之为安全套接字层,是一种标准安全协议,用于在通信过程中建立客户端与服务器之间的加密链接
TLS(Transport Layer Security),TLS是SSL的升级版。在使用的过程中,往往习惯于将SSL和TLS组合在一起写作SSL/TLS
SSL/TLS工作原理
使用SSL/TLS协议对通信连接进行安全加密,是通过非对称加密的方式来实现的。密钥对由公钥和私钥两种密钥组成。私钥和公钥成对存在,先生成私钥,通过私钥生成对应的公钥。公钥可以公开,私钥进行妥善保存
在加密过程中:客户端想要向服务器发起链接,首先会先向服务端请求要加密的公钥。获取到公钥后客户端使用公钥将信息进行加密,服务端接收到加密信息,使用私钥对信息进行解密并进行其他后续处理,完成整个信道加密并实现数据传输的过程
制作证书:可以自己在本机计算机上安装openssl,并生成相应的证书
实际生产过程当中,证书是由公司提供
1 | openssl ecparam -genkey -name secp384r1 -out server.key |
- 前面均可不填,只填写
Common Name Common Name一般填写网站域名,这里设置的名称,后面客户端会用到
Go 1.15 版本开始废弃CommonName并且推荐使用SAN证书,导致依赖CommonName的证书都无法使用了
基于Token认证方式
在web应用的开发过程中,往往还会使用另外一种认证方式进行身份验证,即Token认证。基于Token的身份验证是无状态,不需要将用户信息服务存在服务器或者session中
基于Token认证的身份验证主要过程是:客户端在发送请求前,首先向服务器发起请求,服务器返回一个生成的token给客户端。客户端将token保存下来,用于后续每次请求时,携带着token参数。服务端在进行处理请求之前,会首先对token进行验证,只有token验证成功了,才会处理并返回相关的数据
客户端:实现credentials包的接口,GetRequestMetadata和RequireTransportSecurity
服务端:在metadata验证客户端的信息
拦截器(Interceptor)
上一小节,学习使用了gRPC框架中的两种认证方式:TLS验证和Token验证
但是,在服务端的方法中,每个方法都要进行token的判断。程序效率太低,可以优化一下处理逻辑,在调用服务端的具体方法之前,先进行拦截,并进行token验证判断,这种方式称之为拦截器处理,类似于web框架里的中间件
- 除了此处的token验证判断处理以外,还可以进行日志处理等
中间件是什么
中间件是一个系统软件和应用软件之间的沟通桥梁,可以记录响应时长、记录请求和响应数据日志等,中间件可以在拦截到发送给handler的请求,且可以拦截handler返回给客户端的响应
拦截器的使用
使用拦截器,首先需要注册:在grpc中编程实现中,可以在NewSever时添加拦截器设置,grpc框架中可以通过UnaryInterceptor方法设置自定义的拦截器,并返回ServerOption
1 | grpc.UnaryInterceptor() |
UnaryInterceptor()接收一个UnaryServerInterceptor类型,继续查看源码定义,可以发现UnaryServerInterceptor是一个func,定义如下:
1 | type UnaryServerInterceptor func(ctx context.Context, req interface{}, info *UnaryServerInfo, handler UnaryHandler) (resp interface{}, err error) |
如果开发者需要注册自定义拦截器,需要自定义实现UnaryServerInterceptor的定义
例如,Token验证:
1 | func TokenInterceptor(ctx context.Context, req interface{}, info *grpc.UnaryServerInfo, handler grpc.UnaryHandler) (resp interface{}, err error) { |
在自定义的TokenInterceptor方法定义中,和之前在服务的方法调用的验证逻辑一致,从metadata中取出请求头中携带的token认证信息,并进行验证是否正确。如果token验证通过,则继续处理请求后续逻辑,后续继续处理可以由grpc.UnaryHandler进行处理。grpc.UnaryHandler同样是一个方法,其具体的实现就是开发者自定义实现的服务方法。grpc.UnaryHandler接口定义源码定义如下:
1 | type UnaryHandler func(ctx context.Context, req interface{}) (interface{}, error) |
拦截器注册
在服务端调用grpc.NewServer时进行拦截器的注册
1 | server := grpc.NewServer(grpc.Creds(creds), grpc.UnaryInterceptor(TokenInterceptor)) |